
基于改进SSD的鲁棒小目标检测算法
2023-12-21 06:14李学伟刘宏哲
东北师大学报(自然科学版) 2023年4期
秦 振,李学伟,刘宏哲
(1.北京联合大学北京市信息服务工程重点实验室,北京 100101;2.北京联合大学机器人学院,北京 100101)
0 引言
目标检测是计算机视觉领域中一项基础的任务,被广泛应用于车辆检测、行人检测、交通灯检测等系统中.随着深度学习技术的快速发展,基于传统手工特征的目标检测算法逐渐被淘汰,基于深度学习的方法由于能够同时处理特征提取和分类,以其优越的性能而被广泛使用.基于深度学习的目标检测方法可以分为一阶段和两阶段方法.以R-CNN系列[1-3]为代表的两阶段方法首先在图像上生成候选区域,然后对每一个候选区域依次进行分类与边界回归.而单阶段方法能够在单个步骤中完成目标的定位和分类,其检测精度有所损失,但运行速度快,满足自动驾驶系统等现实应用对目标检测算法的实时性要求[4].
YOLO[5]和SSD[6]是目前最流行的单阶段目标检测算法.YOLO将输入图像分成S×S个方格,物体中心点落在某个方格内,就由该方格负责预测物体.YOLOv2[7]从原始YOLO中删除了全连接层,并应用锚框来提升算法的检测精度.YOLO和YOLOv2对于小对象的检测效果不理想,为了解决这个问题,YOLOv3[8]采用多尺度特征图进行检测,提高算法对小目标的检测准确率.YOLOv4[9]并未进行理论创新,而是在原始YOLO的基础上采用优化策略来提升检测准确率.
SSD算法的速度与YOLO相当,它的检测精度与Faster R-CNN相当.SSD算法通过卷积神经网络提取多尺度特征,可以预测多尺度目标对象.基于SSD的各种研究的特征金字塔结构对多尺度对象的鲁棒性不强,为了提高SSD算法对多尺度对象的鲁棒性,对特征金字塔进行了重构.SD-SSD[10]通过分段反卷积重新设计了融合结构,丰富底层特征图语义信息,提高小目标检测精度.FD-SSD[11]采用空洞卷积获得特征的多尺度上下文信息,同时在通道方向上将深层特征与浅层特征进行连接,增强底层特征的语义信息来提高小目标的检测精度.文献[12]提出新的特征融合模块来丰富细节信息,同时引入注意力机制突出特征图中的关键信息.DF-SSD[13]使用DenseNet作为特征提取主干,同时引入了多尺度特征层的融合机制,将网络结构中的浅层视觉特征和深层语义特征有机地结合起来.最后,在目标预测之前建立一个残差块,以进一步提高模型性能.文献[14]采用基于可变形卷积的ResNet50作为特征提取网络,通过特征融合与引入注意力机制来提高检测性能.TTB-SSD[15]提出一种结合PANet多尺度特征融合网络和自上向下特征融合路径的改进算法,使得深层特征能够准确地对小目标进行定位,强化浅层特征对小目标检测的准确率.但在自动驾驶等现实应用场景中,受到雨雪、光照、遮挡等情况的影响,现有算法对小目标的检测精度明显降低,鲁棒性不强.
因此,本文提出一种基于改进SSD的鲁棒小目标检测算法.提出了一种新颖的特征金字塔结构,该结构通过连接SSD的相邻特征层来生成,有效地利用上下文信息提高小目标检测精度.设计了非局部特征增强模块,用于提取不同大小的非局部特征之间的关系,增强特征映射.在公开数据集PASCAL VOC和KITTI上的实验结果表明,本文方法提升了SSD算法的小目标检测准确率,且比现有方法具有更好的小目标检测性能.
1 改进SSD算法
通过融合SSD相邻的特征图,同时设计非局部特征增强模块,提高网络对小目标的鲁棒性,图1为基于改进SSD的整体模型图.
