
基于YOLOv5s室内目标检测轻量化改进算法研究
2024-03-03 11:21牛鑫宇毛鹏军段云涛娄晓恒
计算机工程与应用 2024年3期
牛鑫宇,毛鹏军,段云涛,娄晓恒
河南科技大学 机电工程学院,河南 洛阳 471003
万物互联的时代悄然到来,物联网技术正在蓬勃发展,对于大多数的物联网移动机器人设备都带有视觉检测功能,以实现更广泛的智能化功能和机器人移动通信[1]。传统的机器学习目标检测算法基于手工提取特征速度慢、精度低[2-4]。随着深度学习的发展,深度学习目标检测算法在特征提取、检测速度、检测效率等方面突破了传统目标检测算法的瓶颈。其中具有两阶段的经典代表算法有R-CNN[5-7]系列算法和具有单阶段的经典代表算法YOLO[8-11]系列算法和SSD[12]算法。这些深度神经网络算法的提出,极大地提高了目标检测的准确性。而大多数算法为了追求过高的精度,不断地增加网络模型的结构,使其模型复杂度和参数量不断上升,然而对于大多数的移动端设备来说如扫地机器人[13]、服务机器人[14]、安防机器人[15]等设备存储空间受到成本因素的影响,无法有效地将复杂的目标检测网络模型应用到小型处理器上进行实时目标检测。因此,对主流的目标检测网络模型结构进行轻量化研究有很强的应用价值。文献[16]采用ShuffleNetv2 轻量化主干网络代替YOLOv5 主干网络,模型复杂度有所下降,且改进模型可对移动设备进行部署,但实验结果精度不高。文献[17]采用MobileNetv3代替YOLOv4的主干网络,引入深度可分离卷积和倒置残差结构模型大小减少37.8%,但是精度在原来基础上损失了0.49%。文献[18]通过在轻量级模型ShuffleNetv2中添加ECA注意力模块,提出了新的骨干网络Shuffle-ECANet。其次,采用BiFPN代替原始特征金字塔网络,提高了网络对特征的描述能力,保证了检测的可靠性,改进的模型比其他方法更小、更轻,更容易植入移动设备中。文献[19]对YOLOv5模型进行优化,并引入注意力机制来增强模型的鲁棒性,改进后的模型更适合在嵌入式设备中部署。文献[20]通过对骨干网络进行实验验证,选出ShuffleNetv2作为模型的轻量化特征提取网络,在网络中添加改进的金字塔结构实现上下文特征的提取能力,并采用EIOU 损失函数加速模型的收敛速度,改进后的算法与原算法相比轻量化效果有所提升。但遗憾的是这些研究设计的模型并没有在检测精度和轻量化之间取得很好的平衡。
本文针对以上问题,提出了以下基于YOLOv5s 的目标检测轻量化改进方法:
(1)在主干网络中,将原来的CSPDarknet53 骨干网络结构更换为ShuffleNetv2[21]轻量化骨干网络结构,该主干网络结构能够显著减少模型的大小和计算资源的需求。
(2)在主干网络末端添加CA[22]注意力机制,该模块能够自适应动态调整注意力权重,更加关注决策过程中有意义的特征,从而提高模型的感知和表达能力。
(3)在颈部网络中,将原来的Conv 和C3 模块替换成轻量化的GSConv和VOV-GSCSP[23]模块,该模块能够综合考虑全局和局部特征信息,更好地捕捉节点的上下文信息。
(4)在算法模型中,将原来的CIOU 更换成EIOU,该损失函数能够直接优化目标检测任务中的IOU,使模型能更准确定位和捕获目标,提高模型目标检测结果质量。
改进后的目标检测模型在保证轻量化的同时,也保证了检测精度。同时满足了室内机器人在作业时对准确性的要求,也能够满足计算能力有限的室内嵌入式机器人设备,从而增加了室内机器人对于室内环境的感知判断能力。为目标检测的轻量化改进提供研究方案。
1 YOLOv5s目标检测算法
