
三维点云深度学习分类模型学习策略分析
——以机载多光谱LiDAR点云为例
2023-11-07 14:54梁家安管海燕
测绘工程 2023年6期
梁家安,陈 科,季 铮,管海燕
(1.南京信息工程大学 遥感与测绘工程学院,南京 210044;2.武汉大学 遥感信息工程学院,武汉 430072)
三维点云数据能够真实地反映目标在三维空间中的几何形态、位置朝向以及大小尺寸等属性,基本不存在扭曲和形变。因此,由于这种几何不失真的优越性、三维空间信息的完整性,三维点云数据近些年在各行各业已受到了广泛的关注。目前,三维点云数据已被广泛地应用于道路桥梁规划、地图导航、自然灾害监测、自动驾驶、基础测绘、文化遗产数字化、影视动漫等领域[1-2]。三维点云数据所描述的自然场景具有数据量大、真三维、高冗余、非结构化、采样粒度分布严重不均以及不完整等典型特点,这对点云数据的存储和智能化解译都带来了严峻的挑战。三维点云数据的高效处理以及智能化解译方法的研发仍然处于相对滞后的状态,同时也存在着一定的瓶颈,亟需进一步的研究和探索。近年来,深度学习方法取得了较大成效,解决了传统机器学习方法无法准确表达显著性、易区分性和空间几何结构等特征,难以满足复杂场景高精度三维点云分类问题。
2017年提出的第一个以原始点云作为输入的网络模型PointNet[3],在ShapeNet数据集实现了83.7%的点云分类综合精度。该研究团队随后提出了PointNet++[4]网络模型,采用分层级网络架构设计,将下一网络层的点视为上一网络层的中心点搜索k近邻点构建局部邻域,利用PointNet提取局部特征,获得多尺度局部几何结构信息提高点云分类精度。后续开发的众多网络模型采用了类似的分层设计。此外,RS-CNN[5]、DensePoint[6]、PointConv[7]等采用三维连续卷积网络架构进行点层面的特征提取与形状分类;Geo-Conv[8]、PointCNN[9]、SFCNN[10]等采用三维离散卷积网络架构提取点云网格化表示的形状特征;DGCNN[11]、KCNet[12]、ClusterNet[13]、RGCNN[14]等则采用图卷积网络架构实现点特征地提取与目标的分类;2020年提出的RandLA-Net[15]模型创造性地提出了随机采样与局部特征整合模块结合的网络模型,在Semantic3D数据上实现了94.8%的点云分类精度,这无疑在网络模型设计方面获得巨大进步。目前深度学习的基础性研究主要集中在网络结构与模型设计,以及样本库的设计与标注这两大部分。网络结构与模型设计中涉及网络类型、网络层数、卷积核、池化函数、以及损失函数涉及等内容。