
基于注意力特征融合网络的DGA恶意域名检测方法
2024-03-01 04:29郝旭光
网络安全与数据管理 2024年1期
郝旭光
(山西省政务和公益域名注册管理中心,山西 太原 030024)
0 引言
域名服务系统(Domain Name System,DNS)是互联网最基础的应用系统,通过建立域名和IP地址的对应关系支撑服务其他业务应用,但其开放性和公平性也被恶意软件利用。僵尸网络借助域名生成算法(Domain Generation Algorithm,DGA)大量生成DGA域名,通过命令与控制(Command-and-Control,C&C)服务器操控受害者主机,达到逃避安全监控、提高生存和攻击能力的目的,从而进行大规模的分布式拒绝服务攻击、发送垃圾邮件、传播非法信息和钓鱼网站、运行勒索软件等恶意活动。其复杂性和隐蔽性导致传统的网络安全防御手段难以有效应对,追踪控制服务器位置变得更加困难。
如何高效检测和拦截DGA域名,是近年来网络安全防护技术研究的热点方向。纵观当前DGA恶意域名的检测方法主要包括基于特征提取的机器学习方法检测、基于无特征提取的深度学习方法检测和基于附加条件的深度学习方法检测[1]。基于特征提取的机器学习方法优势在于可以利用常见特征实现高效检测,比如借助于人工提取的诸如域名长度、元辅音占比、字符频率等,以及DNS请求和响应的频率、时序和地理分布等特征,使用分类器进行域名分类实现快速检测。基于无特征提取的深度学习方法借助深度学习的自动特征学习能力,既能缓解对人工提取特征的过度依赖又能发现传统统计方法无法发现的特征,很大程度上解决了特征检测法实时性差和易被绕开的缺点,提高了DGA恶意域名检测的准确性。基于附加条件的深度学习方法添加了某种附加条件以提高检测准确率,例如将注意力集中在域中更重要的子串并改善域的表达,增加域名的多字符随机性提取方法,通过词法分析和Web搜索来估计域名随机性等措施,以提高模型的检测性能,特别是针对新型DGA域名的检测。
以上方法虽然在一定范围内取得了效果,但为了提高生存率,DGA算法也在不断更新迭代,导致现有检测方法逐步失效。特征法依赖人工提取字符和流量特征,易受到复杂网络环境的干扰,攻击者可以重新设计DGA生成算法绕过检测,导致此类方法在面对新型DGA域名时,泛化能力和准确率受限。深度学习法在遇到如数据量少的DGA域名家族、新型DGA域名时,无法捕捉到某些关键信息,且易受到精心设计的对抗样本的欺骗,在应对更加智能的DGA域名上的表现不佳。附加条件法在不同的附加机制中,针对一些如短域名、高可读性域名存在误判和表现效果不佳的现象。
本文提出了一种注意力特征融合网络。通过Embedding层、卷积神经网络(Convolutional Neural Network,CNN)层、注意力模块和长短时记忆(Long Short Term Memory,LSTM)网络层集合了各种检测方法的优势和长处,显著提升了对DGA域名检测的能力。首先,Embedding层使得网络能够学习输入数据的稠密向量表示,从而捕捉更丰富的信息。其次,CNN层和LSTM网络层的组合实现了层次化特征提取,前者负责提取局部特征,后者捕捉长期依赖关系,增强了模型的泛化能力。第三,注意力模块的引入有助于关注域名字符间重要的局部特征,进一步解决长距离依赖关系难以捕捉的问题。实验表明,使用本文方法检测DGA域名,在准确率、精确率、召回率和综合性能上都有着明显的提升。
