
基于Stackelberg博弈的异步联邦学习激励机制设计
2024-01-27 13:41李炳泽
现代信息科技 2023年24期


摘 要:联邦学习作为能够保护数据隐私和保证数据安全的新型分布式机器学习被广泛关注,异步联邦学习作为传统联邦学习的变种,能有效提高模型训练效率。激励机制的引入能够帮助异步联邦学习有效提高模型训练效用。利用Stackelberg博弈构建了一个联邦学习激励机制,分别对中心服务器和数据拥有者效用进行优化。在此基础上,推导出了整个博弈的均衡解,最后通过算例分析了模型的可行性,得到最优的激励效果。
关键词:联邦学习;Stackelberg博弈;鲁棒优化;数据质量;纳什均衡
中图分类号:TP181;TP309 文献标识码:A 文章编号:2096-4706(2023)24-0037-04
Design of Incentive Mechanism for Asynchronous Federated Learning Based on Stackelberg Game
LI Bingze
(School of Management Engineering and Business, Hebei University of Engineering, Handan 056038, China)
Abstract: Federated Learning, as a new type of distributed machine learning that can protect data privacy and ensure data security, has received widespread attention. Asynchronous Federated Learning, as a variant of traditional Federated Learning, can effectively improve model training efficiency. The introduction of incentive mechanisms can help asynchronous Federated Learning effectively improve model training effectiveness. A federated learning incentive mechanism is constructed using the Stackelberg game, which optimizes the effectiveness of the central server and data owner. On this basis, we derive the equilibrium solution of the entire game, analyze the feasibility of the model through numerical examples finally, and obtain the optimal incentive effect.
Keywords: Federated Learning; Stackelberg game; Robust Optimization; data quality; Nash equilibrium
0 引 言
在过去几十年中,随着人工神经网络算法和云计算环境的发展,机器学习取得了前所未有的成功。尽管数据信息发展给生产发展带来了许多便利,但同时数据安全和信息隐私也成为数据用户关注的首要问题。用户对数据隐私风险更加谨慎,对系统中的交互信息更加敏感,希望个人隐私数据不会被泄露用作它用。各国开始提高对用户个人隐私、商业机密、数据安全的重视程度。各项法规的建立、用户隐私意识的提升对于传统的分布式机器学习来说都是全新的挑战。与此同时,随着数据权利意识的提高,越来越多的实体强调数据的所有权和使用权,特别是在一些重点行业,如医院、银行等,并不允许彼此之间交换数据来进行机器学习。没有用户的同意,无法利用这些隐私数据来进行分析。这就造成了一种被称为“数据孤岛”的现象,它是指由于数据流通率降低,不同实体之间的数据无法有效地交流和共享,从而造成数据封闭和孤立的现象。这种现象的出现使得简单的分布式机器学习无法有效解决大规模数据集的训练问题。
