
基于YOLOv7的人体关联实时吸烟目标检测方法
2024-01-29 00:31孙冰李好黄鑫凯任长宁邹启杰
软件工程 2024年1期
关键词:目标检测
孙冰 李好 黄鑫凯 任长宁 邹启杰



关键词:吸烟检测;目标关联;YOLOv7;目标检测
0 引言(Introduction)
多数作业环境明令禁止吸烟,诸如物流仓储、化工工厂、供电单位等,虽然可以通过中央监控系统实时监控各种作业场景,但是主要依赖人工监查,存在漏报情况,不但不能节省人力成本,而且会对企业和工作人员的生命财产安全造成威胁。随着计算机视觉技术的发展,目标检测技术日渐成熟,智能检测得到广泛的研究和应用,由此本文提出一项基于YOLOv7[1]的人体关联实时吸烟目标检测方法。
当下不乏实时吸烟行为检测的相关研究,但是对于实际应用仍有可提升、待完善的地方,具体如下:第一,对于复杂场景小目标(烟)的检测精度尚有提升空间[2-3];第二,仅对香烟进行检测,对香烟相似物存在漏检误报的情况[4-5];第三,部分研究虽然通过增加姿态检测、特征检测、面部检测等方式进行优化,但是复杂的算法导致模型检测速度降低[3,6]。基于以上问题,本文提出改进方法。首先,通过数据增强提升算法小目标检测能力,从而提高香烟检测的准确率,并解决过拟合问题;其次,基于当前比较先进的YOLOv7算法同时检测人和烟,通过设置人和烟的目标关联阈值,增加检测条件的限制,降低误检率;最后,经过对比实验和消融实验验证方法的有效性和检测方法性能的提升程度,并用工作现场视频进行算法的验证。
1 目标检测(Object detection)
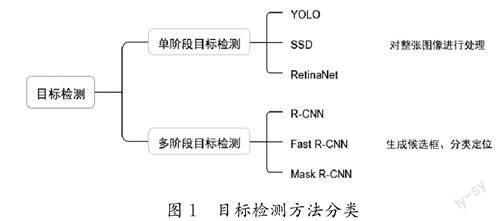
现有典型的目标检测方法可以分为单阶段目标检测(YOLO、SSD、RetinaNet等)和多阶段目标检测(R-CNN、FastR-CNN、Mask R-CNN等)(图1)[7-8]。
1.1 多阶段目标检测算法
多阶段目标检测算法通常包含两个阶段,即生成候选框和分类定位。在第一个阶段,算法使用候选框生成器生成多个候选框,每个候选框都与某个物体相对应。在第二阶段,候选框中的特征图将被送入一个分类器和回归器中,以进一步提取物体的位置和类别信息。常见的多阶段目标检测算法有R-CNN及其变种Fast R-CNN和Mask R-CNN等[8]。多阶段目标检测算法通过使用候选框定位和识别物体,具有更高的准确率和定位精度。但是,与单阶段目标检测算法相比,多阶段目标检测的计算复杂度更高,计算速度较慢,不适用于对实时检测要求高的作业环境。
1.2 单阶段目标检测算法
单阶段目标检测算法通过处理整张图像预测物体的位置和类别。这种算法速度较快,适合实时应用场景。常见的单阶段目标检测算法有(Single Shot MultiBox Detector,SSD)、RetinaNet、YOLO等[3]。这些算法通常将物体位置和类别信息结合起来作为网络输出,使用较少的候选框定位物体。SSD是以单个CNN为基础的目标检测算法,可以同时检测不同大小和比例的物体。RetinaNet将分类和回归任务分别交给两个并行的子网络来解决分类精度和定位精度不平衡的问题,同时引入损失函数来调整难易样本的权重,故此能够获得更好的目标检测性能。
YOLO是端到端的单阶段目标检测算法,具有快速和高准确率的特点。YOLO将输入图像划分成网格,并对各个网格进行分类、定位,生成每个物体的边界锚框和概率。YOLO采用卷积神经网络处理整个图像,以便于实时应用。2020年发布的YOLOv5具有更小的模型体积和更快的推理速度,同时在目标检测精度方面也有一定的提升。2022年发表的YOLOv7算法集成以往YOLO系列的优点,并不断推陈出新,尽管在准确率和运算速度上较以往YOLO系列都有所提升,但存在对小目标检测精度不够的问题。在本实验测试中发现,YOLOv7比以往YOLO系列更容易出现过拟合现象。相比多阶段目标检测算法,单阶段目标检测算法的处理速度更快、计算复杂度更低,适合实时应用场景。但是,单阶段目标检测算法在一些复杂场景下的准确率可能不如多阶段目标检测算法,因此本文在YOLOv7算法的基础上做了一些调整,以适应极小目标(香烟)的检测。
