
自适应特征整合与参数优化的类增量学习方法
2024-03-03 11:21吴永明
计算机工程与应用 2024年3期
徐 岸,吴永明,2,郑 洋
1.贵州大学 省部共建公共大数据国家重点实验室,贵阳 550025
2.贵州大学 现代制造教育部重点实验室,贵阳 550025
当前深度学习模型在完成单一任务(例如语音识别[1]、图片识别[2])方面已经超过了人类水平。但是与能够不断学习和执行连续任务的人类智力相比,这种成功仍然有限。让模型能够具有连续学习能力一直是人工智能领域所面临的难题[3-5]。最近增量学习成为了目前深度学习研究工作中的热点和难点问题。增量学习旨在让神经网络模型适应非平稳且不间断的数据流环境,从而实现更高水平的机器智能。然而,增量学习模型存在灾难性遗忘(catastrophic forgetting),即模型在学习了新知识后,对先前学习过的知识发生遗忘[6-8]。解决增量学习中所产生的灾难性遗忘是人工智能系统走向更加智能化重要一步[9-10]。
针对增量学习中所产生的灾难性遗忘问题,研究人员提出了很多方法。Kirkpatrick等[11]基于贝叶斯概率提出EWC(elastic weight consolidation)算法,该算法通过对旧模型全局参数重要性进行估算,并在新模型训练时对重要参数进行约束。该方法在任务数据关联性较强的数据下表现较好,但在连续图片分类任务中算法性能极剧下降。Li 等[12]利用知识蒸馏与微调方法结合提出LwF(learning without forgetting)算法。该方法首次将知识蒸馏与增量学习结合,通过旧模型训练新模型使得新模型具有旧模型的泛化能力。但在连续任务后期,LwF 依然存在大量知识被遗忘的现象。Rebuffi[13]通过设置额外的内存来保持具有代表性的部分历史任务数据。然而在有数据隐私限制的情况下,这种方法是不被允许的,同时在大数据场景下,保留部分样本对模型性能提升较小。莫建文等[14]利用变分自编码器生成历史任务数据的伪样本,通过新模型对伪样本的学习减轻对旧知识的遗忘。然而,对于复杂的图像数据(如自然图像),训练大型生成模型效率很低。Zhu 等[15]提出PASS(prototype augmentation and self-supervision)算法,该算法通过自监督学习概括和转移连续任务中的数据特征,并在深层特征空间中采用原型增强来维持以前任务的决策边界。吴楚等[16]提出一种任务相似度引导的渐进深度神经网络,该方法通过对比任务间的相似度,并以此对先前任务的参数进行修剪再迁移从而提高算法性能。但在差异性较大的任务之间的相似性表示可能会失效。
