
中文纠错任务为例的数据集增强质量评价方法
2024-03-03 11:22谢振平
计算机工程与应用 2024年3期
宋 程,谢振平,2
1.江南大学 人工智能与计算机学院,江苏 无锡 214000
2.江南大学 江苏省媒体设计与软件技术重点实验室,江苏 无锡 214000
近年来,随着互联网相关技术的快速发展,多种多样的数据正在大量的产生。与此同时,大量先进的机器学习相关研究对数据的要求也越发增大,并且数据质量对训练模型的准确性和泛化能力有着重要影响,因此获取高标准的数据质量的重要性已得到从业者和研究人员的广泛认可。其次,要获取与任务相关并且可靠的训练数据主要依靠专家或雇佣工人。但是使用这种方法存在一些问题,因为越先进的系统对训练数据规模的要求也越大,而大规模的数据往往伴随着高昂的人工成本。所以对于如何生成与任务相关并能够有效提升模型效果的数据集,数据增强被认为是一种有效的方法[1]。但是通过数据增强方法构建有效提升模型性能的增强数据集,现有的方法主要还是通过模型训练进行筛选,使用这种方法存在一定的局限性,比如多次训练模型的时间成本过大、模型性能对测试集数据分布的偏向性等问题。因此,评估增强数据集质量对于训练出高质量的机器学习模型有着重要研究意义。
早期数据质量的评估主要通过领域专家以定性的方式为不同场景下的数据定义多维度的指标。Alizamini等人[2]将数据质量评估结果和使用者的需求相关联起来,在满足所提出的指标的情况下的高质量数据能够在使用时发挥更高的价值。Wang 等人[3]将信息在系统设计中预期用途作为分析数据质量的方法,由于系统的设计服务于用户,因此将用户的观点定义为数据质量的标准,进而总结出了最常引用的26个质量维度,而对于这些指标并没有进一步提供具体量化的方法。
随着人工智能的快速发展,通过深度学习模型提取数据的特征来进行质量评估逐渐变成一种主流的方式。Wu等人[4]提出了两种多样性的优化算法用于众包场景下的数据收集,分别是相似度和任务驱动模型,但这两种模型并未考虑内在质量对数据集的影响。李安然等人[5]提出了一个面向特定任务的针对大规模数据集的具有高效可解释性的质量评估系统,该系统可以通过对数据集内在质量和上下文质量评估来为特定的机器学习任务挑选多个高质量数据集,但这种方法却没有考虑数据集对整个高维空间的覆盖程度。Kang 等人[6]针对对话系统中众包数据收集过程中无法确定数据内在质量提供了明确的建议,提出了多样性和覆盖度两种指标用于评估数据的质量,但对于评价指标没有给出一个合适的计算方法。Chen 等人[7]提出了一个包含质量标准及其相应的评价方法的数据质量评估框架,通过所提出的三个指标全面性、正确性和多样性来量化分析医学概念规范化的数据集,但是并未考虑结合不同维度的结果进行解释分析。Taleb 等人[8]提出一种处理非结构化大数据质量评价的模型,该模型主要是使用文本挖掘技术来获取有用的信息进行评估其质量,最后对样本数据运行评估算法,构建质量报告,但该模型并没有给出具体的案例分析。Xiao等人[9]提出一种以多样性为驱动的不确定数据收集框架,通过数据空间中数据噪声的分布来构建出一个综合模型用于完成数据的收集,但考虑的因素单一,并不能获取有效的高质量数据集。
