
基于LDA-BERT重复缺陷报告检测模型研究
2024-01-10 11:51崔梦天杨善矿袁启航
西南民族大学学报(自然科学版) 2023年4期
崔梦天,杨善矿,袁启航
(西南民族大学计算机科学与工程学院,四川 成都 610041)
软件缺陷报告是负责软件测试的人员对于软件测试过程中出现的缺陷或错误进行记录,并以文档的形式保存.为了提升用户的使用体验,更好的向开发团队反馈缺陷信息,很多软件项目特别是开源项目允许用户直接向缺陷追踪管理系统中提交缺陷报告.由于提交报告的用户素质参差不齐,存在着专业知识不足、技术用词不严谨、表达模糊、描述信息不全等问题,以及出于使问题得到重视而重复提交的目的,使得提交的报告中存在着大量重复的缺陷报告.因为缺陷报告的基数非常大,这些重复缺陷报告的数量也变得非常庞大.有研究表明[1],MapReduce开源项目中的重复缺陷报告的数量占整个缺陷报告库的13.9%.Mozilla Firefox和Eclipse IDE这些大型的项目中,重复缺陷报告数量多达20%~30%.
因此,为了减少开发人员人工检测重复缺陷报告的工作量,国内外的很多学者研究人员都投入到重复缺陷报告检测领域的研究中,并有效提出了一系列的关于重复缺陷报告的检测技术.
软件缺陷报告重复检测技术主要的关注点是:由维护或测试人员提出一份新提交的缺陷报告,由系统自动返回存在于缺陷报告库的最相似的软件缺陷报告,该报告是前人已经提交在软件缺陷报告库.由于检测精度的局限,一般的做法是返回与维护人员提交的最相似的k份候选报告,称为Top-k,k的取值范围由维护人员自行决定.图1是软件缺陷报告重复检测的整个流程构建图.

图1 重复检测流程图Fig. 1 Repeat detection flow chart
目前重复软件缺陷报告检测方法根据使用的技术手段进行分类[2],主要分为三种:基于自然语言技术的方法、基于机器学习的方法、基于深度学习的方法.
在基于自然语言技术的相关工作中,蒋颀志[3]研究发现LDA模型在重复缺陷报告检测中具有良好的精度和召回率,他使用LDA进行重复缺陷报告检测实验,并且还加入了执行信息的相似度比对,两者相似度结合记作最终相似度,将其与传统向量空间方法进行对比实验,实验结果证明其方法确实有效,也侧面反映了主题模型对于重复缺陷报告检测的研究是有作用的.Budhiraja[4]等人提出了LWE模型,该模型是将主题模型LDA同词嵌入方法相结合,同时获得两者的优势.Aggrawal[5]等人在BM25F模型的基础上提出了构建上下文特征的方法来进行检测重复缺陷报告的思路.
在基于机器学习技术的重复缺陷报告检测的相关工作中,Wang[6]提供了一个PVRE模型,该模型使用段落模型来检测重复的缺陷报告.模型通过计算缺陷报告文本数据中上下文语序信息的相似度,此外,还加入了REPext模型,它是负责计算文本相似度数据和执行数据相似度.最后,采用类似总体均值的线性组合来获得总体相似度以达到重复缺陷报告检测的目标.陈信[7]等人采用的数据集是众包测试系统中存储的缺陷报告,第一步进行数据的异常处理,即去除异常的缺陷报告,第二步对缺陷报告进行数据预处理,最后使用模糊聚类的方法划分测试报告,将它们分成众多的簇类,确保簇类中的缺陷报告要尽可能一致,而不同的缺陷报告要确保分在不同的簇类中.姜玥[8]等人提出量子免疫克隆BP算法用于软件缺陷领域,同样是基于机器学习技术展开的研究.
在基于深度学习技术的重复缺陷报告检测的相关工作中,He[9]等人使用词向量和卷积神经网络模型技术抽取文本语义信息,以提高识别重复缺陷报告的有效性.该方法不依赖于人工提取的特征,而是基于收集的开源数据训练词向量和卷积神经网络模型,自动获取数据的特征,最终实现识别重复缺陷报告的自动化.Cui[10]等人提出基于复杂网络和图神经网络的软件缺陷预测模型,实验结果表明,该方法将软件缺陷与复杂网络结合起来的模型是有效的.Guo[11]将循环神经网络技术和注意力机制与长短记忆模型相结合,并将其应用到重复缺陷报告检测的工作中,实验结果表明,基于循环神经网络的方法模型是有效的.
本文针对基于自然语言技术中的主题模型过度关注主题的划分,忽略了词义等粒度的缺点.在此基础上,融合深度学习技术,提出了二级特征向量再检测方法,并提出LDA-BERT模型.该模型融合了BERT[12](Bidirectional Encoder Representations from Transformers)、LDA[13](Latent Dirichlet Allocation)模型的优势.实验结果表明,该模型方法对于重复缺陷报告工作是有效果的.
1 LDA-BERT模型的创建
1.1 二级特征向量再检测方法
二级特征向量再检测方法,即在重复缺陷报告检测的过程中,发现直接检测重复报告的时间花费得过多.但是在实际应用中,开发及维护人员可能未必会有这么长的时间来等待检测,因此为了保证检测的精度以及减少检测时间,在两者之间把握平衡,所以提出了二级特征向量再检测方法.
二级特征向量再检测方法具体步骤如图2所示:

图2 二级特征向量再检测示意图Fig. 2 Schematic diagram of the two-level eigenvector re-detection method
二级特征向量再检测方法的主要思想是将现有的缺陷报告数据集先进行聚类,通过LDA-BERT模型得到每个报告文档的概率向量分布.将其分配到概率最高的簇类中.这个过程将在每个缺陷报告上重复,直到将所有缺陷报告分配给它们关联的簇类,每个簇类的软件缺陷报告数据集代表一个主题.
经过第一级的分类操作后,当有新的重复的软件缺陷报告输入时,将该缺陷报告经过数据预处理后同样输入到LDA-BERT模型中,计算新的缺陷报告的概率分布.将其分类至概率最高的簇类中,不过与第一级操作不同的是,不再将其插入到簇类中,而是通过采用Word2vec模型抽取其簇类中的特征向量,并通过对其特征向量的余弦相似度进行对比,并按照相似度进行排序.
1.2 LDA-BERT模型
LDA-BERT模型的整体框架主要分为两个部分:向量获取和向量连接部分.其中,关于向量获取模块又分为两个部分:主题向量获取和句子嵌入向量获取.主题向量获取通过建立主题模型,输入训练数据集,输出主题概率向量.句子嵌入向量则是由BERT模型输入训练数据集获取.在获取主题向量和句子嵌入向量之后,是模型框架的第二部分:主题向量和句子嵌入向量的连接,由于主题向量和句子嵌入向量的维度不同,故而需要采用自动编码器来连接二者.LDA-BERT模型的整体流程图如图3所示.

图3 模型框架图Fig. 3 Model frame diagram
LDA-BERT模型的构建过程是将经过数据预处理过后的缺陷报告数据集分别输入到LDA模型和BERT模型.将LDA模型输出的主题概率向量和BERT模型输出的句子嵌入向量通过自动编码器连接,最后得到LDA-BERT向量.根据LDA-BERT向量进行簇类的划分.
针对主题概率向量获取部分,主题概率向量的获取如图4所示:

图4 主题向量获取步骤 Fig. 4 Topic vector acquisition step
主题概率向量的获取主要分为三步:
1)将数据集进行预处理,详细步骤参考数据集中预处理部分.
2)将预处理过后的数据集,此时已是单词序列,根据单词序列创建词典.
3)将数据集输入模型,设定相应的参数,训练主题模型.
主题模型训练完成之后,主题模型的输出向量即为LDA-BERT模型所需要的主题概率向量.
关于句子嵌入向量部分的获取,本文使用的是BERT模型.BERT模型是一种预训练模型.顾名思义,就是提前利用大规模的语料数据进行训练,获取该类语料数据中丰富的上下文语义信息,然后再将其应用到该类数据集的自然语言处理中去.因此,在获取句子向量之前,需要准备大量的软件缺陷报告,用来进行语料训练.
通过语料训练BERT模型之后,就可以通过BERT模型获取句子嵌入向量.关于句子嵌入向量获取的具体流程如图5所示.

图5 BERT模型流程图Fig. 5 BERT model flow chart
图中,BERT模型通过将输入的文本的每一个词表示成向量,作为模型的输入,除了词向量表示外,模型还会在训练的时候,自动学习表示文本向量和位置向量.文本向量代表文本之间上下文语义信息.位置向量则表示词与词之间的位置信息,例如“这是一个缺陷数据”和“那是一个缺陷数据”,这之间的区别是由位置向量来表示.
预训练模型还会根据特定的任务进行微调,在本文的重复检测任务中,还需要添加[CLS]符号,其符号的意义是用以区分重复或非重复.
关于LDA-BERT模型框架中的第二部分:向量之间的连接.本文采用加权参数来平衡主题概率向量和句子嵌入向量的相对重要性.但由于连接向量位于信息稀疏且相关的高维空间中,因此需要使用自动编码器来学习连接向量的低维潜在空间表示.其中,自动编码器的伪代码如下所示.

