
基于深度学习的动态环境视觉里程计研究
2023-12-30 14:26崔立志杨啸乾
空间控制技术与应用 2023年6期
崔立志, 杨啸乾*, 杨 艺
1. 河南理工大学电气工程与自动化学院, 焦作 454003 2. 河南省煤矿装备智能检测与控制重点实验室, 焦作 454003
0 引 言
同时定位与地图构建(simultaneous localization and mapping,SLAM)是指智能体在未知环境下,依靠传感器对周围进行感知和自我定位,并同时构建周围环境地图[1].视觉SLAM的主要传感器是相机,相机可以储存更加丰富的场景信息,并且具有价格低廉、体积小和易携带等优点,目前广泛应用于虚拟现实、无人驾驶和航空航天等领域[2].比如在航空航天领域中,利用视觉SLAM算法可以实时地对飞行器的位置和环境进行建模和估计,这对于无人机和其他航空航天器的自主导航和任务执行非常重要.
视觉里程计是视觉SLAM的核心前端,它利用相邻图像之间的差异分析来估计相机的运动位姿,并创建周围环境的局部地图[3].经过多年发展,在特定的场景已经非常成熟,一批经典的视觉SLAM系统,如ORB-SLAM2[4]、ORB-SLAM3[5]和大尺度单目SLAM系统(large scale direct monocular-SLAM,LSD-SLAM[6])等因此而产生.其中,MURARTAL等[4]提出基于特征点法的ORB-SLAM2系统,这是特征点法的代表,集成了单目、双目和RGB-D相机的综合SLAM系统,能够在大型的环境中实时运行,并且构建周围环境的稀疏点云地图.CAMPOS等[5]在ORB-SLAM2的基础上提出基于特征点法的ORB-SLAM3系统,增加惯性里程计、多地图融合等功能.ENGEL等[6]提出一种基于直接法的LSD-SLAM系统,它使用直接法来匹配图像中的像素,能够构建大尺度、全局一致的环境地图.然而,这些经典的视觉SLAM系统大多是基于静态环境的假设,当算法处于动态环境中时,相机的位姿估计可能受到动态物体的干扰,不稳定的特征点会使得相机出现特征丢失和轨迹漂移等现象,使得系统的稳定性[7]和鲁棒性受到影响.
为了解决这些问题,减少动态物体的干扰,国内外研究人员做了很大的努力.CHENG等[8]提出一种稀疏运动去除模式,根据连续帧之间相似性和差异来检测动态区域.TAN等[9]采用自适应的随机抽样一致(RANSAC)算法来区选图像中的动态点和静态点.LI等[10]通过选择深度图像的边缘点来寻找对应关系,并且设计了一种静态加权法来减轻动态点的影响.这些仅依赖几何约束的方法,更加适应低动态的场景,由于没有先验语义信息,在高动态场景中可能造成特征点识别过度或者识别不足.
近些年,随着深度学习的发展,越来越多的学者将几何约束和深度学习结合[11].BEASCOS等[12]提出DynaSLAM(tracking, mapping and inpainting in dynamic scenes SLAM)系统,它应用分割掩码区域卷积神经网络 (mask regions with CNN features, Mask R-CNN)逐像素地分割图像中的动态对象,并结合多视图几何来剔除动态特征点.YU等[13]提出DS-SLAM(a semantic visual SLAM towards dynamic environment)语义系统,与语义分割网络SegNet(segmentation network)结合,利用光流法进行运动一致性检测滤除动态特征点,同时构建语义八叉树地图.RDS-SLAM系统由LIU等[14]提出,该算法添加语义分割线程和基于语义的优化线程,并使用数据关联算法删除异常值.FAN等[15]提出Blitz-SLAM系统,使用BlitzNet掩码深度信息进行动态物体的检测,并应用极限约束技术对其进行分类.虽然结合深度学习方法可以更好地过滤动态点,提高系统的定位精度,但是SegNet、Mask R-CNN等分割网络比较耗时,不仅增加计算量而且实时性较差,很难应用到实际的生产工作中.
为了实现现有视觉SLAM系统在动态环境下的实时性,并且提高系统的定位精度和鲁棒性,本文主要有以下贡献:
1) 提出一种高效的轻量级目标检测网络,与ORB-SLAM3的前端视觉里程计结合,准确快速地检测潜在动态物体;
2) 将目标检测网络与运动一致性算法结合,用于判断并剔除动态点,仅使用静态点进行特征匹配和位姿估计;
3) 在TUM的RGB-D数据集上,将本文算法与其他系统算法进行对比测试,评估本文系统的相机位姿定位精度.
1 系统设计
传统的ORB-SLAM3[5]算法系统基于静态环境的假设,然而现实应用场景中,往往存在移动的物体从而造成特征点的误匹配.本文以ORB-SLAM3算法系统为基础,在其前端视觉里程计增加目标检测线程和运动一致性检测线程,使得网络在检测动态物体的同时减少动态特征点对视觉里程计的影响.
1.1 改进的ORB-SLAM3算法系统
自2015年以来,ORB-SLAM系列算法已成为特征点法中的经典代表.学者们基于ORB-SLAM[16],先后推出ORB-SLAM2和ORB-SLAM3算法,使得特征点法在SLAM系统方面达到新的高度.ORB-SLAM3采用3个并行线程,分别为跟踪、局部建图和回环检测.跟踪线程作为核心线程,实时处理相机图像帧序列来执行相机的姿态估计,其中局部建图线程的主要职责是建立局部地图并优化关键帧和局部地图的位姿,最终删除不必要的关键帧和地图点.回环检测线程则负责检测并闭合回路,以进一步提高SLAM系统的准确性.这3个线程相互协作,实现了高效的实时点云SLAM.
