
依据散列查找的分布式网络数据分流算法
2023-12-27 05:05梁鑫龙徐永贵
新乡学院学报 2023年12期
梁鑫龙,徐永贵,史 君
(淄博师范高等专科学校信息系,山东 淄博 255100)
近年来,在各项先进技术的大力推动下,互联网规模和应用数据量呈直线上升趋势, 越来越多的应用需要借助分布式网络实现快速且精准的数据分流。例如,在通过路由器转发网络数据时, 需要在较短时间内快速找出分布式数据中的路由表,确保数据可以实现精准分流。可见,针对数据分流展开研究是十分必要的。现阶段,针对分布式网络中的数据分流,一般使用专门的分流装置,按照分流策略,将大流量网络中的数据分成几个小流量的数据。 但是,当前的分流算法有两大问题,一是数据的完整性问题,二是负载平衡问题。
对此, 本文提出基于散列查找的分布式网络数据分流算法。通过对网络数据进行特征提取,根据数据不同的特性,将其划分为多种不同的种类;通过不断更新数据聚类中心,使数据具有高度动态变化特征,实现数据的分流处理。将本文方法与其他方法进行对比,结果表明,本文方法具有最佳的数据分流处理效果。
1 分布式网络数据分流描述
1.1 “流”的局部性定义
“流” 可以被理解为具有相同目的和地址的数据包,顾名思义,分流[1-2]就是将具有相同地址和目的的数据包划分为多个不同的流。 在网络环境下,FTP (文件传输协议)文件和WEB(全球广域网)界面[3]以及其他协议等具有相同的地址,需要对其分流后再传输。一旦FTP 文件首次发送成功, 那么在一定的时间范围内,其他分组在同一数据流中的成功传递概率[4]将会显著提高。这种现象称为流的局部性特征,示意图如图1 所示。
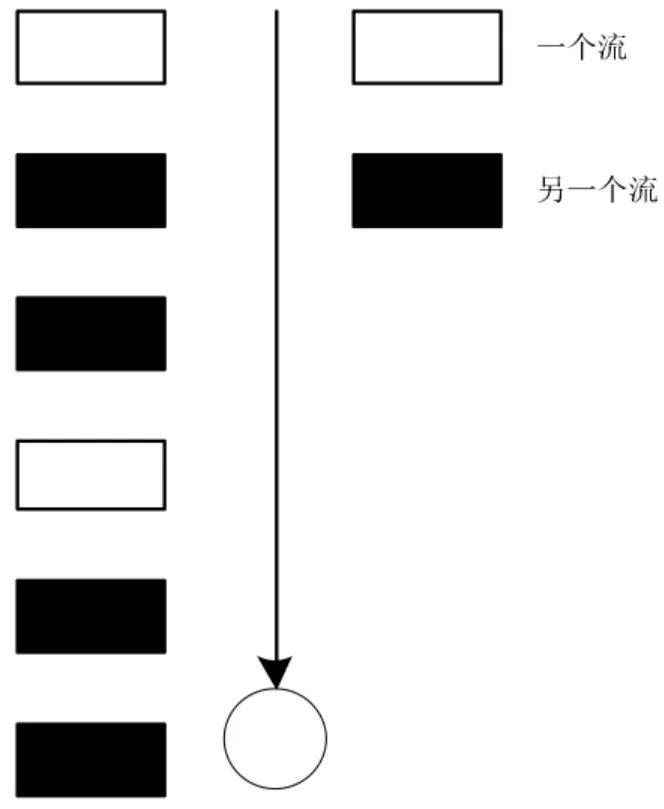
图1 “流”的局部性特征示意图
1.2 分布式网络数据分流约束条件
式中,w表示分布式网络的大小,x表示网络节点通道,b表示嵌入维数最小值。
对分布式网络数据做归一化处理[6],得到
将数据分流问题近似地看作是具有约束特征的非线性问题,那么可得
通过上述计算, 可以得到数据分流的对偶函数[7]表达式
式中,α表示网络节点的约束条件[8]。
式(4)的约束特性为
在高维空间中,通过式(5)的约束,计算对偶函数的二次函数,表达式为
1.3 能量消耗模型
