
基于双胞循环神经网络的雷达捷变频行为识别
2024-03-05 10:31孟宪鹏刘利民胡文华
系统工程与电子技术 2024年3期
孟宪鹏, 刘利民,*, 董 健, 王 力,2, 胡文华
(1. 陆军工程大学石家庄校区电子与光学工程系, 河北 石家庄 050003;2. 中国人民解放军32203部队, 陕西 华阴 714200)
0 引 言
雷达行为是雷达在一定的场景中为实现某种目的而相应采取的一系列操作[1-4]。操作涵盖的范围包含了天线、发射机、接收机和信号处理模式等环节[5]。从电子侦察一方的角度看来,雷达行为的表现为发射参数的变化,脉冲体制雷达常用的参数分为脉间参数和脉内参数。脉间参数包含载频(carrier frequency, CF)、脉冲重复周期(pulse repetition interval, PRI)、到达时间(time of arrival, TOA)、到达方向(direction of arrival, DOA)和脉宽(pulse width, PW)[6]。脉内参数主要是脉冲调制类型以及对应的调制参数。脉冲调制类型主要有线性调频(linear frequency modulation, LFM)、Barker码调制、二相编码调制、Costas编码调制以及多相码调制等。不同的调制类型具有各自的优势[7-10],雷达可以根据自身需要选择不同的调制类型,但受限于硬件条件,同一部雷达一般仅能选择有限数量的调制类型。雷达抗干扰时可以选择多种不同的发射参数,其中常见而且比较有效的方法是脉间捷变频[11-12]。脉间捷变并非毫无目的地变化,而是带有很强的目的性[13-15],雷达根据不同的场景使用不同的捷变规律[16-19]。常用的捷变方式有任意固定频率、小范围内快速捷变、在整个调谐范围内快速随机捷变、程控频率捷变和自适应频率捷变[20]。当前,全相参捷变频雷达可以在大带宽内快速随机捷变,如AN/APG-81型有源相控阵雷达[21],干扰机难以跟踪其频点。
为了提高干扰效率,干扰机需要预测雷达的频点,进而实施窄带瞄准式干扰或者欺骗干扰。目前,在雷达和通信电子战领域,针对跳频规律的预测研究较多[22-27],例如针对伪随机跳频序列预测有3种非线性模型:Bernstein多项式预测器、支持向量机(support vector machine, SVM)预测器[28]和径向基(radial basis function, RBF)神经网络非线性预测器[29]。李文情[30]采用时频图的方法对跳频信号进行检测。Li[31]设计了堆叠长短期记忆(long short-term memory, LSTM)网络对基于m序列的伪随机频率序列进行预测。张家树[32]基于混沌理论论述了混沌捷变频伪随机序列的短期可预测性,如m序列、RS(Reed-Solomon)跳频码和基于Logistic-Kent映射设计的跳频码,并针对具有混沌特性的捷变频序列,提出了二阶Volterra自适应预测法和基于非线性函数变换的乘积耦合型自适应预测器。以上方法主要以伪随机捷变频频率序列为研究对象,建立模型做短期行为预测,而针对程控捷变频预测的研究较少。