本文主要在其前端视觉里程计部分进行改进,如图1虚线所示,在跟踪线程增加目标检测线程和动态点剔除线程.
1.2 动态目标检测
为了准确地识别动态物体,同时满足SLAM系统在实际应用中实时性的要求,本文结合深度学习提出一种高效的轻量级目标检测网络,它可以对运动中的每一帧图像进行目标检测,整体框架如图2所示.

图2 目标检测网络结构Fig.2 Object detection network structure
1.2.1 目标检测网络YOLOv5s分析
YOLO(you only look once)是一种基于神经网络[17]的单阶段目标检测网络,它的基本概念是将目标检测任务转化为回归问题,通过使用单张图片作为神经网络的输入,仅仅经过一个神经网络,就能够得到目标边界框的位置和所属的类别信息[18].YOLOv5由Ultralytics公司于2020年5月提出,目前仍在迭代更新,根据网络大小的不同主要分为YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x 4个版本.
网络分为4个组成部分,包括输入部分(input)、主干网络(backbone)、颈部网络(neck)和推理部分(prediction).输入部分运用Mosaic数据增强、自适应锚框计算和自适应图像缩放等策略,以对输入数据进行预处理,增加小目标检测的准确性.主干网络结构主要由C3、Conv和SPPF模块组合而成,C3模块将输入的特征图分成2个部分,在依次完成操作后再加以组合,就可以完成丰富的梯度组合,在保证准确率的同时降低了计算成本,并且通过残差连接控制有无残差网络,默认为True值,表示有残差网络,否则为Flase值.空间金字塔池化(spatial pyramid pool-fast,SPPF)进行多尺度信息特征的融合,也大大增强了模型特征的提取能力.颈部网络采用路径聚合网络(path aggregation network,PANET)结构,增强了语义信息和定位信息.推理部分非极大值抑制(non-maximum suppression, NMS)对检测的目标框进行筛选.
本文选择YOLOv5s v6.0版本网络模型作为基础目标检测网络结构,与其他版本网络相比,YOLOv5s在准确度与速度之间取得平衡,虽然不是YOLOv5系列中最快的版本,但在广泛的硬件上,仍能提供实时目标检测能力.由于其较小的尺寸和较低的计算需求,YOLOv5s更容易部署在边缘设备和嵌入式系统上.可见YOLOv5s在速度、效率、模型大小和部署方面具有优势,非常满足SLAM系统的要求.