要开展基于深度学习的三维点云分类和目标提取研究,需要高精度、大样本训练数据库,很多学者人工标注、自动标注和人工标注结合,对已有遥感产品采用迁移学习等标注方法发布了相关开源数据集等。目前很多研究针对模型本身设计展开了众多研究,如上述所提到的卷积网络架构等,通过改进特征模块以及模型结构来提高点云分类精度。研究发现这些设计复杂的模型算法在点云分类精度方面并没有太大的飞跃,但是模型复杂性增加会导致其计算耗能提高、数据处理效率低下等问题。更为重要的是,尽管这些方法在小尺度公共数据集上取得了很大的成功,甚至根据公共数据集也给出了最优学习策略配置,但是这些方法在处理大尺度遥感数据时,特别是海量、不规则的三维点云数据,存在数据采样中自然地物和人工地物几何不完整性、地物多样性造成算法泛化能力不强等问题,阻碍深度学习算法在遥感数据领域广泛应用。
针对这样的问题,文中选择了网络结构与模型设计中除模型本身外的训练样本生成、数据增强、损失函数、模型选择以及测试方法等构建一组学习策略,拟以点云分类网络模型PointNet++为基础模型,构建一套通用的、可以提高三维点云深度学习方法实际应用性能的学习策略组合,提高其在点云数据中的适用性。本次学习策略构建工作主要以新一代机载多光谱 LiDAR 数据为例展开研究,提高LiDAR数据的智能化解译水平与自动化程度。
1 学习策略
深度学习中涉及诸多学习策略,有些学习策略需要按照模型设计、设备性能以及数据集特点来精细调整其参数,例如学习率、迭代次数等。这些学习策略是直接与特定设计模型紧密联系,文中不考虑无通用性、不能提高大部分模型性能的学习策略。因此,文中研究的学习策略主要包括数据增强、损失函数、训练样本生成、模型选择以及测试方法5个方面。这些学习策略皆是独立于网络模型之外,可以广泛适用绝大多数的深度学习模型,替换其中任何一个学习策略内容对于网络模型本身没有影响,仅影响该网络模型完成点云分类性能。因此,文中仅以PointNet++为基本网络模型,重点研究和分析这5种学习策略内容对于点云分类所带来的影响。表1为目前广泛使用的学习策略。

表1 模型学习策略
1.1 数据增强
基于深度学习的遥感目标提取和分类依赖于高精度、大样本训练数据库。而对于三维点云数据,获得相应的高质量、可靠的学习样本通常费时费力,成本巨大。同时,由于三维点云数据通常受采集仪器,以及地形、环境等复杂自然因素影响,数据的通用性受到一定程度的制约。在处理三维点云数据过程中,通常采用数据增强(data augmentation)来增加模型训练的泛化能力。抖动(添加高斯噪声)、沿y轴旋转、随机缩放和随机平移方法是常用的几种点云数据增强方式。