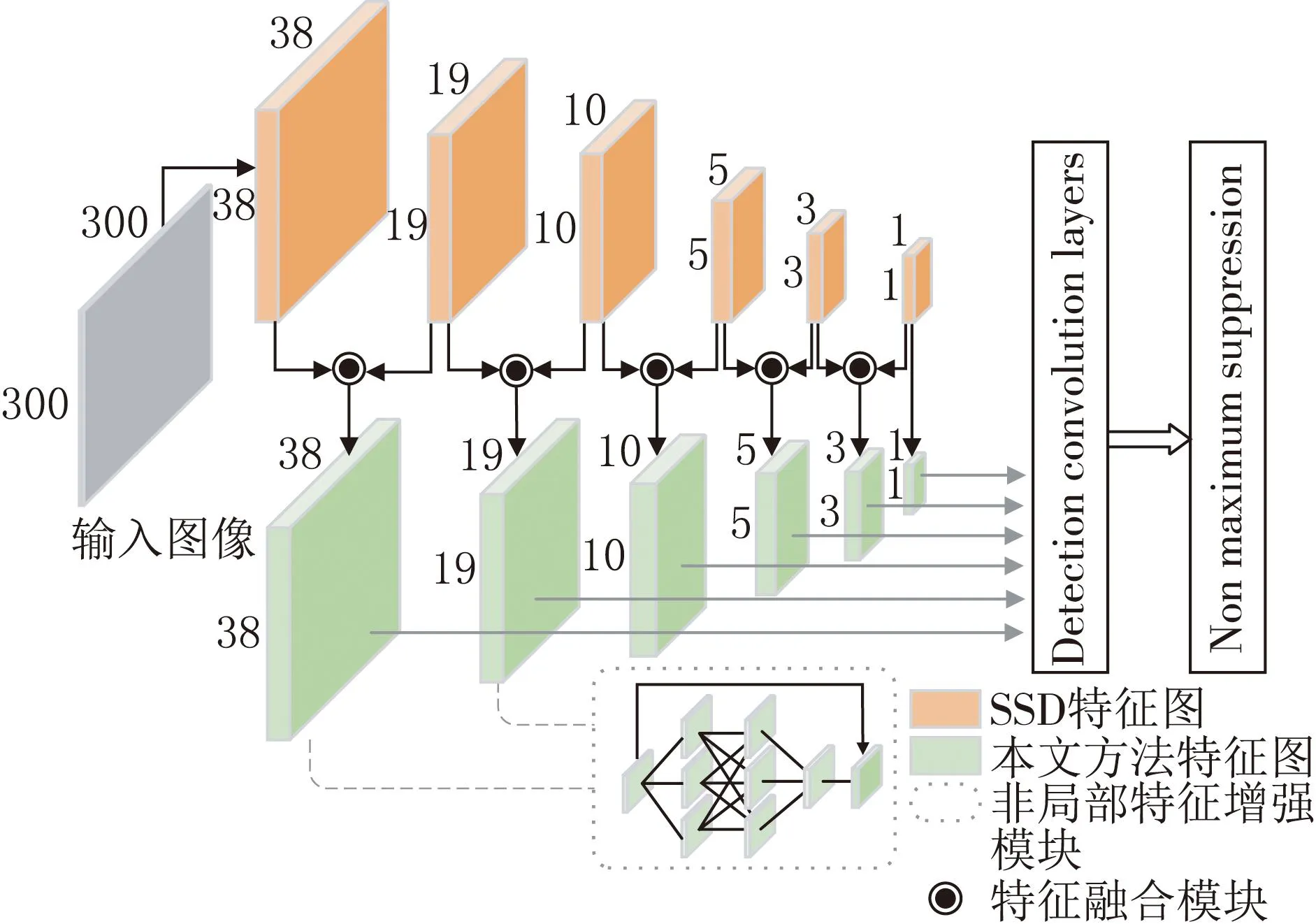
图1 改进SSD的整体结构
1.1 整体结构
本文方法的基本框架基于SSD算法,采用VGG16作为骨干网络进行特征提取,将VGG16中的全连接层FC6和FC7通过权重采样变成卷积层Conv6和Conv7.SSD中卷积层Conv4、Conv7、Conv8、Conv9、Conv10与Conv11生成不同分辨率的特征图,通过所提出的特征融合模块将这些特征进行融合.选择将相邻的特征图进行融合,对上下文具有鲁棒性,而不会丢失细节信息.表1为融合后特征层的详细信息.
