
基于文本语义指导的自然场景文本图像超分辨方法
2023-12-27 07:18习晨晨孟雅蕾张凯兵
空军工程大学学报 2023年6期
习晨晨,何 昕,孟雅蕾,张凯兵
(1.西安工程大学电子信息学院,西安,710048;2.西安工程大学计算机科学学院,西安,710048)
文本图像作为一种特殊图像存在于人们的生活当中,人类大脑时刻在对看到的场景进行分析,并根据场景中的文字指导行为。但是受环境、设备等因素的影响,采集的文本图像往往存在模糊、失真等低质量的情况。因此如何正确提取低质量文本图像中的信息来获得更高质量的图像已经成为一个日益紧迫的问题。文本图像超分辨重建技术应运而生[1-2]。文本图像超分辨重建技术已经在交通安全监控、笔迹识别、证件识别、自动驾驶以及书法文物保护与恢复等领域具有极大的应用价值。
相比于规整的扫描文档图像,自然场景中拍摄的图像所包含的文本有水平、倾斜甚至弯曲的文字,而且受制于硬件设备、摄像机抖动、相机与目标对象间的相对运动等拍摄条件的限制导致图像存在不同程度的模糊、昏暗或者分辨率低等情况,多种因素表明自然场景文本图像超分辨(scene text image super-resolution,STISR)非常困难。近年来,随着深度学习技术的快速发展,基于深度学习的自然场景文本图像超分辨技术克服了传统方法复杂度高、泛化性差且需要较多的先验信息等的局限性,取得令人瞩目的成就。Wang等[3]引入条件生成对抗网络(conditional generative adversarial networks,cGAN)来重建STISR,去除了cGAN中的批归一化(batch normalization,BN)层,引入了Inception结构,有效扩展了网络的宽度,使生成器能自适应地捕捉图像中不同大小的文本线索,更适合STISR重建任务。Xue等[4]采用残差密集网络(residual in residual dense network,RRDN)提取比普通残差网络更深层的高频特征,并利用注意力机制增强空间和通道特征,同时引入了梯度损失监督网络训练,以获取更加清晰的文本边缘,该方法在STISR任务上取得了不错的结果。Zhang等[5]设计了一种不需要预训练的STISR重建网络,该网络主要由卷积层、BN层、LeakyReLU激活层以及上采样层和下采样层组成,利用深度图像先验(deep image prior,DIP)的特点,设计了一种新的加权MSE损失函数来突出文本图像的高频细节。
2021年,Fang等[6]提出文本超分辨生成对抗网络(text super-resolution generative adversarial networks,TSRGAN),引入生成对抗网络来防止网络产生过平滑图像,同时加入三元组注意力机制提高网络的表征能力,并引入小波损失来重构更清晰的边缘。Honda等[7]提出了一种基于多任务学习的STISR网络(multi-task super-resolution,MTSR),该网络使用了2个并行任务:图像重建和图像超分辨(super-resolution,SR),将重建模块和SR模块的特征进行融合然后送入下一层进行迭代,使SR网络能够学习到重建任务中所提取的特征,最后得到一个训练完备的STISR模型,获得不错的重建效果。但上述方法缺少先验信息的利用,导致恢复图像缺少细节信息,不能达到令人满意的效果。