本文针对雷达捷变频行为中的任意固定频率和程控捷变频模式的识别进行研究,基于非线性时间序列建模的思想,将频率序列从低维空间变换到高维空间,利用数据驱动的方法,采用记忆存储的思想,设计具有状态记忆功能的神经网络,找到高维空间中的函数映射的近似,同时存储每一种程控捷变模式,用于频率序列的在线识别。
1 程控捷变频行为建模
在仅仅考虑抗有源干扰的情况下,雷达可以选择伪随机捷变频的方式发射波形,虽然全相参捷变频雷达可以实现测速、测距和成像功能,然而其实现较为复杂,研究起步晚,所以装备数量较少。程控捷变频可以按照预先设定的频率点进行捷变频,信号处理相对容易,雷达可以预先设定多个频点,形成多个组合,如阶梯步进频编码和Costas编码就是一组具有优良模糊函数特性的频率编码[7,20]。假设雷达从一个有限数量编码集合中选择一个编码调制发射信号[8-9],且对编码集合的任一子集的编码没有使用偏好,那么可以使用均匀分布对编码使用规律进行建模。
1.1 频率编码模型
频率捷变信号模型可以表示为
(1)
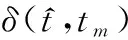
fm=fc+a(m)Δf,m=1,2,…,M
(2)
式中:M表示累积脉冲数量;a(m)表示随机整数,也叫频率调制编码,取值范围为0到N-1;N表示当前编码所含频点的数量,N>M;Δf表示相邻载频间隔。一般而言,为增强脉冲间正交性,令
(3)
式中:k是正整数;Tp是脉冲的宽度[33]。
(4)
令
(5)
(6)
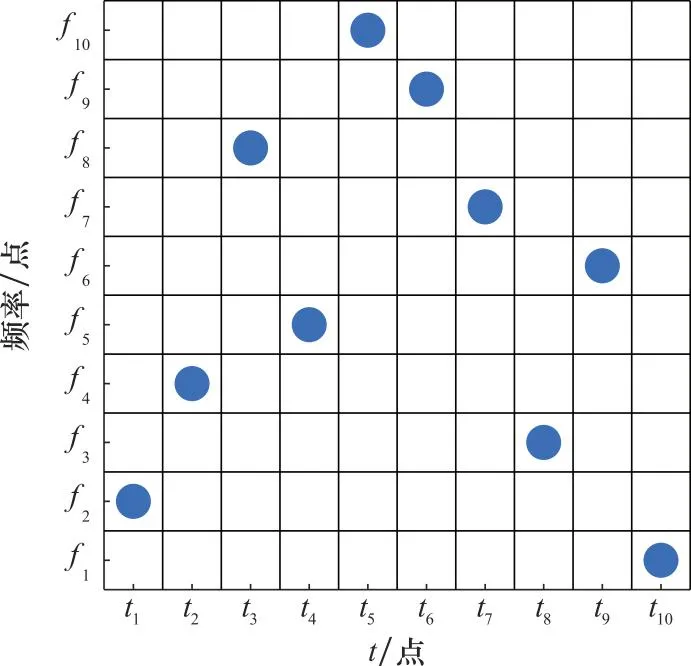
图1 一个10阶Costas编码的频点分布图Fig.1 A frequency distribution map of a 10-order Costas encoding
1.2 雷达捷变频行为建模
当雷达工作在程控捷变频模式时,其使用的频率调制编码数量是有限的。基于这个事实,从干扰方的角度提出随机频率模板的方法对雷达程控捷变频行为进行建模。假设干扰方可以截获所有的发射脉冲,并且所截获的频点序列包含了雷达所有的频率调制编码,那么可以定义一个编码集合描述所截获的编码集合,即
C={ci|i=1,2,…,Nc}
(7)
式中:ci表示第i个频率编码;Nc是频率编码数量。令
(8)
s={o1,o2,…,ok,…,oL},ok∈C
(9)
式中:ok为观测序列s中的某个频率编码;L是观测得到的编码数量。
由于雷达可用编码数量是有限的,可以假设雷达反复使用编码,则干扰方会反复观测到同一编码。理想情况下,当L→∞时,干扰方会观测到足够数量的频率编码,每个频率编码对应一种捷变频行为。这里将任意固定频率的编码视为一种特殊的捷变频行为:在数学上任意固定频率的相邻载频的差值为0。在长期观测雷达反复出现的行为基础上,希望利用数据驱动的方法识别雷达不同的捷变频行为,并能预测该行为模式下的频点序列。