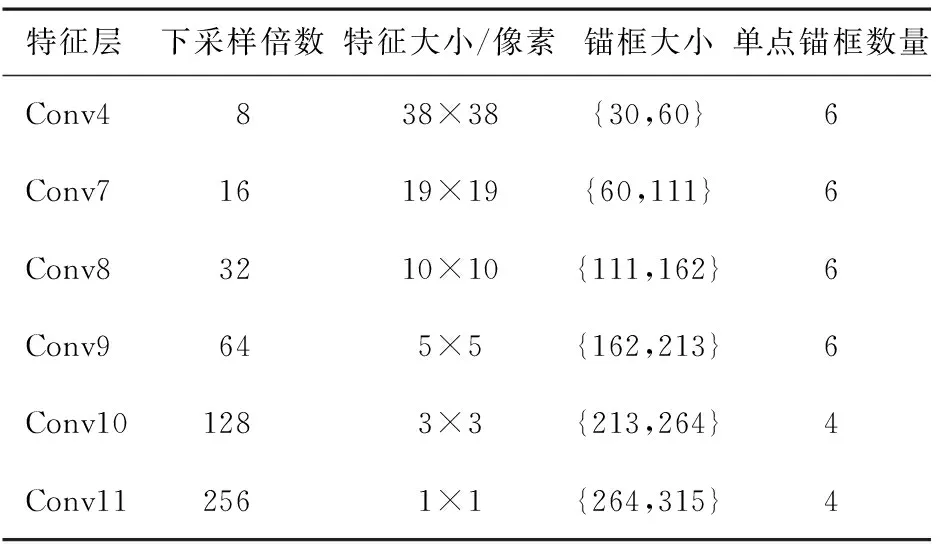
表1 融合特征的详细信息
从表1中可以看出,本文方法将原始SSD的Conv4层每个单元锚框的数量由4个增加到6个,允许更多的锚框作为小目标的输出,提高小目标的检测性能.同时这些特征图具有连续递减的空间分辨率和递增的感受野,更低层的特征层由于感受野较小,可以关联小尺度的锚框,用于检测小目标.因此,本文方法在最底层的两个特征层中应用提出的非局部特征增强模块,更专注于小目标检测.
本文方法的中间特征层Conv8和Conv9是由RFB生成的.如图2所示,RFB通过将给定的特征图分为3个具有不同感受野的特征图,并将它们再次合并,形成了与人类视觉相似的感受野模型,提高了特征图的辨识度和鲁棒性.而最顶层的特征图由于分辨率太低,无法应用特征增强模块,即Conv10和Conv11层的特征图并没有使用特征增强.

图2 RFB模块结构
本文方法共输出11 620锚框,比原始SSD的8 732个锚框多出2 888个.其中,Conv4和Conv7的两个特征图主要用于小目标检测,分别产生8 664和2 166个锚框.将不同特征图获得的锚框结合起来,经过非极大值抑制方法来抑制掉一部分重叠或者不正确的锚框,得到最终的检测结果.
1.2 特征融合模块
提出的特征融合模块通过一次反卷积、一次批归一化、一次ReLU和两次卷积运算设计了特征融合模块,如图3所示.该模块相较于其他融合方法结构简单,但能够将上下文信息传递到融合特征中.
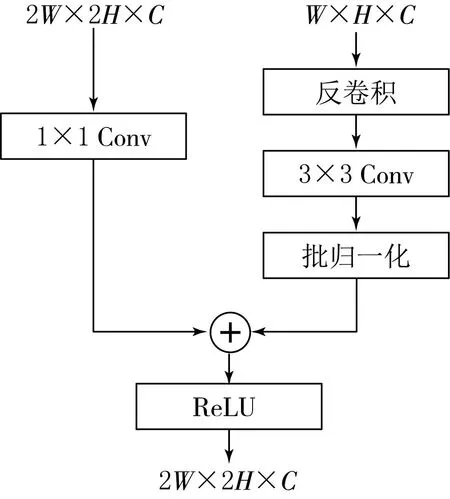
图3 特征融合模块
反卷积用于提升特征图的大小,使低分辨率特征图和高分辨率特征图的大小保持一致.每个卷积层都对输入特征图进行变换,使融合后的特征图既有上下文信息又有详细的融合特征信息.批归一化层是对特征进行归一化.在逐元素求和与ReLU操作之后,生成输出特征.
1.3 非局部特征增强模块
在融合后的Conv4和Conv7层的特征图中应用非局部特征增强,以提高对小目标的检测性能.NLNN提取通过1×1卷积从特征图分支生成新的特征图之间的非局部关系来增强特征,但NLNN只能计算相同尺寸的特征关系,不能推导出不同尺寸的特征之间的关系.RFB通过融合具有不同感受野的特征图来考虑不同大小的语义特征,但它只是一种局部方法.因此,本文提出的非局部特征增强模块使用了具有不同感受野的特征图的非局部关系,其结构如图4所示.
