
基于深度学习的驾驶员分心驾驶行为预警算法*
2024-01-09 05:08欧阳壮朱天军
机电工程技术 2023年12期
欧阳壮,朱天军,文 浩
(1.广东省肇庆市质量计量监督检测所,广东肇庆 526070;2.肇庆学院机械和汽车工程学院,广东肇庆 526061)
0 引言
据国家统计局官方数据公布,2021 年全国道路交通事故发生249 345 起,造成61 513 人死亡、245 143 人受伤,直接财产损失152.5亿元,所以汽车驾驶安全问题非常值得人们重视。其中,驾驶员的驾驶行为不规范成为汽车安全问题的主要原因之一,尤其是驾驶疲劳和分心驾驶行为的问题极为突出[1-9]。因此,利用深度学习技术手段研究驾驶员分心驾驶行为,做出一套可实时检测驾驶员分心行为并发出预警信号的安全系统对交通安全的改善具有极大的现实意义。
近年来,随着深度学习技术的快速发展,基于深度学习的驾驶员分心驾驶行为预警系统也得到了广泛关注。在国外,欧洲慕尼黑工业大学的研究人员进行的一项研究提出了一种基于卷积神经网络的驾驶员分心检测,该检测方案依赖于视觉线索,例如头部方向和凝视方向[10]。华威大学的研究人员进行的另一项研究使用卷积神经网络和长短期记忆(LSTM)的组合来构建可以实时运行的驾驶员分心警告系统[11]。美国犹他大学的研究人员提出了一种基于视频的系统,用于基于LSTM 网络的检测驾驶员分心事件[12]。内布拉斯加大学林肯分校的研究人员进行的另一项研究使用基于深度学习的方法,根据面部表情检测和分类驾驶员分心[13]。
在国内,基于人体脑电波信号检测方面,北京航空航天大学研究团队设计了一种基于EEG 信号的驾驶员分心行为预警系统,通过EEG 头戴式设备采集驾驶员的脑电波信号,使用深度学习算法分析数据并实现分心状态预测[14]。西南交通大学等研究者提出了一种基于深度学习的行为识别框架,该框架通过深度卷积神经网络提取驾驶员视频资料的空间特点,并使用Hadamard 矩阵将层级卷积特征转换成低维向量。随后,将该信息输入到支持向量机(SVM)分类器中,以分类判断驾驶员的分心驾驶行为[15]。
综上所述,基于深度学习的驾驶员分心预警系统具有提高道路安全性的潜力。本研究以深度学习的驾驶行为预测模型为基础,以早期发现和预测驾驶员干扰行为,提升行车安全水平为目标。本研究的主要内容包括驾驶员疲劳检测与驾驶员分心驾驶行为检测。在疲劳检测方面,利用Dlib 来进行脸部关键位点的检测,对眼睛的开闭区域和嘴唇开合程度的大小进行计算,从而对是否出现了闭眼动作或打哈欠的行为进行判断,并利用Perclos模型来计算出相应的疲劳程度。在分心驾驶行为检测方面,采用卷积神经网络YOLOv5 来检测驾驶员是否存在玩手机、抽烟、喝水等分心动作。检测完成后,通过程序逻辑对驾驶员分心驾驶行为发出预警,以规范驾驶员行为,达到安全驾驶的目的。试验结果表明:该算法在驾驶员疲劳和分心行为检测上具有极高的准确性,并在驾驶员规范驾驶行为上具有良好的应用性。
1 分心驾驶行为预警算法
