
不平衡数据下基于SVM增量学习的指挥信息系统状态监控方法
2024-03-05 10:21焦志强张杰勇姚佩阳
系统工程与电子技术 2024年3期
焦志强, 易 侃, 张杰勇, 姚佩阳
(1. 空军工程大学信息与导航学院, 陕西 西安 710077; 2. 中国人民解放军95910部队,甘肃 酒泉 735018; 3. 信息系统工程重点实验室, 江苏 南京 210007)
0 引 言
近年来,随着指挥信息系统网络化、智能化的理念不断加深,基于面向服务的思想体系结构(service-oriented architecture, SOA)构建指挥信息系统势在必行,并已经取得了长足的发展[1]。新一代指挥信息系统将以军事作战云为依托,将各个功能模块以服务的形式部署到各个节点中,以实现功能模块之间的解耦,从而为提高系统整体的敏捷性提供基础。指挥信息系统作为现代战场上的粘合剂和战斗力的倍增器,不可避免地需要面对高对抗、强干扰的复杂作战环境,由于系统运行状态的正常与否将直接影响整体作战效能,因此亟需对其状态进行实时监控以及时发现异常并执行相适应的演化策略,从而维持指挥信息系统的正常运转。
针对系统状态的监控问题,许多云服务提供商已经将资源运行状态数据作为一种关键服务向用户开放,并开发了相应的云环境下资源监控工具。例如,Amazon的CloudWatch、Microsoft的Azure Monitor等。这些工具通过对CPU/RAM利用率、网络流量、响应时间等指标的监控和处理,分析用户订购服务的运行状态并为用户进行预警。在这个背景下,系统状态的监控问题在民用领域涌现出了大量研究[2-5]。
与此同时,针对指挥信息系统状态监控的研究还处于起步阶段。文献[6]考虑了监控系统在监控图生成、集中监控和扩展性等方面的不足,为了在已有系统上实施全方位监控,提出了一种基于分层式插件化架构的一站式综合监控系统,并对该系统的总体架构进行了论述,分析了其中的插件设计、通用结构树和虚拟图元等关键要素。文献[7]从故障诊断的角度出发,利用监控代理对系统相关数据进行收集和分析,提出了故障诊断专家系统的总体结构,但并未对具体方法做深入的研究。文献[8]则分析了指挥控制网络存在的问题,提出了建立实时流量监控系统的思路,并基于WinPcap体系结构设计了面向指控网络的流量监控系统架构。可以看到,已有研究偏重于对指挥信息系统状态监控总体结构的构建,而在监控方法层面的研究还有待进一步深入。
