
基于城市热点大数据的连锁便利店选址模型研究
2023-12-15 05:59聂佳文张莹翁克瑞缪乐王竞勇
中国市场 2023年35期
关键词:覆盖
聂佳文 张莹 翁克瑞 缪乐 王竞勇
摘 要:人口分布信息是城市规划、商业布局的基础条件,然而,相比人口调查的成本高、周期长、流动性大等缺点,城市热点大数据具有数据实时、低成本、可视化效果强等优点。文章研究城市热点大数据的连锁便利店选址问题:已知便利店覆盖半径和便利店建設数量,如何以最优选址覆盖最大数量的城市热力值,以实现最大化覆盖城市活跃人口,考虑了连锁便利店之间的间隔约束等条件。文章提出了基于热力指数的覆盖选址模型,开发了禁忌搜索算法求解模型,为解决连锁便利店选址问题提供了有力支持。
关键词:便利店选址;覆盖;禁忌搜索;城市热力指数
中图分类号:F713文献标识码:A文章编号:1005-6432(2023)35-0115-04
DOI:10.13939/j.cnki.zgsc.2023.35.115
1 引言
便利店(convenience stores)区别于一般的零售店,是一种满足顾客应急性、便利性需求的零售业态,通常位于居民住宅区、学校以及客流量大的繁华区,以即时消费、小容量、应急性为主,80%的顾客是目的性购买[1]。
便利店通常以连锁的模式经营,高密度的特性能够更好地提升品牌知名度,是连锁便利店的重要竞争力。品牌扩张的首要环节是选址决策,而便利店的经营成败与选址密切相关,选址质量直接决定了未来便利店的客流量、销售额和生存能力。因此,如何在候选店中选择最优位置使得连锁店覆盖的目标群体最大成了重要问题。
一般而言,连锁便利店的目标群体包括活跃的固定群体和流动群体。固定群体是指在连锁店附近生活或工作的活跃目标群体,流动群体是非附近居民路过时的流动人口。以百度热力指数为代表的城市热点大数据,通过收集用户访问百度产品的位置信息,统计不同区域内的人口活跃数量,可以同时反映固定群体和流动群体中潜在顾客的数量。
精确的人口信息是便利店设施选址决策的重要依据,然而对具体小区或商圈的人口数据收集是一项较难统计的工作。传统针对城市热点区域的分析多以问卷调查、实地调研或是直接采用政府收集数据等方式进行,成本高、周期长,且由于流动性会与真实数据有一定偏差。
一些研究提出过很多更有效率的方式去获取数据,但很少有学者尝试将城市热点数据与选址决策联系起来。李依璘等(2022)在2022年研究了新零售背景下基于GIS的连锁企业商圈分析与门店选址的应用前景[2]。苏洋(2021)在2021年提出了使用百度地图API替代实地调研获取人口统计数据的方法,节约了大量实地调研的时间[3]。李翔等(2021)使用八爪鱼采集器爬取了高德地图兴趣点(POI)数据,并利用Arc GIS、SPSS及空间句法对影响24小时便利店选址六大构面量化分析数据[4]。原榕等(2021)结合POI数据和2020年南京市统计年鉴数据,对比研究南京市罗森、便利蜂和京东三种品牌便利店的空间分布特征及其影响机制[5]。
上述研究对零售选址问题都提出了可行的解决方法,但未考虑到城市热点数据在零售选址问题中的巨大应用。于是,文章将基于GIS技术获取城市热点大数据,采用百度慧眼2023年3月武汉市常住人口网格数据来衡量固定群体数量。将百度慧眼识别的常住人口的热力值表示为各经纬坐标的热力值,连锁店的覆盖热力值即为覆盖范围内各经纬坐标的热力值之和。通过GIS分析城市热点数据,可以更好地为商业中心的选址、旅游景点的开发等提供科学依据,旨在构建一个基于城市热点数据的连锁便利店选址问题模型,并尝试利用禁忌搜索算法求解模型。
文章主要贡献如下:一是构建了基于城市热力指数的连锁便利店选址问题模型,用于替代实地调研以获取相关人口需求数据信息,给出了应用示范;二是大型城市的热力指数网络数量大,通常有5万个网络节点以上,于是开发了禁忌搜索算法求解模型,计算实验验证了很好的求解效果。
文章第二部分针对LMOCCS构建一个整数规划模型,第三部分设计关于LMOCCS的禁忌搜索算法,第四部分结合城市热点数据测试禁忌算法的求解效率和效果。
2 模型
令N={1,2,…,n}表示n个热力值坐标点,对i∈N,(dix,diy,hi)分别表示节点i的经度、纬度及热点值。M={1,2,…,m}表示m个候选点。对j∈M,Cj表示该位置选址的覆盖半径。定义(djx,djy)表示候选点的纬度、经度坐标,G表示连锁店的最小间隔距离,S0表示已建候选连锁店集合。
在以上定义下:定义零一系数aij表示候选点j能否覆盖目标点i。即:
aij=1 若 (dix-djx)2+(diy-djy)2≤Cj0 若 (dix-djx)2+(diy-djy)2>Cj
定义零一系数lkj表示候选点j与k是否在规定的最小距离范围之外。即:
lkj=1 若 dkx-djx2+dky-djy2≥G0 若 dkx-djx2+dky-djy2<G
定义以下决策变量:零一决策变量Zi表示目标点i是否被覆盖;零一决策变量Xj表示候选点j是否被选为连锁店。建立了整数规划模型如下:
max ∑i∑jhiXjZi(1)
s.t.
