
强化学习在军事上的应用
2024-01-18 10:23宋泠澳赵冬梅董宏扬
火力与指挥控制 2023年12期
宋泠澳,刘 涛,赵冬梅,董宏扬
(西南科技大学计算机科学与技术学院,四川 绵阳 621010)
0 引言
随着科学技术的发展和军事理论的不断创新,军事辅助决策系统经过多年建设,取得了长足进步,在数据采集、传输、存储、处理等方面有了不少成果。然而,多场地、无人化、复杂化的现代军事博弈场景,需要高精度、多角度、多层面的全局或者局部决策,单纯依靠人力进行指挥调度与作战决策正变得愈发困难[1],这导致在现代战争高烈度、快节奏的博弈环境下,在有限时间内进行决策分析十分困难。且现有的决策支持系统在情报处理、态势认知、文书生成和方案评估等方面,距离实战要求还有很大的距离,与现代智能化战争的发展趋势不相适应,亟待人工智能技术的介入。
近几年,强化学习(reinforcement learning,RL)被广泛应用于交通、自动驾驶、自然语言处理等多个领域[2-9],其基本思想是通过将智能体(agent)从环境(environment)中获得的累计奖赏值最大化,以学习完成目标的最优策略,因此,RL 方法更加侧重于学习解决问题的策略[10]。
本文主要就强化学习技术在军事领域的应用进行分析与总结,包含军事领域的5 种强化学习算法。基于以上5 种算法,介绍了13 种强化学习在军事方面应用。通过以上6 种强化学习算法与13 种强化学习在军事方面的应用,分析强化学习在军事领域的可能应用领域以及未来发展趋势。本文分别列举了强化学习在海、陆、空领域的应用,并分析强化学习对军事智能决策系统搭建以及智能装备发展的作用。
1 Q-learning
Q-learning 是一种无模型强化学习算法[11],它的目标是学习一种策略,告诉agent 在什么情况下要采取什么行动。Q-learning 不需要智能体直接与环境互动(off-policy),不需要环境模型;可以处理随机转换和奖励的问题,无需进行调整;每次更新状态时都可以使用在训练期间内任意时间点收集的数据,而不管获取数据时智能体的选择。下面3 个例子说明了Q-learning 的军事应用可行性。
1.1 空战目标分配
目标分配是空战中一个重要而又困难的问题[12-13],大多数目标分配算法都被证明过于缓慢或不稳定,无法收敛到全局最优[14-15]。2004 年,HONG等利用Q-learning 建立制造环境动态变化模型,进行多目标调度决策[16];2005 年,WANG 等将Q-learning 算法应用于机器调度规则的选择,检验了将Q-learning 算法应用于单机调度规则选择问题的效果,证实了具有Q-learning 算法的机器代理能够为不同的系统目标学习最佳规则[17]。2006 年,JUNE等在设计一种二维移动机器人时采用了Q-learning,该机器人在学习未知环境后能够独立移动,提出了一种基于Q-learning 的空战目标分配算法[17]。
2016 年,国防科技大学验证了Q-learning 是一种适用于空战目标分配的强化学习算法,可以用来寻找最优的行动选择策略[18]:首先,对空战智能体的属性、结构和动作进行建模;其次,定义了状态-动作对的判据,给出了基于Q-learning 的目标分配算法,当学习到设计的动作-价值函数时,可以通过选择每个状态中值最高的动作来构造目标分配最优策略,实例分析表明,该算法不需要大量的训练集,避免了对先验知识的依赖,而且具有很好的寻优能力,能够很好地摆脱局部最优[19]。
1.2 动态目标防御