自动编码器伪代码输入:主题向量和句子嵌入向量连接后的向量encoded = Dense(input_vec)decoded = Dense(input_dim,activation=self.activation)(encoded)encoded_input = Input(shape=(self.latent_dim,))decoder_layer = autoencoder.layers输出:连接向量在低纬度的潜在空间表示
2 数据集
一份软件缺陷报告的生命周期如图6所示.
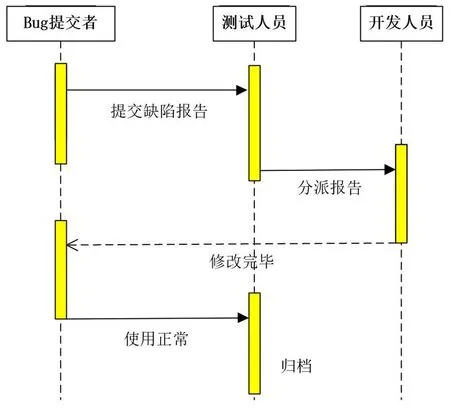
图6 软件缺陷报告生命周期图Fig. 6 Software defect report lifecycle diagram
缺陷报告在经由终端用户或测试人员发现bug并提交给测试人员,测试人员将其分派给开发人员,开发人员在修改完bug之后,让bug提交者进行返测.若是返测成功,则将该缺陷报告记录成档案,进行归档.重复检测主要是针对图中测试人员分派报告给开发人员的步骤,在分派给开发人员之前,先进行一次软件缺陷报告重复检测过程.若是不进行检测,势必会造成同样的缺陷多次指派给开发人员,造成时间和人力的浪费.但在检测过程之前,用户或测试人员提交的缺陷报告的质量也对检测效果有影响.因此,选择合适的软件缺陷报告,即实验数据集的筛选对于实验效果产生至关重要的影响[14].
为了实验效果的准确以及实验顺利地开展,本文实验所选的数据集是来源于大型开源软件的缺陷报告管理库,主要的对象是Eclipse、Mozilla和OpenOffice,Eclipse是一个大型的支持多种语言的开发工具,Mozilla大家可能并不熟悉,但它旗下拥有着我们所熟知的Firefox火狐浏览器,OpenOffice是微软公司的办公软件.之所以选择这三大开源项目,是因为它们具有普遍性,因为涉及的群体具有普适性,所以能够保证缺陷报告的普遍性,并且这三者的开发语言也各不相同.除此之外,同类的研究所用的数据集基本都是来源于这三者的软件缺陷报告库.所以,基于以上的综合考虑,最终选定该数据集.
Lazar[15]等人替后来的研究人员提供了研究重复软件缺陷报告检测的统一数据集的便利,他们通过网络爬虫工具Scrapy爬取了上述三大开源软件项目库中的缺陷报告,爬取的缺陷报告截止日期是2014年年1月1号之前的,并通过镜像方法将数据转储在数据库MongoDB之中.本文直接使用的实验数据是他们经过处理之后转储在MongoDB中的数据,但由于该实验数据过于庞大,因此,需要对该缺陷报告数据集进行一定的筛选,选取部分的数据子集作为本次实验的数据集.本文对数据集的筛选条件主要是按照缺陷报告的时间线,原因是软件缺陷报告的特性通常是离散的,用户在使用软件每隔一段时间才会提交一份缺陷报告,数据并不集中.
本次实验采用的数据预处理主要包含:剔除字段、文本清洗、分词、删除停用词以及词干抽取[16].数据处理步骤如图7所示:

图7 数据处理步骤Fig. 7 Data processing procedure
剔除字段是为了剔除数据集中所不需要的字段.数据集中存在很多冗余的字段,这些字段通常会对实验效果产生影响,因此需要去除与本次实验无关的数据字段.本文主要使用的字段包括Issue_id、Duplicated_issue、Title以及Description.
文本的清洗的主要目的是清洗掉没有任何内容意义的描述语句.在清洗文本过程中,会发现很多报告存在很多与缺陷报告本身并无太大关联,却在缺陷报告中占据大量的存储空间的句式信息,产生相关重复信息,给重复缺陷报告检测的实验结果造成比较大的干扰.因此,要将这类毫无意义的句式信息在缺陷报告文本过滤掉,只保留关键的有用的简洁的缺陷报告文本,以达到实验效果的准确性.
分词.顾名思义,分词是将文本分隔成词序列.英文数据集的分词相比较中文数据集的分词操作更简单,中文数据集需要对字和词语进行识别,而英文数据集不一样,只需要对英文数据集按照空格进行即可,并将英文文本中的标点符号、连接符等特殊符号进行处理,最后只输出成一个单词序列即可.
删除停用词.这一步骤是所有步骤的重中之重,是因为这一步的处理好坏,涉及到最终实验的效果优劣,因为在英文文本中,停用词占据了大量的存储空间,并对缺陷报告本身并无太大意义.
词干抽取.在英文数据集中,不同于中文文本,单词有多种表现形式,例如过去式,现在式词干提取,因此是需要进行词干提取这一步骤的,它是去除词缀得到词根的一个过程,最终得到单词最一般的写法.
3 实验
3.1 评价指标
本文重复缺陷报告相似度的计算采用的是余弦定理计算方法[17],采用向量空间维度之间的夹角进行余弦值计算,如图8所示.
一般来讲,夹角的角度越小则表示两个向量之间的相似度越高,也就表明两篇文档之间的语义相似度越大,也就意味着重复的可能性越大;反之夹角越大则表明两篇文档之间越不可能是重复相似的报告.

图8 向量余弦值计算Fig. 8 Vector cosine calculation
因此缺陷报告的相似度可以使用两个输出向量之间的余弦值大小来表示,其计算公式如下:
COS(V,V′)=V×V′/|V|×|V′|.
(1)
本次实验使用了召回率和精度(Emap)作为模型的评价指标,精度是代表实验预测的精度,召回率指的是在实验预测的正样本占数据集的实际正样本的比例,用来反映模型效果的整体情况.召回率的计算公式如下:
(2)
其中,Ntrue是能够正确找到与其关联的主报告的重复报告的数量,Ntotal是重复报告的总数.
3.2 实验设置
本次实验使用的操作系统为Windows10,编程语言为python,版本为3.6,处理器为i7-10750H 2.60G Hz,硬盘内存为500 G,运行内存为16 G,显卡型号为GTX 3060,12 G显存.
除此之外,在模型训练过程中,模型的参数配置如表1所示,选择的文本最大长度为200,词向量维度为100,学习率为0.000 5,批处理大小设置为32.

表1 参数表Table 1 Parameter list
3.3 实验结果分析
本节将从以下几个方面阐述实验结果:1)不同主题数对主题模型LDA的影响;2)不同主题模型的选取对LDA-BERT的影响;3)与其他模型和基准模型相比,本文所提出的模型和方法是否表现出更优的性能.
3.3.1 不同主题数对主题模型LDA的影响
针对本文的模型,考虑到不同的主题数量会对模型实验效果造成影响,故而设置了主题数从1至12,探究不同主题数量对主题模型LDA的影响,用主题连贯性(Coherence Score)[18]来评价模型的好坏,主题连贯性用来衡量主题之间的主题词是否具有连贯性的.实验结果如图9所示.

图9 主题连贯性得分图Fig. 9 Topic score result graph
从图中可以发现,当topic数量取值为10时,Coherence score得分最高.当topic数量设置少于10或高于10时,Coherence score都呈下降趋势.因此,主题模型LDA的最佳的topic数量应该设置为10.
为了更加直观地看见LDA抽取的主题,本文使用pyLDAvis工具包[19]可视化主题模型LDA下的主题,主题数设置为10,如图10所示.

