
新型语义分割D-UNet的建筑物提取
2024-01-01 13:32龙丽红朱宇霆闫敬文刘敬瑾王宗跃
遥感学报 2023年11期
龙丽红,朱宇霆,闫敬文,刘敬瑾,王宗跃
1.汕头大学 工学院电子系,汕头 515063;
2.中山大学 电子与信息工程学院,广州 510006;
3.集美大学 计算机工程学院,厦门 361021
1 引言
随着地球观测遥感卫星技术发展取得了卓越的成就,大量的遥感数据为各种应用提供丰富的可挖掘的信息(孙伟伟 等,2020)。建筑物信息作为地理信息的重要组成部分,广泛应用于道路交通规划、土地规划、城市管理等领域,在生活中有着越来越重要的应用,本文主要研究遥感图像的楼房分割问题。
在传统分割方法中,通常根据灰度、颜色、纹理和形状等特征将图像划分成若干互不相交的区域。典型的分割方法有基于阈值、边缘、区域、图论等分割方法。基于阈值的分割方法,其基本思想是基于图像灰度特征计算灰度阈值,并将图像的每个像素灰度值与阈值相比较,得出其类别。如李丽等(2013)根据建筑群的分布和纹理特点,利用小波变换和自适应全局阈值法提取建筑群标记信息实现分割;吴诗婳等(2018)提出了一种基于直线截距直方图的多阈值分割方法等。基于边缘的分割方法(Hu等,2013;Wang等,2015),主要根据图像边缘灰度、颜色、纹理等特征的突变来进行边缘检测,比如使用基于Roberts(康牧等,2008)、Sobel、Prewitt(邹柏贤 等,2013)、Laplacian(桂预风和吴建平,2011)等微分算子对图像进行边缘检测,识别出图像的边缘信息,从而完成分割。基于图论的分割方法,其基本思想是将图像的分割问题与图的最小分割问题相关联,最终实现分割效果。如Felzenszwalb 和Huttenlocher(2004)介绍一种基于图表示的图像分割方法,基于贪心聚类算法提出可变型部件模型算法,奠定了基于图论的分割算法。但由于遥感图像包含丰富的光谱信息,使用传统的特征提取方法对于要求高的遥感图像分割应用场景,仍然存在很大的局限性。
近年来,深度学习理论及应用取得重要进展,并在图像语义分割中取得良好的效果,特别是对高级语义信息提取,解决了传统图像分割方法中语义信息缺失的问题。2014 年,全卷积神经网络FCN(Fully Convolutional Networks)首次将深度学习应用于图像分割,实现像素级分割,奠定了深度学习神经网络用来解决图像分割问题的基础(Shelhamer 等,2017)。