2 循环神经网络
循环神经网络(recurrent neural network,RNN)可以用来处理时间序列数据。随着计算机计算能力的发展和大数据的积累,RNN被广泛应用于自然语言处理、语音识别和机器视觉领域[34-38]。这种网络的设计包含了参数共享的思想:假设序列的未来样本可以由历史样本计算得到,那么在序列的任何一个片段,计算未来样本所需要的映射需要共享相同的参数。同时,RNN也采用了非线性空间变换的思想,将一维的时间序列样本映射到高维空间,并成为隐状态,在这个隐状态空间求出能够共享参数的映射。即
f(t+1)=g(t)(f(t),f(t-1),f(t-2),…,f(2),f(1))=G(h(t-1),f(t);θ)
(10)
h(t)=Γ(f(t),h(t-1);λ)
(11)
式中:h(t)为t时刻的隐状态,相当于历史输入的在高维空间的有损摘要;g(t)为t时刻的序列一步预测函数;f(t),f(t-1),f(t-2),…,f(2),f(1)为从时刻1到时刻t的历史观测频率序列;G为共享相同参数θ的函数,该函数可以利用h(t-1)和t时刻的输入f(t)计算得到t+1时刻的样本f(t+1);Γ为含有共享参数λ的函数,该函数可以将t+1时刻以前的输入序列映射为一个隐状态h(t)。
RNN的计算过程如图2所示[34, 39],图中输入频点f(t)转变为独热向量f(t),U、V、W为变换矩阵,o(t)为t时刻的预测输出,Loss为损失函数,计算公式为
h(t)=Active(W·h(t-1)+U·f(t))o(t)=V·h(t)
(12)
式中:Active(·)为非线性激活函数,此处使用双曲正切函数tanh(x)。利用批量处理随机梯度下降的方法,调整网络参数,使得在观测的数据集上有:
min Loss(f(t+1),o(t))
(13)
式中:Loss取交叉熵损失函数。经过数值计算,得到神经网络的共享参数U、V、W,由于随机梯度下降方法无法保证网络参数能收敛到全局最优解,因此损失函数可能只是在某一个局部极小值处,不一定达到全局最小值。
在训练过程中,需要设定序列预测步数Nstep,Nstep设定过大,会超出很多频率编码的长度,导致训练过程难以收敛;Nstep设定太小,又难以捕捉长序列的规律。由于假设雷达使用的频率编码长短不一,设定短一些相对较好,原因是长序列可以视为由多个短序列相连接而成。RNN不会因为Nstep设定小于较大频率编码长度而无法完成训练,网络可以将长编码按照多个长度为Nstep的编码进行训练。所以,仅仅需要根据干扰引导的需求和雷达跳频速度来设定频率编码预测长度。
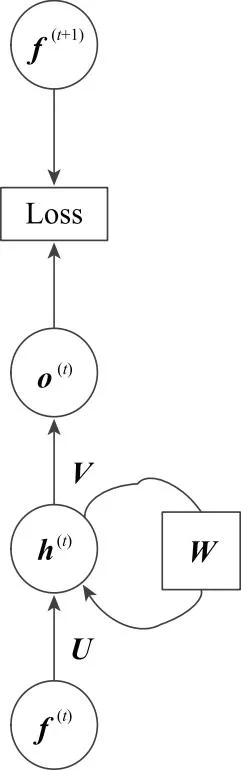
图2 RNN的计算图Fig.2 Computational graph of RNN
3 双胞RNN的设计
