
基于全局注意力机制的单像素成像图像增强方法
2023-12-30 15:16杨照华赵梓栋余远金
空间控制技术与应用 2023年6期
刘 辉, 杨照华, 吴 云, 赵梓栋, 余远金
1. 北京航空航天大学,北京 100191 2. 北京控制工程研究所,北京 100094 3. 北京理工大学,北京 100081
0 引 言
单像素成像已经成为了量子光学领域的前沿技术,在光谱成像、光学加密、3D成像、目标跟踪和空间探测领域上极具潜力[1-5].单像素成像的原理是利用空间光调制器调制散斑照射到物体上,同时使用桶探测器记录物体反射的总光强值,通过关联算法完成图像重构.单像素成像与计算鬼成像的区别在于成像目标和空间光调制器在光路中的先后顺序,在很多论文中,由于成像原理与方法基本一致,所以不再区分单像素成像与鬼成像,本论文也是如此.为了提高重构的图像质量,在低采样率时,俞文凯等[6]提出一种切蛋糕(cake-cutting,CC)序方法对空间光调制器生成的哈达玛散斑进行排序,确保重构出的图像无重叠的阴影部分.为了克服光学设备不稳定带来的光强涨落的影响,FERRI等[7]提出使用差分鬼成像的方法利用散斑和桶探测器值对图像进行重构,提高了图像的重构质量.尽管使用上述方法对重构图像进行了初步增强,恢复出来的图像质量仍然不佳.
为了进一步提高图像的质量,很多研究人员提出使用深度学习的方法进行图像增强.LECUN等[8]提出LeNet神经网络,首次将卷积神经网络使用在图像分类上.KRIZHEVSKY等[9]提出AlexNet神经网络,由于其优异的性能,使卷积神经网络成为了图像处理领域的主流算法.为了将卷积神经网络应用到单像素成像处理中,WANG等[10]将单像素成像过程中生成的桶探测器序列值输入到卷积神经网络中,实现了更高质量的图像重构,该方法在训练集上取得了很好的效果,但在测试集上表现欠佳,问题在于网络模型过拟合.RIZVI等[11]提出一种基于自编码器网络的重构方案,该方法先使用CGI(computation ghost imaging)算法恢复出低质量的图像,然后使用编码器将CGI算法恢复的图像先编码成隐层信息,再根据隐层信息解码出原始图像,编码器与解码器的网络架构解决了模型过拟合的问题,但缺点是图像重构的效果取决于隐层信息的表达,限制了模型的图像增强性能.KARIM等[12]提出使用生成对抗网络对单像素成像的图像做后处理,此模型的骨干网络仍然是卷积神经网络,模型的性能受限于感受野的大小.
DEL等[13]提出Transformer神经网络模型,在自然语言处理(natural language processing, NLP)领域取得了优异的成绩.受此启发,计算机视觉(computer vision,CV)领域的科研工作者们提出了ViT(vision transformer)模型[14]和ST(swin transformer)模型[15],解决了传统卷积神经网络的平移不变性和无法获得全局感受野的问题.LIU等[16]提出了SUNet(swin transformer UNet),它是一个神经网络降噪模型,基于UNet架构,使用ST提取图像的特征;使用块合并层(patch merging)去除冗余的图像特征,使用块扩展层(patch expanding)方法恢复图像的细节信息.SUNet模型采用滑动窗口注意力机制获得全局的感受野,可进一步提升模型的图像去噪能力.本文将SUNet网络引入到单像素成像领域中,采用STL-10图片数据集,根据CC序对哈达玛散斑排序,使用差分鬼成像算法得到重构图像,确保重构图像具有较高的质量,最后将该图像送入神经网络模型中训练,并在测试集上取得了较好的结果.