本文提出了一种自适应特征整合与参数优化的类增量学习方法(adaptive feature consolidation with parameter optimization,AFC-PO),以缓解在增量式场景下图片分类场景下深度学习模型所产生的灾难性遗忘问题。鉴于增量学习有限的模型容量但需要学习无限的新信息的情景,本文考虑分别对数据特征与模型参数进行处理。因此,模型将知识蒸馏技术作为基础框架,以非样本保留的方式使用数据特征对模型进行迭代训练,同时,限制增量任务模型中重要参数的变化。AFC-PO 包括了自适应特征整合与重要参数优化两个部分。一方面,在自适应特征整合模块,首先对前后任务的模型主干网络的输出特征进行整合,并使用自定义差异损失维护旧任务模型主干网络的特征表示。然后在模型分类层利用输出特征构造具有模糊性的软标签作为语义监督信息,以此吸收先前任务的知识。另一方面,在增量学习阶段有选择地保留或删除知识,即对模型参数重要性进行评价,并在学习新任务时,对重要参数的改变施加惩罚,从而有效防止新模型覆盖于以前任务相关的重要知识。
1 相关描述和问题定义
1.1 类增量学习
在现实世界中,数据是以数据流的形式存在,并且总是受存储限制和隐私约束等问题的制约,导致一些数据不能长时间存储,这使得在数据流中的神经网络模型需要适应时间和存储的变化[17-18]。这要求网络模型在不忘记旧任务知识的情况下学习新知识,以实现模型稳定性和可塑性之间的平衡。对于神经网络模型需要不断学习适应的场景,将它称之为增量学习或者持续学习。其中,连续图片分类任务是增量学习中具有挑战性的任务场景,这种数据类型增量任务被称为类增量学习(class incremental learning,CIL),如图1 所示,在类增量学习中新的类别不断地到来时,模型的输出层需要增加相应的神经元节点,同时,模型需要对已学习过的数据进行分类预测,即在连续任务序列中每一个任务都包含与其他任务不相交的图片类型,模型需要对不同任务阶段学习过的所有图片进行分类。
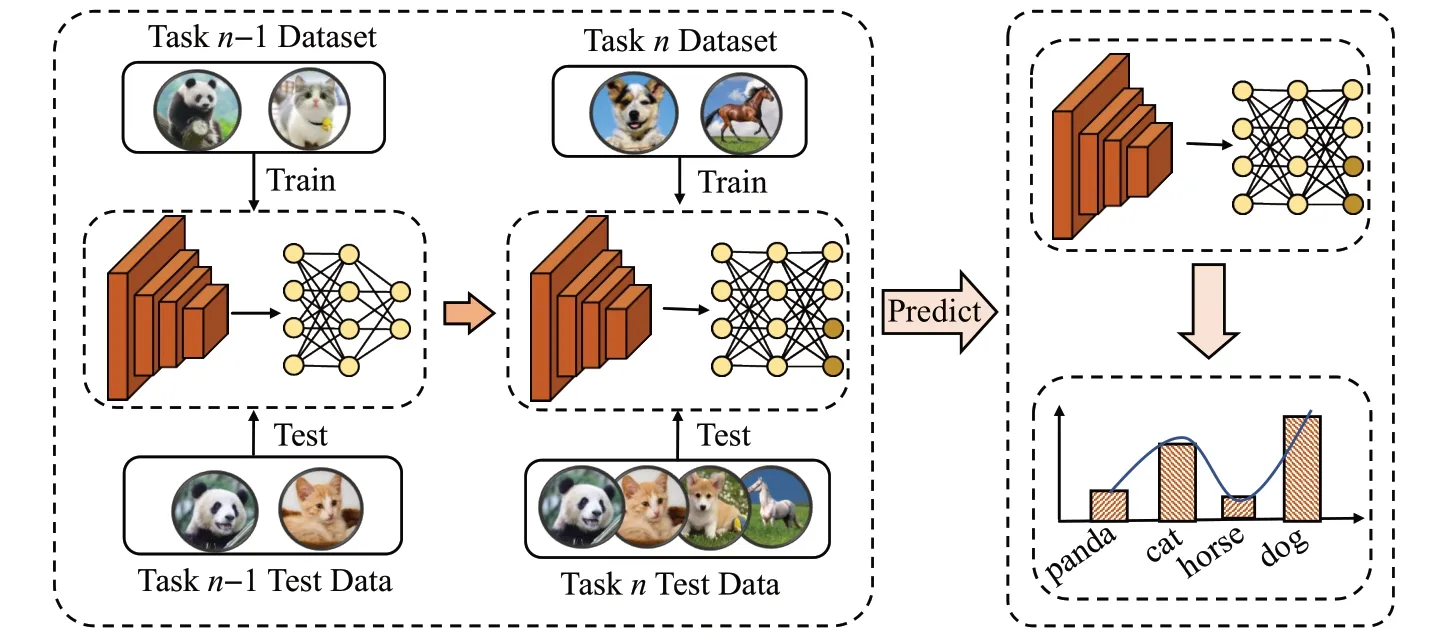
图1 类增量学习流程概括图Fig.1 Overview of class incremental learning process
类增量学习问题定义如下:假设X和Y分别为训练集和标签集。而在连续不断的数据流中,训练集则为X1,X2,…,Xt,其中t表示为增量任务阶段。第i个增量任务阶段的数据集Xi(1 ≤i≤t) 对应其标签集Yi。类增量学习任务序列中每一个任务阶段都包含与其他任务不相交的图片类型,那么可形式化表示为Xi⋂Xj=∅(i≠j)。由于AFC-PO为非样本保留方法,则模型在第t个任务阶段时,前t-1 个阶段的数据不可用,模型只拥有第t个任务阶段的数据集Xt。在一般情况下,在第t个任务阶段模型f t通过主干网络对任务数据特征进行提取,然后通过由全连接网络构成的分类输出层进行分类预测。在本文中使用ResNet作为主干网络,其形式化表达为:
