
基于纯自注意力机制的毫米波雷达手势识别
2024-03-05 10:30张春杰王冠博邓志安
系统工程与电子技术 2024年3期
张春杰, 王冠博, 陈 奇, 邓志安
(1. 哈尔滨工程大学信息与通信工程学院, 黑龙江 哈尔滨 150001;2. 先进船舶通信与信息技术工业和信息化部重点实验室, 黑龙江 哈尔滨 150001)
0 引 言
60~64 GHz毫米波雷达相比传统长波段雷达对细微动作的获取能力更好。雷达工作环境受环境光影响小,不会暴露个人影像信息,与传统的数据手套、摄像头相比具有丰富的优势。近年来,基于毫米波雷达的非接触式人体动作识别在远程控制、智慧家居、健康检测等领域都得到了重点关注。其中,基于毫米波雷达的手势识别系统在智能互联设备操控,残疾人及行动不便者辅助信息传达等领域拥有十分开阔的应用前景。
目前,有关毫米波雷达对人体姿态,手势动作识别的算法研究大多是先积累目标回波数据,获取目标动作每一帧的二维快速傅里叶变换(two-dimensional fast Fourier transform, 2D-FFT)矩阵和基于多重信号分类(multiple signal classification, MUSIC)算法获得的角度信息,将这两组数据处理为图像,通过两组并行的卷积神经网络(convolutional neural network, CNN)学习其中隐含的特征信息并将这两组特征进行特征融合,再把这些图像数据通过长短时记忆(long short-term memory, LSTM)网络来获得时序特征,最后通过一个全连接层进行分类。文献[1]提出基于CNN的雷达手势识别方法,通过对目标手势回波数据在慢时间维和快时间维两个维度做两次快速傅里叶变换(fast Fourier transform, FFT),获得目标手势的距离-多普勒图,设计数据集并将数据集输入CNN进行训练,对数据集中数据进行分类。文献[2]提出基于双流融合网络的毫米波雷达手势识别方法,除了获得目标手势的距离-多普勒图外,再通过MUSIC算法估计目标手势的角度信息,分别通过两组CNN进行特征提取,再进行特征融合,将融合后的特征通过LSTM学习时序特性,最后通过全连接层输出分类结果。此种方法,增加了角度维特征作为输入,提高了分类结果的准确度,但双图谱的并行输入和MUSIC算法增加了网络模型和预处理算法的复杂度。文献[3]提出基于多通道调频连续波(frequency modulated continuous wave, FMCW)的雷达手势识别方法,通过对目标手势的雷达回波数据在慢时间、快时间、天线通道3个维度做3次FFT,得到距离-时间、速度-时间、角度-时间3组谱图,并将3组谱图按帧编号进行拼接,构建数据集并输入CNN进行训练、分类。此种方法的输入数据维度过大,并没有直接关联不同帧之间的时序信息,造成网络训练的收敛速度较慢。文献[4]提出了基于串联式一维神经网络的毫米波雷达手势识别方法,将采集到的目标手势回波不经任何预处理,直接传入CNN中获得特征,将这些学得的特征通过一维Inception v3结构,再将输出通过LSTM提取时序特征,从而对手势进行分类识别。此种方法尝试了用纯深度学习的思想解决雷达问题,但只依赖CNN来提取特征会造成整体网络训练难度增大,且对数据量也有较大的需求。文献[5]提出基于双视角时序特征融合的毫米波雷达手势识别方法,通过两个毫米波雷达获取目标手势信息,将两个视角的距离-多普勒图,角度随时间变化图分别通过嵌入注意力机制的时序特征融合神经网络,获得最后手势目标的分类结果。此种方法通过增加传感器的方法,进一步提升了分类准确率。然而,上述基于LSTM+CNN组合网络的毫米波雷达手势识别方法都存在模型复杂问题、收敛速度较慢。在数据集构建部分,数据集中不同种类的手势之间特征差异比较明显,对同类手势的统一性要求过高,测量环境较理想化,而这些与实际应用是不相符的。
人机交互领域中,使用毫米波雷达作为传感器实现非接触式的命令传达或信息交互是十分重要的研究方向之一,此研究方向需要注意保证手势识别的准确性和及时性。对此,本文提出一种基于纯自注意力机制的毫米波雷达手势识别方法,拥有以下创新点:① 采用特定种类特征(固定数量种类)提取,代替CNN提取目标雷达回波数据的特征,对每一帧雷达回波数据的三维(three-dimensional, 3D)-FFT数据矩阵进行特征提取,通过峰值寻找来获得目标手势回波的固定定义特征,相比于利用CNN提取特征,既不需要训练时间,计算复杂度也大幅下降,且不需要将特征拆分再并行输入,可实现单网络分类。② 采用基于纯注意力机制的雷达特征变换(radovr feature transformer, RFT)网络来代替LSTM+CNN组合网络,RFT网络可以通过更改位置编码方式来改变时序关联的顺序,增加了时序的灵活性,并且相比LSTM+CNN的组合网络,模型的算法复杂度低,在有限的硬件资源下更加利于硬件移植。