单阶段的YOLOv5s 目标检测模型框架来源于YOLO系列的改进结构,由Input、Backbone、Neck、Head四部分构成。模型的输入端模块采用了Mosaic数据增强策略,对输入图像进行随机排列,随机裁剪和色彩调整。通过数据融合增强了背景信息和多尺度目标的检测泛化能力,采用K-means自适应聚类算法可以首先对数据集进行最优锚框值的计算,有效降低了模型计算负担。骨干网络采用CSPDarknet53 框架,该框架结构由Conv、C3、SPPF三部分组成。主干网络中将Conv和C3层进行连接加强特征提取,C3 模块将大小不同的特征分为两部分,一部分向下传递,另一部分通过瓶颈与其他特征相互融合,有效避免梯度消失现象。SPPF 结构通过使用三个最大特征池化层,以加强网络对图像的感受能力和特征信息的分辨能力。颈部网络采用了FPN和PANet 特征金字塔网络结构,FPN 结构将语义特征信息按自上向下路径进行特征融合,PANet 结构将强定位特征从较低的网络层次迁移到较高的网络层。YOLOv5s 的预测部分由三个不同尺度的预测层组成,小尺度检测头适用于检测大目标,大尺度检测头适用于检测小型目标。在对目标检测后进行处理时,通过非极大值抑制处理得到最终结果。YOLOv5 通过改变模型的深度和宽度可以获得四种不同的版本,由大到小分别是YOLOv5x、YOLOv5l、YOLOv5m、YOLOv5s。由于YOLOv5s模型结构的深度和宽度最小使得其网络结构的计算量以及参数量最小,符合本文所研究的实际应用问题。因此本文选择采用YOLOv5s作为本文的初始模型。YOLOv5s网络模型如图1所示。
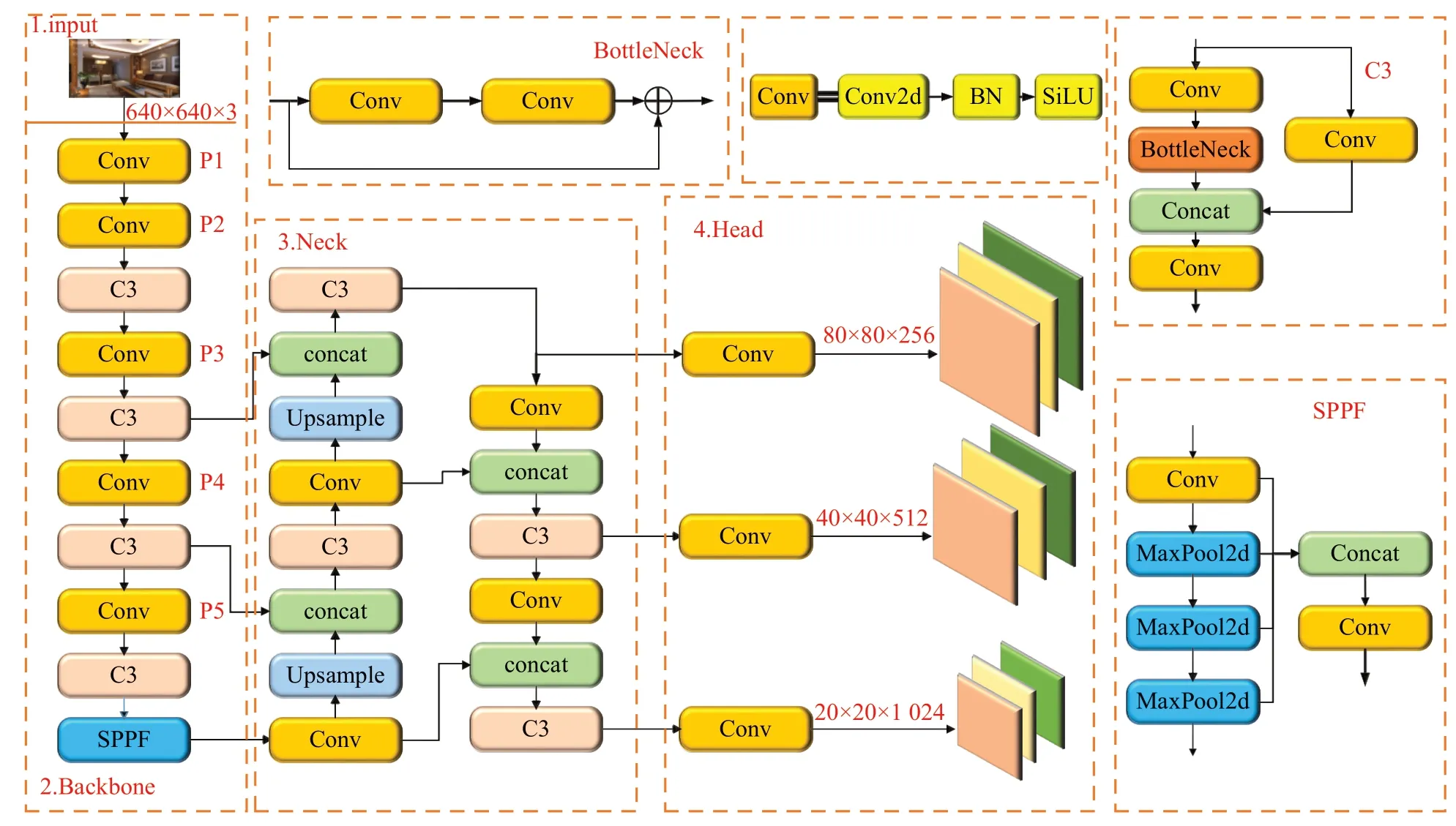
图1 YOLOv5s 网络结构Fig.1 YOLOv5s network structure
2 改进的YOLOv5s算法
虽然YOLOv5s 在不同的目标检测任务中表现出了优异的性能,却难以应对计算能力和储存能力有限的移动端机器人设备或嵌入式设备中并进行部署以及对YOLOv5s 进行轻量化改进后其精度难以保持等问题,对其网络模型进行改进。改进后的模型结构如图2 所示。首先,用轻量化ShuffleNetv2 网络去替代CSPDarknet53网络用于输入特征的提取,极大程度减少了计算量以及模型参数,对整体的网络结构起到了轻量化的作用。然后,在骨干网络中添加注意力机制模块CA,提取图像中的关键信息同时忽略无关信息,能够进行自适应特征融合,在不增加计算量以及模型参数的前提下,有效提高算法检测的精度。其次,在网络的颈部将Conv 卷积和C3 层替换成轻量级的卷积神经网络GSConv和VOV-GSCSP即能在减轻模型计算量和参数量的同时从而提升模型推理速度和精度。最后,通过引入EIOU 边框损失函数,该损失函数考虑到所需回归框之间的向量角度,重新定义了惩罚指标,加速了网络收敛速度。
2.1 轻量化骨干网络
本文将用ShuffleNetv2 轻量化骨干网络代替YOLOv5s 的骨干网络。ShuffleNetv2 网络模型高效且准确。高效率的模型构件可以利用更多的特征通道和拥有更大的网络容量。工作原理如图3所示。Unit1通过Channel Split将特征通道一分为二,左侧特征通道直接向下传递,右侧特征通道经过卷积和批归一化处理,有效减少了每个通道中参数数量且加快了特征提取能力,Concat 模块将左右分支通道特征进行信息融合。Unit2是空间下采样单元,特征图缩减二分之一,维度增加一倍,使用深度可分离卷积可以有效降低参数量和运算成本。将不同特征通道的输入信息进行分组卷积后,输出该通道的特征,将该通道特征信息与其他通道特征信息进行混剪洗牌操作后输出新特征,该操作降低了模型的计算复杂度,大大提高了计算效率。两个单元共同构成了ShuffleNetv2 网络结构,从而实现轻量化特征提取骨干网络模型。
