
基于图卷积的云制造服务编码算法
2024-02-06 03:47谭文安
河南科技大学学报(自然科学版) 2024年1期
朱 海,谭文安,2,郭 凯
(1.南京航空航天大学 计算机科学与技术学院,江苏 南京 211106;2.上海第二工业大学 计算机与信息工程学院,上海 201209;3.河南科技大学 管理学院,河南 洛阳 471023;4.河南省有色金属协同创新中心,河南 洛阳 471023)
0 引言
随着云计算技术的发展,很多制造企业开始服务化转型。制造企业将企业的制造资源和制造能力进行虚拟化和服务化,并接入到云制造管理平台,由其进行集中统一的智能化管理和运营[1]。云制造模式根据用户特定需求,将处在不同位置、不同企业的服务进行选择、组合,为用户提供各类按需制造服务。如何在大量功能相似、服务质量相近的云制造服务中检索并选择合适的服务,已成为云制造平台亟待解决的难题[2-3]。
在现实场景中,大量制造业务不仅考虑服务个体性能等指标,更多需要考虑服务间的协同信任关系等社会因素[4]。良好的协同与合作信任关系有助于在企业间建立稳定的业务合作、提高生产投入、促进制造能力提升[5]。云制造过程中服务组合、协同关系、服务质量之间的相互作用,有效提高了服务质量和创新能力。因此,任务间协同能力也必须是服务选择的重要指标[6]。
在云制造等大数据场景下,对海量数据进行准确、快速检索时,基于哈希的检索方法被越来越多的学者所关注[7]。哈希检索方法也逐渐变成比较流行的目标检索方法之一。为了提高监督方法的性能,文献[8]提出了一种基于内核的监督哈希模型,使用核函数解决了线性不可分问题,极大提升了目标检索准确率[8]。为了加快哈希算法的运行速度,提高数据处理规模,文献[9]提出了一种新的基于学习的快速监督哈希离散算法,通过一个单一哈希码求解步骤,提高了算法的效率。考虑到实现图像类别标签信息完全获取的困难性,为了降低数据标记带来的高昂成本,半监督哈希方法仅使用部分标签信息对模型进行训练[10-11]。通过对多视图哈希模型的研究,文献[12]选择将部分标签信息融入模型训练过程,提出了一种半监督多视图哈希模型[12]。无监督哈希方法避免了对样本标注标签的行为,利用发现数据内在联系的方法保持数据原有的结构特征,以达到训练哈希函数的目的[13]。与有监督方法一样,无监督方法也经常用于执行图像检索任务[14]。文献[15]以无监督的方式学习二进制哈希码,设计了一种高效的生成对抗框架,实验表明其与有监督的哈希方法的性能不相上下。为提高相似性搜索的效率,文献[16]通过使用伪标签将无监督的深度哈希转换为有监督模型,从而构建了一种无监督框架,并通过实验验证了该模型在性能上的有效性[16]。