当网络节点发送和接收相同数量的数据时, 能耗计算公式为
式中,l表示分布式网络节点接收和发送的数据总量。
对于接收数据的源节点来说, 由于其包含头部信息,使得第k个获取数据的源节点能量消耗为
式中,表示源节点接收数据的能耗,、分别表示数据量的大小。
将源节点接收的数据做压缩处理后再进行传输分流,这个过程能耗计算公式为
通过上述分析计算可知, 分布式网络数据传输分流能耗与数据量大小有着直接关系,数据量越大,传输和分流数据所产生的能耗就越高。
2 基于散列查找的分布式网络数据分流实现
将同一个流中完成分流的数据进行缓存, 缓存可以减少算法计算时间,减少散列表的查找步骤,提高算法整体的运算效率。 散列查找中“流”的局部性原理[9]如图2 所示。
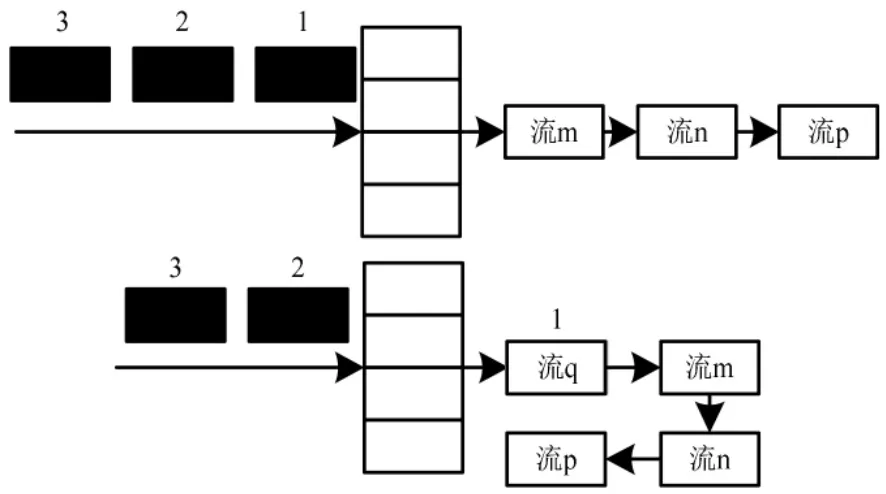
图2 散列查找中“流”的局部性原理图
2.1 分布式网络数据特征提取
完成对分布式网络数据的能耗分析后, 从空间重建观点出发,利用非线性映射方法[10],建立数据分流过程的时间序列信息模型。利用指标数据的映射方法,建立一个具有高维映射矢量的非线性模型, 并对其进行分析,得出最优解和最大延迟特性,从而实现对网络数据的特征提取。
式中,t0表示数据采集初始时刻, ∆t表示数据采集间隔时间段,表示所有网络数据在同一时间序列下的相似性特征度,ϖn表示数据相关性系数。
式中,si表示映射向量分量,g表示数据时间序列系数值。
构建分布式网络数据目标查找函数, 将R定义为分流过程中数据特征矢量的关联函数[12],ug为数据交叉分布模型,用公式表示为
式中,a0表示网络数据原始采样幅值,ua−1表示分布式网络数据均值与方差完全相同的标量序列,bi表示最佳分裂属性。
接下来利用C均值聚类算法对目标函数进行求解,假设µik是目标函数的聚类最大值,表达式为
通过式(13)得到数据时延特征ξi,至此完成分布式网络数据的特征提取。 计算过程为
2.2 分布式网络数据分流实现
对分布式网络数据的特征提取后, 根据数据自身特性的不同, 划分为不同的种类, 完成数据的分流处理。 分流的第一步是确定分布式网络数据的原始聚类中心,在分流过程中不断更新该中心的内容,以此满足环境变化带来的数据高度动态变化特征。