∑jaijXj≥Zi i (2)
∑jXj=p i (3)
Xk+Xj≤lkj+1 k,j(4)
Xj=1 j∈S0(5)
Xj=0,1;Zi=0,1(6)
模型中,目標函数(1)可表示为使得被覆盖热点值最大化。约束(2)表示若目标点i被覆盖,则至少有一个能够覆盖i的候选点被选为连锁店。约束式 (3)表示在N中建立p个便利店(包括已建便利店)。约束式 (4)表示任意两个便利店的距离大于规定距离。两个候选点距离小于G时,lkj=0,Xk与Xj最多只有一个为1。约束式(5)定义已建连锁店。
3 禁忌搜索算法
禁忌搜索算法(tabu search algorithm)是一种用于求解组合优化问题的启发式算法。该算法模拟盲人寻路时避免最近已走过的路,通过引入“禁忌表”来避免搜索过程中陷入局部最优解,并且可以在解空间内进行较大范围的搜索,具有较好的全局搜索能力。
3.1 算法要素
3.1.1 初始解
初始解由贪婪算法给出。即从问题的初始状态开始,设定每一次选址都要覆盖最多的群体(城市热点数据最多),每次选择局部最优的策略,直到达到预先固定的连锁便利店数量结束。考虑到其局限性,笔者后续将结合禁忌搜索算法的局部寻优性,尝试将贪婪算法和禁忌搜索算法结合起来对该问题进行求解。
3.1.2 邻域结构
由单点替换产生。N为所有上万个点的集合,另外T0为贪婪算法求解得到的初始解的选址点集,记录当前最优解Tbest=T0,N-T0为未选点集,则让T0与N-T0每次交换一个点生成新的集合Ts,S={1,2,…,p(n-p)},N(Ts)即为邻域。例如,定义节点数N=5和候选点个数p=3的连锁便利店选址问题,令初始解集为(1,2,3),则可求得其邻域由以下解组成:(1,2,4)、(1,2,5)、(1,3,4)、(1,3,5)、(2,3,4)、(2,3,5)。笔者可以计算,其邻域中有p(N-p)个解集。
3.1.3 禁忌对象
在每次迭代中,都会选择在邻域中产生最佳解决方案的移动,即使这会导致更差的解决方案。禁忌搜索算法每次都会在邻域中选择覆盖热点值最多的对象移动,依次迭代,这就有可能会出现循环或者陷入局部最优。为了不出现上述问题,引入禁忌对象,从而避免迂回搜索而多搜索一些解空间中的其他地方。
3.1.4 禁忌长度
即在不考虑特赦准则的情况下,对禁忌对象的最大选取次数的限制。当禁忌对象被选取的次数达到禁忌长度时,它将不再允许被选取,直到禁忌长度为0时才能解除禁忌,重新允许被选取。禁忌长度的选择需要考虑问题的规模和复杂程度。
3.1.5 特赦规则
笔者将其定义为迄今为止出现的最好解。特赦规则是用于解除对某些禁忌解的禁忌限制,允许它可以被重新选取作为当前解的候选解。
3.1.6 迭代步数
由于贪婪算法求解的初始解具有较好的结果,因此禁忌搜索算法无须迭代过多步就能得到全局最优解,经过多次试验,笔者将其定为50。它表示算法已经进行了多少次迭代操作。在禁忌搜索算法中,每一次迭代都包括了一次邻域的生成、邻域搜索以及检查邻域中最好值等操作。
3.2 算法流程
设定N为网络中所有n个节点的集合,T为被选中的点集,N(T)={T1,T2,…,Tp(n-p)}为与之相对应的邻域,则目标函数值Z(T)=∑i∑jhijmin(1,∑k∈T∑m∈Takmij)为所选点集T所对应的覆盖流量。并定义Vi与Wi分别为从T中换出和从N-T中换进的点。令tabu_tag(i)为节点i所处的禁忌步数。算法流程如下。
第一,由贪婪算法生成满足间隔约束的初始解T;令迭代步数t=0,令禁忌表为空;即对所有的点i∈N,令tabu_tag(i)=0;确定当前最优解,令T0=T。