综上所述,目前的工作对于数据集质量评估还存在所设计的评价指标考虑的因素不完善、不能综合多个维度结果进行解释分析。因此,本文提出了一种以中文纠错任务为例的数据集增强质量评价方法来更加全面地量化增强数据集的质量。首先通过将原始语句转换到高维空间,其次结合文献[10]中所给出的内在质量和上下文质量来考虑增强数据集与特定任务的关联性、数据点之间的关系和对整体高维空间的覆盖程度等三个方面来进行评价,最后对多个维度指标进行融合来完成增强数据集的评价结果排序,进而筛选出最适合当前任务的增强数据集。总而言之,本文的主要贡献如下:
(1)设计并实现了一种以中文纠错任务为例的数据集增强质量评价方法,可以独立于测试集性能检验方法来为不同数据增强方法生成的训练集选用提供依据。
(2)本文在四种数据增强方法、两个中文纠错数据集和三个中文纠错模型进行了广泛的评估,通过联系模型精度和评价结果排名的方式来验证该设计的合理性。实验结果表明,在面向中文纠错任务上质量越高的增强数据集在模型性能的提升上会有更好的表现。
1 数据集增强质量评价方法
数据集增强质量评价方法通过给定一组增强数据集D、面向中文纠错任务的测试集T和由标准正态分布生成的模拟数据集S来进行评估,其衡量过程首先对增强数据集进行特征提取,再把增强数据集多个维度的指标进行量化,最后通过融合不同维度的评价结果来对增强数据集进行质量排序,具体过程如图1所示。

图1 质量评价方法Fig.1 Quality evaluation method
1.1 特征提取
对于数据集增强质量的评价方法,一种有效的特征提取方式是非常重要的环节之一。因此为了获得更加有效的句子表征,本文使用自变压器双向编码器(bidirectional encoder representations from transformers,BERT)来生成句向量。同时为了能够获取更加准确的向量表示,收集了常用的与中文纠错相关的数据集,然后将整理后的数据集用于无监督语义相似度任务,但是直接用BERT 输出的句向量做无监督语义相似度计算效果会很差,文献[11]验证了原因在于BERT 输出向量分布的非线性和奇异性,任意两个句子的句向量的余弦相似度都非常高。为了解决这一问题,使用文献[12]中提出的方法,在计算句向量的过程中引入对比学习的方法来提升表示空间的质量,使用对比学习可以让空间中的向量分布更加均匀,进而达到优化句向量的效果。
1.2 互覆盖度
互覆盖度旨在模拟增强数据集覆盖相应任务表达式空间的程度。考虑到不同任务都有常用的测试数据集来验证模型在该任务上的表现,因此,本文使用测试集作为中文纠错任务的表达式空间的近似表示。而对于中文语法和拼写纠错这两类任务,分别使用了NLPCC2018和SIGHAN Bake-off 2015中的测试集。
为了测量给定测试集的训练集的覆盖程度,首先将预训练模型输出的错误和正确句子的向量进行拼接,其次通过余弦相似度来为每一个测试集中的句子对在训练集中识别出最相似的句子对。然后,通过对测试集中所有句子对的最大相似度求平均来导出互覆盖度。对于给定的测试集,希望训练集具有尽可能高的覆盖率。具体地,对于测试集T和训练集D,其计算公式如式(1)所示:
其中,Ti和Di分别表示测试集T和训练集D中的句子对,cos(a,b)表示测试集和训练集中句子对的余弦相似度。
1.3 总分散度
总分散度旨在评估增强数据集本身在空间中的分散程度。其背后的思想是,训练数据集越分散,下游模型越不可能过拟合,因此它将更好地推广到测试集中。