式中,表示第t个任务阶段主干网络ResNet 中的参数,rt表示通过主干网络提取出的特征。模型分类输出层通过全连接网络将数据特征rn映射为其所属类别。那么由全连接网络构成的分类输出层的映射关系可表示为:
式中,表示第t个任务阶段分类输出层全连接网络中的参数,ct表示通过模型输出的结果。结合上述式(1)、式(2)可以获得在第t个任务阶段模型f t的映射关系:
1.2 知识蒸馏框架
知识蒸馏旨在将知识从预训练模型(即教师模型)转移到目标网络(即学生模型),从而实现更好的泛化性能。在类增量学习的场景下,旧任务模型通常被视为教师模型,则新模型被视为学生模型。在增量学习阶段,新模型需要继承旧模型参数作为模型的初始参数开始训练。
在增量学习中,研究人员提出了很多基于知识蒸馏的方法。iCaRL[13]保留一部分历史样本,并联合蒸馏损失与交叉熵损失让模型在保留旧类别区分能力的基础上,具备区分新类别的能力。UCIR[19]通过最大化教师模型和学生模型嵌入的特征之间的余弦相似性来解决遗忘问题。另一方面,LwM[20]最小化旧任务中输出层得分最高的类与主干网络所提取特征的差异,以此缓解模型主干网络特征表示的显著性变化。
之前的大部分工作都是联合蒸馏损失和交叉熵损失构造损失函数。与此同时,大部分研究都会使用独热(One-Hot)标签作为监督信息[21-22]。然而大部分情况下,一个样本不是严格属于某个类别。数据标签中含有丰富的语义信息,所以真实数据标签表示的是样本隶属于各个类的可能性。因此本文将不单独使用独热标签,而是通过对旧模型分类输出层的特征(软标签)与独热标签进行处理,构造具有模糊性的软标签作为语义监督信息。其次,对前后任务的模型主干网络部分构造差异损失,并将前后模型主干网络的自适应特征进行整合,以此维护旧任务模型主干网络的特征表示。
2 算法描述
针对增量式场景下图片分类场景下深度学习模型所产生的灾难性遗忘问题,提出一种自适应特征整合与参数优化的类增量学习方法。在本章中,首先基于知识蒸馏模型框架提出了一种自适应的特征整合方法,以防止前后模型在主干网络和分类输出层出现显著性变化。一方面,自适应的特征整合方法在主干网络根据前后模型的主干网络输出特征构造差异损失,并将旧模型与新模型的主干网络特征整合。同时,在分类输出层通过旧模型输出的软标签与独热标签通过Softmax进行整合,构造具有模糊性的软标签作为语义监督信息。另一方面,提出了参数优化方法,在知识蒸馏框架的基础上,对参数的重要性进行评价,对重要参数的改变施加惩罚,从而有效防止新模型覆盖与以前任务相关的重要知识。
2.1 自适应特征整合方法
类增量学习需要具备识别已知类别和新增类别的能力,同时,知识蒸馏模型框架具备将知识从旧任务模型转移到新任务模型的能力。因此本文考虑把知识蒸馏作为基础框架,如图2 所示,在第n个任务数据到来时,首先,数据通过第n-1 个任务阶段模型分别获得当前数据在旧模型上主干网络与分类输出层的表征信息,然后,利用自定义差异损失与蒸馏损失对当前模型进行训练。自适应特征整合方法(AFC)通过对前后任务网络模型的主干网络和分类输出网络特征进行处理,以此缓解新模型对旧知识的遗忘。