分心驾驶行为指驾驶员在驾驶汽车行驶过程中因为各种原因,如接疲劳驾驶、接打电话、喝水、抽烟等分散其注意力,从而导致其无法集中注意力驾驶,增加了交通安全事故的风险。本研究提出的预警算法是运用深度学习中的卷积神经网络算法,对驾驶员的面部、身体动作等综合信息进行检测、提取和分析,可以实现对驾驶员分心状态的实时监测和识别,从而在驾驶员分心状态下发出警报,提醒驾驶员要注意行车安全。该算法能够有效地降低分心驾驶带来的交通事故风险,提高道路行车安全性。分心驾驶行为预警算法框架如图1所示。

图1 分心驾驶行为预警算法框架
如图1 所示:在驾驶员分心驾驶行为预警的总体框架下,包括疲劳驾驶行为和分心驾驶行为两个模块。疲劳驾驶行为检测模块主要是针对于驾驶人员打哈欠和眨眼两个动作进行驾驶员疲劳程度检测。分心驾驶行为检测模块,重点检测喝水行为、抽烟行为、玩手机行为。从这3个动作入手去检测驾驶过程的分心驾驶行为。
1.1 疲劳驾驶行为检测
在本算法中,主要通过对驾驶员的眼睛和嘴巴开闭程度来评估驾驶员疲劳状态,它是通过获得眼睛和嘴巴的关键点和形状来实现的。本算法应用中,Dlib 主要用于人脸检测和人脸关键点检测,对眼睛的开闭区域和嘴唇开合程度的大小进行计算,从而对是否出现了闭眼动作或打哈欠的行为进行判断,并利用Perclos 模型来计算出相应的疲劳程度[16-19]。
后期Dlib的训练过程涉及到以下步骤:
(1)数据采集:需要收集足够数量的人脸数据集,包括分心驾驶行为和正常驾驶行为的图像数据。这些数据应该具有丰富的变化,例如不同角度、光照和表情等。
(2)数据先处理:采集到的人脸面部图像进行先处理,包含图像加强、归一化和裁剪等,以减少数据中的噪声和冗余信息。
(3)特征提取:利用Dlib 提供的人脸检测和人脸关键点检测算法,提取出每个人脸图像中的特征点集合,例如眼睛、嘴唇、眉毛等。
(4)数据标注:针对采集到的每张图像,标注对应的分心或正常驾驶行为标签,以供训练时进行监督学习。
(5)神经网络训练:基于Dlib提供的深度学习框架,构建适合该任务的神经网络模型,并利用标注好的数据集,对该模型进行训练和优化,以提升其分类准确率和泛化能力。
(6)神经网络测试:当训练好的神经网络达到一定准确度之后,使用测试集进行测试,评估其在未见过的数据上的分类准确率,来验证在未知数据上检测模型的泛化能力。
(7)系统部署:当训练好的模型经过评估验证后,将其部署到实际系统中,以实现分心驾驶的预警功能。Dlib 主要用于人脸检测和关键点检测,并配合深度学习进行分类任务的训练和预测,在完成数据预处理、特征提取、数据标注等一系列前置工作后,利用Dlib进行监督学习训练,构造一个针对驾驶疲劳程度的检测应用模型。
1.2 分心驾驶行为检测
YOLOv5 是一种用于目标识别和定位的卷积神经网络(CNN),它结合了CNN、Transfer Learning 以及深度强化学习等多种技术,使得它能够处理图像中不同大小和不同种类的对象[20]。本算法采用卷积神经网络YOLOv5来检测驾驶员是否存在玩手机、抽烟、喝水等分心动作。
YOLOv5的网络结构可以分为4个部分。
(1)输入端:在目标检测算法中,锚框(Anchor Box)是一种用于定义检测框(Detection Box)位置和大小的参数。为了适应不同的图片大小,YOLOv5 实现了自适应图片缩放的功能,能够在不改变检测结果的情况下自动调整输入图片的尺寸。这个功能也可以在代码中进行控制,通过修改train.py 中的相应参数来开启或关闭。