1.2.2 改进的C3Ghost模块
GhostNet[19]是华为诺亚方舟实验室提出的一种轻量级神经网络.Ghost模块是GhostNet网络的主要模块,它仅通过少量的计算就能生成大量的特征图,在保证网络精度的同时减少网络参数和计算量.首先利用较少的卷积核生成一部分特征图,接着对这部分特征图进行线性变换生成更多的特征图,最后拼接2组特征图形成GhostNet特征图.传统卷积和Ghost模块卷积过程如图3所示.
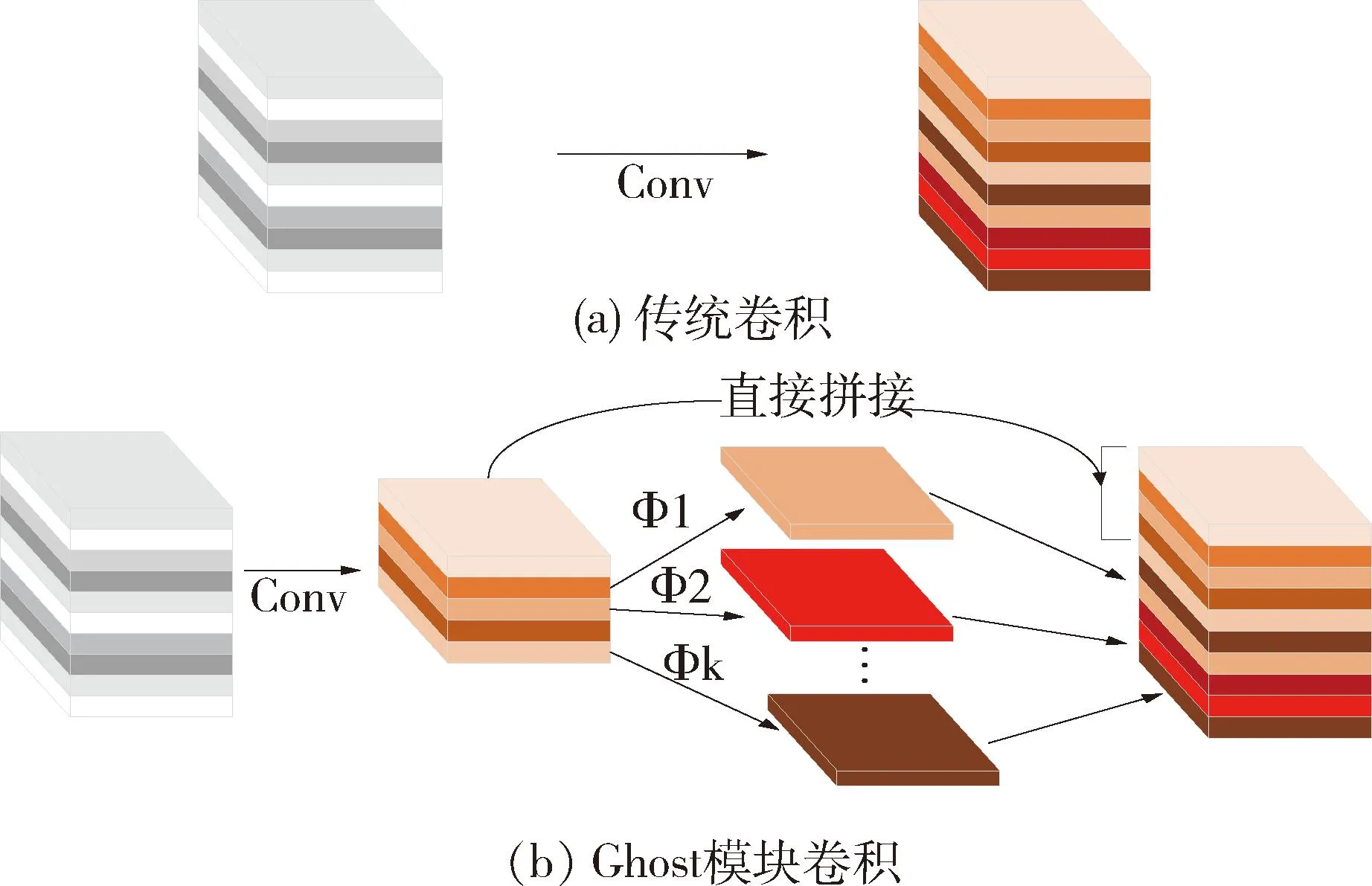
图3 传统卷积和Ghost卷积过程Fig.3 Traditional convolution and Ghost convolution process
假设输入的特征尺寸大小为h×w,通道数为c,输出的特征尺寸大小为h′×w′,卷积核大小为k×k,数量为n,则传统卷积的FLOPs数据量为n×h′×w′×c×k×k.
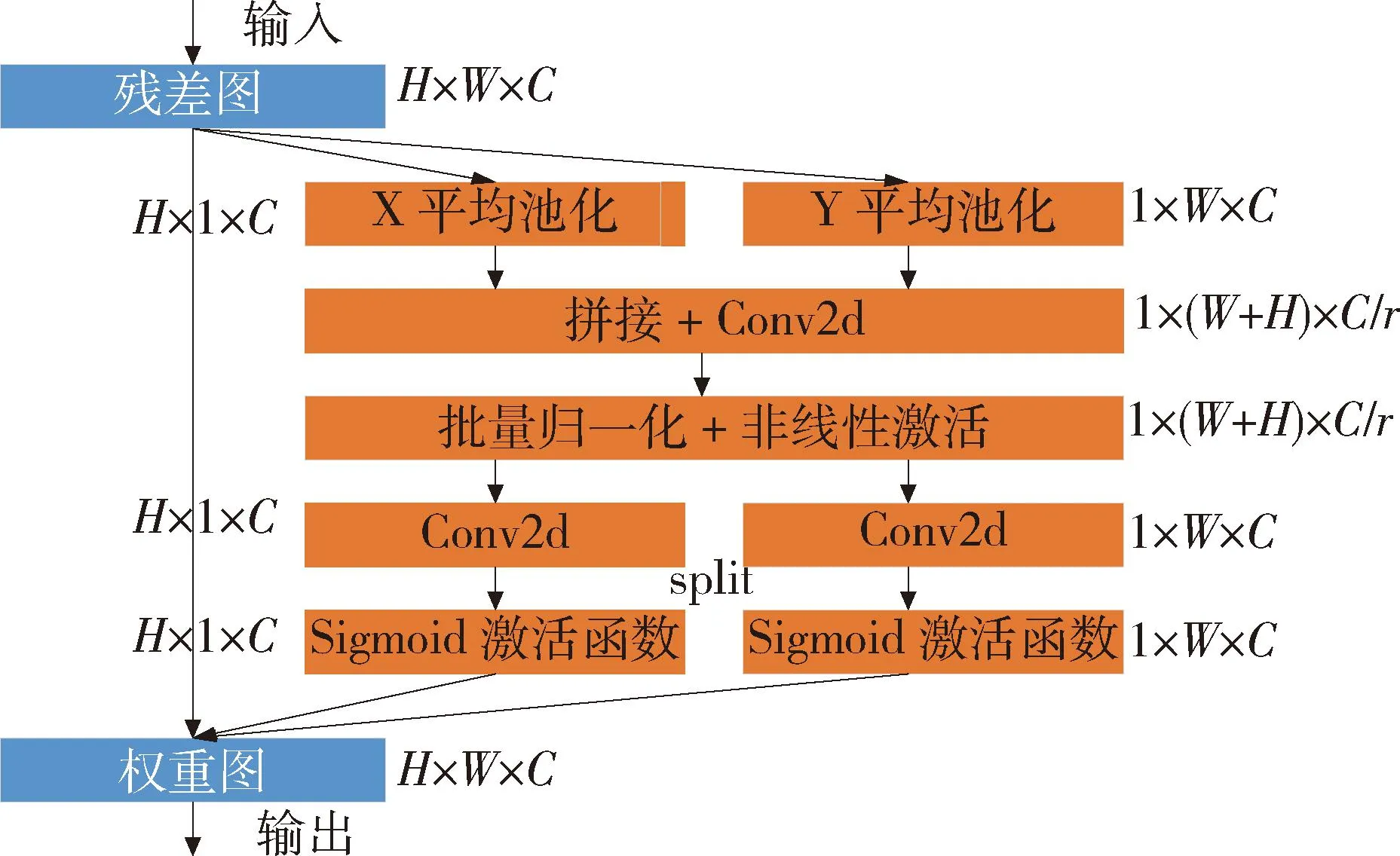
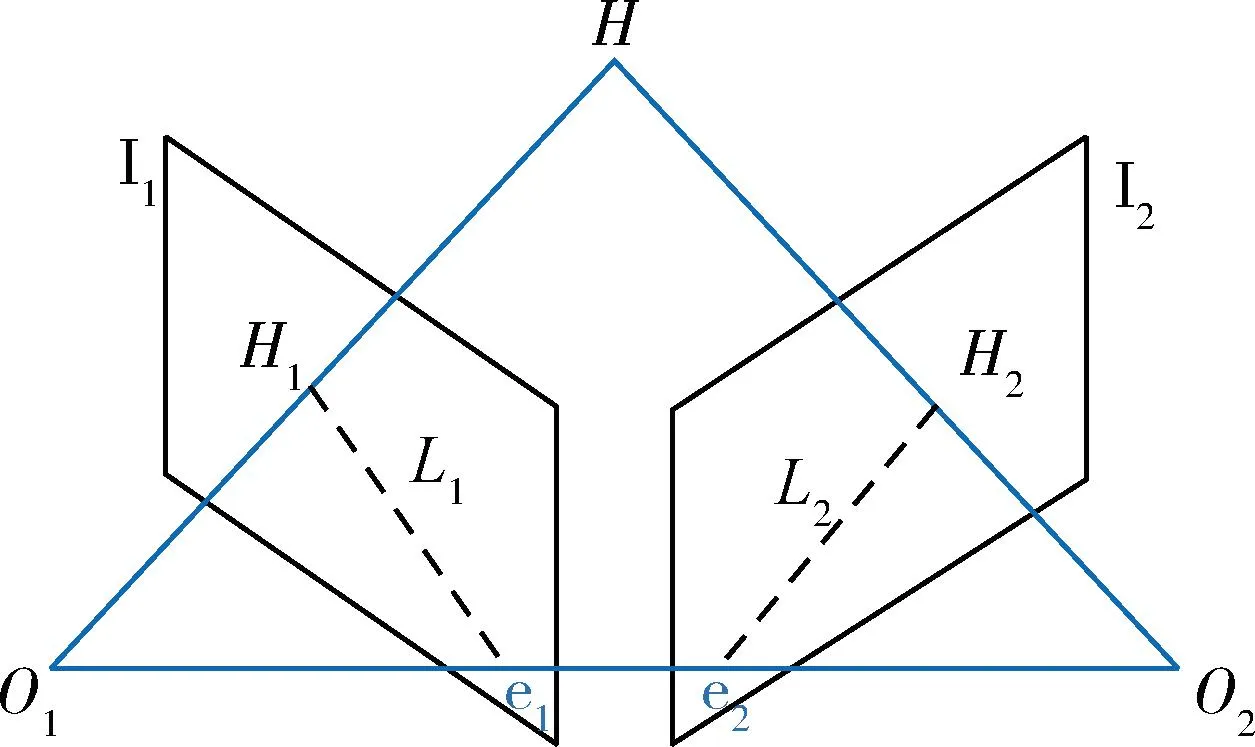
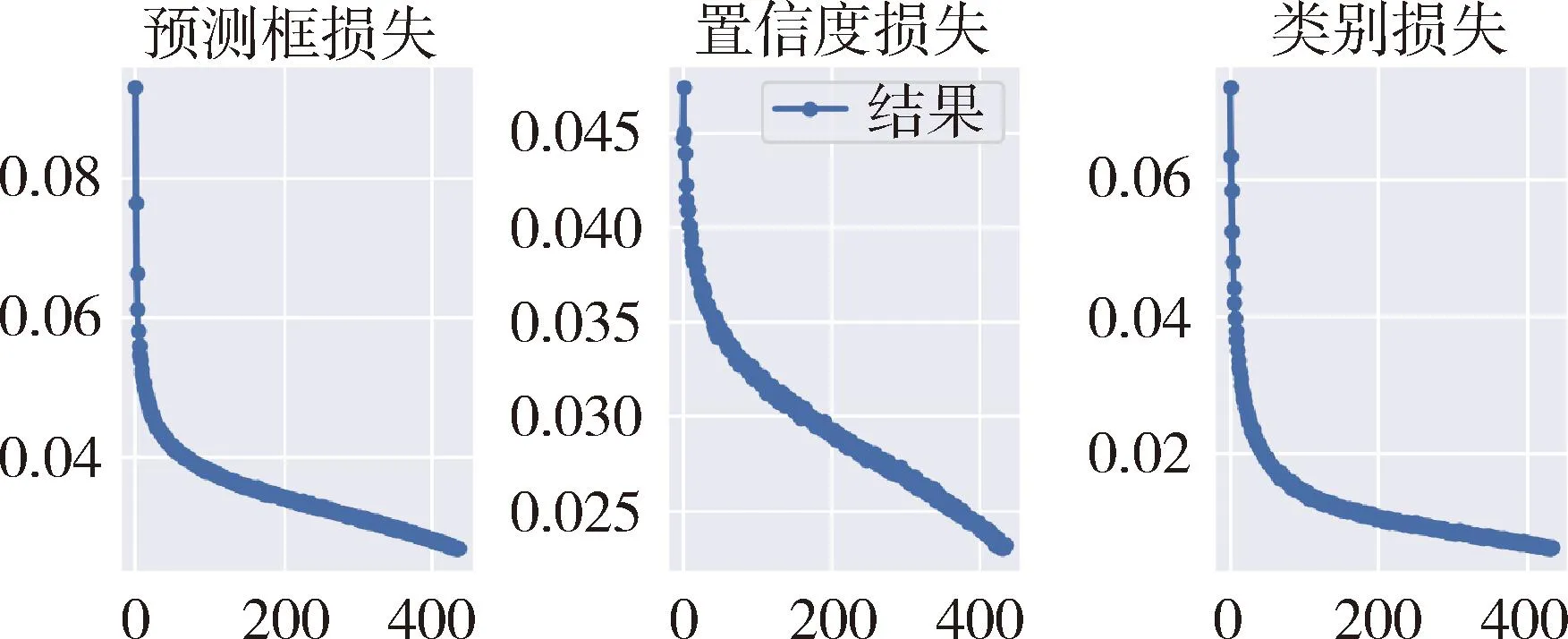
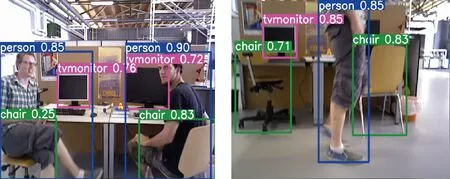
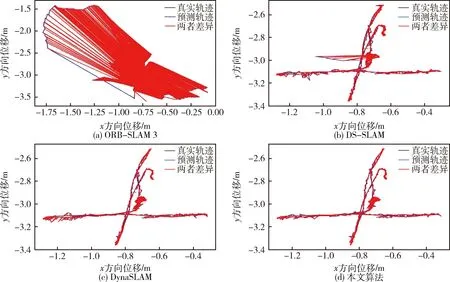
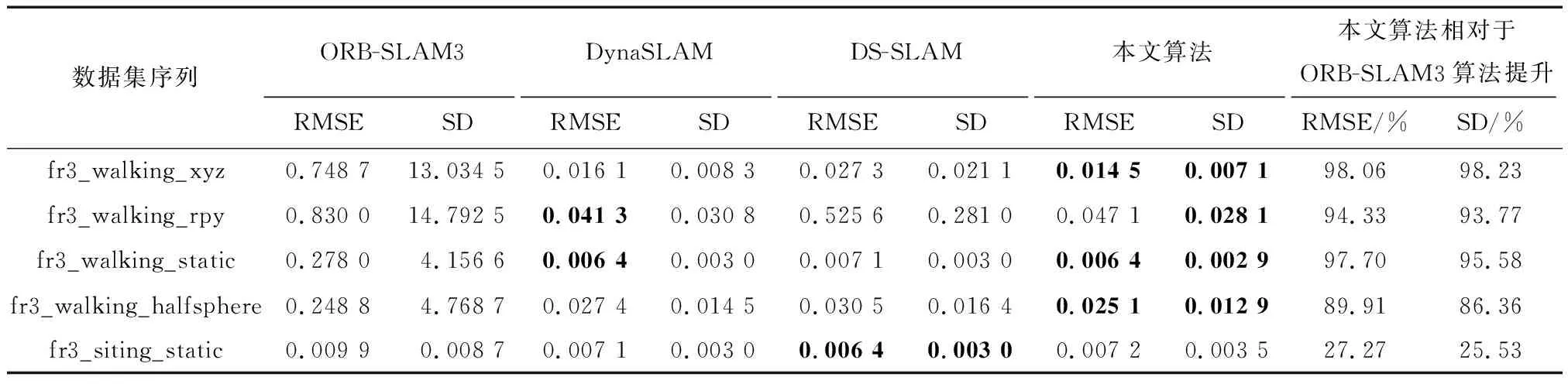
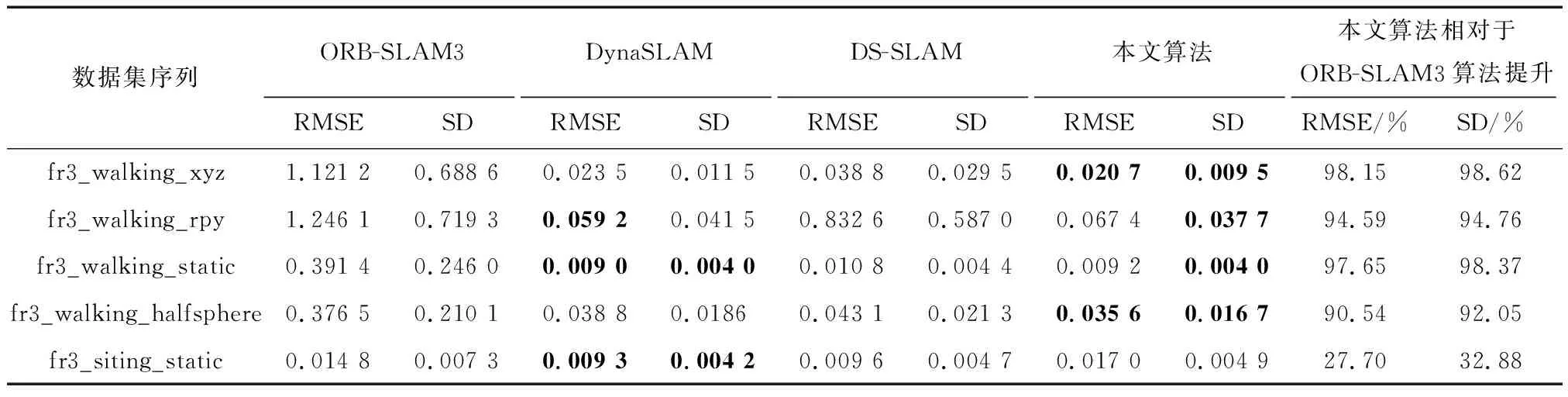
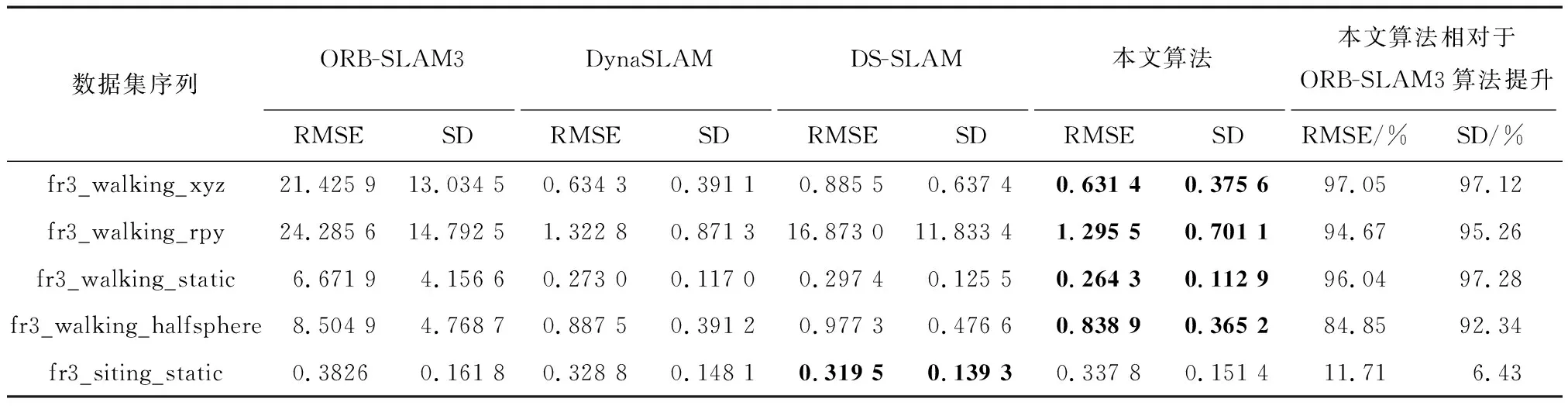
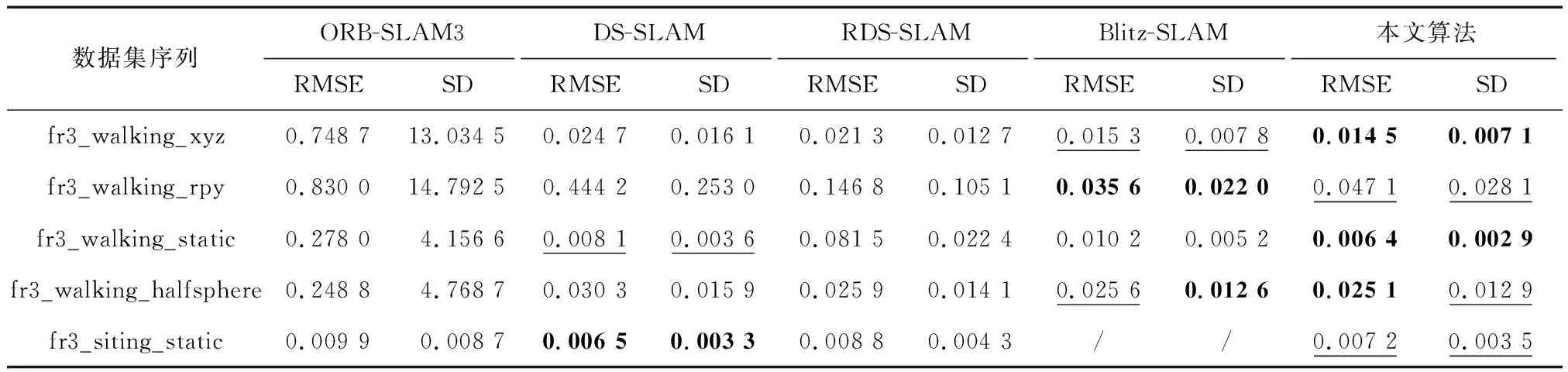
对于Ghost模块卷积,如图3(b)所示,第一部分进行普通卷积过程,假设生成m个特征图,其m Ghost模块卷积有一个直接拼接和s-1个Ghost特征图.比较传统卷积和Ghost模块卷积,公式如下: (1) 其中,分子表示传统卷积的复杂度,分母表示Ghost模块卷积的复杂度,s代表Ghost模块卷积第二部分每个通道产生的总映射,s远小于传统卷积通道数c,n/s指Ghost模块卷积第一部分普通卷积输出的直接特征图,d×d为线性操作卷积核大小,具有与k×k相似的大小,由式(1)可知,传统卷积的计算量约是Ghost模块卷积计算量的s倍,从而证明GhostNet网络的轻量化效力.