2.2 引入注意力机制模块
人类总能从众多信息中筛选出对当前任务最为重要的信息,注意力机制则起源于人类对信息选择性关注的研究。它使得神经网络在目标检测领域中具有感知适应能力,通过感知每张特征图的重要信息差异来抑制无关信息,提取有用信息。CA 注意力机制与其他注意力机制相比,除了关注通道信息外,还捕获了方位和位置敏感信息。CA注意力模块机制使得特征在融合过程当中可以自动学习每一个特征在融合中的重要性或者权重,从而使得该模块拥有自适应特征融合的能力,权重反映了特征对最终输出的贡献程度。通过对注意力权重的调整,模型能够更加聚焦于重要的特征,并抑制对于结果贡献较小的特征。特征融合能力使得模型能够根据输入数据的不同情况进行灵活的特征选择和融合,提升模型的性能和泛化能力,使模型在目标检测时能够准确定位到感兴趣物体的位置,显著提高了计算效率和检测性能。CA 注意力模型不仅足够地轻量灵活,而且是能够应用到轻量级网络的核心模块。图4是CA注意力模块的工作机制。输入特征任意张量大小为X=[x1,x2,…,xc],其中C、H、W分别为特征图的通道数、高度、宽度。首先,分别为对全局平均池化进行分解,能够有效捕获精准位置信息的远程交互特征,避免了空间信息被压缩到通道中。对于输入特征尺寸C×H×W的特征分别按照公式(1)X和公式(2)Y方向进行池化,在水平和垂直的方向生成zh和zw大小为C×H×1 和C×1×W的特征图。
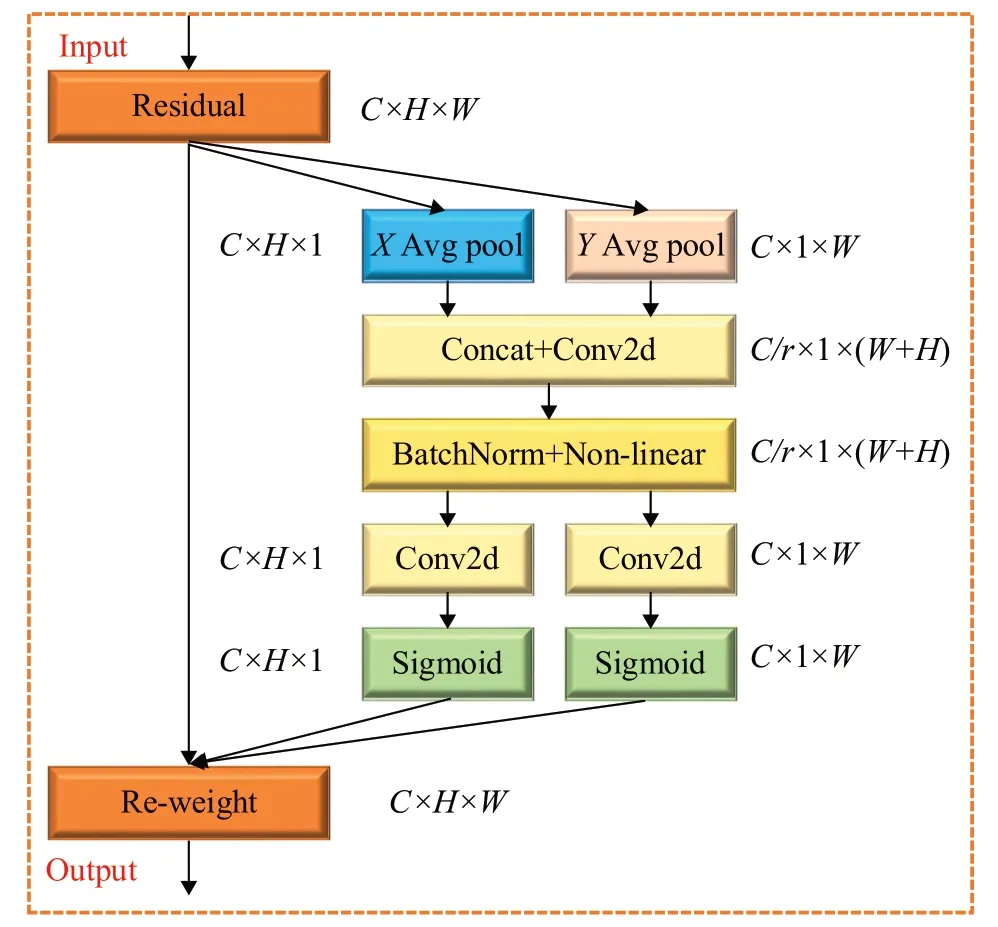
图4 CA 注意力机制模块Fig.4 CA attentional mechanism module
接着将生成的特征图在第三维度中两个带有特定方向信息的特征图进行Concat 操作。再利用1×1 卷积进行降维操作,然后非线性激活函数生成中间特征向量f=R(C/r)×1×(h+w)包含水平和空间垂直信息。其中r为通道过程中下采样比例。沿着空间维度将特征图f进行Split操作,生成两个特征向量f h=R(C/r)×H×1和f w=R(C/r)×1×W。再分别利用1×1卷积进行升维操作后,再结合激活函数Sigmoid 得到的注意力向量gh=RC×H×1和gw=RC×1×W。最后输出特征图与特征权重相乘从而加强了特征表征能力。本文设计了三种不同的嵌入式方法如图5所示,通过对比实验来探究注意力模块在主干网络中嵌入的不同位置对算法精度的影响。
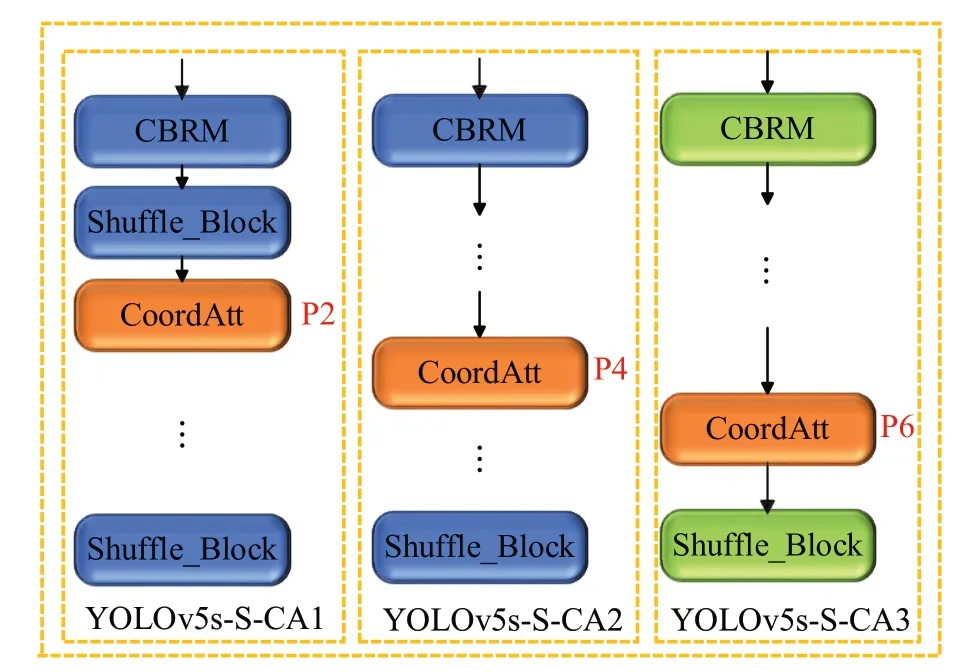
图5 CA 注意力模块位置Fig.5 CA attention module location
2.3 引入GSConv和VOV-GSCSP轻量化模块
GSConv 模块是由标准卷积、深度可分离卷积和Shuffle三部分卷积混合而成如图6的Unit1所示。该模块对标准卷积所生成的特征信息通过Shuffle混合策略渗透到深度可分离卷积生成的特征信息的每一模块中,使得该方法的卷积计算接近于标准卷积的输出,但降低了计算成本。通过添加深度可分离卷积层和Shuffle层增强了特征信息的非线性表达能力,使得GSConv卷积更加适用于轻量化的模型检测器。普通卷积计算量计算公式是式(14),深度可分离卷积计算量计算公式是式(3),GSConv卷积计算量计算公式是式(4)。

图6 GSConv和VOV-GSCSP模块Fig.6 GSConv and VOV-GSCSP modules