本文受文本先导超分辨(text-prior guided super-resolution,TPGSR)网络[8]启发,以文本超分辨网络(text super-resolution network,TSRN[13])为基础,从先验信息利用和损失函数2个角度考虑自然场景文本图像超分辨任务,提出了一个新的文本语义指导的超分辨网络(text-semantic guided super-resolution network,TSGSRN)。针对TPGSR方法中使用低分辨文本先验指导网络训练导致先验信息利用不准确的问题,本文提出使用预训练语义感知网络建立SR图像和真实高分辨(high resolution,HR)图像之间的文本语义监督,以有效提高网络模型对文本字符的语义理解能力。除此之外,针对现有的十字交叉注意力机制只关注局部特征的问题,本文使用循环十字交叉注意力[9],提升远距离像素之间的相关性,更好地融合周围像素的上下文信息,从而捕获全局信息。最后,考虑到现有方法使用边缘检测算子提取边缘导致的边缘特征丢失问题,采用软边缘损失和梯度损失对重建结果进行优化。在相同的实验条件下,提出的TSGSRN能获得比现有方法更好的质量评价指标[10-11]。
1 TSGSRN整体框架
本文提出的TSGSRN的整体框架如图1所示,由超分辨重建模块和文本语义感知模块组成。
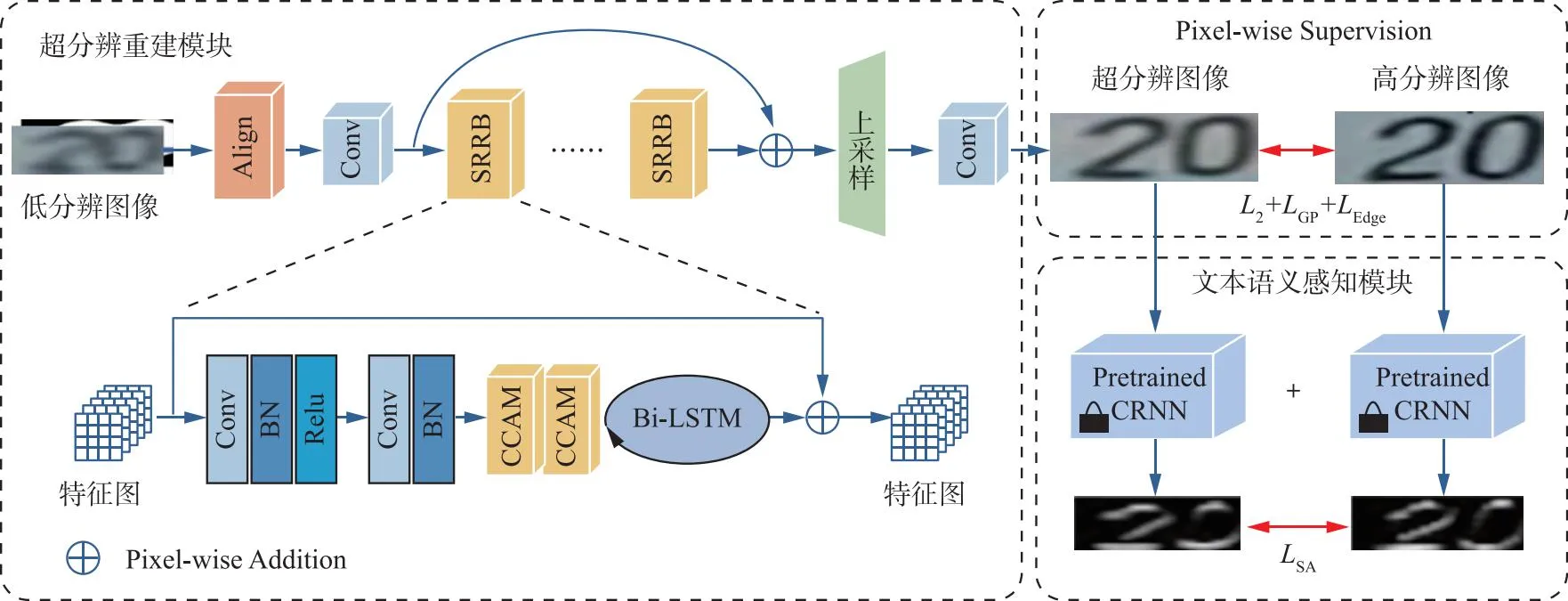
图1 基于文本语义指导的自然场景文本图像超分辨方法整体框架
超分辨重建模块以LR图像及其二进制掩码图作为输入。其中,LR图像为RGB图像,二进制掩码图为二值图(文字区域置为1,背景区域置为0)。首先,网络的输入经过中心对齐网络进行对齐,然后通过单个卷积层提取特征;其次,通过7个相同的超分辨残差块;最后,使用Pixel-Shuffle对处理后的特征映射进行上采样,以生成SR结果,并通过L2损失、梯度损失和软边缘损失计算重建图像和真实图像之间的差异。文本语义感知模块通过预训练识别网络建立SR图像和HR图像之间的字符类别概率分布差异,获得更多面向文本的信息。相比于TSRN,TSGSRN有以下改进:①使用预先训练的语义感知网络感知文本自身的语义信息,使得模型具有更好的语义理解能力;②TSGSRN在每个超分辨残差块中加入了注意力机制进一步提升超分辨效果;③使用软边缘损失对生成图像的边缘进行约束,得到边缘更准确、清晰的超分辨结果。
2 TSGSRN设计
2.1 超分辨重建模块
SR重建模块主要由对齐模块、基于残差网络的重建主体、后上采样模块组成。首先,LR文本图像及其二进制掩码图像作为输入,送入到对齐网络中,使得输入的LR图像与真实的HR图像具有中心对齐的效果,以减小数据本身存在的像素误差。对齐网络采用薄板样条变换(thin plate spline,TPS),对齐过程可以表示为:
Fin=fTPS(ILR)
(1)
式中:fTPS表示薄板样条变换;Fin表示对齐网络的输出特征。然后,输出的特征经过一个卷积核大小为9×9的卷积和PRelu激活函数,表示为:
(2)
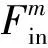
(3)
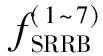
(4)
式中:fup表示2倍上采样操作;ISR表示整个超分辨重建模块的输出结果。
2.2 文本语义感知模块
为了使得网络能够充分理解文本的内容信息,具有更好的感知能力,本文提出文本语义感知模块见图2,为文本语义感知(semantic-aware,SA)模块的内部结构。

图2 文本语义感知模块结构
SA模块使用CRNN网络[12],该网络结构包含3个部分:卷积层、循环层和转录层。卷积层使用卷积神经网络(convolutional neural network,CNN),从输入图像中提取图像特征;循环层使用循环神经网络(recurrent neural network,RNN),对图像特征的语义信息进行建模,用来预测从卷积层获取的特征序列的标签分布;转录层使用CTC损失使得预测序列更准确地与目标序列对齐,把从循环层获取的标签分布去重整合得到最终的分类文本先验。
SR重建模块得到的SR图像ISR和真实的HR图像分别送入CRNN网络中,以SR图像为例:首先经过6个卷积层,得到卷积层的输出特征:
(5)
然后,特征FCNN送入循环层,循环层使用双向长短时记忆网络,根据输入的特征进行预测,得到所有字符的SoftMax概率分布,该分布是长度为字符类别数,高度为字母表a~z和数字表0~9的向量。将该分布送入第3部分转录层,使用CTC损失使得预测序列更准确地与目标序列对齐,把从循环层获取的标签分布去重整合得到最终的分类文本先验,如图3所示。白点越明显,表示属于该类别的概率越高;越模糊,表示属于该类别的概率越低。

图3 字符分类概率图
2.3 循环十字交叉注意力
随着注意力机制被提出,超分辨任务也取得了进一步的发展。通道注意力首先被提出,其旨在建立不同通道之间的相关性,通过对每个通道的特征赋予不同的权重,从而强化重要特征,抑制非重要特征,更关注于全局特征;空间注意力旨在增强关键区域的特征表达,通过对空间中每个位置生成权重掩膜进行加权,增强感兴趣区域表达,弱化无关的背景区域;三元组注意力通过利用三分支结构实现跨维交互,建立维度间的依赖关系;坐标注意力则是将位置信息嵌入到通道中,分别沿2个方向聚合特征,可以在一个空间方向上捕获远程依赖关系,同时在另一个空间方向上保存精确的位置信息,其只能捕获某一个坐标的信息,不能捕获周围相邻像素的信息,而循环十字交叉注意力通过级联2个相同的十字交叉注意力,更好地融合全局上下文信息。