用d表示网络数据的初始聚类中心,将v定义为初始特征数量, 选出其中的κ个特征作为初始聚类核心Si,每个Si代表一种数据类型。 通过对数据特征的分析和计算后,得到v−κ个数据特征与Si之间的目标距离。 然后,将数据特征划分到不同的聚类核心中,实现数据特征点的匹配。
通过上述描述将网络数据特征区划分为κ个不同特征
其中,zi表示分布式网络数据特性,表示Si的均值化结果,DF表示网络数据特征区划分形式总数的类型特征。在分布式网络数据分流的过程中,通过对数据特征分析和计算,将数据划分为不同的类型,并根据特征点匹配的结果进行数据分流[13],以达到提高数据处理效率和实现优化的目的。
将网络数据特征区划分为κ种特征后,数据特性集合为T j(j=1,2, …,κ),简化表示为T={DF}。 经过重复迭代计算后,确定分布式网络数据的分流过程。
步骤一:确定分布式网络数据的原始聚类中心d,将其划分为κ个子聚类中心,划分过程需在满足
的基础上进行。
步骤二:对数据特性做循环迭代计算,得到新的数据特征集合TFi+1。
步骤三:当g=0时,聚类中心为TF0。
步骤四:在此基础上,分析数据分流过程中的误差和方差。 当方差满足预先设定的值后,停止计算,输出结果即为最终的分流结果。
网络数据的聚类中心不断更新变化,可以更好地适应互联网环境下的数据动态变化特性[14],得到最佳分流函数
综上所述, 基于散列查找的分布式网络数据分流过程如图3 所示。
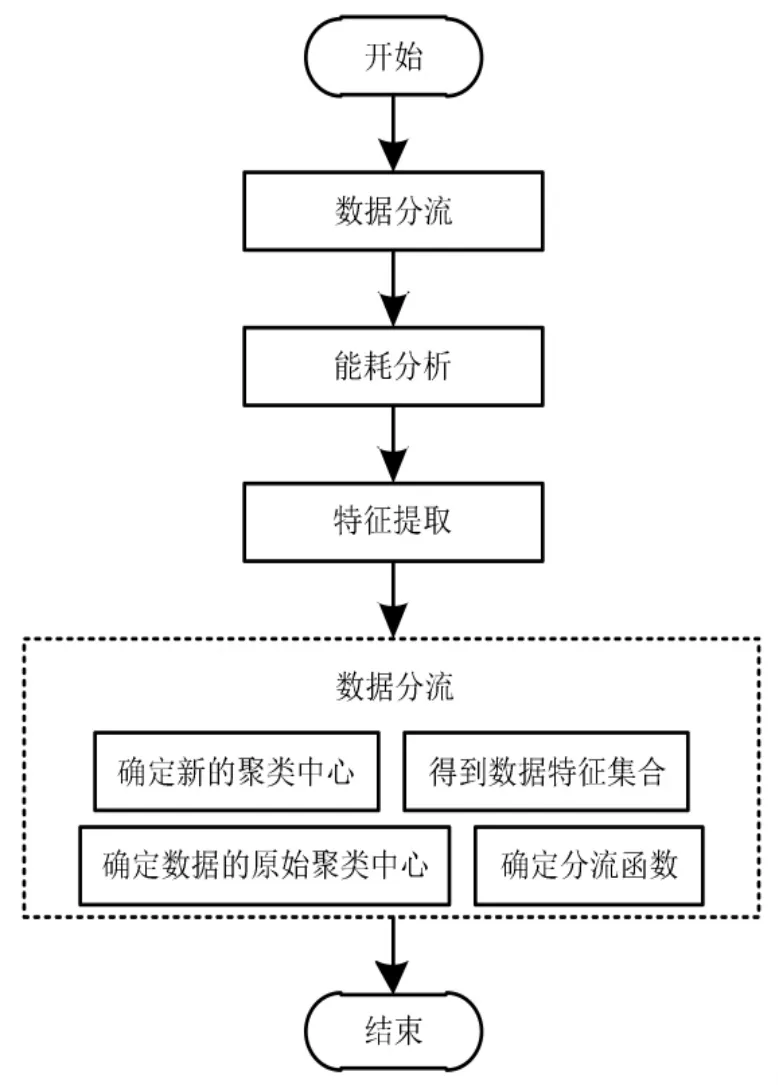
图3 基于散列查找的分布式网络数据分流过程
3 仿真实验
为了验证本文方法在实际应用中是否同样有效,与马尔科夫决策过程和数据分区算法展开对比仿真实验。实验中,数据集选用的是Kddcup99 数据集,其中包含了实验所需要的高速网络流量数据。
3.1 所提方法性能测试
为了验证所提方法在网络数据分流方面的性能,以网络拥塞率为指标对其进行测试,结果如图4 所示。
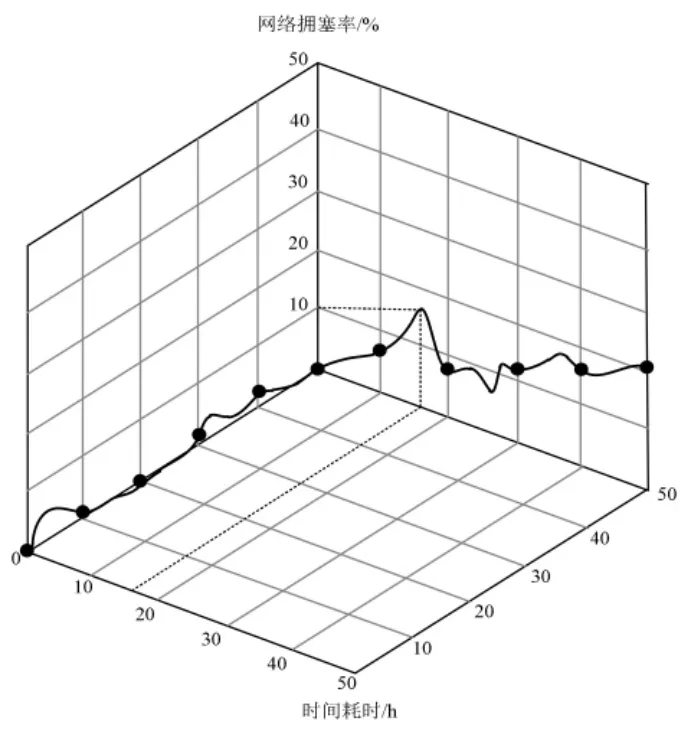
图4 所提方法平均时延结果
从图4 中可以看出, 所提方法拥塞率始终都保持在较低的水平, 可保证数据分流时具有较高的传输效率。这是由于所提方法对数据进行聚类划分,根据数据特性的不同将其划分到不同的聚类中心中, 结合最佳分流函数, 即可保证数据在分流过程中避免出现拥塞的情况。
