
超融合存储控制器数据分布与捕获技术
2024-01-02 13:11程瑞鹏
山西电子技术 2023年6期
程瑞鹏
(山西潞安矿业(集团)有限责任公司信息科技分公司,山西 长治 046204)
0 引言
随着计算机技术的飞速发展,DDR存储器性能也随之提高,这也意味着存储控制器工作频率也越快,而这则导致存储控制器有效数据窗口变得越来越小。数据捕获技术可以通过大数据挖掘和资源优化配置,实现数据优化挖掘和自主控制,提高数据分类管理能力。因此优化数据捕获技术,实现数据高效准确捕获对提高数据信息融合和挖掘等方面的能力具有重要意义。
1 存储控制器数据结构和提取
1.1 存储控制器数据结构
目前,计算机系统常见存储器数据宽度为64位,而大部分数据存储器具备ECC功能,在数据存储过程中就有72位来自不同SDRAM、DDR存储器数据,再加上传输长度、阻抗等参数影响,进一步增加了数据到达存储控制器的离散,导致数据同步困难,甚至可导致数据窗口消失[1]。为减少数据离散程度,实现数据的有效捕获,同时提高存储器控制器存储服务效能,建立以分布式结构为主的结构模型,并融合ACSESS存储和云存储结构,实现存储数据的信息调度和分区融合。该存储器结构模型集成了映射关系分析和数据融合两种功能,根据数据动态标签实现数据快速检测和链路设计,即将作为数据检测序列模型,利用超融合架构模型对存储控制器数据进行挖掘和分析,进而获取数据关联向量。在该结构模型下,根据Map/Reduce编程计算方法得到非结构数据库时态集合E=U/RC={Ei|i=1,2,…,n}和聚类分布模型。
(1)
式中:z为数据访问比特率,z=[z1,z2,…,zn]∈Pmn(其中zn为存储控制器数据分布状态集)。
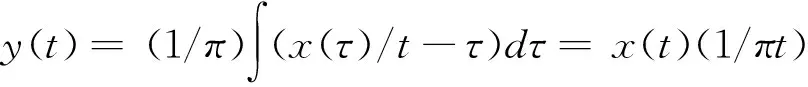
(2)
式中:τ为数据捕获延迟;d为时间;x(t)为存储控制器数据时间序列。
为准确表达超融合存储控制器数据多样性特征,重构数据库信息流特征,进而得到数据输出控制函数l(t):
(3)
式中:vn为数据传输速率;f为数据采样频率;un为数据获取时间窗口宽度。
根据上述数据访问模型,利用数据挖掘和数据频谱分析方法可以实现数据的快速、有效捕获[2]。
1.2 数据特征提取
存储控制器数据捕捉存在不确定延时影响因素和输入延时因素,并且数据传输至存储控制器寄存器的时间与核心时钟的相位关系为非固定状态,而存储控制器数据捕获需要精准的时间和有效窗口。为提高超融合存储控制器数据捕获能力,借助超融合架构建立数据特征信息流[3]。由于超融合存储控制器本身存在邻阶向量等影响因素,为消除以上干扰,利用波束冗余滤波法滤除数据传输过程中存在的干扰,进而达到提高数据分析和辨识能力的目的,超融合存储控制器数据滤波函数为:
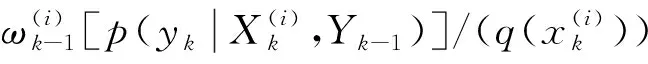
(4)
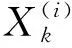
为进一步提高有效数据挖掘效率和质量,采用相位差分识别法计算数据融合误差平方,如式(5):
ε2(k)=d2(k)-2d(k)XT(k)W+
WTX(k)XT(k)W.