第二,生成邻域N(T),并计算邻域中所包含的解集的对应覆盖流量Z(Ti),i=1,2,…,p(n-p)。
第三,检查邻域中最大的目标函数值Z(Tl)。如果tabu_tag(Wl)=0或者Z(Tl)>Z(To),则T=Tl,否则,N(T)=N(T)-Tl,重复步骤(3)。检查T是否满足连锁店间隔约束,若满足,让Vl加入禁忌表,禁忌步数tabu_tag(Vl)根据问题规模而定,进入步骤 (4)。若不满足,N(T)=N(T)-Tl,重复步骤(3)。
第四,令t=t+1,如果Z(T)>Z(T0),则令T0=T (更新当前最优解)。
第五,如果t<100,则更新禁忌状态,即对所有tabu_tag(i)>0的点令tabu_tag(i)=tabu_tag(i)-1,返回步骤(2);否则结束,最终解为T0。
4 计算实验与应用实例
4.1 数据来源与预处理
百度慧眼通过整合百度地图位置服务中的去隐私化人口位置信息(6个月),以及用户标注、土地使用属性等数据,提取人口活动的位置属性、时间分布等特征。基于人工智能技术(GBDT、XGBoost)挖掘得到精度高、覆盖广的人口热力数据。该平台可为用户提供人口、出行、客群、交通等多维度城市数据分析及多样式可视化大数据展示服务,其终端覆盖处于行业领先地位,北斗高精定位日调用量超5000亿次,拥有覆盖全球的2亿POI数据,可以帮助用户提升数据分析效率及决策科学性。因便利店的可替代性强,当消费者距便利店越远、会花费更多的出行成本时,其前往该便利店的可能性便会降低。因而文章设定单一便利店的覆盖半径为500m。
主要数据来源于通过百度慧眼识别的人口热力数据,文章以武汉为例,市内的点状人口热力数据,每个点上的属性信息代表以该点为几何中心的150m×150m的方形格网为单元的每个单元内的人口活跃数据信息。数据获取时间为2023年3月,共获取五万余点经纬度坐标以及人口热力数值。
4.2 计算实验
为测试计算效果,笔者首先在LINGO商业软件平台上计算小规模实验(随机选取一小块10~20个节点的区域,选址3~5个连锁便利店),与禁忌搜索算法比较求解得到的目标值,计算发现算法在15次实验中全部得到最优解。
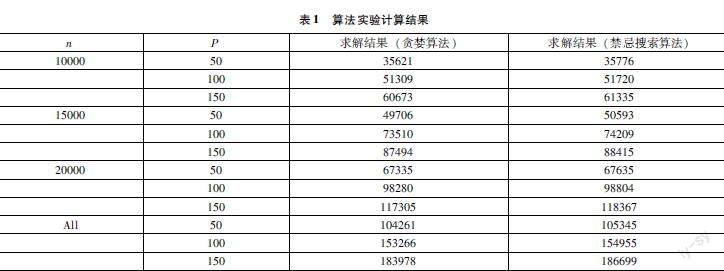
在较大规模的便利店选址问题中,随机选取一大版区域中的10000、15000、20000个节点,选址50~150个连锁便利店,将文章的算法计算结果与经典的贪婪算法计算结果进行对比,如表1所示,实验结果证明禁忌搜索算法的求解质量得到了明显的改进。
4.3 应用实例
传统的零售选址选择方法包括经验法、问卷调查等。随着科技的进步,现代的零售选址方法,如数据分析、地理信息系统(GIS)和人工智能等先进技术都被用于零售选址,以便确定最佳选址。文章基于GIS技术获取城市热点大数据,采用百度慧眼2023年3月武汉市常住人口网格数据衡量固定群体数量。
经笔者分析得出,将百度慧眼识别的常住人口的热力值表示为各经纬坐标的热力值,以提取人口活动的位置属性、时间分布等特征,收集了连锁店的覆盖热力值即为覆盖范围内各经纬坐标的热力值之和。实验结果证明,参考该工具展开禁忌搜索算法,在求解质量上得到了明显的改进,能够更好地理解人类活动的模式和趋势,这有助于各种应用,例如城市规划、公共安全和智能交通。
有研究指出,运用GIS的空间分析模块分析人口密度、交通状况、竞争对手和基础设施4个因素,研究新型超市的备选建设点选址方法[6]。
同时,也有学者分析了连锁便利店选址的影响因素,提出了双层模型研究竞争选址问题,开发了一种利用人口、商店选址特征、经济考虑、竞争等标准对商店位置进行战略排名的方法[7]。
