
基于模糊Petri网的文献知识元语义集成研究
2024-01-27 09:20汪圳祝婷
现代信息科技 2023年24期
汪圳 祝婷

摘 要:为提升面向用户的精细化知识服务质量及资源利用效率,提出一种基于模糊Petri网的数字图书馆标准化知识元集成方法,充分展示内容之间的语义关系。首先,引入本体与模糊Petri网技术,对数字图书馆文献知识进行获取和重组,从而构建知识元库;其次,将本体应用于知识元的语义链接,使计算机能够“理解”知识元的语义并能自动集成;最后,构建知识元模糊Petri网以规范用户和系统对概念语义的理解,清晰描述知识元概念之间的语义关系,由此消除人与计算机对语义理解的歧义。文献集成案例展示语义知识元的集成策略,案例表明该方法可以有效揭示文献内容之间的语义关联及文献之间的关联程度。
关键词:模糊Petri网;数字图书馆;知识元;本体;知识集成
中图分类号:TP301.1 文献标识码:A 文章编号:2096-4706(2023)24-0072-06
Research on Semantic Integration of Literature Knowledge Units Based on Fuzzy Petri Nets
WANG Zhen1, ZHU Ting2
(1.Chang'an University Library, Xi'an 710064, China; 2.Xi'an Technological University Library, Xi'an 710021, China)
Abstract: To improve the quality of user oriented refined knowledge services and resource utilization efficiency, a standardized Knowledge Units integration method for digital libraries based on fuzzy Petri nets is proposed, fully demonstrating the semantic relationships between contents. Firstly, the ontology and fuzzy Petri net technology are introduced to acquire and reorganize literature knowledge in digital libraries, thereby constructing a knowledge metabase; secondly, applying ontology to semantic linking of Knowledge Units enables computers to “understand” the semantics of Knowledge Units and automatically integrate them; finally, a Knowledge Units fuzzy Petri net is constructed to standardize the understanding of conceptual semantics by users and systems, clearly describing the semantic relationships between Knowledge Units concepts, and thus eliminating ambiguity in semantic