(2)Backbone 架构:在YOLOv5 中,图片输入到Backbone 架构前的一个处理模块称为Focus 模块[21]。每隔着一个特征点处截取一个像素点,可以得到4 张互补相似的图像,将这4 张图片进行拼接,就形成了一个新的特征图。
(3)Neck结构:YOLOv5现在的Neck采用FPN+PAN的结构[22]。
(4)输出端:YOLOv5 的输出端是一个三层级联的检测头(Detection Head),它可以同时预测位于不同特征图层级上的多个物体。检测头的输出由包含物体的锚框(Anchor)进行解码[23]。
每个锚框会和真实物体之间进行匹配得分,表示锚框和真实物体之间的相似程度,用于筛选出最适合的锚框。锚框和真实物体的匹配度所得分数分别为86.49、84.0、69.7,如图2所示。

图2 锚框和真实物体的匹配度得分
驾驶员分心驾驶行为检测过程如下。
(1)数据准备
首先需要根据监测任务确定数据来源和数据类型,并进行数据的收集和预处理,例如针对视频监测任务,可以使用摄像头捕获图像或视频,使用图像处理技术进行预处理,例如裁剪、缩放、色彩空间转换等;同时需要标注或分类数据集,例如标记出图像中是否出现了分心物体或者驾驶员是否闭眼等行为。
(2)根据任务特点,可以选择CNN 或者Transformer等深度学习模型进行建模。以视频监测为例,常用的CNN 模型包括VGG、Inception、ResNet 等,可以使用其中的预训练模型或者自行训练模型。为了提高模型的准确性,要将这些数据分成不同的类别,如80%用于训练,20%用于检验。此外还需要进行数据增强,例如随机裁剪、翻转、旋转等操作,从而增加数据集的多样性,减少模型的过拟合现象。
(3)预测与报警
完成模型的训练和验证之后,就可以将模型应用到实际监测场景中。在应用过程中,可通过Dlib 等库进行人脸检测和关键点定位,对每一帧进行数据处理、预测和报警。比如,对于视线监测,可以使用训练好的CNN模型,输入摄像头采集到的图像,输出眼睛状态(是否闭眼)的概率或者是否存在喝水、使用手机等分心行为。然后根据设定的阈值判断当前驾驶员是否存在分心行为,如果存在,就及时发出警报,提醒驾驶员注意。
(4)多尺度融合
多尺度融合是对特征金字塔方法的补充,由于特征金字塔方法在多尺度下依然存在分辨率不高的问题,因此引入多尺度融合模块进行进一步的特征处理。多尺度融合模块可以在检测层和分类层之间设计,引入不同层次的特征,并提高分辨率,例如可以使用FPN 或者PANet中的lateralconnections和top-downpathways等结构实现。
2 分心驾驶行为预警算法试验验证
2.1 使用手机行为检测
根据前期检测到的人脸坐标和大小,在面部两侧和下方区域进行切割,作为手持电话行为的检测区域,再进行特征提取和行为分类检测图。检测区域是指用来判别司机手持电话的影像区域。这个时候驾驶人员注意力集中在手机上,对驾驶的专注度有很大的影响,此时为认定驾驶分心行为的关键场景之一。
手持手机的检测区域如图3 所示,本算法不仅可以实时检测驾驶员疲劳情况,如当前驾驶员是否清醒,眨眼次数和哈欠次数等信息,而且可以准确捕捉到驾驶员使用手机的分心行为,并实时警告驾驶员分心行为信息。

