
基于可变尺度先验框的声呐图像目标检测
2024-03-05 10:21黄思佳宋纯锋
系统工程与电子技术 2024年3期
黄思佳, 宋纯锋, 李 璇,*
(1. 中国科学院声学研究所水下航行器信息技术重点实验室, 北京 100190;2. 中国科学院大学电子电气与通信工程学院, 北京 100049;3. 中国科学院自动化研究所智能感知与计算研究中心, 北京 100190)
0 引 言
伴随着计算机的普及以及互联网的飞速发展,信息的传递变得更加方便快捷,人们的交流媒介逐渐从文字转变成图片以及视频。相比传统处理图像的方法而言,深度学习方法凭借其强大的处理数据和提取信息的能力、较高的准确率和快速计算等优点,脱颖而出成为图像识别和目标检测领域的研究热点[1]。
传统的声呐图像目标识别一般采用机器学习的方法,主要由候选区域生成、特征提取器以及分类器三部分组成。传统的目标识别方法对于目标的先验信息,形状等都有一定的要求,特征提取非常依赖人工的选择,若图像的像素太少或者特征不够有代表性,识别目标的效果就会比较差。然而,由于水下环境复杂,回波受到混响噪声、环境噪声的影响,导致声呐图像分辨率低,边缘细节较为模糊,很难找到像素和具有代表性的良好特征。另外,由于水下环境的不确定性很大,人工获取先验信息的代价也比较高,因此传统的目标检测算法在声呐图像的目标检测中效果并不理想。
近些年,深度学习在人脸识别[2-4]、医学图像识别[5-7]、遥感图像分类[8-10]等领域都有了广泛应用,许多学者开始将深度学习的模型迁移到声呐图像的目标检测中进行应用,提高了水下声呐图像的识别精度和速度。文献[11]提出利用轻量级的CPU卷积神经网络(lightweight CPU convolutional neural network, PP-LCNet)替换原Yolov5网络中的跨阶段局部网络结构(cross stage partial darkNet, CSPDarknet)主干网络,在不降低检测精度的前提下减少了模型参数量和网络计算量,能够更好地满足低功耗平台的在航检测要求。文献[12]针对声呐图像数据量不足的情况,建立了水下目标的仿真模型,并且利用仿真样本与真实样本相结合进行实验,在不同的模型下都有一定的提升效果,为声呐图像数据不足的问题提供了解决思路。文献[13]针对声呐图像像素空缺,成像效果不好的问题,采用双线性插值算法进行像素填充,让声呐图像变得更加清晰饱满,并且在Yolov3模型上进行实验,取得了良好的效果。文献[14]针对声呐图像散斑噪声强、分辨率低、图像质量差等问题,提出了一种基于快速曲线变换的去噪算法,有效提高了混响干扰下声呐图像的质量。文献[15]结合显著性分割和金字塔池化的检测模型,减小了输入数据的维度并且减小了图像背景对目标提取的干扰,有效提高了水下目标识别的准确率。文献[16]利用声呐图像模拟器来模拟声呐传感器的成像机制,结合各种退化效应来合成训练图像,一定程度上缓解了声呐图像数据量不足的问题。