此外,也有学者选择最佳的零售便利店位置,对其展开了系列研究[8]。然而需要注意的是,在既往研究中,不少学者仍然基于传统的人流量与调研群体推断目标需求,没有运用城市热点数据的便利性。
因此,文章将构建一个基于用城市热点数据的连锁便利店选址问题模型,并尝试利用禁忌搜索算法求解模型。最终,文章在基于百度慧眼对禁忌搜索算法进行改进后得出,禁忌搜索是一种启发式搜索算法,通过避免一些被认为是较差的搜索路径,可以更有效地从数据中提取有用的信息,为诸如调度问题、旅行商问题带来参考。将从百度慧眼网站中获取所有节点文件导入QGIS 3.30.3软件中,采用WGS84坐标系,绘出武汉市热力图。再将由禁忌搜索算法求得的结果录入QGIS软件中,可得到最终候选便利店地址。在热力图中,红色圆圈的中心为候选便利店,半径为覆盖范围(500米)。由于比例尺原因,候选便利店个数过多,在热力图中不好展示,因而这里以n=1000,p=5给出应用示例。
综上所述,通过GIS分析城市热点数据,可以更好地为商业中心的选址、旅游景点的开发等提供科学依据。
5 结论
随着大数据技术的不断发展,连锁便利店在选址决策中可以充分利用这些数据。文章旨在探讨如何建立基于城市热点大数据的连锁便利店选址模型,以帮助连锁便利店更准确地选择店址。文章探讨了连锁便利店选址优化问题,提出一种选址方法,该方法利用百度慧眼提供的API获取城市热力数据,构建连锁便利店选址模型,结合禁忌搜索算法寻求大型城市的便利店选址方案。本方法获取数据方便,可以节省大量实地调研时间,且求解效果良好。
在后续的研究中,文章希望可以针对连锁便利店选址模型展开进一步的优化,将更多的影响因素纳入模型中,如人口分布、交通状况、竞争对手位置等,并充分利用更高级的机器学习算法来训练模型,以提高预测的准确性和稳定性,让更多的学者可以基于城市热点大数据的连锁便利店选址模型来为连锁便利店的选址决策提供科学依据。
參考文献:
[1]于恬,胡启亮.连锁经营管理原理[M].北京:科学出版社,2008:1761-178.
[2]李依璘,李轻舟,王亚娟.新零售背景下基于GIS的连锁企业商圈分析与门店选址策略研究——以全家便利店为例[J].经济师,2022(9):33-34.
[3]苏洋.百度地图在新零售线下门店选址中的应用[J].电脑知识与技术,2021,17(1):250-252.
[4]李翔,余明.多元数据下24小时便利店选址研究——以北京市老城区为例[J].福建师范大学学报(自然科学版),2021,37(2):75-86.
[5]原榕,石飞.从地理中心到无界零售:新零售的布局选址及影响机制——以南京市三类便利店为例[J].城市问题,2021(8):72-82.
[6]汤云峰,张泽键,李荣森,等.新型零售网络中多业态组合选址问题[J].山东科学,2022,35(5):104-111.
[7]芮志彬.二线城市连锁便利店选址的影响因素[J].经营与管理,2018(6):52-53.
[8]ZHOU N.Research on urban spatial structure based on the dual constraints of geographic environment and POI big data[J].Journal of King Saud University-science, 2022, 34(3).
猜你喜欢
环球时报(2016-12-14)2016-12-14
科技传播(2016年13期)2016-08-04
