
基于迁移学习和集成神经网络的皮革缺陷检测
2023-11-17 05:17侯灿阳朱北辰
东华大学学报(自然科学版) 2023年5期
侯灿阳,朱北辰,吴 清
(华东理工大学 机械与动力工程学院, 上海 201424)
皮革的缺陷检测直接影响产品的质量,为满足日益增长的客户需求,确保皮革的生产质量的重要性日益凸显。皮革的种类繁多,缺陷的大小和外观更是呈现出各种变化,这给目标检测任务带来了许多困难。目标检测算法的发展大致分为2个阶段,即传统的目标检测方法和基于深度学习的目标检测方法。第一阶段的研究主要集中在2000年前后,其间提出的方法大多基于滑动窗口和传统的特征工程,代表性成果有AdaBoost检测器[1]、Viola-Jones检测器[2]、HOG+SVM检测器[3]、DPM检测器[4]。这些检测器在过去常被用于行人检测,并取得了不错的效果,因此具有一定的参考价值。
随着深度学习方法的不断发展与完善,国内外运用深度学习的方法进行缺陷检测的研究[5-7]也有所增加。由于缺乏皮革缺陷方面的数据库,这方面的应用一直受到限制。Liong等[8]基于Mask R-CNN的方法,通过机械臂控制高清摄像头实现自动化缺陷检测。该方法通过修改RPN(Region Proposal Network)的锚框尺寸使得网络更适合检测皮革的微小缺陷。然而该方法只针对孔洞这种单一缺陷,应用范围受到较大的限制。邓杰航等[9]在ResNet50的基础上进行参数优化。残差结构能够很好地克服梯度消失和梯度爆炸的问题,使得更深的神经网络成为可能。然而该方法的检测准确率最终只达到92.34%,对于工业生产该精度仍需提高。丁彩红等[10]提出以CNN为主、显著性特征为辅的组合检测方法。图像先经过卷积神经网络预测,再通过显著性特征进行验证,以此提高线状缺陷的预测准确率。然而他们的方法最终只达到3.4 s/帧的预测速率,相比传统算法虽然有显著提高,但仍难以满足工业需求。Nguyen等[11]研究指出,YOLO系列算法具有不亚于RetinaNet和Faster-RCNN的预测精度,且预测速度显著高于这两种方法,在速度和精度方面表现更加均衡。YOLOv5作为目前YOLO系列算法的前沿成果,可以较好地代表基于深度学习的目标检测算法。
本研究基于YOLOv5算法提出一种新的皮革缺陷检测方法,并与传统目标检测算法和其他深度学习算法进行比较。为提高算法的检测效果,在预训练后尝试不同的微调方案,对比不同微调方案对检测精度的影响。在测试阶段采用集成学习和测试时增强的方法,分别检验了集成学习和测试时增强的效果并尝试将两种方法结合使用,最终获得了检测性能优越的模型。该模型可以满足工业生产过程中的精度要求,同时检测速度显著高于传统方法。
1 检测方法介绍
1.1 传统目标检测算法:HOG+SVM
