
基于新浪微博的学校网络舆情系统设计与实现
2024-01-08 12:14殷美桂
现代计算机 2023年20期
殷美桂
(河源职业技术学院电子与信息工程学院,河源 517000)
0 引言
大数据时代下,随着互联网应用技术的成熟,越来越多的用户使用社交平台,其中微博作为一种非常流行的媒体平台,成为人们自由表达观点及社会交流的媒介。据2022 年9 月微博发布的三季报显示,9 月的月活跃用户数为5.84亿,日均活跃用户数为2.53亿[1]。微博凭借庞大的用户群体及实时的社交互动方式,成为社会热点话题讨论和舆情发酵平台[2]。大学生群体具有思想独立、上网时间长和猎奇心理强等特点,更愿意通过网络媒体发声;同时,大学生群体因思想不成熟,在面对真假难辨的消息时更容易受到他人蛊惑。近年来,高校频频成为网络舆论场,根据人民网舆情数据中心统计,2020 年涉及高校全国重大舆情同比增加33%,与2018 年相比增幅达到133%[3]。高校管理者如何从互联网海量的信息提取出针对本校的舆情数据,以及在网络舆情的发展形成之际对网络舆情进行正确的引导,显得尤其重要。高校网络舆情系统可以代替人工监测,舆情系统能对校园网络舆情进行自动监控,从互联网中挖掘出针对本校的舆情信息,并对舆情信息进行主题词的统计和情感分析,帮助管理者了解学生关注的主题以及敏感事件的情感倾向,从而捕捉学生的思想动态情况,能维护学校的舆论安全稳定。
网络舆情系统采用B/S模式,使用Django与Vue 框架实现前后端分离技术,数据存储使用MySQL。系统后端采用Python 的Django 框架提供数据访问的接口,前端框架通过Axios 访问后端API 接口获取数据,从而构建可以展示的网站平台。
1 相关理论和技术分析
1.1 网络爬虫
网络爬虫又名“网络蜘蛛”,是建立在搜索引擎基础上的信息收集技术,从网站的某一个页面开始,按照指定规则循环读取网页的链接,以获取网页内容。网络爬虫按照实现技术,可分为通用网络爬虫和主题网络爬虫。Scrapy 是基于Python 语言开发的Web 数据采集框架[4]。Scarpy 是最受欢迎的爬虫框架之一,面向用户的多种需求,可进行定制爬虫开发。Scrapy 爬取的网页信息具体流程如下[5]:
(1)初始化爬取链接。调度器(Scheduler)将需要爬取的微博网页URL传递给Scrapy引擎。
(2)发送请求。调度器负责接收Scrapy 引擎发送的请求(Request),并将请求加入调度队列。调度器将处理好的Request返回给引擎。
(3)获取响应。Request 由下载器(Downloader)获取响应(Responses)信息,交给Scrapy引擎,引擎转交给Spider处理。
(4)处理Responses 信息。 Spider(爬虫)负责处理所有的Responses,使用Xpath 进行指定数据的提取或者将需要继续处理的URL 提交引擎。Spider 将获取的Item 字段由引擎交给Item pipelines 模块。Item Pipelines 模块会根据设置将数据储存在CSV文件中。
1.2 Django框架
Django 是一个开放源代码的应用框架,基于MVC 的DjangoMVT 框架。Model 与MVC 中的M 功能相同,负责与数据库中的进行交互[6]。View 与MVC 中的C 功能相同,负责进行业务处理。Template 与MVC 中的V 功能相同,负责封装构造返回的html。程序员利用Django 快速、便捷地创建数据库驱动的应用程序。Django 中嵌入对象关系映射(ORM)框架,采用类定义数据模型,并将模型与关系数据库连接,获得一个数据库操作的API。ORM 的优点是以对象的方式操作数据库,即使不懂SQL 语句的开发者也可以通过ORM轻松操作数据。
1.3 Vue框架
Vue.js用于构建用户界面的渐进式框架,是目前应用较为广泛的JavaScript框架之一[7]。Vue开发优势主要表现在组件化开发,大大减少代码编写量;另外其最突出的优势是可以对数据进行双向绑定,采用v-model 指令对View 和Model层进行数据绑定,当视图中的数据发生变化,同步更新后台数据,后台数据的变化也会反映在视图中。
2 系统功能设计
网络舆情系统涉及的技术领域包括网络舆情信息的采集技术、话题检测与跟踪技术、文本情感分析技术[8]。根据网络舆情涉及的技术,系统分为后端功能模块和前端结果展示模块。系统功能结构图如图1所示。