1 DGA域名及其特征
1.1 DGA域名
DGA域名指通过DGA算法自动生成的域名,通常依赖于一个种子值(如当前日期、特定数值或者内置种子等)和一个预定义的算法。僵尸网络客户端通过DGA算法生成大量域名,并且进行查询,攻击者在控制端运行同一套DGA算法,生成相同的备选域名列表。当需要发动攻击的时候,从列表中选择少量的域名注册开通便可以建立通信,同时可以利用IP速变技术,实现IP和域名快速变化隐藏C&C服务器,逃避网络安全设备的监测跟踪,为僵尸网络提供一个持续且难以被追踪的通信连接。
以著名的Conficker僵尸网络为例,其A/B变种的DGA算法基于当前日期作为种子值,每天生成250个.com域名和250个.net域名。具体的,其使用一个基于时间的种子值,对26个字母进行置换,生成长度不同的域名。而CryptoLocker是一种勒索软件,其基于种子值和日期,通过一系列的数学运算和映射,生成不同的域名。Banjori是一种恶意软件,其DGA具有多元递归关系,每次都会根据前一个域名生成下一个域名,用加减和取模运算得到下一个域名的前四个字母,同时保持后缀不变。表1展示了这三种恶意软件中使用DGA所生产的恶意域名以及部分正常的域名。

表1 DGA域名与正常域名示例
1.2 DGA域名特征
DGA域名由算法自动生成,无需人工干预。其具有语义不明确、结构不均衡、长度变化大、存活时间短等特征。可以将DGA域名与正常域名的差异总结为以下三点:
(1)语义性。正常域名通常具有较强的语义性,通常是为了表示实际的公司、组织或产品而创建的。正常域名往往包含有意义的单词、缩写或短语,以便用户能够轻松地识别和记住。相反,DGA域名通常缺乏语义性,因为由算法自动生成,目的是让其难以被预测和追踪。
(2)结构和可读性。正常域名通常具有较好的结构和可读性,字符分布较为均衡,可能包含辅音和元音的组合,以及一定比例的数字和特殊字符。而DGA域名的结构和可读性通常较差,字符分布可能不均衡,字符组合可能显得更加随机和无规律。
(3)域名长度。正常域名的长度通常在一定范围内变化,具有较短的平均长度。而DGA域名的长度可能有很大差异,根据所使用的生成算法,长度可能非常短或非常长。不过部分DGA可能会生成较短的域名,以模仿正常域名的外观。
虽然这三个方面的差异能够帮助区分正常域名与DGA域名,但也正因为DGA域名无语义、无规律的特点导致一般方法难以有效检测。
2 相关工作
基于DGA域名的特征,通过分析其不同的生成算法,研究者设计提出了不同的应对思路和检测方法,归纳起来主要为以下三类。
2.1 基于特征提取的机器学习方法的检测
利用合法域名与DGA域名在字符组合上的差异,Ma等人[2]提出了一种轻量化的方法来检测DGA域名。该方法利用URL的词法构造特征,如URL的长度、中英文句号的数量和特殊字符的数量等判定DGA域名。Wang和Shirley[3]使用词语分割从域名中提取标记来检测恶意域名。所提出的特征空间包括字符数、数字和连字符的数量等。胡鹏程等人[4]从域名中提取了包括随机性、可读性、数字与字母分布情况、顶级域名、域名长度在内的多个特征,并使用机器学习算法进行测试。王红凯等人[5]通过人工提取域名长度、字符信息熵、多类字符比例等特征,使用随机森林实现DGA域名的检测。Agyepong等人[6]则通过人工提取的KL散度、Jaccard系数等特征用于训练模型完成检测。