文献[17]利用生成对抗网络(generative adversarial networks, GAN)合成真实声呐图像作为目标物体的训练图像,该方法可以合成不同角度和不同环境的真实训练数据,为其他基于声呐图像的算法提供了一定参考。 文献[18]针对声呐图像噪声干扰严重的问题,提出了一种自适应全局特征增强网络,能够获取声呐图像多尺度语义特征,在噪声严重的情况下仍然能对目标进行准确的检测和定位。文献[19]提出一种基于Yolov4改进的声呐图像目标检测算法,将Yolov4中的路径聚合网络(path aggregation network, PANet)特征增强模块替换为自适应空间特征融合(adaptively spatial feature fusion, ASFF)模块,来获得了更好的特征融合效果。文献[20]针对前视声呐图像中的小目标检测问题提出了一种基于脉冲耦合神经网络和Fisher判别的实时目标检测方法,该算法结合模糊c均值聚类和K均值聚类获得感兴趣的区域,在低虚警概率下检测误差小,实时性好。文献[21]根据实测过程中不同原因造成的成像差异进行了数据的增强与扩充,并改进了池化方式,提升了检测效果。
上述研究通过借鉴深度学习在计算机视觉领域的成果,提升了声呐图像目标检测的性能。然而,声呐图像的目标检测方法仍然存在数据获取难、数据量少、目标尺度分布集中、检测性能不佳、模型实时性差的问题,因此本文提出了一种基于轻量级目标检测模型Yolov5改进的水下目标检测方法。针对声呐数据集与COCO数据集在目标大小上的差异,利用目标尺度的先验信息,自适应地生成可变尺度的先验锚框,有效提高了声呐图像中目标的尺度适应性。深度学习的模型训练需要大量的数据支撑,因此本文采用了数据增强的方法对训练集进行有选择性的扩充,进一步增强模型的鲁棒性。此外,本文还探索了模型的轻量化,在不牺牲模型精度的前提下,通过删减大目标检测层降低了模型复杂度,可更好地适应实时检测的要求。
1 基于可变尺度先验框的声呐图像目标检测方法
1.1 网络结构介绍
(1) 轻量化目标检测模型概述
相比于快速局部卷积神经网络(fast region-convolutional neural network, Fast R-CNN)[22]以及Faster R-CNN[23]等两阶段目标检测算法,Yolo系列作为单阶段目标检测算法的代表,不需要生成候选区域,而是直接通过网格进行坐标回归,大大提高了目标检测的速度。Yolov1[24]将图像分成S×S个网格,如果物体的中心点落在某网格内,那么该网格就负责预测这个目标。在Yolov1当中,每个网格对应两个预测边界框,并且每个网格只对应一个类别,所以对于比较密集的小目标检测效果较差,会出现漏检的情况。Yolov1在预测目标位置的时候,是通过直接预测目标的宽高以及中心点坐标,这种预测方法导致目标框与物体的位置之间偏移量很大。