然而FCN 采用双线性插值上采样恢复特征图,丢失许多细节信息,导致分割结果比较模糊和平滑。如图1所示,在航空遥感图像数据集INRIA(Inria Aerial Image Labeling Dataset)上使用全卷积神经网络对遥感影像进行分割,其中图1(a)为原图像,图1(b)为图像的真实标签,图1(c)是使用全卷积神经网络的分割效果图。可以看出,与真实标签相比(如红框所示),测试结果边界出现明显模糊,小尺寸的目标未能精确识别,整体分割效果较为粗糙。2015年,U-Net(Ronneberger等,2015)作为FCN的改进与发展,通过捕获上下文信息的收缩路径来实现更精准的像素边界定位。采用网络结构完全对称的典型编码解码结构,但由于其网络结构仅在单一尺度上预测,不能很好地处理多尺度问题,且速度较慢,冗余较多。然而,遥感影像具有语义丰富,分辨率低,清晰度低等特点,且建筑物图像具有多尺度、大跨度等特点,且上下语义联系紧密,与自然图像相比具有极其复杂的特性,简单地使用全卷积神经网络或U-Net不能很好地满足分割的应用需求。为了解决这个问题,Bischke 等(2019)采用了一种新型的多任务损失函数,他们的方法可以很好的保存建筑物的分割边缘并且提高了分割准确率,但缺点是网络复杂且不易优化。类似的,Li 等(2019)在网络模型中收集多尺度特征信息来提高遥感影像分割的精度,韩彬彬等(2020)在残差卷积网络中加入了带孔卷积和稠密连接机制以构建稠密空间金字塔结构来提取多尺度特征。而Pan等(2019)采用对抗神经网络并且在其中引入注意力机制来提升分割的效果,他们的方法在INRIA 数据集上取得了很好的结果。与上述方法不同,本文提出了一种基于U-Net 的新模型Dilated-UNet(D-UNet),即在U-Net中间加入精心设计的空洞卷积模块来解决这个问题,并设计了一种交叉熵和Dice-coefficient的联合损失函数,更好的训练模型以达到预期分割效果。

图1 FCN分割效果对比图Fig.1 Comparison of FCN segmentation effect
2 基于U-Net改进的卷积网络模型
本文提出一种基于U-Net改进的全新卷积神经网络分割模型D-UNet(Dilated-UNet),接下来将详细介绍D-UNet 网络结构,主要包括U-Net、空洞卷积模块、联合损失函数和实现细节等,具体网络结构如图2所示。
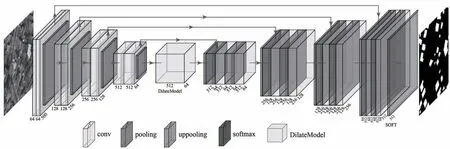