understanding between humans and computers. The literature integration case demonstrates the integration strategy of semantic Knowledge Units, and the case demonstrates that this method can effectively reveal the semantic correlation between literature content and the degree of correlation between literatures.
Keywords: fuzzy Petri net; digital library; Knowledge Unit; ontology; knowledge integration
0 引 言
文獻资源是学者们在科研过程中必不可少的参考资源,然而数字图书馆面对海量数据的冲击,检索系统提供的文献结构化的信息格式只能展示文献及其相关属性值,已不能满足科研用户精细化的信息需求。目前文献的组织方式不能充分挖掘文献内容层面的语义关系,导致用户通过关联关系学习理论或衍生新知识的效率不高。知识元集成的目的是将隐性知识进行显性化,实现知识元的有序化,衍生新的知识单元。通过提取文献资源中的知识节点,并建立文献之间知识元的语义链接,从而为研究人员提供高效的知识服务。
模糊Petri网是在Petri网图形表达的基础上增加了模糊数学的推理机制,不仅能清晰描述元素之间的关系,也可以进行知识的推理、分析及决策等,是一种融合Petri网和知识表达的良好建模工具。相关研究主要应用在安全评估、物理系统分析及故障排查等领域,本文将Petri网应用到知识元语义集成领域,实现文献之间有价值节点的语义链接的问题,促进跨领域学科的新知识的衍生学习。
1 相关研究综述
知识元是相对独立且具有完备知识表达的基本单元,通过对知识元的准确标引和有效集成,可以挖掘同一或不同学科之间的隐形和显性的知识关系[1]。知识元标引是实现跨领域知识集成与知识发现的基础。温有奎等首次提出了知识元标引的概念,对文本知识元类型及其标引规则进行了研究[2],在此基础上付蕾设计了一个知识元标引系统,并对该系统进行了设计和实现[3];蒋玲则进一步将以主题词为知识元名称进行标引的标引技术细化到属性信息进行提取,提出了基于规则的知识元标引方法[4]。总结知识元标引方法主要有两类:基于分类的标引和基于主题的标引,前者比如Jiang等研究了基于知识元的中文文本知识标引,提出了知识元标引的步骤[5];后者比如Luo等设计了基于知识元标引的智能资源学习系统,通过智能学习系统,实现自动知识元标引[6]。
知识元集成是将存在逻辑关联的不同的知识元进行链接,从而构成以知识元为基本单位的知识网络[7];温有奎等研究了基于语义知识库的智能推理机的问题答案服务系统[8];曾建勋探讨基于知识元的知识链接的4种主要构建方式[9];姜永常提出了一种基于知识元本体语义链接的知识网络实现流程[10];陈兰杰梳理了知识链接理论与实践的三个时期,并指出以知识元链接为核心的知识服务模式是发展的必然趋势[11];王静等以饮食与疾病领域的知识元为研究对象,对两个领域的知识元之间的语义关系进行了链接,从而实现了知识元的语义推理[12];曾建勋认为知识链接将朝着面向科研环境、个性化推荐链接、基于本体的语义关系链接等方面发展[13]。总结知识元集成主要有两类方法:利用关联数据等建立知识元之间的导航和应用本体技术进行知识元的集成,前者如温有奎等探讨了利用谱分析对知识元进行提取的算法[14],高劲松等利用关联数据的相关技术对抽取的文献知识元之间的语义进行了链接[15];后者比如Wu等设计了一种基于本体的知识元链接的系统[16]。