通过网络流量分析并结合上下文特征,韩春雨等人[7]提出了一种基于DNS流量的Fast-flux域名检测方法,利用DNS流量中的域名语言特征和统计特征来区分Fast-flux域名和正常域名,并使用机器学习模型进行分类。其也引入了量化的地理广度、国家向量表和时间向量表特征,以加强对Fast-flux域名检测的针对性。Manasrah等人[8]提出了一种基于DNS流量挖掘的DGA域名检测方法。该方法使用了多个相关的语言特征,如随机度、稀有度、打字难度等来衡量域名的特征,在不同类型的DGA域名上实现了高准确率和低误报率。Wang等人[9]利用DNS流量中的域名统计特征和时间序列特征来区分DGA域名和正常域名,并使用聚类算法来划分不同类型的DGA域名。该方法使用如域名长度、元音比例、熵、请求频率和持续时间等特征来描述域名的特征,并在多种DGA家族上实现了良好的检测效果。Antonakakis等人[10]提出称为Pleiades的检测系统。通过提取与NXDOMAIN字符串相关的统计特征,包括n元分布和字符频率,并使用机器学习算法将NXDOMAIN字符串分成DGA生成和合法两类,在大规模的DNS流量测试中表现出高检测率和低误报率。Silveira等人[11]提出了一种使用被动DNS自动检测恶意域名的方法,从DNS流量中提取了12类不同的特征,并使用XGboost算法对特征进行学习,在数据集上的AUC达到了0.976。
2.2 基于无特征提取的深度学习方法的检测
Highnam等人[12]提出了一种混合神经网络Bilbo,用于分析域名并评分其由字典DGA生成的可能性。该模型在跨不同字典DGA分类任务的泛化性能方面,在AUC、F1分数和准确性方面都能取得较好的成绩。Kumar等人[13]提出了一种基于深度神经网络的增强DGA检测模型,该模型结合了额外提取的人工特征以及由深度学习模型提取的特征,在DGA域名分类方面的性能优于SVM、RF等现有方法。Yu等人[14]通过将LSTM和CNN用于DGA域名检测,证明了深度学习方法相比于如随机森林等机器学习方法在检测时性能上的优越性。但其同时也发现,传统深度学习方法的性能容易受到数据不平衡的影响,导致在样本较少的DGA域名家族上的检测效果较差。申宋彦[15]通过卷积神经网络分别提取域名中的字符特征和词特征,并通过改进的卷积神经网络实现了对难度较大的恶意域名家族的识别效果提升。Vinayakumar等人[16]比较了RNN、CNN、LSTM等深度学习方法在检测DAG恶意域名时的性能,发现递归神经网络的架构能够有效增强深度学习模型的整体检测能力。还有部分工作[17-19]采用了不同架构的RNN来检测恶意域名,包括门控循环单元(Gated Recurrent Units,GRU)和双向循环神经网络(Bi-directional Long Short-term Memory,Bi-LSTM)等,但这些方法在检测随机性较高的DGA域名时无法很好地捕捉到字符之间的序列关系,识别率较低。此外,生成对抗网络(Generative Adversarial Network,GAN)得益于其建立在博弈论上优秀的网络训练机制,在DGA域名识别任务中也得到了使用。如袁辰等人[20]和Anderson等人[21]通过在生成网络中不断生成真实度更高的恶意域名,同时在判别网络中对生成的恶意域名进行检测,使得判别网络的识别能力不断提高。