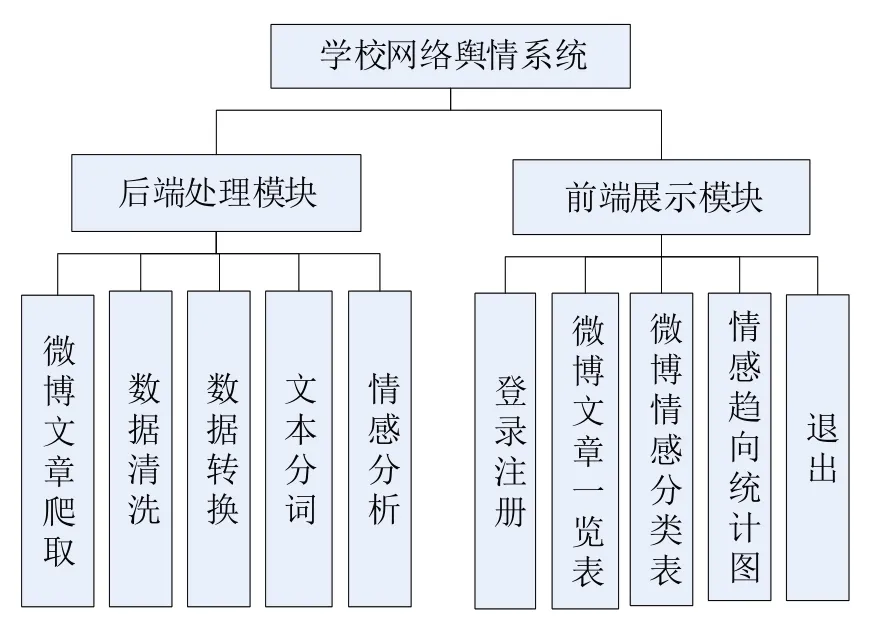
图1 系统功能结构图
2.1 数据采集模块
高校一般在新浪微博都有官方账号用于发布学校资讯,而大学生喜欢在微博平台发布个人看法及热点事件的评论,系统主要采集新浪微博数据作为数据源。数据获取主要分为三个步骤:向URL发送请求、数据爬取、数据存储。本系统采用Python 语言中的Scrapy 爬虫框架,调用新浪微博公开的应用程序接口(API)实现对特定网页信息的爬取,其检索策略是基于设定好的学校名称关键词。在采集工作开始之前,先在URL 队列中初始化一个或几个URL,爬虫程序可根据设定的URL 依次去请求访问对应网页,因微博需登录验证后才可以访问网页,Request 中必须包含登录验证的Cookie 信息。爬虫接收网页端的Responses,使用Xpath 来定位爬取指定内容,储存在CSV文件。
在进行舆情分析、热词发现和情感分析之前,要对数据进行预处理。数据预处理分为数据清洗、数据转换和文本分词。
(1)数据清洗。由于未经处理的数据含有噪声,如数据中存在很多无意义的符号、连接、数字、图片等噪音,并且还会有大量的缺失值,这对文本的数据分析没有太大意义。去除“脏数据”的方法有很多,一般采用正则表达式进行规则匹配,利用正则表达式过滤掉无意义的词语。系统对脏数据进行清洗主要包括:去除乱码和填充空字段等。采集到的网页源码往往存在一定程度的乱码和一些对文本分析无意义的信息,如广告和注释等,因此需要对其进行过滤操作去除乱码,通过过滤对数据进行标准化处理。另外,由于采集到的微博字段有些为空,因此需要将空值进行填充。
(2)数据转换。数据转换就是将数据进行转换或归并,从而构成一个适合数据处理的描述形式。系统主要对一些属性,如日期、评论、点赞等数据进行转换,将其转换为规格化的数据。如在抓取微博发布时间时会出现“2 小时前”“昨天”“刚刚”等字眼,这会导致数据库中发布时间字段格式不统一,因此需要将时间格式统一为“年-月-日”。