十字交叉注意力结构如图4所示,对于输入特征X,首先使用3个不同的1×1卷积核获取注意力模型中的Q,K,V;通过Q和K来获取当前像素下横向和纵向像素点之间的相关性。最后将相关性矩阵与V整合,再加上原始的特征X,得到最终的注意力特征X′,但是该注意力只计算了“十字”结构中像素点的相关性,对于周围的像素点未遍历,只关注到局部特征。因此,通过级联双层的十字交叉注意力可对周围像素点进行遍历,从而融合全局上下文信息。循环十字交叉注意力在语义分割任务中已经取得不错的效果。由于文本超分辨的目的是增强文字区域,弱化背景区域,因此该注意力可应用于文本超分辨任务。
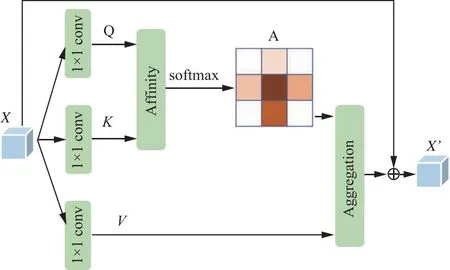
图4 十字交叉注意力
2.4 损失函数设计
在SR任务中,联合不同损失函数对网络模型进行优化,有利于加快网络训练时的收敛速度,从而提升模型的重建性能。因此,本文将像素损失、梯度损失、软边缘损失和文本语义感知损失联合起来共同训练所提出的深度网络。本文方法使用的损失函数如下:
1)像素损失。像素损失表示SR结果和目标图像之间的曼哈顿距离,相比于L1损失,L2损失有利于恢复清晰的边缘,提高模型收敛速度。因此,本文采用L2损失度量重建图像与目标图像之间的误差。像素损失表示为:
(6)
式中:ISR为SR图像;IHR为真实的HR图像。
2)梯度损失。图5(a)、(b)和(c)分别表示LR、SR和HR图像,图5(d)、(e)和(f)分别表示其梯度图。可以看出,LR图像的梯度场为矮胖型,而HR图像的梯度场为高瘦型,为了减小SR图像和真实HR图像之间的梯度分布差异,引入梯度损失,从而进一步减小SR图像和真实HR图像之间的差异,表达式为:
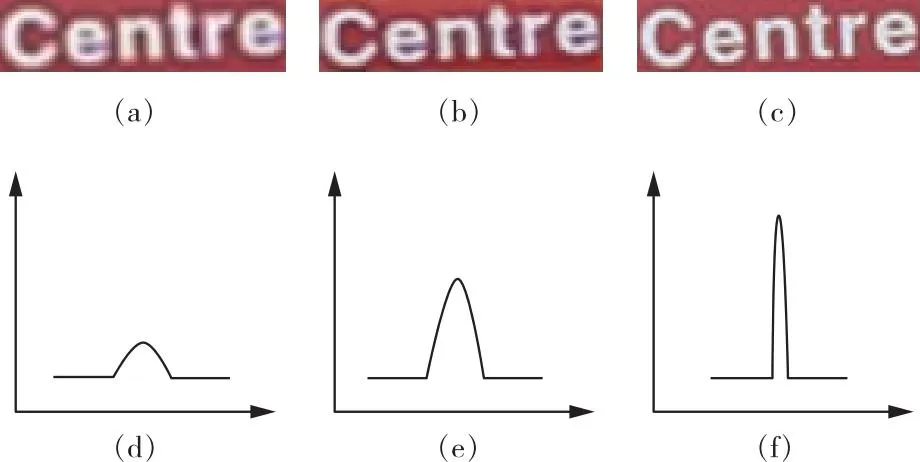
图5 低分辨、超分辨和高分辨图像及其对应的梯度图
Lgrad=‖∇ISR-∇IHR‖1
(7)
式中:∇表示梯度操作。
3)软边缘损失。为了保证恢复图像的边缘完整性,本文直接通过软边缘损失对SR图像和HR图像进行监督,表达式为:
(8)
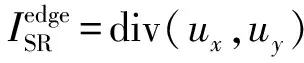
4)文本语义感知损失。由于CRNN中的CNN的浅层特征和深层特征分别关注局部结构信息和全局语义信息,因此,文本语义感知损失可以同时保证低级笔画结构和高级文本上下文之间的一致性。相比于一般的自然图像超分辨方法侧重图像的局部细节,对文本语义和字符的形状理解不佳,因此,从预训练的文本语义感知模型中可以获得更多面向文本的信息,它可以更好地衡量SR图像和HR图像中前景字符之间的相似性,表达式为:
Ltsa=λ1|tSR-tHR|+λ2DKL(tSR‖tHR)
(9)
式中:tSR和tHR分别表示SR图像和HR图像的语义类别概率;|·|表示L1范数;DKL表示KL散度操作;λ1和λ2为很小的常数,均设置为1.0。本文联合以上4个损失对网络模型参数进行优化,整个网络的损失函数表示为:
L=αLpixel+βLgrad+γLedge+λLtsa
(10)
式中:α,β,γ,λ为用于平衡4个损失的权衡因子。本文将权重分别设置为:20、0.1、0.1和0.1。