指挥信息系统作为军事信息系统,其部署的空间更为分散,对状态监控的实时性要求也更为苛刻。同时,由于系统状态数据的保密性问题,历史监控数据不能像民用系统一样进行分享和传播,因此在初期可能无法拥有足够多的训练样本。此外,就状态监控问题本身而言,其正常状态的样本数量肯定大于异常状态的样本数量,这种样本类别间的不平衡将有可能导致漏警率偏高的情况出现,这些都对指挥信息系统的状态监控造成了困难。从技术手段上看,系统状态监控本质上是一种分类问题,即通过各类指标数据将当前状态分为正常或是异常。常见的方法有:基于贝叶斯后验概率的统计分析方法[4-5];基于最近邻的分类方法[9-10]、基于支持向量机(support vector machine, SVM)的分类方法[11-12]、基于深度学习的分类方法等[13-14]。考虑到SVM在解决分类问题中的小样本、非线性和高维数据特征上具备良好的性能[15],本文基于SVM提出了一种面向不平衡数据的SVM增量学习方法(incremental learning method for unbalanced data based on SVM, ILMUDSVM),该方法利用过采样的思想对样本集合进行补充以平衡各类样本间的数量关系;以KKT(Karush-Kuhn-Tucker)条件为基础,放松了模型更新触发的条件,尽可能减少了模型更新的次数;通过定义重要度对每次模型更新后的样本集合进行优化筛选保留;并在学习过程中引入遗忘率以降低模型更新的时间开销,从而有针对性地解决了指挥信息系统的状态监控问题。
1 问题描述
指挥信息系统的状态监控本质上是一个分类问题,即根据数据采集系统得到的各类参数对系统当前状态做出判断。假设当前系统的各项参数为z∈Rn×1,系统状态可以表示为Sys=f(z),若Sys=-1时表示系统正常运行,若Sys=1则表示系统运行出现异常。因此,本文要解决的问题就是寻找一个映射函数f(·),使得系统状态能够被准确地判断。考虑到指挥信息系统的状态监控问题具有初始样本少、实时性要求高和数据不平衡等特点,本文以SVM为基础设计了一种系统状态监控方法。下面首先对SVM过程进行简单介绍。
SVM的核心思想就是在样本空间中找到一个最优的分类超平面,根据样本点相对于分类超平面的位置将样本集分为不同的类别。假设给定的样本集为{(xi,yi)|xi∈Rn×1,yi∈{-1,+1},i=1,2,…,m}。其中,xi为样本的属性向量;n为属性的个数;yi为样本的标签,若yi=yj,则说明样本i和样本j属于同一个类别;m为样本集中所有样本的个数。在给定样本集后,需要对SVM进行训练以得到针对该样本集的分类模型,从而对后续未知类别的样本进行分类。