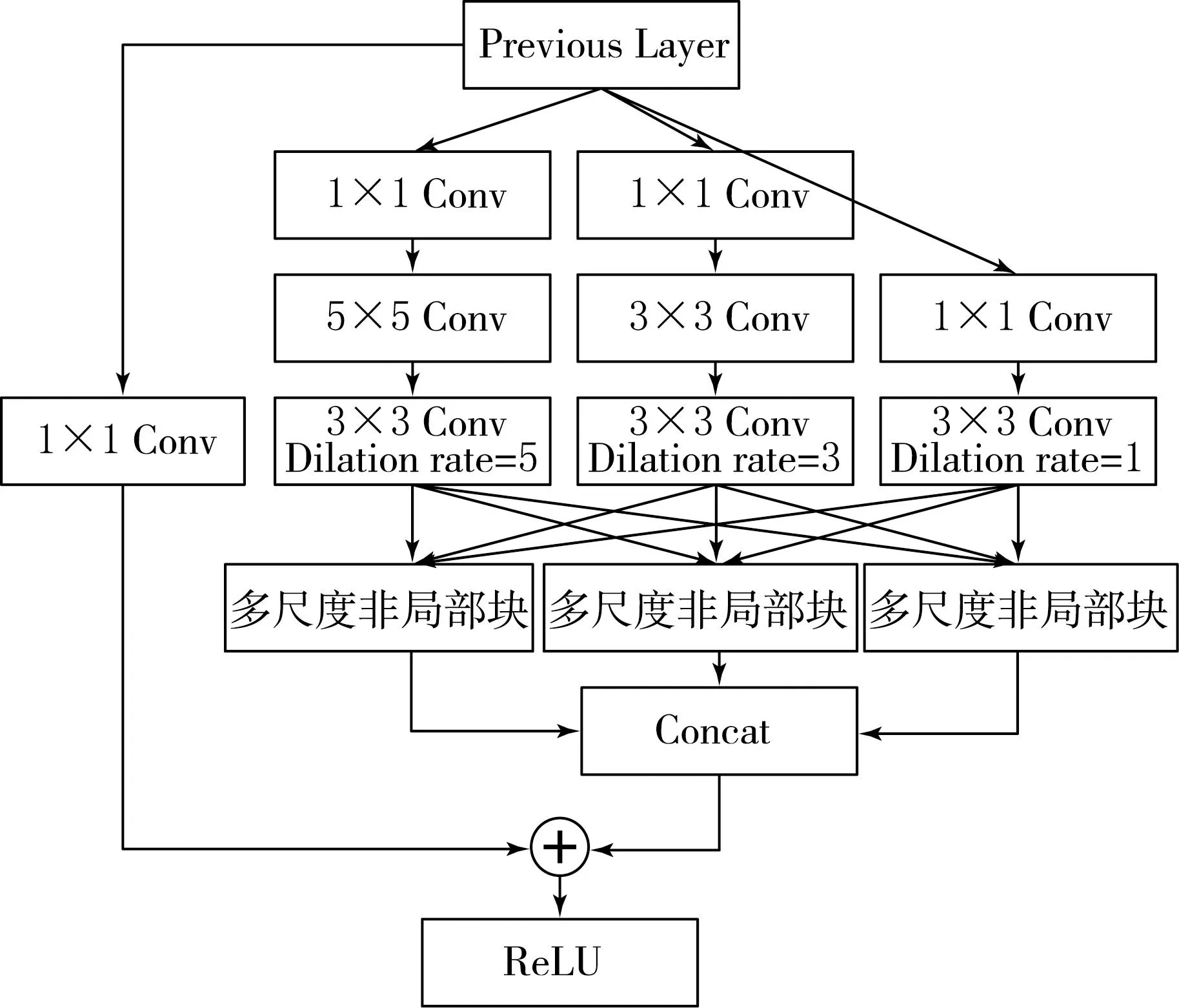
图4 多尺度非局部特征增强模块
根据卷积核的大小和空洞卷积的扩张率,将一个输入特征图分支为3个感受野不同的特征图.这3个特征图具有相同的空间大小,但它们的网格单元具有不同大小的感受野,所以它们的语义大小也不同.
3个不同大小的卷积核被用来产生不同大小的感受野.图4中最左边的分支,通过1×1卷积,输入通道被降低到1/4.为了有效降低其他两个分支的计算复杂度,通过前面的1×1卷积,将输入通道降低到1/8,通过应用3×3和5×5卷积,将输入通道大小降为1/4的特征图作为输出.然后将空洞卷积应用到每个分支特征图中.空洞卷积可以在不增加计算成本的情况下,通过调整核内的间隔来扩展感受野.在3个分支的特征图上分别应用扩张率为1,3和5的空洞卷积.