1 单像素成像原理
1.1 单像素成像图像增强算法

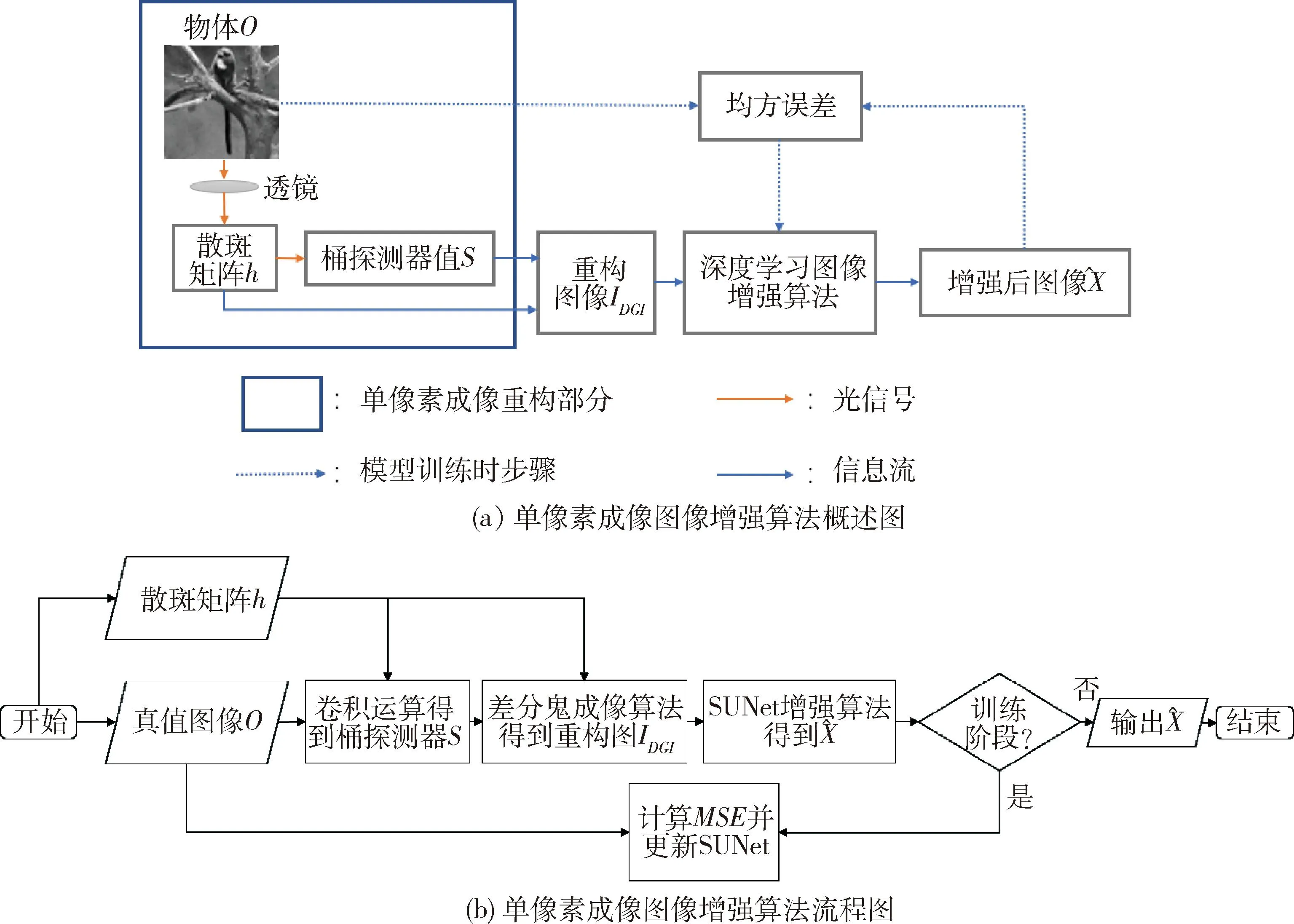
图1 单像素成像图像增强算法原理图Fig.1 Schematic diagram of single-pixel imaging image enhancement algorithm
1.2 单像素成像流程
单像素成像包括光场调制、探测与重构2部分.单像素成像的成像原理如图2所示,光线从光源发出经物体O反射到数字微镜阵列(digital micromirror device,DMD)上,DMD预先加载的掩膜矩阵序列h会对入射光场进行空间光场调制,最终由桶探测器接收与掩膜矩阵序列一一对应的总光强序列值.第m次桶探测器探测的总光强值Sm可表示为

图2 单像素成像原理图Fig.2 Schematic of single-pixel imaging
(1)
n=Nβ
(2)
N=pq
(3)
式(1)中,h(x,y)表示掩膜矩阵(h∈Rp×q),O(x,y)表示真值图像(O∈Rp×q),m=1,2,3,…,n,m为掩膜矩阵的序号,(x,y)为图像坐标;式(2)中,n为采样次数,β为采样率;式(3)中,N是掩膜矩阵p行与q列的乘积,p、q为掩膜矩阵的维度,也为重构图像的像素数,本文中p=q=64.