利用样本集对SVM进行训练就是寻找最优分类超平面的过程,如图1所示。可以看到,两类样本分别位于分类超平面的两侧。两类样本点中距离分类超平面最近的样本点被称为支持向量,支持向量到超平面的距离为d,该距离直接决定了两个类别间的间隔边缘。分类超平面的最优性体现在间隔边缘上,即认为间隔越大分类效果也就越好。图1(a)和图1(b)分别显示了同一个样本集下的两个分类超平面,根据上述定义,可以发现图1(b)中的分类超平面明显优于图1(a)中的分类超平面。因此,SVM本质上就是寻找一个令间隔边缘最大的分类超平面。
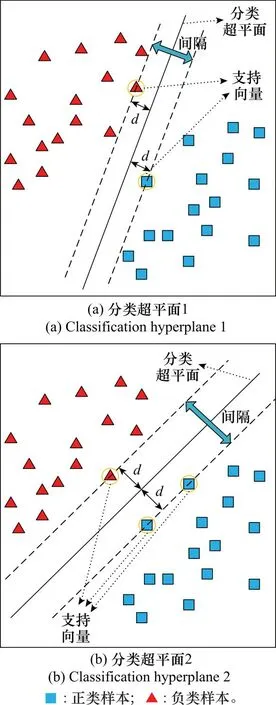
图1 SVM原理示意图Fig.1 SVM principle diagram
在给定样本集后S,分类超平面可以用以下线性方程来描述:
ωTx+b=0
(1)
式中:ω∈Rn×1和b分别为最优分类超平面的法向量和截距,可通过求解以下优化问题得到。
优化问题1:
(2)

ωTx+b=0,
(3)
需要注意的是,在计算b时可以选取任意在最大间隔边界上的支持向量进行计算。
2 面向不平衡数据的SVM增量学习方法
2.1 不平衡数据的处理
针对样本数据的不平衡性,现有的工作一般通过减少或增加相应样本的方式来处理,即欠采样[16]和过采样[17]。欠采样方法会导致一些样本信息的丢失,从而造成模型分类效果的下降。而经典的过采样方法在过采样时具有一定的盲目性[18],容易导致合成的新样本质量较差。因此,需要有针对性地生成高质量的新样本以进一步提升模型训练效果。基于上述分析,本文首先利用样本集进行SVM预训练,然后利用支持向量在预分类面附近产生有潜力的新样本,同时借鉴文献[19]中分带过采样的思想,根据距离进行分带,然后逐带生成均匀分布在当前带内的新样本以保持各类样本数量的平衡。
2.1.1 基于支持向量的新样本生成
在进行预分类得到预分类超平面ω′Tx+b′=0和支持向量集合SV′={sv′+,sv′-}后,根据每个类中支持向量的数量来确定需要生成的新样本数量。假设正类为样本数量少的一类,其样本数量为m+,负类样本数量为m-(m++m-=m),则利用支持向量生成的新样本数量为

(4)

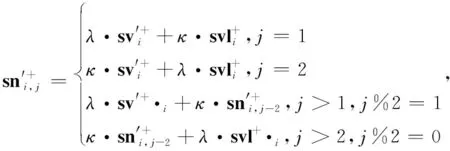
(5)
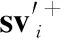

图2 基于支持向量的新样本生成过程示意图Fig.2 Schematic diagram of new sample generation process based on support vector
本文提出的基于支持向量的新样本生成算法如算法1所示。