针对Yolov1当中定位不准的问题,Yolov2[25]开始采用基于先验框进行预测,相比于直接预测目标边界框,采用先验框偏移的方式进行预测使得网络更容易学习且更快收敛。Yolov2中每个网格对应5个先验框,且每个先验框可以预测不同类别,改善了较为密集物体的目标检测的问题。除此之外,Yolov2还进行了一些尝试,例如多尺度训练、通过passthrough层更好地提取目标的细粒度特征等,速度和精度相对Yolov1都有了一定的提升。Yolov3[26]采用Darknet-53作为骨干网络,引入了空间金字塔池化(spatial pyramid pooling, SPP)的思想。在颈部引入了特征金字塔池化(feature pyramid network, FPN)的思想,可以融合不同特征图的信息,能够更好地提取目标的特征。与FPN不同的是,Yolov3是在深度方向上进行拼接,可以更好地保留特征信息。Yolov3在3个预测特征层上进行预测,在每个预测特征层上分别使用3个不同大小的先验框,可以检测不同大小的目标。Yolov4[27]采用CSPDarknet53作为骨干网络,在Darknet53的基础上引入了跨阶段部分(cross stage partial, CSP)结构,增强了CNN学习的能力以及降低了显存的使用。Yolov4将(rectified linear activation function, ReLU)激活函数改为Mish激活函数,Mish激活函数的图像更加平滑,还采用了一些优化策略,例如Mosaic增强,引入缩放因子来消除网格的敏感度等。与Yolov4相比,Yolov5在骨干网络中增加了Focus层,在不影响算法精度的情况下提高了每秒浮点运算量(floating-point operations per second, FLOPS),Yolov5还引入了C3模块,促进特征融合,与Yolov4相比性能更强。除此之外,Yolov5网络还能通过改变参数来改变网络的深度和宽度以更好地适应不同数据量规模的需求,这种改进对于声呐图像这类数量较少的数据集有一定作用,可以根据声呐数据集的大小调整模型的参数,实现更好的自适应。
(2) 本文采用的骨干模型
Yolov5的网络结构可以分为Backbone和Head两大部分。输入通过骨干网络下采样5次,选取3个特征层作为Head部分的输入。在骨干网络部分,输入首先经过一个Focus层,将数据的宽度和高度减小为原来的一半,减少了参数量,同时也提高了网络的前向传播速度。然后,通过4个卷积层和C3层,C3层是在Yolov4网络CSP层的基础上提出的,C3层可以帮助骨干网络更好地提取特征信息。Yolov5将激活函数改为Silu函数,Silu函数更为光滑且处处可导。最后,Yolov5在最后一个卷积层和C3层中间增加了SPP模块,SPP将输入并行通过多个不同大小的最大池化,然后进一步做融合,可以在一定程度上解决目标多尺度的问题。