联邦学习作为一种新兴的分布式机器学习模型被提出[1]。联邦学习被认为是最有能力能够突破“数据孤岛”的机器学习模型,并受到了广泛的关注[2]。异步联邦学习作为传统联邦学习的变种,通过在不同设备上的本地模型参数的异步通信来实现模型的训练。与传统联邦学习不同,异步联邦学习不需要等待所有设备完成本地训练之后再發送更新参数,从而可以更快地完成训练。目前,异步联邦学习的相关研究主要考虑的是异质性、异步联邦模型优化等问题[3],为提高模型效率、确保模型有效性和保证隐私安全。然而,这些研究都是在一个乐观的前提下,即所有的数据拥有者都会无条件参与和上传更新参数到中心服务器中。但事实上,异步联邦学习模型训练效果在很大程度上取决于数据拥有者所能提供的数据质量,并且数据拥有者需要消耗大量的计算资源和通信资源,如果没有一定的激励,这些数据拥有者可能不愿意使用自己的数据来参与异步联邦学习其中涉及多方参与且参与方之间在数据质量方面的存在差异,导致数据拥有者不愿参与或不愿使其自身在参与联邦学习时处于不公平的地位。因此设计激励机制对异步联邦学习系统推广应用至关重要,本文考虑引入Stackelberg博弈来设计异步联邦学习激励机制,对数据拥有者和任务发布者的效用都起到有效激励作用。
1 模型构建
我们考虑由一个任务发布者和多个数据拥有者组成的异步联邦学习如图1所示。其中异步联邦学习第一步将模型训练任务分发给不同的数据拥有者,每个数据拥有者独立地运行本地训练,并在训练过程中周期性地将其本地模型更新发送给中心服务器。中央服务器收到这些更新后,可以将它们合并为一个全局模型,并对更新后的全局模型进行分析,重新给数据拥有者发送新的模型训练任务,每个设备都可以使用最新的全局模型根据新的训练要求来继续本地训练。具体来说,在异步联邦学习模型训练中,每个数据拥有者都将各自的私有数据存储在本地,根据中心服务器设置的初始模型和参数要求,利用局部数据进行模型训练。在联邦学习中,每个数据拥有者在完成本地模型训练任务后,将训练得到的模型参数传回联邦学习中心服务器。服务器聚合这些更新参数,以更新全局模型,并向数据拥有者下发新的迭代任务。数据拥有者需要按照要求持续迭代训练,直到达到目标性能或预设的迭代次数。这种方式可以避免集中式训练中的数据隐私问题,同时加快了模型训练的速度。
假设每个数据拥有者n ∈ N拥有相同的局部数据样本大小来参与联邦学习。但每个数据拥有者使用不同的CPU周期频率来训练局部模型fn。在完成一项数据训练的CPU周期数由cn来表示。因此,本地模型训练计算所需时间为Tn = (scn / fn),则在完成一次局部数据训练时CPU消耗能量为: [4]。数据拥有者的训练效率表示为λn,使用log(1 / λn)来表示局部训练的迭代次数,则全局迭代的模型更新计算时间为:。数据传输过程中,传输速率可以表示为:rn = B ln(1 + ρnhn / N0)),B为传输宽带,ρn是数据拥有者的传输功率,hn是传输信道增益,N0是背景噪声。则局部模型更新的传输时间为:
假设数据拥有者获得报酬为Rn = qn fn,其中qn为数据拥有者使用CPU频率fn工作的单位价格[5]。数据拥有者提供更多的计算资源,局部模型训练速度越快,从而获得更高回报。数据拥有者可以随意选择签署合同来完成联邦学习任务。但如果不能按照所选合同完成联邦学习工作,则不能得到既定报酬。
将任务发布者效用定为全局迭代时长:
当数据拥有者n从任务发布者那里获得相应报酬Rn时,考虑到参与学习过程中产生的能量损耗,而其能量损耗取决于CPU的功率大小。因此对于每个数据拥有者而言,其目标是使其自身利润最大化,即:
该式受到fn≤fmax约束,其中fmax为数据拥有者CPU功率的上限,μ是预设的能量消耗权重参数。
2 基于Stackelberg博弈的激励机制求解
运用Stackelberg博弈构建模型,下层博弈为:
上层博弈为:
一般而言,Stackelberg博弈的均衡可以通过找出其最优的纳什均衡来获得。在本文构建的博弈中,给定数据拥有者CPU功率的单价后,数据拥有者之间是非合作博弈关系,对于非合作博弈,纳什均衡定义为没有任何一个参与者可以通过改变自己的策略来提高收益。对于非合作博弈,若博弈满足:1)博弈参与双方集合有限。2)博弈的策略空间集合数据优势空间的有界闭集。3)非合作博弈的利润函数在策略空间上是连续且满足凹函数特性。则该博弈中存在纳什均衡,每个博弈方的效用都会最大化,任何参与者都无法通过自私改变自身策略来获得更高收益。本文构建的博弈中,博弈的参与者数量有限,中心服务器所能提供的最优CPU频率单价都是欧式空间中的有界闭集合,并且下层博弈的效用函数随自变量连续变化,利润函数满足凹函数特性。将下层博弈的利润函数对CPU功率求一阶导数和二阶偏导数可知,二阶偏导数结果为负,利润函数满足严格凹函数特性,因此该Stackelberg博弈模型存在子博弈纳什均衡解。
对于上述构建的博弈模型,我们考虑求得任务发布者与数据拥有者的Stackelberg均衡解问题。针对考虑未知数据质量的Stackelberg博弈,利用反向归纳法来确定上下层博弈均衡解[6]。首先针对下层博弈,根据一阶最优性条件来求其均衡解。之后,将得到的下层均衡解带入上层博弈中来寻求博弈解决方案。异步联邦学习的Stackelberg博弈如图2所示。
为求出数据拥有者在下层博弈中的均衡解,取下层博弈中的利润函数对CPU功率fn进行一阶求导可得:
令上述等式为零,可得到数据拥有者的CPU功率为:
首先将下层博弈达到均衡解时数据拥有者的最佳CPU功率替换到上层博弈的效用最大化问题中。因上层博弈问题的约束条件是线性的,因此采用拉格朗日法求解。优化问题的拉格朗日函数为:
为了得到最优解,对上述拉格朗日函数 中的qn进行一阶求导,并通过KKT条件得出拉格朗日乘子α在最佳点的值为:
对上层博弈的效用函数求一阶导数可知,上层博弈效用函数与数据拥有者提供的CPU功率fn为负相关。任务发布者支付报酬时的CPU功率单位价格与数据拥有者提供的CPU功率之间为正相关。由此可知上述等式右侧第一项为正,又因第二项恒为正,综上可知,拉格朗日乘子α>0恒成立。
结合上述KKT条件中:
可知:
因此根据KKT的互补松弛条件,该博弈的纳什均衡解存在于边界上。因此对于所有n ∈ N,上层博弈的均衡解为:
3 数值分析
在仿真实验中,我们使用MNIST数据集和广泛使用的软件環境TensorFlow来执行数字分类任务,来评估上文构建的激励方案。在联邦学习任务中,我们设置10个任务发布者和100个数据拥有者,其中数据拥有者按照数据质量名义值不同均分为十种,并且所提供的数据质量好坏存在不确定性。为了真实反映数据拥有者在本地训练模型时的异质性,我们通过重复训练次数来对参与的数据拥有者进行随机选择。我们规定单个数据拥有者的最大CPU功率fmax为15,规定任务发布者提供的最大CPU频率单位价格qmax为100。表1中给出了仿真实验中的其他参数。
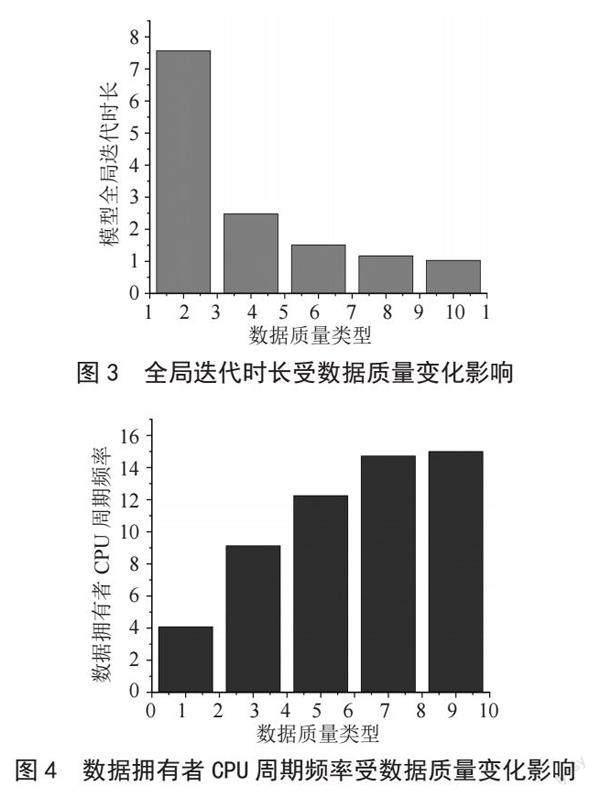
在本文中,上层博弈的效用为最小化全局迭代时长,我们将100个按照数据质量分类的数据拥有者参与模型训练,通过求解其迭代时长均值来分析数据拥有者不同数据质量对任务发布者效用的影响。如图1所示,上下层博弈达到均衡最优解时,随着数据质量的提高,数据拥有者提供的CPU频率在不断提高,并且任务发布者的模型全局迭代时长不断降低,并且降低速度不断变缓,任务发布者的模型全局迭代时长变化呈现拟凹性。造成这种现象的原因主要是由于随着数据拥有者数据质量的提升,数据拥有者自身为达到相同的模型精度的耗能降低,并且为了能够使自身获得更高的报酬,提高自身的CPU频率,因此图3、图4中,随着数据质量的提升,数据拥有者的最优CPU频率在不断提高,但由于数据质量对模型计算时间的影响越来越小,使得数据拥有者提高CPU的幅度也在不断变小。而任务发布者的全局迭代时长也随着数据拥有者的最优CPU频率提高而不断缩短,并且在最优CPU频率变化放缓时,任务发布者的模型全局迭代时长的降幅也在不断变小。因此,在对异步联邦学习中模型训练参与的数据拥有者进行选择时,我们应尽量选择数据质量较好,并且愿意提供将其用作模型训练的数据拥有者,以此来提高模型整体的训练效用,并且提高数据拥有者自身的报酬,降低能耗,从而达到双方的相对最优。
4 结 论