为了满足SLAM系统的实时性要求,本文将GhostNet网络融入到YOLOv5s的C3模块,形成新的C3Ghost模块,如图4所示. GhostConv的第一个Conv采用了1×1卷积核,并使用步长为1将输入特征图的通道数减半.接下来,将特征图送入一个深度可分离卷积层,该层使用5×5卷积核进行处理,最后将2者拼接.GhostBottleneck利用第一个GhostConv对输入特征图的通道数进行降维,并利用第二个GhostConv将通道数恢复如初,随后使用3×3深度可分离卷积产生的残差边与恢复后的特征图相加,以实现特征融合.C3Ghost模块使用GhostBottleneck代替原来的Bottleneck,这样可以减少大部分3×3传统卷积的使用,从而压缩模型,减少计算量,并提高运行速度. 1.2.3 融合CA注意力机制 在人类的感知中,注意力扮演着至关重要的角色,帮助人们有针对地关注重要的事物并获取所感兴趣的信息.将这种注意力引入到机器学习中,就形成了注意力机制,可以显著提升模型的性能.常见的注意力机制有挤压和激励通道注意力模块(squeeze-and-excitation,SE[20])、卷积注意力模块(convolutional block attention module,CBAM[21])和高效通道注意力模块(efficient channel attention,ECA[22])等,然而像SE等一些通道注意力机制仅增强了通道信息而忽略了位置信息,本文研究的SLAM算法对定位要求较高,因此引入了CA[23]. 从图5可知,CA注意力模块为了准确编码图像位置信息并获得图像宽度和高度的注意力,将输入特征图分为宽度和高度2个方向分别进行全局平均池化,获得2个方向的特征图,这样可以捕捉到更精确的位置信息. 图5 CA注意力机制流程Fig.5 CA attention mechanism process 图6 运动一致性检测示意Fig.6 Motion consistency detection instructions 图7 损失函数可视化Fig.7 Loss function visualization 然后将以上2个输出的特征图进行拼接,接着进行1×1的卷积变换,将其维度降为原来的C/r,经过批量归一化处理获得特征图f,接着将特征图f按照原来的高度和宽度进行1×1的卷积,分别得到通道数与原来一样的特征图Fh和Fw,经过Sigmoid激活函数后,分别得到特征图在高度和宽度上的注意力权重gh和gw,最后通过乘法加权计算,将得到在高度和宽度方向上带有注意力权重的特征图. 