为了测量给定训练集的分散程度,首先对每一个训练集中的句子去识别出另一个相似度最低的句子。然后,通过对训练集中所有句子的最不相似度求平均来导出总分散度。最后为了让不同维度指标趋势一致,增加了一个负号来保证该值越接近1,训练集的分散程度也越好。具体地,对于训练集D,其计算公式如式(2)所示:
1.4 自支撑度
自支撑度旨在模拟增强数据集对完整向量空间的覆盖程度。其基本思路是句子的向量表示可以代表其周边的小范围的空间,那么当这些小范围空间覆盖到完整空间的时候,这些组成小范围空间的句子向量表示的数量被认为是对完整空间的近似表示。
那么为了实现上述思路,需要解决两个问题,第一个是如何确定一个句子向量表示可以覆盖到的范围,第二个是如何计算出组成完整空间的句子向量表示的数量。
为了解决第一个问题,本文将相似句子之间的距离作为句子向量表示能够覆盖到的范围,对于每一对相似句子可以看成是对原始句子进行的编辑操作,那么将相似句子之间的编辑距离和句向量之间的余弦距离联系在一起,就可以将真实世界和高维空间中相似的句子关联起来,进而推测出相似句子所能覆盖到的范围。因此,首先将随机插入、删除、替换和交换作为基本编辑操作,然后在不同大小的编辑距离中随机挑选句子对计算余弦距离,进而得到余弦距离分布密度图,最后观察在不同编辑距离的情况下余弦距离的变化趋势。如图2所示,可以发现随着编辑距离的增加余弦距离的大小会以更高的概率变大,因此选择余弦距离等于0.1 作为单个句子向量表示的最大覆盖范围。
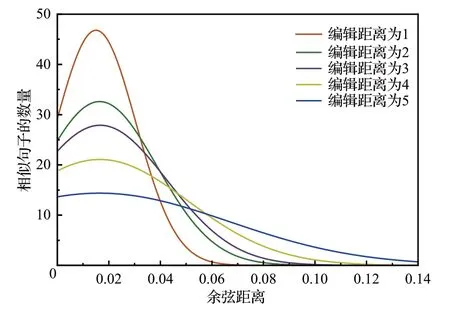
图2 余弦距离在不同编辑距离下的变化曲线Fig.2 Change curve of cosine distance at different edit distances
针对第二个问题,为了能够使用有限的数据来覆盖到完整向量空间,本文首先使用标准正态分布生成5维向量的数据,其次对于如何计算出组成完整空间的向量表示的数量,可以把它看成一个集合覆盖问题,由所有句向量组成全集,而每一个向量都对应一个集合,该集合中包含的向量与当前向量的余弦距离都小于所设定的覆盖范围。然后用最少的集合来覆盖全集,这些最少集合的数量可以作为组成完整空间的最少覆盖数量。最后为了减少误差,本文模拟了100 万到500 万的5 维向量,并且让余弦距离从0到0.11以0.004作为间隔,分别计算在不同覆盖范围下完整空间的最少覆盖数量。如图3 所示,随着覆盖范围的不断增大,完整空间的最少覆盖数量也随之减少,并且随着数据量规模的增大,曲线变化也越接近,因此当数据量规模为500 万的时候,余弦距离从0.004到0.1之间的曲线下方面积可以被认为是完整空间的近似表示。

图3 不同数量下的最少覆盖数量变化曲线Fig.3 Change curves of minimum coverage quantity under different quantities
为了测量给定训练集的自支撑度,首先需要将预训练模型输出的向量进行降维和聚类来减小数据规模,之后通过贪心算法对每一类计算出最少覆盖数量,最后整合所有类别结果画出完整空间最少覆盖数量变化曲线。对于给定的训练集,通过训练集所构造的曲线越接近模拟曲线越好。具体地,对于训练集D和模拟数据集S,其计算公式如式(3)所示:
