
基于光谱—空间注意力双边网络的高光谱图像分类
2024-01-01 13:32杨星池越周亚同王杨
遥感学报 2023年11期
杨星,池越,周亚同,王杨
河北工业大学 电子与信息工程学院,天津 300401
1 引言
随着遥感技术的快速发展,高光谱成像技术图像同时具有丰富光谱信息和详细的空间结构,高光谱图像每个像素包含数百个连续光谱带,其波长范围跨越可见光和红外波段。相较于其他遥感图像,高光谱图像HSI(Hyper Spectral Image)由于其丰富的信息量,对于目标物理、化学等特性有更好的表征能力(Li 等,2016),高光谱图像被广泛应用于环境管理(Chen 等,2019)、农业和资源管理(Murphy等,2018)、城市开发(Ghamisi等,2015)、海洋观测(曹引 等,2019)、军事(Shimoni 等,2019)等多种领域。高光谱图像分类HSIC(Hyper Spectral Image Classification)是HSI 处理与应用中最为基础也是最为重要的一环,为遥感数据的后续研究提供了科学依据。HSIC 的目的是将HSI 中每一个像素分类到给定的地物类别中,如植被和农作物。
在HSIC 研究早期,由于HSI 光谱反射曲线良好的判别性,不同地物类别的光谱曲线不相同。研究者将传统机器学习方法加以改进并用于HSIC,包括支持向量机SVM(Support Vector Machine)(Melgani 和Bruzzone,2004)、K 均值聚类(Ma 等,2010)、随机森林(Ham 等,2005)、极限学习机(Zhou 等,2015)等。这些传统方法利用光谱曲线构造特征提取模型,提取判别性特征。然而不同波段之间具有较强的相关性且存在大量的冗余信息,过高的光谱分辨率所带来的更多计算量,都可能导致维数灾难,使得这些传统方法存在一些局限性。为了避免维数灾难,常采用特征选择和特征提取两个方法对光谱波段进行降维。特征选择是选择一部分对结果更有效的光谱波段。Sun 和Du(2018,2019)提出了一些波段选择方法来减少波段之间的冗余。然而,对于不同类别的像素,每个光谱波段有不同的贡献,每个类都有它的最优分类光谱波段子集,而这些子集对不同的类可能是不相同的。例如波段1,6,10,…,对类别1是有用的,而波段2,7,9,…,对类别2 是有用的。特征提取是通过线性或者非线性变换将这些光谱波段结合在一起。主成分分析(PCA)(Rodarmel 和Shan,2002)、独立成分分析(ICA)(Wang 和Chang,2006)和Fisher线性判别分析(LDA)(Luo 等,2015)等是最常用的几种降维方法。主成分分析的方法是提取出前k个主成分作为光谱特征。但参数k需要通过专家经验手动设置,合适的k会将所有有用的特征保存,不合适的参数可能会丢失一些有用信息或者保留较多的冗余信息。传统的特征提取方法的缺点是需要手工制作特征,依赖于设计者或领域专家的先验信息,对于不同的数据集适应和泛化能力较差,无法处理复杂和新的情况。