虽然隐状态h(t)可以保存历史输入的一个摘要,但是随着输入序列的增加,距离当前时刻较远的输入就会被“遗忘”。为了保留长期记忆,有学者提出了LSTM模型[34,40]。该模型引入了记忆单元,能够根据输入频率序列上下文动态调整时间积累的尺度,这不仅需要单步预测,还需要具备一定的多步预测能力,这就需要RNN能够根据频点序列的前几个输入判断当前序列所属的频率编码。为此,本文提出了双胞RNN(bi-cell RNN, BRNN),用以提高预测能力。其网络结构如图3所示[39]。其中,图3(a)是LSTM单元结构图,单独的LSTM可以由输入控制输入门和遗忘门来对历史序列进行动态截取,而不需要像传统的自回归模型那样建立固定的线性关系。这种设计使得LSTM可以灵活地控制在下次预测时所采用的历史信息的长度。但是,单独的LSTM单元也有局限,就是容易产生“偏见”,即一个记忆单元根据历史输入序列生成的有损摘要可能有很大的信息损失,从而导致无法根据这个有损摘要判断当前的上下文环境。因此,添加了一个并列的LSTM单元,由两个记忆单元共同预测,再对两个预测结果加权,得到实际的预测,其结构如图3(b)所示。
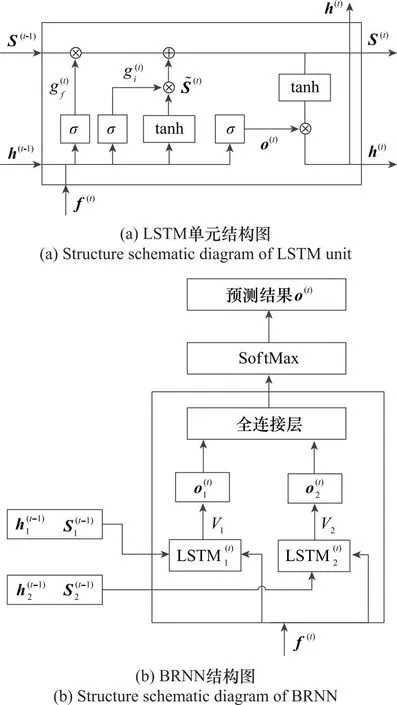
图3 BRNN的组成Fig.3 Illustration of the BRNN
一个LSTM的计算过程[39]如下:
(14)
(15)
(16)
(17)
(18)
(19)

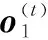
(20)
经过全连接层线性变换后,再由SoftMax函数将向量转化为类似概率分布的向量[39],得到预测结果o(t),即
(21)
式中:W是全连接层矩阵的参数。该参数的作用是综合两个记忆细胞单元的判断,防止发生“偏见”。两个记忆细胞单元属于并列结构,由于初始值为随机数,在训练的过程中,两个记忆细胞单元的输出分布并不完全相同,且对历史输入都有独立的有损摘要,所以设立两个细胞的加权输出可以得到稳健的预测。预测频点为
f(t+1)=Index(max(o(t)))
(22)
式中:Index(·)为取下标函数;max(·)为取最大值函数。
4 实验设置和评价指标
训练集可选频点数量为25,共选择了36个Costas频率编码和5个固定频率编码,最短的频率编码长度为8,最长的频率编码为16。训练集由随机选择的频率编码前后连接构成,每个编码被选择的概率相等,训练集有1 000个编码。用相同的方法生成测试集,编码的数量为200,在蒙特卡罗仿真过程中,每次测试都重新生成测试集。
训练步数Nstep指的是模型每次迭代训练过程中选取的训练数据的长度,不同的取值可能会对模型精度有影响,下文会讨论这一点。设置批处理大小为50,训练次数设为300,学习率设为0.01,蒙特卡罗仿真次数为1 000次。

(23)
(24)
每次仿真会输出两种正确率曲线,利用1 000次仿真结果,分别求取两种预测正确率的均值,同时求出预测结果的方差。用以表征预测正确率随时间推移的变化趋势和捷变频行为识别能力,即预测正确率随时间推移趋于平稳,说明预测模型能够以一定概率正确预测未来的频点。方差趋于0,说明该模型能够以一定概率稳定识别当前频率序列所属的捷变频编码。