图2 D-UNet网络结构图Fig.2 D-UNet network structure diagram
2.1 模型结构
(1)U-Net。U-Net,首次是应用于医学图像分割,其采用典型的编码—解码结构。在编码结构上,每经过两个卷积核为3 × 3 的卷积层后进入2 × 2 的最大池化层,便得到新尺度的特征图,共有4个卷积池化模块。在解码结构上,每进行一次2 × 2 的上采样,与上一次卷积操作得到的特征图在裁剪后进行多尺度的融合,丰富细节信息,提高分割精度,共有4个上采样模块。在编码和解码的结构上具有完全对称的特点。但U-Net网络卷积层次较少,对特征的提取与表达不够准确,边缘模糊现象没有得到很好解决。
(2)空洞卷积模块。图像输入到CNN 中,FCN 或U-Net 和传统CNN 一样对图像进行卷积、池化等操作,以降低图像尺寸,增大感受野。图像分割是像素级输出,因此要进行上采样恢复到原始图像尺寸大小,但过程降低了空间分辨率并严重丢失图像的细节信息。空洞卷积极好地解决了这个问题(Yu 和Koltun,2016)。空洞卷积可类似看成是在卷积核内部插入(扩张率)个0来扩大卷积核大小,从而在扩大感受野的同时捕获多尺度的上下文信息。
空洞卷积可扩大感受野,例如3个卷积核大小为3 × 3 的普通卷积核叠加,3 层的感受野大小分别是3 × 3,5 × 5,7 × 7。而3 个大小为3 × 3 的卷积核叠加,扩张率为1 时,其感受野为3 × 3;扩张率为2 时,其感受野为7 × 7;扩张率为5 时,其感受野为17 × 17。显然,上述卷积核参数始终为9,在保持参数个数不变的情况下,使用空洞卷积可以大幅度增大卷积核的感受野,感受野示意图如图3所示。其中红色点表示感受野的中心,蓝色的深浅表示参与卷积运算的次数,越深表示参与卷积运算的次数越多。
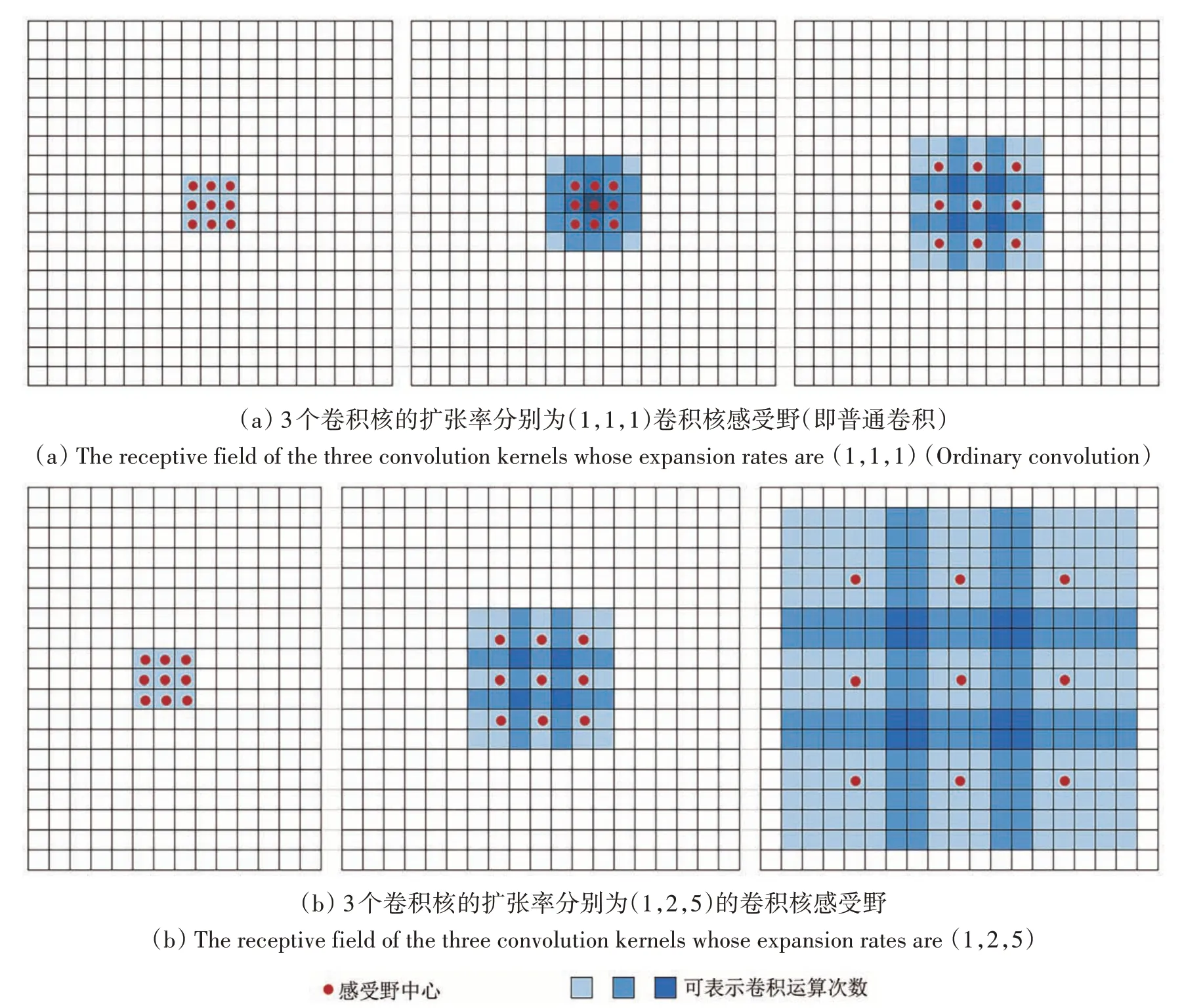
图3 3个3×3卷积核感受野对比图Fig.3 Comparison of three 3×3 convolution kernel receptive fields
本文设计的空洞卷积模块如图4 所示,共4 条数据信息流通道,使用的卷积核大小均为3 × 3。第一通道使用4 个3 × 3 的卷积核,且空洞卷积的扩张率分别为1、2、5、8,其感受野分别3 × 3、7 × 7、17 × 17、33 × 33。随后每条通道相对应的空洞卷积扩张率不变,逐渐减少卷积层层数,直到扩张率为1的卷积核,即普通卷积。即提取到的特征进入四条通道,分别生成不同的信息流,然后进行信息连接。