Dollar等[12]研究发现,在假阳率相等的条件下,HOG+SVM检测器和DPM检测器的漏检率相比Viola-Jones检测器有显著降低。因此本研究尝试使用HOG+SVM的方法进行皮革缺陷检测,以检验传统目标检测方法对皮革缺陷的检测效果。首先采用HOG算法提取特征,然后将HOG算法提取出的梯度方向分布特征用于支持向量机的训练,最后将训练出的模型用于皮革缺陷检测。检测过程中,通过缩放滑窗实现对多尺度特征的识别。值得一提的是,HOG算法将整张图片均分为若干个大小相同的单元格,一定数量的单元格又组成一个区块,HOG算法通过计算每个单元格内的梯度方向分布,并在区块内进行归一化来减小光照变化等外界因素对检测效果的影响。
1.2 YOLOv5
与传统的two-stage算法不同,YOLO算法无需生成候选区,而是将输入图像均分为若干个网格,每个网格中包含一定数量的边界框(bounding box, bbox)。通过对每个bbox进行检测,得到每个种类的置信度(Confidence)和bbox的位置、尺寸,从而实现单步检测,加快预测速度。
Confidence=Pr(Classi|Object)×Pr(Object)×IOU
(1)
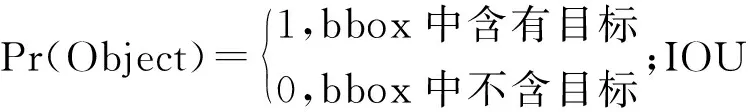
YOLOv5系列提供4种网络模型(YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x),这4种网络模型的架构基本相同,区别在于模型深度及卷积核的个数。
YOLOv5的基本网络结构如图1所示。在骨干网络中,由空间金字塔池化结构[13]改进而来的SPPF(spatial pyramid pooling fast)结构将输入的特征图分成4个部分,其中3个部分经过5×5的卷积核进行池化,最后将所有特征图进行拼接,从而融合不同尺度特征图的信息。两种Bottleneck模型分别被用于骨干网络和颈部网络,区别主要在于残差结构的使用。骨干网络中的BottleNeckCSP模块借鉴于CSP网络[14],主要由BottleNeck模块组成,在特征提取中发挥关键作用。如图1所示,骨干网络中的Bottleneck模块是一种残差网络结构,输入特征图尺寸等于输出特征图尺寸,这种结构使得网络深度得以增加,从而在保持网络轻量化的前提下提取更多特征。此外,BottleNeck在卷积层间穿插使用批归一化方法,以此加快网络训练速度[15]。
为实现特征融合,YOLOv5在颈部网络中借鉴了特征金字塔网络(feature pyramid network,FPN)[16]和路径聚合网络(path aggregation network,PAN)[17],并且把PAN结构中的捷径操作修改为连接操作。FPN和PAN结构形成互补,融合浅层特征图和深层特征图的信息,从而提升多尺度特征检测的性能。
1.3 迁移学习和微调
迁移学习的基本思想是将在源域中学到的知识经过微调后用于目标域。唐李文等[18]和Christopher等[19]利用迁移学习的方法缩短了训练时间,同时提高了模型的预测精度。COCO(common objects in context)数据集[20]具有丰富的特征,因此常常作为迁移学习中的源域。Hou等[21]将COCO数据集的预训练神经网络用于人-物交互检测的训练过程中,有效提高了模型的检测精度。鉴于皮革缺陷数据有限,本研究提出一种基于迁移学习的方法,并将COCO数据集的预训练神经网络用于目标域训练。