由于深度学习可以提取更高层次和更抽象的特征,研究者们开始研究如何利用深度学习解决HSIC。这些方法包括堆叠自编码器SAEs(Stacked Autoencoders)(Deng 等,2019;Mei 等,2019a)、深度信念网络DBNs(Deep Belief Networks)(Chen等,2015)、卷积神经网络CNNs(Convolution Neural Networks)(Zhong等,2018;Wang等,2018;Mei等,2019b)、循环神经网络RNNs(Recurrent Neural Networks)(Zhang 等,2018;Mou 等,2017)和生成对抗网络GAN(Generative Adversarial Networks)(Zhu等,2018)。Chen等(2014)等首次使用多层SAE为HSI提取深度特征,在深度网络最后一层加入logistic 回归分类器,利用标记样本对整个网络进行微调。Li(2015)等使用单一限制玻尔兹曼机和多层DBN 为HSI 提取频谱空间特征。基于SAE和DBN 的方法主要问题是将图像平展成向量,无法在空间特征提取阶段考虑空间信息。而CNN 可以很好的缓解上述问题,因此将CNN 引入HSIC。Zhang 等(2018)等提出一种光谱—空间残差网络(SSRN),该网络使用光谱和空间残差块,从HSI学习深度判别特征。然而其使用原始HSI三维块作为输入,不加任何处理,导致计算量巨大,迭代速度较慢。而其他一些CNN 的方法则是使用降维之后的三维块,丢失一部分光谱信息。同时这些CNN 对每个像素和光谱进行相同的处理,而由于混合像素问题和冗余波段问题,使得这样的处理方法同样具有局限性。
由于注意力机制可以自适应的抑制或者增强输入信息,已经广泛应用于图像处理(Vaswani 等,2017),很多学者都尝试在HSIC中结合注意力机制来关注更为重要的特征。Li(2020)等设计DBDA(Double-Branch Dual-Attention Mechanism)两个分支,以通过不同注意力结构提取HSI中大量光谱和空间特征,然而其复杂的结构导致需要更多的训练时间。Roy 等(2020)结合SENet(Squeeze and Excitation Network)和残差网络(ResNet)提出FuSENet(Fused Squeeze-and-Excitation Network),其通过SENet压缩和激发得到通道的权重值,提取出每个特征图的重要性。Das 等(2020)设计一个Multi-Receptive Lightweight Residual 模块(GhoMR),并提出GhoMR-Net。GhoMR 模块通残差结构提取特征,多接受域提取其权重,以分层的方式提取更为重要的特征。这些注意力机制多关注于光谱或空间信息,不能很好地体现HSI 光谱合一的特点。
虽然已经有许多基于卷积神经网络的高光谱图像分类模型被提出,但仍然存在一些问题。
(1)如何自适应的强调对分类有效的光谱信息和空间信息;
(2)如何充分提取HSI不同层次的特征,并且从不同层次特征中提取出判别性特征;
(3)如何设计一个端到端的网络,在保证分类精度的同时,有效加快网络训练速度。
针对这些问题,我们借鉴注意力机制,提出一种用于HSIC 的端到端的空间光谱注意力双边网络SSABN(Spectral-Spatial Attention Bilateral Network)。通过光谱注意力模块自适应的学习不同原始输入数据中每个光谱波段的权值,将特征选择隐式的应用于光谱向量上。在空间特征方面,由于与中心像素相同类别的周围像素对分类贡献大,不同类别的周围像素贡献小,空间注意力模块将根据像素对中心像素分类的贡献,自适应的学习其重要性,提高相同类别的周围像素权重,削弱不同类别的周围像素权重。双边网络通过不同的卷积结构,提取不同层次的特征,通过特征融合模块将不同层次特征融合得到判别性的特征。