参考空间金字塔模型(Zhao 等,2017)和ResNet 的残差结构(He 等,2016),本文设计的空洞卷积的扩张率多样化,可提取多尺度信息,在扩大感受野的同时成功避免空洞卷积理论问题,即“网格效应”(Wang 等,2018),且扩张率越大,能提取到更多边缘信息细节,提高模型效果。通过多通道进行并行计算,将经过不同空洞卷积扩张率的特征图进行相加融合,克服单通道的单一性不足,且不同通道对不同大小的目标分辨率不同,从而提高整体的分辨效果。
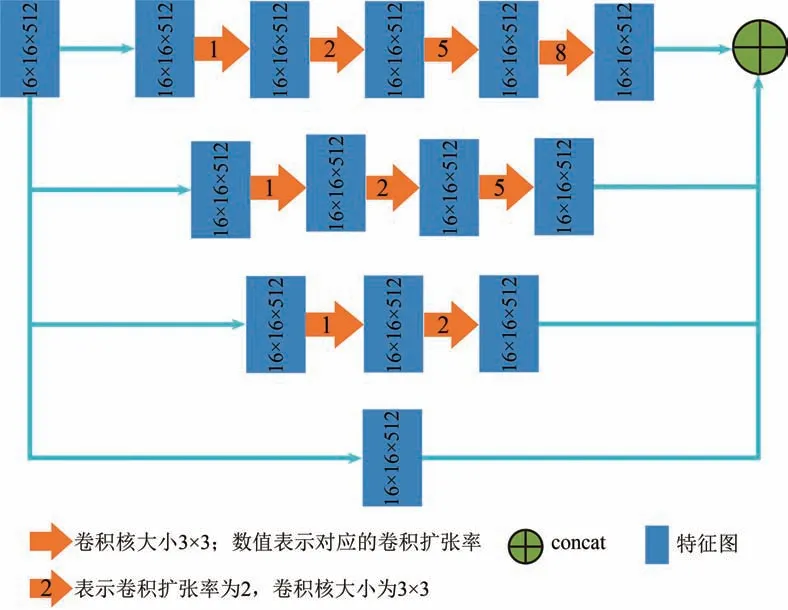
图4 空洞卷积模块图Fig.4 Dilated convolution network module
其中,16 × 16 × 512 表示特征图的长和宽是均16,通道数是512;采用的卷积核均是3 × 3,箭头上的数字表示所对应的空洞卷积扩张率。
(3)D-UNet。本文提出的D-UNet模型采用典型的编码—解码结构。编码结构由4 个卷积模块,共8 个卷积层,4 个最大池化层组成,每层卷积前都进行归一化操作,使用ReLU 作为激活函数,每两层卷积后接一个最大池化层。下采样后进入空洞卷积模块,增大感受野,提取多尺度信息,进一步提高边缘分辨率。解码结构包含4 个上采样块,每个上采样块包含转置卷积和上池化操作,使特征图恢复到与输入图像相同的尺寸,保留原始图像的空间信息,最后使用softmax 函数进行逐像素分类,最终实现分割效果。
2.2 联合损失函数
本文设计的损失函数采用联合策略,将交叉熵和Dice-coefficient 的进行联合,联合损失函数表达式为
式中,LBCE为二值交叉熵损失函数(Binary Cross Entropy Loss),LDice为Dice 系数损失函数,L为联合损失函数,λ为权重调节参数。
假设训练数据D={(x1,y1),…,(xn,yn)},其中x∈Rn为训练样本,y为标签,且y∈{0,1}。二值交叉熵损失函数表达式如下:
式中,i为第i个样本;n为总样本数;yi为第i个样本的真实标签;为第i个样本的预测标签。然而,二值交叉熵损失函数衡量标准只是对正确分类的预测概率,具有单一性,因此本论文采用联合损失函数。
Dice 系数损失函数,可度量集合相似度,可用于计算两个样本的相似度(取值范围为[0,1])。然而,当样本极度不均的情况下,二值交叉熵损失函数对样本不平衡的问题很敏感,训练时会偏向于样本多的一方,导致训练效果下降,但Dice系数损失函数表现效果较好。假设X和Y为两个样本,Dice 系数为(3),Dice 损失函数可表示为(4),可微形式可表示为(5),其中y为真实标签,为预测标签,则梯度为(6)。当样本差异越大时,s越小,则梯度越大,训练越稳定。