图10 LDA可视化主题Fig. 10 LDA visual topic map
3.3.2 不同主题模型的选取对LDA-BERT的影响
针对本文模型,考虑到LDA-BERT模型中LDA模型是否为最合适的主题模型,因此将选取主题模型LDA和GSDMM[22]分别和BERT模型进行连接,并对模型的聚类效果进行分析.
对于模型的聚类效果,本文通过UMAP工具来表现两种主题模型的聚类效果优良.UMAP是一种流形数据降维工具,主要分为两个步骤:第一步学习主题向量的高维空间中的流形结构;第二步将其在低纬度中表示.
本文将实验数据集分别输入LDA-BERT和GSDMM-BERT模型中,通过K-means对其输出向量进行聚类,其中,K取值为10.将聚类结果通过UMAP表现出来,绘制成图,聚类效果如图11所示.
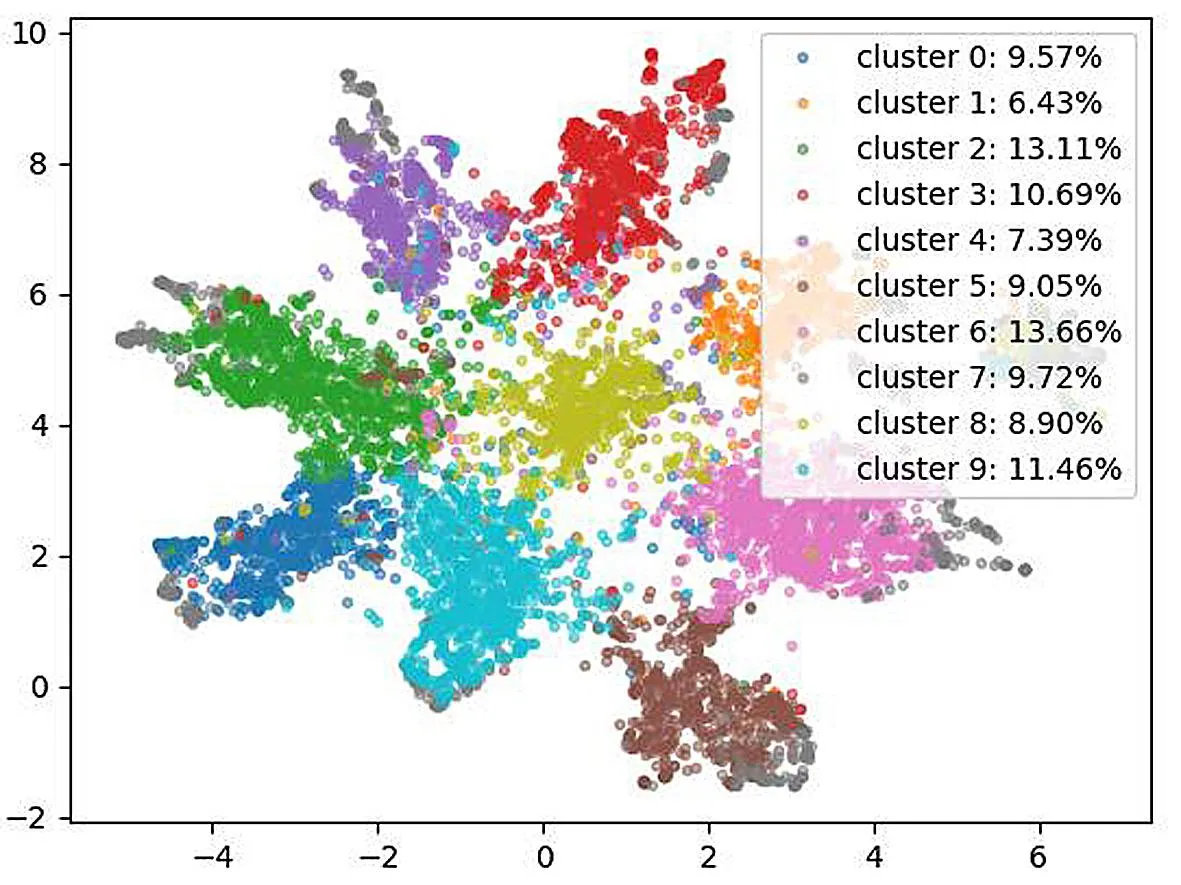
(a)LDA

(b)GSDMM图11 LDA和GSDMM聚类效果图Fig. 11 LDA and GSDMM clustering effect diagram
从上图两种主题模型结合BERT模型的聚类效果图的对比,可以很清晰地发现,在同一份实验数据集下,LDA-BERT的聚类效果远远超过GSDMM-BERT的聚类效果.因此,针对LDA-BERT模型中主题模型部分,LDA-BERT是优于GSDMM-BERT.
3.3.3 LDA-BERT模型对比实验效果
为了验证本文中所提出的模型重复缺陷报告检测的有效性,本次是将初始LDA模型和LDA-BERT组合模型以及DWEN模型和REP模型进行对比实验,结果如表2所示.

表2 不同模型的实验结果Table 2 Experimental results of different models
为了能够更加直观地看到LDA-BERT模型性能的优势,用折线图可视化所有的评价指标.如图12所示,其中y轴表示召回率评价指标得分%,x轴为Top-N,其中N分别取10、100、500、1 000、2 000.