(3) 可变尺度先验框模型
本文提出的可变尺度先验框模型如图1所示,首先对声呐图像的训练集进行分布统计,获取目标的尺度信息,并利用(intersection over union, IoU)聚类的方法重新设定先验框;其次利用平移、旋转、改变亮度、加噪声、cutout、镜像等方式选择性的对数据集进行增强,将扩增后的数据集输入到Yolov5骨干网络提取目标特征信息;最后在两个尺度的目标检测层进行目标定位以及类别判定。
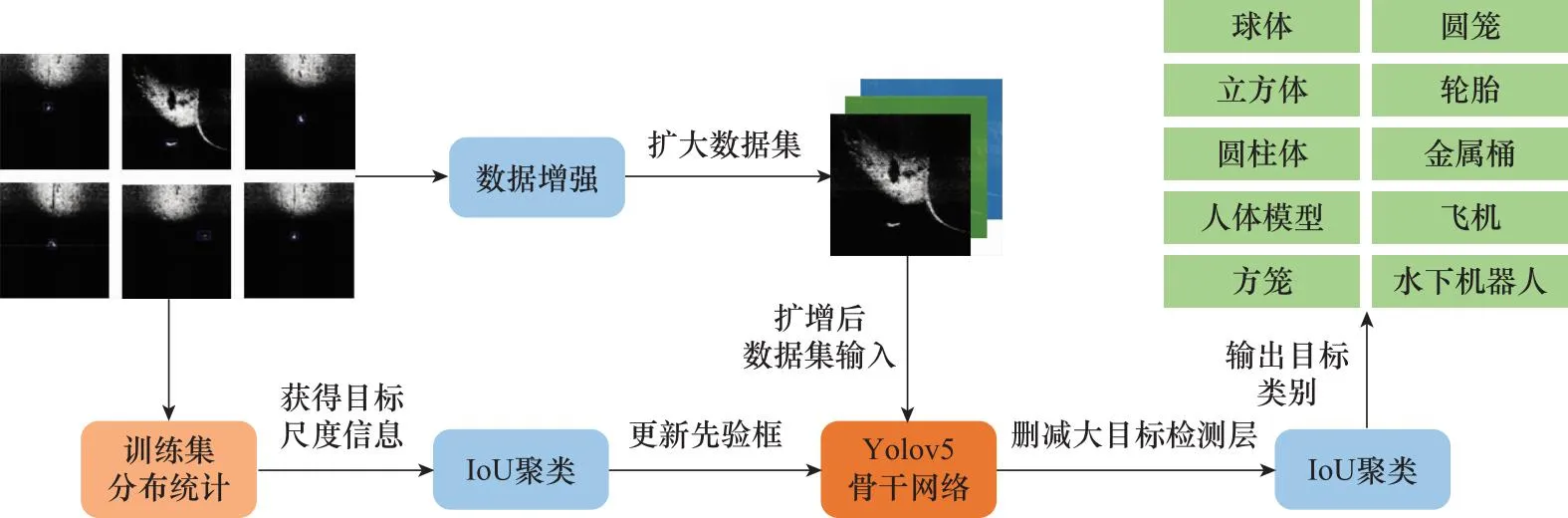
图1 可变尺度先验框模型Fig.1 Variable scale prior box model
1.2 可变尺度先验框目标检测模型
1.2.1 基于数据统计的目标尺度分布获取
本文所使用的数据集来源于2022年全国水下机器人大赛(underwater robot professional contest, URPC)的比赛数据集[28],该数据集共有9 200张前视声呐图像,分别由人体模型、球体、圆笼、方笼、轮胎、金属桶、立方体、圆柱体、飞机模型以及水下机器人10类目标组成。
在进行目标检测之前,需要先对数据集的目标进行分析。深度学习算法是以数据驱动的, 虽然数据集有9 200张图片,但对于深度学习而言,数据量还是偏少。针对数据量不足的问题,本文根据声呐图像的特点进行相应的增强。在获取水下目标的声呐图像时,由于声呐检测的角度不同、水底地形的干扰、水下深浅不一导致信号有偏差以及各种环境噪声、混响噪声的影响,导致水下目标检测困难。为增强图像的鲁棒性,本文采用旋转、平移、改变亮度、加噪声等图像增强的方式对数据集进行增强,能够有效的提高检测目标的精度。
目标尺度的统计结果如图2所示,图2(a)给出了目标框最长边与图片边长的比例,可以看到大多集中在0.04~0.16左右,图2(b)给出了所有目标的面积与图片面积的比例,大部分集中在0.002~0.008附近。通过各类比例可以发现,该数据集的目标基本上都是小目标,而Yolov5网络的先验框是以COCO数据集聚类得到的,与本文所使用的数据集差异较大,所以本文根据该数据集的特点重新设定先验框。除此之外,Yolov5的head部分有3个不同尺寸的检测头,分别用来预测大目标、中目标以及小目标,由于本文所使用的数据集多为小目标,所以对Yolov5进行剪枝操作,减少一个检测头,在参数量减少的基础上保持精度不变且提升了检测速度。
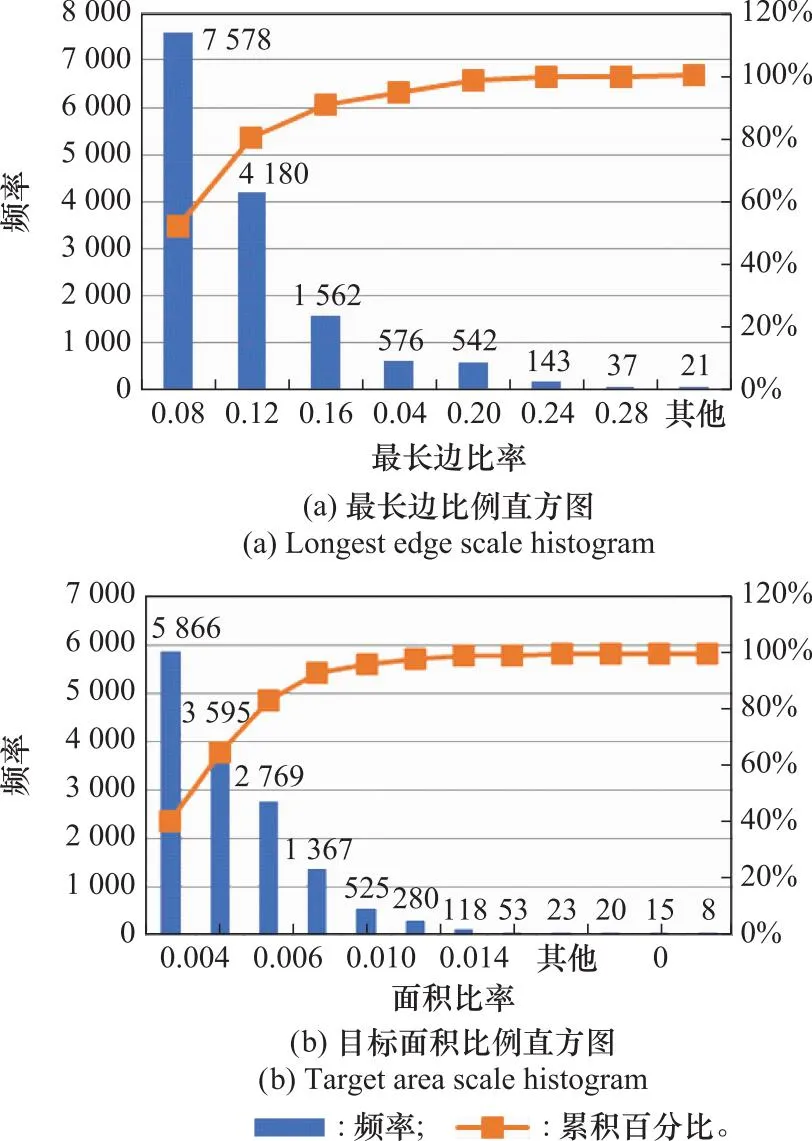
图2 目标尺度分析结果Fig.2 Target scale analysis results
1.2.2 先验框计算
