
基于CUACE 分等级的空气质量预报研究
2024-02-22 09:48石霖晟杰刘妹宁秦闻通
科学技术创新 2024年3期
石霖晟杰,刘妹宁*秦闻通,吴 瑕
(1.内蒙古自治区气象科学研究所,内蒙古 呼和浩特;2.内蒙古自治区包头市气象局,内蒙古 包头;3.内蒙古自治区根河市气象局,内蒙古 根河)
引言
春季是沙尘频发的季节,新疆塔克拉玛干沙漠、内蒙古巴丹吉林沙漠、腾格里沙漠、乌兰布和沙漠、河西走廊地区都是重要的沙源地[1],内蒙古受沙尘的影响比较严重,沙尘的发生往往伴随着低能见度和低空气质量,对百姓出行和交通安全都造成了巨大的隐患。为此中国气象局积极研发气象环境预报模型,拓展跨部门合作和服务业务,对保障人民健康、指导出行和经济发展都具有重要意义[2]。
廖国莲[3]通过分析CUACE 模式在广西空气质量预报中的效果,发现CUACE 模式预报效果最稳定,其评分基本不随预报时效的延长而明显降低,杨亚丽[4]使用CUACE 模式对银川市重污染天气预报做了检验,结果表明CUACE 模式能较好的模拟首要污染物、AQI、PM2.5、PM10 等。研究者在各地开展了CUACE的适用性分析[5-13],使用线性模型、随机森林、主成分分析、神经网络等算法,在局地建立了基于CUACE 的空气质量预报模型,本研究使用K-means 聚类算法将CUACE 沙尘浓度划分为五层,并基于随机森林模型建立了空气质量等级的预报模型。
1 资料与方法
本研究使用的数据包括2021 年6 月2 日—2022年7 月9 日亚洲沙尘暴数值预报系统(CUACE-Dust)产品、空气质量AQI 数据, 研究区域包括呼和浩特市、包头市、鄂尔多斯市、乌兰察布市、呼伦贝尔市。其中亚洲沙尘暴数值预报系统产品(以下简称CUACE)是中国气象科学研究院自主研发的区域天气—大气化学—大气气溶胶双向耦合模式,由中尺度数值天气预报模式 MM5( Mesoscale Model 5)和气体—气溶胶模块组成,CUACE 模式于2012 年8 月开始在中国气象局国家气象中心应用[5]。
CUACE 产品是0.5°* 0.5°的栅格数据,分为08 时预报和20 时预报。空气质量AQI 数据为站点监测数据,其中呼和浩特市有8 个监测站、包头有6 个、鄂尔多斯有5 个、乌兰察布有4 个、呼伦贝尔有2 个,使用双线性插值法将栅格数据插值到25 个空气质量监测站,插值后CUACE 对应的08、20 预报时次分别有68 382 条和73 198 条。
2 CUACE 分层
