
利用随机森林算法预测束鹿凹陷束21 井区馆陶组储层砂地比
2023-12-14 14:43付君豪陈再贺李云峰胡慧婷
大庆石油地质与开发 2023年6期
付君豪 陈再贺 付 宪 李云峰 胡慧婷
(1. 长江大学资源与环境学院,湖北 武汉 430100;2. 中国石油华北油田分公司第五采油厂,河北 辛集 052360;3. 东北石油大学地球科学学院,黑龙江 大庆 163318)
0 引 言
砂地比是表征储层特征的重要参数之一,被广泛应用于地质研究的多个领域。作为碎屑岩沉积响应的特征值,砂地比可用于开展沉积物源分析及沉积相刻画[1-5]、分析地层沉积旋回及划分地层[6]、开展裂缝发育程度预测[7]等工作。同时,砂地比是评价碎屑岩储层输导油气能力的重要指标[8-12],被广泛应用于油藏类型判断及有利区带预测等工作中。
砂地比资料可以通过录井数据和测井岩性解释数据获得,但这种方法只能提供井点处的砂地比信息,应用受限,在无井区则需借助地震资料开展预测。地震属性是根据一些数学算法提取地震数据中的特征信息,利用其与砂地比等储层参数建立关联而开展储层参数的三维空间估算[13-15]。单一地震属性除了受岩性影响外,还会受到孔隙结构、孔隙中流体性质以及随机噪声等多种因素干扰,预测结果存在多解性。
因此,越来越多的学者尝试应用人工智能算法,综合多种地震属性建立地震属性与储层参数之间的非线性关系[16-22]。随机森林算法在生物信息、文本分类、遥感地理学等领域均取得了良好的效果[23-30],并由M.J.Cracknell 等[31-32]首次引入到地球物理领域,应用于航空数据确定岩性分布关系。同时,其在利用地球物理数据开展岩性识别等方面也有初步尝试[33-35],对于岩性判别这种离散型数据识别效果好于支持向量机和神经网络。
本文以井筒岩性信息为标签数据,以单砂体和地震分辨率为约束的细分法来解决样本量不足的问题。采用随机森林算法进行直接预测砂地比,获得了比线性回归方法有较大提升的结果。
1 区域地质特征
束21 井区位于束鹿凹陷北端,紧邻陡坡带,含有丰富的油气资源(图1(a))。受地层超覆的影响,束21 井区仅发育馆陶组和东营组,其中馆陶组是主要的油气储层。
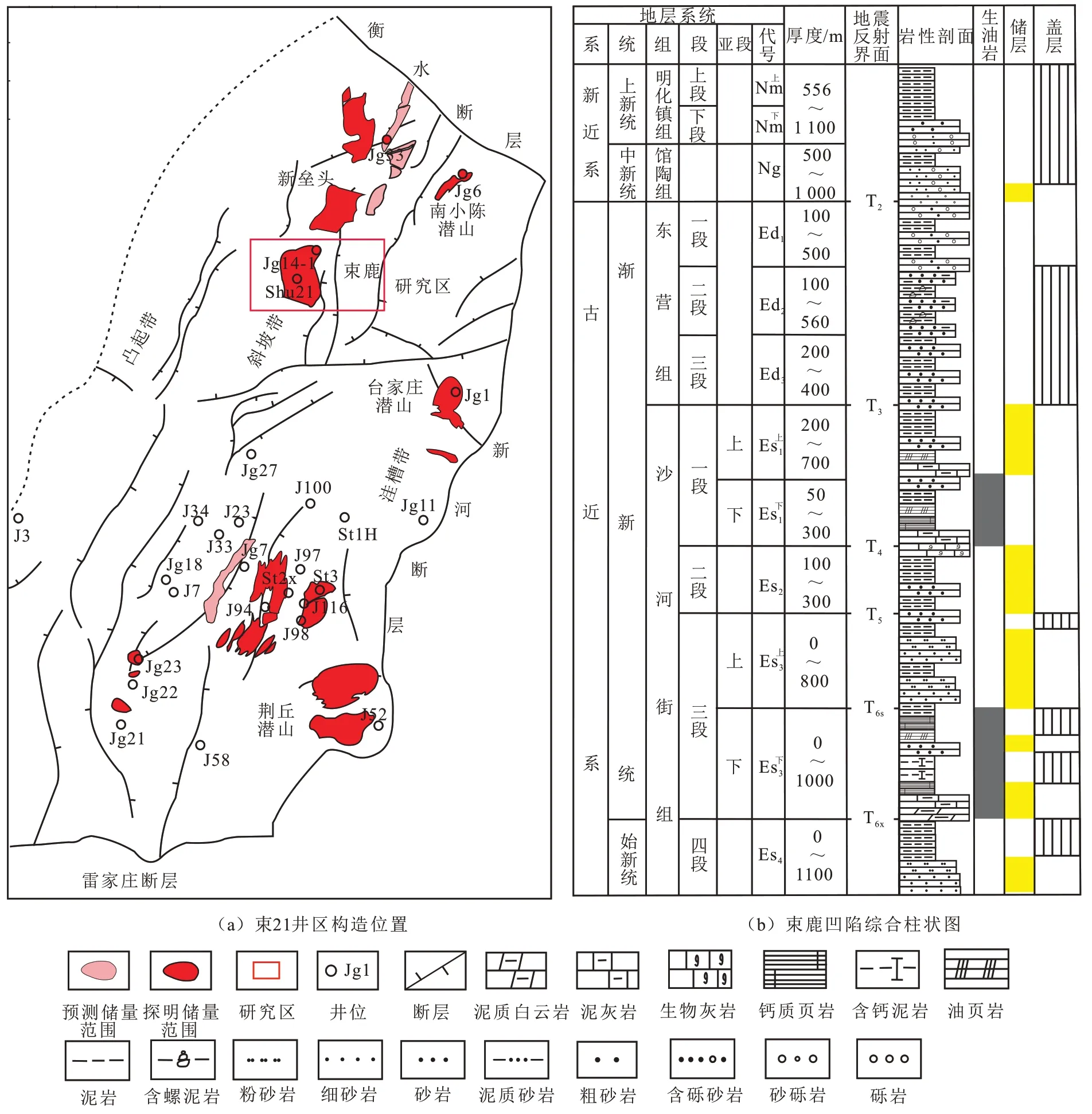
图1 束21井区构造位置及地层综合柱状图Fig. 1 Structural location and comprehensive stratigraphic column of Shu21 well block
束鹿凹陷的主要成藏期为馆陶组末期和明化镇组中期至现在,根据砂体输导连通概率的研究,砂地比是束21 井区馆陶组油层成藏评价的关键参数,束21 井区砂地比的大小直接影响着油气的运移和成藏,对束21 井区砂地比的准确评价,有助于预测该区域油气资源的分布和成藏规律研究。