算法 1 基于支持向量的新样本生成算法输入 样本集合{(xi,yi)},利用支持向量生成新样本的比率α,参与新样本生成的支持向量个数m+sv步骤 1 利用样本集合{(xi,yi)}进行SVM预训练,得到支持向量集合SV'={sv'+,sv'-};步骤 2 根据α和样本集合中正类样本和负类样本的个数确定需要生成的新样本个数msvnew;步骤 3 计算正类支持向量到其类中心的距离csn'+,对其进行降序排列,并选取前m+sv个作为生成新样本的支持向量;步骤 4 计算每个支持向量应该生成的新样本数m+svi,初始化集合Ssv;步骤 5 对于每个被选中的支持向量利用式(5)生成新样本,并加入到Ssv。输出 由支持向量产生的新样本集合Ssv
在第2.1.1节的基础上,为了使新产生的样本更加均匀的散布在当前带内,本文提出了一种基于分带的过采样方法。该方法利用分带的思想对样本空间进行划分,并根据样本所处的分布选择相应的样本以在样本分布稀疏的区域生成新样本。
2.1.2 样本空间的分带过程
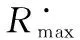
(6)
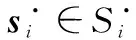
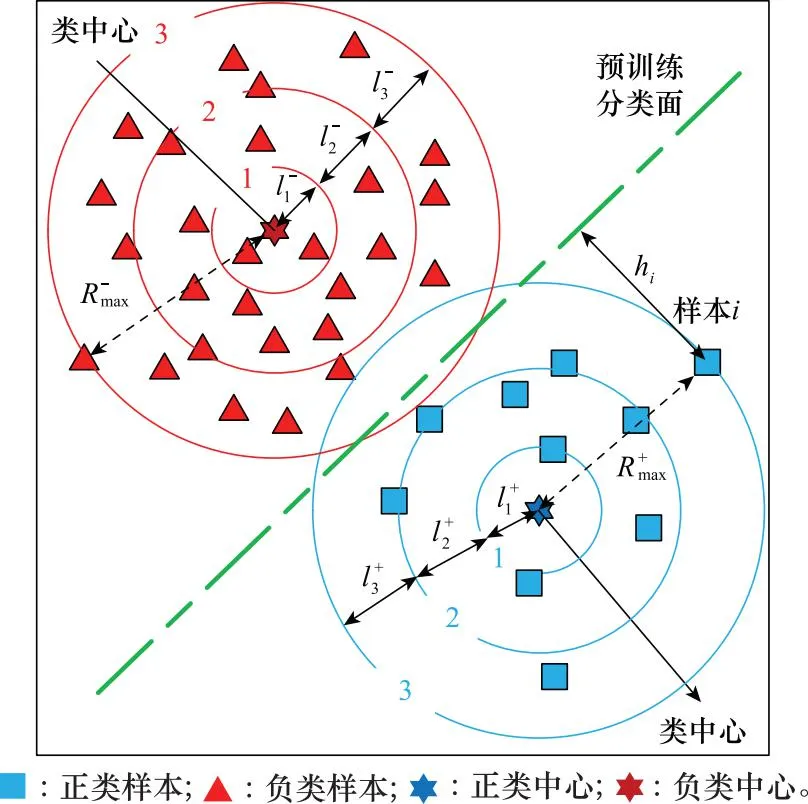
图3 样本空间分带示意图Fig.3 Schematic diagram of sample space zoning
2.1.3 基于分带的新样本生成
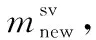
(7)
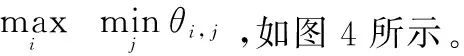
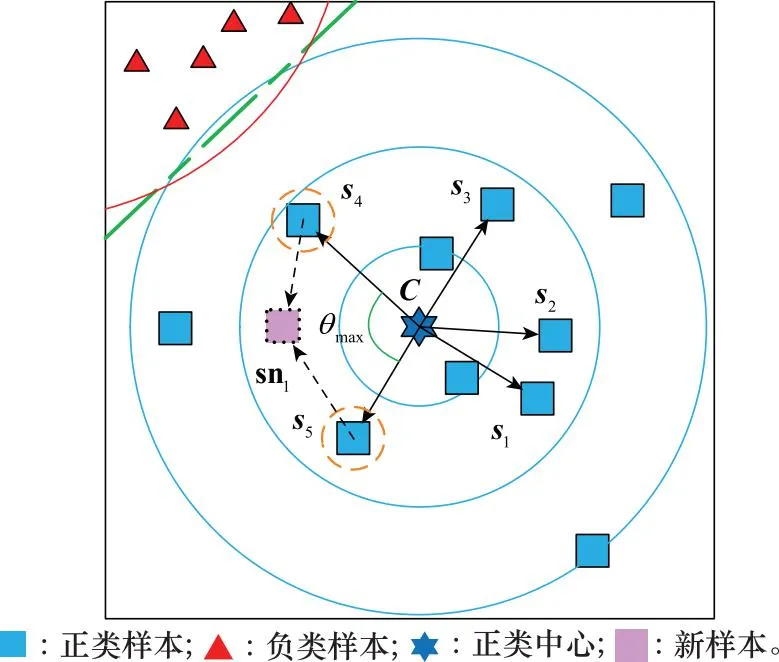
图4 带内新样本生成过程示意图Fig.4 Schematic diagram of in-band new sample generation process
在图4中可以看到,θmax表示相邻向量间的最大角度,意味着在该带内样本4和样本5间的角度间隔最大,为了使新样本分布均匀,可以利用样本4和样本5生成一个介于上述样本间的新样本sn1。
在得到样本对(si,sj)后,新样本可以表示为
(8)
snk=ν(si-C)+(νsj-C)+C=νsi+νsj-(2ν-1)C
(9)
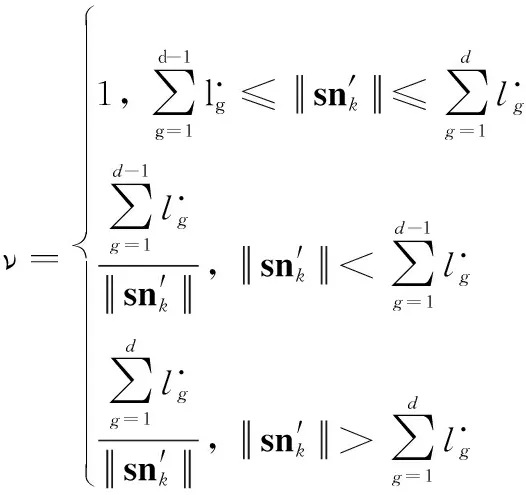
(10)

(11)
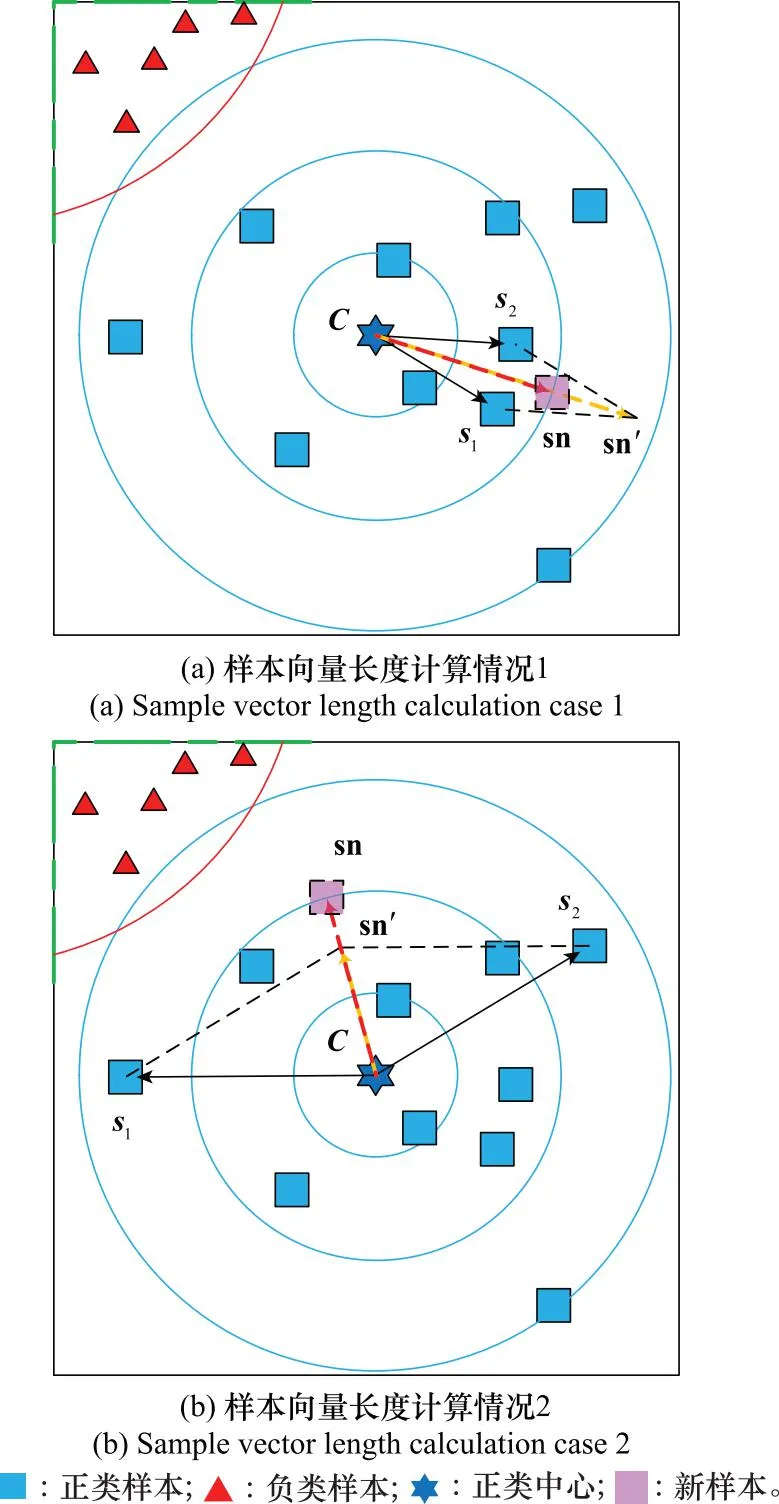