以上可知CA注意力模块具有丰富的位置信息,并且可以提升目标检测的准确性,非常符合SLAM系统对定位的要求,本文将CA注意力模块融入到YOLOv5s网络的SPPF模块前,增强网络的特征提取能力. 通过目标检测网络可以有效区分运动物体,然而目标检测有一定的局限性,通常情况下,会在现实场景中看到人们短暂停留,电脑里的人像图片等等静止物体,这些物体的特征点会被误识别为动态特征点,所以需要进一步判定潜在运动的物体目标是否真正在运动,本文使用目标检测和运动一致性算法结合对动态特征点进行检测和剔除. I1和I2是连续的2帧图像,O1和O2分别对应相机的光心,2个光心的连线为基线,空间点H在I1和I2的投影点分别用H1和H2表示,此时H1和H2的归一化平面坐标P1和P2分别为P1=[u1,v1,1]、P2=[u2,v2,1],与基本矩阵F满足 P2FP1=0 (2) 特征点H1和H2与相机光心平面基线的交线L1和L2称为极线,在平面中用方程Ax+By+C=0表示,则点H1到极线L2的映射为 (3) 根据点H2与极线L2的关系,可以判断特征点的状态.当点H2不在极线L2上时,特征点可能为动态点,事实上,受到系统误匹配等因素的影响,特征点也可能为静态点,此时计算点H2到极线L2的距离 (4) 当距离D大于设定的阈值时,将这些特征点判定为动态点,并将其剔除. 为了验证本文算法的有效性,使用TUM RGB-D公共数据集中的动态场景数据进行测试.TUM[24]数据集由德国慕尼黑工业大学提供,是一个RGB-D数据集.该数据集是在真实环境中使用Kinect摄像头和多台高速摄像机拍摄而成的,包括彩色图像、深度图像和准确的真实位姿轨迹(ground truth)等内容.其中动态场景又分为低动态Sitting和高动态Walking 2类序列,这2类序列包含Halfsphere、Static、xyz和rpy 4 种不同的相机运动方式,分别表示为:相机沿着半球面移动、相机近似静止、相机沿着x、y和z轴方向运动以及相机做翻滚、俯仰等运动.本文实验使用高动态数据集fr3_walking_xyz、fr3_walking_rpy、fr3_walking_static和fr3_walking_halfsphere序列以及低动态数据集fr3_sitting_static序列. 