其中,area(D)和area(S)分别表示真实曲线和模拟曲线面积。
1.5 质量融合
给定任意数量的通过数据增强方法构造的数据集,可以通过之前介绍的方法来完成各维度的质量评价。但是对于不同维度的质量评价结果并没有一种可以比较的方式,因此将三种维度的质量值进行融合。
考虑到三个维度的评价结果的取值范围都在0 到1,并且不同维度的理想趋势是一致的,都是越接近于1越好,那么如果存在一个增强数据集其各质量维度都能够达到最优值,那么这个增强数据集就可以被认为是理想上最好的。因此,采用了文献[13]中给出的乘法合成法来作为不同维度指标综合的方法,可以对增强数据集给出一个整体评价的结果。因此,对于任意一个增强数据集D、测试数据集T和模拟数据集S,其质量融合的计算公式如式(4)所示:
其中,coverage(T,D)代表互覆盖度,dispersity(D)表示总分散度,support(D,S)表示自支撑度。其中,对于互覆盖度的结果,本文设置了一个因子γ,因为在数据规模上升的情况下,总分散度和自支撑度可以进行稳定的提升,而互覆盖度由于测试集的局限性,其增长速率会随着数据量的上升而逐渐减缓,所以在数据量较小的时候因子γ应该设置的较大来增大互覆盖度对整体评价的影响,而在数据量足够大的时候可以将因子γ设置为1来保证三个维度对整体评价有相同的影响。因此,在不到1万条SIGHAN Bake-off 2015训练集的拼写纠错任务上本文将因子γ设置为5,而在10 万条NLPCC2018训练集的语法纠错任务上将因子γ设置为2。
2 实验设计
本文提出了一种以中文纠错任务为例的数据集增强质量评价方法,可用于筛选出高质量的增强数据集。为了验证不同方法生成的数据集对模型性能的影响,采用文献[14]中使用的方法,首先使用增强数据集对模型进行预训练,然后用人工生成的训练集来对模型进行微调。其次,将不同数据增强方法生成的数据集进行质量评估并与纠错模型训练结果进行关联起来,尝试使用不同数据增强策略、同一种数据增强策略下设置不同参数和数据量规模增大的情况下来验证质量评价的合理性。
2.1 数据集增强质量评价实验方法
为了衡量增强数据集的质量,首先需要通过预训练模型来提取文本的数据特征,因此将NLPCC2018 数据集一共120 万和SIGHAN Bake-off 2013—2015 年比赛提供的训练数据集6 476条数据通过对比学习的方式来优化预训练模型输出的句向量。
对于互覆盖度的计算,为测试集中每一个句子对在增强数据集中找到相似度最高的句子对,但是通过BERT 输出的句向量是768 维,将正确句子和错误句子拼接后达到1 536 维,如果采用传统的方法两两计算余弦相似度值,再获取最小值,由公式(1)可知时间复杂度为O(n×m),n为增强数据集的大小,m为测试集的大小。因此,为了能够减少在高维向量之间的余弦相似度计算时间,本文使用文献[15]中的方法,使用分层的可导航小世界(hierarchical navigable small world,HNSW)进行高维向量检索,通过HNSW 对由增强数据集生成的句向量进行分层构图,然后对测试集中的所有句子对生成的向量,都可以快速在分层图中查找到最相似的增强数据集中的句子对,其时间复杂度为O(m)。