云制造服务进行协同制造时,协同关系对服务选择也有着至关重要的作用,当前方法无法同时处理服务特征和协同关系两种数据。图卷积神经网络方法利用邻居节点聚合,同时提取节点特征和边特征,是解决该问题的重要途径。此外,针对图数据关联关系的学习和提取,图卷积网络表现出具有与其它神经网络结合更高效、更方便的特点[17]。近几年,其在节点预测、信息检索等方面得到了越来越广泛的应用[18-21]。文献[22]利用谱图卷积的局部一阶近似构建了图卷积神经网络(graph convolutional neural networks,GCN),提出了基于图卷积网络的半监督学习方法,避免模型仅依赖于单一图结构问题[22]。为了克服模型因浅层架构造成的局限性,文献[23]对图卷积网络模型展开了深入研究,提出了图卷积网络的联合训练和自训练方法[23]。针对基于图的半监督学习方法性能局限这一问题,文献[24]提出了一种新的基于图卷积网络的半监督学习方法,该方法利用数据相似性和图结构获得低维表示以提高方法的性能。
针对上述挑战,本文提出了一种基于图卷积的云制造服务编码检索算法,针对服务选择过程中仅考虑服务质量(quality of service,QoS)属性,从服务间协同关系角度研究云服务初选任务。算法根据编码相似度获取服务候选集,为后续服务组合提供候选服务候选集。算法利用图卷积网络和深度哈希编码技术,构建了一个端到端的深度网络框架,面向云制造服务协同提出一种制造服务哈希检索(manufacturing services hashing,MSH)算法,并在2个仿真数据集上进行实验,分析了所提算法的有效性。该方法考虑QoS属性为服务选择的基础,对服务关系特征中存在的重要信息进行挖掘,以联合学习QoS属性特征和服务关系特征的方式,构建了服务网络图,以解决服务选择过程中社会属性缺失问题。
1 MSH算法
不同的制造服务具有不同的QoS属性、合作关系、任务调度等复杂特征,这些会对服务质量和性能造成不确定的影响。服务平台进行服务组合或服务重调度时,面对海量制造服务,对平台上全部服务进行检索需要消耗巨大的资源。因此,需要根据目标服务或需求生成候选集以缩小计算量。
1.1 服务特征的图表示
为了解决面向协同的制造服务编码问题,本文建立的制造服务图的定义如下:
定义1 制造服务提供者。记当前平台中的服务提供者为集合E={E1,E2,…,Em},其中:有m个制造服务提供者;Ei为第i个制造服务提供者。
定义2 制造服务。制造服务企业能够为外部提供的、具有独立功能且不可分割的制造业务,在日常过程中,制造服务可以与企业内外部的服务进行合并,形成1个独立的服务功能。
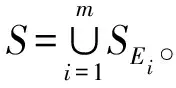
定义3 制造服务协同关系。即制造服务间所有制造服务协同关系的简称,当两个服务si与sj有协同关系,则定义eij=(si,sj)表示服务间协同关系。根据具体任务,可对其定义不同的连接关系和权重。