所有实验在操作系统Ubuntu18.04下进行,其CPU为英特尔i7-8700k,显卡为NVIDIA GeForce GTX1080Ti.目标检测网络使用Python3.8编写,SLAM部分使用C++编写. 为了验证本文所提出的动态目标检测网络具有高效的检测性能,选择了包含人、汽车、椅子和沙发等20种不同物体的VOC-2007数据集进行训练[2].训练参数设置如下:训练周期为430,批处理量为16,训练时输入图像大小为640×640,进程数为8,初始学习率为0.01.训练可视化结果如图8所示,可见预测框损失、置信度损失和类别损失均在稳步下降. 图8 检测效果Fig.8 Detection effect 使用训练出来的最佳权重文件best.pt对fr3_walking_xyz数据集中的859张图片进行多次检测,检测效果如图8所示,摄像机仅拍到的下半身人像也可以准确地检测出来.并且与目标检测网络YOLOv5s在CPU上检测对比,如表1所示,参数量减少了48.1%,检测时间平均提升了21.7%. 表1 CPU实验检测Tab.1 CPU experimental detection 实验使用EVO(Python package for the evaluation of odometry and SLAM) 轨迹评估工具将数据集序列的估计轨迹与真实轨迹进行比较,以评估SLAM系统的性能.综合考虑算法的精度和轨迹的全局一致性,使用绝对轨迹误差(absolute trajectory error,ATE)和相对位姿误差(relative pose error,RPE)这2个评价指标.ATE是指算法估计位姿和真实位姿之间的直接差值,可提供直观的精度评估,反应算法精度和轨迹全局一致性.RPE则表示相机在平移和旋转方向上的相对误差,主要描述的是与真实位姿相比,相隔固定时间差2帧位姿差的精度,相当于直接测量里程计的误差.针对每个指标,进行统计分析,采用均方根误差(RMSE)、平均误差(mean)、中值误差(median)和标准偏差(standard deviation,SD)这4个参数.其中RMSE描述估计值和真实值的偏差,易受到较大或偶发错误的影响,因此能更好地反映系统的鲁棒性,SD评价估计轨迹相较于真实轨迹的离散程度,能够反映系统的稳定性.误差的改进值由式(5)计算 (5) 其中,η为改进值,ηos3为ORB-SLAM3运行结果,ηour为本文方法运行结果. 