
基于大数据的电商数据仓库可视化平台的设计与实现
2024-01-03 08:42吴宪传吴绍荣颜远海
现代计算机 2023年21期
吴宪传,吴绍荣,颜远海
(广州华商学院数据科学学院,广州 511300)
0 引言
随着电子商务迅猛发展,各类电商网站、电商APP 不断涌现,电商企业对电子商务信息需求逐渐增多。怎样提高用户商品复购率,如何判断用户消费偏向等问题成为电商企业面临的难题。电商企业产生海量数据,企业需要对数据进行有效管理,并对数据进行分析与提取。在数据处理方面,电商企业已经开始使用大数据技术处理数据,并且大数据相关的生态技术也在持续更新中。
电商数据仓库可以支持电商企业决策分析,制定策略。通过收集用户行为数据和业务数据进行ETL 处理,提取有用主题信息,提高电商企业市场竞争力,推进电子商务智能化发展。在国内,大部分中小型公司并没有自己的数据仓库系统,往往采用阿里云或华为云等大数据一站式解决方案。数据仓库是致力于从纷繁复杂的数据中抽取有用的决策信息,从而帮助企业更好制定解决策略。基于上述问题,本文提出利用大数据技术实现对电商数据仓库平台数据可视化展示,为中小型企业及管理者更好了解和掌握实时的动态数据,并为更好制定方案和策略提供有效参考。
1 电商数据仓库可视化平台研究
1.1 系统采用的相关技术简介
(1)HDFS。 HDFS(hadoop distributed file system)是Apache Hadoop 的核心组件之一,是一个分布式文件系统,用于存储和处理大规模数据集。它是为了解决大规模数据处理问题而设计的,HDFS 的设计思想是分块存储。同时,HDFS 还提供了数据冗余备份机制,可以在数据节点出现故障时自动恢复数据。HDFS 广泛应用于大数据处理、机器学习、数据挖掘等领域,是构建大规模数据处理平台的重要组成部分。
(2)MapReduce。MapReduce 的核心思想是“分而治之”,即将一个大而复杂的问题分解为多个小而简单的问题,先解决多个小问题,再把多个小问题的结果组成大问题的结果。MapReduce 作为一种分布式计算框架,主要用于解决海量数据的计算问题。MapReduce 计算过程可以分为两个阶段:Map 阶段和Reduce 阶段[1]。其中,Map阶段负责将大任务分解为多个小任务,Reduce 阶段负责将多个小任务的结果合并。
(3)YARN。ApacheHadoopYARN(yetanother resource negotiator),即另一种资源协调者,是一个通用资源管理系统和调度平台,基本思想是将Hadoop1.0的MR中的jobTracker拆分为两个独立的任务,即ResourceManager 和Application-Master。
(4)Zookeeper。Zookeeper 是一个分布式协调服务的开源框架,它主要用来解决分布式集群中应用系统的一致性问题,避免造成数据脏读的问题[2]。它将所有的数据存储在内存中,因此具有非常高的读写性能。
Zookeeper 的架构采用了主从模式,其中一个节点作为主节点,负责协调所有的从节点。Zookeeper还提供了一些高级功能,如事务支持、观察者模式等。
(5)Kafka。Apache Kafka 是一种高吞吐量分布式发布订阅消息系统,它可以消费所有动作流数据,例如实时日志、事件、消息等。Kafka 可以用于构建实时系统,支持实时数据处理、数据流处理、日志处理和消息队列等。
(6)Flume。Apache Flume 的核心是通过数据采集器把数据从数据源(source)收集过来,再将收集的数据通过缓冲通道(channel)汇集到指定的接收器(sink)[3]。Flume可以将日志数据从一个系统节点流传输到另外一个系统节点,可以实现数据的采集、聚合和传输。Flume采用了“源-汇”模型,即每个源(source)将数据发送到一个或多个汇(sink),汇将数据写入指定的目的地。
Flume是流式日志采集工具,能够提供从本地文件、实时日志、Kafka 等数据源上收集数据的能力。
(7)Sqoop。Sqoop 主要用于在Hadoop 和关系数据库或大型机器之间传输数据,其目的是让Hadoop 开发人员可以轻松访问和分析传统数据库中的数据。Sqoop 使用MapReduce 编程模型来实现,能够将数据从关系型数据库管理系统导入到Hadoop 分布式文件系统中,或者将Hadoop 中的数据导出到关系型数据库管理系统(MySQL)[4]。
(8)Hive。Apache Hive是底层封装了Hadoop的数据仓库处理工具,它运行在Hadoop 基础上,定义了简单类SQL 查询语言HQL。它可以将HQL 语言转换为MR 任务,在Hadoop 集群上运行,也可以通过Hadoop 执行其他编程语言来操作和分析大数据集,如Java、Perl、Python等。Hive 的优势在于它可以快速轻松地处理大量数据。它也可以与其他Hadoop 组件一起使用,如Pig、HBase等,以构建大型数据分析系统。
1.2 系统的功能设计
电商数据仓库系统主要功能包括数据采集模块、数据仓库模块和数据可视化模块,如图1所示。