定义4 图(Graph),给定无向图G=(V,E,X),其由服务节点集合V={v1,v2,…,vN}、服务协同关系边集合E⊆V×V和服务特征集合X构成。节点数量N=|V|;边eij=(vi,vj)∈E表示节点vi与vj具有连接关系;矩阵X={x1,x2,…,xN},其中,xi表示第i个节点的特征向量。
定义5 邻接矩阵。令A表示图G的邻接矩阵,如果节点xi、xj之间存在连接关系,则Aij=1,否则Aij=0,对于无向图有Aij=Aji。令D表示图G的度矩阵,其为对角矩阵,且对角线上的元素表示各个顶点的度。顶点vi的度表示和该顶点相关联的边的数量,即Dii=d(vi)。
定义6 图哈希编码。定义图哈希编码器H为云制造服务图到哈希编码的映射。即H:G→hash∈{-1,1}N×K,定义服务Si的哈希编码为hashi。
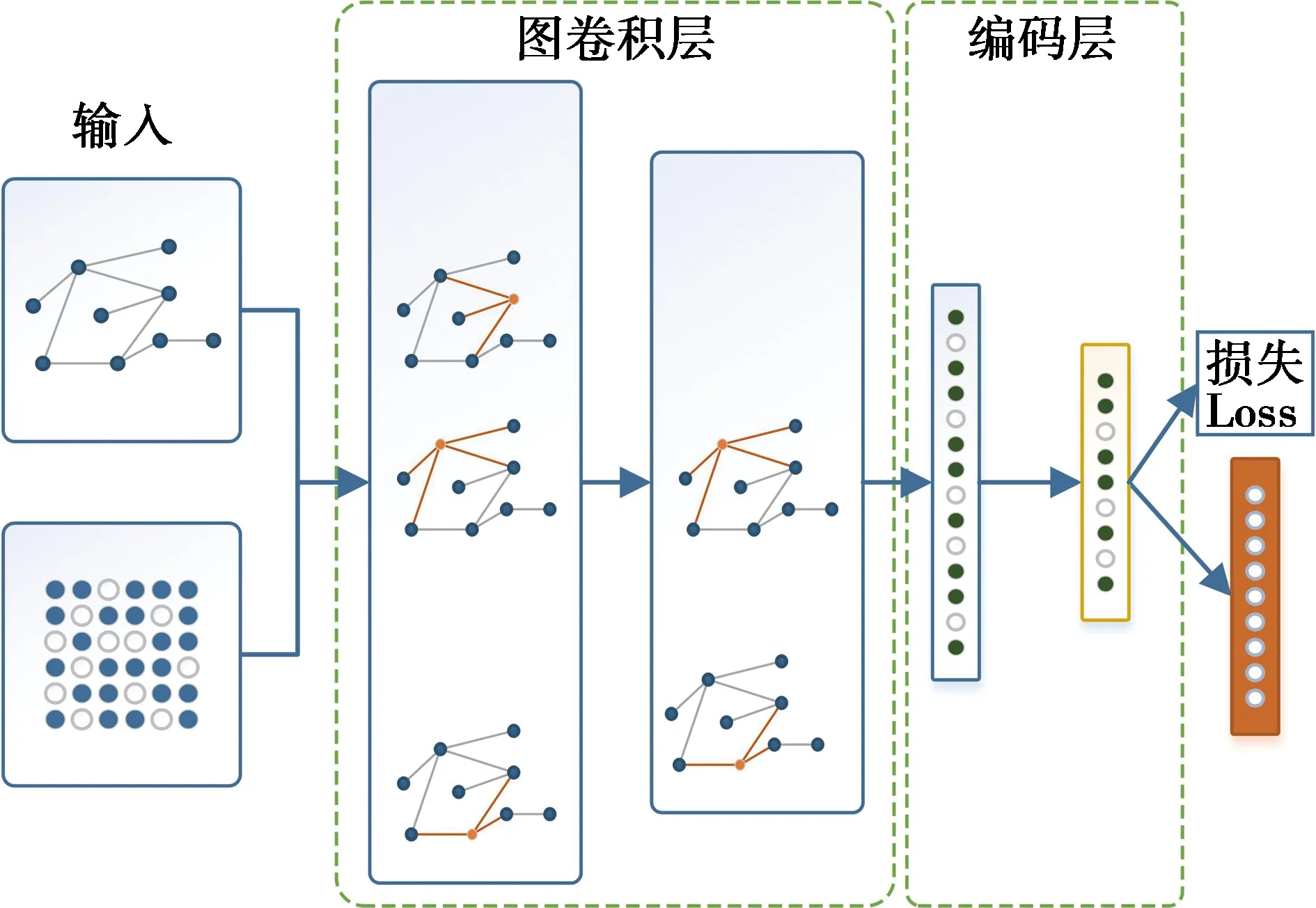
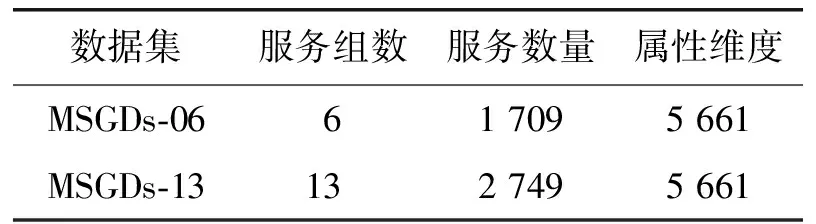
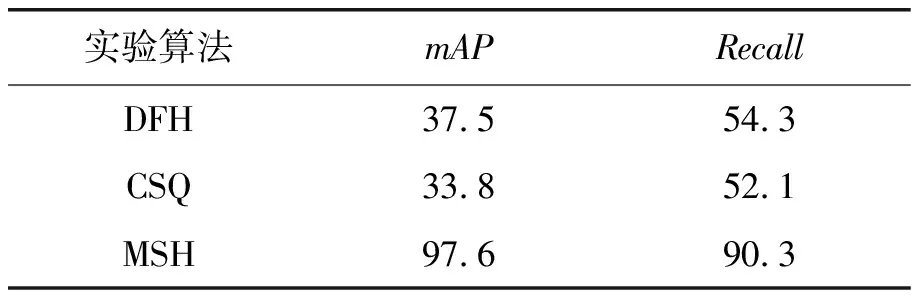
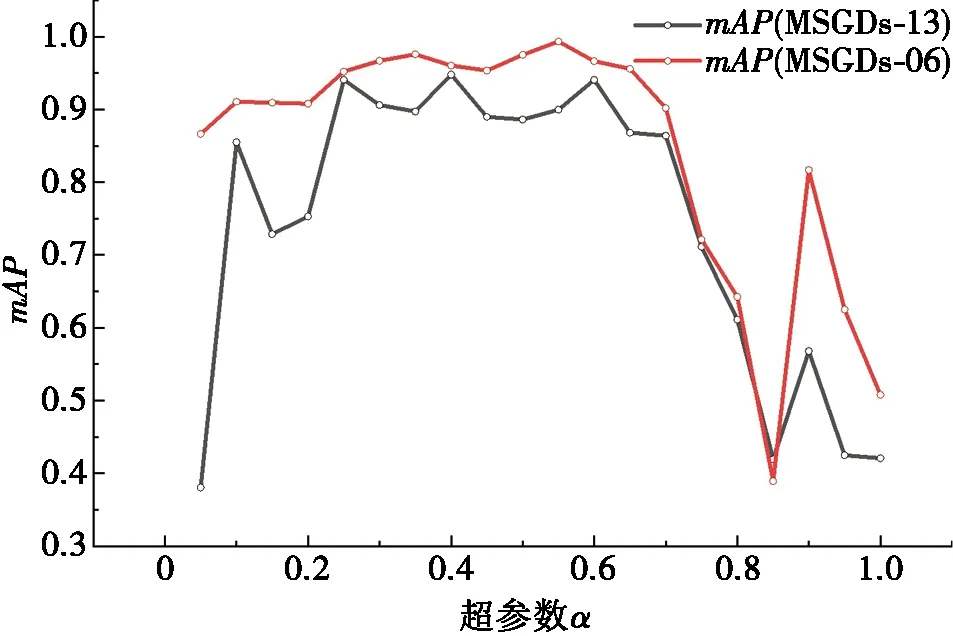
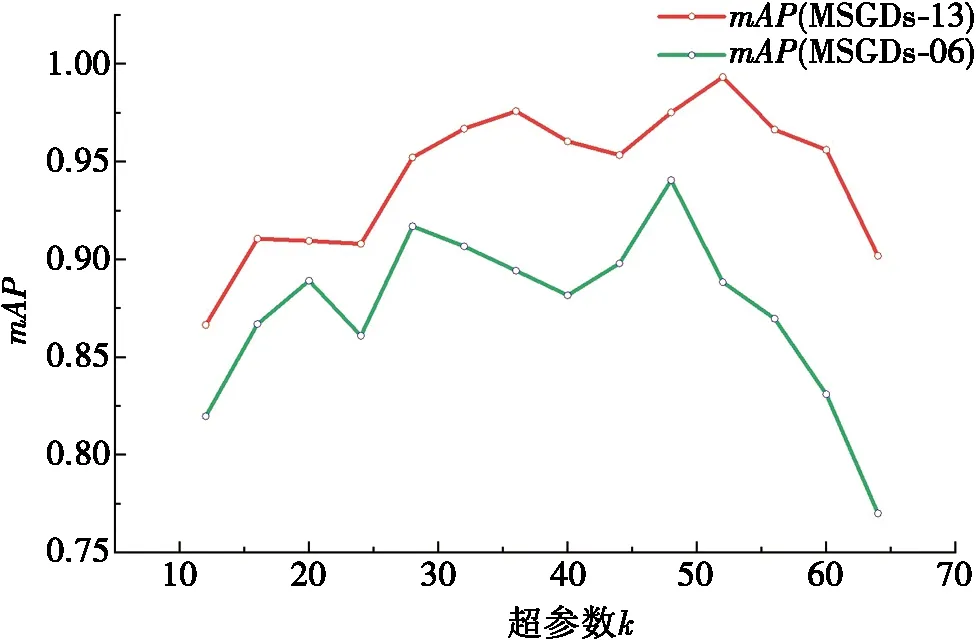
定义7 距离。指不同服务的相似度Sim,利用服务的哈希编码距离Dist对其进行度量。对于∀sm,sn,starget∈S,假设Sim(sm,starget) 为了生成服务特征的中间表示,本文设计了服务编码的神经网络,首先构造了1个图卷积层φ:G→u∈RN×d;然后定义哈希层ω:u→hash∈{0,1}N×K,以学习二进制的哈希编码,神经网络框架图如图1示。 图1 基于图卷积的服务编码神经网络框架 该神经网络定义了一个参数化的非线性映射,将包含拓扑结构和节点特征的图节点vi映射为哈希编码hashi,其中拓扑结构和节点特征分别表示服务制造中的服务间合作关系与制造服务属性。图卷积网络φ的参数Γφ和哈希层ω的参数Γω为可学习的参数,通过神经网络的反向传播学习。 1.2.1 图卷积层 如图1所示,图卷积层φ包含2层图卷积神经网络,它以图G为输入,输出节点中间向量u。其中图G中的服务特性X和服务关系A通过GCN获取其整体的低维表示。对于单层GCN,其逐层传播规则如下: H(l+1)=GCN(H(l),A)=σ(AH(l)W(l)), (1) 其中:W为神经网络的权重参数,通过神经网络的损失反向传播自动学习;σ为神经网络的激活函数。 图卷积层φ可以表示为: φ(H,A)=σ(Aσ(AXW(1))W(2))。 (2) 1.2.2 哈希编码层 哈希编码层连接图卷积层,接收节点中间向量u前向传播,以生成节点的二进制哈希码。如图2所示,利用2层全连接神经网络(fully convolutional networks,FCN)构建哈希编码层,对于给节点v的中间表示ui,采用全连接层FCN将ui转换为K维嵌入向量zi∈K: 图2 算法在MSGDs-06数据集上的性能与损失 FCN(ui)=σ(WTui+b)。 (3) 所以, (4) 为了将生成的嵌入表示转换为二进制哈希码,本文设置激活函数σ为tanh函数,即z∈[-1,1]。在此之后,为了将生成嵌入向量z表示为精确的二进制哈希码,选择符号函数将连续的K维向量zi转换为hashi∈{1,-1}K,即: (5) 1.2.3 损失函数 给定上述定义的图编码器和哈希层,图卷积网络φ的参数Γφ和哈希层ω的参数Γω需要通过反向传播学习。在后面的工作中,目标是学习从图G到K维二进制编码的映射,在模型学习过程中采用半监督学习的方式,故利用部分有类标签的数据对网络进行学习。相似服务的哈希码之间的距离应尽可能接近,而不相似服务其哈希码之间的距离应远离。基于该目标设计损失函数。 首先定义 (6) 其中:hm,hn分别为服务m,n的哈希码;t为服务相似的布尔值。为了能够在神经网络中通过梯度下降训练模型,需要将对二元实值网络进行松弛。为此,本文将Dist(hm,htarget)中的汉明距离替换为欧氏距离,则式(6)更新为: (7) 其中:α为超参数;r为正则化器,公式化的表达为: (8) 根据式(6)~式(8),可得到目标损失函数为: (9) 在实际工作中,训练过程对于模型的优化至关重要。本文提出的MSH算法将服务特征X和服务关系邻接矩阵A同时放入神经网络,有效提取了面向协同制造的云服务特征,通过合理设置的损失函数对网络模型进行优化,实现了有效的服务编码。训练优化过程如表1所示。 表1 训练优化过程 当前在云制造服务选择研究中,实验多采用小批量真实数据或仿真数据进行验证,面向大数据的研究数据较为匮乏。为了评估所提出算法的性能,实验将提出的MSH算法与一些基线算法如深度Fisher哈希(deep fisher hashing,DFH)算法、中心相似度量化(central similarity quantization,CSQ)算法进行对比分析。其中,CSQ利用中心相似性量化方法优化数据点之间的中心相似性;DFH算法采用卷积神经网络(convolutional neural network,CNN)直接学习编码,并用正则化方法将编码进行约束。由于DFH、CSQ模型不支持图数据,实验中仅输入节点特征数据。