3.2 3 种算法负载平衡效果对比
计算机负载平衡效果可以通过计算丢包率与网络数据流量得到。 3 种算法负载平衡效果如图5 所示。
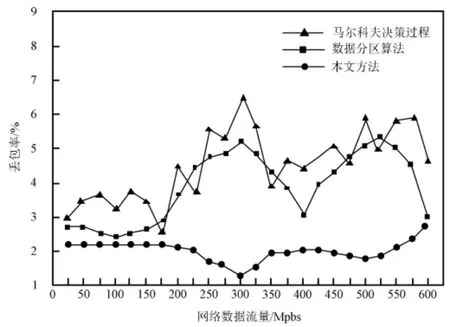
图5 3 种算法负载平衡效果对比结果
通过观察图5 可以很明显地看出: 在3 种算法中,本文方法的丢包率最低,且曲线整体波动较为平缓。 反观其他两种方法,丢包率相对较高,而且曲线波动幅度较大。
3.3 3 种算法分流效率对比
分流效率OEο就是分流得到的网络数据流量与数据总流量之间的比率,计算公式为
分流效率可以更加清晰地反映分流算法的性能优劣。 分流效率值越接近100%,算法的分流性能就越优秀。 3 种算法分流效率对比结果如图6 所示。

图6 3 种算法分流效率对比结果
从图6 中可以看出:随着网络数据流量的不断增加,3 种算法展现出了不同的分流效率; 本文方法取得的分流效率最接近100%,数据分区算法次之,马尔科夫决策过程最低。这是由于本文方法对网络数据进行特征提取后, 通过映射的方式建立了非线性数据分流模型,在一定程度上提高了算法的分流效率。
4 结论
传统算法在对网络数据分流时常常存在分流效率低、耗时长、负载不平衡等情况,基于此,本文提出了基于散列查找的分布式网络数据分流算法。对网络数据分流能耗计算后,对散列查找中“流”的局域性展开分析;建立网络数据分流的目标函数,通过求解计算后完成数据的特征提取;将数据特征区划分为不同的类型,通过计算数据特性误差方差完成数据分流。 仿真实验结果表明,本文方法取得了最佳负载平衡效果和较高分流效率。
猜你喜欢
预防青少年犯罪研究(2022年1期)2022-08-15
电子技术与软件工程(2019年21期)2020-01-16
电子制作(2018年19期)2018-11-14
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
电信科学(2017年6期)2017-07-01
自动化学报(2017年11期)2017-04-04
雷达与对抗(2015年3期)2015-12-09
肝胆胰外科杂志(2015年1期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