将特定层的梯度设置为0从而冻结特定层的参数,并微调其他层参数的方法被广泛应用于迁移学习。通过微调可将从源域中学习到的知识转化为适用于目标域的知识。赵章焰等[22]关于起重机类型识别的研究表明,微调可以对模型的性能产生显著的影响。为了获得更好的模型性能,分别采用top-k和标准微调(standard fine-tuning)[23]策略对YOLOv5m的预训练模型进行微调试验。在top-k策略中,预训练模型的前k层参数被冻结,其他参数得到微调;而在标准微调策略中,则对所有层的所有参数都进行微调。
1.4 集成学习
为进一步提高预测性能,本研究还采用了集成学习的方法。集成学习的基本思想是通过合成多个基学习器[24]来产生最终的预测结果。龚安等[25]利用集成学习的方法将ImageNet上预训练的多个神经网络模型结合,在皮肤镜图像分类领域获得较好的分类效果。本研究将经过预训练和微调后的3种模型框架(YOLOv5s、YOLOv5m、YOLOv5l)作为基学习器,最后通过非极大值抑制(non-max suppression,NMS)的方法将各基学习器的预测结果进行合并从而得到最终的检测结果。非极大值抑制的方法通过抛弃置信度较低、交并比较高的bbox来消除多余的bbox。
1.5 测试时增强
受数据扩增方法的启发,测试时增强(test-time augmentation, TTA)通过在预测时对原始图像进行裁剪、旋转、缩放等若干种变换,再将这些图像分别进行预测后得到的结果进行合并,从而得到最后的预测结果。Wang等[26]提出一种描述测试时增强的理论公式,并通过试验证明TTA有助于消除过度自信的错误预测。Moshkov等[27]运用镜像和旋转两种变化评估了TTA方法在荧光显微镜数据集和组织病理学图像数据集上的表现。其试验结果表明,TTA方法在大多数情况下能够提高分割精度,特别是在训练样本较少的时候。因此,TTA对于皮革缺陷检测任务具有一定的参考价值。本研究采用水平镜像和尺寸缩放对测试集进行TTA处理。扩增后的图像经YOLO网络预测后恢复到原本的尺寸并将预测结果融合,最后通过NMS剔除多余bbox,产生最终结果。
1.6 数据集处理与划分
考虑到样本数量较少,划分后的数据集可能难以代表全体样本,易产生过拟合的问题,本研究采用K折交叉验证的方法对数据集进行划分。在K折交叉验证中,数据集被划分为K个大小相等的部分。随后执行K次训练和测试,在每次迭代中部分数据集用于测试,其他K-1部分数据被用于训练。最终,对K次预测的结果取平均作为最终的预测结果。交叉验证的方法能够很好地评估检测器的泛化能力。在本研究中,数据集被等量划分为5份(K=5),以实现交叉验证。图2为数据集的划分方法。此外,为提高预测性能,本研究通过平移、旋转、灰度变换等55种方式对训练集进行数据扩增,最终将训练集扩充至2 970张图片。图3展示了本研究提出的改进方法。
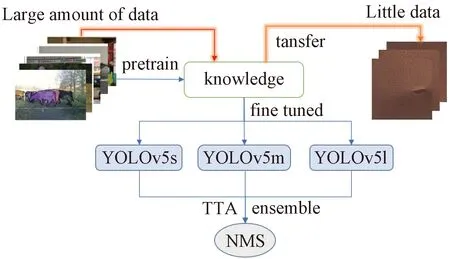