本节通过制造服务仿真程序模拟现实云制造场景来创建实验数据集,命名为制造服务组数据集(manufacturing service group dataset,MSGDs);然后,给出了2个广泛使用的评价指标用于评价实验算法在服务服务选择任务中的性能;最后,详细且全面地汇报并分析了所提出方法的实验结果,以验证所提出方法的有效性。数值实验将服务作为图节点,将服务属性作为节点特征,相同服务提供商的同类服务具有相同的标签。本文期望能够通过云制造服务选择缩小云制造模式下服务匹配范围,提高服务匹配和组合的效率。 仿真程序初始化制造任务并发布到平台。平台根据任务需求选择合适的服务,并通过服务组合完成制造任务。仿真过程中,程序将服务制造顺序关系记录为日志。考虑到制造服务合作关系对服务选择的重要性,本文利用服务属性特征和服务间合作关系构建图数据集,二者在图数据集中分别表示节点特征与连接关系。具体的,数据集将服务作为图节点V,服务的QoS属性作为节点特征X,邻接矩阵A根据服务间产生的合作日志生成。标签数据根据制造服务的服务商和服务类型属性划分,即相同服务商的同类型服务划分为相同服务组。实验采用0.2∶0.6∶0.2将数据节点划分为训练集、测试集、验证集。为了进行性能分析,本文建立了2个不同规模的数据集验证所提出模型的性能,分别为MSGDs-06与MSGDs-13。实验采用的数据集的统计信息如表2所示。其中,MSGDs-06包含分属于6个服务组的1 709个服务,以及7 504个表示合作关系的边,且每个服务用5 661维的浮点数表示服务属性。MSGDs-13中有分属于13个服务组的2 749个服务,以及11 550个表示合作关系的边。2个数据集中的服务均采用5 661维的浮点数表示服务节点特征。 表2 数据集统计信息 为了评估所提出方法的性能,实验采用2个广泛使用的评价指标度量服务检索性能,分别为召回率、平均精度均值。 召回率(Recall)能够衡量信息检索的覆盖率。给定一个信息检索请求Q,令R为集群中与Q相关的文档集,Recall可根据检索需求获得检索集合A。集合R和A中元素个数分别为|R|和|A|,|R∩A|表示同时在R和A中的文档数。则召回率定义为Recall=|R∩A|/|R|。 实验环境为i7 10750H CPU+64G内存+3090显卡,运行操作系统为Windows 10,编程语言采用Python,统一计算架构(compute unified device architecture,CUDA)版本为11.4。实验将服务特征X和邻接矩阵A送入模型中进行训练,在反向传播过程中,使用训练集的标签进行半监督学习。在评价过程中,模型在根据编码的汉明距离选择出前N个服务作为候选集并验证,实验过程中,令N=10。 本节在MSGDs-06和MSGDs-13数据集上对模型性能进行分析。实验采用mAP和Recall这两种度量指标,运行在MSGDs-06数据集上的实验结果如表3所示。