使用不同大小的卷积核和空洞卷积,生成3个不同感受野的特征图,然后将它们同时输入到多尺度非局部块中,提取不同分支特征之间的非局部关系,并反映在最终的特征图上.图5为多尺度非局部块的结构.多尺度非局部块可以获得具有不同感受野的多个特征图的非局部关系.在图5中,x1,x2和x3是3个具有不同感受野的特征图,x1是用于特征增强的目标特征图.
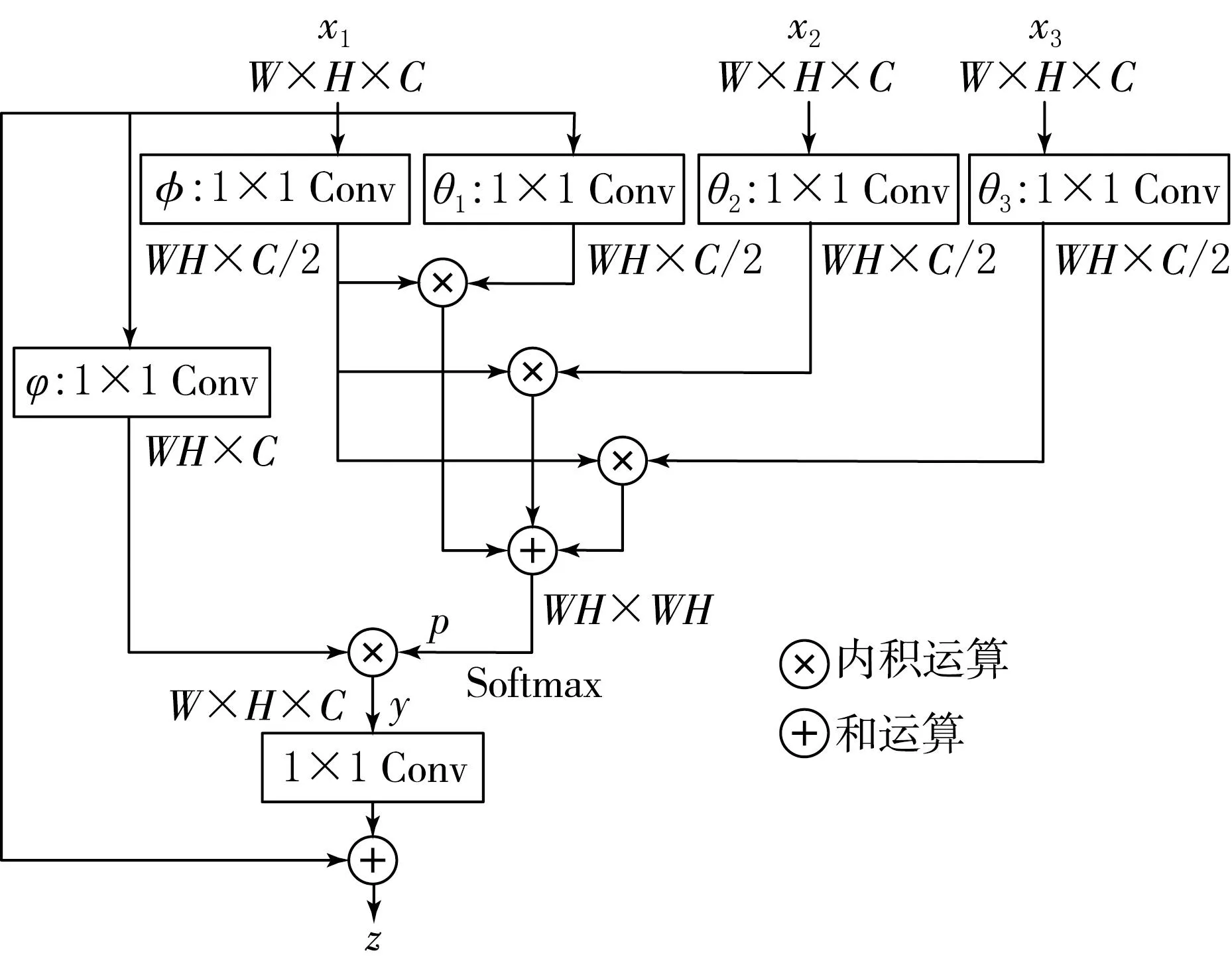
图5 多尺度非局部块结构
首先通过1×1卷积(θ1,θ2,θ3,φ)将可学习参数嵌入到每个特征图中,并将通道降低到1/2以减少计算量.对宽度W、高度H和通道C的特征图进行φ卷积的结果重新排列为C/2×WH,对θ卷积的结果重新排列为WH×C/2,并将φ卷积的特征图与3个θ卷积的特征图进行内积运算,得到所有可能的配对关系,即3张WH×WH大小的关系图.然后将Softmax函数应用于关系图的和,产生一个概率图p,它代表了目标特征图x1和其他特征图x2和x3之间的非局部关系.