由于Yolov1直接计算目标框的方法效率和精度都很低,因此Yolov2基于Fast R-CNN的思想引入了锚框,能够更好地匹配样本的尺寸大小。Yolov3和Yolov4都使用了K均值聚类方法来计算锚框,而Yolov5将手动计算锚框的方式改为自动计算锚框,并将K均值聚类和遗传算法相结合。Yolov5的初始锚框通过统计COCO数据集的目标尺寸获得,而本文所使用的数据集大多为小目标,与COCO数据集的宽高比有较大的差异,因此需要根据聚类结果重新设定初始锚框的大小。原始Yolov5中的聚类方式使用的是传统的K均值聚类,以欧式距离函数作为判断类别是否相近的标准。本文首先尝试了Yolov5默认的聚类方式,由于使用欧式距离函数会使得较大的目标框比较小的目标框具有更大的偏差,因此本文提出利用IoU替换欧氏距离函数,利用IoU作为距离函数能够更好地判断锚框与目标框的匹配程度,提高预测边界框的准确度和精度。
不同聚类方案的结果如图3所示,不同的颜色代表训练集中真实框不同的宽度以及高度分布,五角星分别代表9个类的中心锚框的高度和宽度分布。从图3(a)可以看到,IoU K均值聚类方法得到的锚框与训练集真实框大小的匹配度为85.39%,而图3(b)中使用传统的K均值聚类方法得到的锚框与训练集真实框大小之间的匹配程度为84.23%,平均IoU匹配度提高了1.16%左右。在最小的特征图上,由于其感受野最大,所以用来检测大目标,因此大尺度的先验框应用在小特征图上用来检测大目标,而小尺度的先验框用在大特征图上用来检测小目标。表1给出了特征图与先验框的对应关系。本文将传统的K均值聚类方法替换成IoU-K均值聚类方法,可以有效提高锚框与目标框之间的匹配程度,能够更好的定位目标,减少损失。
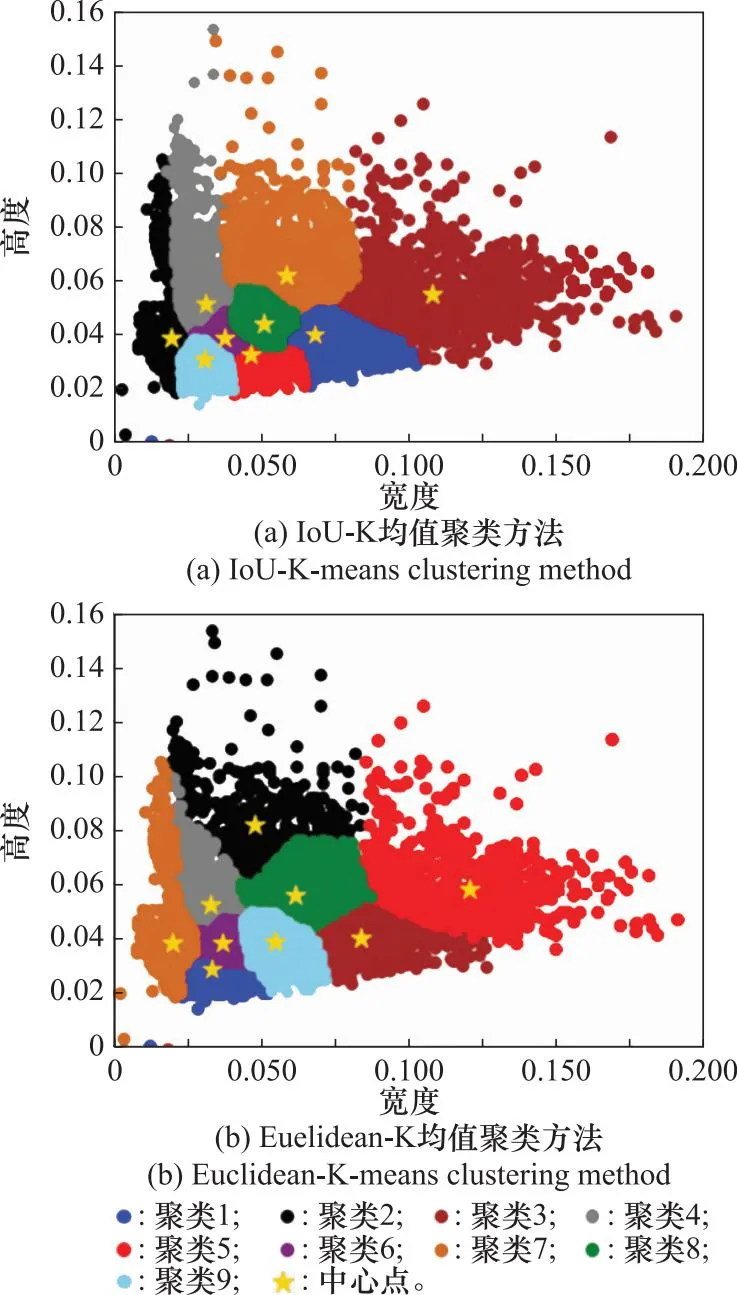
图3 聚类结果对比Fig.3 Comparison of clustering results

表1 先验框尺寸Table 1 Prior box size
1.2.3 选择性声呐数据扩增
深度学习网络训练过程中需要大量的数据支撑,模型样本越多越充足,网络模型的泛化性就越好,鲁棒性越强。本文的数据集一共有9 200张,与经典的COCO数据集以及VOC数据集相比,数据量远远不够,所以本文针对该数据集的特点,对图像进行有选择性的增强。声呐图像通常会因为波浪起伏、拖鱼倾斜等原因造成回波强度的起伏,导致图像出现灰度不均的情况[29]。在利用声呐进行水底探测的过程中,同一个目标由于探测角度、船行方向等原因也会有一定差异,且水下环境复杂,声阴影、混响噪声以及环境噪声等都会影响声呐图像的质量。为了增加数据量和增强图像的鲁棒性,本文采用平移、旋转、改变亮度、加噪声、cutout、镜像等方式随机对图像进行增强。数据集按8∶2的比例划分训练集和验证集,对训练集进行数据增强,将原训练集的每张图片进行两次随机增强,得到新训练集,数量为原训练集的3倍。数据增强的效果如图4所示。

图4 数据增强Fig.4 Data enhancement
1.2.4 基于Yolov5的输出分支裁剪
