
基于用户反馈和对话历史的对话式推荐技术研究
2024-01-29 00:31杨畅姚越方霖枫周仁杰
软件工程 2024年1期
关键词:推荐系统
杨畅 姚越 方霖枫 周仁杰

关键词:推荐系统;对话式推荐;强化学习;图表示学习
0 引言(Introduction)
随着互联网技术的迅猛发展,人们逐渐从信息匮乏的时代走入了信息过载的时代,因此如何应对信息过载问题成为一个迫切需要解决的问题。推荐系统的出现有效地缓解了这一问题。然而,传统的推荐方法在处理新用户冷启动和充分利用用户反馈问题时仍面临挑战。相较之下,对话式推荐系统(Conversational Recommender System, CRS)通过与用户直接交互收集“显式反馈”,从而实现更精确的推荐。鉴于对话式推荐系统在电商和社交媒体中具有巨大的应用潜力,其已成为业界和学术界关注的焦点。本文提出一种新方法,可以解决对话推荐中的准确状态建模和高效策略制定问题。该方法整合了用户负反馈图以优化状态表示,并采用动态奖励函数更有效地指导策略学习。此外,通过在智能体中加入历史对话状态的序列模型编码,进一步增强了模型的推荐性能。
1 相关工作(Related works)
1.1 传统推荐系统
传统的推荐系统通常依赖用户与项目的交互矩阵,并用机器学习方法挖掘其中的隐含关系。例如,协同过滤通过矩阵分解等手段将用户与项目之间的交互映射到低维空间,进而提取特征、找寻相似用户,并推荐用户喜好的项目[1]。SALAKHUTDINOV等[2]引入深度学习架构,使深度学习在推荐系统领域得到广泛应用。HIDASI等[3]用循环神经网络[4](Recurrent NeuralNetwork, RNN)对用户的交互序列进行建模,预测下一个点击的项目。HE等[5]则使用生成对抗网络,分别在生成和判别模型中进行数据捕获和预测。WANG等[6]融合了协同过滤和图表示学习,开发了一个神经图协同过滤框架,通过传播用户偏好的项目特征提升推荐结果的准确性。
然而,以上方法各有一定的局限性,尤其体现在解决新用户冷启动和充分利用用户在线反馈问题方面。相较之下,对话推荐系统通过与用户直接对话并询问问题以了解用户需求[7]。这种对话式推荐在多个环境下已受到研究者的广泛关注。
1.2 基于属性的对话式推荐系统
近年来,学者们在基于属性的对话式推荐技术方面有多项探索。最初,CRM(Conversational Recommender Model)[8]提出了单轮对话推荐方法,不论推荐结果是否被接受,对话都将在一轮推荐后结束。该方法用基于长短期记忆网络[9](LongShort-term Memory,LSTM)的编码模块编码用户输入的属性-值对,并用二路因子分解机[10]预测用户对每个项目的评分。后续研究将CRM扩展到多轮交互,根据先前反馈优化后续推荐,实现了更精确的推荐。