因此,考虑到样本之间的相似程度,本文采用Dice 系数损失函数和交叉熵损失函数进行联合,Dice系数损失函数表达式为
式中,i为第i个样本;n为总样本数;yi为第i个样本的真实标签;为第i个样本的预测标签;ε为调节参数。
权重调节参数λ,初始化λ=1,即L=LBCE,只有交叉熵损失函数。实验表明,当λ=0.7 时,即L=0.7LBCE+0.3LDice,分割效果最好。
2.3 网络训练细节
实验平台采用Intel-i7-7700 四核心八线程CPU 处理器、使用Pytorch 1.5.1 版本的深度学习框架,并使用NVIDIA 公司的CUDA10.1 GPU 平台进行计算加速。实验统计,本文模型训练一个epoch的时间为1.1 个小时,总共训练了50 个epoch,共用时55个小时。
(1)预处理。由于GPU 内存的限制,大尺度的遥感图像不能直接作为网络结构的输入,因此从遥感图像中随机裁剪出图片大小为512 × 512 的图像,并将图像进行归一化处理,使图像的像素值在0 到1 之间,更加便于计算,以提高计算速度。
(2)训练。由于预训练在深卷积神经网络中起着重要作用(Hinton 等,2006),因此本实验使用VGG13 在ImageNet 上的预训练模型,然后以端到端的方式对整个网络进行微调。具体训练过程如下,训练中使用三通道遥感影像作为输入和输出的分割结果,以联合损失函数(1)作为整体模型的损失函数,在GPU 上进行300 次迭代,学习率设为0.001,每50 次迭代学习率缩小10 倍,权重衰减设为0.0001,动量设为0.9,使用Adam算法优化所有网络参数。
3 实验过程及结果分析
3.1 数据集
本文使用的数据集是IAIL 航空图像数据集(Inria Aerial Image Labeling Dataset)(Maggiori 等,2017)。IAIL 航空图像数据集是一个城市建筑物检测的遥感图像数据集,包括高度密集的大都市金融区和高山度假村的各种城市景观,标记只有建筑和非建筑两种。数据集由360 张彩色(3 波段RGB)正射影像组成,包括美国和奥地利的城市住区,其空间分辨率为0.3 m2,训练面积为337.5 km2,验证面积为67.5 km2,测试面积为405 km2,总覆盖面积810 km2(每幅影像大小为50002)。