首先将本文算法和传统的ORB-SLAM3[5]算法以及同类型的DynaSLAM[12]算法和DS-SLAM[13]算法做定量分析,图9表示在高动态数据集fr3_walking_xyz序列下的不同算法绝对轨迹误差结果,其中黑色表示相机真实轨迹,蓝色表示算法估计轨迹,红色表示2者的差异.由图9可知,与传统的ORB-SLAM3算法相比,本文算法的估计轨迹与相机真实轨迹更加一致,具有更好的鲁棒性;对比同类型算法,本文算法也是明显优于DS-SLAM算法的,与DynaSLAM算法轨迹几乎一致. 图9 不同算法绝对轨迹误差结果Fig.9 Absolute trajectory error results of different algorithm 然后在高动态数据集序列和低动态数据集fr3_sitting_static序列上进行定量测试,表2~4分别表示绝对轨迹误差、相对平移误差和相对旋转误差的典型值数据对比以及本文算法与ORB-SLAM3[5]算法对比性能提升的百分比.所有数据均为测试所得,其中黑色表示最优结果. 表2 绝对轨迹误差典型值Tab.2 Typical value of absolute trajectory error 表3 相对平移误差典型值Tab.3 Typical value of relative translational error 表4 相对旋转误差典型值Tab.4 Typical value of relative rotational error 由表2~4可知,在高动态数据集序列上,与传统的ORB-SLAM3[5]算法相比,本文方法在ATE和RPE的典型误差提升率平均可达90%以上,表明本文方法能够显著提高动态场景SLAM系统的鲁棒性和稳定性,特别是在高动态数据集fr3_walking_xyz序列上,在ATE的RMSE和SD的提升率上,分别可达到98.06%和98.23%,同样在RPE上相对平移误差和相对旋转误差的提升率也可达到98%左右,有力地证明了本文方法的有效性,提升了SLAM系统的定位精度.传统的ORB-SLAM3系统对低动态的场景有着非常优异的性能表现,即便如此,在低动态的fr3_sitting_static序列上,本文方法在ATE和RPE的表现也是优于前者的.在高动态数据集序列与同类型的算法相比,本文算法全面优于DS-SLAM[13]算法,与DynaSLAM[12]算法的各项指标相差非常小,可以认为性能相当,但本文方法整体略优于DynaSLAM算法. 