W和H分别是特征图宽度和高度;K为卷积核大小,Cin和Cout分别为输入和输出特征通道数。由公式可得到当输入特征通道数越大时,GSConv 卷积的计算量近似为普通卷积的二分之一,但是其特征提取能力却和后者相同。引入GSConv 卷积使得模型复杂度降低。而为了加快模型推理时间并保持精度添加了VOV-GSCSP模块如图6 所示。图6 的Unit2 为VOV-GSCSP 的瓶颈单元结构。图6的Unit3为采用单次聚合方法设计了跨阶段的VOV-GSCSP模块。该模块推理速度快,适合部署到计算量有限的移动目标平台。
YOLOv5s 在颈部采用了C3 模块,其在空间特征融合方面具有一定的局限性,本文通过使用GSConv卷积模块代替Neck中的普通卷积,用VOV-GSCSP模块代替C3层。该模块在降低模型复杂度的同时加快了推理速度和精度。如图7所示,通过在颈部网络中设计不同数量的GSConv和VOV-GSCSP模块来探究该模块对于网络精度以及轻量化性能的影响。

图7 GSConv和VOV-GSCSP模块位置Fig.7 GSConv and VOV-GSCSP module locations
2.4 损失函数改进
目标检测模型损失函数通常由分类损失、定位损失、目标置信度损失三部分加权相加构成网络总损失函数。通常在目标检测算法中采用IOU 作为目标框的位置损失函数,IOU通过预测框和真实框之间的重叠程度进行学习和训练。A 框和B 框重合面积越大则IOU 值越高,模型预测精度越高。反之,IOU 值越低模型预测效果越差。IOU计算公式如式(5):
然而当A框和B框重合面积为零时,不能正确反映两者的距离和重合度大小。YOLOv5s目标检测模型使用CIOU 作为目标框的位置回归损失函数,不仅考虑了重叠程度、中心点距离和纵横比。而且加快了目标框的损失计算和模型收敛速度。但是CIOU 通过参数间接反映纵横比,由于宽高描述是相对的无法准确定位不能真实反应宽高比及置信度。CIOU 计算公式如式(6)~(8)所示:
所以本文引入了EIOU 计算公式(9)作为改进模型的目标框损失函数。EIOU损失函数是在CIOU损失函数基础上得到的。EIOU 损失函数中包含了重叠程度、中心距离损失并且真实反应了预测框和真实框的高度和宽度。EIOU 前两部分与CIOU 相同,第一部分为IOU 的定义预测框和真实框的合与交之比。第二部分为预测框和真实框的欧式距离比上包含预测框的最小外边框与真实框对角线距离的平方。第三部分EIOU将长宽比因子拆分为宽高损失,使预测框与真实框宽高之差的欧式距离除以最小外边框宽高的平方。EIOU损失函数使这些差异最小化,使得目标检测算法收敛速度更快,精度更高。
如图8 所示是EIOU 损失函数回归框,其中A 和B为两个边界框,b、bgt分别为预测框和真实框的中心点坐标,w、h、wgt、hgt分别为预测框和真实框的宽和高。ρ为真实框和预测框中心点的欧式距离,c为预测框与真实框的最小外接矩阵的对角线距离,cw和ch为预测框与真实框的最小外接矩阵的宽和高。α为正权衡参数。ν为衡量纵横比一致性参数。
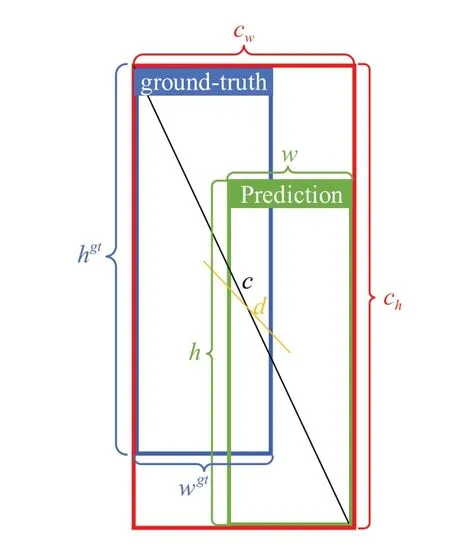
图8 EIOU损失函数回归框Fig.8 EIOU loss for box regression
3 实验与结果分析
3.1 数据集制作
本文以VOC2007 数据集为基础,使用python 脚本文件提取室内常见的九类目标样本作为研究对象,包括了猫(cat)、椅子(chair)、狗(dog)、电视机(TV monitor)、人(person)、沙发(sofa)、瓶子(bottle)、餐桌(dining table)、盆栽(potted plant)等常见的目标组成自制的室内目标检测数据集,本文一共采样了6 624 张图片组成了室内目标检测数据集。按照8∶1∶1 的比例随机划分成训练集、验证集与测试集,表1显示划分好的具体图片数量。

