
融合自注意力机制的垃圾弹幕识别方法研究
2024-02-22 09:53费寅杰曾孟佳
科学技术创新 2024年3期
费寅杰,黄 旭*,曾孟佳
(1.湖州师范学院 信息工程学院,浙江 湖州;2.湖州学院 电子信息学院,浙江 湖州;3.湖州市城市多维感知与智能计算重点实验室,浙江 湖州)
引言
随着互联网的不断蓬勃发展和网络直播日益兴起,通过弹幕文本实现互动成为网络直播用户之间交流的重要方式。
然而,由于网络直播用户来源广泛、文化层次跨度大、情绪控制力参差不齐,出现了在海量直播弹幕中夹杂垃圾弹幕的现象,污染了直播环境,危害了社会风气[1]。为了降低垃圾弹幕对网络直播环境的负面影响,直播平台往往采用专门的方法识别用户发布的内容,确认弹幕是否为违规信息,以便进一步采取管控措施[2]。目前常用的是通过建立关键词字典自动识别垃圾弹幕的方法来识别垃圾弹幕,这种方法误封率高且关键词字典维护成本较高[3],并不能真正满足直播平台的实际需求。
1 相关研究
直播弹幕文本是短文本的一种,对直播弹幕文本中的垃圾弹幕进行识别本质就是文本分类的一种。
2014 年,Kim 等[4]将卷积神经网络(CNN)创造性地运用到了文本分类任务中,提出了TextCNN 模型,利用多个不同尺寸的卷积核来提取句子中的关键信息,从而能够更好地捕捉文本中局部信息的相关性,提高文本浅层特征的提取能力,在短文本领域的分类效果很好,应用广泛。
2017 年,Lin Z[5]等人提出了一个特殊的正则式和一种引入自注意力机制进行句子嵌入表达的方法,该方法能够关注到句子不同地方的不同特征,在情感分类等文本任务上模型性能显著提高。
2018 年,Google AI 团队[6]提出了使用双向Transformer 结构的Bert 模型,该模型采用两种新的词向量计算方法,基于特殊的掩码策略学习任务,将学习到的特征表示应用于下游任务,在自然语言领域的多个任务中取得创纪录的成绩。2019 年,百度公司[7]在BERT模型的基础上做了进一步的优化,扩展了中文全词掩码策略,在中文的NLP 任务上取得了SOTA。杨森淇[8]等提出了一种基于ERNIE、深度金字塔神经网络和双向门控循环单元的EGC 模型,减少其卷积层,保留更多特征,提高了模型的性能。
综合以上研究,本文分析了垃圾弹幕文本特点,设计了一款融合ERNIE、TextCNN 和自注意力机制的适合垃圾弹幕识别的ERNIE-TextCNN-SA 模型。ERNIE 模型针对中文文本制定了特殊的掩码策略,能够更好地理解中文的语义信息;TextCNN 神经网络在短文本分类中性能优秀,能够更好地捕捉文本的局部相关性;加入自注意力机制,提高文本中重要特征的权重,降低无用特征对文本的影响。