为了进一步验证本文改进的视觉里程计方法的有效性,将本文方法与DS-SLAM[13]算法、RDS-SLAM[14](real-time dynamic SLAM using semantic segmentation methods)算法和Blitz-SLAM[15]算法进行ATE定量对比分析,数据来源于文献,其中“/”表示原文献没有提供相关数据,加粗字体为最佳结果,次佳结果用下划线示意.由表5可知,算法的最佳和次佳结果主要来自本文算法和使用语义分割的Blitz-SLAM算法,明显优于DS-SLAM和RDS-SLAM算法,并与Blitz-SLAM算法的ATE指标相差非常小,可以认为性能一致,但本文方法采用目标检测的实时性比其结合分割方法更好,可见本文算法有较好的效果. 表5 不同算法绝对轨迹误差典型值Tab.5 Typical values of absolute trajectory error for different algorithms 本文提出一种基于深度学习的动态环境视觉里程计算法,在传统的ORB-SLAM3系统的基础上,引入高效的轻量目标检测网络,使用轻量级Ghost模块和高效的坐标注意力机制CA模块与目标检测网络YOLOv5s结合,在提升网络检测速度的同时保证检测的准确性,获取更多的语义先验信息,并结合运动一致性检测算法,确定场景中动态目标,剔除动态特征点,仅使用静态特征点进行位姿估计.在TUM数据集实验结果表明,相较于传统的ORB-SLAM3算法系统,本文算法在高动态场景ATE和RPE方面的提升率平均可达90%以上,相比于同类型的算法,本文算法也有相对提升并且实时性更好,表明本文算法能够有效地提高视觉SLAM系统在动态环境下的稳定性和鲁棒性.后续的工作将对本文网络进行模型压缩,移植到智能体上,并且搭建具有丰富场景信息的八叉树地图,以便智能体完成导航、路径规划等更加复杂的任务.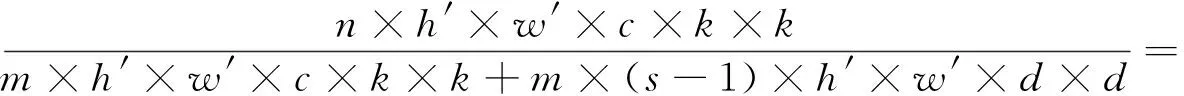
1.3 动态点运动一致性检测
2 实验与分析
2.1 目标检测实验效果

2.2 相机位姿估计误差实验分析
3 结 论
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
环球慈善(2019年6期)2019-09-25
电子制作(2019年11期)2019-07-04
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2018年1期)2018-04-20