2 光谱空间注意力双边网络
本文提出一种光谱空间注意力双边网络模型用于高光谱图像分类。本节首先介绍提出的高光谱图像分类模型。其次介绍所提出双边网络中的特征融合模块,并详细说明了光谱空间注意力模块。最后给出了该模型的损失函数及其优化方法。
2.1 提出模型概述
设高光谱数据集H∈Rh×w×d,其中空间维度的高度和宽度用h,w表示,光谱带的数量用d表示。假设数据集H包含N个标记像素U={u1,u2,…,un}∈R1×1×d,每个标记像素由d个光谱波段构成,其对应的独热编码标签向量为V={v1,v2,…,vn}∈R1×1×k,其中k是类别数。为了充分利用数据中的原始信息,以标记像素U为中心的相邻立方体组成一组新的三维块W={w1,w1,…,wn}。在本文中,我们将每个W中的wi输入到所提出的模型中,对其中心对应像素ui进行分类。
对高光谱数据标记后,首先将所有可用的标记数据随机分为训练、验证和测试数据集,分别用wtrain、wval、wtest表示,对应的标签集为vtrain、vval、vtest。然后使用wtrain、wval优化和测试模型,通过交叉验证找到模型的最佳参数。最后通过wtest对所有像素进行分类,得到性能评价指标,形成分类图。
图1给出了所提出模型的框架。该模型主要有4个模块。其中图1(A)表示光谱空间注意力模块用于寻找有效的光谱和空间部分。空间路径上下文路径为双边网络模型两条不同CNN 路径,分别由图1(B)和图1(C)所示。图1(D)所示的特征融合模块用于融合双边网络不同路径的输出特征。
空间路径共有3层,每层均由二维卷积层、批归一化和Relu 激活函数组成。每一层的卷积核大小为,步长均为2,因此输出特征图大小均为输入特征图大小的1/2。已有研究表明(Luo等,2017),空间信息和感受野是获得高精度的关键,该路径提取的输出特征图尺寸为原始图像的1/8,能编码丰富的空间信息。
常用的增大感受野的方法,如更大的卷积核、金字塔池化模块或者空间金字塔池化,这些方法同时也带来大量的计算量和内存消耗,导致较慢的迭代速度。本文中上下文路径采用一种类似VGG 网络结构,将其4倍下采样和8倍下采样结果通过注意力精炼模块(图2)提取特征。注意力精炼模块通过全局池化,1×1 卷积,Batch Norm 和Sigmoid 激活函数,提取通道权重,可以增强下采样中更有效的特征。最后,将两条路径输出特征通过特征融合模块提取判别性特征,通过全连接层输出像素类别。

图2 注意力精炼模块Fig.2 Attention refinement module
2.2 光谱空间注意力
光谱空间注意力如图1(A)所示,分为光谱注意力和空间注意力,目的是强调有助于最终分类的信息,光谱注意力强调光谱波段即什么样的光谱是有意义的,空间注意力则强调空间信息即在分类像素周围哪里的特征是有意义的。
