
基于VAR模型的多元时间序列预测研究
2024-01-03 08:41张安妮娄立都胡欣雨
现代计算机 2023年21期
张安妮,周 晓,娄立都,胡欣雨
(南华大学计算机学院,衡阳 421000)
0 引言
时间序列是按照时间排序的随机变量集合,通常在相等间隔的时间段内以给定的采样率对某种潜在过程进行观测[1]。时间序列预测可分为单变量预测和多变量预测[2]。在单变量预测中,每次分析时序数据集时独立进行序列,不交叉学习。ARIMA(autoregressive integrated moving average)模型因其丰富的统计基础和Box-Jenkins方法的选择过程而备受青睐[3]。
多元时间序列预测广泛应用于交通、能源、经济学等领域[4-6]。在多元时间序列建模中,变量的预测不仅与它们自身的历史值有关,还受到其他变量的影响。这种影响可能是直接的,也可能是间接的。例如,在一个城市的温度预测中,不仅要考虑该城市过去的温度,还需要考虑周围城市的温度对该城市的影响。VAR(vector autoregressive)模型作为一种早期多维时间序列的分析方法,可以用来探究多个相关联的经济变量之间的动态关系[7]。
为了进一步研究序列之间的相关性是否会对VAR 模型预测结果产生影响,采用传统ARIMA和VAR方法,对给定的中国银行数据(开盘价Open、最高价High、最低价Low、关盘价Close和成交量Volume)进行多元时间序列预测。
1 数据与方法
1.1 数据集选择
本次我们选择网上公开的2014年1月1日至2014 年4 年30 日(即1~4 月)中国银行数据,将其划分为训练集(1~3 月数据)和测试集(4 月数据)。
1.2 ARMIA模型
ARIMA(p,d,q)模型全称为差分自回归移动平均模型,其中AR 是自回归,p是自回归项;MA是移动平均,q是移动平均项数;d是时间序列变得平稳时所做的差分次数[8]。
ARIMA(p,d,q)模型是ARMA(p,q)模型的扩展。ARIMA(p,d,q)模型可以表示为
其中,L是滞后算子(Lag operator),d∈Z,d>0。
1.3 VAR模型
向量自回归模型,简称VAR 模型[9],是AR模型的推广,是一种常用的计量经济模型,是AR 模型的扩展。它由克里斯托弗·西姆斯于1980 年提出。VAR 模型考虑了多个变量之间的相互影响,因此比单纯的AR 模型更为全面。在某些条件下,多元MA和ARMA模型也可以转化成VAR 模型。在VAR 模型中,每个变量都被回归到所有变量的当前值和滞后值上。
模型的基本形式是弱平稳过程的自回归表达式,描述的是在同一样本期间内的若干变量可以作为它们过去值的线性函数。
其中,Yt表示k维内生变量列向量,Yt-1,i=1,2,…,p为滞后的内生变量,Yt表示d维外生变量列向量,p和T分别是滞后阶数和样本个数,ϕi即ϕ1,ϕ2,…,ϕp为k×k维的待估矩阵,B为k×d维的待估矩阵,εt~N(0, Σ)为k维白噪声向量。
2 具体实现
2.1 总体技术路线
为了更直观地展示实验过程,总体技术路线如图1所示。