通过研究AQI、AQI 空气质量等级和CUACE 之间的相关关系,可以有助于理解CUACE 的分层建模依据。参照《环境空气质量指数(AQI)技术规定》,将AQI 对应到空气质量等级,等级越高,AQI 指数越高,空气质量越差。通过分析空气质量等级分布情况,发现1 级和2 级占据85%以上的数据量,2 级到3 级存在断崖式变化,冬季的空气质量较差,见表1。

表1 逐月空气质量等级统计表
通过内蒙古境内空气质量站点数据计算CUACE 和AQI的皮尔斯相关系数仅为0.19,但分析不同地区CUACE 和AQI的相关系数,发现呼和浩特、包头、鄂尔多斯、乌兰察布和呼伦贝尔较高,阿拉善、巴彦淖尔、赤峰、兴安盟较低。
针对相关系数较高的内蒙古中部地区(呼包鄂乌)和呼伦贝尔等地的数据,先对CUACE、AQI 进行标准化公式(1),提高CUACE 的权重公式(2),再使用K-means 聚类算法观察CUACE 的数据分布。其中进行标准化的目的是因为AQI 数值不超过500,而CUACE 数值最大有6 000,在以距离为划分依据的K-means 模型分类下,等同于给CUACE 附加了更高的权重,标准化后再提高CUACE 权重的目的是为了分类上更偏重于从CUACE 的角度进行划分。
根据K-means 聚类结果,以CUACE 的角度,从大到小大致可以分为5 层,分别是CUACE≥5 000、5 000>CUACE ≥3 000、3 000 >CUACE ≥1 000、1 000 >CUACE≥300、CUACE<300,见图1。
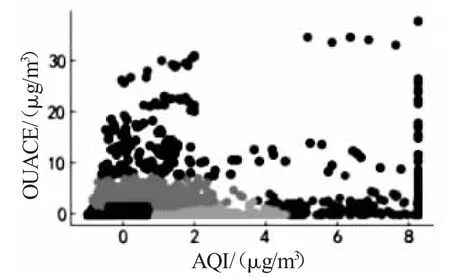
图1 K-means 聚类划分7 类
这5 层各有其特征,第五层CUACE≥5 000,该层特点是AQI 全部大于300。第四层是5 000>CUACE≥3 000,该层的两级分割比较明显,AQI 在200—400 之间的数据量不超过1%,AQI≤100 的数据占16.3%,200≥AQI>100 的数据占58.1%,其余AQI>400 的数据占25.6%。
第三层3 000>CUACE≥1 000,可以发现该层更多的数据集中在了AQI≤100 的区间,400>AQI>200的数据较少。AQI≤100 的数据占41.8%,300≥AQI>100 的数据占35.3%,其余AQI≥300 的数据只占22.8%。第二层1000>CUACE≥300,第2 层和第1 层的分布类似,但AQI≤100 的数据比例更多,AQI≤100的数据占68%,300≥AQI>100 的数据占23.7%,其余AQI≥300 的数据只占8.4%。第一层CUACE<300,该层数据明显集中在AQI≤100 的区间,AQI≤100 的数据占86.2%,300≥AQI>100 的数据占13.5%,其余AQI≥300 的数据只占0.5%。