选择该数据集,可使用交叉验证方法,随机设置5个城市作为训练集,5 个城市作为测试集,避免训练容易产生过拟合现象,有效验证模型的可行性。其次,该数据集是官方公开的数据集,测试集没有标签,因此将模型统一提交到官方网站(https://project.inria.fr/aerialimagelabeling/leaderboard[/2021-01-22])上进行验证。
3.2 验证指标
为了定量评估网络模型效果,本文采用像素精度Acc(pixel accuracy)和交并比IoU(Intersection over Union)这两个度量指标。像素精度是标记正确的像素占总像素的比例,交并比是真实值和预测值集合的交集与并集之比,表达式如下所示。
式中,假设有k+1 个类,pii表示本属于i类且被预测为i类的像素数量,即被正确预测的像素数量,pij表示本属于i类却被预测为j类的像素数量。TP为真正值(True Positive),即判定为正样本,实际上是正样本,FP 为假正值(False Positive),即判定为负样本,实际上是正样本,FN 为假负值(False Negative),即判定为负样本,实际上是负样本。
3.3 主要结果
为了验证本文方法的有效性,我们将D-UNet与航空图像标记数据集上的典型模型和先进方法进行比较,表1为在测试集上的数值评估结果,有SegNet,VGG11(Simonyan 和Zisserman,2014),PSPNet(Zhao 等,2017),LinkNet(Chaurasia 和Culurciello,2017),还包括2018 年IAIL 竞赛的获胜 者AMML(Huang 等,2018),以 及U-Net 和ED-Net 的融合模型(余威和龙慧云,2019)和AMUNet(Guo 等,2020)。由表1 可知,本文方法在测试集的5个城市实验中普遍比经典方法好,交并比IoU和准确性Acc都有很大的提高。比2019年提出的U-Net 和ED-Net 融合模型在IoU 和准确性上分别提高了4.74%和0.64%。同时,比惠健等(2019)在IoU 和Acc 分别提高了8.08%、1.13%,比AMUNet的IoU提高了7.13%,Acc提高了0.64%。由表1 可知D-UNet 在测试集上有两个地区的结果不如其他方法,因为每个地区的建筑物具有不同的分布特点,每个方法在不同的地区中效果较难达到完全的最优,但D-UNet 在整体IoU 和准确性上均超过了其他方法。