针对总分散度的计算,对增强数据集中每一个句向量都需要进行计算再求平均,那么当数据规模和维度都很大的时候,其计算开销和时间成本都会很大,由公式(2)可知时间复杂度为O(n2),n为增强数据集的大小。因此,为了减少运行时间,在计算过程中首先将数据集划分成k个部分,每一部分包含1 万条向量,然后将每两个部分构建成的向量矩阵计算出余弦相似度矩阵,最后比较所有相似度矩阵得出总分散度结果,其时间复杂度为O(k2)。
为了计算自支撑度,由于增强数据集通过基于BERT 的预训练模型输出的句向量为768 维,而通过标准正态分布模拟的数据只有5维,所以本文首先使用等距离映射(isometric feature mapping,Isomap)来对高维向量进行降维。然后使用基于层次结构的平衡迭代聚类方法(balanced iterative reducing and clustering using hierarchies,BIRCH)来对高维向量进行聚类。最后,通过贪心算法对每一个类别计算自支撑度,再综合所有类别结果就可以画出增强数据集对完整空间的最少覆盖数量变化曲线,其时间复杂度为O(l×d×m),l为聚类的簇数,d为类别中向量的平均个数,m为每一个向量对应的子集。
对于上述实验,本文将原始方法与所提出的优化算法的运行时间在NLPCC2018数据集上进行了对比。其中,原始方法指直接计算数据集中向量之间的余弦距离,不考虑使用HNSW 和数据集划分的方法来减少计算开销。而对于自支撑度只给出了优化方法的运行时间,原因在于不通过聚类方法来减小数据规模的情况下直接用贪心算法来计算最少覆盖数量会花费较大的时间成本,其时间复杂度为O(n×m),n为增强数据集中向量个数,m为每一个向量对应的子集。如图4(a)和图4(b)所示,随着数据量的不断上升,本文的优化方法与原始方法相比大大减少了运行时间。在同等数据规模下,自支撑度的运行时间结果如图4(c)所示。

图4 数据集增强质量评价结果及运行时间Fig.4 Dataset enhancement quality evaluation results and running time
2.2 数据集及数据增强方法
为了验证本文方法的有效性,本文分别在用于语法纠错上的NLPCC2018 数据集上随机抽取10 万条数据和拼写纠错上的SIGHAN Bake-off 2013—2015年比赛CSC 任务中提供的训练数据集6 476 条数据进行微调模型,然后使用四种数据增强方案来生成同等规模下的训练数据用于对模型的预训练。测试集分别使用NLPCC2018 公开评测比赛的测试集一共2 000 条句子对和SIGHAN Bake-off 2015年比赛提供的测试集一共1 100条句子对。
针对中文纠错任务的应用场景,需要使用数据增强方法对原始数据增加噪声来模拟中文错误,从而构建出句子对用于模型的训练。为了能够更好地衡量不同方法对模型性能的提升,本文主要通过两类方法,分别是无监督和有监督的方法,无监督方法主要是通过对原始句子修改的方式来构造样本,有监督方法是通过生成模型来实现由正确文本生成错误样本。具体的数据增强方法如下所示:
(1)基于腐化语料的单语数据增强[16]。首先通过jieba分词工具对原始语句进行分词,然后通过腐化算法按30%的概率对每个词进行随机添加、替换或删除,其中设置随机操作的比例为1∶1∶1。
(2)EDA[17]。同样使用jieba分词工具对原始语句进行分词,然后按10%的概率随机选择位置进行随机删除、插入、交换或同义词替换。