3 实验结果与分析
3.1 实现细节
本文方法使用WANG等[13]提出的TextZoom数据集进行训练和测试,该数据集是从CAI等[14]提出的RealSR和ZHANG等[15]提出的SRRAW中裁剪得到。该数据集是第一个用于自然场景文本图像超分辨任务的数据集,由相机在不同焦距的真实场景中捕获(如图6所示),其包含LR-HR图像对,但由于人为抖动等原因,存在像素不对齐问题。

(a)150 mm
TextZoom数据集中18 986张图像用于训练,4 373张用于测试。测试集根据恢复难易程度分为3个等级:easy,medium和hard(如图7所示)。Easy包含1 619张图像,medium包含1 411张图像,hard包含1 343张图像。与合成的文本数据集的不同之处在于,该数据集的LR图像不是经过对HR图像下采样获得。并且TextZoom数据集在真实场景中经历了复杂的退化,这使得SR模型难以恢复高质量的文本图像。低分辨图像大小为16×64,HR图像大小为32×128。本算法模型基于Pytorch平台实现,GPU使用Nvidia 2080Ti,学习率设置为0.001。
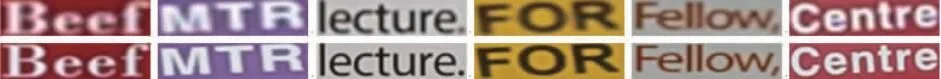
(a)easy
3.2 对比结果与分析
为了验证本文提出方法的有效性,在公共的自然场景文本超分辨数据集TextZoom上进行了验证实验。本文方法对比了8种主流的超分辨方法:BICUBIC[16]、SRCNN[17]、SRResNet[18]、RDN[19]、VDSR[20]、LapSRN[21]、TSRN[13]、TSRGAN[6]。在TextZoom数据集上进行2倍放大的识别率评定结果如表1所示。ASTER,MORAN和CRNN为常用的3种文本识别器。ASTER由矫正网络和识别网络组成,矫正网络使用TPS,识别网络是一种加入注意力机制的序列-序列模型,对矫正后的图像进行字符预测;MORAN由矫正子网络MORN和识别子网络ASRN组成,针对弯曲等不规则文本图像具有较好的识别效果;CRNN的详细介绍见2.2节。表1中,average为3个测试子集识别率的加权平均值,由于3个测试子集数量分别为1 619,1 411和1 343,因此将权重分别设置为0.37,0.32和0.31。PSNR[22]和SSIM[23]指标的定量评定结果如表2所示。在表中最优值均加粗表示。(注:由于TSRGAN方法源码未公开,所有数据均摘录于原论文)

表1 识别率对比实验结果

表2 PSNR和SSIM指标对比实验结果
在所有的比较方法中,前6种方法为一般图像超分辨方法,没有加入任何的图像先验信息,受模型性能制约,效果较差;TSRN使用梯度损失加强边缘的构建,效果略有提升;TSRGAN在TSRN基础上增加对抗损失和小波损失,进一步提升了超分辨效果;本文方法在TSRN基础上加入文本语义先验和软边缘损失,识别率进一步提升。从表1可以看出,本文方法在3个识别器上的平均识别率相比于TSRN分别提升了2.06%、1.80%和2.89%。在ASTER和CRNN识别器上的平均识别率相比于TSRGAN分别提高了0.34%和1.48%。在MORAN上的平均识别率却稍低于TSRGAN。