1.3 基于哈达玛基的光场优化调制
在常见的单像素成像中,通常使用哈达玛矩阵来构建掩膜矩阵序列,但使用自然序列的哈达玛散斑在低采样率下重建图像会导致重构后的图像出现重影,图像的质量偏低.为了初步提高重构图像的质量,可以结合排序方法如CC序、折纸序等序列进行图像重构,本文根据空间探测实时性要求高和硬件资源有限的特点,选择构造简单且易于实现哈达玛基的CC序进行光场优化调制.
根据式(4)生成自然序列的哈达玛矩阵
(4)
式中,⊗表示克罗内克积.将原始哈达玛矩阵H∈RN×N的每一行重塑成p行q列的二维掩膜矩阵,共计N个掩膜矩阵(使用h表示,每个h由H中的某一行变换得到),然后计算每个掩膜矩阵中连通域(图像中联通像素的集合)的个数,根据连通域的个数给这N个掩膜矩阵从小到大排序,再根据采样率从前向后选取掩膜矩阵.哈达玛散斑排序原理如图3所示,图3(a)为16×16的原始哈达玛散斑H,图3(b)上方为原始序列哈达玛散斑生成的掩膜矩阵,下方为经过CC序后生成的掩膜矩阵.

图3 16×16哈达玛散斑CC序图Fig.3 16×16 Hadamard speckle CC sorting map
1.4 基于差分鬼成像的图像重构
在单像素成像的图像重构过程中,通常使用二阶关联算法重构图像.在空间探测应用中,由于光源功率的波动或光学探测器的不稳定性会对探测的总光场强度产生波动,为此,本文选用差分鬼成像算法如下:
(5)
式中,IDGI是重构出来的图像,〈·〉表示对任意函数求系综平均,r是参考光路的总光强值,S是物体光路的总光强值.
差分鬼成像重构结果如图4所示,图像大小为64×64,(a)为原始图像,(b)为自然序列哈达玛散斑的差分鬼成像重构图,(c)为CC序后哈达玛散斑的重构图.对比图4可知,差分鬼成像使用CC序后可以消除自然序列哈达玛散斑的重影问题,进而提升图像的质量.

图4 基于CC序的差分鬼成像实验结果图Fig.4 Differential ghost imaging experiment results based on CC sorting
2 基于SUNet的图像增强
SUNet的增强过程如图5所示.包括浅层特征提取、编码器、解码器和重建模块4部分,该模型包含10张特征图,使用标号①、②、③、…、⑩表示,每张特征图的分辨率大小如图5(b)所示.SUNet的主体为编码器和解码器,针对图4(c)进行图像增强.在编码器部分,先对该图经过一个3×3的卷积操作得到特征图,再经过ST模块提取特征和块合并层下采样后得到特征向量.在解码器部分,特征向量经过ST模块恢复特征和块扩展层上采样恢复到原始分辨率的图像,再使用一个3×3的卷积操作得到增强后的图像.在编码器和解码器网络中,如果特征图的分辨率相同,使用跨层连接可以获得图像的深层信息和浅层信息,增强模型的特征表达能力.最后计算增强后的图像与原始图像的均方误差,并反向传播梯度更新网络参数,数据集迭代200次后结束训练过程.