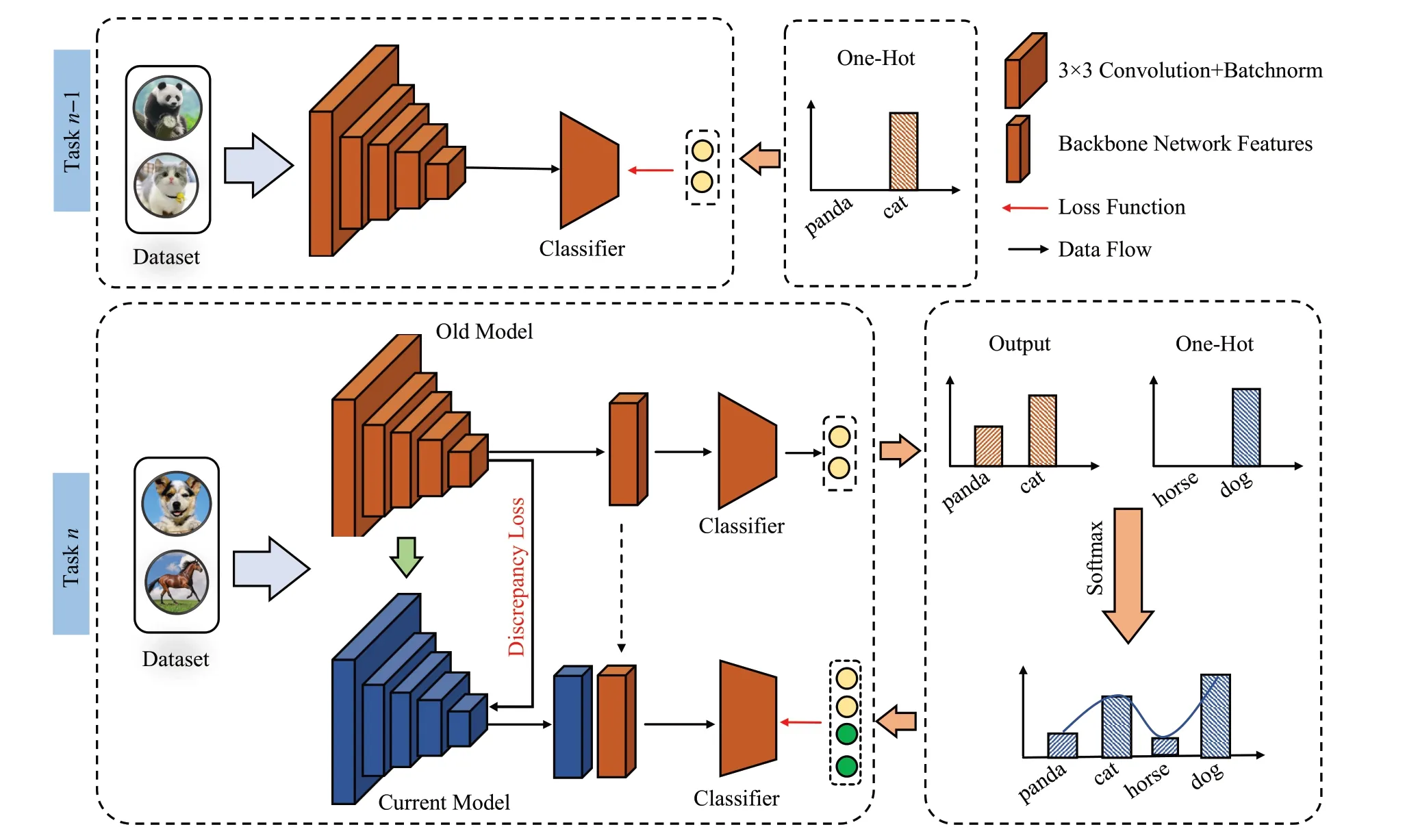
图2 自适应特征整合方法流程图Fig.2 Adaptive feature integration method process
具体而言,当模型在第t个任务阶段时,主干网络部分根据当前阶段模型与t-1 阶段模型对当前数据集Xt进行特征提取,那么两个阶段模型主干网络提取到特征分别为rt-1与rt。本文为使前后两阶段的特征差异尽可能小,从而防止模型出现显著性变化,因此利用L2范数构造特征差异损失:
其中,n表示在第t阶段模型数据集的样本数量。基于知识蒸馏框架造特征差异损失使得新模型特征进行自适应调整。同时,t-1 阶段模型主干网络的输出特征rt-1具有更多的旧模型视觉语义信息,因此考虑将rt-1与rt进行整合,其形式化表示为:
式中,Rt表示为整合后的特征。Rt通过分类输出层进行预测分类,以此维持分类输出层的决策边界。
在特征分类层,将当前阶段数据集Xt输入到t-1阶段模型中,模型输出分类特征ct-1。尽管t-1 阶段模型无法对t阶段数据进行分类预测,但是其输出分类特征ct-1具有丰富的视觉语义信息,即ct-1可以理解为当前数据Xt在旧模型中隶属于t-1 阶段已知类型的可能性。同时,模糊性是数据普遍存在的一种特性。大部分情况下,一个样本不是严格属于某个类别。因此利用当前阶段任务数据的One-Hot 标签ht与t-1 阶段模型分类特征ct-1进行整合,并通过Softmax 构造具有模糊性的样本数据软标签,其形式化为:
其中,zt表示第t个任务阶段One-Hot标签ht与t-1 阶段模型分类特征ct-1进行整合的结果,m表示当前阶段已知类型和新增类型的数量,表示通过Softmax函数后第i个类型的可能性。通过式(5)获得具有模糊性的软标签st作为语义监督信息,因此本文希望数据Xt通过新模型获得预测结果与软标签st尽可能接近,使模型具有旧模型的泛化能力,从而保证模型对已知的类型不发生遗忘。因此,基于和st的损失函数可以通过知识蒸馏形式化为:
模型通过对前一阶段模型具有视觉语义的输出特征的学习能够让新模型吸收先前任务的知识。总体而言,在第t个任务阶段,自适应特征整合方法对模型训练的损失函数为式(4)和式(7)的结合:
式中,λ为两项的调节因子超参数。
2.2 参数优化方法
在自适应特征整合方法中,本文所提方法对数据样本在前后阶段模型各部分的特征进行了处理。而在参数优化方法(PO)中将关注于增量学习过程中模型自身的参数变化。该方法对模型中每个参数的重要性进行评价,并对重要性高参数的变化施加惩罚。从而有效防止新模型覆盖与以前任务相关的重要知识。