图12 实验结果柱状图Fig. 12 Bar chart of experimental results
从图中可以很清晰地发现在Top-N中,N取值为10时,REP、LDA-BERT的召回率基本相差不大,但与LDA和DWEN相比有着明显的优势,很明显REP和LDA-BERT在Top-10的评价指标上比LDA和DWEN模型更占优.但随着N的取值逐渐变大,LDA-BERT的优势逐渐扩大,这意味着随着N的变大,LDA-BERT检测到重复的报告的能力越来越强.相反,随着N的变大,一开始和LDA-BERT不相上下的REP模型,其检测能力越来越弱,当N取值2000时,REP的召回率在四种模型内最低.DWEN则随着N取值变大,逐渐赶超其他两种模型,但仍然低于LDA-BERT模型.不单单是召回率,从表2中可以发现,LDA-BERT的精度也比同类模型高出约3~8个百分点.
为了验证本文所提出的二级特征向量再检测方法对模型性能的影响,将原模型作为基准和加入二级检测特征向量再检测方法的模型进行对比实验.两组模型的其他参数设置保持一致,即与上组对比模型实验参数一样.实验结果如表3所示.
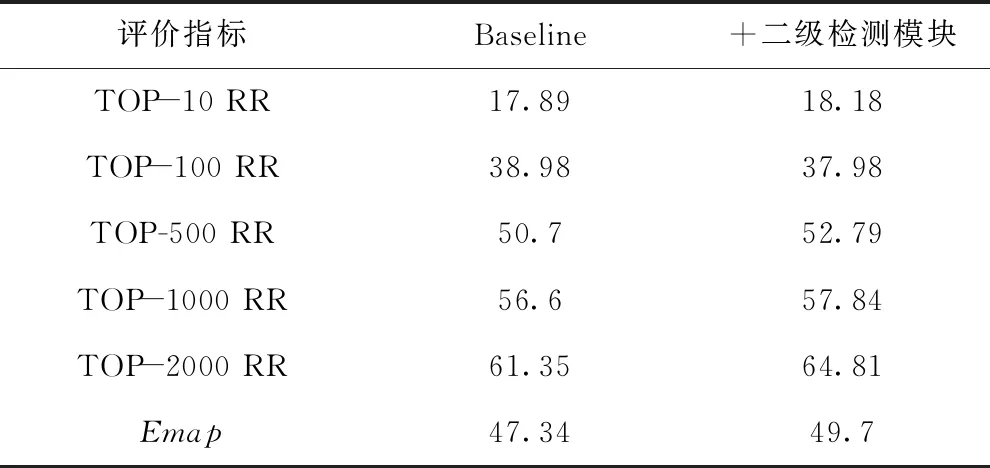
表3 二级检测模块实验结果Table 3 Experimental results of secondary detection module
为了更直观地看到二级检测方法对于基准模型的性能的影响,用柱状图可视化所有的评价指标.如图13所示,其中y轴表示召回率评价指标得分百分比,x轴为对比的实验.

图13 实验结果柱状图Fig.13 Bar chart of experimental results
从上述图表中,可以发现与原模型的对比实验效果,在Top-10,Top-100指标处,两者的召回率是相差不大.甚至在Top-100时,二级检测的召回率比基准模型还要低,这里分析其原因可能是实验误差范围,但当评价指标设为Top-500,Top-1000,Top-2000时,二级检测模块对召回率是有提升的,对照原模型,提升了约有2%~3%的召回率,精度提升了约2.4%.由此可见,二级特征向量再检测方法对于软件缺陷报告重复检测的精度和召回率是有一定提升的,因此二级特征向量再检测方法是有效的.
4 结论
本文提出了一种LDA-BERT模型来进行重复缺陷报告检测,并创新性提出二级特征向量再检测方法.该模型将主题模型概率向量和句子嵌入向量相连接,并将其最后的模型向量进行相似度比对从而进行重复缺陷报告的检测.通过相关的软件缺陷报告数据集的大量实验表面,本论文所提出的方法是有效的. 重复缺陷报告检测研究的目的是更好地解决缺陷分配的问题,这也是未来下一步的研究目标和重点.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
新高考·高一数学(2022年3期)2022-04-28
保定学院学报(2022年2期)2022-04-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
成都信息工程大学学报(2018年3期)2018-08-29
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
电子元器件与信息技术(2017年4期)2017-03-08
高中生学习·高三版(2016年9期)2016-05-14