5 结果与讨论
5.1 训练参数与预测平均正确率的关系
BRNN方法预测平均正确率可以收敛,训练步数Nstep会影响正确率,Nstep越大,非线性变换函数越复杂,模型拟合难度越大;Nstep小,模型难以捕捉到频率编码变化的规律。在雷达发射编码未知的条件下,需要根据训练集调整Nstep,BRNN方法的预测正确率结果如图4和表1所示。
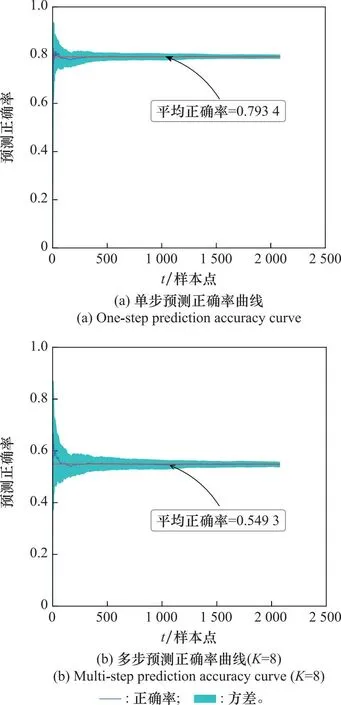
图4 预测正确率曲线Fig.4 Prediction accuracy curve
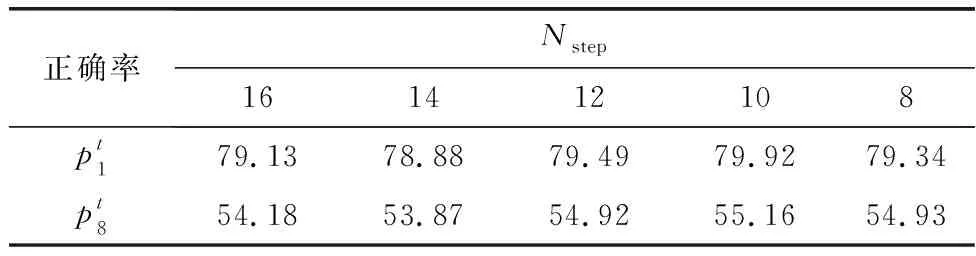
表1 不同Nstep时的预测平均正确率Table 1 Prediction average accuracy with variant Nstep %

表1是不同Nstep条件下的预测平均正确率,由于相参雷达一个相干处理间隔的脉冲至少为8,因而训练步数选取的是从8到16之间的偶数。选择步数太大,则明显超过了很多频率编码的长度,导致无意义的训练结果。表1中,单步预测正确率在79%上下波动,8步预测正确率在54%上下波动,可见在8到16这个区间范围内,选取Nstep不会对预测正确率有明显的影响。
5.2 不同方法的平均单步预测正确率对比
传统的捷变频序列预测方法主要有反向传播(back propagation, BP)神经网络、RBF神经网络、二阶Volterra自适应滤波器和LSTM方法。前3种一般应用于混沌时间序列的建模,需要精细调整建模参数,LSTM是RNN方法的一种[41],BP方法、RBF方法和Volterra方法模型在实验数据上进行多步预测时模型失效。因此,比较指标仅设定为单步预测的平均正确率,结果如表2所示。

表2 不同方法单步预测平均正确率Table 2 One-step prediction average accuracy of different methods %
表2中,参考方法的参数如下:BP神经网络采用4个隐藏层,每一层有10个,分别为输入层、2个隐藏层和输出层,2个隐藏层的节点数量均设为20;RBF神经网络采用30个隐藏节点,利用普通最小二乘(ordinary least square,OLS)算法进行训练,输入层和输出层的节点数量都是1;Volterra自适应滤波器采用2阶Volterra核进行非线性扩展,再利用有限冲击响应的时间正交算法确定非线性部分的系数。LSTM的网络结构如图3(a)所示。