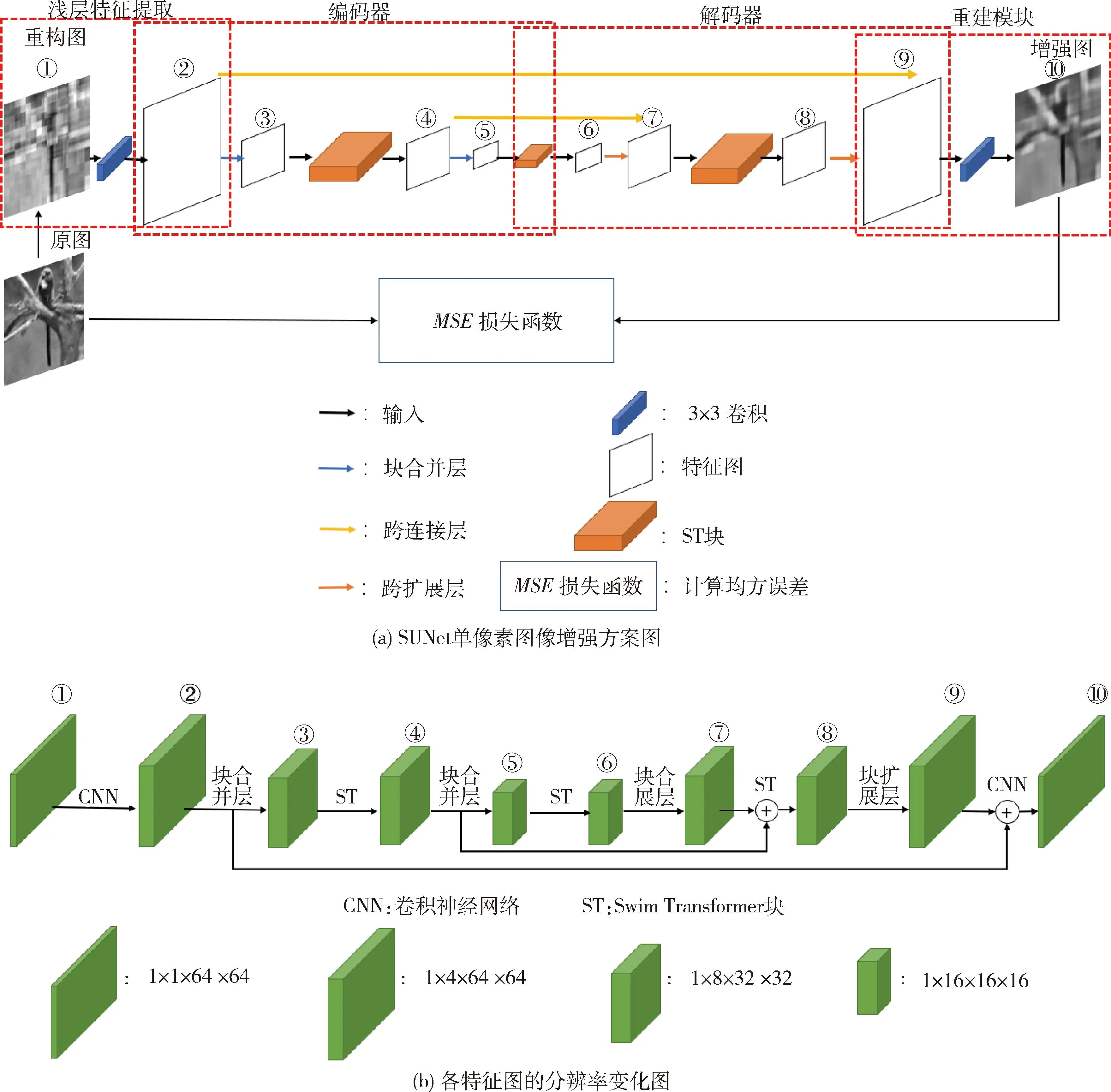
图5 SUNet单像素图像增强方案图Fig.5 SUNet single-pixel image enhancement scheme
2.1 SUNet建模
SUNet的架构基于图像分割模型,在此架构中应用了双上采样模块来避免棋盘伪影,并且SUNet中自注意力操作无法共享内核权重,不同层中的特征使用了不同的内核值,所以相较于传统的CNN架构在图像增强中更为合理.
SUNet由3个模块组成:
(1)浅层特征提取模块
此模块位于图5(a)中浅层特征提取部分,由特征图①、②组成.浅层特征提取是SUNet中的第一个模块,用于获取输入图像的低频信息,如颜色或纹理.在本文中,输入是重构图像IDGI(IDGI∈R1×1×64×64),64×64是重构图像的分辨率,使用3×3的卷积层MSFE(·)提取图像的低频信息,如下:
Fshallow=MSFE(IDGI)
(6)
式中,Fshallow(Fshallow∈R1×4×64×64)表示图像的浅层特征.