(3)中文分词。中文不同于英文,英文单词之间使用空格连接,中文文本都是句子,需要将处理后的数据分割为词语。中文文本的分词软件主要有中国科学院的ICTCLAS、jieba 分词和北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包pkuseg。用户可以根据pkuseg待分词文本的领域特点,自由地选择不同的模型。系统采用网络领域的分词模型,更精确地对微博文本进行分词,分词后对数据去重、去停用词、去无关词、去除开头末尾为数字或符号的分词,如日期、错误分词等。
2.2 舆情的情感分析
微博文本的情感分析基于百度PaddleHub预训练情感倾向分析模型(Senta)[9],针对中文文本,模型可自动判断文本情感极性类别和置信度。Senta 开源一系列模型,如BOW、CNN、Bi-LSTM 等。PaddleHub 可以支持文本、图像、视频、语音、工业应用五大方向,提供高质量的预训练模型,减少用户训练模型的工作量。本文采用Paddle_Senta 的BiLSTM 进行情感的二分类(积极、消极)任务。BiLSTM 模型是长短期记忆神经网络模型(LSTM)的一种变体[10]。情感分析实质上是一个分类任务,系统对微博正文进行情感的分类,对数据进行标注,并将结果写入数据库中,为系统实现微博文章的舆论分析、舆情发展趋势,以及正负面舆论占比等奠定数据基础。
3 网络舆情系统的实现
系统基于B/S采用前后端分离的技术,首先采用Scrapy 采集数据,使用Django+MySQL 搭建系统后端平台,前端采用Vue+Element Plus+Echarts构建前端应用UI界面和图表。
3.1 系统后端模块实现
系统后端采用PyCharm 集成开发环境、程序开发语言Python,搭配Django 框架。使用Django 框架开发程序的流程包括:①首先创建Django 项目。②创建APP 子应用,为了提高代码的利用率,将相同功能模块的代码放在同一个子应用,可实现代码复用。③设计模型类并进行数据库的迁移。系统定义数据微博文章类和微博文章情感类,模型的数据来源为爬虫爬取的数据以及情感分析处理后的数据。④定义视图view.py,在子应用的view.py 定义视图函数,函数会返回包含被请求页面内容的HttpResponse对象,该对象用于向客户端Vue 返回json 数据,通过在Models 中定义类,采用objects.filter()函数过滤数据库中数据。