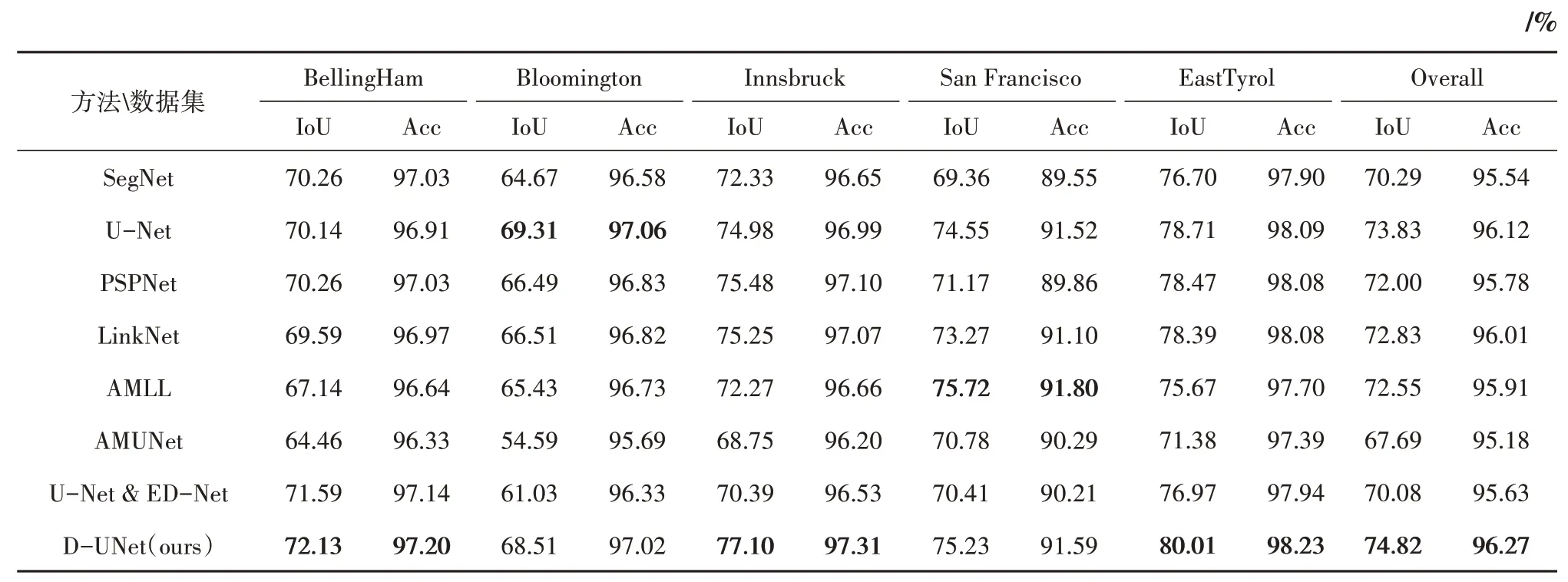
表1 测试集数值评估Table 1 Test set numerical evaluation
在验证集上对比了近一两年在IAIL 航空图像数据集上提出的新分割方法,如表2所示。本文方法D-UNet 比Li 等(2019)提出多尺度的U-Net(Multi-scale UNet)的IoU 和Acc 分别提高了4.74%和0.65%;比Pan 等(2019)使用空间和通道双注意力机制的生成式对抗网络的IoU 和Acc 分别提高了1.46%、0.17%;比Han 等(2020)提出的稠密连接机制改进的残差卷积网络和空间金字塔结构的RDASP-Net 模型IoU 提高了3.05%,Acc 提高了0.51%。Sebastian 等(2020)提出的SEResNeXt101-FPN-CPA 方法,即加入了上下文金字塔模型,通过捕获上下文特征依赖项来改进对不同大小的建筑物进行提取,本文方法D-UNet 的IoU 比其高了1.69%,Acc 高了0.29%。另外,D-UNet 比Guo 等(2020)提出的加入注意力机制块的改进的U-Net方法AMUNet 的IoU 提高了2.02%,Acc 提高了0.04%。表2 充分说明了本方法在验证集上的有效性,D-UNet 在整体IoU 和准确性上优于其他最新方法。
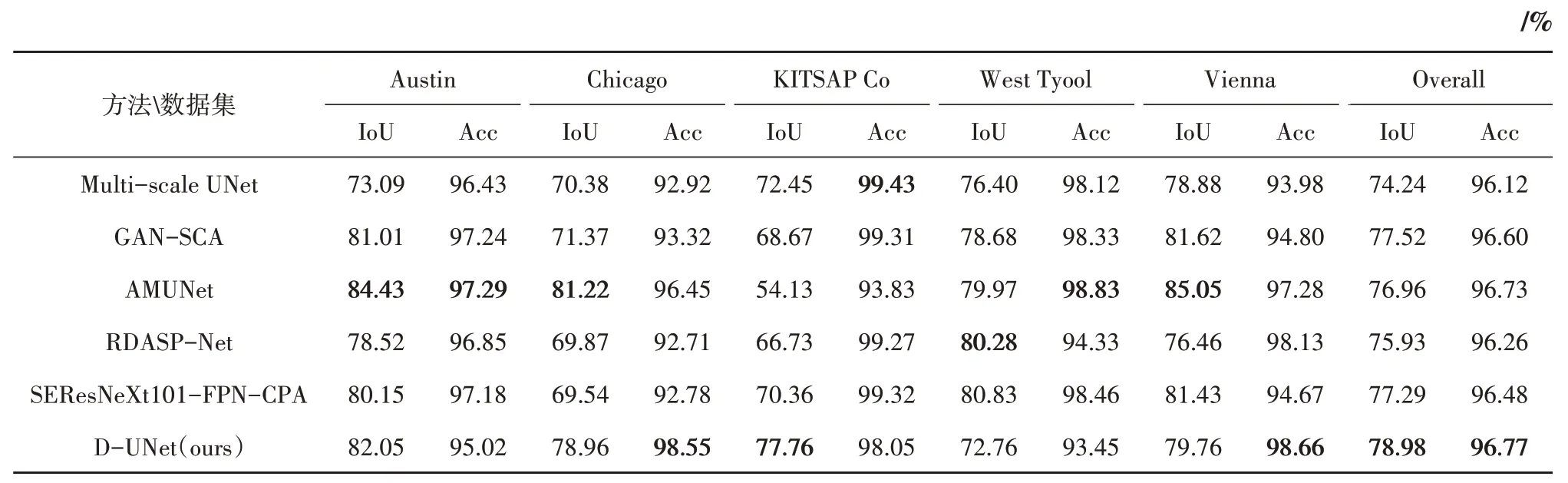
表2 验证集数值评估Table 2 Validation set numerical evaluation
实验可视化图如图5所示。图5(a)为数据集原图,图5(b)为原图标签,D-UNet 的结果如图5(g)所示,SegNet、VGG11、PSPNet和LinkNet分割的视觉效果分别如图5(c)、5(d)、5(e)、5(f)所示。可以看到,与其他方法的分割结果相比,本文方法D-UNet 可以更好区分建筑物之间的边界,预测结果较少有边缘信息的丢失,能捕获更多“尖锐”的细节信息。

图5 各方法实验可视化图Fig.5 Experimental visualization of each method
图6 展示了D-UNet 模型在图像尺寸大小为5000 × 5000 的INRIA 遥感影像测试集上的分割效果,D-UNet 在测试时每次的输入尺寸为1024 ×1024,最后将其拼接为原图大小。