概率图p通过与目标特征图x1进行1×1卷积(φ)的结果进行内积运算反映在目标特征图x1上.因此,通过概率图p可以得到包含非局部关系的特征图y,公式为
(1)
其中,F表示CNN的权重参数,使用归一化指数函数Softmax将输入转换为概率分布.非局部特征增强模块的最终输出z是由x1和y融合产生的.对于自适应融合,如式(2)所示,对y进行1×1卷积(Fz),并将其结果加到x1中.
z=Fzy+x1.
(2)
(2)式的特征图增强作用是通过可学习的参数来平衡两个特征图,从而获得一个更有效的特征图用于目标检测.
具有不同感受野的目标特征图x1,x2和x3通过非局部特征模块得到非局部特征增强的特征图z1,z2和z3,将z1,z2和z3在通道方向通过级联叠加并融合成单个分支特征图,如图4所示.然后将融合的分支特征图添加到包含可学习参数的原始特征图中.为了自适应整合,对原始特征图进行了1×1卷积并使用其结果.最后,通过ReLU激活函数生成非局部特征增强模块的输出,最终输出的大小与原始特征图相同.非局部特征增强模块产生的多尺度非局部特征之间的关系提供了与小目标相关的各种尺寸的上下文信息,从而增强了对小目标的检测能力.
2 实验结果与分析
2.1 实验数据集
使用了2个具有代表性的目标检测数据集PASCAL VOC和KITTI.其中,VOC2007由9 963张RGB图和每个图的标注信息组成,分为包含5 011幅图的训练数据集和包含4 952幅图的测试数据集.VOC2012的训练和验证数据集包含11 540幅图,共包含20个检测类别,如图6(a)所示.

图6 数据集示例
KITTI是一个用于道路驾驶中物体检测的数据集,如图6(b)所示,包含7 481张训练图和7 518张测试图,其中仅有训练图包含标注信息.为了对本文方法进行定量分析,从KITTI训练数据集中选取748幅带有标注信息的图作为测试数据集,训练数据集中剩余的6 733幅图用于训练.KITTI数据集比VOC数据集少了9个检测类别,但是额外提供了仅有边界框信息的其他类.本文实验中使用KITTI数据集,是因为在道路环境中,小目标的检测性能非常重要,其准确性直接关系到驾驶的安全性.
2.2 评价指标
本文采用所有类别的平均精度(mean Average Precision,mAP)作为目标检测模型性能的衡量标准.对于单个类别准确率(P)和召回率(R)的计算公式为:
(3)
(4)
其中:TTP为分类正确的正样本,TFP为分类错误的正样本,TFN为分类错误的负样本.单类别的平均精度(AAP)即为单类别P-R曲线下的面积,其计算公式为

(5)
本文所采用的所有类别平均精度AmAP则是计算所有类别P-R曲线下面积的平均值.
2.3 实验配置
实验操作系统使用Ubuntu16.04,编程语言为Python,深度学习框架为Pytorch0.4.1,关键计算硬件为GeForce GTX Titan X显卡进行加速运算.
骨干网络使用ImageNet进行预训练,并根据实验数据集进行微调.网络输入图像大小固定为300×300像素,数据增强策略与SSD相同.批大小(Batch Size)设置为32.初始学习率和L2正则化的权重衰减值分别被设定为4×10-3和5×10-4.优化器为SGD,动量为0.9,学习周期总数为300.
2.4 对比实验结果
将本文方法与SSD[6]和文献[12-15]进行比较.将PASCAL VOC 2007和2012的训练和验证数据集合并为VOC数据集,所有方法使用一个通用的训练数据集.其中DF-SSD和文献[14]分别使用DenseNet和ResNet50作为特征提取骨干网络,其他方法均使用VGG-16作为骨干网络.表2列出了在VOC数据集上各方法的AmAP值.