表1 数据集分类Table 1 Dataset classification
3.2 实验环境与评估指标
实验运行环境:操作系统为Windows 10 64位,CPU为英特尔Intel®Xeon®CPU E5-2680 v3 @250 GHz,运行内存32 GB,GPU 为NVIDIA GeForce RTX 3080Ti 12 GB 深度学习框架为Pytorch,训练平台为PyCharm。
本实验所采用的实验参数:epochs为200,batch-size为16,优化器为SGD,Momentum 为0.937,学习率为0.01,输入图像大小为640×640。本实验将采用精确率(P)、召回率(R)、平均精度(mAP)、计算量(GFLOPs)、参数量(Params)作为模型性能的评价指标。精确率和召回率计算公式如式(10)、(11)所示:
其中,TP(真阳性)表示样本被正确划分为阳性样本;FP(假阳性)是指样本被错误地划分为阳性样本;FN(假阴性)是指样本被错误地划分为阴性样本;P和R所围成的面积定义为AP,取所有的检测类别AP 的均值为mAP公式如式(12)、(13)所示。AP 用于衡量某一类精度,mAP用于衡量所有类的平均精度。
计算量(GFLOPs)和参数量(Params)作为网络模型复杂度的评价指标,其计算公式如式(14)、(15)所示:
其中,W和H分别是输入特征图的宽度和高度;K为卷积核大小,Cin和Cout分别为输入和输出特征通道数。
3.3 轻量化骨干网络对比实验
本文在选取轻量化骨干网络时,为保证在室内目标检测数据集上性能最佳,分别对两组轻量化骨干网络进行了对比实验,来说明本文所采用的轻量化骨干网络具有优越的性能。骨干网络的目标检测性能实验结果如表2 所示。MobileNetv3 轻量化骨干网络与原骨干网络相比计算量下降9.5×109,参数量下降4.04×106,精度为0.568。ShuffleNetv2 轻量化骨干网络与原骨干网络相比计算量下降7×109,参数量下降3.24×106,精度为0.571。骨干网络从原始输入图像中提取有用特征,这些特征可以捕获图像的结构、纹理、形状等本质特征。为了使主干网络在提取特征时能够获取更多的有用信息,避免因过度地使用轻量化骨干网络而导致精度的损失。所以本文采用了ShuffleNetv2 轻量化骨干网络,该骨干网络实现了轻量化和精度的有效平衡。该骨干网络模型命名为YOLOv5s-S。
3.4 注意力机制对比实验
为验证CA注意力模块对室内目标检测的有效性以及研究注意力机制在主干网络中嵌入的最佳位置对于算法性能的影响。本文在3.3 节的基础上,对三种不同嵌入方法分别进行了实验,如图5 所示,YOLOv5s-SCA1、YOLOv5s-S-CA2、YOLOv5s-S-CA3。实验结果如表3所示。
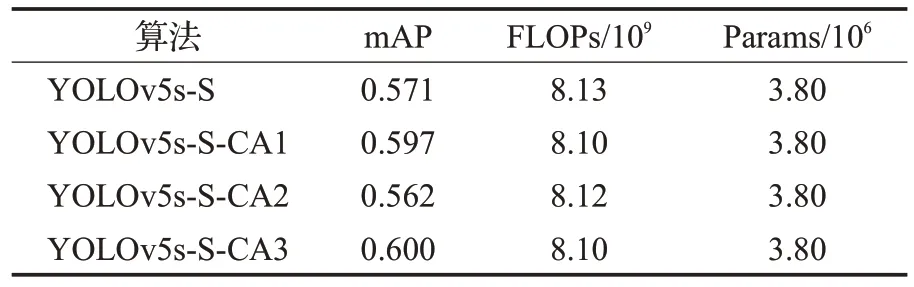
表3 CA注意力机制实验Table 3 CA attention mechanism experiment