1 雷达回波数据处理与特征处理
1.1 雷达回波数据的时序特征提取
毫米波雷达产生的线性FMCW(linear FMCW, LFMCW)信号为
(1)
式中:T为信号时宽;B为信号带宽。雷达回波为经过延时的线性调频信号为
(2)
式中:td为信号传输时延。回波信号与发射信号混频后:
(3)
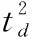
(4)
式中:R为目标相距雷达的距离。首先对混频后的每一帧中频信号进行模拟数字转换(analog-to-digital converter, ADC)采样,按采样点、线性调频、接收通道3个维度进行数据重组,组成一个三维矩阵。对这个三维矩阵分别在3个维度上依次做FFT,即3D-FFT。分别获得目标的距离R,速度v,角度信息θ,如下所示:
(5)
(6)
(7)
式中:fIF为混频后的中频频率;λ为毫米波雷达信号的波长;Δφ为两个连续线性调频之间的相位差;TC为两个线性调频之间的时间间隔;ω为两个RX对应的2D-FFT矩阵峰值处的相位差;d为接收天线之间的间距。
通过3D-FFT算法处理后,得到的是一个与输入维度相同的三维矩阵,根据这个三维矩阵即可得到对应的距离、速度、角度信息。
1.2 噪声抑制
因为在本文采集手势回波数据过程中,环境噪声是不定的,并且存在多个较强的静目标杂波存在,因此通过动目标显示(moving target indication, MTI)+恒虚警率(constant false alarm rate, CFAR)的方法来对环境杂波进行抑制。具体为对1D-FFT的结果做MTI,对2D-FFT的结果(已做完MTI)做CFAR。其中,MTI的作用是滤除静目标的影响[6],在手势回波采集时,人体和周围的大雷达反射截面积的静物是主要的环境噪声因素,MTI算法的主要思想是利用杂波与动目标的多普勒频率的差异使得滤波器的频率响应在直流和脉冲重复频率的整数倍处具有较深的阻带,而在其他频点的抑制较弱,从而通过较深的凹口抑制静目标和静物杂波。本文具体采用的是两脉冲对消器,其中两脉冲对消器的时域表达式和传递函数如下所示:
y(n)=x(n)-x(n-1)
(8)
H(z)=1-z-1
(9)
式中,CFAR的作用是对环境整体噪声进行估计并滤除[7],其工作原理为首先将输入的噪声进行相关处理,得出一个门限,将此门限与输入的待检测信号相比,如输入的待检测信号超过了这个根据输入噪声所得出的门限,则认为有目标,反之,则认为无目标;本文具体采用的具体CFAR种类是单元平均CFAR(cell-averaging-CFAR, CA-CFAR),CA-CFAR的检测原理图如图1所示。
2 手势识别网络模型
2.1 网络输入
目前,深度学习的应用领域主要是自然语言处理(natural language processing, NLP)[8-11]与计算机视觉(computer vision, CV)[12-15],并且深度学习领域中大部分网络都是服务这两个方向[16-19]。在基于毫米波雷达手势识别方法研究中,因为3D-FFT矩阵在格式上与图片数据类似,所以绝大部分方法都套用CNN在图像数据处理方面的方法,即把2D-FFT矩阵转为能量分布图再存为图像格式,用CNN学习这些距离-多普勒图中的隐含特征。而且因为3D-FFT矩阵的能量分布图并不能直观表现出角度信息,所以还需要一组角度-时间图来表征角度维信息,这样就造成了必须使用两组并行的CNN来分别提取信息。然而,雷达数据与图像数据相比,雷达数据中所需获得的部分重要特征是已知的,通过这些固定种类的特征即可完成分类,而不需要通过深度学习的方法再抽取特征。在获得3D-FFT矩阵后,通过峰值搜索即可获得目标的重要特征信息,这与在获得3D-FFT矩阵后,处理为两组图像数据并通过CNN抽取特征的方法相比,可以大幅降低算法复杂度,并省去此部分特征提取模型的训练时间。本文特征提取方式与其他文献提取特征方法差异如表1所示。