具体而言,当模型在第t个任务阶段时,为度量模型中每个参数的重要性,需要对t-1 阶段模型参数进行保留,因此参数优化方法同样也是基于知识蒸馏框架。如图3所示,该方法通过观察前后模型参数的变化程度对模型的影响,从而判断参数的重要性。首先,利用微分性质测量模型f t在学习数据Xt后模型参数变化程度,那么可近似表示为:
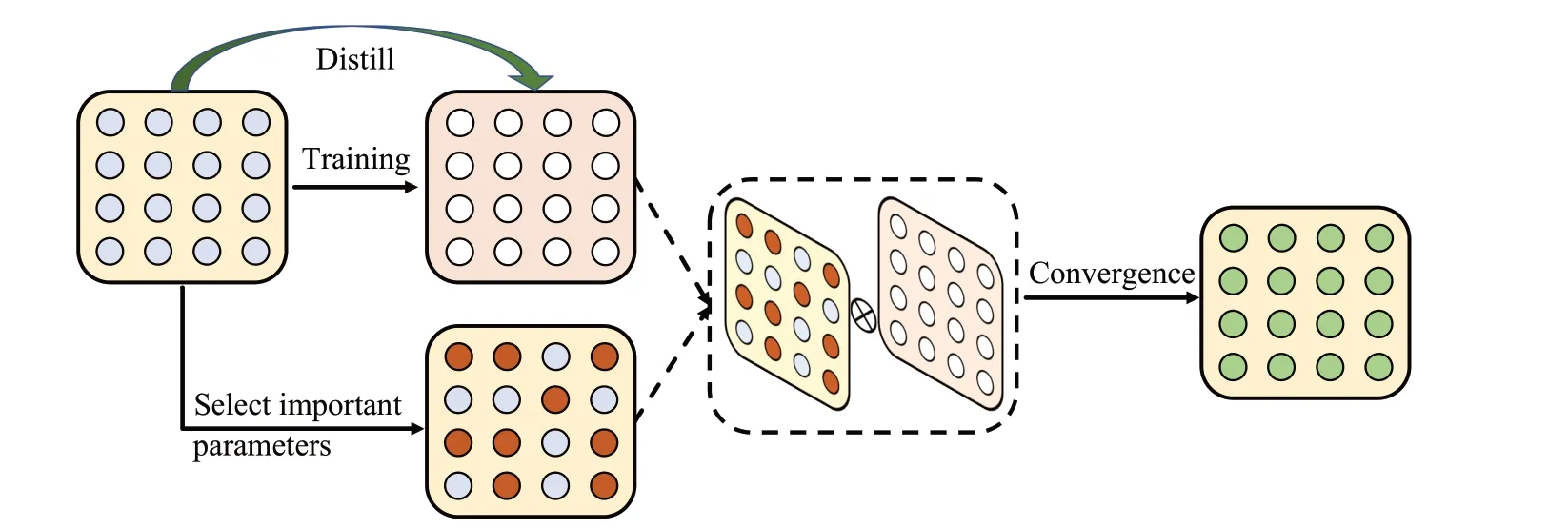
图3 参数优化方法概括图Fig.3 Overview of parameter selection methods
其中,dij表示前后模型参数的变化量,形式化描述为,gij表示在数据样本Xt上模型参数的梯度。如果梯度gij在当前数据样本中的值越大,则说明与其对应的参数对当前模型的越重要。在模型训练过程中,不是一次性训练完所有的数据,而是将数据分成不同批进行训练。所以参数对应重要性评价可以利用δij表示:
式中,b表示不同的数据样本批次,N表示为总批次数量。通过上述式子可以获得对模型全局参数的评价,对重要参数的变化进行惩罚。然而,本文所提模型仅对重要程度高的添加惩罚项,那么在PO 方法中采取对大于平均评价值的参数进行惩罚,其形式化描述为:
根据式(10)、式(11)可以获得模型参数的重要性评价,利用l2正则对重要参数进行限制。同时结合自适应特征整合方法可以得到本文所提算法的损失函数:
其中,λ与μ为调节因子超参数,λ与μ通过后续实验给出。
综上所述,为缓解类增量场景中所产生的灾难性遗忘,本文提出了一种自适应特征整合与参数优化的类增量学习方法(AFC-PO),根据上述算法表述以及损失函数得到AFC-PO算法,其具体实现步骤如下:
算法1AFC-PO算法
3 实验结果与数据分析
3.1 数据集及评价指标
本文实验部分在两个基准数据集CIFAR-10 和CIFAR-100上进行实验验证,这两个数据集被广泛用于持续学习中。CIFAR-10有10个类别的RGB彩色图片,包含50 000张训练图片和10 000张测试图片,且每个图片尺寸均为32×32。CIFAR-100包含来自100个类别的60 000张32×32彩色图像样本,其中50 000张作为训练样本,10 000张作为测样本,其图片尺寸大小与CIFAR-10 相同。为了模拟增量学习任务,本文随机将数据集CIFAR-10和CIFAR-100图片分别分成多个任务数据集,并且每个任务数据类型都与其他任务的数据类型不相交。
在算法评价方面,使用了持续学习中常用的模型评估指标[23],平均准确度和模型遗忘度。
(1)准确率
平均准确度是在新任务学习完成后,模型对先前所有学习过的图片类型预测准确度的平均值,其形式化表达如下:
式中,acct,i为任务t时第i类的准确率,kt表示任务t时的数据类型数目。平均精确度显示了模型在整个持续学习过程中整体性能。
(2)遗忘率
遗忘率则是展现了增量学习算法的稳定性[24]。对于第t个任务的遗忘率的量化形式如下:
其中,较低意味着模型在任务t时,对第i类数据的遗忘程度较小。在任务t时的总体遗忘率需要通过对模型学习过的任务数量进行归一化:
3.2 实验设置
本文主要选取以下代表性方法作为对比方法进 行实验验证与结果对比。基于正则化策略方法((EWC[11]、SCP[21])、基于知识蒸馏的方法(LwF[12])、基于自监督原型增强的方法(PASS[15])、基于回放策略的方法(ICaRL[13]),以及使用微调(Finetune[23])方法作为基线(Baseline)方法进行对比实验。同时,对本文所提方法中自适应特征整合方法和参数优化方法进行消融实验。
本研究提出的AFC-PO模型设置如下:在模型设置方面,与大多数工作相同[12-13,15],本文使用ResNet-18 作为主干网络,ResNet-18 表征学习模块最后展开维度为256,同时,将两层全连接网络作为分类输出层。使用Adam 优化器最小化目标函数,其中初始学习率设置为0.001,权重衰减率设置为0.000 5。模型在100个周期后停止训练,数据批量大小设置为64。
在损失函数的调节因子超参数设置方面,为使模型适应于增量学习,防止灾难性遗忘,本文对调节因子超参数λ和μ进行了实验研究。CIFAR-100 数据集上将图片按类型分为5个增量任务,即20种类型图片为一个任务。将5个增量任务完成后对模型进行测试,实验结果如图4所示,从图中可以观察到,当调节因子超参数μ为0.1时,算法精度较高且较为稳定。将参数μ固定,观察λ对算法精度的影响,可以发现当λ为100,模型平均正确率表现达到最高。实验结果表明知识蒸馏方法对模型精度影响较大,即AFC-PO算法对超参数λ更敏感。
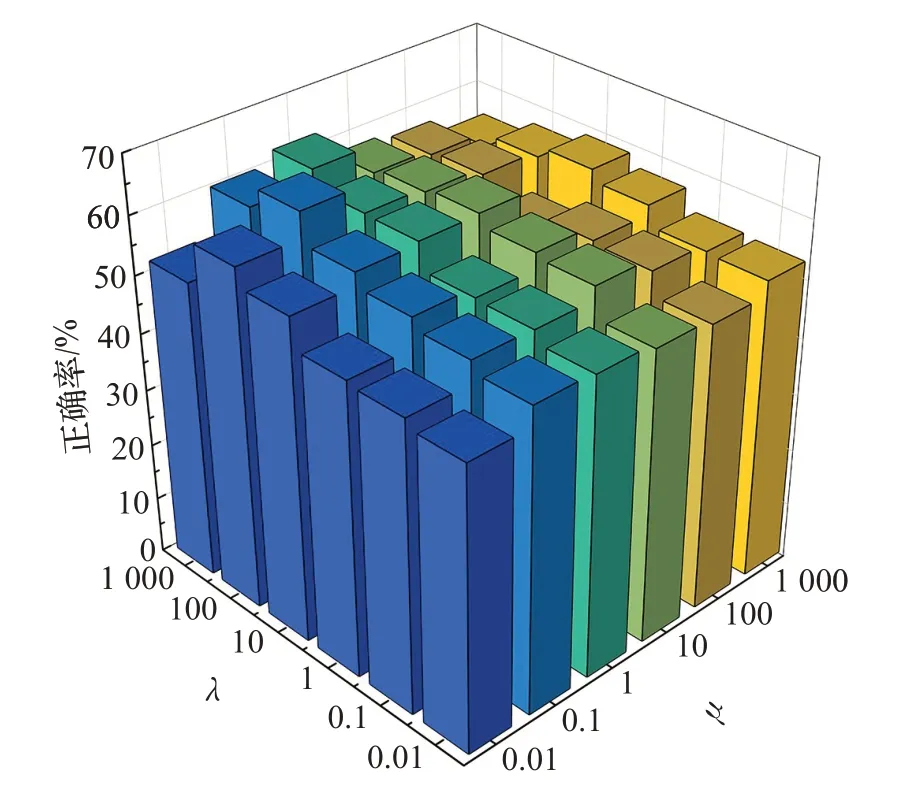
图4 不同λ 和μ 对AFC-PO模型正确率的影响Fig.4 Effect of different λ and μ on correct rate of AFC-PO model
3.3 消融实验
为验证所提方法中自适应特征整合方法(AFC)和参数优化方法(PO)的有效性,本文选择在CIFAR-10数据集上进行了消融实验。CIFAR-10数据集上将图片按类型分为5个增量任务,在每次增量任务结束后对模型进行测试。实验结果如表1 所示,实验中将FineTune[23]方法作为基线方法,PO 方法与AFC 方法的平均分类准确率相较于FineTune 分别提升9.17 和17.54 个百分点。而将两者组合,即AFC-PO 方法,其平均分类准确率相较于FineTune 提升31.93 个百分点。实验证明,本文所提的AFC-PO方法对数据特征和模型参数进行处理,能够有效地降低灾难性遗忘的影响。
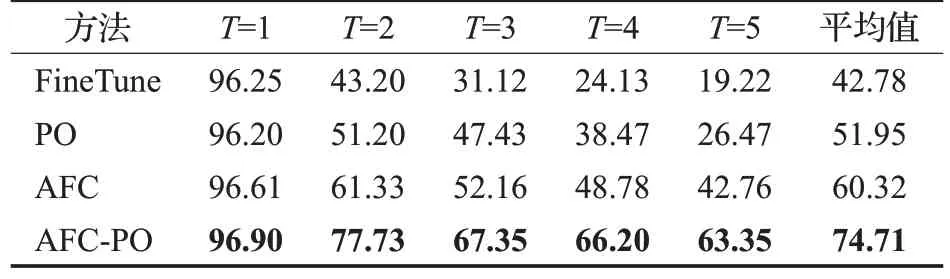
表1 消融实验结果Table 1 Results of ablation studies 单位:%