LEI等[11]提出了一个多轮对话推荐框架,包含评估(Estimation)、动作(Action)和反应(Reflection)三个模块。评估模块采用因子分解机和贝叶斯个性化排序算法,动作模块基于强化学习选取最优策略,反应模块则根据用户反馈更新损失函数[12]。CPR(Conversational Path Reasoning)[13]使用图模型捕捉候选属性和项目间的关系,通过多轮对话和用户互动,不断修剪候选产品和属性,从而提高推荐性能。DENG等[14]综合先前研究,将推荐、询问和决策任务统一在一个强化学习框架中,用基于图的马尔可夫决策过程(Markov DecisionProcess, MDP)和图卷积神经网络[15](Graph ConvolutionNetwork, GCN)、Transformer[16]学习对话状态,再用深度Q网络[17](Deep Q-Network, DQN)进行价值学习。
2 模型构建(Model building)
2.1 融合负反馈的对话状态建模
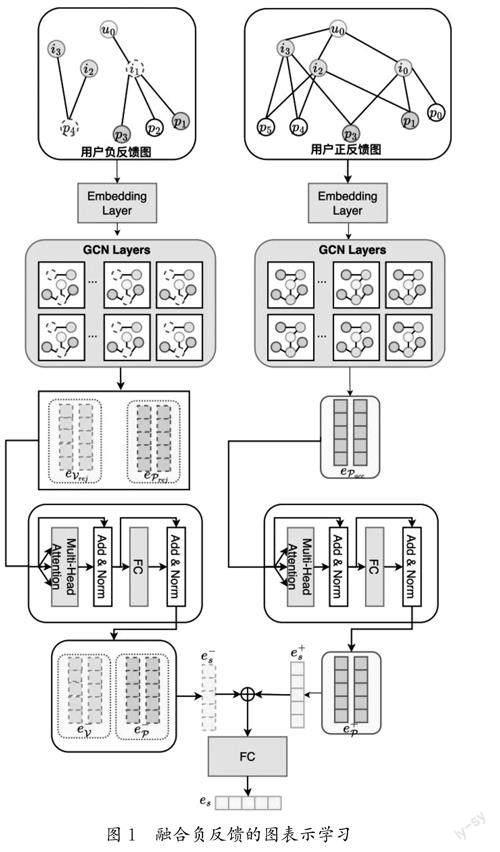
本文通过将用户、商品、商品信息等嵌入基于图的MDP环境中对用户当前的对话状态进行建模。在用户与智能体交互的过程中,不断裁剪环境中的结点,每一步交互都将得到表示用户正反馈和负反馈信息的动态图。图卷积神经网络是一种聚合节点周围信息的有效模型,能捕获到节点的高阶连通性[18]。因此,本文模型在每一步交互结束后,使用图卷积神经网络分别对用户的正反馈图和反馈图进行图卷积,提取图中结点的结构特征,得到每个结点的表示向量。通过注意力机制对上一步中的正、负反馈结点的表示向量进行增强,以此将网络的关注点聚焦于关键的结点上。通过一个全连接层将经过聚合的结点表示编码成最终的对话状态表示向量。融合负反馈的图表示学习如图1所示。
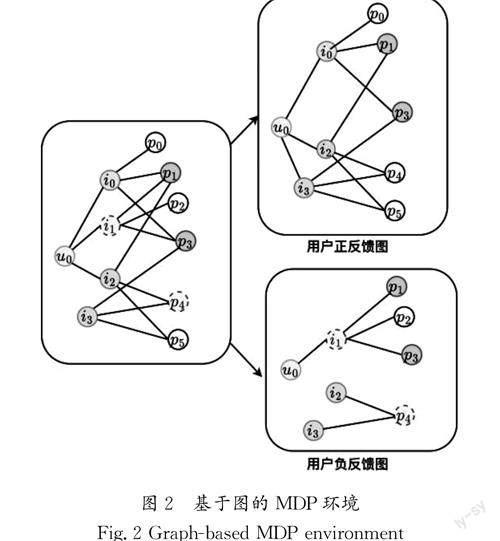
2.1.1 基于图的MDP环境
本文中将基于图的MDP环境定义为由状态空间S、动作空间A、状态转移函数T:S×A→S 和奖励函数R:S×A→ℝ构成的四元组(S,A,T,R)。其中,状态包含了给定用户u 的情况下,时刻t 的对话历史H (t) u = P(t)acc,P(t)rej,V(t)rej 和该时刻下与用户相关的正反馈图、负反馈图G(t) u = G+(t) u ,G-(t) u 。例如,在基于图的MDP环境下(图2),用户u0 的目标项目是i0 且在时刻t已经接受了属性p1 和p3,拒绝了项目i1 和属性p4,则对话历史可以表示为H (t) u0= {p1,p3}, p4 , i1 。
动作空间A= V(t)cand,P(t)cand ,分别代表候选项目和候选属性。其中,候选项目定义为V(t)cand=VP(t)acc\V(t)rej,VP(t)acc代表所有与P(t)acc 中属性直接相连的项目。候選属性定义为P(t)cand=PV(t)cand\P(t)acc ∪P(t)rej ,即候选项目包含的所有属性减去已经交互过的属性。
用户反馈图表示为由结点和邻接矩阵构成的二元组G=(N ,A)。对于正反馈图G+(t) u ,结点集合N +(t)={u}∪P(t)acc∪P(t)cand∪V(t)cand,邻接矩阵则定义为公式(1),用户和候选项目之间的边权重定义如公式(2)所示。