2.3 基于附加条件的深度学习方法的检测
随着DGA域名的算法越来越智能化,采用基于特征和深度学习的检测方法愈感力不从心。研究者又在此基础上增加一些附加条件来达到提高检测率的目标。Chen等人[22]提出了一个结合注意机制的LSTM模型,将注意力集中在域中更重要的子串并改善域的表达,达到了更好的性能,在二元分类中,其误报率和假阴率分别低至 1.29%和0.76%。陈立皇等[23]也提出了一种基于注意力机制的深度学习模型,不同的是,他们采用一种域名的多字符随机性提取方法,提升了识别低随机 DGA 域名的有效性。Satoh 等[24]通过词法分析和 Web 搜索来估计域名随机性,但该方法对域名长度较短时,无法区分,不包含在字典中的域名会被误判。
为了逃避神经网络的检测,恶意域名已升级为多个单词的组合。为此,Curtin等[25]提出了用smash分数来评估DGA域名与英文单词的相似程度,并设计了递归神经网络架构与域注册信息的组合模型。虽然实验在对 matsnu和suppobox像自然域名的家族的检测效果好,但是在那些不像自然域名DGA系列表现效果欠佳。
综合分析以上相关DGA域名检测方法,各种模型算法面对不同的DGA家族在一定时期达到了较高的检测准确率和较好的网络防御效果,但在面对不断升级的DGA算法和一些特殊的结构设计还存在着漏检和误检的情况。随着新技术的发展,特别是恶意算法对新技术的综合运用使得恶意域名特征更加难以捕捉,需要综合利用各种检测方法的优势,提升检测范围的覆盖率、准确率。因此,本文集合深度学习模型的优点,引入注意力模块,提高了DGA域名的检测能力。
3 注意力特征融合网络
本文所提出的注意力特征融合网络模型结构如图1所示,包括输入层、Embedding层、卷积网络层、注意力模块、长短期记忆网络层和输出层。功能分别为:(1)输入层:负责接收原始的域名数据,作为神经网络的起始输入;(2)Embedding层:负责将输入的离散域名字符映射为稠密向量表示,以便更好地捕捉字符间的相关性;(3)卷积网络层:负责提取域名序列中的局部特征,如字符的组合模式,有助于识别DGA恶意域名中的模式;(4)注意力模块:紧接在卷积网络层之后,负责在处理域名的局部特征时关注更具判别力的局部特征,以提高恶意域名检测的准确性;(5)长短期记忆网络层:依据得到的重要性不同的域名局部特征来捕捉域名序列中的长期依赖关系,以便更好地理解字符间的上下文关系;(6)输出层:负责将神经网络的预测结果转化为具体的分类标签,例如判断输入域名是正常域名还是DGA恶意域名。
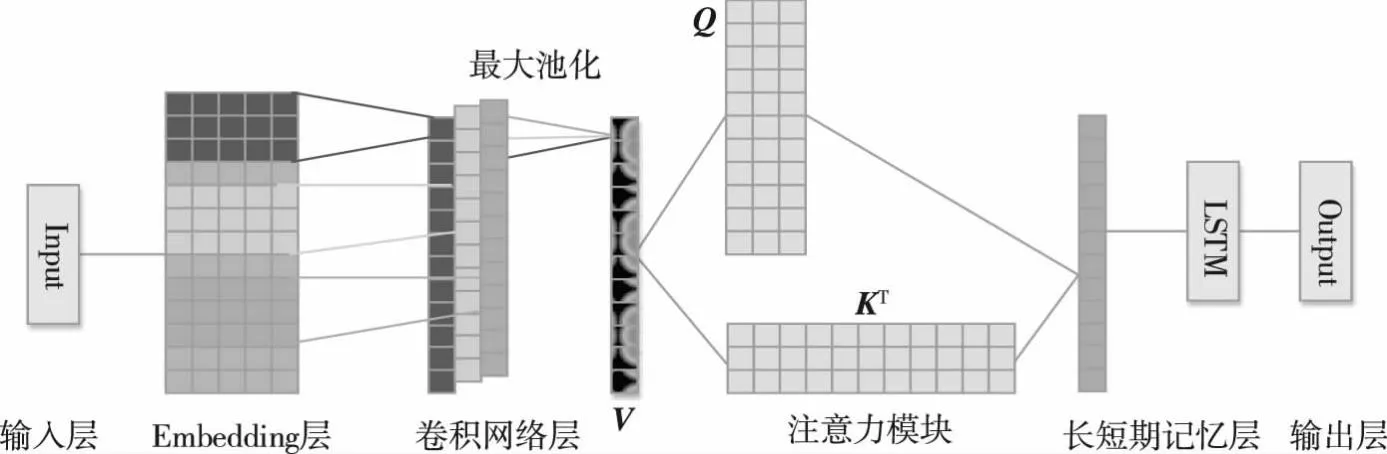
图1 注意力特征融合网络整体结构
3.1 输入层
接收原始的域名数据,并将其转换为适合神经网络处理的格式。作为神经网络的起始部分,输入层对数据质量和格式的处理至关重要,因为它们会直接影响网络的学习效果和性能。