其中,CSQ算法在mAP性能和Recall性能指标上最低,分别为40.6%和50.8%。DFH算法性能略好,mAP性能为45.0%,相较CSQ有12%左右的提升,Recall性能为51.0%,相较CSQ提升不明显。MSH算法的mAP性能和Recall性能最好,分别达到了99.4%和87.1%,基本是CSQ和DFH性能的2倍左右。 表3 运行在MSGDs-06数据集上的实验结果 % 运行在MSGDs-13数据集上的实验结果如表4所示。其中,CSQ算法在mAP性能和Recall性能指标上最低,分别为33.8%和52.1%。DFH算法性能略好,分别为37.5%和54.3%。MSH算法的mAP性能和Recall的性能最好,达到了97.6%和90.3%,其中,mAP性能基本是CSQ算法和DFH算法性能的3倍左右,Recall性能基本也超过CSQ算法和DFH算法约60%。 表4 运行在MSGDs-13数据集上的实验结果 % 算法在不同的数据集上进行实验,最终的mAP指标均能达到0.96以上。这表明服务间合作关系对服务选择能够提出有效决策支持,所提出的算法利用图卷积网络,综合考虑QoS特征和服务间合作关系这两方面的信息,并进行有效的特征提取,进而得到更有助于学习到有效度量服务间相似度的哈希编码,在服务选择的验证中证明具有较高的准确率和召回率。评价指标说明在提取到的10个候选服务中,与查询服务有较高的匹配程度。因此,能够为后续阶段的服务组合等任务提供较为有效的支持。与此同时,得到的Recall值也均能达到0.87以上,且在MSGDs-13数据集上达到0.903的精度值。较好的Recall性能表明在查询到的候选服务中,同类服务具有很高的占比,说明查询结果具有较高的覆盖度。综合分析表3中的结果,不难发现哈希编码能够根据查询服务对候选服务进行较好的区分,能够在提供更准确的查询结果同时,保持候选制造服务的多样性。训练结果表明,服务编码距离能够有效度量服务间的类别相似度,训练之后的编码结果可以进行保存并用于服务间距离度量,进而进行快速服务查询和候选服务集的选择等业务。 2.4.1 模型收敛性分析 本节通过观察在MSGDs-06和MSGDs-13数据集上,随着模型优化模型损失和模型性能的变化分析模型收敛情况,实验结果如图2和图3所示。 图3 算法在MSGDs-13数据集上的性能与损失 在MSGDs-06数据集上,模型训练开始时损失(Loss)大约为35。在前200步训练中,模型损失快速下降;之后,随着模型的进一步优化,损失趋于相对稳定的状态。与此同时,mAP和Recall随着损失下降稳定上升。在400步左右,mAP为0.95,Recall为0.85;接着,随着迭代次数的增加,模型逐渐提取到服务编码信息并经过一定的训练之后能够达到稳定状态,在MSGDs-13数据集上,与MSGDs-06相似,模型经过前200步训练,其损失快速下降并达到相对稳定阶段。