图1 总体技术路线
2.2 原数据可视化
先将2014 年1 月1 日至2014 年4 年30 日(即1~4 月)的所有指标(即Open,High,Low,Close,Volume)数据可视化,如图2所示。
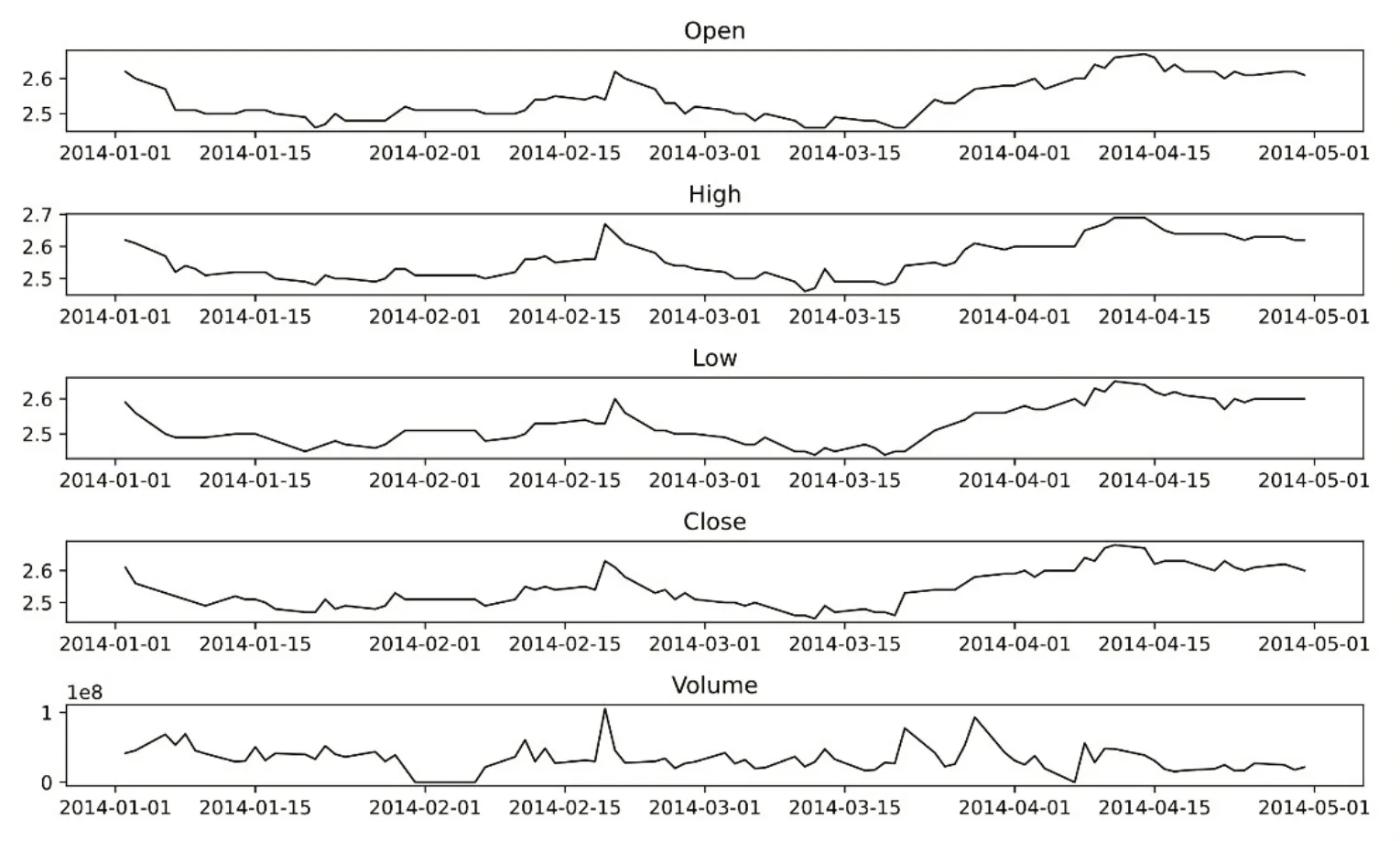
图2 ChinaBank数据可视化
2.3 因果分析
本次选择VAR 做预测,首先对五个序列进行因果分析。结果见表1。

表1 因果分析表格
如果p值小于0.05,则表明存在格兰杰因果性[10]。从结果来看,Open、High、Low 和Close是存在因果关系的,但是Volume 跟这四个指标之间的因果关系不大。因此可以将前面四个和最后一个序列分开预测。
2.4 ADF检验
在进行实验之前,有必要先检查单个变量的稳定性。虽然从可视化过程中也可以看出这几个序列不稳定,但为了更科学地判断,本文对数据进行了ADF测试。结果表明:前四组序列是不平稳的,只有“Volume”序列是稳定的。因此,将这两个序列分开预测能够更加合理和准确。
2.5 VAR+ARIMA模型建立和预测
由于前四个序列都不平稳,首先对前面四个序列使用VAR预测。对这四个序列做协整检验,看是否存在线性组合平稳。结果如图3所示。
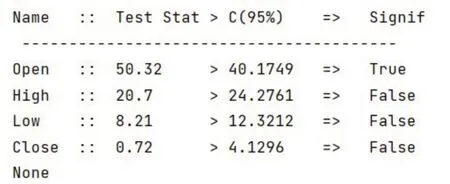
图3 前四个序列协整检验
由图3可知,不存在线性组合。因此需要先差分使它们平稳。划分训练集(1~3 月数据)和测试集(4月数据)。对训练集全部进行一阶差分之后重新进行ADF 检验,发现四个一阶差分序列平稳,之后再建立模型并训练。
模型建立需要根据AIC 值做模型测试,从结果发现lag=6 时达到局部最优,且拟合结果较好,因此选择lag=6 建立模型。然后检验残差项中是否还存在相关性,这一步的目的是确保模型已经解释了数据中所有的方差和模式,检验值越接近2,说明模型越好。结果见表2。