表1 不同文献特征提取差异Table 1 Differences in feature extraction of different documents

续表1Continued Table 1
其中,单层CNN复杂度部分为每秒浮点运算次数(floating point operations per second,FLOPs),M为每个卷积核输出特征图的边长,K为每个卷积核的边长,Cin为每个卷积核的通道数(输入通道数,即上一层的输出通道数),Cout为本卷积层具有的卷积核个数(输出通道数)。本文选取目标距离、速度、水平角度、竖直角度、水平角度随速度的变化、竖直角度随速度的变化这6种特征来表征某一类目标手势回波,具体如图2所示。

图2 某一类手势特征数据Fig.2 A kind of gesture feature data
对于某一类手势特征数据,每一列分别表示表征某一类手势回波的6种特征,其顺序如上述特征说明顺序一致,每一行表示6种特征中对应一种特征在16帧信号中的具体值。6种特征对应的单位如表2所示。

表2 手势特征及对应单位Table 2 Gesture feature and corresponding unit
2.2 RFT网络架构
注意力机制目前已广泛应用于NLP[20-22]和CV[23-25]领域,本文方法使用的是基于缩放点积的多头注意力机制,具体结构如图3所示。
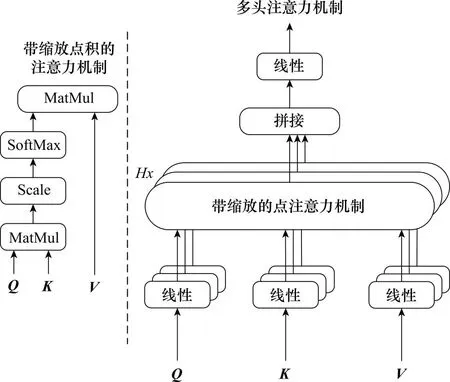
图3 基于缩放点积注意力机制的多头注意力机制结构Fig.3 Multi-head attention mechanism structure based on scaled dot-product attention mechanism
带缩放点积的注意力函数公式如下所示:
(10)

MultiHead(Q,K,V)=Concat(head1,head2,…,headH)WO
(11)
headi=Attention(QWQi,KWKi,VWVi)
(12)
式中:WO为不同头输出做拼接后对应的线性层的可学习的权重矩阵;WQ,WK,WV为Q、K、V对应的线性层的可学习权重矩阵。
基于纯自注意力机制的手势识别网络模型主要根据模型Transformer[26]改进而来,Transformer网络自提出以来,在NLP领域获得了极好的效果[27],随着Vit[28]、Swin Transformer[29]此类针对图像优化网络的出现,注意力机制在图像领域也获得了极大的成功[30-31]。并且,自注意力层相比于卷积层和循环层有着复杂度低,顺序的计算(下一步计算需等待前多少步计算完成)少,信息从一个数据点走到另一个数据点的步长短。具体如表3所示。