束21 井区馆陶组发育辫状河沉积体系,砂体分布较广,自上而下划分为NgⅠ、NgⅡ和NgⅢ,与下伏古近系呈不整合接触(图1(b))。NgⅠ主要发育辫状河道及泛滥平原沉积微相,单砂体厚度为1~20 m,平均为4 m,砂地比为0.3~0.8;NgⅡ主要发育心滩及泛滥平原沉积微相,砂体厚度变化较大,测井曲线呈齿化箱形,单砂体厚度为0.5~38.0 m,平均为8 m,砂地比为0.4~0.7;NgⅢ主要发育心滩沉积微相,地层较薄,单砂体厚度不大但砂地比高,测井曲线呈齿化箱形,单砂体厚度为0.1~17.0 m,平均为5 m,砂地比为0.5~1.0。
束21 井区西北部井网较密,东南部井网稀疏,为了获得全区砂地比展布,需引入地震资料开展预测。地震资料纵向分辨能力为,根据研究区目的层频谱分析可知,地震资料的主频约为20 Hz,根据地层速度1 200 m/s 估算地震资料纵向分辨能力为15 m 左右。
2 预测样本数据的建立
2.1 数据提取
储层岩性等数据可以从井筒的录井、测井、取心等资料获取,也可以通过地震数据提取相关属性来表征。由于井筒数据和地震数据的采集方式不同,需要在井震层位标定的基础上进行样本提取,以确保井震信息的一致性。束21 井区的岩性资料相对较为充分,通过直接利用岩性进行统计计算可以得到各层砂地比。然而,由于井位数量有限,若只提取井点处NgⅠ、NgⅡ和NgⅢ层位的砂地比,数量会受到限制,不利于随机森林模型的训练。
根据前人研究成果,振幅类地震属性、复地震道类和频率类属性均有利于表征储层的岩性变化。由于研究区位于束鹿凹陷西斜坡超覆边界处,因此采用平行于顶面的方式进行地震属性提取。同时,提取范围与井筒计算的砂地比范围保持一致,构建了一套井震统一的标签数据,以地震属性作为输入,井筒砂地比统计值作为输出,用于模型训练。
束21 井区馆陶组目的层单砂体平均厚度在8 m左右,地震资料分辨率在15 m 左右,因此分别以8和15 m 为间隔开展地层细分。通过提取细分层砂地比,对训练数据进行有效扩充。
2.2 数据预处理
受地震数据本身存在的噪声和人为层位解释误差的影响,提取的地震属性无法避免存在一定“野值”和“毛刺”。
首先需对提取的地震属性开展平滑滤波处理;其次,不同地震属性反映的地球物理意义不同,计算公式也不同,导致地震属性之间量纲不统一,个别地震属性数量级差异较大,因此还需对地震属性开展标准化或归一化等处理,进而避免因数据量级差异而导致的贡献率差异。
地震属性数据平滑滤波,通常采用3 点或者5点平滑因子滤波,在特殊情况下,如对某些小面元采集的地震数据进行提取属性时,也可以用7 点或9 点平滑因子滤波,但此时容易掩盖掉某些细微异常。
因此要根据具体的情况来确定所采用的平滑因子滤波的方式[17],其表达式为
式中:y(k) ——滤波后第k个目标样点值;y(i)——滤波后第i个样点值;n——选定的滤波间隔数;M——数据文件的总样点数。