BP神经网络、RBF神经网络和Voltrra方法都难以对程控捷变频序列进行预测。虽然这3种方法都采用了非线性变换的思想,但建立的模型并未对频率编码进行识别。混沌序列的预测可以利用相空间重构的方法,m序列和RS序列的预测可以用BP神经网络、RBF神经网络进行拟合,其思想采用了单步预测思想,即t时刻的频点值与t-1时刻的值有关。二阶Volterra自适应滤波器将t时刻前的一段历史序列进行非线性变换,得到高维空间特征,再用线性最小二乘滤波器求取最优权值,运算量大,不具有通用性,需要手动调整超参数。而LSTM模型和BRNN模型同为RNN模型,LSTM相比BRNN在无测频噪声条件下的预测正确率约高1.4%,可能原因是理想条件下单LSTM单元比双记忆单元判断能力更强,不会出现双记忆单元加权“权衡”的现象。
5.3 无噪声小样本条件下的性能
干扰方的接收机存在测频误差,由于窄带瞄准式干扰具有一定的带宽,干扰方可以以瞬时干扰带宽为间隔将雷达的捷变频范围划分为若干离散的频段。这样,即便存在测频误差,只要偏差在干扰带宽内,就可以认为是有效的干扰引导频率。然而,总有测频误差出现较大偏差的情况发生,本文称其为测频噪声,当测频序列不含测频噪声时,在不同训练样本数量Ntrain下的预测平均正确率如表3所示。

表3 不同训练样本数量下的预测平均正确率Table 3 Prediction average accuracy in different Ntrain conditions %
从表3可以看出,随着训练样本数量的减少,单步预测和8步预测的平均正确率都降低,但随着样本数量的增加,预测正确率的增长逐渐变得平缓,说明模型在样本数量到达一个阈值后,达到了预测能力的上限。本文使用的训练集的频率编码数量是41,样本数量越大,意味着每个频率编码重复次数越多。当样本数量达到6 307时,由于编码出现的概率服从均匀分布,平均每个编码样本出现了约15次。在这种条件下,模型的学习能力趋向饱和,因此预测正确率趋向稳定值,饱和条件下的样本重复次数不仅和模型有关,也和频率编码集合有关。但由于不能假设编码集合完全已知,只能假设干扰方能够侦测到足够数量的频点,以及频率编码出现概率服从均匀分布,因此只能根据实验估计模型饱和时所能达到的预测平均正确率。
5.4 含测频噪声条件下的性能
下面讨论LSTM模型和BRNN模型在测试集频率序列含有测频噪声条件下的预测正确率。假设测频误差范围在单位Δf内,用±1表示,每个频点误差出现的概率为Perr。两种模型的预测结果如图5所示。
从图5可以看出,随着测频误差概率Perr的增大,两个模型的平均预测正确率都在下降。BRNN的预测平均正确率要高于LSTM模型,在测频误差概率为0.1时,无论对于单步和8步预测平均正确率,两种模型性能相差约3%。但随着测频误差概率的增大,两个模型之间的性能趋同,当测频误差概率为0.5时,BRNN的单步预测平均正确率为20.09%,而LSTM的预测平均正确率为19.60%;8步预测平均正确率分别为15.65%和15.01%,性能相差在1%以内。BRNN总是比LSTM抗测频误差能力强,这说明双胞记忆的结构要优于单独的记忆单元。
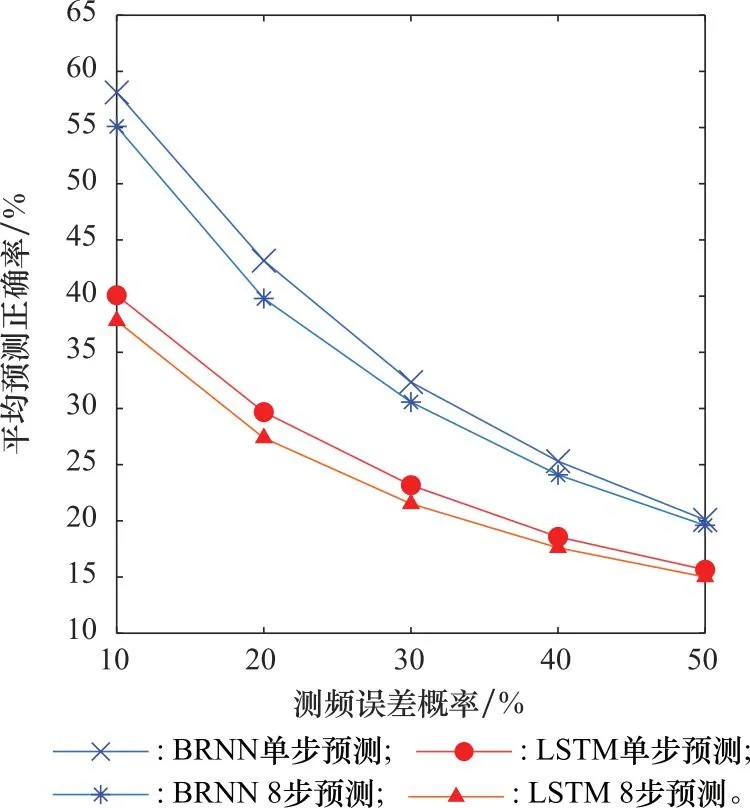