⑤创建模板,使用模板方法可以动态生成HTML。由于项目使用Django+Vue 前后端分离的技术,模板主要通过Vue 打包生成项目,打包完成后,生成dist 目录,该目录下包含index.htm。
3.2 系统前端模块的实现
系统前端采用Vue 3.0+Element Plus+Echarts开发框架。Element Plus 是一款基于Vue3.X的页面结构框架,此框架提供一套完整的组件,包含导航、布局、表单、按钮等功能丰富的组件。Vue 项目使用脚手架直接搭建,用Vue-router 实现前端路由的跳转,用Axios 向后端服务器发起get 或post 请求。前端页面主要包括以下几个模块:①用户注册和登录模块。②微博最新文章一览表。该模块的来源为经预处理后爬取的数据。③微博文章的情感分析表。该模块能显示文章的情感分类情况,负面情感的文章在最前面展示,以便第一时间发现敏感舆论信息,如图2所示。④微博文章的情感趋向图。系统采用柱状图、饼图对微博文章情感趋向进行统计,如图3所示。
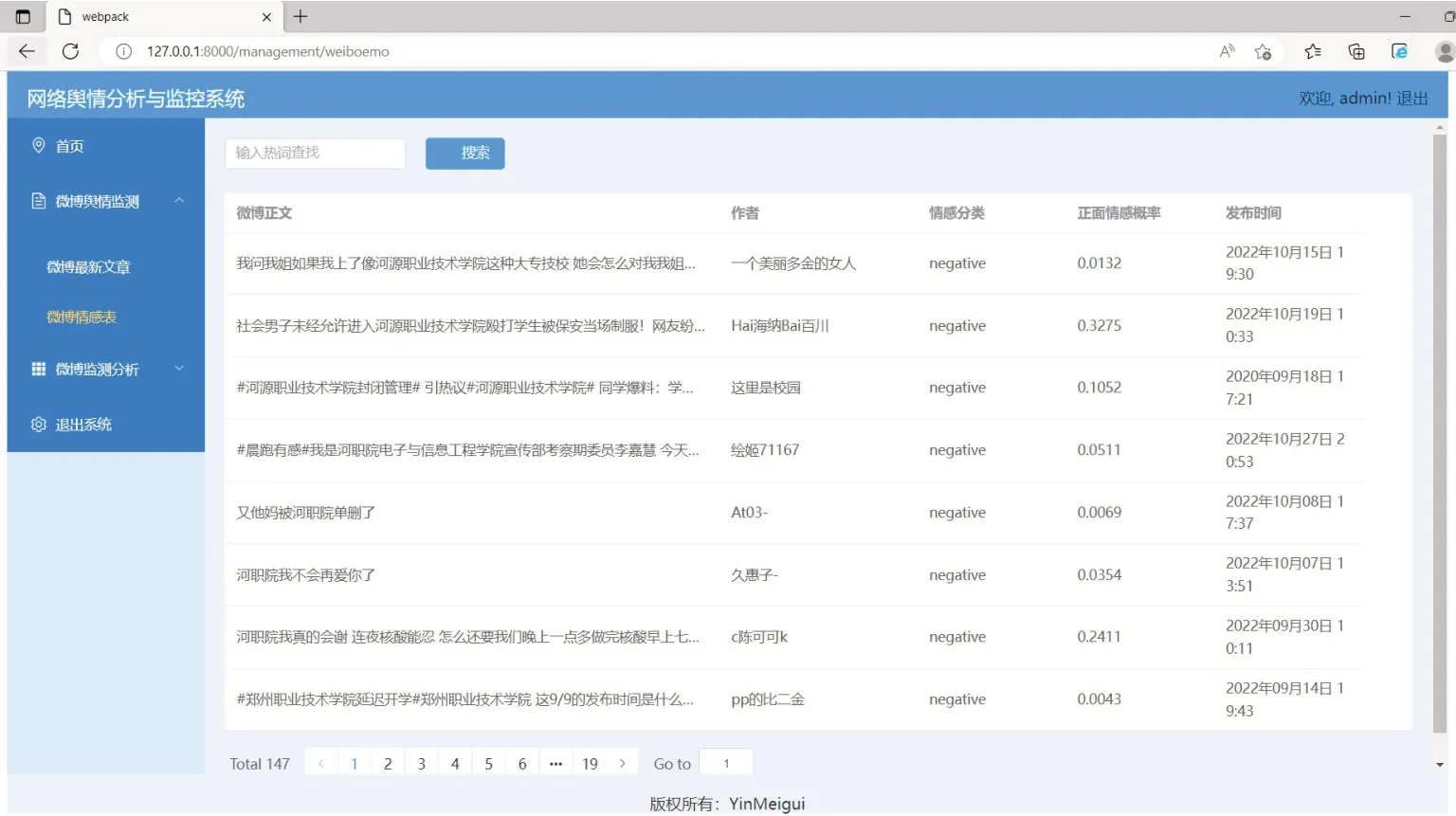
图2 微博文章情感分类表
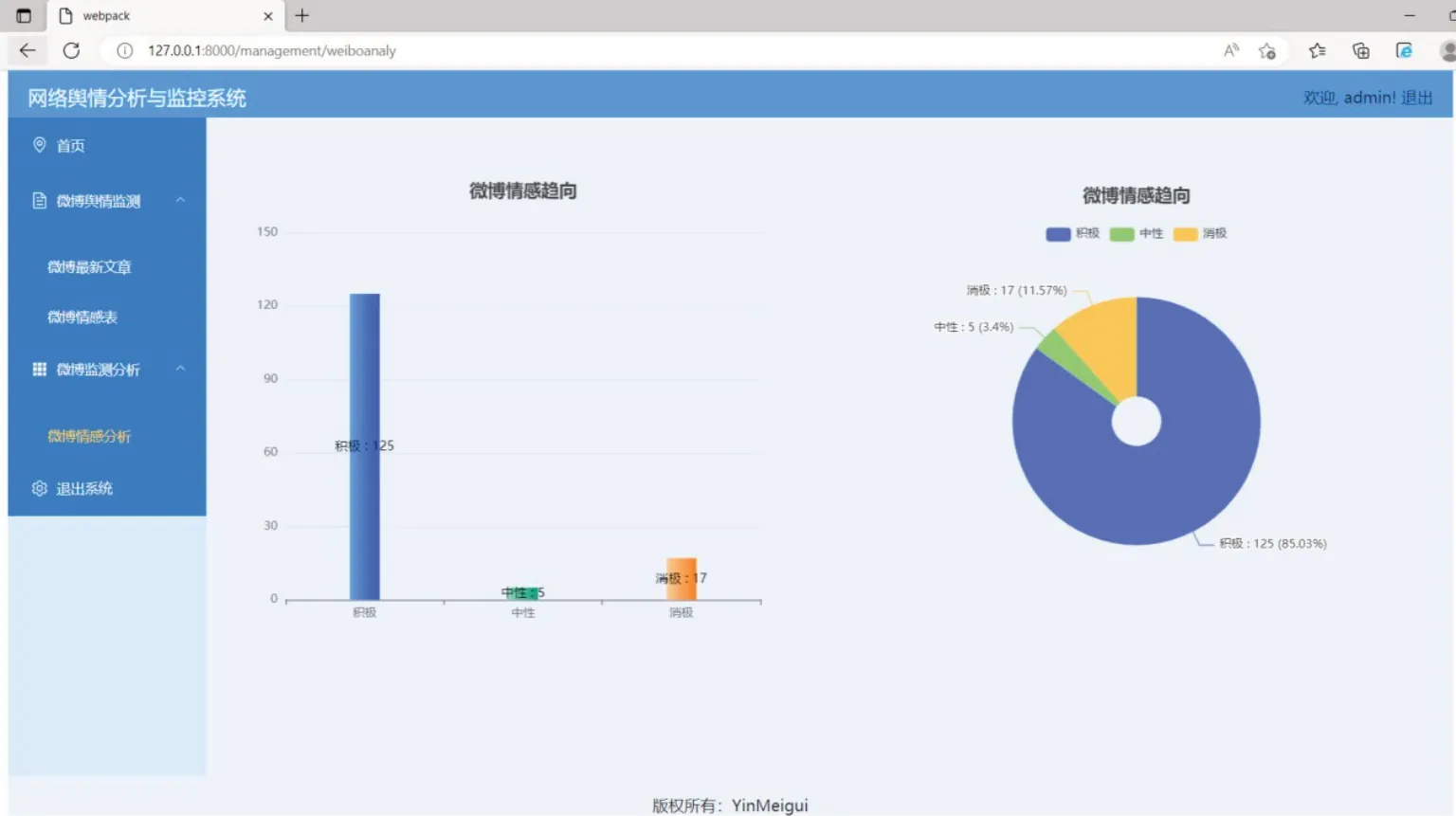
图3 文章情感趋向图
4 结语
本文采用Django+Vue 框架,快速搭建基于新浪微博的学校网络舆情系统,采用Scrapy 框架爬取学校的新浪微博文章,微博文章经过预处理后采用BiLSTM 进行情感分类,情感分类的结果准确率较高。学校网络舆情系统能对学校舆情进行监测,及时发现负面舆情,方便监管部门进行舆情的监管。系统设计达到预期目标,但是系统功能还需要完善,主要包括:一方面,系统爬取的舆情信息不够全面,只针对指定的URL 进行搜索,尚未对信息进行全面采集;另一方面,目前只根据情感的正负方向进行分类,对情感强烈程度尚未区分。未来计划扩大舆情信息的采集范围,充分挖掘数据价值。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