数据预处理流程包括有数据异常值剔除,地震属性值正态标准化处理公式为
式中:y——标准化后数据;x——待正太标准化的数据;μ——原始样本数据的均值;σ——原始样本数据的标准差。
2.3 数据优选
束21 井区馆陶组砂泥互层发育,砂体发育不均,横向变化大,振幅类属性有利于直观展示此类储层发育特征。同时复地震道类、频率类属性也有利于开展储层砂体预测。
因此本文提取目的层间储层类相关属性30 余种,实现储层相关属性第1 步优选;第2 步优选与目标层砂地比相关性高且自相关性小的属性。皮尔逊相关系数能较准确地测量线性关系能力[18],它是一种衡量特征之间线性相关性的指标,可以反映出特征之间的强度和方向。
在地震属性优选中,通过计算不同属性之间的皮尔逊相关系数,可评估它们之间的相关性,并选择最具代表性的特征,从而减少特征数量,便于提高模型效率和准确性。
皮尔逊线性相关系数计算公式为
式中:rx,y——2 个变量x、y之间的线性相关系数;m——样本容量个数;xi——表示第1 个变量中第i条数据的值;yi——表示第2 个变量中第i条数据的值;——xi的平均值;——yi的平均值。
由计算结果可知各地震属性与砂地比之间的相关性。结合数据分布和地质情况,优选与砂地比相关性大于0.3 的地震属性进行建模运算,包括反射强度斜率(相关系数0.355 4)、平均瞬时相位(相关系数0.345 1)、瞬时斜率频率(相关系数0.313 9)和绝对振幅和体(相关系数0.312 1)。
3 利用随机森林方法预测砂地比
结合砂地比预测所需输入数据,随机森林预测流程如图2 所示。随机森林是基于决策树分类模型的一种集成学习方法[19-20],将有限的决策树分类模型进行组合,以投票的方式将分类器的预测结果进行最终分类,从而解决单棵决策树对数据分布特征表征不准确、判别准确率不高、过拟合风险等问题,并广泛应用于智能训练的各个领域[21-23]。

图2 利用随机森林法预测砂地比流程示意Fig. 2 Schematic prediction workflow of sandstone thickness ratio by random forest method
4 结果分析
在建立模型并对样本数据进行预测的时候,通常会根据模型的误差指标来评价模型预测得好坏。本文中主要采取了3 个误差指标来进行评价:均方误差(RMSE)、均方根误差(RRMSE)、平均绝对误差(RMAE)。
4.1 样本数据误差
根据单砂体厚度和地震资料分辨能力,选择8 m 细分层和15 m 细分层2 种间隔开展数据统计,并由此得到2 种样本数据。为验证这2 种样本数据,哪个更优,本次研究采用随机森林算法进行试算。由图3 可以看出随机森林模型的3 个误差指标,均是15 m 细分层的样本数据训练的模型预测效果最好。