光谱注意力模块输入是原始高光谱数据,大小为w×h×d。使用全局平均池化和最大池化两种方式提取互补的光谱全局特征,得到两个1×1×d的光谱特征,再将提取到的特征通过同一个多层感知机MLP(Multi-Layer Perceptron)提取权重信息,将得到两个特征经过Sigmoid 激活函数即可得到光谱权重系数MSe,大小为1×1×d。通过权重系数对原始HSI 进行加权即可得到光谱加权HSI 特征F′。光谱注意力计算可概括为
式中,HSI 指原始高光谱图像,σ指Sigmoid 激活函数,MSe指权重系数。
空间注意力模块输入是HSI进行光谱加权的结果,大小为w×h×d。与光谱注意力相似,空间注意力在通道维度分别进行全局平均池化和最大池化,并将得到大小为w×h×1 结果进行拼接。然后经过一个7×7 的卷积层,同样最后通过Sigmoid 激活函数得到空间权重系数MSa,空间权重系数MSa与光谱加权特征F′相乘即可得到新特征。空间注意力计算可概括为
式中,F′指原始高光谱图像光谱加权的结果,σ指Sigmoid 激活函数,f7×7指卷积滤波器大小为7×7的卷积层。
通过光谱空间注意力模块,可以将与待分类像素类别相同的更多信息进行增强,抑制对分类无效的信息,使得最终判别像素正确类别概率提高。
2.3 特征融合模块
双边网络不同路径由于结构不同,产生不同层次上特征,空间路径由于使用卷积加Relu 函数,得到的特征大多是丰富的细节信息;上下文路径通过多次下采样捕获更多的上下文信息。两种路径输出不同层次的特征,如果简单的进行拼接,无法得到更有效的特征,因此提出一个特征融合模块(图3)来解决特征融合问题。
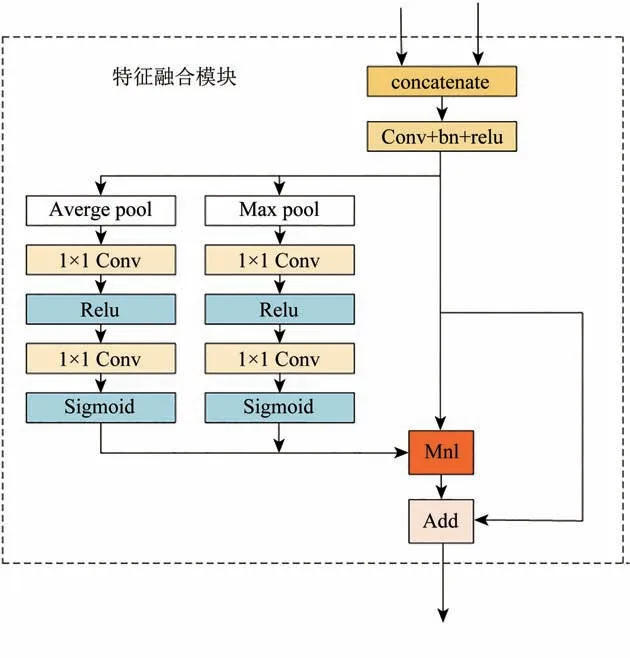
图3 特征融合模块Fig.3 Feature fusion module
对于两条不同路径的输出,将其串联起来,通过批归一化能平衡不同层次特征的尺度。然后将连接的特征通过一种与SENet类似的结构计算出一个权重向量,通过权重向量与原始特征向量相乘可将原始特征进行重新赋权,即完成了不同层次特征的选择和组合。类SENet结构由两条相似路径组成,为了充分利用特征信息,将特征通过最大池化和平均池化,然后通过2 个1×1 卷积限制模型复杂度,并在两个卷积中加入Relu 函数增加其非线性,最后通过sigmoid 函数得到权重向量。具体结构设计细节如图3。
2.4 损失函数和优化器
卷积神经网络优化模型首先需要合适的目标函数,我们使用分类中最常用的交叉熵函数作为SSABN的损失函数,交叉熵的损失函数如下:
式中,y和为真实和预测标签,C是类别的数量,M是样本数量。模型中参数的更新则使用随机梯度下降。
3 HSI分类实验
在本节,首先介绍本文实验中使用的HSI数据集。然后对影响模型性能的一些超参数进行试验分析,之后由消融实验分析光谱空间注意力模块与特征融合模块的作用。最后将提出模型与和其他现有模型进行比较,分析讨论实验结果。
3.1 数据集介绍
我们在实验中使用3个公开HSI数据IPs(Indian Pine),PU(Pavia University),SA(Salinas)来验证提出模型的有效性(表1)。

表1 本文所使用的3个数据集Table 1 Three data sets used in this article