2019 年,有学者从系统角度分析了动态目标防御技术中不同参数对系统的影响,建立了系统正常服务与重配置过程模型,在马尔可夫决策过程的动态目标防御(moving target defense,MTD)策略优化方法基础上,引入Q-learning 算法生成了优化策略集合,来保证在一定时间内生成最优策略,解决了多层次多变化参数集合的动态防御技术的策略优化问题[20]。其基本思想是对每个状态s 和该状态上可以采用的行动aI0=ω1I1+ω2I2+…+ω3I3直接估计其回报因子Q(s,a),s∈S,a∈A,并在选择行动时按照式(1)进行:
该方法既不需要计算数学期望,也不需要估计转移状态的信息,可以计算出优化后的动态目标防御重配置策略,并且能够较好地平衡系统的可用性和安全性,指导动态目标防御技术实际部署问题[21]。
1.3 空战系统的数据融合
随着科学技术的飞速发展和信息技术的广泛应用,大量先进的传感器应用于空战信息系统中,空战的复杂性和对信息处理的要求越来越高,导致数据融合技术在现代信息空战中发挥着越来越重要的作用,研究空战系统中的数据融合技术具有重要意义[13]。
2019 年,为提高现代空战数据融合系统的精度,南京航空航天大学提出了一种基于Q-learning的改进方法,在不需要适应环境的情况下,处理随机过渡和奖励问题[22]:在空战中,传感器系统由多个不同的传感器组成,为了获得最优信息,假设传感器的个数为n,每个传感器都有相应的权值ω1。输出融合数据I0可以按式(2)计算:
该方法融合数据I1,I2,…,In对传感器1,传感器2,…,传感器n 进行监控,对于每一个输出数据,数据融合系统对ω1,ω2,…,ωn有最佳的权重选择,并采用强化学习方法进行权值更新。该系统可以根据每个观测值调整权重,通过观测值与实际值之间的误差来实现融合精度的增强。实例仿真结果表明,该方法可以解决不同传感器的数据处理问题[23]。
上述研究工作展示了Q-learning 在军事领域中的实际应用,表明Q-learning 可以在数据相对较少的情况下得到策略,因为其只需要在一个以state 为行、action 为列的Q-table 中找出最优解。但在大多数情况下,由于State 过多导致Q-table 大于预期估计,使得该模型不能在规定时间内得出解或者无法得到解,这一点对于其在军事应用方面是致命的。针对这种情况,通过引入深度学习代替Q-table 去处理Q 值,可以有效避免Q-table 的低效问题[24]。
2 deep Q-network(DQN)
Deepmind 团队在2013 年提出了deep Q-network(DQN)算法[24],实现了卷积神经网络(CNN)与Q-learning 的结合,将强化学习的决策能力和深度学习的交互能力相结合,能在复杂军事环境中通过智能体与环境交互得到的数据,不断更新网络参数,使得神经网络可以较好地逼近动作状态值函数,更好地作出适合相应状态的动作,达到军事决策的时间和精度要求。
2.1 无人作战飞机
无人战斗机(unmanned combat air vehicles,UCAV)是一种多用途的新型空中武器,可以执行空中侦察,地面目标攻击以及空中作战[25]。早在1933年,无人机就作为“靶机”出现。到了2001 年,美国“捕食者”无人机在阿富汗战场上首次作为攻击者执行了精确打击任务;2003 年,“捕食者”再次作为攻击者实施了“斩首行动”,击毙了“911”主犯阿布-阿里;其后的伊拉克战争中,美国共计投入了高达60 架无人机参与战争。
2019 年,YANG 等提出了一种基于强化学习的无人机近程空战自主机动决策模型,主要包括空战运动模型,一对一近程空战评估模型和基于深度网络(DQN)的需求决策模型[26]。该作者认为面对空战环境等高维连续状态动作空间,应该选择DQN 算法作为强化学习的算法框架,利用深度神经网络来逼近价值函数,使用分阶段训练方法对DQN 进行训练,称为“基本对抗”,这种基本对抗是基于人类从简单认知逐渐过渡到复杂知识的学习过程,这种基于DQN 的决策模型能够实现自学习和策略更新,直至目标被击败。