本文提出了一个基于Stackelberg博弈的异步联邦学习激励机制的设计来分析异步联邦学习中任务发布者与不同数据拥有者之间的利益分配问题。我们所做的工作是将Stackelberg博弈引入激勵机制设计,将任务双方的效用关系及相互作用过程能够更好地体现,以此寻求任务发布者与数据拥有者参与双方的相对最优解。具体而言,我们首先根据异步联邦学习的训练模型分别构建了上下层博弈的效用目标及约束,并分别对下层博弈和上层博弈的均衡解进行求解。通过模拟实验证明和分析了不同数据质量的数据拥有者对模型迭代全局时长和自身的最优CPU频率的影响。
本文仅考虑了理想状态下异步联邦学习的激励机制设计,而现实情况中,可能存在数据质量不确定,传输损耗等不确定因素。而这些因素也都会影响激励机制对异步联邦学习的效果,因此考虑存在不确定因素的基于Stackelberg博弈的异步联邦学习激励机制设计将是进一步的研究方向。
参考文献:
[1] ROBERTS M,DRIGGS D,THORPE M,et al. Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans [J].Nature Machine Intelligence,2021,3(3):199-217.
[2] GONG L,LIN H,LI Z,et al. Systematically Landing Machine Learning onto Market-Scale Mobile Malware Detection [C]//EuroSys'20:Proceedings of the Fifteenth European Conference on Computer Systems,2020:1-14.
[3] YANG Q,LIU Y,CHEN T,et al. Federated Machine Learning:Concept and Applications [J].ACM Transactions on Intelligent Systems and Technology,2019,10(2):1-19.
[4] LU Y,HUANG X,DAI Y,et al. Blockchain and Federated Learning for Privacy-Preserved Data Sharing in Industrial IoT [J].IEEE Transactions on Industrial Informatics,2020,16(6):4177-4186.
[5] SATTLER F,WIEDEMANN S,MUELLER K,et al. Robust and Communication-Efficient Federated Learning From Non-i.i.d. Data [J].IEEE Transactions on Neural Networks and Learning Systems,2020,31(9):3400-3413.
[6] WANG S,TUOR T,SALONIDIS T,et al. Adaptive Federated Learning in Resource Constrained Edge Computing Systems [J].IEEE Journal on Selected Areas in Communications,2019,37(6):1205-1221.
作者简介:李炳泽(1996.11—),男,汉族,山西运城人,硕士在读,研究方向:不确定处理与决策。
猜你喜欢
重庆交通大学学报(社会科学版)(2021年4期)2021-03-25
疯狂英语·新阅版(2020年3期)2020-09-22
重庆邮电大学学报(自然科学版)(2018年1期)2018-03-03
数学杂志(2017年3期)2017-06-15
少年文艺·开心阅读作文(2017年1期)2017-02-24
考古与文物(2016年5期)2016-12-21
知识产权(2016年4期)2016-12-01
计算机应用与软件(2016年4期)2016-05-09
小天使·四年级语数英综合(2014年3期)2014-03-21
电信科学(2011年9期)2011-06-27