(3)反向翻译[18]。使用NLPCC2018和SIGHAN Bakeoff 2013—2015的数据集,通过正确样本到错误样本来训练一个Transformer 模型来模拟中文错误方式,生成错误语句。
(4)OCR+ASR[19]。通过文本转语音或图片,再对语音或图片添加噪声后再转换为文本来模拟中文音似和形似错误类型。
对于上述增强方法,除了反向翻译需要先训练一个模型所以需要花费较大的时间成本,其余方法都可以直接实现,并且在实验过程中都使用NLPCC2018 和SIGHAN Bake-off 2013—2015训练集中的正确语句生成相同大小的增强数据来保证数据量的一致性。
2.3 实验设置
本文在数据集增强质量评价过程中选择Pytorch为深度学习的框架,在PyCharm 2021,CPU 为i7-10700k,GPU 为RTX2060,16 GB 内存,Python 3.8,Win10 64 位操作系统下进行实验。
为了分析不同数据集在中文纠错模型上表现如何,本文使用了三个中文纠错模型,分别是GECToR、基于中文BART 的seq2seq 模型和基于RNN 的seq2seq 模型。GECToR 和基于中文BART 的seq2seq 模型是使用文献[20]提供的代码及默认参数设置,但是将中文BART 的预训练权重修改为BART-base。基于RNN 的seq2seq模型使用的是文献[21]中的默认参数设置。
2.4 评价指标
2.4.1 中文语法纠错评价指标
本文实验采用公开的标准评价指标最大匹配分数(M2-Scorer[22])对中文语法纠错模型在NLPCC2018测试集上的结果进行评估。对于纠错模型输出的改正结果,M2-Scorer 在所有标准编辑集合中计算出与改正结果重叠程度最高的编辑序列。其计算结果包括精确率(Precision,P)、召回率(Recall,R)和F0.5值。具体的计算公式如式(5)~(8)所示:
其中,{e1,e2,…,en} 是由纠错模型输出的改正的集合,{g1,g2,…,gn} 是M2-Scorer 工具包中给出的标准改正集合。
2.4.2 中文拼写纠错评价指标
对于中文拼写纠错任务的评价指标,本文采用SIGHAN Bake-off 2013—2015年比赛中CSC任务提供的计算方法。评价指标的混淆矩阵如表1所示,其中TP(True Positive)表示纠错模型能够正确识别出有拼写错误的句子数;FP(False Positive)表示将没有拼写错误但被识别为错误的句子数;TN(True Negative)表示没有拼写错误的句子被标记为没有出错的句子数;FN(False Positive)表示存在拼写错误却被识别为没有错误的句子数。

表1 混淆矩阵表Table 1 Confusion matrix table
在混淆矩阵的帮助下,本文采用的评价指标包含包括精确率(Precision,P)、召回率(Recall,R)和F0.5值。具体的计算公式如式(9)~(11)所示:
其中,TP+FP表示被纠错模型识别为错误的句子数,TP+FN表示真实存在错误的句子数。
2.5 实验结果