图5 平均预测正确率随测频误差概率的变化曲线Fig.5 Curve of average prediction accuracy with frequency measurement error probability
5.5 含测频噪声小样本条件下的性能
最后,本文探讨在有测频噪声的条件下,训练样本数量对预测正确率的影响。设定Perr为0.1,噪声幅度为1,比较了5种训练样本数量条件下两个模型的平均预测正确率,结果如图6所示。
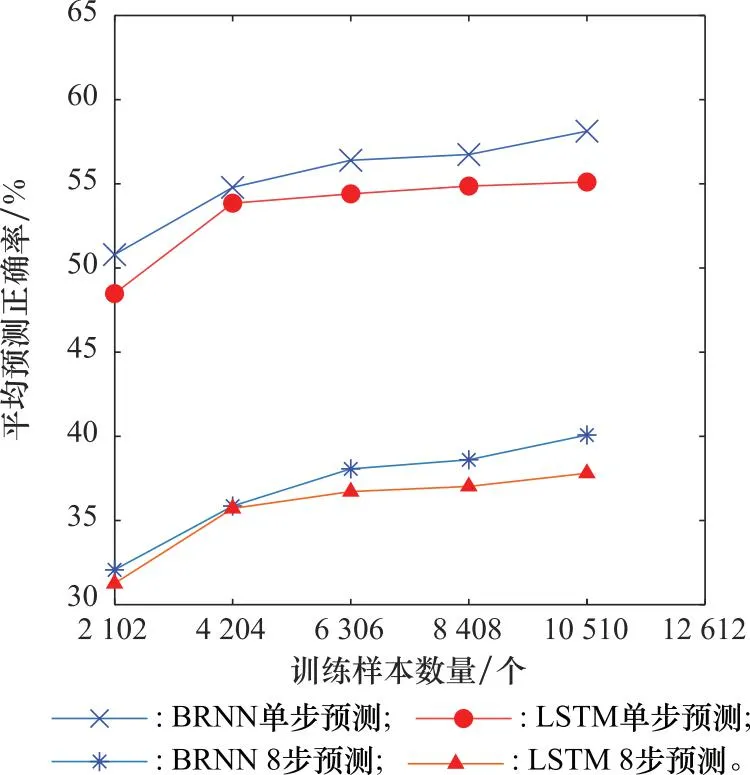
图6 平均预测正确率随训练样本数的变化曲线Fig.6 Curve of average prediction accuracy with number of training samples
从图6可以看出,在含噪声条件下,不论是单步预测或是8步预测,训练样本数量越多,模型的平均预测正确率越高,且BRNN的表现始终好于LSTM。给定10 510个训练样本,BRNN的单步预测正确率能达到58.13%,8步预测的正确率达到40.08%,而LSTM的两种预测正确率分别为55.11%和37.81%。随着训练样本数量的减少,两种模型的性能差别也在减小,但样本数量低于4 204时,LSTM比BRNN的性能下降更快。以上结果说明:BRNN在有测频噪声的条件下性能好于LSTM,双胞记忆的效果要好于单独的记忆单元,抗测频误差的能力更强。
6 结 论
针对雷达程控捷变频现象,本文提出了雷达程控捷变频行为的模型,将捷变频行为识别问题转化为频率编码的识别问题,采用非线性变换和维度变换的思想,利用LSTM单元的优势设计了BRNN,并提出了单步预测正确率和多步预测正确率的评估指标,讨论了模型超参数、训练样本数量以及测频噪声对模型性能的影响。对比其他方法可知,BRNN能够有效识别雷达程控捷变频率编码,识别能力要优于传统的频率预测方法,在有测频噪声的条件下,识别效果好于LSTM。在有限数量的频率编码集上,RNN的记忆单元可以根据频率编码的初始频点识别当前编码,并能以一定的正确率预测下一个频点或者多个频点。
程控捷变频的频率编码集合属于有限个非线性时间序列集合的一种。本文研究结果表明,在输入时间序列是由该集合中的序列随机组合而成的条件下,BRNN模型可以根据时间序列的初始输入“激活”该时间序列的有损摘要,进而判断当前时刻输入所处的时间序列。该结果也说明,BRNN可以将一维时间序列映射到高维空间,并在高维空间找到含有共享参数的映射函数,效果优于手动提取高维特征的方法。
猜你喜欢
广东通信技术(2023年9期)2023-10-29
中华养生保健(2020年7期)2020-11-16
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
设备管理与维修(2016年7期)2016-04-23
电信工程技术与标准化(2015年10期)2015-12-22
自动化博览(2014年4期)2014-02-28
河南科技(2014年23期)2014-02-27
河南科技(2014年3期)2014-02-27