如图1所示,红色的点为原始点云,绿色点是采用其数据增强方式获得的点云。目前流行的深度学习点云分类模型采用其中一种或者几种数据增强方法来扩增训练数据集,如PointNet、PoinNet++、DPAM[16]和SpiderCNN[17]等模型采用了抖动、沿y轴旋转、随机缩放和随机平移等数据增强方法;DGCNN,RSCNN,PointCNN和PointASNL[18]等模型则仅仅使用了随机缩放和随机平移两种数据增强方法。

图1 数据增强策略示意图
1.2 损失函数
交叉熵(cross-entropy)损失函数是目前学习模型中较为常用网络参数,主要用来判定实际输出与期望输出的差异,利用这种差异经过反向传播去更新网络参数。在点云分类中即多分类任务中,一次迭代的交叉熵损失L可以表示为:
(1)
式中:N为一次迭代中的样本数量;M为类别的数量;yij为符号函数,样本i真实类别等于类别j取值1,否则取值0;Pij表示第i个样本预测属于类别j的概率。传统的交叉熵损失函数鼓励模型预测样本为真实标签的概率趋近于1,非真实标签的概率趋近于0。但在训练数据不足以覆盖所有情况或者数据集中真实标签出现错误点的情况下,交叉熵损失函数将会追求接近错误标签的概率,导致网络模型过拟合、泛化能力差。

(2)
式中:K为类别总个数,ε为平滑因子。平滑处理后的标签数据相当于为真实标签添加噪声,使模型不过分依赖所给真实标签,可提高网络模型的泛化能力,加快模型训练速度[19]。
1.3 训练样本数据生成
为了让基于点的深度学习方法适用于各种类型、场景的点云数据,许多研究不得不考虑如何将密度不均匀、分布不规则、点数不固定的点云数据处理生成为点数一致的训练样本数据这一问题。目前,针对三维点云数据进行训练样本生成方法主要有以下几种方法:基于固定点方法、分块后采样策略、最远采样点-k邻近点(FPS-KNN)采样策略。
固定点样本生成是不对点云数据集进行采样操作,最大程度保留原始点云特征,仅对数据集进行归一化处理。
分块后采样(如图2所示)首先将原始点云数据集归一化后,将其切割成一定尺寸的小点云块[20-22], 在每个点云块中采样固定点数N的点作为网络模型输入数据,PointNet、PointNet++以及DGCNN深度模型中采用此分块采样策略。由于每个点云块中包含不同数量的点,当块中的点数超过设置的点数量N,则使用最远采样点(FPS)算法下采样至N个点;反之则通过数据插值以获得设置点数。

图2 分块采样流程
FPS-KNN采样(图3)首先将原始点云数据集进行归一化,对归一化后V进行数据复制获得参考云点,所有后续样本生成操作在参考点云中进行。样本生成具体步骤如下:

图3 FPS-KNN输入点策略流程
1)从参考点云中随机选取一个点作为当前种子点;
2)利用KNN方法,从原始点云中寻找当前种子点的k个最近邻点。k值的设置是根据其设定的样本大小,即样本点个数来确定[23];当前种子点与其k个最近邻点作为一个点云样本,并从参考点云中移除。
3)根据FPS原则[24],计算当前种子点到参考点云中剩余点的距离,并选择最远距离对应的点作为下一个种子点;
4)整合输出样本,检查是否覆盖整个场景,若完全覆盖,则输出点云样本;若没有完全覆盖,迭代操作上述步骤2)和 3),直到参考点云为空。
1.4 模型选择
在深度学习过程中,需要训练集与验证集,在每一次使用训练集进行迭代训练之后,需使用验证集数据进行模型验证,得出该次迭代训练的预测样本,通过其误差反向传播指导网络参数学习。在迭代训练以及验证过程中,深度学习模型使用最佳模型策略或者最终模型策略两种方式来得到最终训练结果。
最佳模型策略是在每一次迭代后对验证集进行精度评估,将最好的评估结果作为最终模型训练,实现在测试集上较好分类结果,如DGCNN和RSCNN等采用此类模型策略。
最终模型策略使用最后一次迭代得到的权重作为模型训练结果,如PointNet和PointNet++采用此模型策略。值得注意的是:最终模型策略并不是不需要验证集,依然在每一次迭代中对验证集进行精度评估,同样使用验证集反向传播指导网络参数学习。
1.5 测试方法
为了进一步提高学习模型三维点云分类精度,很多研究在测试阶段用到了可以提升分类或者目标提取精度的投票测试方法。投票测试主要包括抖动投票、旋转投票、缩放投票以及平移投票。抖动投票是指在测试精度时将最终模型应用在多次抖动处理的点云上,然后将预测结果平均值作为最终精度。旋转投票是指在测试精度时将最终模型应用在多次旋转处理点云上;平移投票也是同理,是指在测试精度时将最终模型应用在多次平移处理点云上。PointNet和PointNet++模型采用旋转投票提高点云分类精度;RSCNN和DensePoint是将模型应用在了多次随机缩放的点云上。
本研究提出的数据增强投票,是在模型的投票测试中对点云测试集进行相应的数据增强,并在每个样本批次(Batch)中重复10次数据增强操作,取预测结果平均值作为该批次结果,将整个测试过程重复100次,取平均精度作为最终点云分类精度。相对于投票测试,非投票测试在模型测试时不对测试集做任何操作,重复测试100次,取平均精度为最终点云分类精度。
2 实验结果与分析