2.2 水下无人车辆的路径规划
水下无人车(unmanned surface vehicles,USV)可作为一个单位部署执行水下任务,路径规划是这些任务完成前提条件的核心。
2016 年,周新源等提出了基于深度DQN 的路径规划算法,用在USV 编队路径规划中[27]。认为将DQN 训练方法用于高维状态和动作场景,不需要Q表格,不需要人类知识与设定规则,通过从以前的状态转换中随机训练,来克服相关数据和经验数据非平稳分布的问题,还可以通过DQN 的目标网络和Q 网络实现训练的稳定性。该算法能够计算编队的合适路径,并在必要时鲁棒地保持编队形状或改变形状,可在具有复杂障碍物的环境中辅助导航。
无人机与无人车辆领域对于DQN 的应用展示了强化学习在智能装备方面有着重要作用。由于DQN 引入了深度学习,其在交互能力上有较大的优势,但在样本标定上也如同深度学习一般较为费时。DQN 在训练时,存在收敛速度慢的缺点,解决思路为更改目标函数来加快收敛速度[28]。
3 actor-critic(AC)
AC 算法框架被广泛应用于强化学习算法的实际应用中,该框架集成了值函数(value function)估计算法和策略评估(policy evaluation)算法,是解决实际问题时最常考虑的框架。其带有对抗性的网络结构,对于军事领域的决策与评估有着较高的适应性。
3.1 自动态势估计研究
2018 年6 月,吴志强等提出了态势预测,并与深度强化学习相结合,利用A3C(asynchronous advantage actor-critic)方法,在预测的基础上,作出的战术行动达到最优效果[29]。
自动态势分析属于认知智能的范畴,基于深度强化学习技术的指挥员agent 可以具备自主认识战场态势,并根据态势演变作出预测的能力。在智能决策系统中,指挥员agent 可引入actor-critic 模型用于自动态势分析,如下页图1 所示。

图1 Actor-Critic 自动态势估计模型Fig.1 Actor-Critic automatic situation estimation model
态势估计可分为态势分析、态势理解和态势预测3 个阶段。态势预测是态势估计问题的难点,利用actor-critic 模型进行强化学习,使得在预测的基础上作出的战术行动达到最优效果。
3.2 导弹目标态势评估模型
2001 年,周锐等讨论了强化学习在导弹制导领域的应用[30];2020 年将强化学习(RL)中的actor-critic(AC)算法引入导弹的目标态势评估模型中,建立导弹-目标模拟作战训练模型,通过仿真和对比实验表明,该模型能有效估计当前形势下导弹攻击的预期效果,得到飞机躲避导弹的最优决策模型。AC 算法结合神经网络模型,可以预测飞机在受到导弹攻击时的状态,并估计可能出现的最坏结果,从而实现导弹对目标攻击效果的评估和预测[31]。
导弹的目标态势评估模型中主要发展是利用强化学习(RL)算法设计空战场景,为人工智能神经网络提供训练数据和反馈奖励。具体做法为:将态势评估定义为对未来收益的估计,并建立导弹-目标作战模型。采用行动者-批评(AC)算法,得到飞机躲避导弹的最优决策模型。AC 算法得到的神经网络模型,可以预测飞机在受到导弹攻击时的状态,并估计可能出现的最坏结果,从而实现导弹对目标攻击效果的评估和预测。
3.3 战争机器人混合动态控制算法