2 模型构建
本文设计了一款融合ERNIE、TextCNN 和自注意力机制的适合垃圾弹幕识别的ERNIE-TextCNN-SA模型,用于识别网络直播中的垃圾弹幕,整体模型架构如图1 所示。
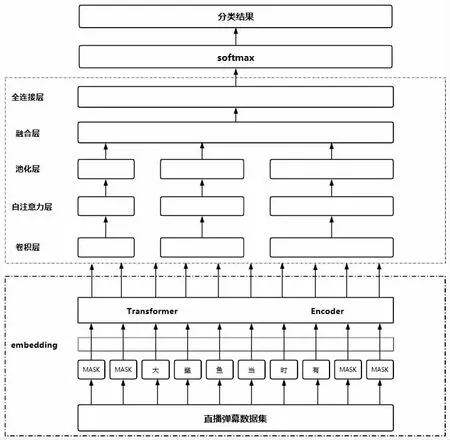
图1 ERNIE-TextCNN-SA 模型结构
2.1 输入层
输入层就是用来将原始的文本数据先进行分词,对分词后的每一个词语,用词向量方法转化为词向量,再将这些词向量做等长处理,最后组成一个向量矩阵。
相较于静态词向量,预训练模型生成的动态词向量可以更好地体现文本中的上下文特征,避免一词多义的现象产生。本文采用ERNIE 词向量来表示文本。对于一条文本信息,以汉字为基本单位对文本进行分割并对其进行掩码训练,得到对应的词向量A:

2.2 卷积层

每一次卷积操作相当于一次特征向量的提取,通过定义不同的窗口,就可以提取不同的特征向量。对句子单词每个可能的窗口做卷积操作得到卷积层的输出
2.3 自注意力层
本文分析了垃圾弹幕文本特点,发现有些垃圾弹幕通过在垃圾文本的前后夹杂正常文本来躲避审查。针对这一特点,本文尝试在TextCNN 模型中加入自注意力机制,对垃圾弹幕文本中的关键特征赋予更大权重,以突出关键文本特征,减轻不相关文本对分类结果的干扰。
自注意力机制的权重矩阵A 由softmax 函数计算归一化后得到的值组成,可以用公式(4)表示:

2.4 池化层和输出
池化层的主要目的是对卷积层所提取的信息进行降维,减少计算量,降低过拟合的风险。TextCNN 模型的池化层选用的是最大池化的方法,对重新分配过权重的特征向量选取最大值并对特征向量进行整合,可以用公式(6)表示:
将最大池化后的特征信息送入全连接层,得到最后的输出,最后将输出通过Softmax 函数得到分类结果。
3 实验及结果分析
3.1 实验数据
本文数据来源于bilibili 弹幕网站与斗鱼直播平台,经过预处理和人工标记后保留了8 000 余条弹幕文本,建立垃圾弹幕识别数据集。为了避免出现数据不平衡问题,数据集中垃圾弹幕文本和正常弹幕文本比例为1:1。
3.2 对比方法与评价依据
通过精准度(Precision)、召回率(Recall)和F1 值3 个指标对模型的分类效果进行评估。3 个指标值均在0~1 之间,值越接近1,说明模型的性能越好。具体的评价指标计算方式如下:
式中:TP 表示判断为某个类别的样本中实际也属于该类别的样本数;FP 表示判断为某个类别的样本中实际不属于该类别的样本数;FN 表示判断为不属于某个类别的样本中实际属于该类别的样本数。
3.3 实验与结果分析