在经过400步训练,mAP为0.9,Recall为0.85,相对于MSGDs-06数据集的指标值略低。直观分析可能是由于数据集大小和每个类的数据量不同造成的偏差。之后,模型经过持续训练,其性能和损失均能够达到稳定状态。 通过上述分析可以发现,随着优化的进行,模型在2个数据集上的损失能够快速下降并最终达到平稳状态。模型性能随着损失的下降不断提升,最终也达到平稳状态。实验结果表明模型经过训练能够达到收敛状态。 2.4.2 超参数选择 超参数的选择对模型性能有着重要影响,本节分析超参数α和编码长度k对模型mAP性能的影响。 对于超参数α,令其在[0.05,1]取值,步长为0.05,在MSGDs-06和MSGDs-13数据集进行训练,记录模型的mAP指标的变化。 综合分析图4中的mAP性能结果不难发现,当超参数α在[0.2,0.7]取值时,能够保持在1个相对稳定且性能较高的水平。当α设置在某一合理范围值时,模型对该参数并不太敏感且能够获得较高的精确值。 图4 超参数α对mAP性能影响 在下一步实验时,将超参数α固定为0.6,通过改变哈希码长度探讨其对mAP性能的影响,其中k∈[12,64],结果如图5所示。分析图5中实验结果,当超参数k∈[28,56]时,模型基本能取得相对较好性能。随着k取值的增加,mAP性能会出现较大的波动。 图5 超参数k对mAP性能影响 云制造平台上的服务具有数量庞大、种类繁多、特征复杂等特点,在服务选择的过程中,服务间协同关系缺失会对服务匹配和服务选择的准确性造成巨大影响。本文提出了一种基于图卷积网络的云制造服务编码模型,同时考虑服务特征和服务协同关系,通过图卷积网络实现半监督学习提取到云制造服务的哈希编码。在2个仿真数据集上验证并证明所提出方法有较好的性能。通过计算该模型生成的服务的哈希编码距离,可以度量服务间相似性,这有助于对制造服务进行快速有效查询和选择,为后续的服务组合、服务调度等任务奠定了基础。1.2 基于图卷积的服务编码神经网络

1.3 算法描述

2 实验结果与分析
2.1 数据集和训练
2.2 评价指标
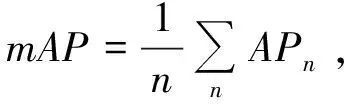
2.3 实验结果

2.4 实验分析

3 结束语
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年11期)2019-07-04
疯狂英语·新读写(2018年3期)2018-11-29
北京航空航天大学学报(2018年1期)2018-04-20
工业设计(2016年8期)2016-04-16
计算机工程(2015年8期)2015-07-03
电视技术(2014年19期)2014-03-11