(2)UNet特征提取模块
此模块由图5(a)中编码器和解码器共同组成,包含特征图②、③、…、⑨.UNet特征提取浅层特征Fshallow被输入到UNet特征提取模块MUFE(·)中提取高级别和多尺寸的深层特征,如下:
Fdeep=MUFE(Fshallow)
(7)
式中,Fdeep(Fdeep∈R1×4×64×64)是提取出的高级别和多尺寸的深层特征.
(3)重建模块
此模块位于图5中重建模块的红色矩形框,由特征图⑨、⑩组成.重建模块负责从深层特征中恢复图像,利用一个3×3的卷积层MR(·)来实现,输入是UNet特征提取部分获得的深层特征,如下:
(8)

2.2 编码器
编码器由ST模块和块合并层组成.ST模块将输入图像分成大小相同且互不重叠的块,以块为最小单位,再将块聚合在一起形成窗口,分别在窗口内和窗口间进行注意力计算,使每个像素点都能获得全局的感受野.块合并层负责进行下采样操作,原理图如图6所示.块合并层将图像全部分成分辨率为2×2的块,并在第三个维度中拼接,以此实现下采样的功能,最后经过3×3的卷积层进行特征降维.

图6 编码器的块合并层操作原理Fig.6 Operating principle of patch merge layer
2.3 编码器
解码器由ST模块和块扩展层组成,负责特征恢复和上采样.ST模块的原理与解码器相同.解码器的块扩展层原理如图7所示,它的目的是将图像分辨率恢复到原始分辨率大小,每个块扩展层可以扩充图像至×2分辨率.上采样由2部分组成:1)直接通过转置卷积得到×2的特征图;2)使用3×3的卷积层将图像特征扩充为初始的4倍,然后将这些特征在二维平面展开,实现×2的特征图.将这2部分得到的×2的特征图在特征维度拼接后送入3×3的卷积层后得到特征降维后的图像.

图7 解码器的块扩展层操作原理Fig.7 Operating principle of patch expanding layer
3 实验结果与分析
3.1 数据集
本文使用STL-10数据集,训练集有105 000张图片,验证集有8 000张图片,从验证集中选出少量的图片做测试集.图像的原始分辨率是96×96,通过双线性插值将分辨率变为64×64.STL-10数据集一共有10个大类:飞机、鸟、汽车、猫、鹿、狗、马、猴子、船和卡车,类别较多,有助于提高神经网络模型的泛化性能.
3.2 模型评估指标
本文中采样的评估标准为峰值信噪比(peak signal-to-noise ratio, PSNR)和结构相似度(structural similarity index measure, SSIM).2种指标的值越大,表明模型的恢复效果越好.MSE指标表示真值图像与恢复图像的均方误差,PSNR计算公式如下:
(9)
(10)
(11)

3.3 图像增强实验
为验证设计的算法有效性,在 Linux操作系统上,基于Python 环境下Pytorch深度学习工具包实现算法的仿真实验,仿真计算机配置为Intel Core i7@4.00 GHz 处理器、16 G内存和2块Nvidia GeForce Titan Xp显卡.
本实验采用基于SUNet模型的图像增强网络对单像素成像的图像进行增强,此方法不需要物体的空间信息,更适合提高在外太空非合作目标超远距离成像的图像质量.实验使用STL-10数据集,模型的输入图像大小为64×64.采样率从0.05到0.5,步长为0.05,模型训练次数为200次.初始学习率为0.000 2,使用Adam优化器自适应调整学习率[17],损失函数选择均方误差.训练方式使用Pytorch的分布式训练,可极大地提高模型的训练速度,每个采样率模型训练时间为25 h.
限于篇幅,图8给出了采样率为0.3时,模型训练的次数与PSNR和SSIM的曲线.由于神经网络参数量巨大,在模型训练初期,大部分参数的梯度下降方向不准确,所以模型的效果会出现突然下降又迅速回升的情况.到了模型训练后期,大部分参数都已经收敛到了次优值,训练的参数调节幅度小,所以曲线会变平滑.