(1)IP(Indian Pines):这组数据拍摄时间为1992 年6 月,由机载可见光/红外成像分光计(AVIRIS)传感器在印第安纳州西北部的印第安松实验地点上空收集,该数据集像素大小为145×145,可用光谱波段数为200。该图像三分之一区域为森林或其他天然植物;接近三分之二的区域为农业作物,图中有一些农作物(玉米、大豆)覆盖率不足5%,是由于该图像拍摄时间为6 月,这些农作物还处于生长初期;除此之外主要为高速公路和铁路线。现有的图像被标记为16 个不同类别。表2列出了每个类的训练、验证和测试样本的数量。

表2 India Pine数据集的类名和每个类样本数Table 2 Class name and sample number of each class for IP dataset
(2)PU(Pavia University):这组数据拍摄时间为2002 年7 月,由意大利北部帕维亚大学的反射光学系统成像仪(ROSIS)采集,该数据集像素大小为610×340,可用光谱波段数为103。现有的图像被标记为9 个不同类别。表3 列出了每个类的训练、验证和测试样本的数量。
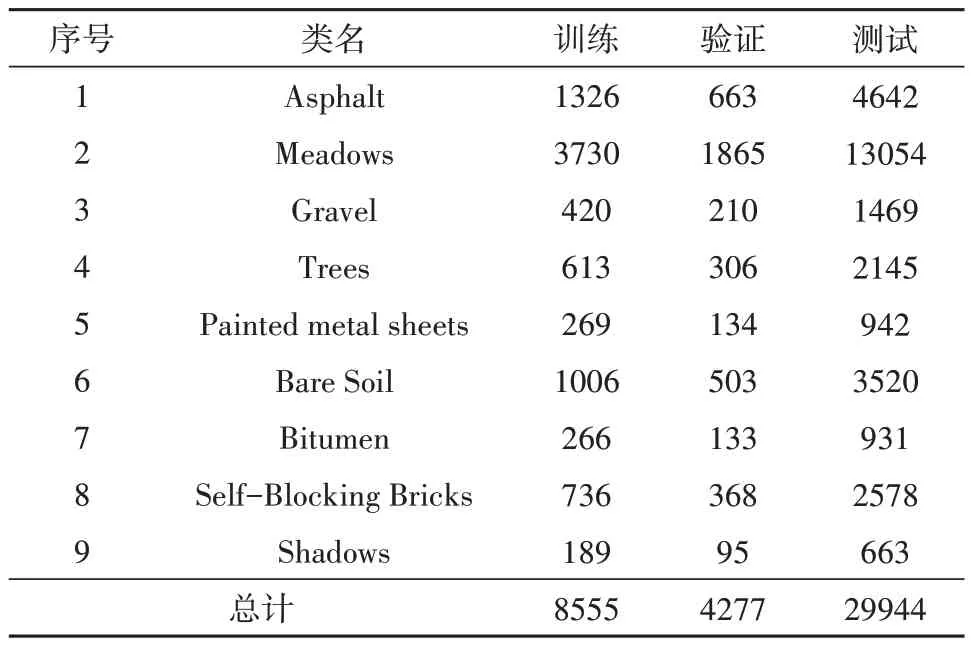
表3 Pavia University数据集的类名和每个类样本数Table 3 Class name and sample number of each class for PU dataset
(3)SA(Salinas):这组数据由AVIRIS 传感器于1998 年在Salinas 山谷收集,该数据集像素大小为512×217,可用光谱波段数为224。现有地物大多为农作物,被分为16 个地物类别。表4 列出了每个类的训练、验证和测试样本的数量。

表4 Salinas 数据集的类名和每个类样本数Table 4 Class name and sample number of each class for SA dataset
3 个数据集有不同的可用标记样本数量。IP 数据集有10249 个标记样本,PU 数据集有42766 个标记样本,而SA 数据集有54129 个标记样本。对于3 个数据集,我们随机选取20%,10%,70%的标记样本分别作为训练样本,验证样本和测试样本,详细数据如表2—4所示。
3.2 实验环境配置
为了评估SSABN 模型的性能,实验在CPU 为Intel Core i7-9750H 2.60 GHz*12,RAM 为16 GB,GPU为NVIDIA GeForce 2060,RAM为6 GB的个人计算机上进行。软件环境的系统为Windows 10家庭版,python版本为3.7.6,深度学习框架为PYTorch,版本为1.4.0。
实验的定量评估方法使用总体精度OA(Overall Accuracy),平均精度AA(Average Accuracy)和Kappa系数(K)作为评价指标。
3.3 超参数设置
我们分析了影响训练进度和分类性能的一些因素即超参数,如批量大小,卷积滤波器核数,空间输入大小和训练样本比例,选取其在验证数据集上分类性能最优的参数,作为最终的实验结果比较。在接下来的实验中,每个实验进行200个epoch。
3.3.1 批量大小
