
一种应用于婴儿监护的改进YOLOv5算法
2024-01-03 08:41吴志攀陈海成郑康泰林贤涛
现代计算机 2023年21期
吴志攀,陈海成,郑康泰,林贤涛
(惠州学院计算机科学与工程学院,惠州 516007)
0 引言
随着国家三孩政策的彻底放开,中国的新生儿数量也将呈现出稳定增加的态势。在家庭生活上,本来应该越来越注重于婴幼儿的呵护教育,但是由于近年来中国市场经济的迅猛发展,人们快节奏的生活也越来越成常态。家长们在家庭生活的重压之下对照顾婴幼儿常常感到力不从心。对现在年轻人而言,不仅在工作中有压力,在照顾婴儿时也需要大量的精力和时间,陪伴孩子时要小心照看,不能使之离开视线范围,导致没有多余的时间顾及其它的事情。使用婴儿监护系统,不仅可以让年轻的父母远程观看到孩子的动向和行为,而且当孩子出现身体状况异常时,可以发出警报提示提醒父母注意。这将会极大地缓解年轻父母照看婴儿的压力,具有广阔的发展前景。
人工智能(AI)被认为具有变革性和全球意义的“第四次工业革命”,包括在医疗保健、公共卫生和全球健康方面[1]。随着深度学习技术的显著发展,目标检测作为计算机视觉领域中一项重要且具有挑战性的问题备受关注[2]。在视频监控、自主驾驶、人机交互等领域,目标检测具有重要的研究意义和广泛的应用价值[3]。最被大众熟知的目标检测算法则是YOLO(you only look once)算法,YOLO 是单阶段目标检测算法的开发鼻祖,因其优越的检测速度而闻名。单阶段目标检测算法只需进行一次特征提取就可以完成目标检测,其速度相比多阶段算法迅速很多,但是相对应的精度低了些,其大多应用于实时性要求高的场景。YOLO 的应用非常广泛,无论是基于改进YOLOv5目标检测的刨花板表面缺陷实时检测[4],还是基于YOLO v5s 的通道修剪深度学习方法,用于在水果变薄之前快速准确地检测苹果果子[5]又或者是基于改进YOLOv3模型的增材制造晶格结构智能缺陷检测方法[6],都很明显地说明了YOLO优秀的实时性以及应用广泛性。YOLOv5是经过YOLO、YOLOv2、YOLOv3、YOLOv4 不断改进成就而来的,YOLOv5 的检测速度很快,每幅图片的推理时间约7 ms,也就是140 frame/s,相比于YOLO的检测速度45 frame/s,提升了三倍多。
婴儿在婴儿床、椅子或床上睡觉时可能会接触到各种危险情况。阿德莱德儿童医院的尸检和咨询档案中对30例在无人看管的情况下睡觉的婴幼儿意外窒息病例进行了审查。死亡原因包括移动到面部被遮盖且上气道闭塞的位置[7]。因此,对婴儿的危险动作进行实时识别并预警就显得十分重要了。基于YOLO目标检测算法的优秀实时性能,本研究拟使用YOLOv5目标检测算法来识别婴儿所处状况,并且对传统YOLOv5算法进行了改进,使其识别准确率有所提升。
以往的监护系统大多都是以传感器检测婴儿呼吸频率[8],又或者利用反射超声检测婴儿的呼吸[9]来对婴儿进行实时监护,虽然监护效果高效但其对用户的可视性以及交互性不友好。本系统的目标只有一个,即快速识别婴儿特定特征,通过特征识别婴儿处于哪种状态,若是危险或者婴儿伤心状态则会及时通知其父母。系统也会每秒记录婴儿的特定特征,然后直观显示给其父母,比如一星期内婴儿哪个特定特征最多,以此帮助父母照顾孩子。
本文研究的难点在于目标检测算法能否实现高效并且高准确的需求,经过实验证明YOLO目标检测算法应用于婴儿监护是有着优秀的快速性以及准确性,并且能将婴儿处于不良状况时可视化供其父母查看,与用户具有优越的交互性。
本文在方法模块讲述增添的Merge-NMS 在YOLOv5 的工作流程,在实验模块讲述传统YOLOv5与改进后的YOLOv5的性能比较,最后对基于改进的YOLOv5算法在婴儿视觉监护系统的应用进行总结。系统与用户交互过程如图1所示。
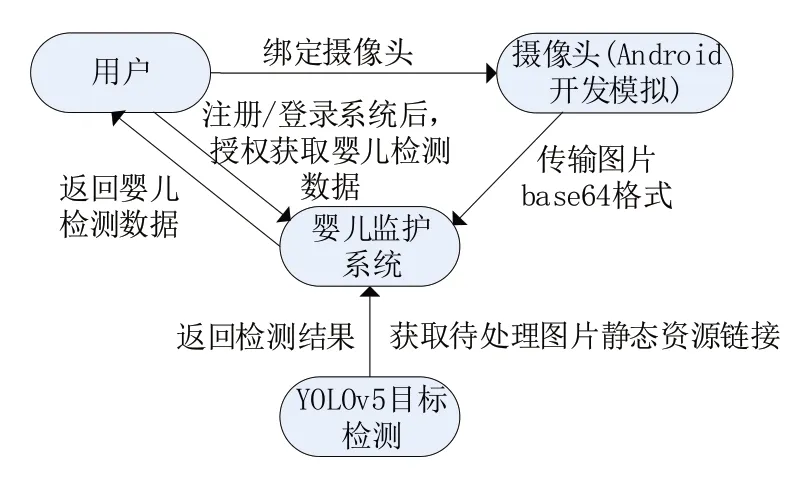
图1 系统与用户交互过程
1 方法
1.1 YOLOv5核心流程
简单来说,YOLOv5的原理是将输入的图片解析成一个个很小的网格,这些小的网格组成了相对整体的网格系统,然后对输出的每一个不同网格框中的包围框置信度以及类概率、矩阵概率进行计算,网格中的每个单元负责检测其内部的目标物体,最后,通过对输出端的过滤,排除掉重叠和低置信度的检测结果,得到最终的预测结果。其主要作用是目标检测,尤其是大目标,这是YOLOv5的优势,它能从一张图像中快速识别到目标位置所在,并且具有较高的准确性。
就目前而言,YOLOv5是一种很优秀的、先进的检测算法之一,它的性能不仅与YOLOv4不相上下,而且比模型Darknet 还要小90%左右,只有27 MB 左右。在YOLOv5 中总共提出了五种网络模型,分别为YOLOv5n、YOLOv5s、YOLOv5m、YOLOv51、YOLOv5x 等模型。在该项目中我们只采用了YOLOv5s,因为其网络最小、速度最快,能很好地满足该项目的要求。
下面介绍一下YOLOv5s的基本框架。
YOLOv5 的网络结构分为输入端、Backbone(主干网络-卷积神经网络)、Neck(一种网络层,它能够混合和组合多种图像特征,并将这些特征传递到预测层)、Prediction(预测层,也就是Head)四个部分,如图2所示。