原Yolov5s网络中存在3个目标检测层,分别对应检测大目标、中目标以及小目标。而本文所使用的数据集小目标居多且不存在大目标,如果保留大目标检测层,反而对小目标的检测有所干扰。所以本文对原Yolov5s网络中的目标层进行了删减,剔除了大目标检测层如图5所示。每个特征检测层的每个网格可以得到3×(5+num) 个检测结果,其中num为目标的类别数量。
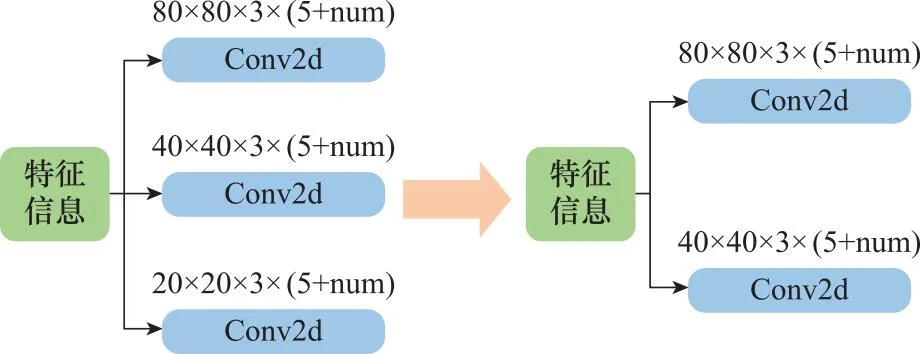
图5 大目标层删减示意图Fig.5 Schematic diagram of deleting large target layers
由于20×20大小的特征层下采样次数最多,感受野最大,所以用来检测大目标。而在不断下采样的过程中,很有可能会丢失小目标的特征信息,因此20×20的检测层对本文所采用的数据集检测意义不大,所以本文选择删除20×20大小的大目标检测层,网络模型的层数由原来的283层缩减为现在的201层,每秒10亿次浮点运算次数(giga FLOPs, GFLOPs)由16.5减少至14.9,在降低网络模型复杂度的同时,精度较原来有所提升。
2 实验与结果分析
2.1 数据集
本节基于各类模型对声呐图像进行目标检测,所使用的数据集为2022年全国水下机器人大赛的比赛数据集,共有9 200张前视声呐图像,分别由人体模型、球体、圆笼、方笼、轮胎、金属桶、立方体、圆柱体、飞机模型以及水下机器人10类目标组成。对于各算法的数据集划分,通过随机种子按8∶2的比例划分为训练集和验证集,针对训练集的数据,采用平移、旋转、改变亮度、加噪等方式随机增强,将原训练集扩大了3倍。为验证模型的有效性,本文选取了2021年URPC的比赛数据集[30]对模型进行验证,该数据集有6 000张前视声呐图像,分别由人体模型、球体、圆笼、方笼、轮胎、金属桶、立方体和圆柱体8类目标组成。由于该数据集的目标也大多为小目标,且有在航检测的需求,所以本文提出的模型对于该数据集同样适用。
2.2 实验环境与模型训练
实验环境配置使用Ubuntu16.04操作系统,使用NVIDIA GeForce GTX 2080Ti 显卡,CUDA版本为11.6,Pytorch版本为1.12.1,Python版本为3.8.15。本实验将epochs设置为150次,batch_size设置为8。在训练过程中,首先将图像输入到检测器中,Backbone生成特征图,然后利用Neck对特征进行增强和融合,最后利用Head从特征空间映射到标签空间。计算预测的标签与真实标签之间的损失,采用随机梯度下降(stochastic gradient descent, SGD)对参数进行更新。
2.3 评价指标