神经网络的收敛速度和收敛性由学习率和批量大小决定,学习率控制着训练过程中梯度下降的步长,批量大小控制训练过程中每一个epoch 中梯度下降的次数。我们使用多步下降策略控制学习率,对于批量大小则考虑以下集合{8,16,32,64,128,256}。结果如图4 所示,在IP 数据集上最佳批量大小为32,而在PU 和SA 数据集上则为64。与IP 数据集相比,PU 和SA 数据集需要更大的批量大小,这是由于在相同学习率下,PU 和SA数据集训练样本数更大。
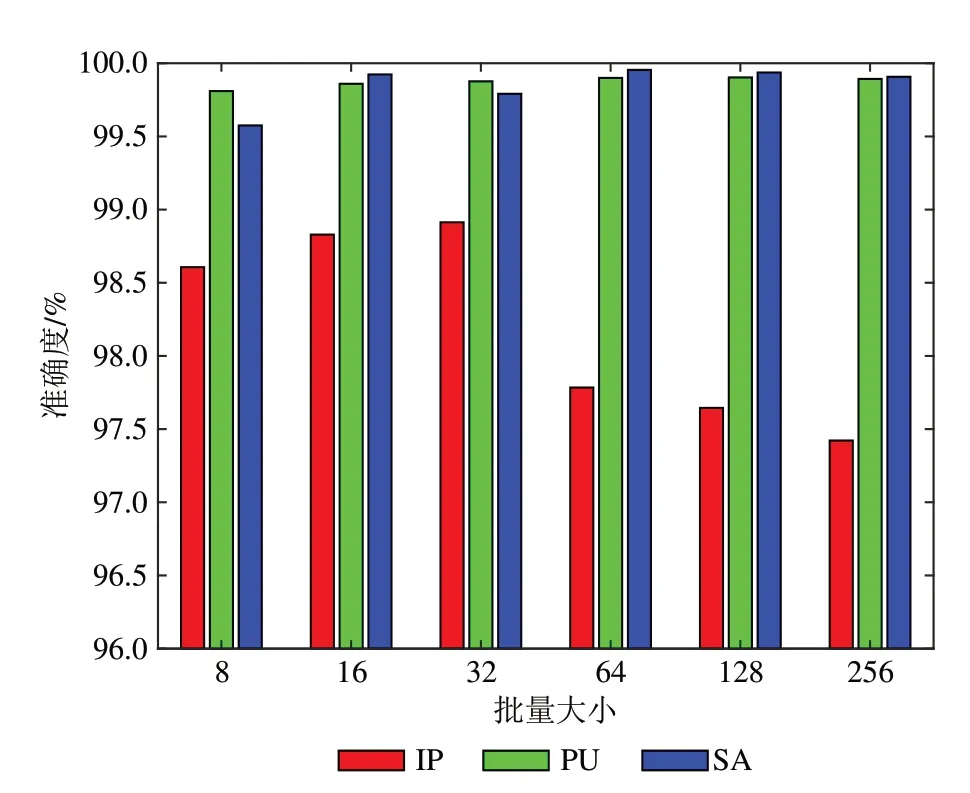
图4 不同批量大小下的准确度Fig.4 Accuracy with different batch size
3.3.2 卷积滤波器核数
在双边网络中,上下文路径和空间路径的卷积滤波器的核数决定了其表示能力和计算消耗,设空间路径每层的核数均为ks,上下文路径第一层同样为ks,之后每次下采样将卷积滤波器的核数翻倍。为寻找SSABN 模型最优滤波器核数ks,我们考虑以下ks集合{8,16,24,32}。如图5所示,卷积滤波器核数越大,在数据集IP 上有更好的准确度,而在数据集PU 和SA 上,卷积滤波器数量为24,模型达到最佳性能。
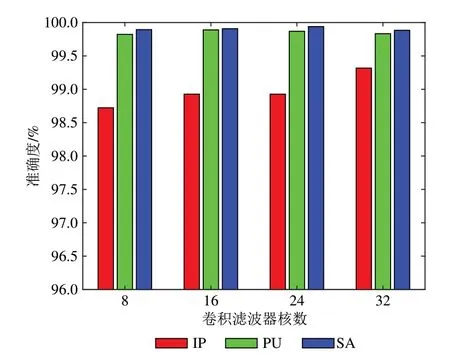
图5 不同卷积滤波器核数下的准确度Fig.5 Accuracy with different kernel numbers of convolutional filters
3.3.3 空间输入大小
空间输入大小决定了有多少空间信息用于分类。随着空间输入大小的增加,可用的空间信息逐渐增加,同时也增加了一定的冗余信息。为评估空间输入大小对SSABN 分类效果的影响,考虑{5,7,9,11,13,15,17,19,21} 的空间输入大小集合。如图6 所示,对于3 个不同的数据集,当空间输入大小大于或等于9 × 9 时,SSABN表现稳健。

图6 不同空间输入大小的SSABN的准确度Fig.6 Accuracy with different spatial input sizes
双边网络结构提取两种不同层次特征,其空间路径提取特征具有丰富的空间信息,上下文路径通过多次下采样提取全局特征。只有当两种不同层次特征有足够区分度时,经过特征融合模块的输出结果才具有足够的判别性和抽象性。由于上下文路径的最大下采样倍数为8,当空间输入小于8时,4倍下采样与8倍下采的空间特征相似。所以当空间输入大小大于9×9时,SSABN表现稳健。
3.3.4 训练样本比例
卷积神经网络由于其结构,相较于传统方法有更强的拟合能力,当训练样本数量较少时更容易产生过拟合。考虑分别使用1%,5%,10%,15%和20%的标记像素作为训练集来训练SSABN。如图7 所示,随着训练样本数量比例增加到15%,SSABN在3个数据集上有更高的整体准确度。当训练样本比例为1%和5%时,SSABN 在IP 数据集上略低于SSRN 和FDSSC,但随着训练样本的增加,SSABN 准确度略高于其他方法。这是由于IP 数据集本身数据量较小,且部分类别样本数过小导致。
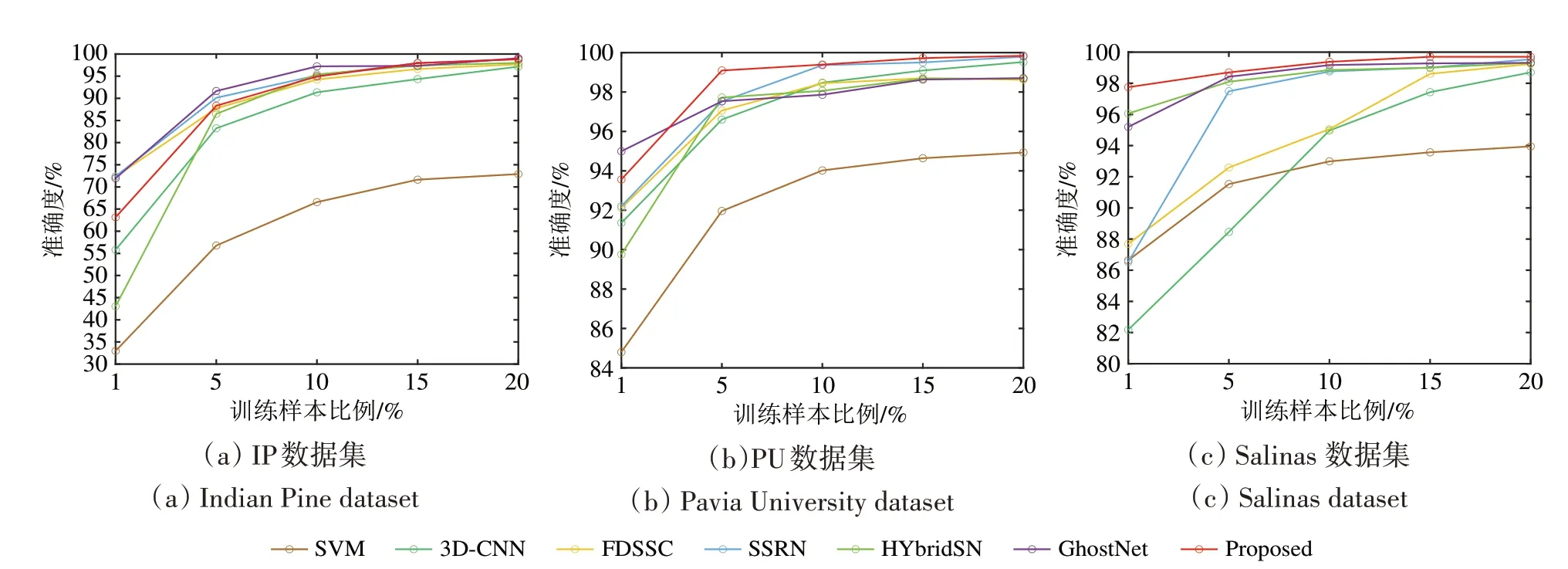
图7 模型在不同训练样本比例的IP,PU,SA数据集上的准确度Fig.7 The accuracy of the algorithm on the IP,PU,and SA datasets of different training sample proportions