图3 8、15 m细分层情况下随机森林预测误差Fig. 3 Random forest prediction error for 8 and 15 m subdivided layers
在细分地层过程中,由于以8 m 间隔细分的层位厚度比以15 m 间隔细分的层位厚度小,因此8 m细分的层位可能会导致该层全是砂岩或泥岩。这将导致所统计出来的砂地比值中有很多0 和1,而这些值属于模型中的异常值,会影响模型的精确度。
因此,建议采用15 m 间隔细分的层位厚度进行细分地层的操作。
4.2 预测模型对比
针对此次束鹿凹陷束21 井区的砂地比的预测,本文主要采用了3 种模型来分析哪一种达到的效果更佳。这3 种模型分别是基于人工智能的神经网络模型、随机森林模型,线性回归模型。
神经网络模型具有非线性映射能力和柔性网络结构,但对于样本数据类型有一定要求;随机森林模型运行速度快、兼容性强,具有随机性;线性回归模型建模速度快,但对异常值敏感,可能影响结果的准确性。随机森林模型在束21 井区的样本训练数据下,其均方误差指标(RMSE)、均方根误差指标(RRMSE)、平均绝对误差指标(RMAE)都明显优于神经网络模型以及线性回归模型(图4)。
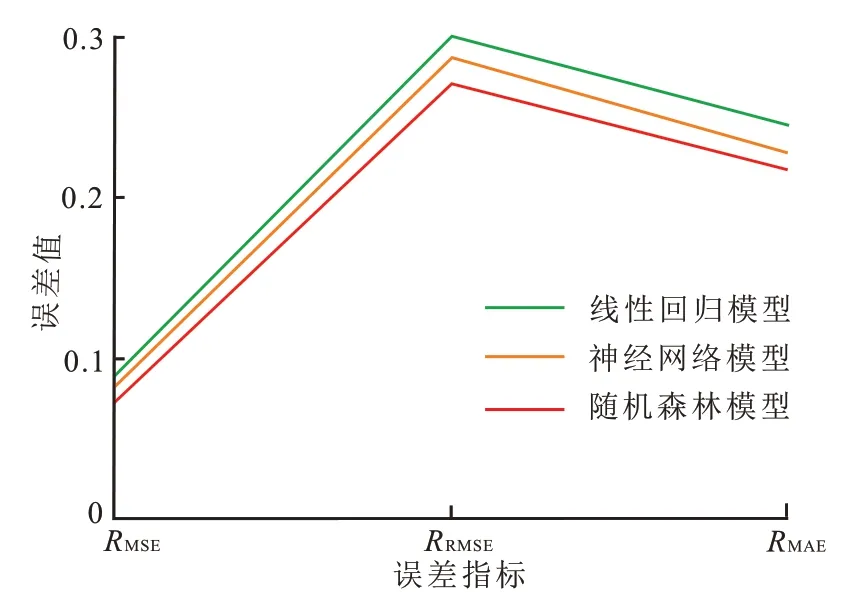
图4 15 m细分层数据的不同模型预测误差Fig. 4 Prediction error of different models for 15 m subdivided layers data
异常数据对于机器学习模型的训练和预测结果具有重要的影响。异常数据可能由于数据采集误差、录入错误、不完整数据或真实存在的极端值等原因产生。
传统的线性回归和神经网络等模型可能会因为异常数据导致过拟合或欠拟合现象,从而影响模型性能。相比之下,随机森林模型具有较好的鲁棒性和泛化性能,在处理异常数据时具有较高的适应性和兼容性。随机森林模型基于决策树算法构建,在每个节点上进行随机特征选择和随机样本抽样,从而减少了异常数据对模型的影响。随机森林模型还可以通过集成多个决策树来进行预测,从而提高模型的准确性和鲁棒性。因此,当数据集中存在异常数据时,可以考虑使用随机森林模型进行建模,以获得更好的性能和准确性。
4.3 预测结果
以束21 井区内井点属性及所对应的砂地比为样本数据集,以15 m 间隔为基础进行层位细分,NgⅠ细分为3层,NgⅡ细分为8层,NgⅢ细分为2层,共使用43口井,后验井5口,311个样本来进行建模训练,随机森林算法预测砂地比的平面分布。
图5 显示了细分层的平均符合率和NgⅠ—NgⅢ小层的平均符合率。其中NgⅠ砂地比预测符合率可达85%,NgⅡ符合率可达81%,NgⅢ符合率可达75%。从图6 中可以看出高砂地比区整体呈现出近南北向展布,与实际地质情况较为符合,说明随机森林算法在砂地比预测过程中,模型的学习能力较强,预测结果较好。