为了确定最佳学习策略,采用PointNet++为基础模型,以机载多光谱LiDAR数据为研究对象,进行三维点云分类研究。本研究实验的硬件环境为Intel Core i7-9700 [CPU],RAM 16G,NVIDIA GeForce RTX 2070 6 GB [GPU]的工作站。软件环境为装有python3.7和Pytorch的Windows10系统。实验中具体网络参数主要包括:学习率(Learning Rate)为0.001,批次大小(Batch-size)为8,训练迭代次数(Epoch)设为200,优化器为Adam[25]。
2.1 研究区域
实验数据相对于传统单波段LiDAR系统,机载多光谱LiDAR系统不仅能够快速获取测区地形表面采样点的空间坐标,而且同时可以采集到多个波段的地物光谱信息,其获取的数据是对地形表面最直接的描述和表达。本文的研究区域是位于加拿大安大略省惠特彻奇-史托维尔的一个小镇,如图4(a)所示。实验数据由加拿大Optech公司的Titan机载多光谱LiDAR系统采集,共采集了19条垂直交叉的航带数据,覆盖范围大约为25 km2。其中Optech Titan系统包含3个独立的300 kHz激光脉冲通道,分别是1 550 nm、1 064 nm和532 nm,并且这3个通道的激光脉冲以3.5°的偏转角度被发送到同1个震荡镜上,生成3个独立的点云数据集。本研究区域从多光谱LiDAR数据中裁剪1个面积为2 052 m×1 566 m的区域。
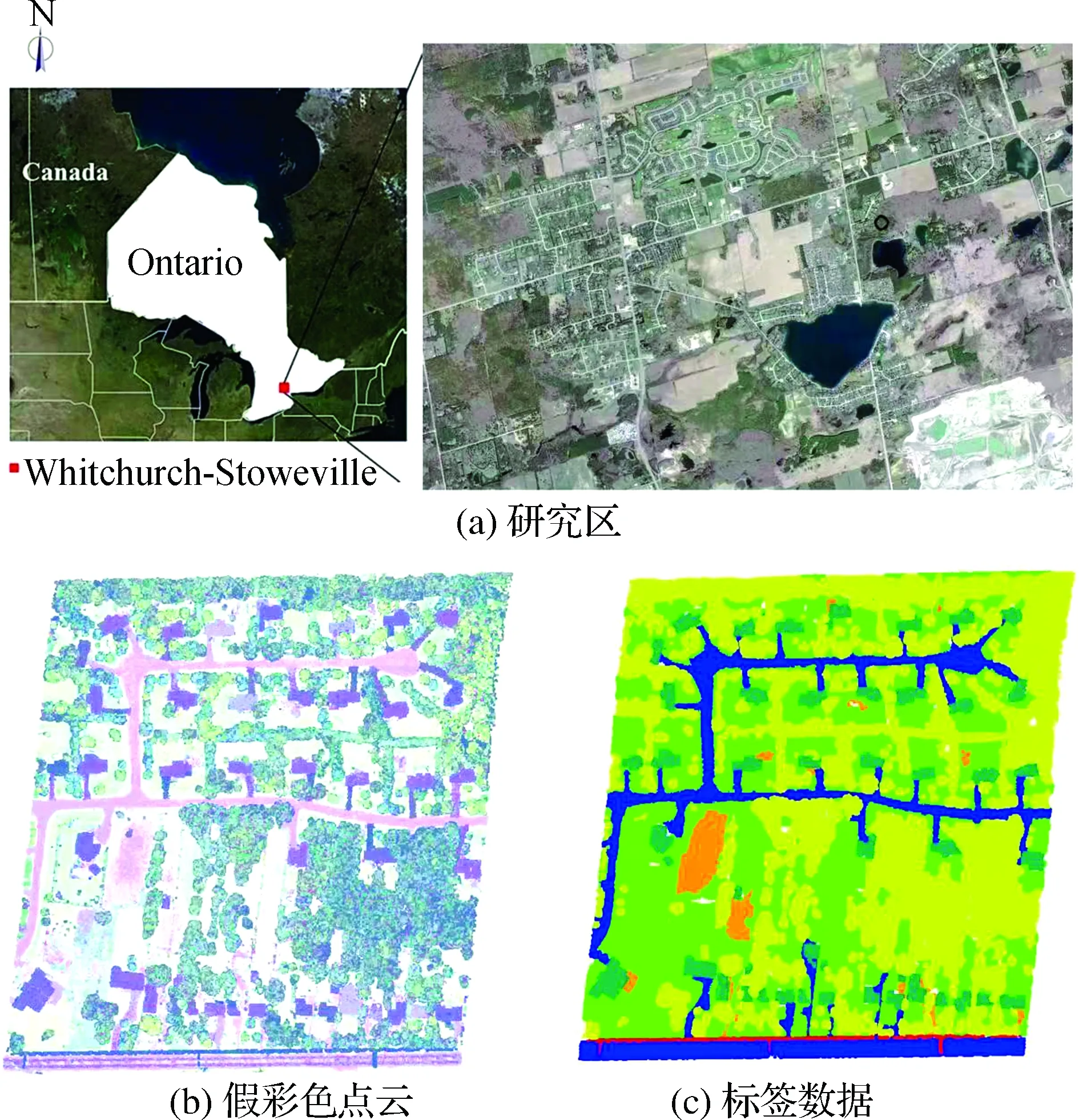
图4 实验数据
从实验区域中选取了13个小场景(包含较为丰富的地物类别:建筑物、树木、道路、草地、裸地、水体等)作为本论文的实验数据采集场景,其中1~9场景为训练数据,10~11场景为验证数据,12~13场景为测试数据,每个场景的面积与点云数量,参见表2。并且根据实验区域的地物分布情况,地物被标记为道路、建筑物、草地、树木、裸地和电力线6种类型。最终每个场景数据都包含每个激光点的三维坐标信息(x,y,z)、3个波段(1 550 nm,1 064 nm,532 nm)的光谱信息和对应的标签类别信息。
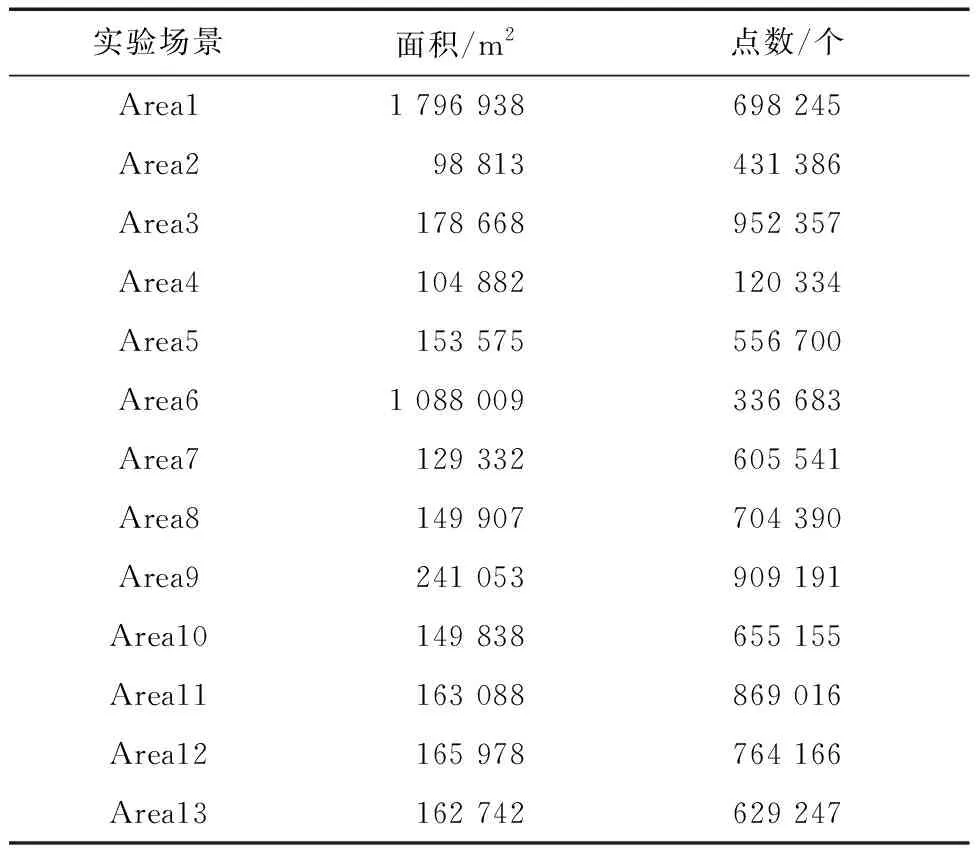
表2 实验场景面积和点云数量
2.2 数据增强与损失函数的对比试验
本节面向多光谱LiDAR数据,分析数据增强和损失函数两个学习策略内容在点云分类中的影响。在数据增强中,抖动策略是在数据集上添加均值为0,标椎差为0.2的高斯噪声;绕y轴旋转的旋转范围设为180°;随机缩放的范围设置在[-0.66,1.5]之间;随机平移的范围设置为[-0.2,0.2]之间。损失函数中,标签平滑损失函数中的平滑因子ε设置为0.2。此次试验中,采用分块后采样训练样本生成方法和最佳模型,且所有的精度均为非投票测试100次的平均总体分类精度。