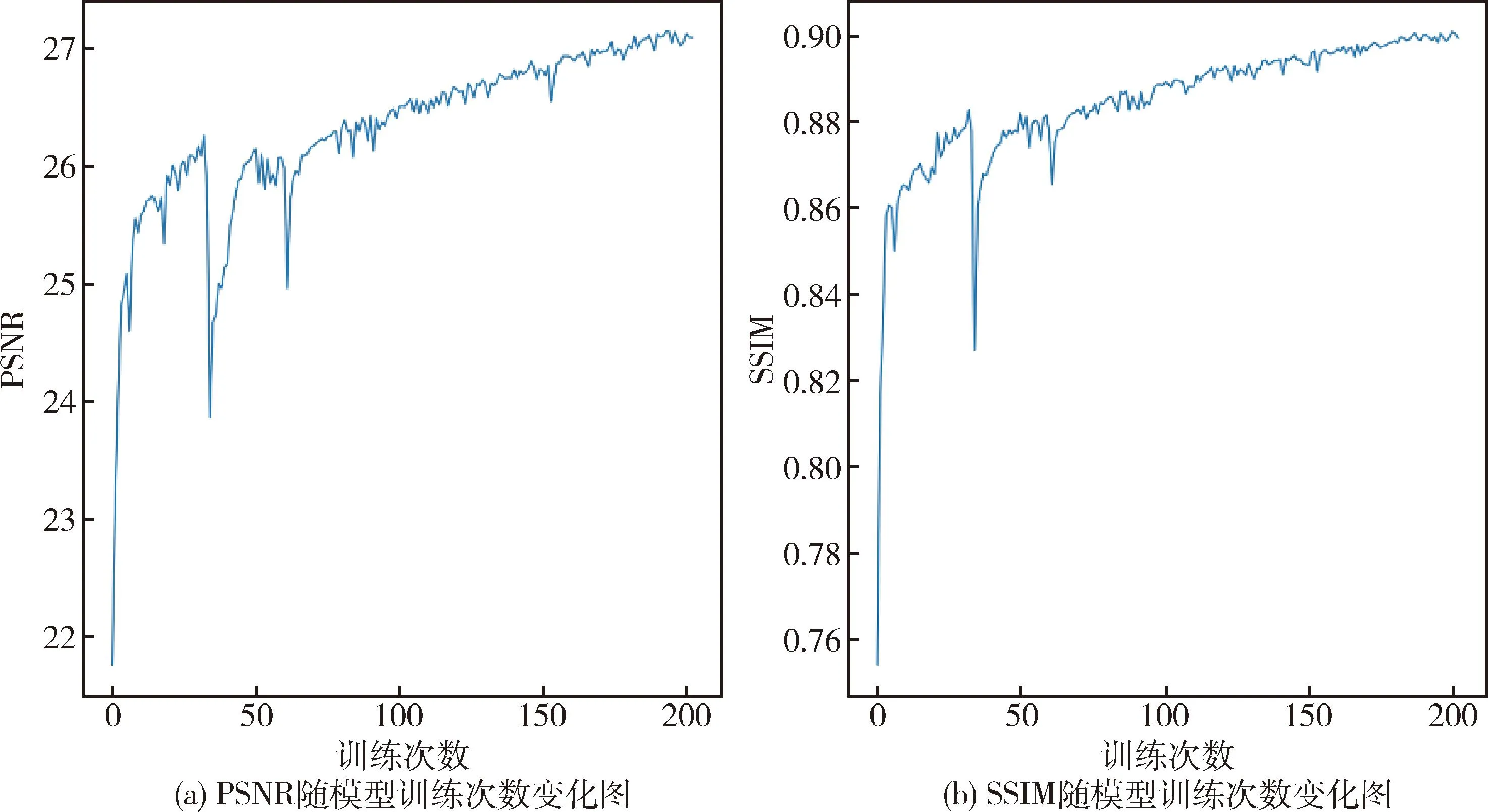
图8 采样率为0.3时,模型PSNR与SSIM训练结果图Fig.8 At the sampling rate of 0.3, PSNR and SSIM vary with model training times
同时,ST使用滑动窗口注意力机制,相对于ViT大大减少了模型的参数量,便于模型训练和误差收敛,完成密集型的像素预测.表1给出了不同采样率下不同模型在测试集上得到的PSNR.表2展示了不同采样率下不同模型在测试集上得到的SSIM.对比模型分别为2010年提出的DGI(differential ghost imaging)模型[18]、2014年提出的稀疏(Sparse)模型[19]、2018年提出的AP(alternating projection)模型[20]、2022年提出的GIDC(ghost imaging using deep neural network constraint)模型[21]和本文提出的SUNet模型.图9为不同采样率下的PSNR曲线与SSIM曲线.本文提出的SUNet与2022年提出的GIDC方法相比,在0.1的采样率下,峰值信噪比从20.05 dB提生到23.34 dB,提升了3.29 dB;结构相似度从0.63提升到了0.71,提升了8%.