输入数据通常以域名序列的形式提供,每个域名由一系列字符组成,包括字母、数字和连字符等。为了使神经网络能够更好地处理这些离散字符,需要对输入数据进行预处理。预处理的主要步骤包括:(1)将域名转换为小写形式,以消除字符大小写的影响;(2)统一域名的长度,对较短的域名进行填充或截断较长的域名,以确保输入具有相同的维度;(3)将离散字符映射到整数编码,以便神经网络能够处理这些数据。
经过预处理后,输出的数据为整数编码的域名序列。例如,给定一个原始域名“example.com”,经过预处理后,输入层可能输出一个整数序列,如[5,24,1,13,16,12,5,28,3,15,13]。整数编码的序列可以被后续的神经网络层(如Embedding层)接收并处理,进一步提取有助于DGA恶意域名检测的特征。本文所使用的域名数据中,域名长度集中分布情况如图2所示。可见,域名长度分布在4~73之间,且集中分布在8~30之间,因此在进行预处理时,将所有域名长度超过32的部分进行截断,而对长度不足32的域名,则对其序列化后的表示进行补零,使得所有输入的序列长度都为32。
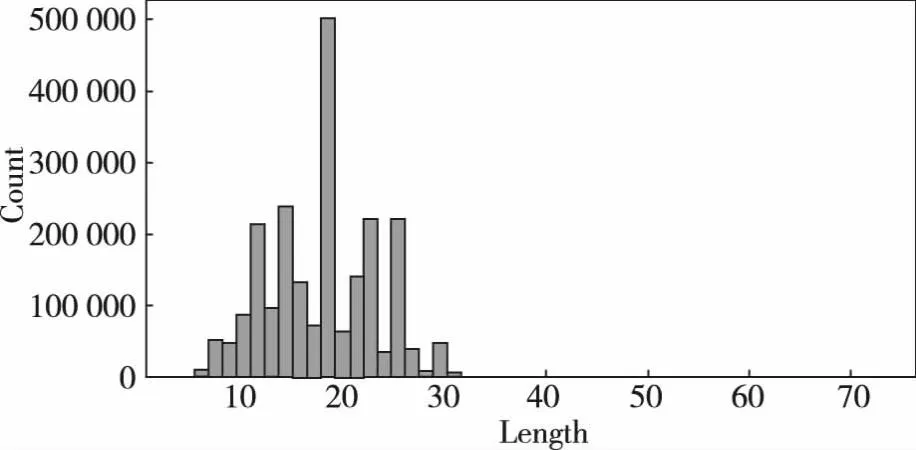
图2 域名长度分布图
3.2 Embedding层
Embedding层将输入层提供的整数编码域名序列转换为稠密向量表示,帮助神经网络更好地捕捉输入数据中的相关性和特征,从而提高整体性能。具体的,是将每个整数编码的字符映射到一个固定长度的连续向量空间。映射过程可以理解为一个查找表操作,其中每个整数编码都对应一个预先定义的向量。在训练过程中,Embedding层会通过反向传播算法更新这些向量,使其能够更好地捕捉字符之间的相关性。因为本文将以域名中的每个字符作为处理对象,所以Embedding的维度为Rv×e,其中v指的是vocabsize,即出现的所有字符的数量,而e指的是embeddingsize,即每条字符向量的长度。每条域名在经过embedding层的映射之后,其维度会变成Ri×e,其中i指的是inputsize,即输入域名的长度。因为在预处理中将域名的长度都对齐为32,所以inputsize为32。
3.3 卷积网络层
卷积网络层负责提取输入序列中的局部特征。通过卷积操作,该层能够捕捉字符之间的邻近关系,从而识别DGA恶意域名中的特定模式。卷积操作可以被表示为一个滑动窗口在输入矩阵上按照一定的步长进行扫描。具体而言,给定一个输入矩阵X,一个卷积核T和一个偏置b,卷积操作可以通过下式计算:
(1)
其中,Yij是输出矩阵Y的第(i,j)个元素,(m,n)是卷积核T的索引。通过遍历输入矩阵上的所有可能位置,可以计算出完整的输出矩阵Y。在本层中采用了一维卷积(1D-CNN),因为这种形式的卷积能够更好地处理序列数据。具体的,一维卷积只沿着域名序列的长度方向进行,从而能有效地捕捉字符之间的局部模式。在模型中同时使用了大小为3的多个卷积核,以实现对多种局部特征的提取,从而增强模型的表征能力。在卷积层后,网络还使用了最大池化层来降低模型的参数,并去除作用不显著的冗余信息。
3.4 注意力模块
为输入序列中的每个元素分配不同的权重,以便在处理序列数据时关注更具判别力的部分。通过注意力机制,神经网络能够更好地捕捉长距离依赖关系,提高恶意域名检测的准确性。本模型中所使用的注意力模块采用自注意力机制(Self-Attention),其计算过程可以分为三个步骤:(1)计算查询(Query)、键(Key)和值(Value)矩阵;(2)计算注意力分数;(3)计算加权值和。假设输入矩阵X的维度为(t,d),其中t是序列长度,d是特征维度。首先,计算查询矩阵Q、键矩阵K和值矩阵V:
Q=XWQ,K=XWK,V=XWV
(2)

(3)
最后,计算加权值和:
Y=SV
(4)
此时,输出矩阵Y的维度与输入矩阵X相同,但元素的权重经过重新分配,使得网络更加关注重要部分。
3.5 长短期记忆层
负责处理序列数据中的长期依赖关系。LSTM是一种特殊的递归神经网络,通过引入门控单元来解决传统RNN中的梯度消失和梯度爆炸问题。LSTM单元包含三个门控单元:输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及一个单元状态(cell state)。给定一个输入向量xt和前一时刻的隐藏状态ht-1,LSTM单元中输入门、遗忘门、输出门的计算过程分别如下所示:
it=σ(Wixxt+Wihht-1+bi)
(5)
ft=σ(Wfxxt+Wfhht-1+bf)
(6)
ot=σ(Woxxt+Wohht-1+bo)
(7)
进而单元状态更新的过程可以表示为:
(8)
ct=ft⊙ct-1+it⊙
(9)
而隐藏状态更新的过程可以表示为:
ht=ot⊙tanh(ct)
(10)
其中,σ(·)是Sigmoid激活函数,⊙表示按位乘法,W和b是权重矩阵和偏置向量。长短期记忆层位于卷积网络层和注意力模块之后,以处理经过局部特征提取和注意力分配的序列数据。通过对序列中的字符进行长期依赖关系建模,LSTM层有助于捕捉DGA域名中的潜在模式,从而提高整个网络的性能。
3.6 输出层
将提取的特征映射到目标任务的预测结果。完成两个任务,判断一个域名是否为DGA域名(二分类任务)和判断一个域名为正常或来自特定算法家族的域名(多分类任务)。
在进行二分类任务时,输出层只包含一个神经元,该神经元使用 Sigmoid激活函数将最后一层的输出映射到(0,1)区间,得到域名为DGA域名的概率:
P(y=1|x)=σ(Whht+bo)
(11)
其中,Wh和bo是输出层的权重矩阵和偏置向量,ht是LSTM层的最终隐藏状态。
在进行多分类任务时,输出层的神经元数量与类别的数量相等,该层使用softmax函数将输出层神经元的输出映射为概率分布:
(12)
其中,Whi和boi分别表示输出层第i个神经元的权重和偏置。模型最终的预测结果就为概率最大的那一类。
4 实验与分析
4.1 实验数据集
本文所使用的数据集由公开的合法域名数据集和DGA域名数据集组合而成。其中合法数据集为Alexa统计的100万个互联网中访问流量最高的网站的域名。DGA域名数据集为360 Netlab发布的42类DGA家族共1 147 770条域名。进一步地,对完整的数据集进行分层采样,即在每个DGA家族以及正常域名内部按比例进行采样,然后将采样的数据合并为训练集、测试集和验证集,三者的占比为7∶2∶1。
4.2 实验指标
在本研究中,选用了以下四项评估指标:平均准确率(Accuracy)、精确率(Precision)、召回率(Recall)及F1值。其中平均准确率的计算方式为:
(13)
精确率的计算方式为:
(14)
召回率的计算方式为:
(15)
F1值的计算方式为:
(16)