结果表明在ShuffleNetv2轻量化网络的不同位置添加CA 注意力模块对模型精度提升具有有效性。其中YOLOv5s-S-CA1 精度略有下降,YOLOv5s-S-CA2 精度提升0.026,YOLOv5s-S-CA3提升了0.029。该实验验证了在ShuffleNetv2主干网络中添加CA注意力对室内目标检测提升精度具有有效性。而且在三种嵌入式方法中模型计算量和参数相似的情况下,第三种嵌入式方法的模型提升精度优于其他两种,所以采用第三种嵌入式网络结构作为本文的改进方案。由上述实验分析可知,在骨干网络中CA注意力机制模块嵌入的位置越往后则精度越高。随着网络的不断加深,特征会变得更加抽象,特征图尺寸会逐渐减小,从而使得CA注意力机制可以利用更多的通道信息来计算通道权重,获得更加广阔的上下文信息。所以CA注意力机制在主干网络中嵌入的位置越往后则可以更好地保留和利用重要特征,使网络更好地适应室内目标检测任务,进一步提高了目标检测模型的精度。为了进一步验证选择CA作为本文的注意力机制模块的有效性,在YOLOv5s-S 结构中分别嵌入CBAM、ECA、SE、CA、四个注意力机制分别进行横向对比实验。实验结果如表4所示。
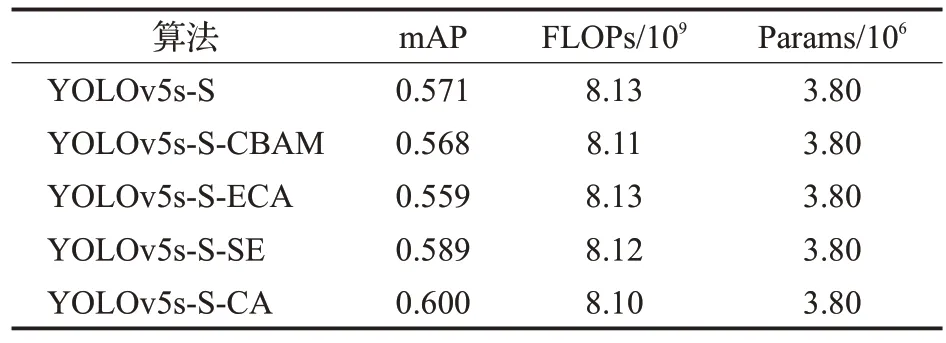
表4 注意力模块对比实验Table 4 Contrast experiment of attention module
通过上述实验分析可知。在骨干网络中嵌入SE和CA 注意力模块使目标检测模型精度分别上升0.018、0.024,ECA 和CBAM 注意力模块使模型精度略有下降。由实验可知,在深度算法模型的骨干网络中可以灵活地嵌入不同类型的注意力机制,这些注意力机制都采用了轻量级的操作,而不会引入太多的额外参数和计算量。由于CA注意力机制使用了全局平均池化来获取通道维数的特征信息,可以采用较少的学习参数来计算通道权重,这使得CA 注意力机制能够具有较低的计算量。所以CA注意力机制与其他注意力机制相比更加轻量化。CA 注意力机制与其他注意力机制相比精度更高,更适用于本文室内目标检测任务。由上述实验分析进一步说明本文选择在骨干网络中嵌入CA注意力机制的优越性。
3.5 引入GSConv和VOV-GSCSP模块对比实验
为了验证GSConv和VOV-GSCSP模块引入后对目标检测模型效果提升的有效性,如图7所示,本文在3.4节基础上对目标检测算法的颈部堆叠了不同数量的GSConv 和VOV-GSCSP 设计提出三种模型YOLOv5s-S-P1、YOLOv5s-S-P2、YOLOv5s-S-P3 将三种算法模型和YOLOv5s-S 算法模型在室内目标数据集上进行实验。结果如表5所示。
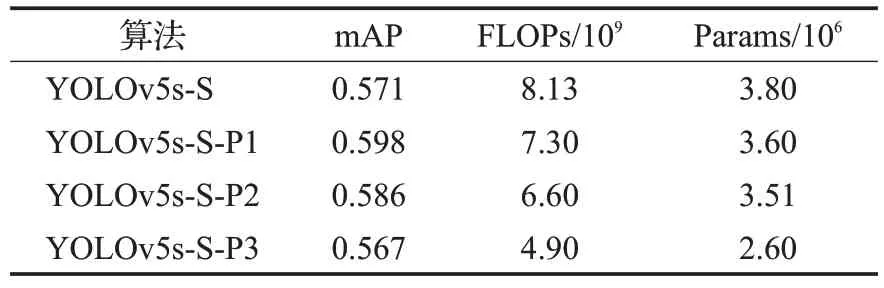
表5 GSConv和VOV-GSCSP模块实验Table 5 Experiments with GSConv and VOV-GSCSP modules
对比表5中添加不同数量的GSConv和VOV-GSCSP模块的实验结果。具体分析为:YOLOv5s-S-P1 相较于YOLOv5s-S,模型检测精度提升0.027,模型计算量降低8.3×108,参数量降低2.0×105。YOLOv5s-S-P2 相较于YOLOv5s-S,模型检测精度提升0.015,模型计算量降低1.53×109,参数量降低了2.9×105。YOLOv5s-S-P3相较于YOLOv5s-S,模型检测精度略有下降,但模型复杂度却降低了3.23×109,参数量降低了1.20×106。实验分析可知,在颈部网络中不断的堆叠该模块,模型的计算量和参数量不断降低,模型轻量化程度不断增强。模型YOLOv5s-S-P1 和YOLOv5s-S-P2 可能是由于堆叠较少的该网络模型而增加了特征的提取能力,模型的精度和轻量化都有所提升。而YOLOv5s-S-P3 可能是由于堆叠了较多的该网络模型,使模型的轻量化程度最佳,而网络模型的深度加深使得模型的精度略有下降。所以,为了在颈部网络中获得极佳的轻量化效果。在选择该模块时,选择了YOLOv5s-S-P3作为颈部网络结构的轻量化模型。