在这一节,本文分别做了三组实验,来验证所提出的质量评价方法的有效性。第一组实验通过对不同数据增强方法生成的数据集在模型上进行预训练,用相同的人工数据集进行微调,然后观察模型在测试集上F值和数据集增强的质量评价结果的关联性;第二组是在同一种数据增强方法下设置不同的错误类型的实验;第三组是在数据量规模增大的情况下进行的实验。
图5 是使用不同数据增强方法生成相同数量大小的训练集分别在NLPCC2018和SIGHAN2015测试集上的模型精度和增强数据集质量评估结果。由图5(a)可知,四种数据增强方法生成的数据集质量融合结果是依次上升的,在三个纠错模型上,前三种方法生成数据集的F 值也是依次上升的,但是对于OCR+ASR 的方法有不同的结果。因为在中文语法纠错任务上,错误类型包含多字、少字、错字和排序错误,但是使用OCR+ASR生成错误样本只有错字,所以不同模型在该方法上的表现会有所差异。其次,在三个模型中只有RNN 的模型没有使用通过大规模数据进行预训练增强,所以它在使用OCR+ASR这种方法下的效果会最差。在表2中总结了NLPCC2018上不同增强数据集的质量评价结果。实验结果表明在NLPCC2018测试集中使用反向翻译生成的增强数据集可以更有效地提升模型的性能。
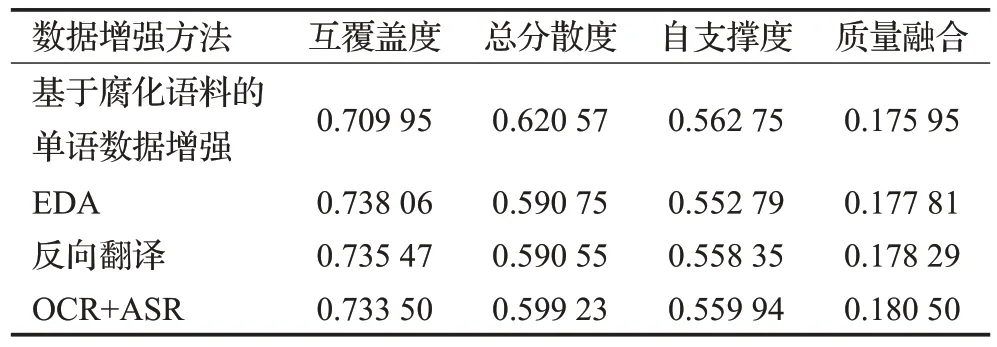
表2 NLPCC2018上增强数据集质量评价结果Table 2 Enhanced dataset quality evaluation results on NLPCC2018
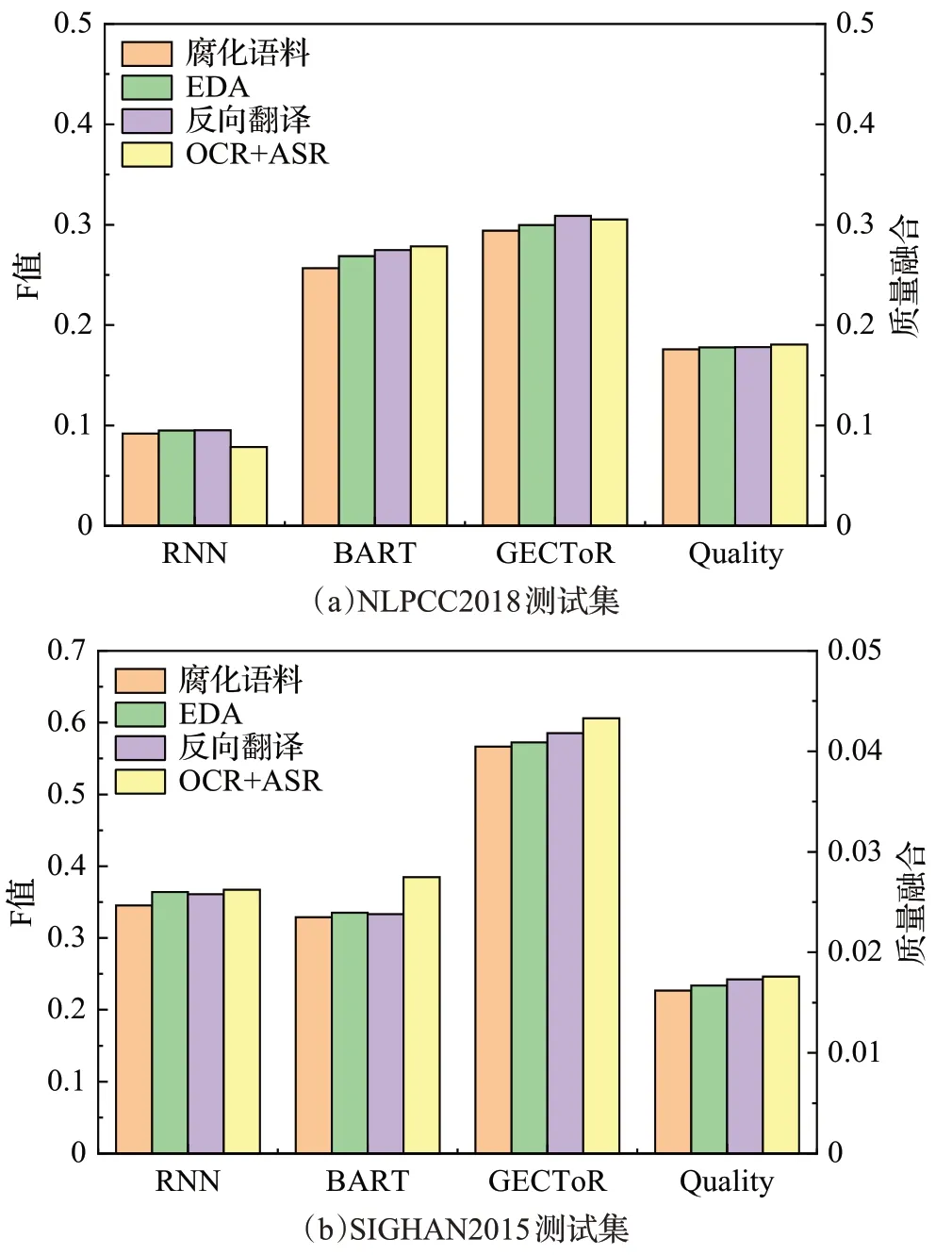
图5 不同数据增强方法下的评估结果Fig.5 Evaluation results under different data augmentation methods
由图5(b)可知,增强数据集质量融合指标结果是依次上升的,在所有纠错模型中使用OCR+ASR的方法达到最优,腐化语料的效果最差,对于另外两种增强方法的结果有不同的结果。因为在中文拼写纠错任务上,错误类型只包含错字,而除了OCR+ASR这种方法,另外的方法都包含其他错误,对于这些错误并不能保证模型能够学习到有用的部分。在表3中总结了SIGHAN2013—2015 上不同增强数据集的质量评价结果。实验结果表明在SIGHAN2015 的测试集中使用OCR+ASR 的方法生成的增强数据集可以达到最优的效果。
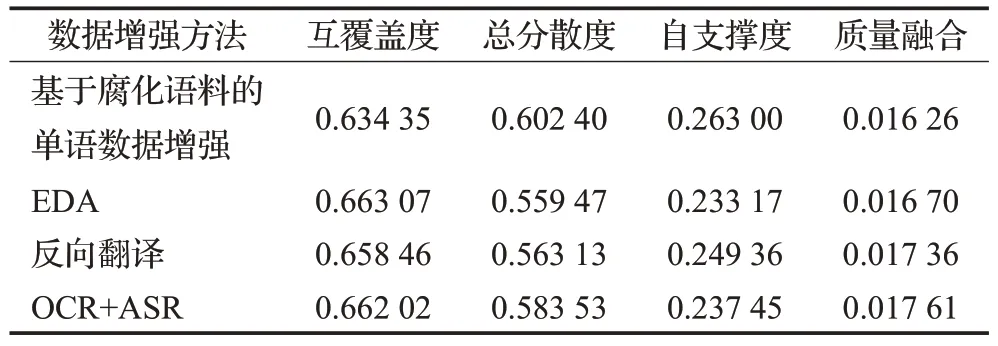
表3 SIGHAN2013—2015上增强数据集质量评价结果Table 3 Enhanced dataset quality evaluation results on SIGHAN2013—2015
图6 是对基于腐化语料的单语数据增强方法中的错误类型进行修改后在两个测试集上运行的模型精度和增强数据集质量评估结果。由图6(a)可知,对于生成增强数据集的方式,使用了单一的错误类型。实验结果表明,质量融合和模型精度结果保持一致,删除方式效果最好,其次是添加方式,最差的是对句子中词的替换。因此,只使用单一的错误类型对模型最终结果都会有一定的影响。相对而言,在NLPCC2018 测试集上使用替换方式对模型性能增强的效果最差,而删除和添加方式对模型性能增强的效果会较高一点。