2007 年NAKAMUR 等改进了AC 算法,并引入到两足机器人的控制算法中[32]。将机器人最早应用于军事行业始于二战时期的美国,为了减少人员的伤亡,作战任务执行前都会先派出侦察无人机到前方打探敌情。文献[32]提出了一种基于强化学习方法中的AC 算法框架的CPG-actor-critic 方法,并将此方法应用于TAGA 等所使用的两足机器人模拟器[33]中。得到的计算机仿真结果表明,采用强化学习方法中的AC 算法可以成功地训练CPG,使两足机器人在矢状面(the sagittal plane)稳定行走,能适应环境的变化,并使控制器能够产生稳定的节奏进行运动。
该方法采用自然政策梯度法,其梯度的估计接近于最陡下降的梯度。对于战争机器人来讲,其在战场上的动作连续性是其作战的根本保障,CPG-actor-critic 体系结构和自然梯度方法相结合,实现了一个高效的RL 系统。该算法具有大量的自由度,使两足机器人能够像人一样面对复杂的战场环境。
3.4 空战环境导弹规避
空空导弹(air-to-air missile)是歼击机的主要武器之一,它属于典型的精确制导武器。在2020 年,我国航空工业集团公司洛阳电光设备研究所提出了一种基于DDPG 算法的深度强化学习模型[34],其训练仿真测试分析表明能够有效地实现对来袭导弹的规避决策。该模型将DDPG 的策略网络作为决策控制器,完成了对战场态势到决策输出的映射,使策略网络向累计回报更大的方向收敛,并将累计期望奖励值最大的策略网络作为规避导弹的最佳策略。
在空战导弹规避问题上,基于DDPG 的深度强化学习算法,能够得到比较好的训练和仿真结果,在高度、速度保持中有很好的表现。该算法需要不间断保持对于距离、高度、接近速度等关键参数的获取,为其连续动作提供支持,以达到规避导弹的目的。
3.5 无人机自主决策
无人机在未来的空战中将发挥巨大的作用,能够压制和摧毁敌人的防空,并打击高价值目标。使用DDPG 算法,可以使无人机在复杂的空战环境中拥有更好的适应性,进行自主优化决策[35]。
空战领域中的学习策略,一般会经历以下步骤:首先,将在攻击区域收集大量的模拟数据,并构建深度学习可使用的网络;然后通过新环境中的真实值来修正网络的模拟值;最后,通过强化学习的方法使无人机自主修正攻击区域。因此,无人机需要在作战中独立地识别周边环境,并使用正确的优化方法来解决神经网络的适应性问题。深度学习是一种在无人机数据处理中广泛应用的方法,而强化学习能够赋予无人机自主决策的能力,两者的结合将使无人机在空战环境中表现更加优秀[26]。
DDPG 相较于其他深度强化学习领域的方法,拥有经验池机制和双网络结构,使得学习过程更加稳定,收敛速度更快。2020 年,LI 等提出了一种有效解决无人机自主决策问题的DDPG 算法[36]。DDPG 算法可以很好地满足无人机在复杂空战环境中的需求,且拥有传统神经网络算法没有的自主学习能力和连续动作域来解决连续问题,对于快速变化的空战环境具有强大的适应性。
态势评估是指挥决策的重要部分,在智能作战指挥上有着重要作用。上述例子中展示了强化学习在态势评估上的适用性,actor-critic 网络可以通过评估网络(critic 网络)对预测网络(actor 网络)进行评判更新,这种具有对抗性的评估网络,可以在指挥决策的对抗博弈中提供优良决策。
4 多智能体强化学习
多智能体技术(multi-agent technology)的应用研究起源于20 世纪80 年代,并在90 年代中期获得了广泛的认可[37],现今已经成为了人工智能领域中的研究热点,在感知、学习、规划、推理以及决策等方面具有较好的优势[38]。
多智能体系统(multi-agent system,MAS)是在同一个环境里,由多个智能体组成的系统[39],常用于解决单一智能体或单层系统难以解决的问题,其中的智能可以由方法、函数、过程、算法或强化学习来实现[40]。在军事领域中由于所面对场景的复杂性,作战单位的部署往往是多元化的,与单智能体强化学习相比,多智能体强化学习能更好地协调不同作战单位之间的协同性,提高不同作战单位之间的联系,更好地达到作战目标。下面将以无人集群协同以及战时备件供应保障动态协调为例子,分析多智能体强化学习在军事领域的应用性。