图1 电商数据仓库系统功能模块
1.2.1 数据采集功能
数据采集是指收集数据的过程。将各种不同来源的数据收集和整理以便进行数据分析的重要步骤。
电商数据仓库系统数据源主要是收集和分析所得的用户行为数据[5]。页面数据主要记录一个页面的用户访问情况,包括用户点击的时间、点击后停留的时间、页面的路径等信息[6]。所有页面表有“首页”“分类页”“发现页”“热门排行”“搜索页”和“商品列表页”等字段,所有页面对象类型表有“商品skuId”“搜索关键词”“多个商品skuId”“活动id”和“购物券id”等字段, 所有来源类型表有“商品推厂”“算法推荐商品”“查询结果商品”和“促销活动”等字段。
事件数据主要记录用户的操作行为,包括用户操作的类型、用户操作的对象、用户操作对象的描述等信息。用户操作的类型表有“favor_add”“favor_canel”“cart_add”“cart_remove”“cart_add_num”“cart_minus_num”“trade_add_address”和“get_coupon”等字段,具体见表1。用户操作的对象表有“商品”和“购物券”等字段。

表1 用户操作的类型
曝光数据主要记录APP 页面曝光的内容,包括APP 页面曝光对象,APP 页面曝光类型等信息。所有曝光类型表有“商品推厂”“算法推荐商品”“查询结果商品”和“促销活动”等字段,所有曝光对象类型表有“商品skuId”和活动“id字段”。
启动数据记录APP 的启动信息。所有启动入口类型表有“图标”“通知”和“安装后启动”等字段。
错误数据记录APP 使用过程中的错误信息,所有错误信息类型表“错误编号”和“错误信息”等字段。
1.2.2 数据仓库模块
电商数据仓库系统是从大量的数据中快速获取有效价值数据的系统[7]。通过收集企业各种内部信息和外部信息,对数据进行抽取、清理和有效集成,同时多角度、多层次分析,发现数据规律和趋势。
电商数据仓库系统主要是面对海量的数据,提供复杂的分析操作,帮助企业决策人员、高级管理人员决策支持,并且能够提供直观易懂的查询结果。
1.2.3 数据可视化模块
电商数据可视化需要将数据转化为图形或图像,通过建模、表面、立体、动画等展示,对数据进行可视化解释,让企业决策者可以通过图形或图像直观地看到数据分析的结果,更容易地理解业务变化趋势。更快地发现市场需求变化,获得更多信息,提高市场份额。
2 数据仓库系统总体设计
2.1 系统总体架构
电商数据仓库系统架构,采用大数据主流框架技术,尤其是用户行为数据采用了Flume-Kafka-Flume框架,如图2所示。