3.4 对比实验
连续图像分类任务在CIFAR-10和CIFAR-100的平均准确率对比实验结果如表2 所示。在此实验中将数据按类型平均分为5 个增量任务。本文对最好的对比实验结果都进行了加粗。根据实验结果可以发现,相较于其他方法,AFC-PO方法在增量学习任务中取得了显著优异的结果。在CIFAR-10数据集中的连续任务阶段(从第二个任务阶段开始),相较于目前先进的PASS 方法,AFC-PO分别提升3.45、11.57、15.18、9.22个百分点;在CIFAR-100数据集中分别提升了0.50、0.64、1.71、0.35个百分点。在两个数据集中,平均准确率分别提升9.22、0.18个百分点。而相比于基于数据回放的ICaRL方法,通过实验结果可以观察到ICaRL 在大型数据集上的效果较差。由于CIFAR-100类型较多,导致保留的各类型数据样本过少,从而使得保留样本对模型性能提升杯水车薪。而AFC-PO 方法明显优于数据回放的ICaRL 方法,这表明AFC-PO方法可以有效地缓解类增量学习中所产生的灾难性遗忘,而无需存储旧的训练样本。AFC-PO方法在使用知识蒸馏方法的基础上,对历史任务数据的深层视觉语义特征进行自适应特征整合与学习,以此吸收先前任务数据特征的知识,同时对历史模型重要参数选择性的优化,这使得AFC-PO的算法性能表现更加优越,同时表明了算法较强的可塑性,能够有效缓解灾难性遗忘。
为验证算法模型对历史任务的记忆程度,本文在CIFAR-100 数据集上对每个增量任务阶段模型训练完成后对任务1 的测试数据进行测试,测试结果如图5 所示。AFC-PO方法在第五阶段模型对任务1数据的测试准确率达到57.55%,相比于PASS方法增加了8.45个百分点。实验表明本文所提的AFC-PO 方法相较于上述方法对历史任务知识的记忆能力有显著的提升。AFCPO 方法能够吸收先前任务的知识,从而使得模型对旧任务知识的记忆程度更高。
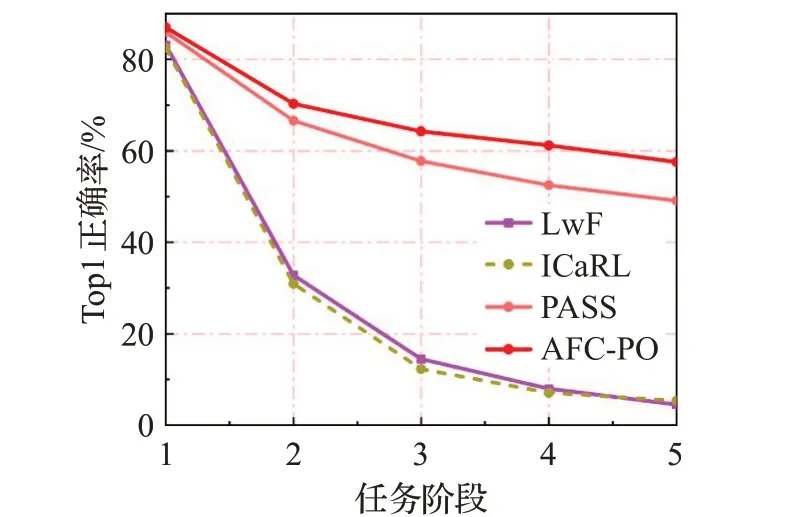
图5 不同增量阶段模型对任务1测试准确率(CIFAR-100)Fig.5 Accuracy of different incremental stage models for task-1 testing(CIFAR-100)
如表3、表4 所示,为了验证本文所提的AFC-PO 方法模型的稳定性,在数据集CIFAR-10 和CIFAR-100 上进行了遗忘率对比实验。实验结果表明AFC-PO 方法在遗忘率方法明显优于其他方法,证实了AFC-PO方法有更好稳定性。在数据集CIFAR-10和CIFAR-100的第5 个任务阶段,AFC-PO 比ICaRL 遗忘率分别提高了12.22 和56.89 个百分点,这表明AFC-PO 方法能够应对连续的复杂图像任务,并且保持对旧知识的记忆。