在二分类和多分类两种情况下,四项评估指标中TP、FP、TN、FN的含义为:
(1)真阳性(True Positive,TP)。二分类:正确预测为DGA域名的实例数量。多分类:将属于该DGA家族的域名成功预测为该DGA家族的实例数。
(2)假阳性(False Positive,FP)。二分类:将正常域名误判为DGA域名的实例数量。多分类:将其他DGA家族的域名或正常域名错误地归类到该DGA家族的实例数。
(3)真阴性(True Negative,TN)。二分类:正确预测为正常域名的实例数量。多分类:将其他DGA家族的域名和正常域名成功预测为非该DGA家族的实例数。
(4)假阴性(False Negative,FN)。二分类:将DGA域名误判为正常域名的实例数量。多分类:未能将该DGA家族的域名成功预测为该DGA家族的实例数。
4.3 实验环境与参数设置
软件方面,本文的实验在Windows 10系统下进行,使用的Python版本为3.10,使用的深度学习库TensorFlow版本为2.10。硬件方面,实验设备的内存大小为16 GB,CPU为Intel®倕 CoreTMi7-8700K。实验中的各项参数设置如表2所示。
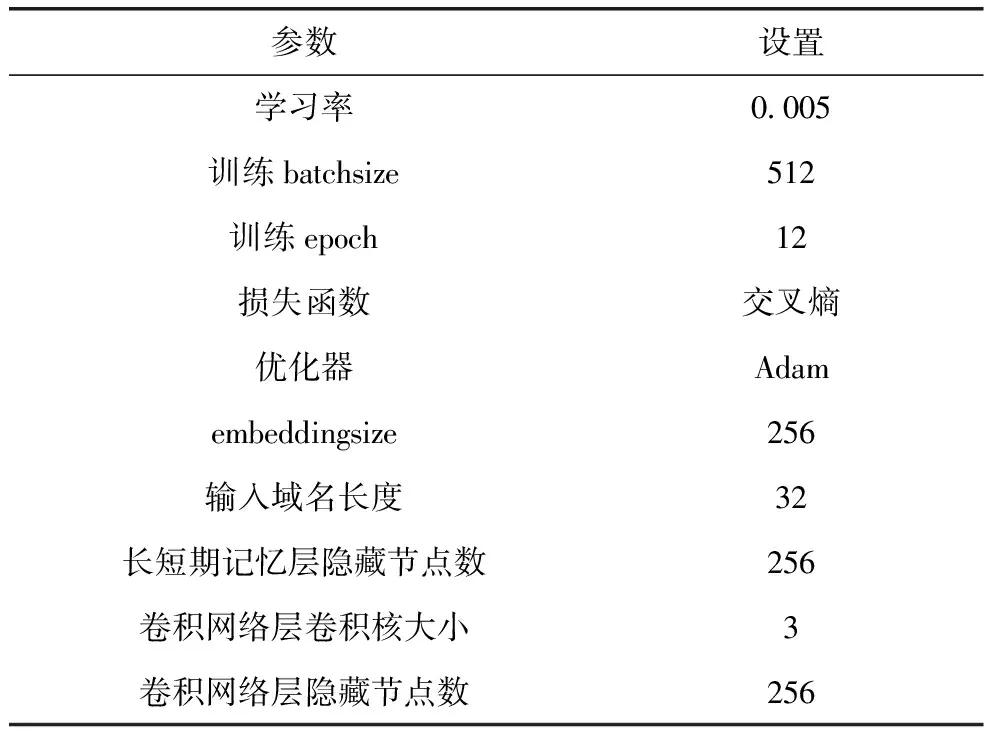
表2 实验所使用的具体参数
4.4 实验结果
实验对比了传统的深度学习网络CNN和LSTM与本文所提出的自注意力特征融合网络在检测DGA域名上的效果。三种网络进行二分类任务时的结果如表3所示。
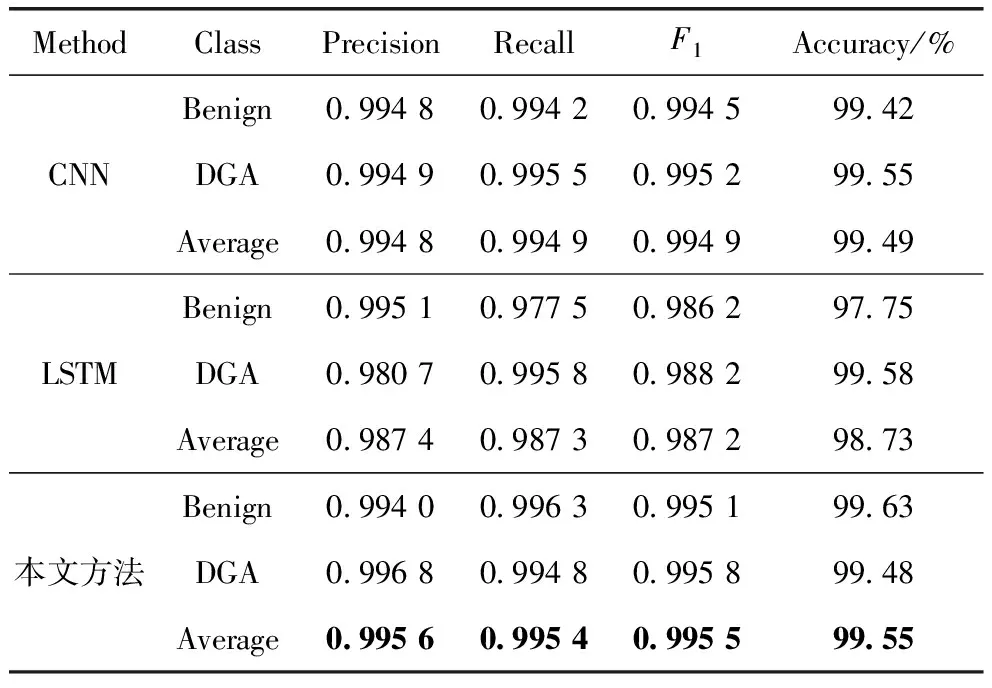
表3 不同方法在判断域名是否为DGA域名时的效果
实验结果表明,本文所提出的方法在所有评价指标上都取得了较高的分数,而且在大多数情况下超过了CNN和LSTM;在平均精度、平均召回率、平均F1分数和平均准确率方面,表现优于其他两种方法;且在识别DGA域名的精度上相比于CNN和LSTM都有较大提升。尽管LSTM在识别DGA域名的召回率上达到了最高(0.995 8),但在识别正常域名的召回率和精度上,LSTM的表现不如其他两种方法,导致其平均表现稍弱。结合前文对DGA域名与正常域名在形式上的差异分析,可以说明本文方法所采用的网络结构能够更好地学习到域名字符序列中局部特征与长距离依赖,有利于当域名中存在大量随机与无规律字符时学习到更加准确的域名表征,从而实现检测效果的提升。
为了直观体现不同架构的网络在泛化能力与学习能力上的差异,进一步绘制了二分类情况下训练过程中不同网络结构的学习曲线,如图3~图5所示。
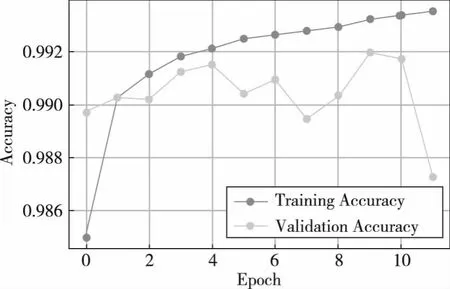
图3 CNN在二分类情况下训练时的学习曲线

图4 LSTM在二分类情况下训练时的学习曲线

图5 本文方法在二分类情况下训练时的学习曲线
可见,随着训练的进行,LSTM在验证集上的准确率与在训练集上的准确率差距逐渐增大,且在第12轮训练时模型在验证集上的准确率已经开始有了下降的趋势,证明网络的性能不仅达到了上限,还即将过拟合,这也说明网络的泛化能力有限,不能较好地学习到域名序列间字符的局部关系。而CNN随着训练的进行,其在验证集上的准确率出现了大幅度的波动与下降,说明模型的泛化能力较差,且出现了较严重的过拟合现象,也说明模型无法学习到字符间的长期依赖关系将导致性能有着较大地下降。而本文所提出的方法随着训练的进行,其在训练集和验证集上的准确率变化都十分平稳,且在验证集上的准确率没有发生下降,说明本模型有着更好的学习能力,能够有效对域名序列中的特征进行学习。