图2 电商数据仓库系统架构
2.2 数据采集模块设计
数据采集模块主要实现两个需求,将用户行为日志数据导入到HDFS和将数据库管理系统中的业务数据导入到HDFS。
将用户行为日志数据导入HDFS 采用了Flume 和Kafka 框架,设计了两层Flume 中间加一个Kafka 集群的结构。第一层用多个Flume 采集日志文件,防止压力过大,保持服务器的负载均衡。第二层Flume 从第一层Flume 里采集数据传输到HDFS 里。但是如果第一层Flume 在某一时间采集的数据量过大,将会导致第二层Flume无法及时处理数据,就会因消息太多导致拒绝服务以及网络拥塞。所以又在两层Flume中间加了一个Kafka集群作为缓冲区。
将数据库管理系统中的业务数据导入HDFS使用的是Sqoop 工具[8]。Sqoop 是Hadoop 生态圈的一部分,将导入导出的命令翻译成MR程序来执行[9],通过JDBC 与数据库进行交互,整个过程是完全自动化的,从而实现高效的传输数据。
2.3 数据仓库设计
电商数据仓库是针对电商企业的数据分析和决策,需要考虑数据清洗、建立维度和度量、以及保证数据的质量和安全。在清洗数据方面,需要筛选掉一些噪声和无效数据;在建立维度和度量方面,需要选择合适的指标和数据类型;在数据质量和安全方面,需要设置权限、控制交互和确保数据的完整性和一致性。
电商数据仓库还需要考虑具体的业务需求,提供定制的数据分析和决策支持。比如,可以针对销售数据进行多维分析,了解产品的销售情况、用户的购买行为、销售渠道的效果等;也可以进行数据挖掘,发掘用户的兴趣点和购物习惯,并根据这些信息进行推荐或者趋势预测等。
本系统的数据仓库分为以下几部分:
(1)ODS(operational data store)层。
ODS 层是电商数据仓库架构中最基础和重要的一层[9],主要承担将业务系统中的数据实时抽取、清洗和转换,为DW(data warehouse)层提供数据源的功能。ODS 层所采用的数据模式需要和业务系统一致,并且不对数据作任何修改,以保证数据的一致性。此外,ODS 层还需要对数据进行实时监控和异常处理,确保数据的正确性和及时性。
ODS 层的主要功能包括:①数据抽取:ODS 层通过多种方式,如JDBC、API 等将数据抽取到ODS 层;②数据清洗:ODS 层需要对抽取到的数据进行清洗、格式化、数据类型转换等处理,并筛选掉无效数据和异常数据;③数据集成:ODS 层需要将来自多个业务系统的数据进行集成,形成一个完整的数据源;④数据传输:ODS 层需提供实时数据传输的功能,将业务系统中的数据及时传输到数据仓库中,以保证数据的及时性和准确性。
ODS 层是电商数据仓库中至关重要的一层,它不仅是数据仓库架构中的数据源,还是实现数据清洗、转换、集成和传输的关键。只有建立了高效、可靠的ODS 层,才能为企业的数据分析和决策提供稳定可靠的数据。
(2)DWD(data warehouse detail)层。
DWD 层是数据仓库架构中的核心层次,它负责接受和整合ODS 层的数据,并根据业务分析需求进行处理和建模,构建出符合业务需求和分析要求的数据模型。
DWD 层的主要任务包括:①数据建模:DWD 层根据业务分析需求建立合适的数据模型,包括维度模型(dimensional model)和实体关系模型(entity-relation model);②数据质量控制:DWD 层可以对数据进行质量控制,包括数据清洗、数据去重、数据过滤等,保证数据的准确性和一致性;③数据存储:DWD 层将整理后的数据存储在数据仓库中,为后续的多维分析和数据挖掘提供支持。