机载多光谱LiDAR点云分类结果如表3所示。由表3中实验1与2可以看出,在使用抖动策略即高斯噪声(均值为0、标准差为0.2)后,PointNet++从原来不使用任何数据增强策略的90.26%下降到了88.24%,抖动策略导致了模型的分类精度下降了2.02%。实验1与实验3对比得知旋转策略(范围为180°)也导致模型分类精度下降了2.43%。而进行随机缩放(范围:[-0.66,1.5])和随机平移(范围:[-0.2,0.2])操作后,模型点云分类精度分别提高了2.57%和1.13%。上述数据增强实验结果表明:随机缩放以及随机平移的数据增强策略可以有效提高训练模型的泛化能力,提高点云分类精度。

表3 PointNet++采用不同数据增强、损失函数的分类精度(综合精度(OA)%)
对于标签平滑,从表3中实验1与6对比可以看出,PointNet++使用标签平滑的点云分类精度比使用交叉熵损失函数的点云分类精度高了0.45%。由此可见,标签平滑损失函数有利于模型的泛化能力,取得了更好的点云分类精度。
2.3 训练样本生成与模型选择策略的对比试验
本节选择不同的训练样本生成方法、模型选择策略进行试验。其余学习策略统一采用无数据增强、交叉熵损失和非投票测试,实验结果如表5所示。其中,分块后采样策略中每个点云块底部边长设置为0.12 m,点云个数N设为4 096个;FPS-KNN和固定点同样设置点的个数为4 096个。3种样本生成方法统一对数据集进行[0,1]的归一化处理。
通过表4中实验1与3的对比可以看出,采用固定点采样方法比采用FPS-KNN方法的分类精度提高了1.11%。实验1与2对比可以看出采用固定点方法比采用分块后采样方法的分类精度提高了3.42%。由此可见:固定点方法可以大幅度提高点云分类精度。但是,该方法存在着两个缺点:①训练样本过于庞大,训练时间长。若训练区域有上百万个点云,直接输入模型则会给计算机带来巨大的损耗;②模型鲁棒性较差。由于是直接对原始点云进行训练,易使模型出现过拟合情况。FPS-KNN方法相比较固定点方法,模型点云分类性能稍差;FPS-KNN方法比固定点方法在训练样本制作上有一定程度的精简,可以较好地保留训练集数据特征,且训练出的模型鲁棒性较强,但样本还是有一定程度的数据冗余并无法实现对输入场景数据的完全覆盖。分块后采样方法是3种方法中模型训练速度最快、鲁棒性最强的方法,该方法可以使用较少的点云进行训练从而实现较好的分类精度,但是分块方法不可避免地破坏地物几何结构信息,导致分类精度较低。