表2 前四个序列残差检验表
从表2 可以看出,结果都接近2,说明模型可以用于下一步预测。根据检验数据,完全有理由使用VAR模型进行预测,将差分结果还原,得到前四个序列最终的预测结果。
单独对“Volume”进行预测。重新导入数据,并且划分训练集和测试集。因为之前已经对“Volume”序列做过ADF 检验,确定是平稳序列,所以这里直接使用训练集数据通过ACF和PACF判断参数。结果如图4所示。

图4 Volume序列ADF和PADF检验
从图4可以发现是零阶,所以采用遍历寻优的方法,选择BIC 的最小值作为模型参数,经测试,选择AR1 和MA0 作为模型参数。使用训练集训练ARIMA(1,0,0)模型,对结果进行预测,将结果可视化,如图5所示。

图5 ARIMA预测Volume可视化
2.6 VAR模型建立和预测
基于最初的ADF 检验,首先对五个序列做一次协整检验,结果表明:不存在使序列平稳的线性组合。
对训练集前四个序列进行差分,然后将差分之后的结果重新与第五个序列做拼接。之后对五个序列重新进行ADF 检验,五个序列全部平稳。根据AIC值,做模型测试,结果表明lag=2 时达到局部最优,所以选择lag=2,拟合效果好。检查残差项发现其结果都接近2,说明模型可用于进行下一步预测。根据检验数据,完全有理由使用VAR 模型。使用VAR 预测,并将前面四个序列的差分结果还原,最后得到原始数据和预测数据,估计预测误差。
3 结果
3.1 评价指标
假设A和B分别为真实值矩阵和预测值矩阵,都是n× 5 的矩阵,用下面公式评价预测误差:
3.2 对比实验结果
本文进行了VAR+ARIMA 模型和纯VAR 模型实验。通过评价指标计算最后预测偏差和,结果见表3。

表3 模型偏差和对比
对于前四个序列,纯VAR 模型的偏差和平均达到0.9,VAR+ARIMA 模型对应值平均为0.5,结果表明:VAR+ARIMA 模型结合了VAR模型和ARIMA 模型的优点,能够更好地捕捉多个变量之间的相互影响以及时间序列的季节性和趋势性。对于没有因果关系的Volume 序列,强行加入前四个序列采用VAR 直接预测反而影响预测精度。
4 结语
本文通过对中国银行数据进行多元时间序列分析,探究因果时序采用VAR 模型做预测的影响,得到结果如下:
(1)通过对比具有因果关系前四组序列和不具因果关系第五组序列预测偏差发现,具有因果关系的序列组预测效果更佳。
(2)相反,非因果序列的预测效果可能会受到影响,并且还可能导致因果序列的拟合效果下降。这是因为非因果序列中的变量可能会引入噪声或误差,从而干扰因果序列中变量之间的真实关系。
此外,本实验存在一些不足之处,比如:本文只使用了一种数据集进行多元时间序列分析,因此结果可能受到数据集的限制。同时,数据集中可能存在一些噪声或错误数据,这可能会影响到分析结果的准确性。但是结果仍然具有一定的参考价值。在将来的研究中,可以通过增加数据集的数量、提高数据集的质量、选择更适合的模型、正确判断因果关系以及增加样本的代表性等方式来改进研究方法,提高分析结果的可靠性和泛化能力。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
新世纪智能(数学备考)(2021年5期)2021-07-28
南大法学(2021年6期)2021-04-19
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
高中生·天天向上(2018年7期)2018-07-23
湘江法律评论(2016年0期)2016-06-15
信息安全研究(2015年3期)2015-02-28
中国检察官(2015年12期)2015-02-27