图6 D-UNet分割效果可视化图Fig.6 Visualization of D-UNet segmentation effect
3.4 消融实验
为进一步验证本文方法的有效性,在验证集上对网络结构进行有无空洞卷积模块的消融对比实验结果如表3所示。在消融实验中,以本文提出的联合损失函数作为模型的损失函数,对比四通道的空洞卷积模块对模型的整体的效果,实验表明,有空洞卷积模块的D-UNet 在5 个城市的交并比IoU 和精确度Acc 均有提升,其中,IoU 最大提升幅度为5.41%,Acc 最大提升幅度为2.18%,模型整体提高分别为:IoU:4.61%,Acc:0.74%,即四通道的空洞卷积模块能够提取大小不同的多尺度特征信息对模型的分割效果具有较好的提升作用。

表3 验证集消融实验评估Table 3 Validation set ablation experimental evaluation
4 结论
从遥感图像中准确自动地分割建筑物对于城市规划和灾害管理等应用领域至关重要。本文提出了一种新的建筑物提取方法,称为D-UNet。考虑到现有的基于全卷积神经网络的方法有很多局限性,如产生模糊边缘和细节信息丢失等问题。D-UNet通过以下3个优势来解决上述问题:(1)D-UNet是端到端结构的像素级分割网络。(2)D-UNet 通过融合不同尺度的空洞卷积模块,在不增大模型计算量的同时提高了分割的精确度。(3)提出了一种新的联合损失函数,使模型能更快更稳定的进行参数更新。
在IAIL 航空图像数据集上的实验结果充分验证了D-UNet 在高分辨率遥感图像语义分割的有效性和优势,其分割精度更高,优于其他方法,具有较高的实际应用价值。但是,D-UNet 仍然具有可以提升的空间。我们将在之后的研究中继续探究如何降低D-UNet 的训练时长以及如何继续提升分割精度。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
数学小灵通·3-4年级(2021年5期)2021-07-16
红领巾·萌芽(2019年8期)2019-08-27
今日农业(2019年15期)2019-01-03
故事作文·高年级(2017年2期)2017-03-01
CHIP新电脑(2016年3期)2016-03-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
新闻传播(2015年20期)2015-07-18
读者·校园版(2015年19期)2015-05-14