状态转移函数T:S×A→S 根据t 时刻的状态st 和智能体在动作空间A 中选择的动作at 给出下一个状态st+1。动作空间中的动作有两类,分别为询问属性p 和推荐项目i。如果用户在t时刻接受了询问的属性pt,则P(t+1)acc =P(t)acc∪pt,否则P(t+1)rej =P(t)rej∪pt;如果用户拒绝了推荐的项目it,则V(t+1)rej =V(t)rej∪it,否则推荐成功,本轮推荐结束。
2.1.2 动态奖励函数
奖励函数R:S×A→ℝ给出在当前状态st 下执行动作at的奖励rt。本文采用根据环境变化而变化的动态奖励函数,首先按照表1根据当前对话的轮次缩放基础奖励,然后按照公式(4)根据候选项目空间中的项目数量的缩减比例计算最终的奖励。
2.1.3 融合负反馈的图表示学习
由于本文将对话式推荐建模为基于图的MDP环境下的统一策略学习问题,因此需要将对话和图的结构信息编码为状态向量表示。本文采用Trans-E[19]进行预训练,确保异构图中的节点表示具备结构化特征。然后使用GCN对环境中的正、负反馈图进行图卷积以捕捉表示当前对话状态的图中的高阶结构信息。对于第l 层图卷积,计算方法如公式(5)至公式(7)所示,其中Ni 是第i 个节点ni 的邻接节点,Wl 和Bl 是训练的参数。
经过GCN编码后,可以得到结合了高阶结构信息的结点表示,接着,将图上所有结点的表示向量视作序列,利用Transformer Encoder来进一步增强结点的表示,从而让网络更加聚焦在重要的结点上,如公式(8)至公式(9)所示;最后,对编码的结果做平均聚合,如公式(10)所示。
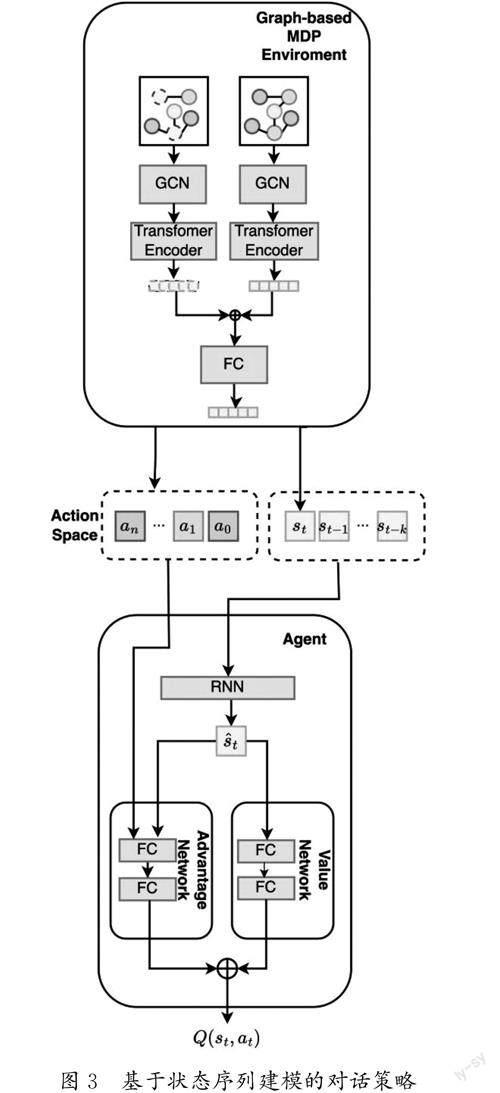
2.2 基于状态序列建模的对话策略
对话策略的学习是使用时间差分(Temporal Difference,TD)算法[20]优化DQN进行的,随着环境给出当前状态和动作空间,基于DQN的智能体给出动作空间中各个动作的价值,并选出最大价值的动作执行,基于状态序列建模的对话策略如图3 所示。
2.2.1 状态序列建模
记本次对话的状态向量序列为St= st-k,st-k+1,…,st ,其中每一个状态向量都携带了特定轮次对话的细节信息。本文利用RNN将状态向量序列进行编码,以提取每一次对话轮次间的状态变化特征。这样的设计旨在捕获对话动态变化的本质特征,以改善推荐准确性和效率。本文采用门控循环单元[21](Gated Recurrent Unit, GRU)的原因是它对长序列数据有优异的记忆和学习能力,尤其在处理具有复杂时序依赖的任务时的表现更加优异。门控循环单元结构简单、计算高效且能解决长时序依赖问题,这些优点使它成为此类任务的理想选择。在实现细节上,状态向量通过GRU层进行处理,每一个状态都被更新并与前一个状态相关联。公式(12)表示状态向量序列通过GRU进行编码后的输出,记为^st。