2 基于YOLOv7的吸烟检测方法(A smokingdetection method based on YOLOv7)
2.1 YOLOv7模型
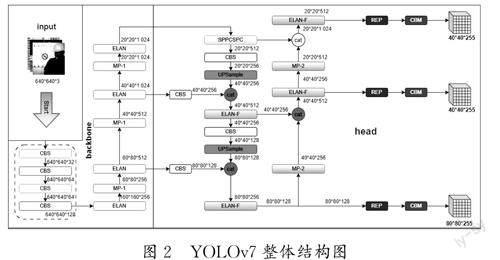
YOLOv7算法主要由输入端(Input)、主干網络(Backbone)和头部网络(Head)构成,采用扩展高效长程注意力网络(EELAN)、基于级联模型的模型缩放、卷积重参数化等策略,在检测效率与精度之间取得了非常好的平衡[9-10]。输入端由数据增强、自适应锚框计算和自适应图片放缩构成,将输入图像缩放至固定的尺寸,实现数据增强。主干网络主要由多个CBS、ELAN、MPConv等模块组成,用于图像特征的提取[11]。预测端用于预测,采用聚合特征金字塔网络结构,将底层信息通过自底向上的路径传递到高层,实现差别层次特征的融合,借助REPcon结构对不同尺度的特性进行通道数调整。
如图2所示,YOLOv7首先对输入的图片进行预处理,处理为640×640像素大小的RGB图片,其次输入主干网络,通过主干网络的三层高效长程注意力网络进行输出,并继续在头部网络层输出三个不同大小的特征图,经过重参数化和卷积进行图像分类、图像前后背景分类以及边框预测,输出最后的结果。
2.2 数据集增强
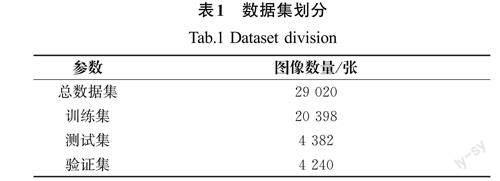
本实验通过互联网收集了来自安防场景、公共场所、危险场所等现实场景的共计3 628张吸烟行为的图像,并通过旋转方式进行数据集增强,将抽烟行为数据集扩充到14 512张,结合14 508张人体数据集,共计29 020张图像,并按70%、15%和15%的占比分成训练集、测试集和验证集,数据集划分见表1。
对数据集进行如图3所示的标签标注,采用线上标注工具makesense进行目标标注,分别标记为“person”“smoke”,获得以文本文件形式存储的标注结果。
2.3 目标关联
吸烟行为的出现一般需要同时具备两个基本条件———人和烟,故本研究通过YOLOv7模型同时定位人和烟,并进行目标关联,在算法中计算人和烟的中心点距离,当二者距离小于设定阈值后,发出吸烟告警,实现吸烟检测。
场地人员检测锚框(x2p -x1p )×(y2p -y1p ) <50 000时,人的坐标(xp ,yp )如下:
3 实验与分析(Experiment and analysis)
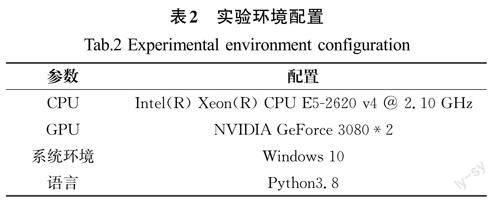
3.1 实验环境
实验环境使用Windows 10操作系统、NVIDIA GeForceRTX 3080显卡进行运算。具体实验配置见表2。网络模型训练阶段,训练迭代次数设置为150次,Batch size 设置为8,Imgsize 设置为[640,640],设置好限定条件后进行训练。
3.2 性能分析
3.2.1 分析指标
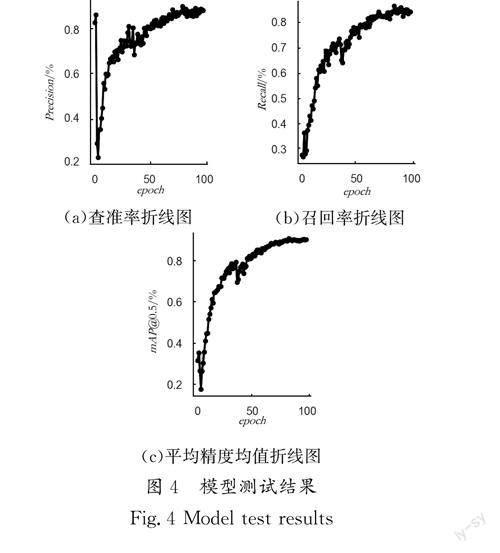
本实验将查准率(Precision)、召回率(Recall)、平均精度均值(mAP)作为评价指标,生成了三者随迭代次数变化的折线图,并生成Precision-recall曲线图像作为分析评价的辅助参考。
精确率也称查准率,该指标用来判断模型检测是否准确,是在识别出的物体中正确的正向预测所占的比率。在公式(3)中,TP 表示真的正样本,FP 表示假的正样本。
召回率也称查全率,是指正确识别出的物体占总物体数的比率,该指标用来判断模型检测是否全面,在公式(4)中,FN表示假的负样本。