3.6 损失函数对比实验
将本文采用的EIOU损失函数和原来的CIOU损失函数进行对比实验,来验证改进的损失函数在目标检测算法上的有效性。实验结果如表6所示。
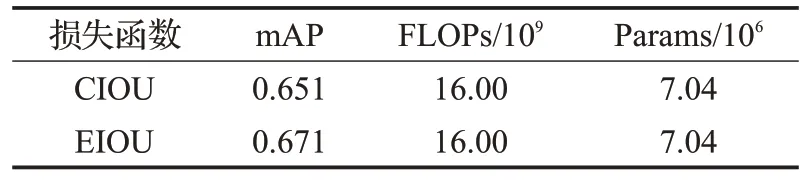
表6 损失函数对比实验Table 6 Loss function comparison experiment
通过对原有算法损失函数的改进进行对比实验,由表6 可得原始CIOU 的mAP 为0.651,而本文提出的EIOU 的mAP 达到了0.671。在其他实验参数相同的情况下,模型的检测精度提升了0.02。图9 为损失函数mAP对比训练图。由图可知分别采用EIOU与CIOU损失函数对模型进行训练时,EIOU 损失函数损失训练精度高于CIOU 损失函数精度,EIOU 损失函数更准确地预测了真实框和目标框的重叠程度,有效提高了模型的计算效率和模型检测性能。说明了EIOU损失函数性能高于CIOU损失函数。所以采用EIOU作为模型的损失函数。
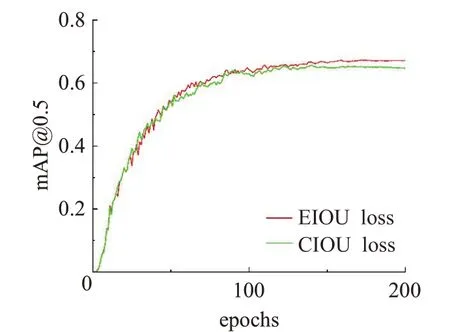
图9 损失函数对比图Fig.9 Comparison of loss function
3.7 消融实验模型
为了验证每一个模块对于改进算法的有效性,对所改进的模块进行消融实验。首先在YOLOv5s的基础上添加ShuffleNetv2 模块。其次在ShuffleNetv2 网络模块中添加注意力CA模块,然后在颈部网络中添加GSConv和VOV-GSCSP 模块,最后采用EIOU 损失函数代替CIOU 损失函数作为改进算法的损失函数,形成最终的改进算法模型。与原始算法YOLOv5s进行对比实验结果如表7所示。
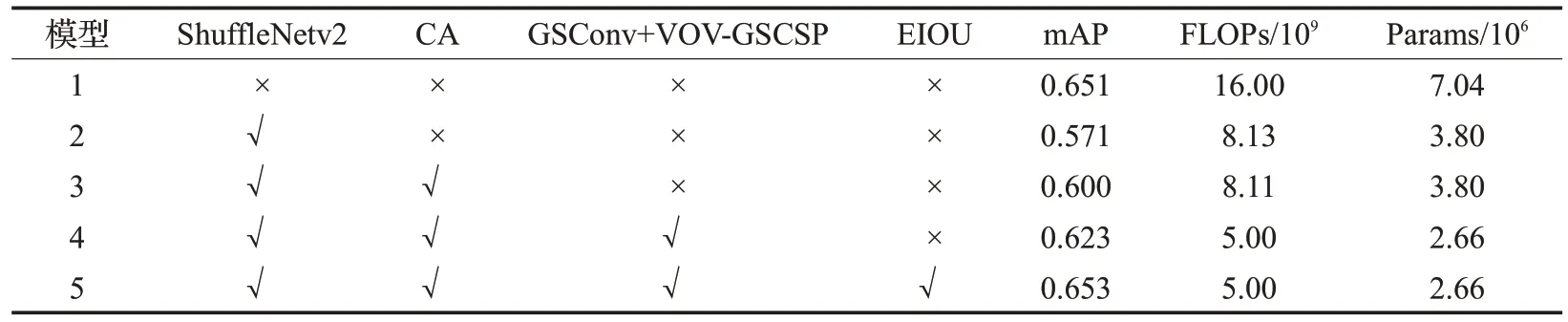
表7 消融对比实验结果Table 7 Results of ablation comparison experiment
从表7实验结果可得,与原始算法相比加入Shuffle-Netv2对网络骨干进行轻量化改进后模型的复杂度和参数量随之降低,满足了轻量化要求。由于对主干网络进行轻量化改进,导致了模型精度下降严重,所以通过添加CA 注意力机制模块,使得模型精度相比序号2 精度提升了0.026,证明在骨干网络中添加CA注意力机制的有效性。模型4 在模型3 的基础上添加了GSConv 和VOV-GSCSP 模块,模型的精度在原来的基础上提升0.23,计算量减少3.11×109,参数量减少1.44×106,证明在颈部网络中引入GSConv和VOV-GSCSP模块既可以提升网络精度,也可以同时减少模型的计算量和参数量。最后采用了EIOU 损失函数,有效提高了模型收敛速度。改进后的网络与原算法相比,精度达到了0.653,改进后的计算量减少到5×109,参数量减少到2.66×106。上述消融实验分析可知,在原算法模型中改进的不同网络模块都表现出优异的性能。
3.8 与其他算法做比较
为验证本文的改进算法相比于其他算法具有优越性,增加权重文件大小作为轻量化评价指标。本文将改进的算法与Faster-RCNN、SSD、RetinaNet[24]、YOLOv3、YOLOv4、YOLOv7-tiny、YOLOv8n 进行对比实验,实验结果如表8所示。
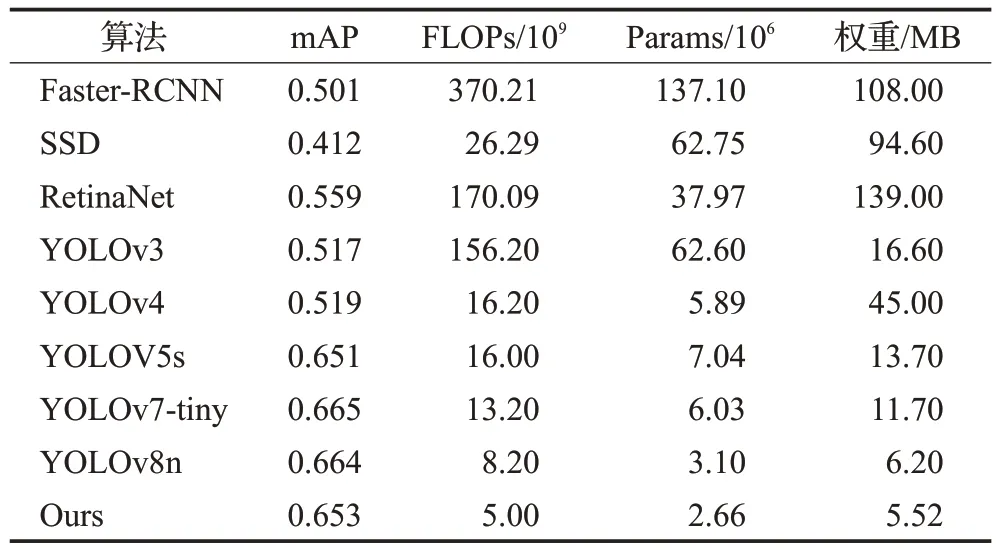
表8 主流算法对比实验Table 8 Comparison experiments of mainstream algorithms