本文参考的关于模糊Petri网本体建模的相关研究如下:王卓等将本体概念视为各种模型与Petri网模型之间转换的桥梁[17];相东明等根据领域本体为Petri网中的所有库所添加语义标记,使其与已有的语义库建立联系[18];裘杭萍等提出了一种基于Petri网的OWL-S语义匹配机制[19];刘如娟等基于本体理论设计了一种基于时间约束Petri网的Web服务时间模型定义方法,该方法不仅扩展已有的Petri网本体,而且增强其描述能力,使其能够描述服务数据及时间信息,并定义了在OWL-S上定义的时间本体与Petri网时间本体间的关系[20];吴敏敏等提出了一种Petri网和本体的语义Web服务组合方法[21]。
泛在环境下知识元的标引和集成是并发的,需要协同标引手段,模糊Petri网作为动态系统的有效建模工具,在并发服务等方面取得了很多研究成果,但缺少在知识元协同标引和集成过程方面的研究。因此,本文利用模糊Petri网进行数字图书馆文献层面知识元的协同标引,同时将本体应用于知识元的集成过程,使计算机能够“理解”知识元的语义并能自动集成,以解决知识元集成过程中语义的链接,进而揭示文献内容层面的语义关系。
2 基于模糊Petri网的文献知识网络
知识之间存在不同类型和程度的关联关系,但传统的知识描述方式缺乏对知识之间关联类型和程度的表达和描述,不能很好地描述知识之间的关联关系,模糊Petri网可以通过描述临近知识之间的关系,形成知识间的语义链接,进而组成知识网络,使计算机能够“理解”知识间的相互关系并能自动集成。同时,还可以跨越领域、地域等限制,发现隐藏的知识关系,扩大知识应用范围,促进创新也启发用户思维。
2.1 文献知识标准化处理
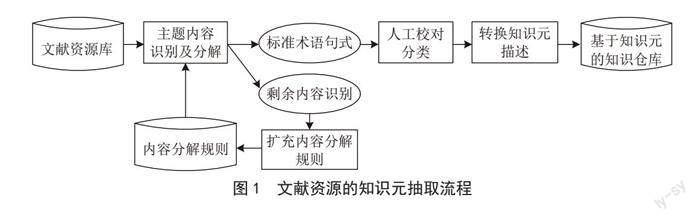
数字图书馆的知识资源数据库来源主要包括学术论文、专著、课题报告等,要实现对这些知识资源的知识元抽取,首先需要制定内容分解规则来识别和分解数据库资源的主题内容,一般分为三步:
1)判断知识资源类型及领域,分解归类到不同的资源库。
2)依据语法结构和内容表现形式,将每条知识中包含的语句分解为简单的主谓宾结构,再进一步转换成“对象—属性”的表现形式。
3)隐藏冗余语句,建立剩余语句之间的知识关系,突出主题内容。
经过处理后的知识被重新组织排列成具有标准术语的句式,然后就可以根据知识元分类,经过人工识别筛选,生成基于知识元的知识库,数字图书馆文献知识元标准收取过程如图1所示。
主题内容识别与分解过程中常常会产生无法识别的内容,一般情况下需要人工进行识别描述,并形成新的内容分解规则,扩充到内容分解规则中。
2.2 文献知识的本体描述
知识元缺乏面向语义的表达和描述,不能很好地支持语义集成,因此可以将本体(Ontology)应用于知识元的语义链接,使计算机能够“理解”知识元的语义并能自动集成。本体早在20世纪60年代就被計算机领域使用,却一直缺少对本体统一的看法,从1993年到1997年,经过Gruber、Borst等人给出本体定义的基础上,Studer等人认为本体是“共享概念模型的明确的形式化规范说明”[22]。这个普遍公认的定义指出本体描述的是专业领域内的概念与概念之间的相互关系,从而构成一个学科领域内部概念的词表以及概念间清晰的层次关系。
本体的目标是规范用户和计算机对概念语义的理解,表达清晰的概念层次和语义关系,建立孤立知识概念间的语义联系,通过推理关系得到概念间蕴含的联系,由此消除人—计算机对语义理解的歧义。