总结来说,K-means 聚类出的一至五层的数据比为4 044:111:26:6:1,其中第五层的CUACE 和AQI 都是大数,聚类效果也最好,第四层出现了两级分化、中间无数据的情况,这一层200≥AQI>100 的数据最多,其余3 层则以AQI≤100 的数据量占比最多。在AQI≥300 的数据中,一至五层的数据量占比分别是54%、24%、15%、4%、3%。
3 随机森林模型
将AQI≤100 作为第0 类,200≥AQI>100 作为第1 类,AQI≥300 作为第2 类,根据K-means 算法聚类出的5 层,分层建立随机森林模型,预报空气质量等级,见表2。可以发现预测效果呈现倒三角式变化,CUACE 预测的两端效果最好,且第0 类的划分效果相较于其余两类更好。

表2 随机森林模型的建模结果
随机森林模型的评判规则可进一步参考图形化的表述,见图2。图中规则树为标准的二叉树,每一个节点(方框)对单一要素划分,将本节点的数据预测为第0 类、第1 类或第2类,下分两个子节点,相对左侧的子节点是父节点判断规则为True 的节点,相对右侧的子节点是父节点判断规则为Fasle的节点,子节点在最后一行用class 表示预测结果。通过gini评估各节点划分效果,gini 越小说明该节点划分的效果越好。方框中的samples 表示该节点的数据量,value 是带权重的样本比例(举例来说,[第0 类的数量,第1 类的数量,第2 类的数量]),有时value 中的总数会大于samples,这是因为本研究对第1 类和第2 类赋予了更高的权重。另外方框颜色的深浅也能表示划分的效果,偏橙色代表预测为第0 类,偏绿色代表预测为第1 类,偏蓝色代表预测为第2 类,颜色越深,划分的效果越好,value 中各类样本的数量相差越大,gini 越小。
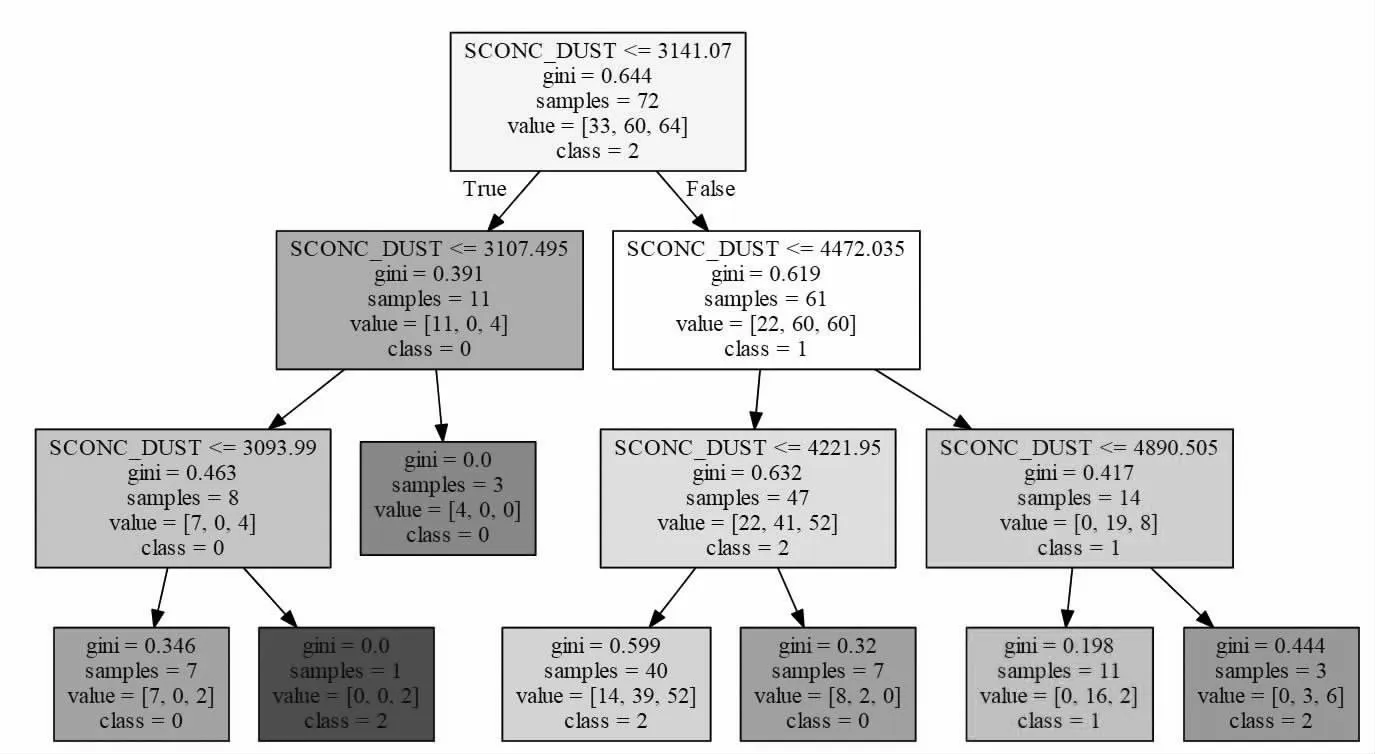
图2 第四层的建模结果
根据检验结论,模型整体的预测效果优于CUACE,特别在分层预报中表明,CUACE 数值越大,分层效果越好,其中第四层和第三层的预测效果较好。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
少儿美术(快乐历史地理)(2020年3期)2020-07-24
电子制作(2019年13期)2020-01-14
草原歌声(2019年2期)2020-01-06
草原歌声(2018年2期)2018-12-03
草原歌声(2017年3期)2017-04-23
环境保护与循环经济(2017年3期)2017-03-03
汽车与安全(2016年5期)2016-12-01