2.2.2 价值学习
最优动作价值函数Q* (st,at)为采取最优策略π* 能得到的最大折扣期望汇报,根据Bellman方程,最优动作价值函数定义为公式(13),其中γ 为折扣因子。
本文采用Dueling Q-Network[22]的设定,将价值网络实现为状态价值网络和动作优势网络两个独立的神经网络,如公式(14)所示。其中:fθV (st)是状态价值網络,θV 是网络的参数,fθA (st,at)是动作优势网络,θA 是网络的参数,θS 是图表示学习的参数。
在每轮对话中,智能体都能从基于图的MDP 环境中得到当前时刻t的状态的表示向量st=es 和动作空间At,接着通过状态序列建模将本次对话中的每轮对话状态向量进行编码,并得到包含状态变化特征的状态表示向量^st。智能体利用动作价值函数Q(st,at)估计动作空间A 中的各个动作的价值,并使用ε-greedy策略从动作空间中选出要执行的动作at。环境则根据智能体选择的动作给出动作at 的奖励rt,然后转移到下一个状态st+1 并更新动作空间At+1。
记六元组(st,at,rt,st+1,At+1,St-1)为一条经验,为了提高价值网络的学习效率,将每次对话得到的经验存放在重放记忆(Replay Memory)D 中,每次采样一个小批量用于更新网络参数。如公式(15)至公式(16)所示,本文通过最小化均方差损失的方式优化价值网络,其中yt 是TD 误差。
3 实验(Experiment)
3.1 数据集
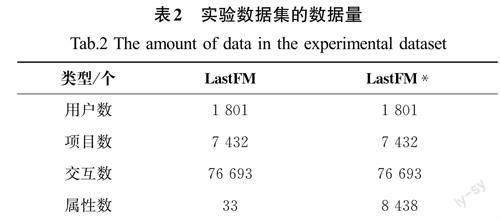
实验数据集采用LastFM数据集和LastFM*数据集。其中,LastFM数据集是由Last.fm发布的音乐推荐数据集,包含来自1 801位用户的听歌记录。为了便于建模,LEI等[11]将LastFM的原始属性人工手动合并成33个粗粒度属性组。同时,LEI等[13]认为手动合并属性在实际应用中并非最佳实践,因此他们在LastFM 数据集的基础上使用原始的属性重构出LastFM*数据集。LastFM数据集和LastFM*数据集的数据量见表2。
3.2 实现细节
本文将最大对话轮次数T 设为15轮,将推荐列表的大小K 设为10,并将每个数据集分割为7∶1.5∶1.5用于训练、验证和测试。本文使用OpenKE[23]中实现的Trans-E算法,在基于训练集构建的图上进行节点表示的预训练。对于实验中所有的基线方法,本文都使用用户模拟器[11]进行了10 000轮对话的在线训练。超参数的设置如下:嵌入大小和图表示学习的输出层大小分别设置为64和100;GCN层数Lg ,Transformer层数LT 和GRU的层数Ls 分别设置为2、1和2;选中的候选属性Kp 和项目Kv 的数量都设置为10;在DQN的训练过程中,经验回放缓冲区的大小为50 000,从经验回放缓冲区中每次采样的小批量的大小为128;学习率和L2范数正则化系数分别设置为10-4 和10-6,使用Adam 优化器;折扣因子γ 和更新频率τ 分别设为0.999和0.01。