图2 YOLOv5核心层与流程
(1)输入端:主要采用了Mosaic 数据增强,并且具有自适应锚框计算和自适应图片缩放等功能。
(2)Backbone:采用Focus结构和CSP结构。
(3)Neck:采用FPN+PAN的结构。
(4)Prediction(Head):采用GIoU_Loss 做Bounding Box的损失函数。
相关概念:
(1)Mosaic 数据增强:这是一种基于CutMix数据增强的变体形式,其主要思想是通过随机缩放、裁剪和排布的方式将图像拼接在一起,以提升对小目标的检测效果[10]。其利用四张图像进行裁剪、缩放之后,采用一定的算法进行排列组成一张图片,不仅可以丰富数据集,还可以增加样本的目标,又利用提升网格的训练速度,降低模型对内存的需求。Mosaic 数据增强流程如图3所示。

图3 Mosaic数据增强流程
(2)Backbone:内置有Focus、CSP 等结构,其最为重要的步骤就是切片操作。其中Focus是可以根据输入图片的尺寸进行切片操作以及通道拼接操作等。如输入的图像尺寸为3×4×4,经过切片和通道的变换,变成2×2×12 的图像,然后由卷积操作输出。这样操作的好处是最大程度地在保留输入信息的同时又减小了输出图像的尺寸,最重要的是可以提高该项目的推理熟读以及网格训练。Focus 切片操作以及结构示意图如图4所示。

图4 Focus切片操作以及结构示意图
(3)Neck:YOLOv5 应用的是FPN+PAN 这种双结构,其中FPN 的特点是自上而下的,使用上采样的方式对信息进行传递融合,从而获取预测的特征图;PAN 则是应用自底向上的特征,类似于金字塔的方式。YOLOv5 FPN+PAN结构如图5所示。