DWD 层是电商数据仓库中数据处理的重要部分,负责管理事实表和维度表,提供数据的逻辑处理和建模,确保数据的质量和可用性,为后续的分析和决策提供高质量的数据。
(3)DWS(data warehouse summary)层。
DWS 层是数据仓库架构中分析和决策的数据来源。DWS层通过对DWD 层中整合、清洗后的数据进行加工、计算和汇总,得出更高层次的聚合数据,以支持更广泛的业务分析和决策。
DWS 层的主要任务包括:①数据汇总:DWS 层需要生成更高层次的报表和指标,以支持经理层级和高层管理层级的决策需求;②数据加工:DWS 层根据特定的业务需求,对数据进行加工、计算和转换,得到更加精准和实用的指标和分析结果;③数据建模:DWS 层根据具体的决策需求建立决策支持模型,为决策提供清晰、准确的图像和指南。
DWS 层的数据模型和数据加工方式需要根据具体的业务需求和分析目标进行设计和调整。它承担着向上级管理层提供决策支持的重要功能,因此需要在保持数据准确性和一致性的基础上,更加注重数据的实用性和可解释性。
(4)DWT(data warehouse transform)层。
DWT 层通常是指汇总历史数据的层次,它不同于DWS 层,不是用于决策支持,而是用于历史数据的存储和管理。DWT 层中的数据是基于DWS 层的数据计算出来的,通常是每天或每周的数据汇总,或者是对某个时间段内的数据进行汇总。
DWT 层的主要功能包括:①数据汇总:DWT 层负责对DWS 层的数据进行时间段的汇总和聚合,形成历史数据的总体框架和趋势;②数据质量校准:DWT 层需要对汇总后的数据进行质量控制,确保数据的正确性和一致性;③数据管理:DWT层需要对历史数据进行管理,包括数据的备份、恢复、迁移、清理等。
DWT 层主要用于历史数据的存储和管理,通常不直接用于业务分析和决策。与DWS 层不同,它强调数据的历史性和可追溯性,为企业提供可靠的历史数据支持,因此也是数据仓库架构中的重要组成部分。
(5)ADS(analytic data store)层。
ADS 层是电商数据仓库的数据展示层,是电商数据仓库系统中的一个重要组成部分,旨在为业务分析和智能决策提供高性能、高可靠、高可扩展的数据查询服务,帮助电商企业快速发现业务趋势和问题。
在ADS 层中,数据会被预处理和加工,生成适合各种数据分析需求的数据模型。通俗地说,ADS 层就是我们平时所说的BI 系统,提供了各种分析指标和图形化界面,便于业务人员进行数据分析和决策。ADS 层是电商数据仓库的核心部分之一,是企业业务决策的重要依据。通过ADS 的分析,企业可以及时发现问题和机遇,制定更好的业务策略和决策。
2.4 数据可视化模块设计
Apache Superset 工具能够对接许多数据源,如Hive、MySQL等,并且操作简单。同时Superset拥有较多图标、图形,支持使用仪表盘工具,拥有可简易操作的UI界面。所以可以使用Superset对数据仓库进行可视化展示。
2.5 服务器规划设计
大数据生态组件安装在服务器上,需要考虑的因素有:①需要消耗内存的组件安装在不同的服务器上,避免造成服务器内存溢出或内存不足;②需要多次传输数据的多个组件安装在同一台服务器上,提高数据传输的速度,例如Flume-Kafka-Flume、Zookeeper 等。本系统的大数据生态组件和服务器规划见表2。