3.4 消融实验
3.4.1 光谱空间注意力
我们将SSABN 与第一层没有光谱空间注意力模块的双边网络进行比较,结果如表5。在3 个数据集上,SSABN 分类准确度上均优于没有第一层注意力模块的双边网络。这些结果表明,第一层光谱空间注意力模块能有效选择有用的原始HSI数据进行后续的特征学习。

表5 有/无光谱空间注意力模块的OATable 5 OA of with/without spectral-spatial attention module
我们将光谱—空间注意力模块与其他常用注意力模块:通道注意力,空间注意力,SENet进行比较。结果如表6 所示,除了PU 数据集,光谱—空间注意力在3 个数据集上,比其他3 个注意力模块都有更高的OA。而由于PU数据集具有1.3 m/pix的像素分辨率,这使得相邻像素对中心像素分类有更大影响,所以空间注意力比光谱空间注意力有更高的OA。
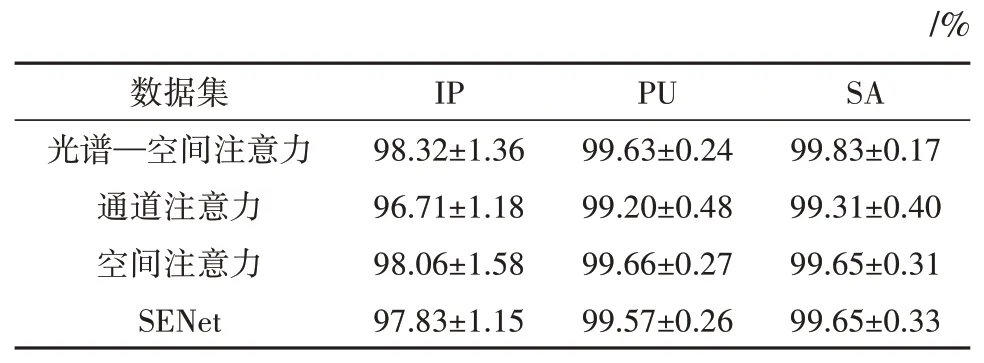
表6 不同注意力模块的OATable 6 OA of different attention module
3.4.2 特征融合模块
我们将SSABN 与没有特征融合模块的双边网络进行比较,结果如表7。在3 个数据集中,含有特征融合模块分类准确度高于不含特征融合的网络,这说明特征融合模块能有效融合两条路径不同输出,产生更具判别性特征。
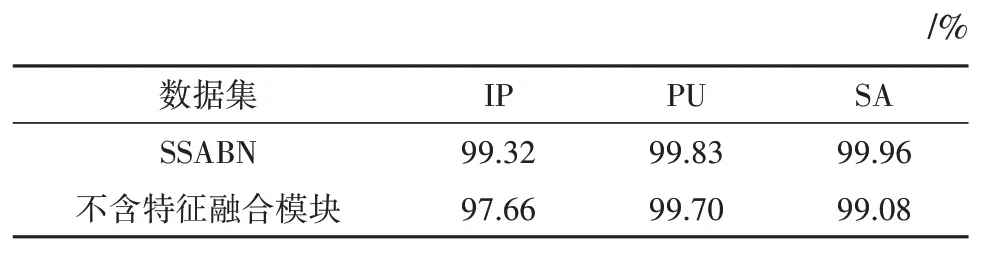
表7 特征融合模块对OA影响Table 7 The influence of feature fusion module on OA
3.5 HSI分类实验
在本节中,我们将提出的SSABN 与一种传统机器学习方法:SVM(Melgani和Bruzzone,2004),以及3 种基于深度学习的方法:3D-CNN,FDSSC(Wang 等,2018),SSRN(Zhong 等,2017),HYBridSN(Roy等,2020)以及GhostNet(Das等,2020)进行对比。我们进行10 次重复实验,实验结果以平均值±标准偏差表示。
(1)定量分析。不同方法的定量度量见表5—8。由表5—7 可以看出,与传统算法相比,深度学习方法能在3 个公开数据集上取得更好的性能。这是由于它们可以学习更多抽象的高级特性,而SVM 仅仅使用原始数据的光谱特性进行分类。此外,光谱空间注意力模块能有效地提取光谱和空间信息,双边网络结构能有效地利用多尺度特征,使得SSABN 的分类准确度优于其他几种深度学习方法。
上述实验证明,我们提出的方法在同等条件下可以达到较高的准确度,而一个好的方法应该平衡准确度和效率。在每个数据集中随机选取20%标记像素作为训练样本验证,其他参数选取算法的最优参数。由表8可以看到,SSABN相比其他大部分深度学习方法有更快的迭代速度,这是由于光谱空间注意力模块是简单的轻量级模块,上下文路径模块由于下采样有快速的计算速度,而空间路径本身2D卷积结构计算量小于SSRN的3D卷积结构,使得SSABN拥有更快的计算效率和迭代速度。所提出SSABN训练时间略高于HYBridSN,这是由于HYBridSN对原始HIS进行PCA降维,大大减少了计算量。