图3 改进方法Fig.3 Improved method
2 试验结果与分析
2.1 试验条件
软件配置为Win10操作系统。显卡驱动为NVIDIA Tesla P100-PCIE(16281 MIB);深度学习框架采用PyTorch-1.7.1;使用Labelimg作为标注工具。
2.2 数据集
2.2.1 皮革缺陷数据集
皮革缺陷数据集[28]包括89张含有缺陷的皮革图像以及600张不含缺陷的皮革图像,图像大小均为1 024×1 024。数据集中包含5种主要缺陷,分别是划痕、孔洞、色杂、胶黏和褶皱。89张包含缺陷的图片按6∶2∶2的比例划分到训练集、验证集和测试集中,然后对训练集的图片进行数据扩增。此外,训练集中加入了一些不含缺陷的皮革图像,作为背景图片以提高训练表现,降低假阳率。图4为这个数据集中具有代表性的几张图片。

图4 皮革缺陷数据集中的部分图片Fig.4 Some pictures in leather defect dataset
2.2.2 COCO数据集
COCO数据集[20]是由Microsoft提供的一个大规模对象检测、分割数据集。该数据集包含80种不同的物体,由32.8万张图片组成。
2.3 评估指标
准确率(precision,P)、召回率(recall,R)、全类平均精度(mean average precision,mAP)、F1值等指标常常用于评估目标检测算法的性能。考虑到实际生产要求,采用P、R、mAP50作为评估标准。
(2)
式中:TP为被准确预测为含有相应缺陷的样本数,FP则为被错误预测为含有相应缺陷的样本数。
(3)
式中:FN为被错误预测为不含相应缺陷的样本数。
(4)
式中:P(R)为R的函数。几何意义为当NMS阈值为50%时,P(R)曲线下覆盖的面积。
2.4 试验结果
2.4.1 HOG+SVM的检测效果
部分准确检测结果如图5所示,可见传统的方法有时也能精确地定位缺陷。但在大多数情况下传统方法的表现并不好。如图6所示,传统方法在检测出缺陷的同时,常常也将没有缺陷的部位标记为缺陷。然而尝试通过提高分类器的阈值来降低假阳率时,又常常出现漏检的问题(见图7)。此外,由于HOG特征提取算法在预处理时对图像进行了灰度化处理,导致检测器对于杂色缺陷的分辨能力较差(见图8)。除了上述问题,传统的HOG+SVM方法对大尺度缺陷的检测效果同样较差。例如,有时边界框没有包含整个缺陷,有时边界框又比实际缺陷大得多(见图9)。HOG算法提取的是检测区域内梯度的方向分布特征,这类特征主要反映目标边缘的取向信息。由于行人在图片中往往是以直立的形式出现,在竖直方向上具有较为独特的边缘特征,因此这类传统的目标检测算法多用于行人检测任务。然而皮革缺陷不同于行人,多数皮革缺陷的边缘没有明显的取向规律,并且皮革缺陷的形式复杂多变,因此将传统的目标检测算法运用于皮革缺陷检测时难以取得良好的效果,最终检测精度和召回率均不足50%。此外,传统方法的检测速率仅为27.5 s/帧,无法满足实际生产要求。