由表2可以看出,本文方法相比于TSRN在3个测试子集的结构相似性(structual similarity,SSIM)指标分别提升了0.008 1、0.014 3和0.012 7;峰值信噪比(peak signal to noise ratio,PSNR)指标分别提升了0.47、0.34和0.22。相比于TSRGAN方法,本文方法的SSIM指标在测试子集easy和medium上略低,原因在于TSRGAN引入了对抗网络,使得生成的文本图像具有更丰富的细节。
由于PSNR指标具有争议性,模糊的图像可能具有较高的PSNR值,而清晰的图像可能倾向于表现出较低的PSNR值,不一定符合人眼的视觉感知质量,因此,不以PSNR指标作为主要评价指标。综上,本文方法相比于其他对比方法表现出了一定的优势。
为了更直观地对比不同SR方法的重建性能,图8展示了所有对比方法在TextZoom数据集上的SR重建效果对比。本文选取一些最具有代表性且边缘细节及文字完整性较好的图像进行视觉质量对比。可以看到,方法SRCNN、SRResNet、RDN、VDSR、LapSRN和TSRN方法的重建结果较为平滑,边缘完整性较差,而本文方法获得的结果均表现出较为完整的字符边缘,这主要得益于模型加入了文本语义信息和软边缘损失。尽管TSRN也能够重建出较好效果的图像,但是在细节上仍然存在问题,字符的分离度较差,存在相邻字符之间的粘连问题。其原因在于该网络在训练的过程中只针对边缘结构进行了优化,而缺少文本本身的语义信息参与指导,导致训练得到的模型在重建过程中很难对相邻字符之间的特征进行精准表示。

图8 不同超分辨方法视觉对比结果
综上,本文方法在相邻字符的处理上具有一定的优势,且效果逼真,识别错误率最低。此外,本文方法与TSRGAN相比在参数量上也有明显的优势。本文提出的基于文本语义指导的STISR方法具有较好的重建性能,更适合STISR重建任务。
3.3 消融实验
1)循环十字交叉注意力。为了验证提出方法使用的循环十字交叉注意力的有效性,对比了几种具有代表性的注意力:通道注意力(CA)[24]、通道-空间注意力(CBAM)[25]、三元组注意力[26](TAM)和坐标注意力(CoA)[27],在3个测试子集的对比结果如表3所示。
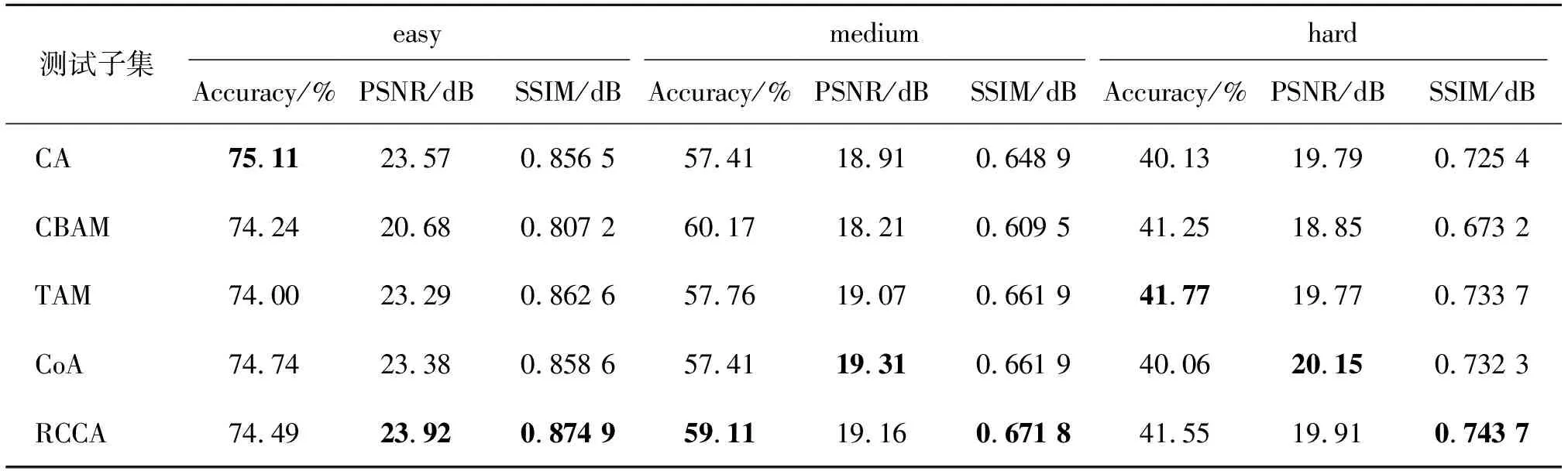
表3 不同注意力的对比实验结果
由表3可见,相比于其它注意力模型,使用的循环十字交叉注意力在easy和medium测试子集上的识别率、PSNR和SSIM指标具有一定的优势,能显著提升重建图像质量。
2)文本语义感知模块。为了验证SA模块的有效性,对该模块进行了消融实验,从定量和定性2个层面证明SA模块的有效性,定量对比结果如表4所示,加入SA模块后,在测试集的3个子集上的平均识别率、平均PSNR和SSIM值都高于没有SA模块的模型。重建图像的视觉质量对比如图9所示。从图9可以看出,在SA模块的作用下,模型具有较高的字符语义理解能力,字符的完整程度明显较高,与HR图像的相似性更高。