AP 代表Precision-recall 曲线下方面积,分类器越好,AP值越高。如公式(5)所示,目标检测算法中最重要的指标之一mAP 代表多个类别AP 的平均值,大小处于[0,1]内,越接近1,表明该目标检测模型在给定的数据集上的检测效果越好。
3.2.2 結果分析
将实验数据进行可视化处理,绘制查准率、召回率和平均精度均值的折线图,如图4(a)、图4(b)所示,查准率和召回率均达到90%且图4(c)中的平均精度均值达到90%以上,说明模型在检测精度上表现出色。
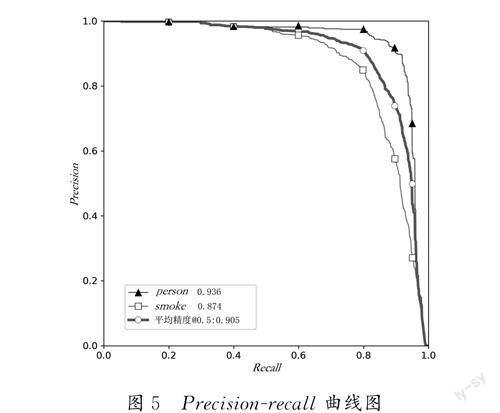
通过不断改变识别阈值,使得系统能够依次识别前N 张图片,阈值变化的同时会导致Recall 与Precision 值的变化,从而得到Precision-recall 曲线[12]。如图5所示,本模型测试所得曲线下方的面积较大,并且在Recall 值增长的同时,Precision 的值能保持在一个很高的水平,在Precision 和Recall 之间实现了较好的平衡[12]。
为了验证本模型性能,将原YOLOv7作为基线模型,通过对YOLOv7模型定位内容的修改比对进行如表3所示的消融实验,分别取实验中最优的模型在制作好的测试集进行验证。在基于YOLOv7分别进行仅定位香烟和人体关联检测两种方法中,虽然人体关联的方法牺牲了一定的训练时长,但是将误检率降低到了0.001%,较仅定位香烟的方法有6%的性能提升,基本解决了香烟检测的误判问题。
3.2.3 性能对比
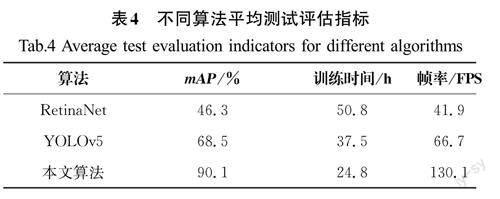
为了证明本文方法对比于其他方法在检测准确率、模型精简度和检测速度上具有一定优势,选取RetinaNet和YOLOv5两种算法在同一数据集上进行测试,以mAP、训练时间和帧率作为评价指标进行3种算法的性能对比判断。
由表4可知,与其他两种算法相比,本文所提方法的mAP值较RetinaNet算法提升了94.6%,较YOLOv5算法提升了31.5%,训练时间较RetinaNet算法和YOLOv5算法分别缩短了51.2%、33.9%,帧率分别提高了210.5%、95.1%,性能提升效果显著。
综合对比实验结果,基于YOLOv7的人体关联实时吸烟目标检测方法较RetinaNet和YOLOv5算法大大提升了吸烟行为的检测准确率,降低了训练时间,提高了检测帧率。
3.3 检测结果可视化
使用现场拍摄的安防场景吸烟行为和人员作业行为的视频做测试,在低像素、远距离的情况下,图6(a)中安防器械场地准确定位了场地作业人员。图6(b)中安防办公场地准确定位了人和烟,判断满足距离关系后,以人和烟中心为对角线框出吸烟行为,实现抽烟行为的准确定位,并对吸烟行为发出告警。
分别在不同光线、不同角度、不同像素情况下进行视频检测验证,结果如图7所示,图7(a)有照明高像素正面视角和图7(b)无照明低像素侧面视角都成功定位了人和烟,并判断存在抽烟行为,说明方法具有一定的可靠性和可行性。
4 结论(Conclusion
本文以复杂背景下小目标检测为基础,针对安全要求较高的环境下的吸烟行为检测进行研究,提出了基于YOLOv7的人体关联的实时吸烟目标检测方法。通过同时关联定位香烟和场地内人员,提升吸烟行为检测的准确度。通过以相同数据集为基础进行验证发现,人体关联检测较仅定位香烟检测,虽然在训练时间上有一定的牺牲,但是显著提升了检测准确度。此外在同一数据集验证发现,YOLOv7算法与RetinaNet、YOLOv5算法相比,大大缩短了检测时间,并且检测准确度和帧率都显著提升,说明本方法能够有效提升检测率,降低漏检率,具备实时性和高效性。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
科学与财富(2016年28期)2016-10-14
无线互联科技(2016年7期)2016-05-30
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