图5 精确的预测结果示例Fig.5 Samples of correct detection results

图6 假阳问题示例Fig.6 Samples of false positive detection

图7 漏检问题示例Fig.7 Samples of false negative detection
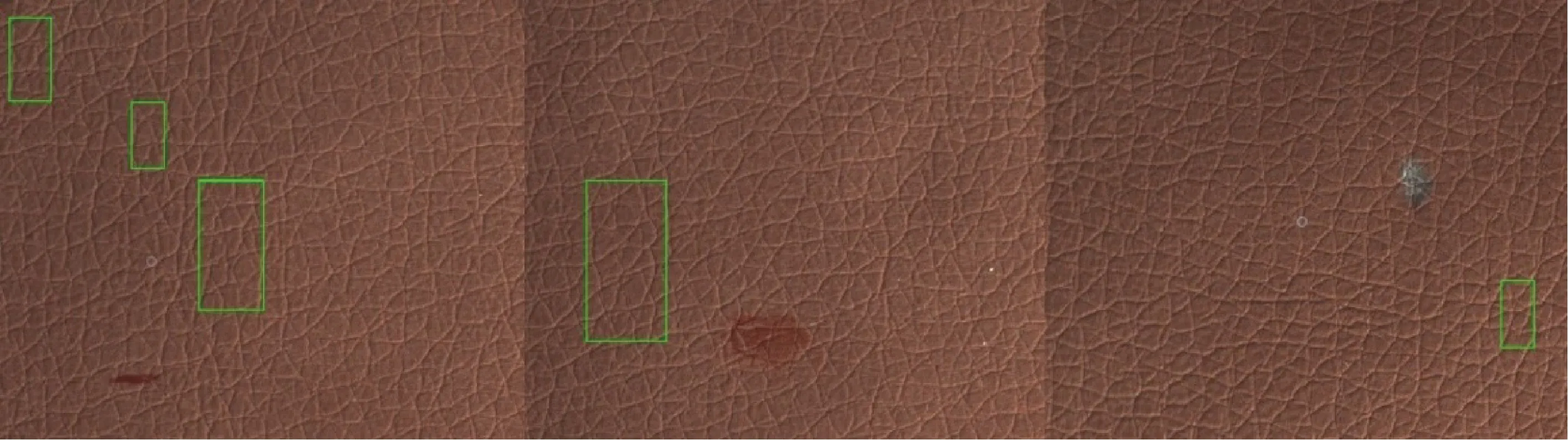
图8 部分色杂缺陷检测结果Fig.8 Some detection results of color defect

图9 部分褶皱缺陷检测结果Fig.9 Some detection results of wrinkle defect
2.4.2 迁移学习+微调
以YOLOv5m为试验模型,以不进行迁移学习得到的检测结果(scratch-m)为对照,采用top-2、top-4和标准微调策略分别进行微调,观察不同微调策略的效果,试验结果如表1所示。由表1可看出,标准微调和top-4策略都可以提高模型的预测能力,而top-2策略的表现较差。top-4策略可得到较高的精度,但召回率和mAP50均不如标准微调的测试结果。由此可见,重复利用从其他领域学习到的低层特征未必能够提高模型性能。基于此试验结果,将在接下来的集成学习中采用标准微调的方法对所有基学习器进行微调。
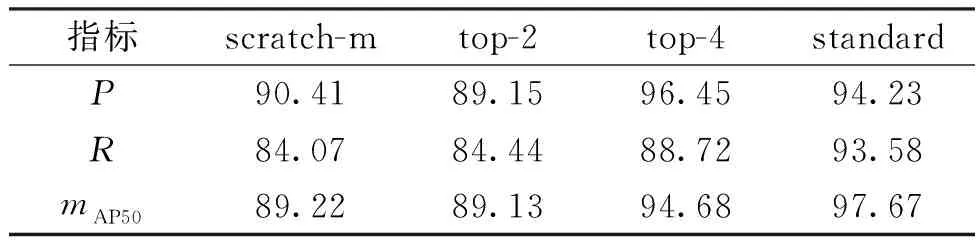
表1 不同微调策略对比
2.4.3 集成学习
将3种经过迁移学习、微调后的基学习器进行组合,测试各种组合的预测性能,结果见表2(表中,s、m、l分别表示YOLOv5s、YOLOv5m、YOLOv5l,下同)。试验中,以不进行集成学习的YOLOv5l模型为对照组(scratch-l),来验证其他集成方法的效果。从表2可以看出,不同的集成学习方案总体上都能提高模型性能,其中YOLOv5s+YOLOv5m+YOLOv5l集成模型在所有选定的性能指标上都显著优于对照组。但考虑到部分方案的推理时间过长,且YOLOv5s+YOLOv5l集成模型以及YOLOv5s+YOLOv5m集成模型在各方面表现更加均衡,最终选择YOLOv5s+YOLOv5l模型作为集成学习方案。
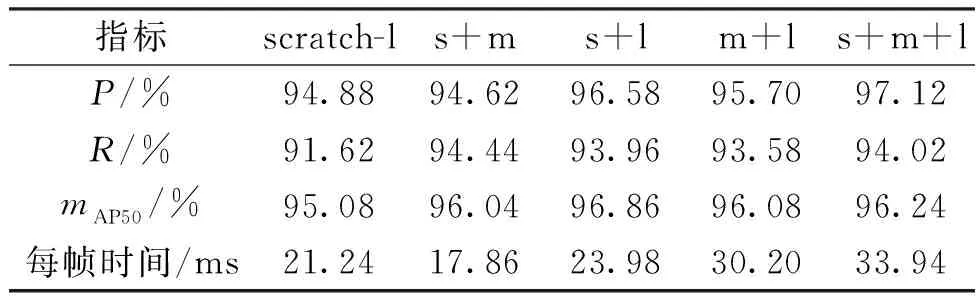
表2 不同集成学习策略效果比较Table 2 Comparison of different ensemble method
2.4.4 测试时增强
对比YOLOv5的3种模型架构(YOLOv5s、YOLOv5m、YOLOv5l)在使用测试时增强前后的表现,试验结果如表3所示。由表3可知,在大多数情况下,运用TTA的方法能够提高精度、召回率和mAP50等性能指标,尤其是mAP50。
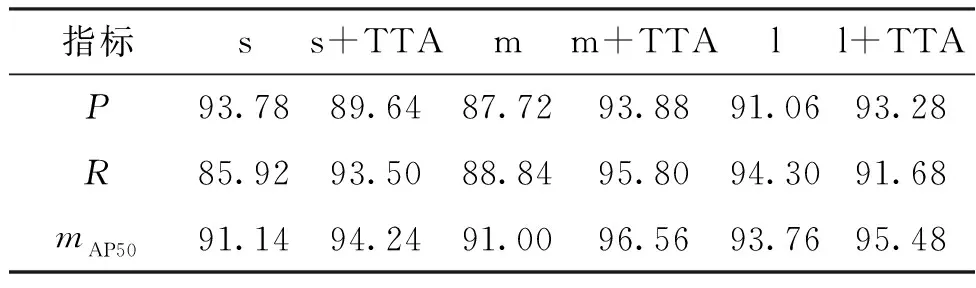
表3 测试时增强前后性能比较Table 3 Performance comparison before and after TTA %
2.4.5 集成学习与测试时增强并用