表4 语义感知模块有效性定量对比实验结果

(a)无SA模块
3)损失函数。为了验证本文方法所用损失函数的有效性,对其进行了消融实验,如表5所示。

表5 不同损失函数的消融实验对比结果
由表5可以看出,相比于单一的损失函数,联合所有的损失函数能够显著提升模型的重建性能,得到更好的重建效果。表5中,第1行只使用像素损失,模型的重建效果不理想;第2行表示在像素损失的基础上加入梯度损失,可以看出,在3个测试子集的识别、PSNR和SSIM指标均有所提高;第3行表示在像素损失、梯度损失的基础上加入软边缘损失,可以看出,在medium测试子集的识别率提高了0.66%,在medium测试子集上的PSNR指标提高了0.51 dB;第4行表示在像素损失、梯度损失和软边缘损失的基础上加入文本语义感知损失,可以看出,在3个测试子集的识别率、PSNR和SSIM均有所提高,相比于只使用像素损失的模型,对比指标有大幅度提升。上述实验结果验证了本文提出的3个损失函数对模型性能提升均有贡献。
4)SRRB的数量。此外,还验证了SRRB的数量对网络模型重建性能的影响,结果如图10和图11所示,对于STISR任务,并不是越深的网络效果越好,主要在于图像先验信息的引入,由图10可以看出,SRRB数量为7时,模型在3个测试子集上均具有最好的识别率。
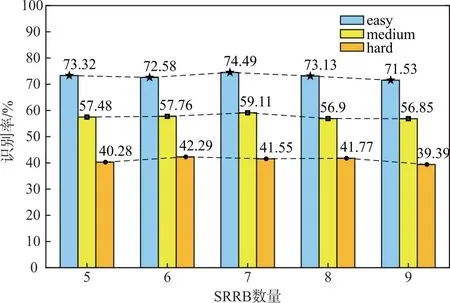
图10 SRRB数量的消融实验在识别率上的对比结果
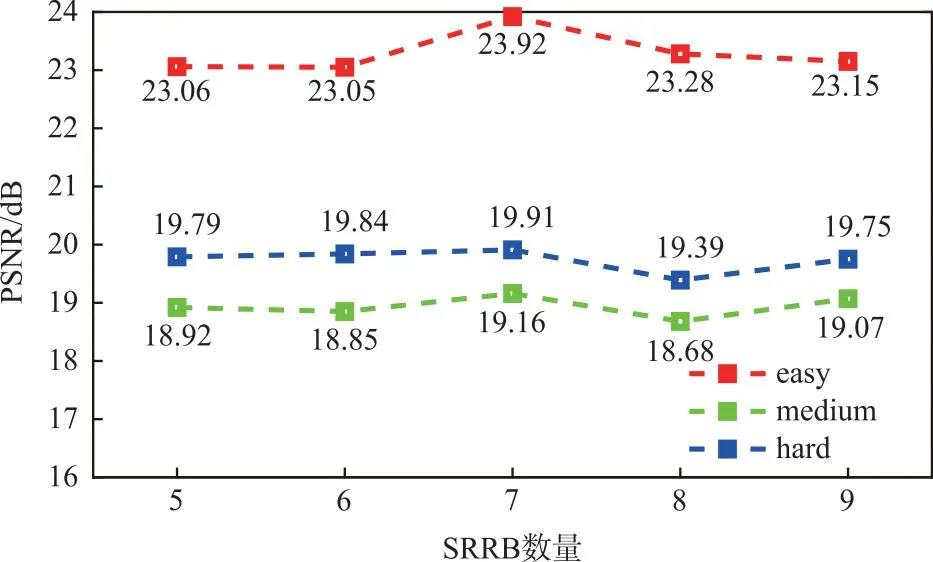
(a)PSNR指标
SRRB的数量对PSNR和SSIM指标的影响结果如图11所示,可以看出,当SRRB数量为7时,模型具有最佳的PSNR和SSIM指标。
4 结语
本文提出了一种基于文本语义指导的STISR模型,该模型能够充分利用文本图像的文本语义信息指导超分辨模型训练,通过循环十字交叉注意力提升模型对文本上下文的理解能力,提升有效信息的表达能力,将更多的注意力放在文字本身。在常用的基准数据集TextZoom上的实验结果表明,本文提出的方法在主观和客观质量评价方面都能够获得更好的重建结果,尤其在处理文本字符的粘连问题方面相比于其他方法具有显著优势。
尽管提出的基于文本语义指导的STISR重建方法能够获得更好的重建性能,但是仍然存在不足之处。首先,数据集中存在大量模糊图像,模型对其语义理解能力不佳,效果较差;其次,STISR任务可以视为高频信息恢复后的颜色填充问题,如何只对图像的高频信息进行处理显得尤为重要,是未来需要进一步研究的问题。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国交通信息化(2016年2期)2016-06-06
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