表8 不同模型在IP数据集上分类准确度Table 8 Accuracy of different models on the IP dataset

表9 不同模型在PU数据集上分类准确度Table 9 Accuracy of different models on the PU dataset

表10 不同模型在SA数据集上分类准确度Table 10 Accuracy of different models on the SA dataset
以上实验证明,我们提出的SSABN 不仅在有较高的准确的的同时,有效减少了训练时间,能很好地提高准确度和效率,是一个较为优质的解决方案。
(2)定性分析。图8—10 是原始图像的groundtruth图和不同方法在3个数据集上的分类结果可视化。从3个数据集的分类图可以看到,SSABN有误分点,生成的分类图最为准确,特别是在两类的分界线上,同时在没有标记类别的区域有更精细的分辨率。这是因为该模型利用空间信息来学习中心像素与周围像素的关系,所以能产生更为平滑的边界。
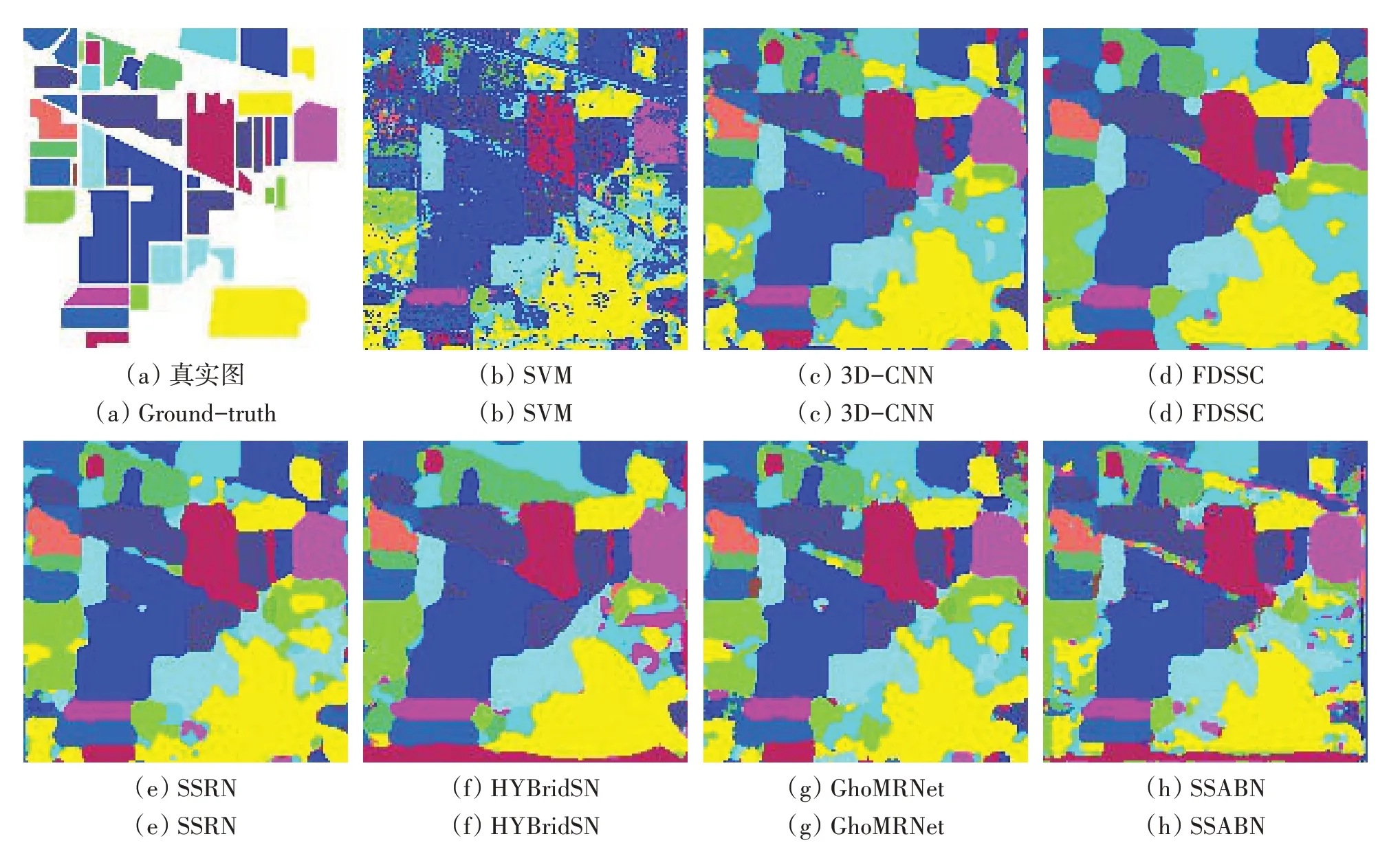
图8 使用不同模型的IP数据分类图Fig.8 Classification maps for the IP dataset

图9 使用不同模型的PU数据分类图Fig.9 Classification maps for the PU dataset
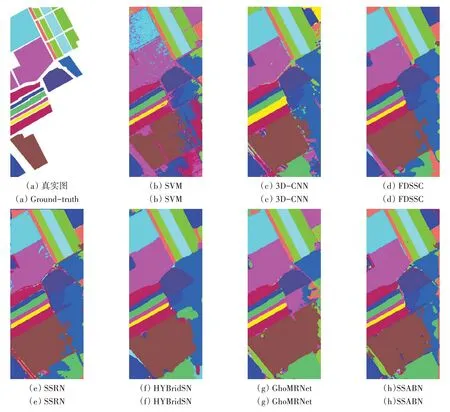
图10 使用不同模型的SA数据分类图Fig.10 Classification maps for the SA dataset
4 结论
本文中提出一种用于HSIC 的SSABN 模型,该模型用双边网络作为基础网络结构学习光谱和空间特征,用光谱—空间注意力来进行光谱波段和空间信息的选择和增强,最后由特征融合模块进行特征融合输出判别性特征。
首先,原始的HSI 块直接作为模型的输入,这是一个端到端的二维CNN 网络框架,不用依靠领域知识和专家经验。其次,利用光谱注意力和空间注意力模块来增强和提取有效的波段和像素。消融实验表明,光谱空间注意力模块能有效地提取抽象性特征,增加分类精度。双边网络提取丰富信息后由特征融合模块提取判别性特征,并通过全连接层输出预测类别,通过熔断实验证明了特征融合模块的有效性。最后,在3 个公开数据集上进行对比实验,由定量分析可以看出,SSABN 网络模型均取得了更加好的分类精度同时也降低了计算消耗时间,结果可视化也表明,SSABN 网络能有效地划分边界,且分类精度高于其他模型。
猜你喜欢
艺术家(2023年8期)2023-11-02
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
小雪花·成长指南(2022年1期)2022-04-09
红领巾·萌芽(2019年8期)2019-08-27
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
CHIP新电脑(2016年3期)2016-03-10
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