表2 大数据生态组件服务器规划
3 数据仓库系统实现
3.1 数据采集详细实现
如图3 所示,数据存储在HDFS 上需要搭建一个Hadoop 集群。实现采集模块的日志数据采集需要搭建两层Flume、一个Zookeeper 集群、一个Kafka 集群。实现业务数据采集需要部署Sqoop框架。

图3 数据采集模块架构
3.1.1 Hadoop集群实现
Hadoop 中的HDFS 起到海量数据的高效存储,而YARN 是本系统需要的资源调度框架。如图4 所示的Java 进程均说明Hadoop 集群成功启动。

图4 Hadoop成功启动后的所有进程
成功启动集群之后,可以分别查看HDFS的Web 页面、SecondaryNameNode 的Web 页面、YARN 的Web 页面,具体如图5、图6、图7 所示。

图5 HDFS的Web页面

图6 SecondaryNameNode 的Web页面

图7 YARN的Web页面
3.1.2 Zookeeper集群实现
部署完成之后启动Zookeeper集群。如图8所示的Java进程均说明Zookeeper集群成功启动。

图8 Zookeeper成功启动后的所有进程
3.1.3 Kafka集群实现
部署完成之后启动Kafka 集群。如图9 所示的Java进程均说明Kafka集群成功启动。
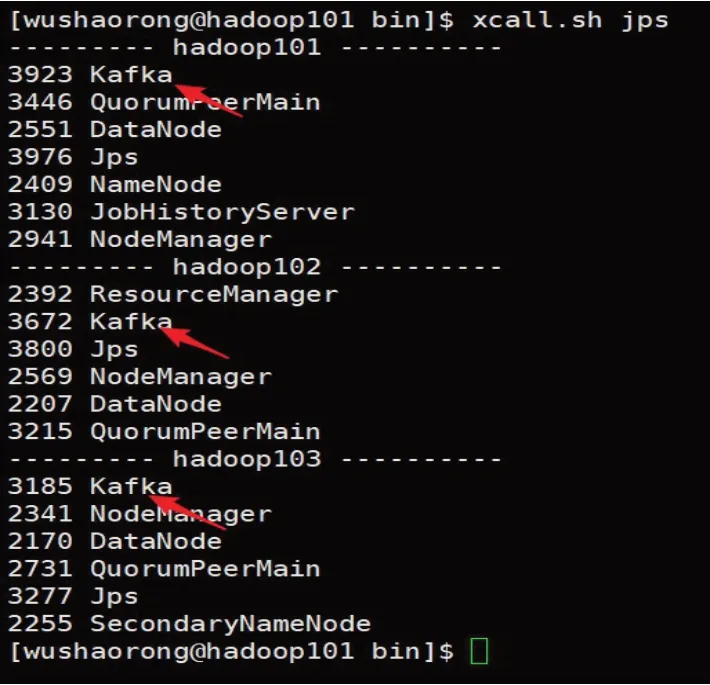
图9 Kafka成功启动后的所有进程
3.1.4 采集层Flume实现
部署完成之后启动采集层Flume。如图10所示的Java进程均说明采集层Flume成功启动。
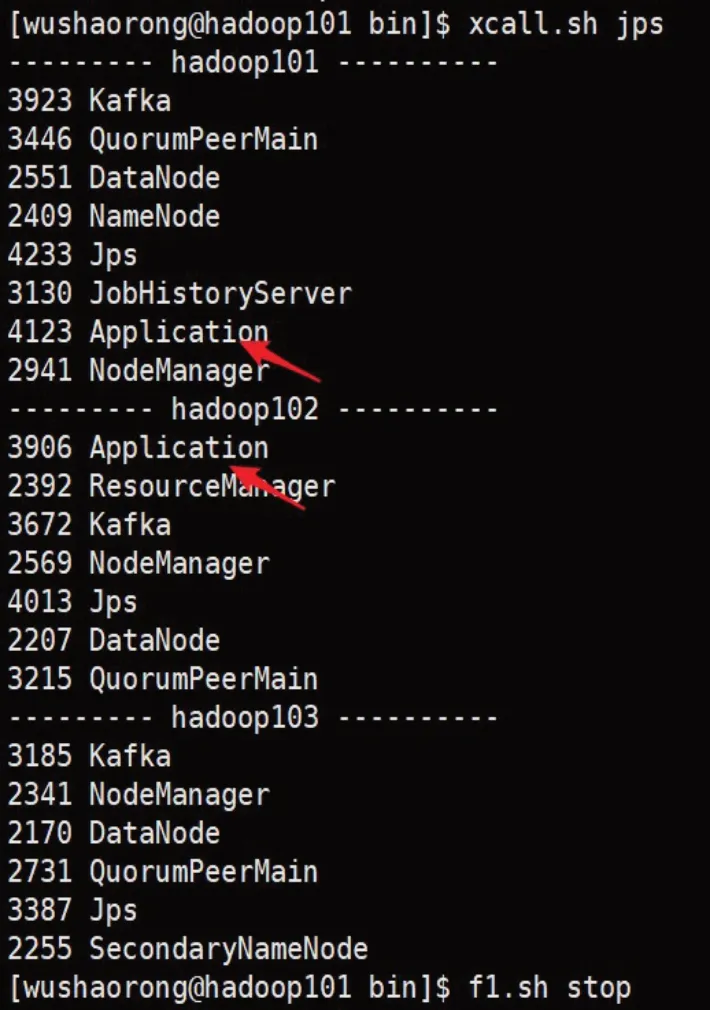
图10 采集层Flume成功启动后的所有进程
3.1.5 消费层Flume实现
部署完成之后启动消费层Flume。如图11所示的Java进程均说明消费层Flume成功启动。
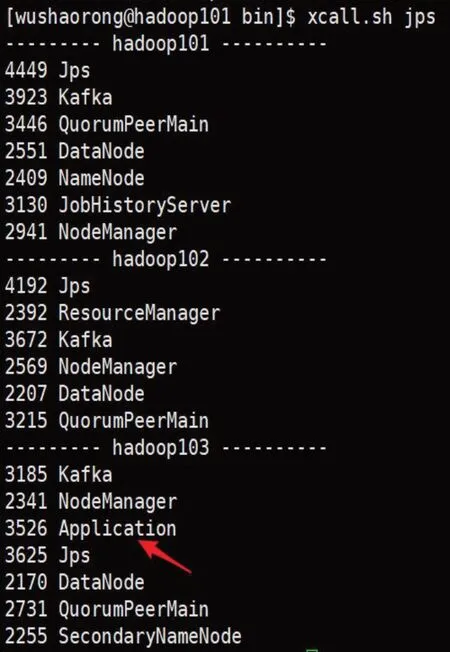
图11 消费层Flume成功启动后的所有进程
3.2 数据仓库详细实现
3.2.1 ODS层数据仓库实现
ODS 层主要用于存放原始的数据,保证数据的可靠性。OSD 层电商数据表结构关系如图12所示。