(5)
式中:d(k)为数据迭代次数;W为比特序列识别率。
根据式(5)建立多重假设判断标准,深入挖掘超融合存储控制器数据信息。对于数据融合和跟踪处理,采用混合差分进化法建立不同尺度下的存储控制器数据分布关联维x(t)=λRe{an(t)e-j2πfcτn(t)sl(t-τn(t))e-j2πfc},其中λ=LEQKL/LEQw+pL是频数特征值。在确定数据挖掘频数特征值和待捕获数据特征量的情况下,利用超融合方法计算存储控制器数据增益特征值:
(6)
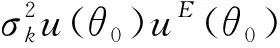
存储控制器数据融合过程中,为进一步提高数据挖掘速度和质量,建立数据融合函数:

(7)
式中:A为聚类幅值;ρ为加权系数;m为滤波器阶数;ejφ为期望值;z为随机变量zφ(0,1)。
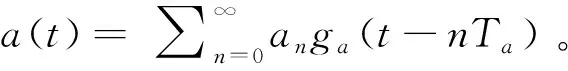
2 超融合存储控制器数据捕获优化
2.1 技术优化
根据超融合存储控制器数据模糊调度和分布结构模型,对数据捕获技术进行优化,进一步提高数据捕获精度和数据挖掘精度[6]。根据数据挖掘过程中存在的干扰信息特征,对存储控制器中的数据进行模糊调度处理,充分挖掘存储控制器中有效数据和干扰数据的信息特征和关联关系,然后按照数据序列对数据重新排序。采用数据统计融合方法,对数据进行处理,假设数据采样宽度为Tc=1/Re,则存储控制器数据高阶统计量为:
(8)
式中:cn为数据捕获过程中优化分类尺度,cn取值为1或-1;gc为数据特征值。
为简化分析过程,基于存储控制器高阶统计量,将数据挖掘问题转换为假设检验问题,如下所示:
(9)
式中:r(t)为数据指数分布;n(t)为平均统计信息量;g(t)为数据聚类中心矢量。
2.2 数据捕获
根据数据模糊分区调度和高阶统计量,计算存储控制器数据采样时间,假设采样时间间隔,结合时间开销算法计算出存储控制器数据分块匹配函数为:
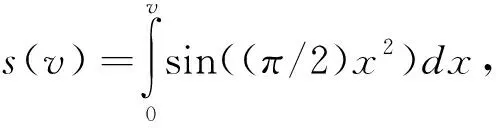
(10)
在存储控制器中,采用逆向检索方式获取有效数据,并获取数据输出状态矢量x(t)=R(a(t)eiθ(t)=a(t)cos(t)),根据该矢量算法对存储控制器中的相同信息属性和语义的数据分类,进而获得数据挖掘分类属性和特征辨识函数:
(11)
(12)
根据存储控制器数据特征、模糊分区调度和高阶统计量分析结果,得到经过优化后的存储控制器数据挖掘结果输出相频特性:
φl(f)=-[π(f-f0)2]/k+arctan[s(v2)+
s(v2)/c(v1)+c(v2)].
(13)
对超融合存储控制器数据捕获优化后,可以实现存储控制器的自我学习,并根据数据关联特征,结合数据模糊分区调度和高阶统计量分析结果,快速捕获有效数据。
3 仿真分析