本文采用平均精度均值mAP来评价各网络模型在前视声呐图像目标检测中的性能。平均精度AP由精确率P和召回率R决定,指的是P-R曲线的面积,而mAP代表的是各类目标P-R曲线面积的平均值。当IoU大于或等于设置的阈值且类别判断正确时,那么该预测框为正确检测框TP,随着IoU指标的提升,目标检测的定位回归标准就越严格。在本文中,分别采用0.5和0.75的IoU标准来评价网络的性能。此外,结合IoU从0.5变化到0.95的平均mAP值,用以衡量每个模型的精度。
本文采用GFLOPs来衡量模型的复杂度。FLOPs为浮点运算数,可以用来衡量模型的计算量;而一个GFLOPs代表每秒十亿次的浮点运算。GFLOPs越大,模型越复杂。
2.4 实验结果及分析
2.4.1 模型消融实验
消融实验经常用来探索某些网络改进或者训练策略对网络模型性能的影响[31]。针对本文提出的简化网络结构,基于目标框进行聚类得到先验框以及数据增强3部分改进方案,为了验证其有效性,设置了多组消融实验,实验结果如表2所示。

表2 消融实验结果Table 2 Results of ablation experiment
(1) 各项改进对网络模型的影响
表2第一行是以原Yolov5s网络训练得到的结果,由于数据集中都为小目标,与COCO数据集的目标大小有较大差异,所以在不改变先验框大小的时候,检测效果一般。虽然本文数据集一共有9 200张图片,但是对于以数据驱动的深度学习模型而言,数据量还是偏少,所以在划分完测试集与验证集以后,对测试集进行扩增,数量为原测试集的3倍,对精度有了一定提升。原Yolov5s网络有3个目标检测层,分别检测大目标、中目标以及小目标。由于本文数据集大多为小目标,所以取消了大目标的检测层,在不影响网络精度的前提下,降低了模型复杂度,提高了目标检测速度。
(2) 不同大小网络模型的影响
本文还比较了几种不同深度和宽度的YOLO网络的性能,Yolov5m和Yolov5l在一定程度上提高了模型的检测精度,但效果并不明显。由于声呐图像的数据量有限,更深层次的网络并没有突出其优越的检测性能。同时,由于模型的深度和宽度增加,GFLOPs大幅提升,网络模型复杂度增加,检测速度进一步降低。
(3) 各类模型结果分析
通过比较各模型的训练和测试性能,发现本文提出的改进方案在前视声呐图像的目标检测中表现最好,检测精度mAP@0.5、mAP@0.75以及mAP@0.5:0.95分别达到了0.971、0.585和0.559,与原Yolov5s网络模型相比,mAP@0.5提升了0.9%,mAP@0.75提升了5.8%,mAP@0.5:0.95提高了3.1%。由于减少了目标检测层,网络模型复杂度降低,所以GFLOPs也有所下降。综上,本文提出的改进方案不仅有效提升了检测精度,同时也降低了运算量,为后续基于深度学习的声呐图像目标检测提供了一定的参考。
2.4.2 多数据集验证
为验证本文算法的有效性,在其他的前视声呐数据集上也进行了相应的验证,数据集来源于2021年的URPC比赛数据集,针对该数据集,以8∶2的比例随机划分训练集与验证集进行实验。各模型的测试结果如表3所示。