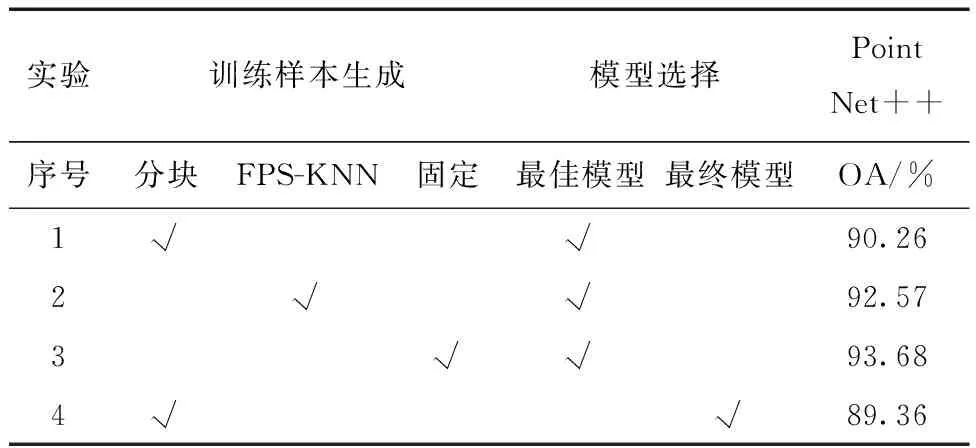
表4 模型采用不同训练样本生成、模型选择的分类精度(综合精度(OA)%)
深度学习模型训练是一个优化的过程,每一次训练都是尝试向最优解前进的过程。迭代次数作为一个超参数,由于数据、模型、优化器和损失函数等因素的不同,无法提前确定最优迭代次数,最后一次训练出的模型不一定是获得点云分类最佳性能。通过表4可以看出,使用最终模型策略的点云分类精度为89.36%,相比较最佳模型策略的点云分类精度低了0.90%。由此可见,最佳模型策略比最终模型策略训练出的模型性能更好。主要是因为最佳模型策略在每一次迭代后,利用验证集评估当前模型分类性能,尽可能模拟出模型在测试集上的分类效果,取分类精度最高的模型作为最终模型。因此,这种方法比最终模型策略要更加先进。
2.4 测试方法的对比试验
为了验证测试方法对点云分类结果的影响,本节在进行数据增强的情况下训练模型,对PointNet++模型分别采用非投票以及投票的测试方法进行点云分类,其他学习策略统一采用分块后采样样本生成方法、交叉熵损失以及最佳模型选择。
数据增强抖动和旋转点云无法给模型带来积极的效果,但是为了验证投票测试对于点云分类模型影响的普遍性,仍然将带有抖动和旋转方法的投票测试加入了实验。从表5可以看出,模型投票测试较非投票测试得出的点云分类精度高出约0.12%至0.23%。但是这种投票测试并无法提高模型本身分类性能,仅仅是在测试数据上进行对模型更加有利的处理,使点云分类精度有所提高。
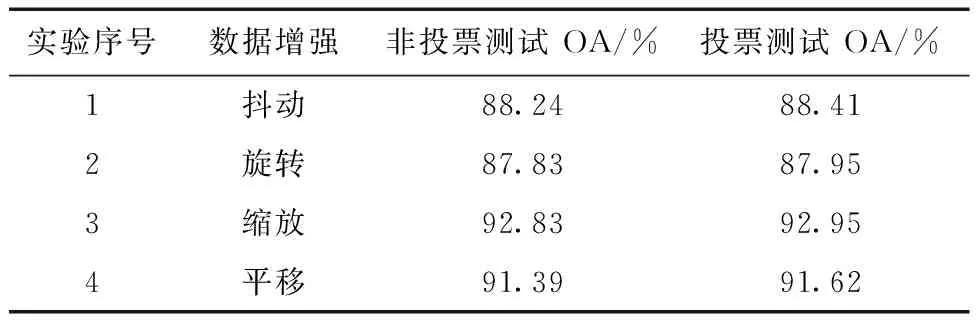
表5 非投票测试与投票测试精度对比
2.5 学习策略的组合对比实验
通过2.1~2.4实验分析可以看出:数据增强策略中随机平移与随机缩放、标签平滑损失、固定点样本生成策略以及最佳模型是基于PointNet++深度学习模型多光谱LiDAR点云分类的最优学习策略。为了进一步验证其组合学习策略的通用性以及优越性,在模型PointNet++基础上,本研究又选择3个经典深度学习模型,即PointNet、DGCNN和RSCNN,对所构建的学习策略进行测试与验证。这4个基本模型加入学习策略构建的新模型分别称为PointNet-LS、PointNet++-LS、DGCNN-LS和RSCNN-LS模型。为了对比,将无数据增强策略、交叉熵损失、分块后采样输入和最佳模型选择这一套学习策略组合应用在PointNet、PointNet++、DGCNN和RSCNN上,称为基准模型。为了更清楚分析这4种模型的分类结果,除综合精度(OA)外,另外添加均交并比(mIoU)、综合评价指标F1-score以及Kappa系数进行定量分析。其中mIoU代表标签的真实值和预测值两个集合的交集和并集之比,F1-score代表所有类别精确率和召回率的调和平均数,Kappa代表分类与完全随机的分类产生错误减少的比例。