4.1 无人集群协同
无人作战已经是现代化战争的主流,采用多智能体强化学习算法的无人集群协同作战已经有良好的效果。无人集群系统的协同控制(guided deep reinforcement learning for swarm systems,GDRLSS)包含协调和合作两个方面。协调的目的是为了避免无人集群在执行任务的过程中内部之间发生冲突,即无人集群中的动作控制。合作的目的是让无人集群互相协作,共同完成任务,即组织和决策机制问题[41]。
运用强化学习等技术能够使无人集群平台的自主控制有更好的适应性和灵活性,能够增强无人集群的协调协作,提升无人集群系统的整体性能。在无人平台系统中,单个无人平台感知的环境信息是局部的,因而传统单智能体强化学习算法的策略不具有普适性。为了解决该问题,多智能体强化学习在此基础上增加了系统中智能体的数量,并通过引入分布式协同策略机制,使每个智能体具有自主性、目的性和协调性。
采用多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)[42]算法框架进行学习。无人集群强化学习框架如图2所示。
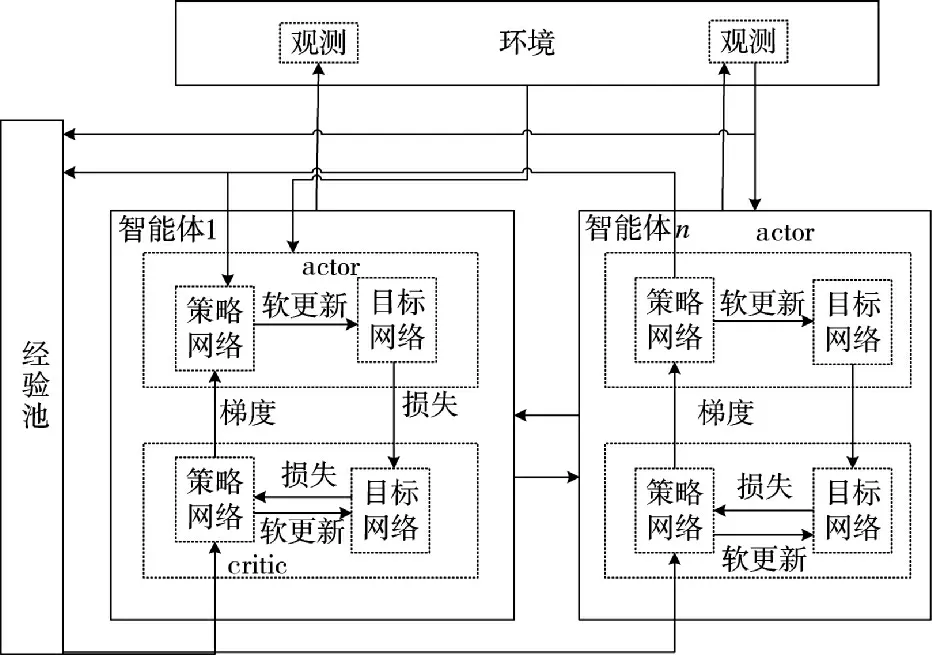
图2 无人集群强化学习框架Fig.2 Reinforcement learning framework for unmanned swarm
当前军事无人集群系统的作战研究中,采用了多智能体强化学习方法实现无人集群系统的分布式协同控制[22]。随着武器装备体系智能化升级与现代战争节奏不断加快,以及无人集群作战平台及其新技术的发展与应用,未来战争要求无人集群具备快速、自动和自主决策能力,因此,采用强化学习算法不断优化模型,提升无人集群协同作战能力,已成为当前主要研究思路。
4.2 战时备件供应保障动态协调
战时备件供应保障系统(wartime spares support system,WSSS)是为满足战场环境条件下航空装备对备件的需求,战时备件供应保障的特征主要是自治性、分布性等。而多agent 系统符合这些特征,采用仿真技术对战时备件供应保障进行模拟和研究,运用多agent 强化学习建模仿真技术,来模拟研究目前战争任务中各个阶段供应保障过程中的协调效果,由仿真结果可以得出结论,强化学习策略明显优于平均随机分配策略[43]。
与单智能体强化学习相比,多智能体强化学习在环境适用性上有着较强的适用性,与一般的应用场景不同,强化学习在军事上的应用面临着多场地、高纬度、复杂化的军事博弈场景,要求高精度、多角度、全域性的作战指挥决策,环境的复杂性使得单一智能体的泛化能力受到严重的挑战,面临着精度不足、鲁棒性不够和难以设计的特点。多智能体强化学习遵从的是随机博弈过程,它更关注合作型智能体之间互相配合,能够完成高复杂度的任务;竞争型智能体之间也可以通过博弈,互相学习对手的策略,这在军事博弈方面多智能体强化学习更是考虑到局部最优与全局最优之间的“协调”,在作出全局最优决策的情况下,保障了局部策略的权益。
5 逆强化学习——舰载机甲板调度
强化学习的奖励函数是人为给定的,而且对学习结果有着重要的影响,但在很多复杂的环境之中,奖赏函数通常难以确定,所以就有了逆向强化学习[44]。逆向强化学习的目标就是找到一个合适的奖赏函数,思想是专家在完成某个任务时,所作出的决策一般是最优的、或者接近最优的,所以可以通过专家的决策来学习找到合适的奖赏函数。本章以舰载机甲板调度问题举例,说明逆强化学习在军事方面的应用。