图3 使用手机行为检测
2.2 喝水行为检测
按照前期检测到的人脸坐标位置点和尺寸大小,喝水行为待测区精确定位为人脸面部的左右侧部区域,将左右区域图像定位喝水行为待测区域,提取待测区域特征信息进行行为判别。
喝水的水杯手势区域主要会与嘴的左右下角进行重合,会遮住嘴巴的显示,只是嘴型有程序模拟生成,此时主要面向喝水动作识别,遮住嘴巴为检测允许的环境,喝水行为特征图像生成如图4 所示。当前驾驶员处于清醒状态,并显示眨眼次数和哈欠次数等信息,而且可以准确捕捉到驾驶员驾驶过程中喝水(drink)分心行为时,则实时警告驾驶员分心行为信息。
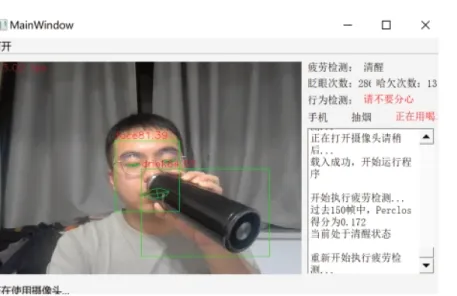
图4 用保温杯喝水行为检测
2.3 吸烟行为检测
吸烟动作也是驾驶员分心动作之一,由于抽烟过程需要呼吸换氧气,抽烟过程手持香烟是不可避免的,一般抽烟时驾驶员会分出一只手来手持香烟,这样对于车况的掌握控制相当于少了一只手臂。
经此可以认定监测过程中通过摄像头检测待测区域时,该待测区域一般会位于人脸面部区域位置的左右两端。检测结果如图5~6 所示。图5 识别结果显示,驾驶员处于清醒状态,同时可以准确捕捉到驾驶员用手普通抽烟动作的分心行为,并实时警告驾驶员分心行为信息。图6 识别结果显示,驾驶员已经处于疲劳状态,同时也准确捕捉到驾驶员嘴叼式抽烟动作的分心行为,系统实时警告驾驶员分心行为信息。

图6 嘴刁式抽烟动作检测
2.4 综合检测
为了验证本算法的全面性和抗干扰性,进行一种分心驾驶行为综合检测试验,即进行检测手机、抽烟、喝水、眨眼、打哈欠嘴形等多元的综合检测试验,以验证检测模型的全面性以及检测过程中各个检测模块各不干扰。检测结果如图7 所示,结果表明本算法可以综合识别出驾驶员当前处于清醒状态,并存在使用手机、抽烟和喝水多元分心驾驶行为,同时能够在系统里实时警示驾驶员当前存在分心驾驶。综合检测试验证明,本算法可以实时全面监控驾驶员疲劳状态和分心驾驶行为,准确性较高,抗干扰性强。
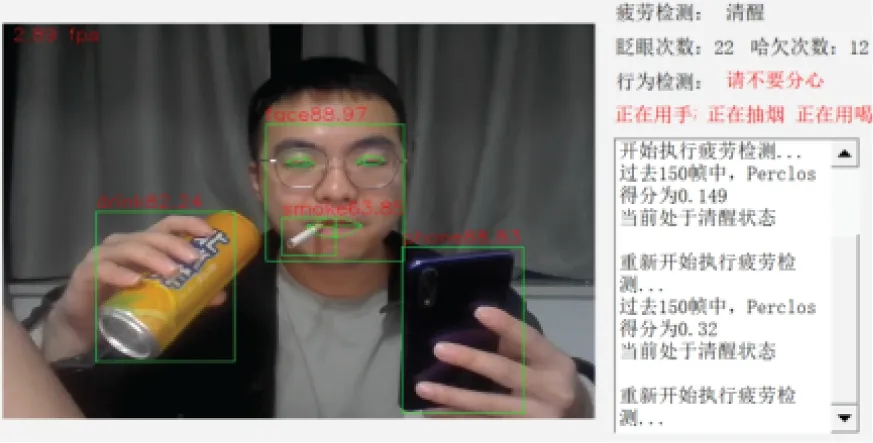
图7 综合检测
3 结束语
本文设计了一种基于深度学习的驾驶员分心驾驶行为预警系统,结合了疲劳检测和分心行为检测2种方法,实现了对驾驶员专注度全方位监控。
(1)采用YOLOv5 进行驾驶员分心行为检测,能够很好地检测驾驶员是否在玩手机、吸烟或者喝水等分心行为,从而实现对驾驶员专注性的全面监测。
(2)采用Dlib 和Perclos 模型是比较成熟和准确的技术手段,能够很好地实现驾驶员疲劳检测。
(3)该算法结合了驾驶员疲劳程度检测和分心行为检测2 个模块,能够实现全方位的驾驶员专注性监测。通过发出预警来规范驾驶员行为,从而保障交通行车的安全。该研究可以为汽车主动安全性的普及提供技术支持,有效提升汽车的行驶安全性。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
公民与法治(2016年4期)2016-05-17
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