图5 YOLOv5 FPN+PAN结构
图5中根据金字塔网络的思想,可以知道在三种倍数,经过深层次的卷积后特征尽管有着丰富的语义特征信息,但是该方法带来了一个问题,那就是多次卷积的过程中有可能会失去一些目标信息,如位置信息。这对于小目标检测是极为不友好的。与此相反,在浅层卷积中获得的特征图虽然语义信息相对较少,但目标的位置较为清晰,正适合用来检测婴儿的行为表现。YOLOv5 特征提取模型如图6所示。
(4)Prediction(Head):YOLOv5以GIoU_Loss作为回归损失函数,这种损失函数通过改进交叉尺度的测量方式来提高性能。其中损失函数由定位损失、置信损失和类别损失三部分构成。
基于上述描述的五种模型中实时性需求,本系统采用YOLOv5s 模型,这一模型具有模型最小(大小仅为14 MB),检测速度最快(识别图片速度达到2.2 ms)的特点。
1.2 YOLOv5改进
传统YOLOv5 使用原始NMS 做后处理,NMS 流程如图7 所示。尽管可以快速去除重合度很高的、目标定相对不准确的预测框,但对重合度很高的目标就不友好了。例如,多个人在一起的时候,某人只露出半张脸,NMS 就难以对目标进行识别了。
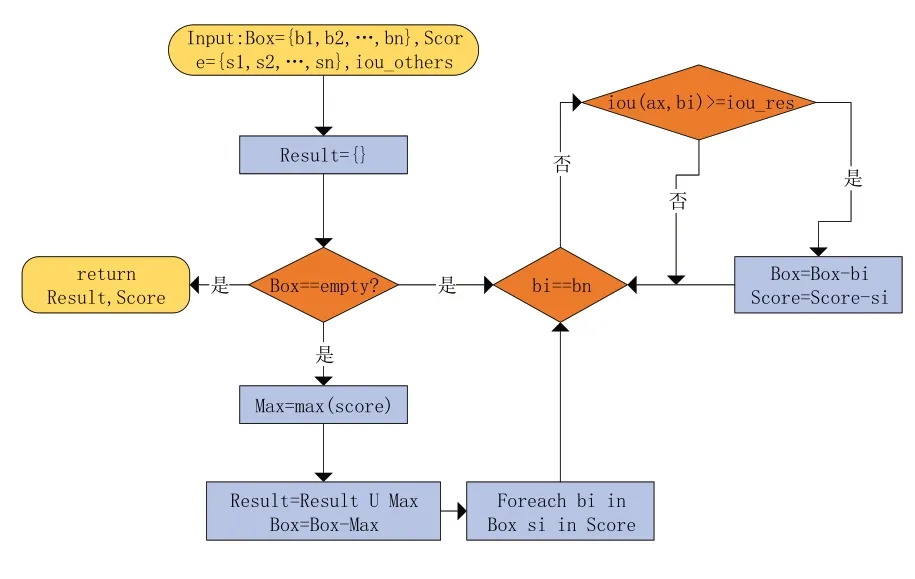
图7 NMS流程
在原始YOLOv5基础上对所对应的Prediction层的NMS 非极大值抑制检测算法去除大量重叠框后,在得到结果的基础上,通过引入保留框位置平滑策略,也就是对重叠框的位置信息的平均计算进行求解,可以提高框的准确性和稳定性。核心就是重视权重更高的预测框(即NMS处理后的结果),同时也要关注其他预测框(被NMS 淘汰的),这就是Merge-NMS,其流程如图8所示。Merge-NMS相比于NMS对重复框更为友好,对预测框处理的结果更为准确。

图8 Merge-NMS流程
一张婴儿图片中可能涉及多个特征标签,比如婴儿躺着并笑着,这就涉及到“躺着”以及“笑着”两个标签,但是二者没有逻辑关系,所以改进后的YOLOv5在本系统的场景下要排除多标签的干扰,这里简单采用一阶策略,即忽略标签之间的相关性,标签与标签之间不相关。
2 实验
2.1 实验数据集
数据集在目标检测算法性能评估和比较中扮演着重要角色,同时也是推动目标检测向更加复杂和实用方向发展的强大动力[3]。
本文数据集来自网络婴儿行为视频截取的图片,共1321 张与婴儿相关的高质量图片,涉及婴儿的爬动(creep)、反躺(lie_down)、正躺(lie)、坐着(sit)、站着(stand)、平静(calm)、开心(happy)、伤心(cry)这八种特征标签,并且保证每类标签至少出现100次。训练标签数据集以及总特征标签数见表1。