检验测试时增强和集成学习并用的效果,并结合所有试验结果选出综合性能最优的模型。试验结果如表4所示。结合表2~4可知,虽然单独采用TTA策略和单独采用集成学习策略时模型的性能都有所改善,但将两者结合使用时却无法产生更好的结果。在Moshkov等[27]的研究中也出现了部分样本的预测精度在采用TTA方法后有所下降的现象。这表明测试时增强可能将一些正确的预测变为错误的结果。此外,TTA的方法显著降低了预测速度,因此并不适用于工业应用。结合上述所有试验结果,选择预训练和标准微调后的YOLOv5s+YOLOv5l集成模型作为最优模型。
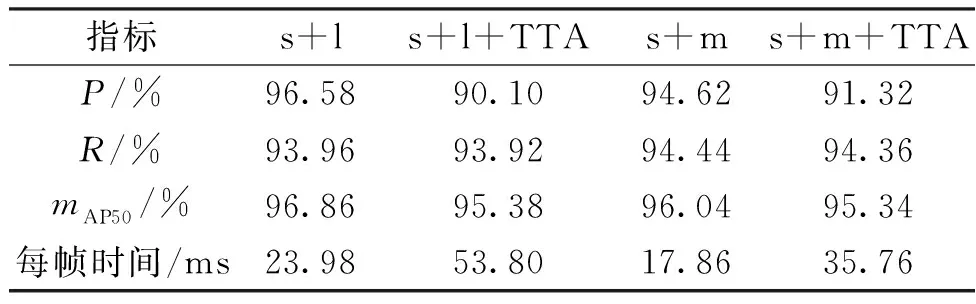
表4 TTA+集成学习效果Table 4 Effectiveness of TTA+ensemble
2.4.6 检测效果
图10展示了本文方法(最优模型)对部分缺陷试样的检测效果。表5为本文方法与其他深度学习算法的性能比较。由表5可知,本文算法在精度、召回率和平均精度方面相比RetinaNet和YOLOv5l均有显著提高,检测速度则是略低于YOLOv5l。此外,相比RetinaNet,本文方法能将每帧预测时间缩短约14 ms。
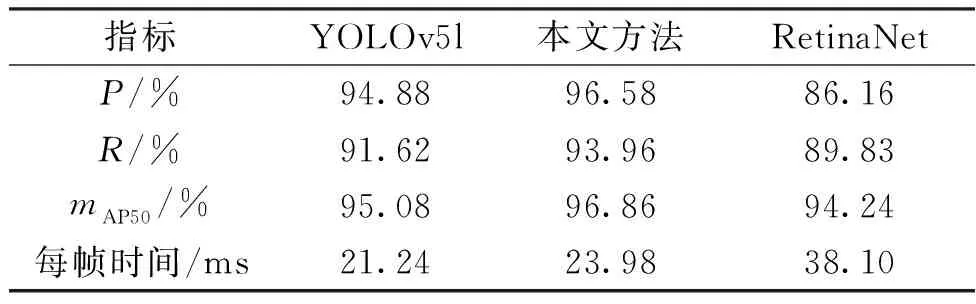
表5 本文方法与其他深度学习算法比较Table 5 Comparison with other deep learning algorithms
3 结 论
针对传统皮革缺陷检测方法检测速度低、小样本下泛化能力差的缺点,基于YOLOv5算法提出了一种结合迁移学习和集成学习的皮革缺陷检测方法。试验结果表明:基于深度学习的目标检测算法相比传统方法在检测精度和速度方面均具有显著优势。迁移学习、集成学习、测试时增强对于模型的预测表现均有显著提升作用。标准微调相比其他微调策略能够达到更优越的性能,YOLOv5s+YOLOv5l的集成策略能够在速度和精度间取得较为均衡的表现。由于集成学习与测试时增强的组合并不能提升模型预测精度,并且测试时增强的引入增加了预测时间,因此抛弃了测试时增强的方法。本研究提出的方法不仅能达到96.58%的检测精度,而且在预测速度上优于传统算法,每帧预测时间低至24 ms,可满足工业生产的要求。由于所采用的皮革数据集并不能很好地涵盖实际中可能出现的各种缺陷,因此进一步获取大量、具有多样性的样本是推广应用的重点。
猜你喜欢
小资CHIC!ELEGANCE(2021年32期)2021-09-18
电子制作(2018年11期)2018-08-04
电线电缆(2018年2期)2018-05-19
家庭影院技术(2017年10期)2017-11-23
小学阅读指南·低年级版(2017年5期)2017-05-18
测绘科学与工程(2016年5期)2016-04-17
Coco薇(2015年12期)2015-12-10
电子设计工程(2015年3期)2015-02-27
教育科学论坛(2014年8期)2014-03-01
河南科技(2014年14期)2014-02-27