舰载机甲板调度是影响航空母舰战斗力的重要因素,早在1966 年就已经出现了计算机辅助调度系统-舰载机甲板操作控制系统(carrier aircraft deck operation control system,CADOCS)[45];1974 年GIARDINA 和JOHNSON 完善了CADOCS[46-47],但是没能得到充分的应用;2002 年,TIMOTHY 提出了基于智能agent 调度系统的需求分析[48],得出数字化甲板调度系统是必然趋势的结论;2009 年,JEFFREY 等设计了一种能够提供危险预警和舰载机的路径规划的甲板持续监控系统[49],同年美国海军开发出了舰船综合信息系统(integrated shipboard information system,ISIS)[50];2011 年,RYAN 等为美国海军自动项目研究所设计开发了一个为甲板指控人员提供舰载机作业流程和辅助调度方案的航空母舰甲板行动规划软件(aircraft carrier deck course of action planner,DCAP)[51];2013 年,李耀宇等提出了基于逆向强化学习的舰载机甲板调度优化方案生成方法[52]。
李耀宇等以“尼米兹”级航母作为研究对象,建立基于MDP 的舰载机状态转移模型,通过逆向强化学习,该文章为模拟指挥人员的调度演示学习并确定优化后的回报函数,再通过强化学习生成优化过后的舰载机甲板调度方案[52]。
实验证明该方法具有较好的拟合效果,所生成的优化策略方案是可行并符合实际需求的。该方法有助于我国航母的甲板调度工作优化,提高航母战斗力。
6 面临的挑战
综上所述,强化学习在军事应用的诸多应用中均可提供强有力的自主/辅助决策能力,在不涉及先验模型或者数据的前提下,获得比较准确的结果。但是,强化学习发展至今,依然存在一些问题,在其与军事应用相结合前提下,鉴于军事应用往往对于时间、效率、精度等要求与常规问题很大区别,强化学习的效率问题、奖励问题,局部最优与全局最优等问题则凸显出来,成为当前强化学习在军事应用中进一步开展的挑战,下面一一说明。
6.1 样本效率问题
提升样本效率可以减少训练时间,节约军事资源,提高决策和反应速度。解决该问题有3 种思路:第1 种可以通过重复利用数据样本来提高效率;第2 种思路是简化状态表示和行动表示,使其在运行过程中加速迭代以达到提升样本效率;第3 种思路是利用先导经验示例数据来提升样本效率[53]。
6.2 稀疏奖励问题
在训练过程中,智能体采用随机策略,而奖励的获取则需要一系列复杂的操作,由于智能体在军事场景中初始化策略下很难获得奖励,使得强化学习算法迭代缓慢,甚至难以收敛,从而导致学习成本高昂,相关应用难以落地实施。改进奖励函数[28]以及增加奖励估计模块,可以在一定程度上避免稀疏奖励的问题。
例如作战无人机群在开始训练时,设定击毁某个目标或者到达某个区域会获取到一定的奖励值,但在无人机起飞到得到奖励值这一阶段之间还有着若干动作和状态,在这些状态下并不会获取到奖励值,这将导致作战无人机训练过程迭代次数增加,加大训练成本。通过对奖励函数的改进,使得无人机在无奖励值阶段减少迭代次数或者增加奖励估计模块,来引导无人机获得奖励可以减少训练成本,加快相关应用的实施。
6.3 奖励函数定义问题
在军事应用多变、复杂的环境中,设计一个合理的奖励函数并不容易,尤其当涉及到的agent 动作较为复杂、场景范围较大时,奖励函数的合理定义依然存在很大困难。在军事领域奖励函数设计时,可以考虑使用多智能体强化学习由局部奖励函数到整体奖励函数这一过度途径,以及逆强化学习人为给定奖励函数,来降低奖励函数难以定义的问题[54]。
以稀疏奖励中的作战无人机群来讲,改进的奖励函数能够减少稀疏奖励的问题,但是设定无人机群获得奖励的函数定义是比较困难的,这时增加智能体如将无人机群中每一个无人机设定为智能体,单独设定单个无人机的奖励函数,最终达到一个总的奖励函数值,达到简化奖励函数的目的。