P?erez等人对本体进行诸多研究,提出本体的五元组逻辑结构[23],本文结合此研究,定义知识元本体模型Knowledge=
知识元的初始标识(C)即本体的唯一标识代码,便于存储和提取。
知识元的存在领域(RC)依据《中图法》对本体的类别进行划分,即5大部类、22个大类,它们的标识符和类名如下:A:马克思主义、列宁主义、毛泽东思想;B:哲学;C:社会科学总论;D:政治、法律;E:军事;F:经济;G:文化、科学、教育、体育;H:语言、文字;I:文学;J:艺术;K:历史、地理;N:自然科学总论;O:数理科学和化学;P:天文学、地球科学;Q:生物科学;R:医药、卫生;S:农业科学;T:工业技术;U:交通运输;V:航空、航天;X:环境科学;Z:综合类。
知识元内包含的内容(I)即知识元的定义或模型等具体解释性内容。
知识元与其他知识元间的关系类型(XR)是知识元间比较显性的关系(如part-of:部分与整体的关系、kind-of:继承关系、instance-of:实例和整体的关系、attribute-of:属性关系)的描述。
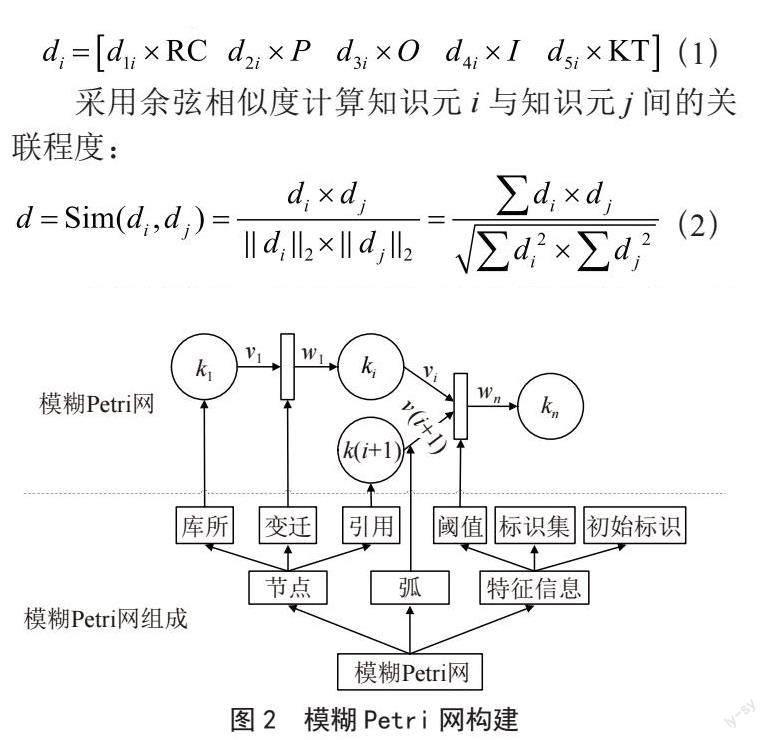
知识元与其他知识元间的关联程度(XRD)不仅可以描述知识元间的紧密程度,还可以進一步体现知识元间的隐性关系(即相同、相似、相关、无关)。关联程度采用五元组进行表示:XRD=(RC,P,O,I,KT);其中,RC为知识元存在领域,P为知识元的语义来源,O为知识元描述对象,I为知识元内容,T为知识元应用情景。假设第j种要素对知识元i的影响程度为dji,则知识元i的向量模型为:
采用余弦相似度计算知识元i与知识元j间的关联程度:
当相似度值d大于某阈值时认为这两种知识元是相同的,介于某两个阈值之间表示两种知识元是相似的,小于模拟阈值且大于0时两种知识元有关系,等于0时知识元是无关的。阈值的选取根据不同情况可采用专家评分的方法确定阈值。
2.3 基于模糊Petri网的知识网构建
Petri网最早由物理学家卡尔· A ·佩特里应用在描述并发现象上。Petri网中不存在“全局时间”概念,描述的是专业领域内的事件与事件之间的相互关系,只要条件成熟,节点所包含的事件就可以发生,从而构成一个学科领域内部知识点间清晰的层次关系。
模糊Petri网是由Petri网与模糊数学相结合,对并行问题进行模糊处理的建模工具,主要要素包括库所节点、变迁节点、连接强度以及负实数变迁启动阈值等。其构建流程如图2所示。
模糊Petri网主要由节点(库所、变迁、引用)、特征信息和弧组成,每条知识有唯一的初始标识,经过加工处理后会被赋予其他更规范的不同标识;节点分为库所节点、变迁节点和引用节点,库所和变迁两节点之间的关系通过弧连接,弧的强度超过特征信息中的阈值时,变迁节点启动;引用节点包括引用库所和引用变迁,是对另外不同网络中知识的引入,可以实现不同模糊Petri网之间的关联,扩大知识链接面。
构建模糊Petri网的目标是规范用户和系统对概念语义的理解,表达清晰的概念层次和语义关系,建立孤立知识概念间的语义联系,由此消除人—计算机对语义理解的歧义。
本文采用大数据统计方法对知识库内知识元之间的关联性进行统计,推理出知识元间的模糊关联规则,构建基于模糊Petri网的知识关联关系,主要分为两步:
1)对每条知识内部的知识元进行梳理,确定知识内部知识元间基于模糊Petri网的关联关系,如图3所示。
知识元k1和k2在条件达到各自变迁节点启动的阈值v1、v2后启动变迁节点,与一个或多个知识元ki产生关联,wi为关联系数;以此类推,经过多个知识元间的规则转换后最终与知识元kn产生关系。当条件不能达到启动阈值时,vi = 0,则有:
当vi ≠ 0时,知识元ki与知识元kn之间存在的关联程度lin = vi×wn;
若vi = 0,lin = lij×…×ljn;
结合式(2),和知识元km有关联的知识元kn与知识元ki的关联程度lin表示为:lin = lim×dmn;
取:
2)以知识内部的每条知识元作为节点,在知识库内寻找与之有关联的知识元及其所在的知识内容,并根据知识元之间的关联关系形成知识间的关联关系,如图4所示。
知识i和知识j内部存在相同的或者可以产生关系的知识元,将之通过关联规则产生联系,最终形成知识i和知识j之间的关联关系。
为了实现不同领域间的知识关联,我们选取知识i中的知识元与知识j中的知识元关联程度最大的值作为知识i与知识j的关联程度值:
可以根据知识之间的关联程度值来发现不同领域有关联的知识内容,从而实现知识的融合。
3 基于模糊Petri网的文献知识元集成实例
本文选取两篇文献作为实例进行知识集成说明,由于篇幅问题,只选取主要步骤的重要部分进行展示。
3.1 知识资源标准化处理
论文依据《中图法》对知识资源的类型及领域进行划分,再根据论文内容提取主要内容及所包含的知识元,如表1所示。
3.2 知识元交互关系及相关知识元整理
确定知识资源《基于用户情境的高校图书馆书目协同过滤推荐研究》中的知识元间的语义交互关系。如图5所示。
并根据式(1)(2)搜索并计算与知识资源《基于用户情境的高校图书馆书目协同过滤推荐研究》中知识元相似的知识元,部分结果如表2所示。
3.3 基于模糊Petri网的知识网构建及关联程度分析
本文主要目的是链接不同学科领域间知识内容的语义,进而扩展需求者思维,随机筛选一篇相关示例文献《贝叶斯更新下基于情景树的动态订货策略研究》,与示例文献进行对比分析。
将处理过后的知识文献按照知识元关联规则用模糊Petri网表示出来,如图6所示。
根据式(3),文献《贝叶斯更新下基于情景树的动态订货策略研究》中知识元与文献《基于用户情境的高校图书馆书目协同过滤推荐研究》中的知识元——书目推荐的关联程度计算结果如表3所示。
对比文献与书目推荐的关联程度l = max{0.367,0.294,0.406,0.337} = 0.406。
根据式(4),文献《贝叶斯更新下基于情景树的动态订货策略研究》与文献《基于用户情境的高校图书馆书目协同过滤推荐研究》的相关程度L = max{l1,8,l1,9,l3,7} = max{0.906,0.752,0.910} = 0.910。,即两篇文献存在一定的关联性。
两篇文献中,都需要通过用户需求来推理情境,所需要的理论方法有一定的相似性;同时,贝叶斯定理在两篇文献中都有应用,知识需求者可以根据这种关联关系学习理论或衍生跨领域的新知识。
4 结 论
通过模糊Petri网模型将文献资源在知识元层面进行了语义关联,可以为用户提供文献内容层面知識的产生和发展脉络,通过建立知识元之间的语义关联,清晰了解独立知识元的发展轨迹和现状,为用户提供文献内容全景式的知识网体系;知识元语义集成过程,消除了学科领域界限,可视化展示跨领域的知识内容层面的语义联系及文献之间的关联程度,为跨学科演进新知识提供理论层面的推理机制。
参考文献:
[1] 温有奎,焦玉英.基于知识元的知识发现 [M].西安:西安电子科技大学出版社,2011:12-14.
[2] 温有奎,温浩,徐端颐,等.基于知识元语义网格平台的知识发现研究 [J].计算机工程与应用,2006(4):4-6+34.
[3] 付蕾.知识元标引系统的设计与实现 [D].武汉:华中师范大学,2009.
[4] 蒋玲.面向学科的知识元标引关键技术研究 [D].武汉:华中师范大学,2011.