表1 训练标签数据集以及总特征标签数
2.2 YOLOv5性能指标
精确率(Precision,P):即所有预测为正样本的结果中,预测正确的比例。
其中:TP(True Positive),表示正确预测为正样本的数量;FP(False Positive),表示错误预测为正样本的数量;FN(False Negative),表示错误预测为负样本的数量;TN(True Negative),表示正确预测为负样本的数量。
召回率(Recall,R):所有正样本中被正确预测的比率。
Precision Recall(PR)曲线:是以召回率(Recall)为横坐标,精确率(Precision)为纵坐标绘制的曲线。
平均精度(Average Precision,AP):PR 曲线下面积。
Mean Average Precision(mAP):各类别AP的平均值。
Mean Average Precision@0.5(mAP@0.5):即在IoU=0.5下的mAP。
Mean Average Precision@0.5∶0.95(mAP@0.5∶0.95):表示在IoU=[0.5,0.95]区间,步长为0.05上的mAP之和求平均。
最终以mAP@0.5∶0.95 的大小来比较权衡模型优次。
3 结果
图9 所示为优化前后的YOLOv5 数据对比,可以看出优化后的mAP@0.5∶0.95 优于原始的YOLOv5。图10 更为直观地显示了改进前后的mAP@0.5∶0.95 比较,其优化增加的百分比见表2,其中总体特征标签mAP@0.5∶0.95 增加了2.7个百分点,优化幅度最大的特征标签为creep(爬动),提升了4.0 个百分点;优化幅度最小的则是cry(伤心),只提升了2.1个百分点。

表2 YOLOv5改进前后mAP@0.5∶0.95在各个标签上的提升百分比

图9 YOLOv5改进前后的训练结果
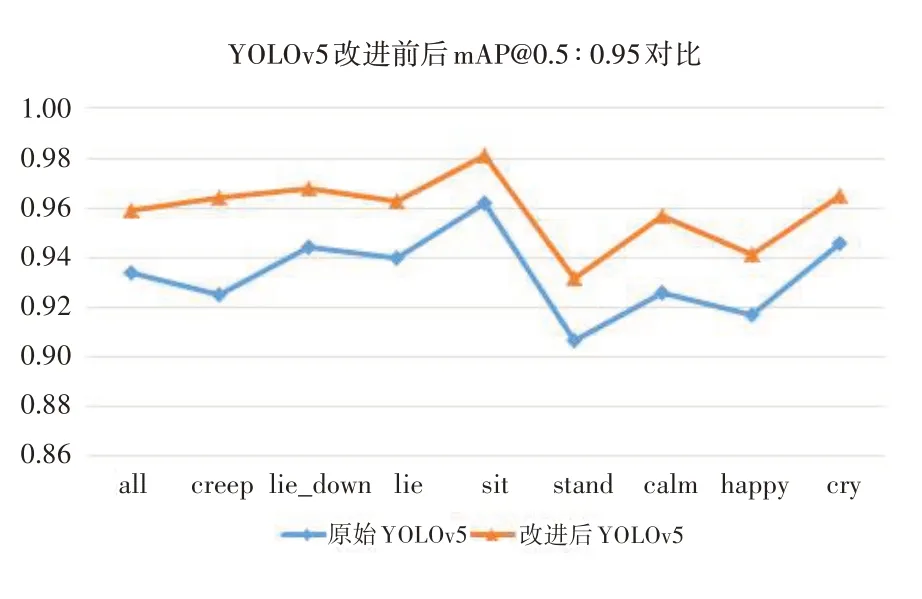
图10 YOLOv5改进前后mAP@0.5∶0.95在各个标签上的对比
如图11 所示,原始YOLOv5 训练后的模型只识别出婴儿爬动的特征,却没有识别出婴儿的标签特征,比如开心特征。改进后的YOLOv5训练后的模型识别出图片中婴儿有爬动、开心的特征标签,基本符合系统的所需要求。

图11 YOLOv5改进前后的预测结果示例
4 结语
改进后的YOLOv5更加符合系统所需,即识别出婴儿更多特征,有了这些特征就能更好地辅助系统做出决策,来决定是否需要提醒父母。通过在原始YOLOv5 的NMS 非极大值限制基础上对预测框进行Merge-NMS,使得预测框结果更为平滑。此算法的改进有助于婴儿视觉监护系统更加正确地检测婴儿所处状况,由于系统所需的实时性,此系统采用的模型是YOLOv5s。
本系统训练的数据量为1321 张,数据量相对较小,未来若使系统为大众服务,朝着更加精确快速的方向发展,需要收集大量的数据。有了更多的图片就能再次训练出多个模型,然后系统结合框融合算法对多个模型的预测结果进行融框,而不是直接替换已经训练完成的模型,这样综合多个模型的预测结果可以用来增强预测的准确性。
猜你喜欢
英语世界(2023年10期)2023-11-17
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
数学年刊A辑(中文版)(2019年3期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2017年6期)2017-11-23
数位时尚(幼儿教育)(2016年9期)2016-10-15
浙江大学学报(工学版)(2016年10期)2016-06-05
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