表3 不同类型层比较Table 3 Comparison of different types of layers
其中,n为序列长度,d为向量长度,k为卷积核大小。因此,本文基于Transformer原模型,针对毫米波雷达手势识别任务做了特定的优化,网络整体架构如图4所示。
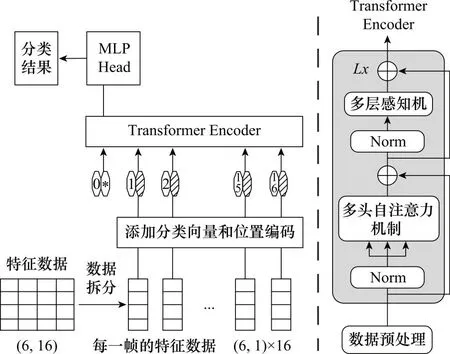
图4 RFT网络整体架构Fig.4 RFT network overall architecture
RFT模型首先对特征数据(维度为6×16)按帧编号进行拆分,获得每一帧的特征数据(维度为6×1,共16组),对这16组特征数据添加一个分类向量用于最后的分类(组成17组6×1特征向量),再给这17组特征向量添加位置编码(本文使用的是可学习的位置编码),以关联不同帧之间的时序信息,再将组合后的这17组向量输入Transformer网络的Encoder部分。Transformer的Encoder部分对经过预处理的特征数据(原始数据经过分割,添加分类向量,添加位置编码)做层归一化,再经过多头自注意力机制,再做LayerNorm和多层感知机。以上定义为一个Block,将这个Block堆叠L次,每个Block之间采用残差连接,最后抽取分类向量,通过一个Dense层进行分类。
3 实验分析与讨论
3.1 实验设备
本节使用TI公司生产的IWR6843ISK-ODS毫米波雷达开发板与DCA1000数据采集卡,将数据采集卡输出的bin文件(雷达回波数据)传输到PC端进行保存与处理,PC端重要硬件配置包括GTX1650显卡和4GDDR3内存,其中IWR6843ISK-ODS的收发天线如图5所示。通过编号RX1和RX2做竖直方向上的角度估计,用RX1和RX4做水平方向的角度估计。本文使用的天线模式为一发四收模式。

图5 IWR6843ISK-ODS天线图Fig.5 Antenna diagram of IWR6843ISK-ODS
3.2 数据采集与数据集构建
本文实验的数据采集环境如图6所示。

图6 实验数据采集环境Fig.6 Experimental data collection environment
手掌与天线距离为30 cm(±8 cm)。另外,考虑到手势识别系统的真实应用场景,本文实验中添加了一个静坐不动的人,后部存在一个正常坐姿的人,以及不定时在后方行走及周围出现的人作为复杂环境的模拟情况。在此情况下对手势数据进行采集。毫米波雷达开发板参数设置方面具体参数如表4所示。

表4 雷达参数配置Table 4 Radar parameter configuration
在数据集构建方面,首先通过3D-FFT算法、MTI和CA-CFAR算法,获得手势回波的特征数据,具体表征为距离、速度、水平角度、竖直角度、水平角度随速度的变化,竖直角度随速度的变化这6类特征数据。将这6类特征数据按行放置,以帧序号按列拼接,获得某一类手势的特征-时间数据(帧序号即表征了时序信息),具体如图2所示。本文实验一共采集了13组不同的手势,分别推拉、逆时针旋转、反z滑动、顺时针旋转、下滑、左滑、右滑、斜向左下滑、斜向左上滑、斜向右下滑、斜向右上滑、上滑、正z滑动,每类手势数据采集80组作为训练集,80组作为测试集。具体如图7所示。

图7 手势类别图Fig.7 Gesture category diagram
在进行同一种手势采集时,要求所采集的手势尽可能不统一,如图8所示。

图8 同类手势测量规则(上滑)Fig.8 Same gesture measurement rules(up-slip)
而在进行不同种手势采集时,若可能与其他种类存在混淆情况(不同类手势数据存在特征类似的情况),尽可能增加混淆度,如图9所示。