表3 URPC(2021)数据集实验结果Table 3 URPC(2021) dataset experimental results
(1) 各类方法对比
表3第一行是以原Yolov5s网络模型训练得到的结果,与两级检测模型的代表Faster R-CNN相比有明显的优势,准确率比Faster R-CNN高,GFLOPs仅为Faster R-CNN的1/4。由于Faster R-CNN需要先提取候选区域,所以模型更为复杂。文献[32]提出了一种基于Yolov5模型改进的声呐图像检测方法,通过实验表明,本文提出的可变尺度先验框模型优于文献[32]的方法。
(2) 各部分改进对比
针对该数据集的目标重新进行聚类得到先验框,与原Yolov5s网络相比,mAP@0.75和mAP@0.5:0.95都有了一定提升,由于mAP@0.5的值已经非常高了,所以有一定的波动是正常现象。该数据集也大多为小目标,所以针对网络结构部分,也删减了大目标检测层。虽然检测精度有所下降,但是降低了模型复杂度,提升了检测速度。结合先验框和网络简化两部分的改进,mAP@0.5达到了0.979,GFLOPs下降到14.9,与原Yolov5网络相比都有了一定提升。实验结果表明,针对类似的数据集,本文的改进方案具有一定的参考价值,有良好的泛化性。
3 结束语
本文根据声呐图像目标检测的特点以及使用场景,提出了一种基于可变尺度先验框的目标检测方法。首先,对于声呐图像目标较小的问题,利用先验统计重新设定锚框的大小,有效提高目标物的尺度适应性,加快训练速度。其次,针对声呐图像数据量不足的问题,对图像进行有选择性的增强,丰富训练数据集,增强模型鲁棒性。最后,为满足声呐图像在航检测的需求,通过删减大目标检测层简化模型结构,在不降低模型精度的条件下加快检测速度。
实验结果表明,本文提出的改进方案检测精度最高且模型复杂度最低,对声呐图像的目标检测有一定的参考意义。然而由于水下环境复杂、噪声严重,导致声呐图像质量不高,目标边缘模糊,且存在部分目标样本稀少等问题,严重影响了目标检测准确率。为了获得更好的检测性能,下一步将开展边缘检测、模型压缩和少样本学习等研究。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
海洋信息技术与应用(2020年3期)2020-08-24
小学科学(学生版)(2019年10期)2019-11-16
成都信息工程大学学报(2019年3期)2019-09-25
电子测试(2017年15期)2017-12-18
自动化学报(2017年5期)2017-05-14
雷达学报(2017年6期)2017-03-26
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
电子设计工程(2015年6期)2015-02-27