为测试超融合存储控制器数据捕获效果,搭建计算机仿真平台展开测试分析,仿真平台配置包括两台10M存储控制器、云平台组件、Intel Core i5处理器等。存储控制器为Eucalyputs结构模型,通过云平台对存储控制器数据进行挖掘和捕获。数据捕获过程中,设置数据采样时间间隔为0.1 s,干扰强度为-10 dB,带宽为120 Buad。分别选取不同数量的数据块与未优化的数据捕获技术进行对比分析,以此来验证优化后的数据捕获技术的高效性和准确性。本文分别对深度学习算法标签生成方法、空间学习语义标签生成方法和本文提出大数据用户画像标签生成方法进行仿真测试。
3.1 数据辨识系数测试
表1所示存储控制器捕获技术优化前后数据辨识测试结果,从表中可以看出,采用数据模糊分区调度和高阶统计量方法对数据捕获技术进行优化后,数据辨识系数较高,并且随着数据块识别数量增加,优化后的数据辨识系数也有一定程度提升,相较于优化前的数据捕获技术,优化后的数据捕获技术在数据辨识方面的优势明显,由此可见优化后的数据捕获技术可以准确识别数据类型。
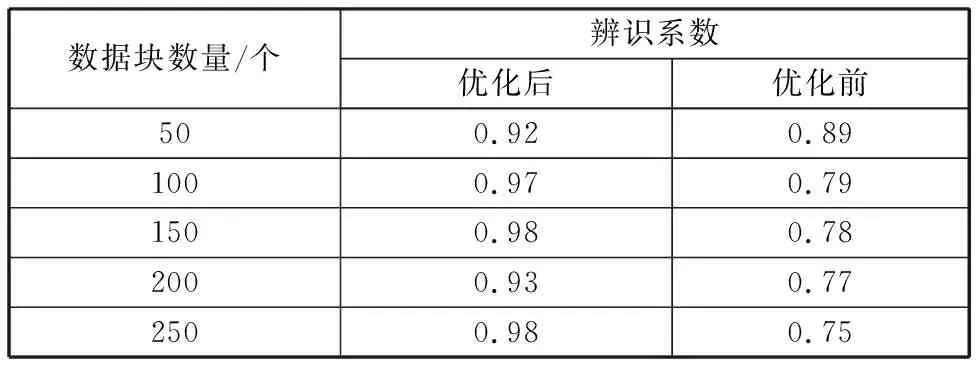
表1 存储控制器数据辨识系数测试结果
3.2 数据辨识可靠性测试
表2所示优化前后可靠性测试结果,从表中可以看出,经过优化后数据捕获技术辨识准确性明显高于优化前的数据捕获技术。本文提取了存储控制器同类数据标签特征共性,并根据提取结果对数据模糊分区调度和高阶统计量分析,实现了数据有效识别,因此经过优化后的数据捕获技术在数据辨识方面的可信度得到了一定程度的提升。
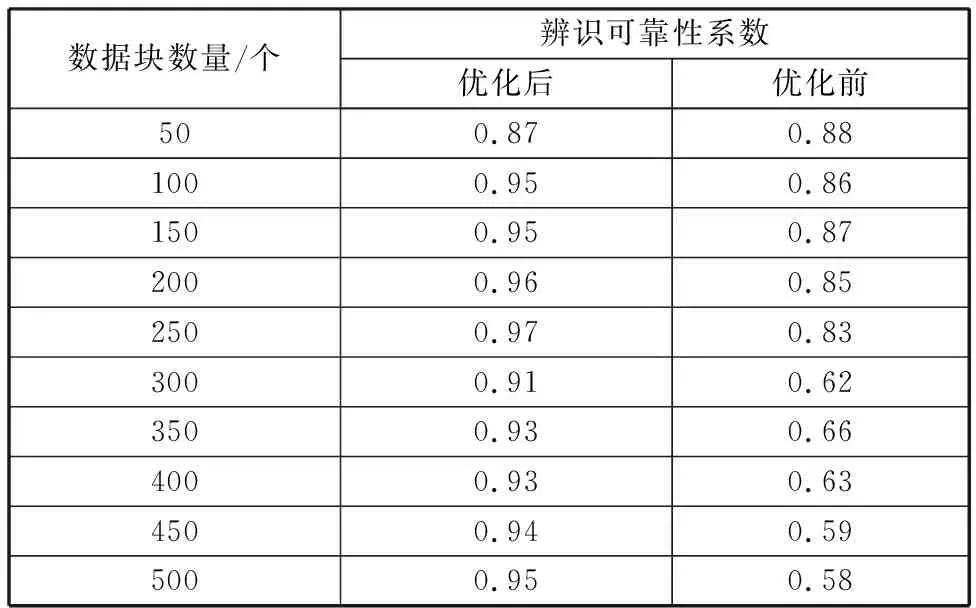
表2 数据辨识可靠性测试结果
3.3 数据捕获精度测试
表3所示数据捕获精度测试结果,从表中可以看出,经过优化后的数据捕获精度得到了一定程度的提升,并且随着数据块数量的增加,测试结果精度也有所提升。由此可见,经过优化后的数据捕获技术在数据辨识度和捕获精度方面具有较高的可靠性。
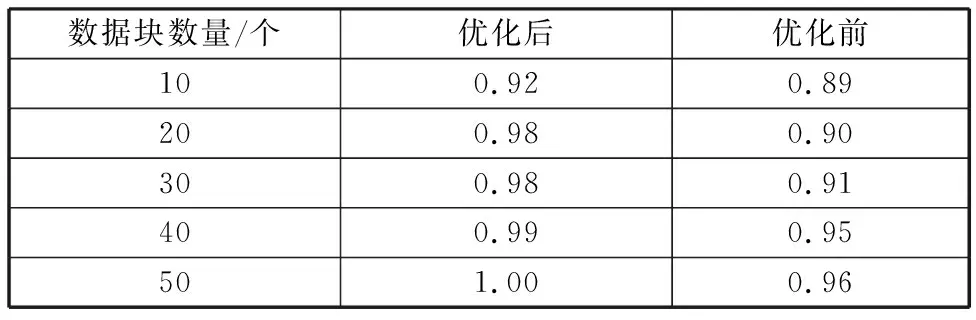
表3 数据捕获精度测试结果
4 结语
综上所述,本文研究了以超融合架构为基础的存储控制器数据分布与捕获技术,基于超融合架构建立了存储控制器数据分布结构模型,并提取了存储控制器数据特征量,根据数据特征提取结果对数据进行模糊分区调度和高阶统计量分析。为进一步提高数据捕获辨识精度和捕获精度,对干扰因素进行滤除,进而实现数据高效、准确捕获。
猜你喜欢
数学物理学报(2021年1期)2021-03-29
大众投资指南(2021年35期)2021-02-16
数学物理学报(2020年6期)2021-01-14
哈尔滨轴承(2020年1期)2020-11-03
铁道通信信号(2020年10期)2020-02-07
成都信息工程大学学报(2019年3期)2019-09-25
三门峡职业技术学院学报(2019年1期)2019-06-27
数学物理学报(2018年5期)2018-11-16
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