图9 不同类手势测量规则(下滑,左滑,逆时针)Fig.9 Different gesture measurement rules(down/left-slip,anticlockwise)
3.3 网络训练与实验结果分析
本文采用基于纯注意力机制的网络模型RFT作为分类模型。其中,模型的输入维度为6×16,输入文件格式为xls;网络采用6层堆叠Transformer Encoder;训练批次大小设置为2,学习率设置为动态学习律,初始学习律为0.001,最大学习率为0.01;损失函数为分类交叉熵和利用L2范数计算张量误差值(优化目标函数正则项,避免因参数过多导致的过拟合)这两种的混合误差(相加),衰减权重为0.000 1;优化器采用SGD,共训练100个epoch。对训练数据集进行打乱操作。RFT模型的重要参数如表5所示。
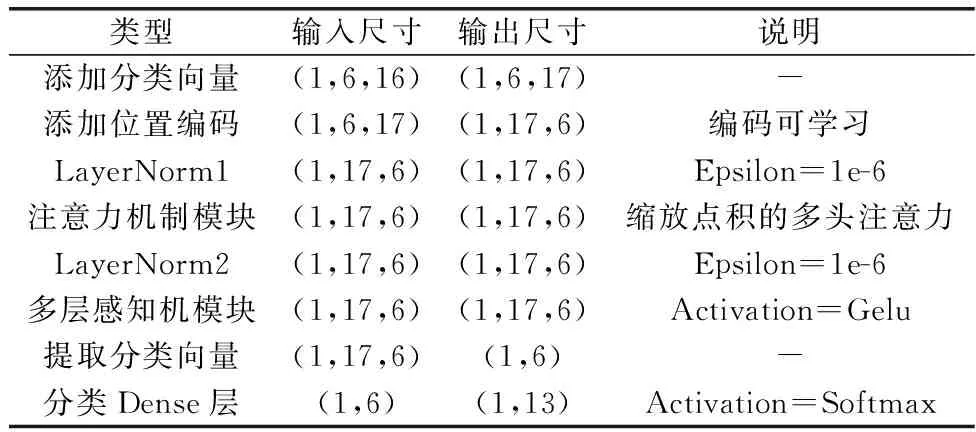
表5 RFT模型重要参数(以batch_size=1为例)Table 5 Important parameters of RFT model (taking batch_size=1 as an example)
其中,添加分类向量用于最后的分类而不是根据最后一个向量的输出进行分类的方法借鉴了Transformer网络中的操作;使用可学习的一维位置编码,而不是采用绝对位置编码,是借鉴了文献[32]模型的操作。
为了测试不同Block数(即Transformer Encoder的深度)对分类效果的影响,本文做了不同Block数的网络性能对比实验,其中训练部分如图10和图11所示。
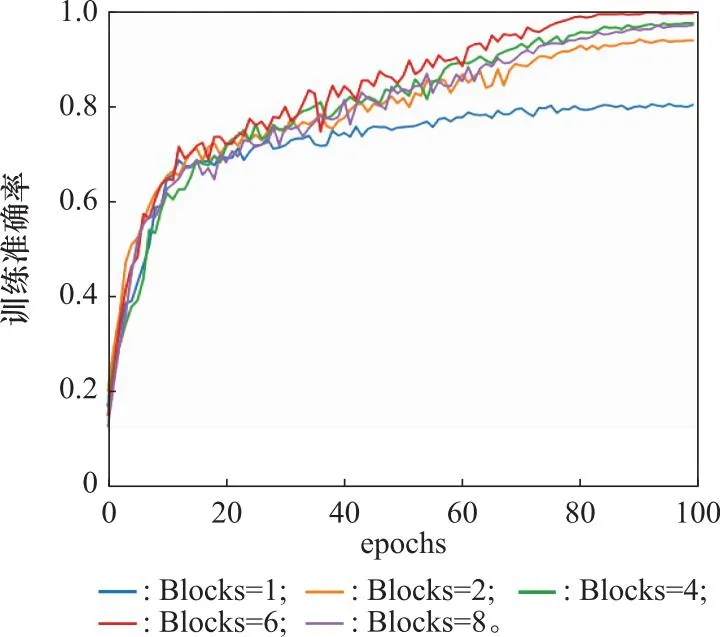
图10 不同Block数的训练准确率Fig.10 Training accuracy of different Blocks