在6 个不同的文本分类模型上进行垃圾弹幕识别对比实验,给定一个弹幕文本数据,预测该文本数据是否为垃圾弹幕。6 个文本分类模型均在同一个训练集上训练、测试、调整超参数,对实验结果进行比较。实验结果如表1 所示。
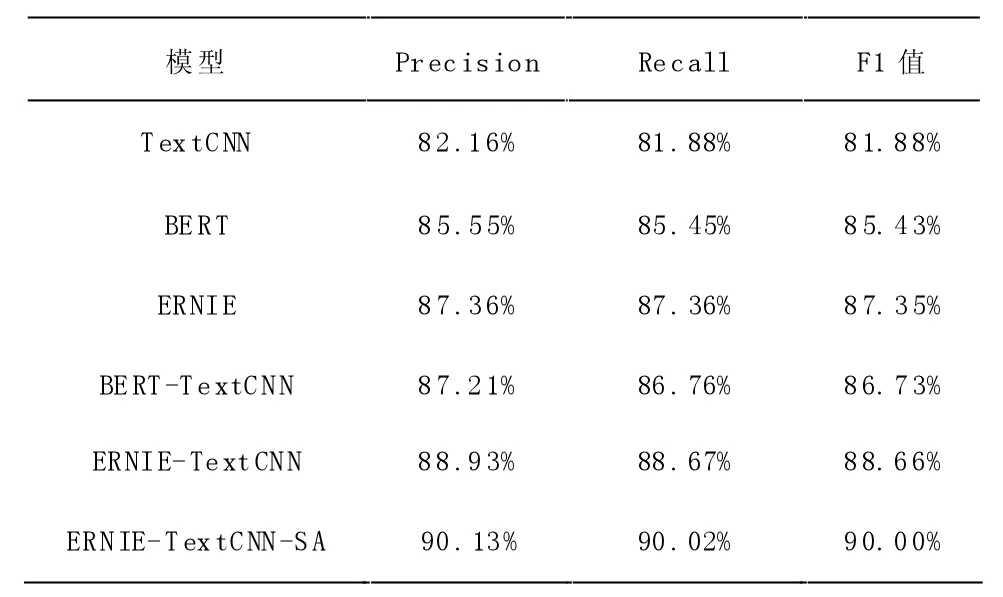
表1 6 个文本分类模型在数据集的实验结果
对于垃圾弹幕识别数据集,本文所挑选的6 个深度学习文本分类模型,分类效果均达到良好以上,在一定程度上说明将深度学习方法应用于垃圾弹幕识别是可行的。6 个模型中ERNIE-TextCNN-SA 模型的分类效果最好,精确度到达了90.13%,与单纯的ERNIE 模型相比精确度提高了2.77%,相比没有改进过的ERNIE-TextCNN 文本分类模型精确度高约1.2%且精确度较TextCNN 文本分类模型有较大提升。由此可知,将ERNIE-TextCNN-SA 模型融合的方法用于垃圾弹幕的识别相较于其他方法有一定优势。
部分直播弹幕文本的分类结果如表2 所示。有些垃圾弹幕为了躲避审查会在垃圾弹幕文本的前后夹杂正常文本,根据表2 可以看出,对于这一类的垃圾弹幕,没有引入自注意力机制的文本分类模型对大部分类似的垃圾弹幕识别错误,而引入了自注意力机制的ERNIE-TextCNN-SA 模型仍能够正确识别。由此可知,在垃圾弹幕文本分类中引入自注意力机制来突出文本的关键特征,关注文本中更为重要的信息,能够提高垃圾弹幕文本分类方法的性能。
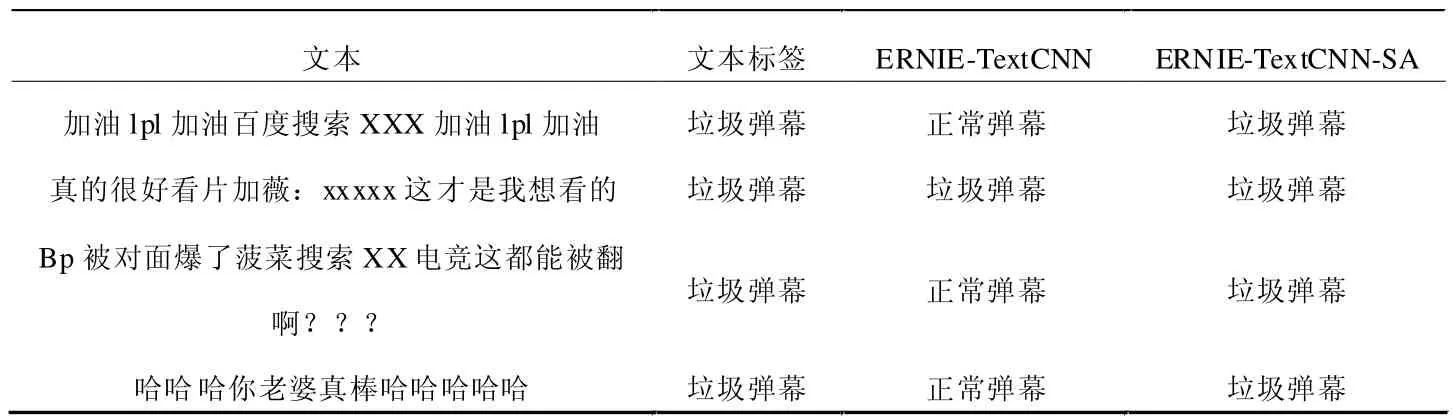
表2 直播弹幕文本分类样例
结束语
本文构建的ERNIE-TextCNN-SA 模型,在对比试验中的实验结果为6 个模型中最优。实验证明了该模型用于垃圾弹幕识别相较于其他算法有一定优势,为今后相关视频直播弹幕文本相关领域的研究提供了一定的参考,但是仍然存在一些不足。本文所构建的垃圾弹幕文本识别数据集还不够全面且数据具有一定的时效性,一定程度上影响了文本分类模型的实际性能。在后续的研究中要继续扩大数据集,加强数据集的全面性。
猜你喜欢
中学生天地(B版)(2023年2期)2023-04-01
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
汉语世界(2021年2期)2021-04-13
小学科学(学生版)(2020年10期)2020-10-28
电子制作(2019年11期)2019-07-04
小哥白尼(野生动物)(2019年3期)2019-07-01
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