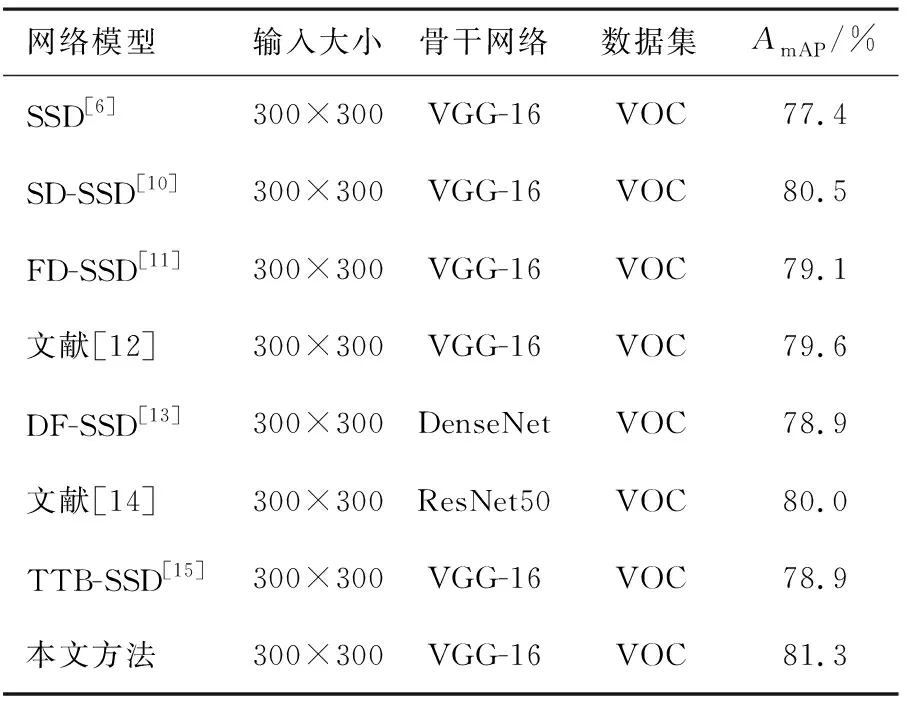
表2 VOC数据集上各方法AmAP值
通常,输入图像的大小会直接影响检测性能,输入图像越大,图像中物体像素越多,越有利于小目标的检测.从表2可以看出,本文方法与其他方法一样,具有最小的输入图像大小,但本文方法的AmAP值最高,达到了81.3%,证明了本文方法在小目标检测中具有较好的鲁棒性.
由于本文方法是基于SSD框架,且特征融合模块与非局部特征增强模块分别参照DSSD的DM模块与RFB-Net的RFB模块设计,因此,在KITTI数据集上对SSD、DSSD、RFB-Net与本文方法进行比较.表3为在KITTI数据集上各方法的AmAP值.
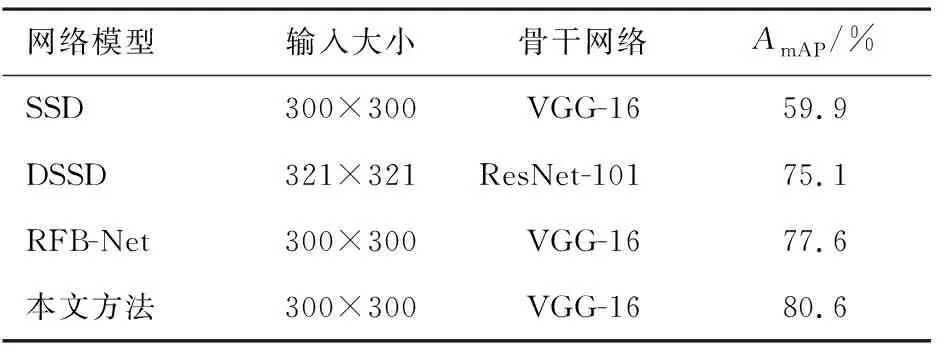
表3 KITTI数据集上各方法的AmAP值
由表3可见,本文方法的AmAP最高,达到了80.6%,证明本文设计的特征融合模块与非局部特征增强模块相较于DM模块与RFB模块能够有效提升目标检测性能.
本文参照COCO数据集进行目标尺寸分类,在该数据集中,将小于32×32像素的物体定义为小目标,将大于32×32像素小于96×96像素的物体定义为中目标,将大于96×96像素的物体定义为大目标.本文同样根据边界框的大小对物体进行分类,如表4所示.由于边界框比目标对象本身大,因此判别参考值略有增加.根据表4中的标准,KITTI数据集有1 055个小目标、2 004个中目标和882个大目标.