3.3 实验结果与分析
3.3.1 对比实验
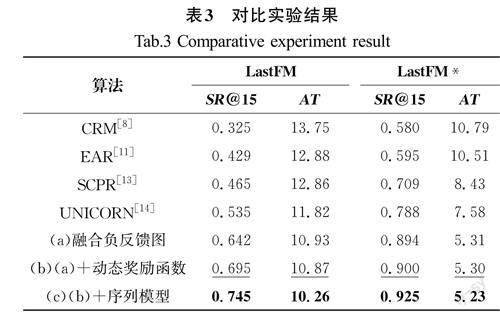
为了验证本文所提出模型的有效性,比较了本文提出的模型与四个基线模型在15轮推荐准确率(SR@15)和平均推荐成功轮数(AT)指标上的性能表现,实验结果如表3所示。本文分别实现了三个不同版本的推荐模型,如表3中的(a)将用户负反馈信息分别建模为正反馈图和负反馈图;(b)在(a)的基础上实现了动态奖励函数;(c)又在(b)的基础上在智能体中使用GRU对历史对话状态序列进行编码。表3中的结果表明,本文提出的模型(c)在两个数据集上均取得了最佳结果,相较于次优模型分别在推荐成功率指标上提升了21%和13.7%,在平均推荐轮次数指标上降低了1.56轮和2.35轮。
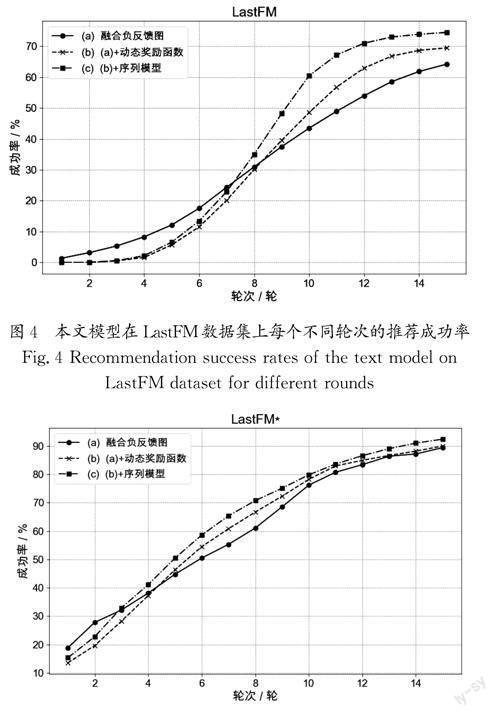
3.3.2 不同轮次内的推荐成功率
图4和图5展示了在LastFM 和LastFM*上,本文模型在每个对话轮次t下的推荐成功率(SR@t)。虽然动态奖励函数在推荐初期可能降低成功率,但是它能提升模型的长期推荐效果。这是因为,在初期,询问属性有助于了解用户偏好,进而缩小推荐范围。短期内这可能会降低成功率,但从长远看,能更精确地满足用户需求,提高推荐成功率。模型在不同数据集上使用了不同推荐策略。例如,在属性丰富的LastFM*上,模型更倾向于早期推荐,而在属性较少的LastFM 数据集上则较为保守,前几轮几乎没有推荐。引入GRU对历史对话进行编码进一步提高了推荐效果,说明历史对话对于了解用户需求和偏好很重要,GRU 能有效捕获这些信息,为模型提供准确的上、下文。
4 结论(Conclusion
本文通过深入探究对话式推荐系统中用户负反馈及对话历史信息的有效性,成功构建了一个全新的对话式推荐模型。負反馈图不仅为系统提供了更全面的用户偏好画像,动态奖励函数也成功地缓解了奖励稀疏的问题,促使系统能更好地从用户反馈中学习。此外,序列模型的引入进一步优化了推荐效果,证明了对话历史信息在揭示用户深层次需求和偏好中的关键作用。在实验中,该模型被应用于LastFM 和LastFM*两个数据集,与最优的基线模型相比推荐成功率分别提升21%和13.7%,平均推荐轮次数也分别降低了1.56轮和2.35轮。尽管本文提出的模型考虑了用户负反馈和对话历史信息,但如何有效地处理用户历史反馈的漂移和变化,并在不断学习的过程中保持推荐系统的稳定性,是一个值得未来深入研究的方向。
猜你喜欢
软件(2016年4期)2017-01-20
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年25期)2016-11-16
商(2016年29期)2016-10-29
电脑知识与技术(2016年16期)2016-07-22
商(2016年15期)2016-06-17
电脑知识与技术(2016年3期)2016-04-07
中国市场(2016年2期)2016-01-16