[5] JIANG L,YANG Z K,WANG J X. Knowledge Indexing of Chinese Text Based Knowledge Element [C]//2008 International Symposium on Knowledge Acquisition and Modeling.Wuhan:IEEE,2008:35-38.
[6] LUO L M,YANG L Q. Design of the Intelligent Learning Resources Learning System Based on the“Knowledge Points”Indexing [C]//2013 Fourth International Conference on Intelligent Systems Design and Engineering Applications.Zhangjiajie:IEEE,2013:264-267.
[7] 司莉,李月婷.我国三大全文数据库知识链接方式比较分析 [J].图书馆建设,2013(4):33-35+40.
[8] 温有奎,温浩,乔晓东.让知识产生智慧——基于人工智能的文本挖掘与问答技术研究 [J].情报学报,2019,38(7):722-730.
[9] 曾建勋.知识链接的构建方式研究 [J].图书情报工作,2010,54(12):32-35+77.
[10] 姜永常.基于知识元语义链接的知识网络构建 [J].情报理论与实践,2011,34(5):50-53+45.
[11] 陈兰杰.知识链接理论与实践的三次嬗变探究 [J].图书情报工作,2010,54(12):46-49+63.
[12] 王静,刘成山,秦春秀.一种基于模糊Petri网的知识元语义集成方法 [J].情报理论与实践,2017,40(9):140-144.
[13] 曾建勋.知识链接的研究现状与发展趋势 [J].情报理论与实践,2011,34(2):119-123.
[14] 温有奎,焦玉英.知识元语义链接模型研究 [J].图书情报工作,2010,54(12):27-31.
[15] 高劲松,马倩倩,周习曼,等.文献知识元语义链接的图式存储研究 [J].情报科学,2015,33(1):126-131.
[16] WU D,LI X J,ZHANG C W. The design of ontology-based semantic label and classification system of knowledge elements [C]//2011 International Conference on Uncertainty Reasoning and Knowledge Engineering.Bali:IEEE,2011:95-98.
[17] 王卓,冯晓宁,徐玉如.基于本体的Petri网模型转换方法 [J].计算机科学,2009,36(6):147-149+166.
[18] 相东明,马炳先,张正明.基于语义的Petri网自动共享合成方法研究 [J].系统仿真学报,2012,24(11):2237-2242.
[19] 裘杭萍,胡汭,罗晨.基于Petri网的OWL-S语义匹配机制研究 [J].计算机科学,2012,39(10):174-176+213.
[20] 刘如娟,陈俊杰,王立军,等.一种基于Ontology的WEB服务时间约束定义及验证方法 [J].四川大学学报:工程科学版,2009,41(6):158-164.
[21] 吴敏敏.基于Petri网的语义Web服务组合方法 [J].南阳理工学院学报,2016,8(4):29-34.
[22] 陆建江,张亚飞,苗壮,等.语义网原理与技术 [M].北京:科学出版社,2008.
[23] P?EREZ A G,BENJAMINS V R. Overview of Knowledge Sharing and Reuse Components: Ontologies and Problem-Solving Methods [EB/OL].[2023-04-06].http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-18/.
作者简介:汪圳(1992—),男,汉族,山东临清人,
馆员,硕士,研究方向:数字图书馆技术及应用;祝婷(1990—),女,汉族,陕西咸阳人,助理馆员,硕士,研究方向:个性化推荐。
收稿日期:2023-05-06
基金项目:2023年度长安大学中央高校基本科研业务费专项资金资助项目(300102503601);陕西省科学技术情报学会项目(2022KTF-06)
猜你喜欢
哲学分析(2023年4期)2023-12-21
中国音乐学(2020年4期)2020-12-25
制造业自动化(2017年2期)2017-03-20
医学信息(2016年29期)2016-11-28
资治文摘(2016年7期)2016-11-23
电脑知识与技术(2016年24期)2016-11-14
企业导报(2016年12期)2016-06-17
文学教育(2016年27期)2016-02-28
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