由于中文拼写纠错任务只包含错字的错误类型,所以在单一错误类型上,只验证了删除和替换错误方式。因此由图6(b)可知,质量融合结果和GECToR模型精度保持一致,但是在RNN和BART模型上运行结果相反,原因可能在于当前测试集只有错字的错误类型,并且这两个模型都是将中文纠错看作是一个错误句子翻译为正确句子的过程,所以能够从替换的错误方式中学到更多有用的错误。因此,通过实验结果表明在SIGHAN2015测试集上使用替换方式对RNN和BART模型的增强效果最好,删除方式对GECToR模型的增强效果最好。
图7和图8是在数据量规模增大的情况下对模型召回率和增强数据集质量评估的结果,分别对基于腐化语料的单语数据增强和EDA方法生成的数据集依次扩充到5倍,可以发现质量融合结果上升的速度是逐渐减缓的,而对于BART 和GECToR 模型来说,随着数据量的增加,模型的召回率会有所增加,但当数据量增加到一定规模的时候,召回率就有下降的趋势,说明此时通过重复数据增强生成的句子对会对模型的性能有一定的影响,并不是数据量越多越好。
但是RNN 模型的召回率并没有此规律,该模型之前没有经过大规模的数据预训练过,因此对于不同数据规模的数据集可以学习到不同的错误。
在表4 和表5 中分别给出NLPCC2018 测试集和SIGHAN2015 测试集上使用基于腐化语料的单语数据增强方法生成的不同数据规模的增强数据集在GECToR模型上的训练结果。实验结果表明,在NLPCC2018 测试集上,使用相同的训练数据,通过数据增强方法进行规模增长的方式并不能获取有效的模型性能增益。而在SIGHAN2015测试集上,通过数据规模的增长可以明显看到性能的有效提升,但是并不能保证数据规模的增大的同时模型性能也保持稳定的上升。对于这一问题,原因在于拼写纠错数据集规模较小,所以在数据量规模增大的情况下对模型性能有明显的提升,而NLPCC2018数据集规模较大,所以使用数据增强方法进行规模增长的方式并不能有效提升模型性能。
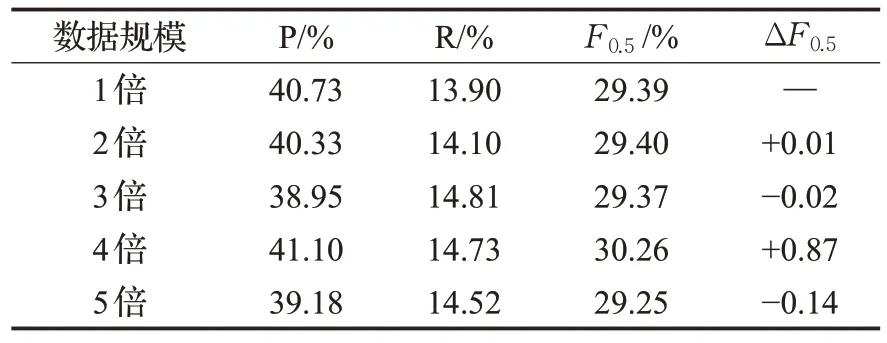
表4 NLPCC2018上模型训练结果Table 4 Model training results on NLPCC2018
3 结束语
本文提出了一种以中文纠错任务为例的数据集增强质量评价方法,以此缓解在不同应用任务中缺乏有效的方法来评估增强数据集质量的影响。该方法根据增强数据集的多维质量进行评估并通过质量融合的方式来进行排序,本文通过训练已知算法的模型并将质量融合指标与模型精度相关联来验证质量评价的有效性。实验结果表明,具有更高的整体质量的数据集可以在中文纠错任务上实现更好的性能。未来的工作将通过质量评价来探索更适合特定任务的数据集构建方法,从而获得具有更高质量、更高效的与任务相关的增强数据集。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
世界科学技术-中医药现代化(2021年10期)2021-03-02
幽默大师(2020年11期)2020-11-26
摄影之友(影像视觉)(2019年3期)2019-03-30
摄影之友(影像视觉)(2019年2期)2019-03-05
摄影之友(影像视觉)(2018年12期)2019-01-28
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国教育技术装备(2015年19期)2015-03-01