表3 CIFAR-10上各阶段模型的遗忘率Table 3 Forgetting rate of each stage on CIFAR-10 单位:%

表4 CIFAR-100上各阶段模型的遗忘率Table 4 Forgetting rate of each stage on CIFAR-100 单位:%
图6 显示了LwF、ICaRL 和本文所提出的AFC-PO方法通过混淆矩阵进行比较。对角条目表示正确分类结果,非对角条目表示错误分类结果。由于在新任务训练时,新旧数据类型之间的严重不平衡,如图6(a)、(b),LwF与ICaRL倾向于将数据样本分类为新类。而AFCPO(图6(d))能够消除大部分类增量学习不平衡所带来的影响,并在不依赖旧类的存储数据的情况下获得更好的算法性能。
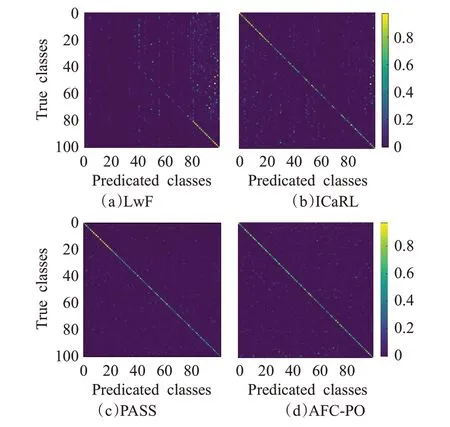
图6 CIFAR-100上混淆矩阵对比图Fig.6 Comparison of confusion matrix on CIFAR-100
综上所述,自适应特征整合方法和参数优化方法维护模型在稳定性与可塑性之间的平衡。AFC-PO 方法则采用非样本保留方法,在实验中获得了显著的实验效果,能够有效缓解持续学习中的灾难性遗忘问题。
4 结束语
针对深度网络模型在连续图片分类任务中所产生的灾难性遗忘问题,本文提出一种自适应特征整合方法和参数优化(AFC-PO)方法,该方法以知识蒸馏技术作为基础框架,以非样本保留的方式对模型进行训练。AFC-PO 方法首先对前后任务的模型主干网络的输出特征进行整合,并使用自定义差异损失维护旧任务模型主干网络的特征表示。同时,在模型分类层利用输出特征构造具有模糊性的软标签作为语义监督信息,以此吸收先前任务的知识。此外,在增量学习阶段有选择地保留或删除知识,即对模型参数重要性进行评价,并在学习新任务时,对重要参数的改变施加惩罚,从而有效防止新模型覆盖与以前任务相关的重要知识。并在CIFAR-10 与CIFAR-100 上进行了实验验证。在实验中与具有代表性的方法相比,AFC-PO能够有效地缓解灾难性遗忘。在将来的工作中,计划将进一步评估AFC-PO模型在更多数据集上的可行性,同时关注于历史任务模型内部的参数之间变化对模型遗忘程度的影响。
猜你喜欢
军事文摘(2024年2期)2024-01-10
当代陕西(2022年6期)2022-04-19
广东教育·高中(2022年1期)2022-03-16
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·中考版(2019年9期)2019-11-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电信科学(2016年9期)2016-06-15
新课程研究(2016年21期)2016-02-28