6.4 强化学习容易陷入局部最优
强化学习本质上是智能体与环境之间不断探索和交互的过程,在智能体取得一定的奖励之后,单纯从奖励层面看,其可能会陷入到局部最优陷阱中,从而导致无法得到全局最优结果。该问题可以通过增加好奇心驱动机制来解决[55],避免陷入局部最优,这就要求设计网络时将好奇心机制加入网络。
该问题会影响相关强化学习应用的落地实施,更好地解决以上4 点挑战, 将使得强化学习应用在军事领域发挥更大的作用。
7 未来发展趋势
强化学习的大力发展得益于计算能力的大幅提升和相关算法的研究,其并不具备如人类一般在战场上进行主管决策的能力,如上文的例子,强化学习需要结合场景与状态,为军事指挥人员提供当前状态下的决策支持。基于强化学习本身特点与优势,以及当前军事应用的特点,强化学习应注重在以下几个领域的发展:
7.1 基于模型的强化学习
基于模型方法能根据历史经验生成环境模型,通过使用内部模型来推理未来。虽然需要先验学习模型,但基于模型的方法具有更好的泛化能力,且能够利用额外的无监督学习信号,在面对多场地、多维度、复杂化的军事博弈场景,能够有效的提高数据效率。
7.2 强化学习相与迁移学习、深度学习、协同学习等人工智能技术结合
强化学习在表达能力以及反馈机制上有所不足,与其他人工智能技术相结合可以弥补强化学习的不足。深度学习在特征提取上有着较大的优势,前面DQN 就是深度强化学习的代表[24]。在一些陌生或者小样本军事应用场景中,数据样本并不足以完成强化学习的训练,强化学习与迁移学习相结合,可以有效解决小样本数据以及个性化问题。而多智能体强化学习中,智能体之间的协同学习将加速模型收敛、提高智能体之间的协作性。
7.3 强化学习与真实军事应用场景建模与融合技术
强化学习的本质决定了其运行环境的质量好坏,它将直接决定结果的质量,然而在实际的军事应用场景中,往往呈现不完全透明/单向透明、场景复杂、范围广、参与单位层次多,以及存在随机问题等诸多制约因素,且相互之间存在一定的耦合影响。因此,对军事应用场景的快速准确建模、不确定因素的量化考量,以及强化学习与构建场景的相互融合,将成为一个重要的支撑技术。
此外,强化学习被认为是通往通用人工智能的关键技术,强化学习不同于其他机器学习技术,它的核心是决策,这也是强化学习与军事领域有着较高适应性的原因,但是解决在一定算力的情况下达到既定效果,也是强化学习未来发展的趋势。
8 结论
随着现代军事博弈过程和环境的越发复杂化,强化学习侧重于学习解决问题的策略特性在军事领域凸显出了其特殊性。强化学习在诸多军事应用领域中正在发挥着越来越重要的作用,目前已经在无人装备的自主决策领域得到了有效利用,同时在目标分配与防御、复杂数据融合、供应保障动态协同,以及航母的甲板调度问题等复杂军事应用得到了应用,并显示出良好的应用势头和优势。随着相关技术和计算机技术的不断发展,在博弈论思想基础上,强化学习亦可在军事战略布局、作战指挥决策等领域,为多层次和非线性、行为多样性和信息不完备的复杂问题分析和决策提供有力的支撑。
猜你喜欢
小哥白尼(军事科学)(2022年1期)2022-04-26
小哥白尼(军事科学)(2019年2期)2019-04-17
小哥白尼·趣味科学画报(2019年12期)2019-02-28
军营文化天地(2017年6期)2017-06-28
岷峨诗稿(2017年4期)2017-04-20
新高考(英语进阶)(2017年12期)2017-02-26
百科探秘·航空航天(2015年10期)2015-11-07
军事文摘(2009年9期)2009-07-30
全国新书目(2009年24期)2009-07-17
军事文摘(2009年5期)2009-06-30