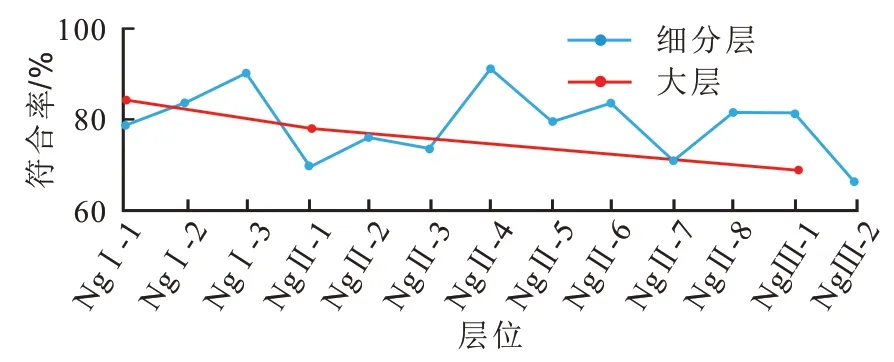
图5 不同小层砂地比预测结果符合率Fig. 5 Coincidence rate of prediction results of different sublayers sandstone-strata thickness ratio

图6 NgⅢ砂地比预测平面Fig. 6 Sandstone-strata thickness ratio prediction plane of NgⅢ
5 应用效果
由上述分析可知,应用15 m 细分层开展样本统计,采用9 个分类器的随机森林模型开展预测,砂地比预测效果最优。
据此,以多点地质统计学为手段,以单井解剖为条件数据,以现今束鹿凹陷束21 井区辫状河沉积体系为概率模型,结合断裂特征已有研究认识,利用地质软件平台建立非均质复合输导格架模型。并基于侵入逾渗理论的三维油气运移数值模拟,耦合分析非均质输导体系中运移动力和阻力,定量模拟了束21 井区关键成藏期油气运移路径,并且以含油气饱和度的形式显示(图7)。

图7 束21井区馆陶组油气运聚过程模拟结果(自东向西视角)Fig. 7 Simulation results of hydrocarbon migration and accumulation process of Guantao Formation in Shu21 well block (from east to west perspective)
根据束21 井区油气运移路径模拟图,在油气运移路径上部署新钻井4 口,较原有井产量提升约10%。
6 结 论
(1)随机森林方法和神经网络法均优于单一属性法,砂地比预测精度更高。受钻井数量及地层厚度统计间隔影响,样本数量少且分布不规则,针对这种数据特点,随机森林法适用性相对于神经网络而言更强。
(2)砂地比预测样本数据可以通过细分层统计得以有效扩充,应用与地震资料分辨率相当的厚度间隔统计砂地比值相对于应用单砂体厚度为间隔统计砂地比值开展预测,其预测精度更高。若开展提高地震资料分辨能力等预处理方法,则需重新分析地震资料分辨极限,并用此极限值为厚度间隔开展砂地比统计,可进一步提高预测精度。
猜你喜欢
——北美又一种非常规储层类型
石油与天然气地质(2021年5期)2021-10-29
化工管理(2021年7期)2021-05-13
华人时刊(2020年23期)2020-04-13
西南石油大学学报(自然科学版)(2018年5期)2018-11-06
录井工程(2017年3期)2018-01-22
石油地球物理勘探(2017年2期)2017-11-23
专用汽车(2016年9期)2016-03-01
专用汽车(2015年2期)2015-03-01
河南科技(2015年3期)2015-02-27
石油化工应用(2014年8期)2014-03-11