图12 电商数据表结构关系
在Hive 中先创建数据库gmall,然后以日志表为例创建表,代码如下:
drop table if exists ods_log;
CREATE EXTERNAL TABLE ods_log(‘line’string)
PARTITIONED BY(‘dt’string)
STORED AS
INPUTFORMAT
‘com.hadoop.mapred.DeprecatedLzoTextInput
Format’
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.HiveIgnoreKeyText
OutputFormat’
LOCATION‘/warehouse/gmall/ods/ods_log’;
最后创建1 张表存放日志数据和23 张表存放业务数据。ODS层数据表如图13所示。

图13 ODS层数据表
3.2.2 DWD层数据仓库实现
DWD层主要是对ODS层的24张表进行维度建模解析,提高查询的速度。电商数据表维度建模如图14所示。

图14 电商数据表维度建模
对ODS 层的数据表进行维度建模后,生成DWD层新的维度表和事实表,如图15所示。

图15 DWD层数据表
3.2.3 DWS层数据仓库实现
DWS层将DWD 层数据分为会员主题、活动主题、商品主题、地区主题、设备主题等五个大主题,如图16 所示。每个主题拥有每个主题的宽表。

图16 DWS层数据表
3.2.4 DWT层数据仓库实现
DWT 层需要对DWS 层的主题数据表进行进一步汇总,因此建立DWT 层数据表表示某一段时间的度量,如图17所示。

图17 DWT层数据表
3.2.5 ADS层数据仓库实现
ADS 层主要是统计各种数据,为生成可视化报表提供数据支撑,如图18所示。

图18 ADS层数据表
3.3 数据可视化模块详细实现
使用Superset进行UI可视化展示。当Superset安装成功并启功后,进入http://hadoop101:8787显示登录界面,正确输入用户名和密码即可登录系统。
4 系统运行测试及可视化展示
4.1 数据采集运行测试
电商数据仓库部署完成后,执行编写好的脚本,生产日志模拟数据。然后通过HDFS 的Web 端页面查看日志数据是否被采集到磁盘。同样生成业务模拟数据,然后通过Sqoop 导入MySQL 里的模拟数据到HDFS。如图19 所示,说明日志数据和业务导入到了HDFS。数据采集模块运行测试成功。

图19 用户行为日志数据和业务数据成功导入HDFS
4.2 数据仓库运行测试
电商数据仓库部署完成后,执行编写好的脚本,在HDFS下查看各层次数据生成状况,如图20所示,说明数据仓库各层次数据生成成功,数据仓库运行测试成功。

图20 数据仓库各个层次导入结果
4.3 数据可视化展示
将ADS 层的数据表,在MySQL 里创建相应的表,这里使用adsarea_topic 和ads_user_topic这两张表为样例。再编写脚本使用Sqoop框架把这两张表的数据从HDFS 导入到MySQL 对应的表里。通过Superset 进行可视化展示,如图21所示,通过分析ads_area_topic 来对各地区订单进行可视化展示。

图21 各地区订单数
通过分析ads_area_topic 并对全国各省份订单进行可视化展示。通过分析ads_user_topic 并对用户日活动趋势进行可视化展示。如图22 所示,通过Superset仪表盘工具,将各个图进行整合,方便分析数据,最后进行可视化大屏展示。

图22 BI可视化大屏展示
5 结语
数据仓库的建立和使用,可以帮助企业更加深入地了解其业务状况、优化运营流程、提高决策效率和精准度。为此,本文通过分析电商行业的数据特点和业务需求,提出了基于大数据技术的电商数据仓库可视化设计方案,运用数据仓库建模、ETL 流程、数据存储和数据分析等技术,实现了对电商数据的全方位分析,并利用Hadoop 生态系统和Hive 等工具,可以处理庞大的数据,提供更为全面和准确的数据支持,帮助企业在市场竞争中取得优势,对于电商企业的决策和管理具有重要意义。
此外,电商数仓在实际应用中还有一些场景和效果,例如销售预测、用户行为分析、流量分析等,为后续进一步研究提出了方向。
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
党员生活(2020年2期)2020-04-17
自然资源信息化(2019年4期)2019-03-29
铁道通信信号(2018年10期)2018-12-06
小学生(看图说画)(2017年6期)2017-11-06
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
中国石油企业(2014年4期)2014-11-30