表4 目标尺寸分类
在KITTI数据集上对本文方法和其他方法进行定量比较,实验结果如表5所示.从表5中看出在大目标上,本文方法仅略微领先于其他方法,大目标检测性能提高了1.3%.但是本文方法在中、小目标检测性能上相较于其他方法有着明显的提升,AmAP值分别达到了80.1%与61.8%,分别提升了2%和4.2%.由于KITTI数据集中小目标占比高达26.8%,其检测结果的提升更能说明本文方法在小目标检测上的有效性.

表5 KITTI数据集不同尺寸目标AmAP的检测结果 %
2.5 消融研究
为验证本文方法中各模块对提高小目标检测性能的有效性,在KITTI数据集上对本文方法的各个模块进行消融实验,实验结果如表6所示.
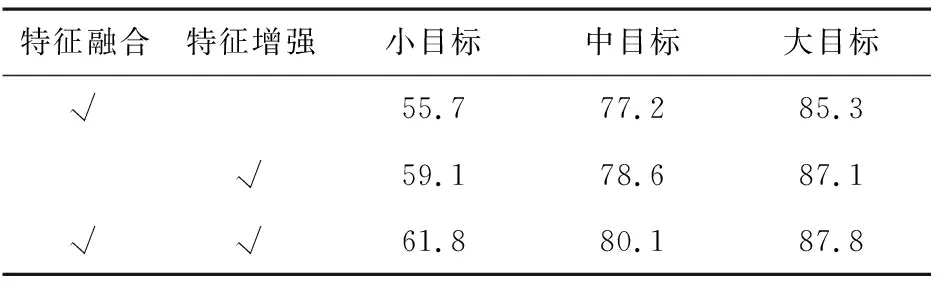
表6 每个模块对检测结果的增益效果的AmAP值 %
从表6中可以看出,本文所提的特征融合方法与非局部特征增强模块对于小目标检测的提高有着明显的效果,有效提高小目标检测的鲁棒性,从而有效提高整体的目标检测性能.
2.6 结果可视化
为了直观地展示本文方法在小目标检测上相较于传统SSD的性能优越性,对部分结果进行可视化对比.PASCAL VOC 2007数据集上本文方法与传统SSD的检测结果可视化对比见图7.从图7中可以明显看出,本文所提的方法在小目标检测上效果要明显好于传统SSD,其中,第一行中传统SSD方法将两个sheep类对象错检为dog类与cow类,且漏检了上方像素较少的sheep类对象,而本文方法则没有出现漏检错检的情况;第二行中传统SSD则完全忽略了上方的cow类小目标,本文方法则成功检测出cow类的小目标;第三行中本文方法相较于传统SSD成功检测出每一个person类小目标;第四行中本文方法成功检测出左侧的car类小目标,而传统SSD方法则未检测出小目标.

图7 VOC数据集检测结果可视化对比
图8为KITTI数据集上本文方法与传统SSD的检测结果可视化对比,其中左侧为传统SSD的检测结果,右侧为本文方法的检测结果.从图8中可以明显看出,无论是在道路还是窄巷的交通场景中,本文方法在小目标检测上明显优于传统SSD.如图8(a)所示,在道路的场景中,传统SSD对于远处的汽车以及交通信号灯等小目标出现了明显的漏检情况,而本文方法则成功的检测出远处的车辆以及交通信号灯,可以更好地保证自动驾驶的安全性.在窄巷的场景中,传统SSD同样对于远处停放的小目标车辆出现了漏检的情况,而本文方法则成功检测出远处的小目标车辆,如图8(b)所示.

图8 KITTI数据集检测结果可视化对比
图9和图10给出了本文方法对VOC数据集和KITTI数据集的检测结果示例,每张图片都包含一个或多个小目标,可以明显看出,本文方法能够有效地检测出不同场景图像中各种类型的小目标.
3 结论
本文提出一种基于新的特征融合方法与特征增强模块的改进SSD小目标检测算法,通过将SSD中的相邻特征融合来有效利用上下文信息,然后通过不同尺寸特征之间的非局部关系来增强特征映射,从而提高对小目标的检测精度.实验结果表明,本文算法提升了SSD算法的小目标检测准确率,且比现有方法具有更好的小目标检测性能,对于自动驾驶等应用有着现实意义.本文所提的算法在小目标检测精度上还有进一步提升空间,下一步工作将针对真实驾驶场景对算法做进一步的优化,以提升真实驾驶环境中算法对小目标的检测性能.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2021年2期)2021-06-09
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