从表6可以看出:所构建的学习策略5个内容,即固定点样本生成、随机缩放、随机平移、标签平滑损失函数、最佳模型,没有相互冲突,共同作用于PointNet、PointNet++、DGCNN和RSCNN模型中,综合精度分别提高了6.18%、4.42%、5.31%和5.12%;均交并比分别提高了18.16%、17.45%、19.67%和12.29%;F1指标分别提高了20.14%、13.67%、16.66%和12.25%;Kappa值分别提高了0.137 3、0.115 0、0.130 3和0.130 8。这一套学习策略组合可以适用于大多数深度学习模型并有效地提高深度学习模型在完成机载多光谱LiDAR数据点云分类任务的性能。
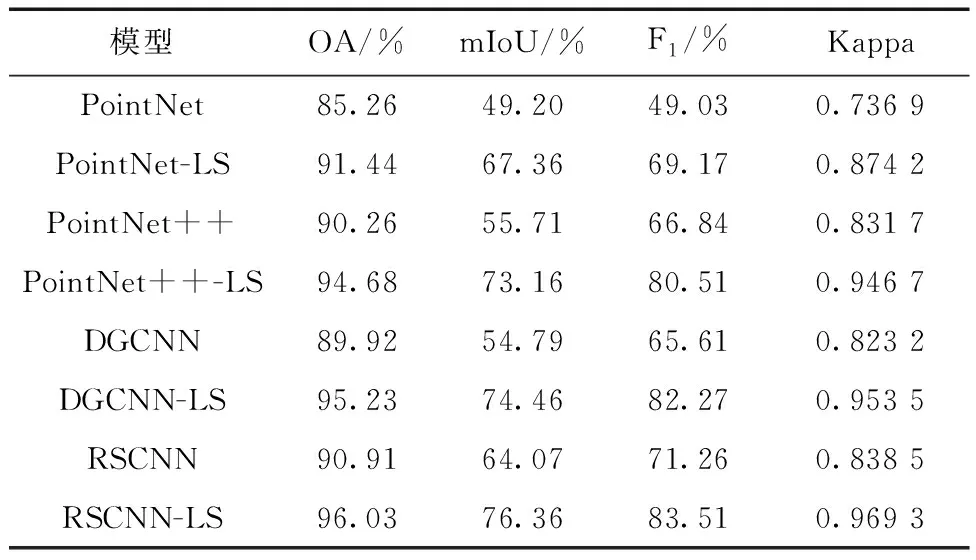
表6 采用改进学习策略的模型与基准模型点云分类精度(综合精度(OA)%)
3 结 论
本文以加拿大Optech公司的Titan 机载多光谱LiDAR点云数据为例,研究深度学习模型中学习策略对于点云分类精度的影响程度。研究结果表明:
1)学习策略对于模型本身性能的影响较大,在网络模型设计时,独立于网络模型之外的学习策略应该得到重视;
2)训练样本生成在点云分类性能表现上最好;数据增强策略中随机平移与缩放可提高模型分类性能;标签平滑损失比交叉熵损失表现的更好;最佳模型是更好的模型选择策略;投票测试可以得出更高的精度,但是不能提高模型本身的性能;
3)固定点方式的训练样本生成、随机平移与缩放、标签平滑损失、最佳模型选择以及投票测试这一套学习策略组合课通用于绝大部分深度学习模型,并且可以有效地提高网络模型的点云分类精度。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年11期)2018-08-04
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
数理化解题研究(2017年4期)2017-05-04
测绘科学与工程(2016年5期)2016-04-17
江西理工大学学报(2015年3期)2015-12-22
电子设计工程(2015年3期)2015-02-27
湖北科技学院学报(2014年6期)2014-07-12