图11 不同Block数的训练损失Fig.11 Training loss of different Blocks
可以看出,在较少的Block数可以获得较好效果,最后在测试集上对不同Block数的模型进行测试,结果如图12所示。

图12 不同Block数的测试准确率Fig.12 Test accuracy of different Blocks
根据测试结果,本文RFT模型Blocks最终选用6。通过训练,本文的RFT模型在100个epoch内即可得到较好的效果,且每个epoch训练时间仅为41 ms,证明了此模型可以快速收敛,训练的准确率与损失函数曲线如图10和图11中红色线所示。此外,本文额外采集了13类,每类80组的额外手势数据作为RFT模型的测试数据,所得预测结果的混淆矩阵如图13所示。

图13 预测结果的混淆矩阵Fig.13 Confusion matrix of prediction results
其中,数字0~12分别代表推拉,逆时针旋转,反z,顺时针旋转,下滑,左滑,右滑,斜向左下滑,斜向左上滑,斜向右下滑,斜向右上滑,上滑,正z这13类手势。
关于对比实验部分,本文采用的数据集是提取的特征数据,本文的数据集中每一帧数据维度是6×1,而对应的图像格式数据集维度是244×244。如果在本文的数据集上采用CNN,会因输入数据维度过小导致模型收敛效果很差,造成最终的分类准确度较低。因此,若采用本文的方法构建数据集时,RFT网络与其他文献中的网络相比会因数据集维度方面而导致准确率有明显的差异,不一定完全是因为网络结构导致,也就无法直接比较模型之间的准确率优劣。所以本文直接根据不同文献中结论给出不同模型的准确率,如表6所示。

表6 不同文献的手势分类准确率Table 6 Accuracy of gesture classification in different literatures
其中,文献[4]共采集上下按压、前后推拉、手掌翻转、手指摩擦、抓握5种手势,每种手势采集800组,以其中80%作为训练集。本文RFT模型共采集推拉、逆时针旋转、反z滑动、顺时针旋转、下滑、左滑、右滑、斜向左下滑、斜向左上滑、斜向右下滑、斜向右上滑、上滑、正z滑动共13种手势(且模拟复杂噪声环境下采集),每类手势采集80组作为训练集。为针对因数据集维度差异导致无法直接判别模型优劣的情况,在其他复杂下游任务中(如雷达点云成像分类),可以通过增加特征类别和帧数来增加特征-时间数据集的维度,使其可以适应于CNN,便可以直接比较这两种模型之间的准确率优劣。
4 结束语
本文提出了一种基于纯注意力机制的RFT网络用于毫米波雷达手势识别任务。通过固定类别的特征提取方法,与CNN提取特征相比,计算复杂度降低,特征的提取可靠性、可用性、高效性得到提升。通过基于自注意力机制的RFT模型可内部直接关联时序信息,并直接获得所有特征输入。与传统的采用多组并行CNN提取特征再进行特征融合,通过LSTM抽取时序特征的方法相比,系统的结构更简洁、算法复杂度更低、收敛速度更快、更容易训练,且保证了较高的准确率。考虑到RFT模型的高效性和准确性,后续的研究可以将此模型套用到手语识别等复杂分类问题上,且根据Transformer网络已有的研究,在利用此种结构的网络进行复杂分类问题时,应保证样本尽可能多,因此可以考虑使用数据生成网络对数据进行扩充,以获得更好的分类效果。
猜你喜欢
大自然探索(2023年7期)2023-08-15
中国农业信息(2021年3期)2021-11-22
红领巾·萌芽(2019年9期)2019-10-09
小学生学习指导(低年级)(2018年12期)2018-12-29
小学科学(学生版)(2018年12期)2018-12-19
电子制作(2017年13期)2017-12-15
小学阅读指南·低年级版(2017年6期)2017-06-12
电子制作(2016年15期)2017-01-15
火控雷达技术(2016年3期)2016-02-06
百科探秘·航空航天(2015年4期)2015-11-07