表1 不同采样率下各模型的PSNR值对比Tab.1 Comparison of PSNR of different models under different sampling rates
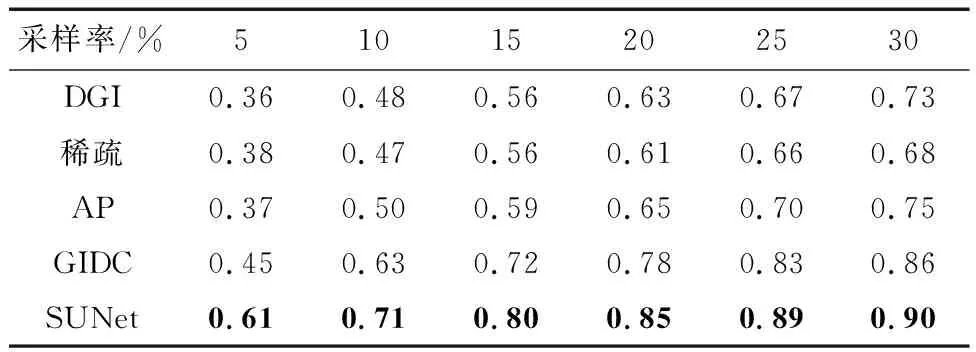
表2 不同采样率下,各模型的SSIM值对比Tab.2 Comparison of SSIM of different models under different sampling rates
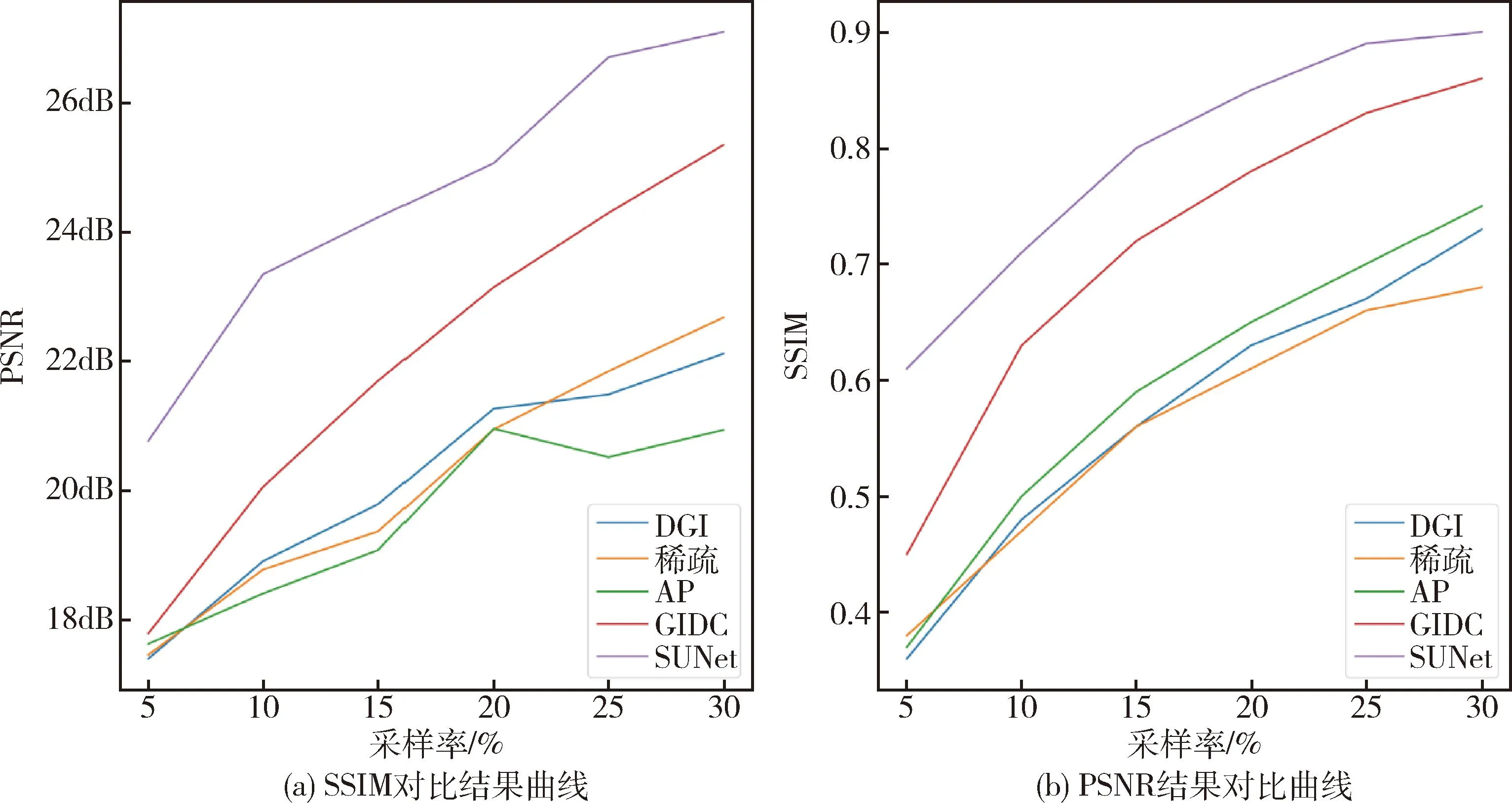
图9 低采样率下性能指标折线图Fig.9 Performance metrics line chart under low sampling rates
本文选择部分测试集的图像通过不同的深度学习方法对图像进行增强,如图10所示.最左边的一列图像表示原始图像.其余各列分别为DGI、AP、稀疏、GIDC模型和本文提出的SUNet模型在25%采样率下增强后的图像,其性能指标PSNR和SSIM显示在图像下方.本文提出的SUNet方法恢复的图像质量最佳,通过CC序后的哈达玛散斑与桶探测器值使用差分鬼成像算法恢复出低质量的图像,然后使用深度学习方法对图像进行增强,并使用均方误差反向传播梯度更新模型的参数,最后在测试集中采样评估模型的性能.与GIDC方法相比,在0.1的采样率下,峰值信噪比提升了3.29dB,结构相似度提升了8%,表明ST的性能优于传统CNN,全局感受野可以有效提高图像增强的质量,实现低采样率条件下较好的图像增强.
4 结 论
本文为了应对空间非局域目标探测问题,降低采样率,提高成像速度,采用基于全局注意力机制的SUNet模型,在低采样率下实现单像素成像图像增强.提出的方法在单像素成像图像恢复领域取得了较好的效果,证明ST的全局注意力机制相对于传统的卷积神经网络能够进一步提高增强后图像的质量.最后,与其他基于深度学习的方法相比,本文的方法对测试集中的图像能表现出更好的图像增强性能,更适用于空间非合作目标在低采样率下的图像感知与识别.最后,SUNet还可以扩展到超分辨图像恢复领域,有望实现单像素成像的超分辨图像重构.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
音乐教育与创作(2022年6期)2022-10-11
中国体视学与图像分析(2021年3期)2021-11-24
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
民族音乐(2019年3期)2019-08-14
中国生物医学工程学报(2019年5期)2019-07-16
制造技术与机床(2017年10期)2017-11-28
北京航空航天大学学报(2017年3期)2017-11-23
草原歌声(2017年4期)2017-04-28