通过对比表8可得,与其他几种算法进行对比实验结果如下。模型Faster-RCNN 的模型检测精度达到了0.501,而本文提出的改进算法精度比Faster-RCNN 高0.152,模型计算量减少3.652 1×1011,参数量减少1.344 4×108,权重减少102.48 MB。模型SSD的模型检测精度达到了0.412,而本文提出的改进算法精度比SSD高0.241,模型计算量减少2.129×1010,参数量减少6.009×107,权重减少89.08 MB。模型RetinaNet的模型检测精度达到了0.559,而本文提出的改进算法精度比RetinaNet高0.094,模型计算量减少1.650 9×1011,参数量减少3.531×107,权重减少133.48 MB。模型YOLOv3 的模型检测精度达到了0.517,而本文提出的改进算法精度比YOLOv3 高0.136,模型计算量减少1.512×1011,参数量减少5.994×107,权重减少11.08 MB。模型YOLOv4的模型检测精度达到了0.519,而本文提出的改进算法精度比YOLOv4高0.134,模型计算量减少1.120×1010,参数量减少3.23×106,权重减少39.48 MB。模型YOLOv7-的模型检测精度达到了0.665。虽然精度略高于本文的改进算法,但是改进的模型相比于YOLOv7-tiny 模型计算量减少8.20×109,参数量减少3.37×106,权重减少6.18 MB。模型YOLOv8n 的模型检测精度达到了0.664,虽然精度略高于本文的改进算法,但是本文改进的模型相比于YOLOv8模型计算量减少3.20×109,参数量减少4.4×105,权重减少0.68 MB。通过上述算法对比实验可知,本文提出的改进算法同时兼顾了精度和轻量化,解决了精度与轻量化无法同时优化的问题。为进一步说明本文改进方法的优越性。与文献[20]改进方法比较计算量减少4.2×109,参数量减少1.35×106,权重文件减少4.58 MB。与文献[25]改进方法相比模型计算量减少4.2×109,参数量减少5.92×106,权重文件减少3.36 MB。与文献[26]改进方法相比模型计算量减少2.6×109,权重文件减少1.11 MB。通过与其他改进方法进行比较充分说明了本文改进方法的显著优势。图10 和图11 为不同的室内目标检测环境。图10中的图片为本文拍摄的真实室内实验室图片,图11 为拍摄的真实室内客厅图片。由图片实验结果可得改进后的目标检测算法置信度值提高,并且改进后的算法漏检率和误检率低于原始模型,改进后的模型检测效果提升明显,验证了改进算法的有效性。

图10 实验室场景图片Fig.10 Laboratory scene picture

图11 客厅场景图片Fig.11 Living room scene picture
4 结束语
本文提出了一种结合ShufflNetv2 的轻量化骨干网络、CA 注意力机制、GSConv 和VOV-GSCSP 模块以及EIOU损失函数的轻量化目标检测模型。改进后的模型能够实现对室内场景中常见目标的精准检测。其中,模型检测精度为0.653,模型计算量为5.0×109减少了68.75%,模型参数量为2.66×106减少了62.2%,权重文件为5.52 MB减少了59.7%。该模型适合于计算能力有限的室内嵌入式机器人设备,同时达到了检测精度和轻量化的有效平衡,可以满足在实际应用部署中轻量化和精确度的需求。下一步工作本文将改进的目标检测算法嵌入ROS移动机器人平台,用于对室内目标的检测,增加机器人对于环境的感知能力。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
专用汽车(2016年1期)2016-03-01