三种网络进行多分类任务时的效果如表4所示。需要说明的是,数据集在去除样本个数少于2的DGA类别后,共有38个不同的DGA类以及1个正常类。其中,表格中在对每一类域名分类时效果最好的方法的结果进行了加粗显示。

表4 不同方法在判断域名所属具体类别时的效果
通过对数据分析,发现本文所提出的方法在所有39类域名中的21类取得了最好的识别效果,在其中的13类上与其他方法同时取得了最好的效果,仅仅在其中5类上的效果落后于其他模型,由此可见本网络在同时检测多类DGA域名时的有效性。结果中的平均F1值为根据各方法在各类域名上的F1值与该类域名在数据集中的占比进行加权平均得来的,可以发现本文方法取得了最好的效果,以此也说明了本文方法在学习域名字符间的局部特征以及长期依赖关系上的有效性。特别需要注意的是,本文所提出的方法不仅能够在CNN与LSTM已有较好检测效果的特定DGA家族(如Necurs、Suppobox和Padcrypt)上实现进一步的效果提升,还能够对CNN与LSTM几乎无法检测的特定DGA家族(如Proslikefan、Matsnu)实现检测,说明本文方法不仅有着更好的泛化性能,还能够学习到传统网络无法学习到的特征。
更进一步地,绘制在多分类情况下不同网络结构的学习曲线,如图6~图8所示。
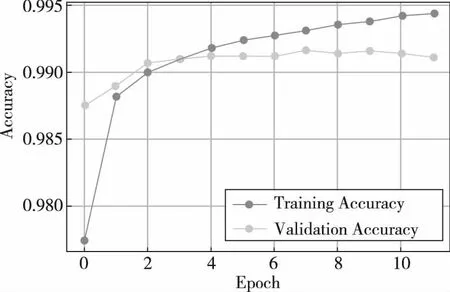
图6 CNN在多分类情况下训练时的学习曲线

图7 LSTM在多分类情况下训练时的学习曲线
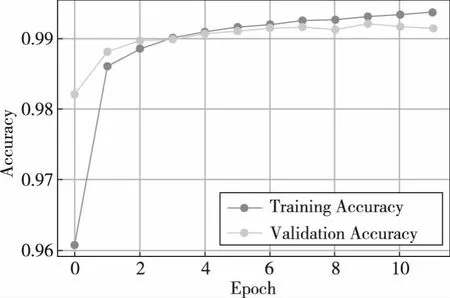
图8 本文方法在多分类情况下训练时的学习曲线
可见,在多分类情况下,随着训练的进行CNN在验证集上的准确性首先平缓上升,然后出现了下降的趋势,说明模型即将过拟合。而LSTM随着训练的进行,在验证集上的准确率上升并不平缓,而是有所波动。虽然其在训练终止时并没有出现过拟合现象,但因其收敛速度过于缓慢,其在验证集上的结果始终都低于另外两个模型。而本文方法兼具收敛快速与泛化能力强的特点,使其随着训练的进行,在验证集上的准确率稳步提升,且没有出现过拟合的现象。
5 结论
本文针对网络安全领域中的DGA恶意域名检测问题,提出了一种基于注意力机制的特征融合网络。该方法结合了Embedding层、卷积神经网络层、注意力模块和长短时记忆网络层,旨在实现更精确和高效的域名分类。实验结果表明,所提出的方法在各项评价指标上均优于传统深度学习方法,具有较强的泛化能力。未来研究将进一步探讨更高效的神经网络结构、结合多源信息以及在实际网络环境中的部署和应用,以实现更全面和实时的DGA恶意域名检测。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
中国教育网络(2018年12期)2019-01-18
少儿美术(快乐历史地理)(2018年7期)2018-11-16
北京航空航天大学学报(2018年1期)2018-04-20
计算机与网络(2018年10期)2018-02-15
中国知识产权(2015年9期)2015-05-30