图5 样本向量长度计算过程示意图Fig.5 Schematic diagram of sample vector length calculation process

图6 样本向量的反向过程示意图Fig.6 Schematic diagram of reverse process of sample vector
综上,基于分带思想的过采样算法如算法2所示。

算法 2 基于分带思想的过采样算法输入 样本集合{(xi,yi)},支持向量集合SV'={sv'+,sv'-},利用支持向量生成新样本的比率α,分带数q步骤 1 利用式(6)对非支持向量集合{(xi,yi)}/SV'中的样本进行分带;步骤 2 利用式(7)计算每个带内需要产生的新样本个数mfd;步骤 3 令新样本集合Snsv=ϕ,对于每个带内的样本进行如下步骤:步骤 3.1 令mfcd=0;步骤 3.2 计算带内样本集合Setd中最大相邻夹角θmax,确定被选中的向量si和sj;步骤 3.3 利用式(11)计算得到新样本sn;步骤 3.4 将新样本sn加入到当前带内样本集合中,Setd←Setd∪sn,并在新样本集合中保存该新样本Snsv←Snsv∪sn;步骤 3.5 令mfcd=mfcd+1,若mfcd=mfd,则当前带内新样本生成结束;否则,转步骤2)。输出 由非支持向量产生的新样本集合Snsv
2.2 SVM增量过程
考虑指挥信息系统的特殊性,其系统状态监测数据在初期可能不会非常全面,需要在其运行过程中不断地积累,这就对SVM的增量过程提出了需求。对于增量学习过程的研究大多集中于KKT条件[20-21]。在此基础上,许多工作得以进行展开[22-24],并出现了大量的增量SVM方法。这些方法大多是基于以下流程:首先判断新样本集中是否存在违反KKT条件的样本,在此基础上分析有可能成为新支持向量的样本并组成待训练样本集St,然后利用St进行训练,从而得到新的SVM模型。
2.2.1 模型更新的触发机制
对于优化问题1,样本集中的每个样本都应该满足以下KKT条件:
(12)
当新样本xnew到来时,可以假设其对应的拉格朗日系数anew=0,计算判定式yif(xi)-1,若其大于0,则认为该样本满足KKT条件,模型无需进行更新;否则,需要考虑对SVM进行重新训练。这里,为了减少在线学习时模型的频繁更新的情况,可以考虑将判定式放宽松为yif(xi)+μ-1。其中μ为模型更新触发的松弛系数。从图7中可以看到,新样本A(μ∈[2,+∞)),B(μ∈[1,2))和D(μ∈[0,1))均违反了KKT条件,这说明此时的分类超平面理论上不是最优的,需要进行模型的更新。但如果只从分类结果上看,样本D的分类结果还是正确的,因而这里可以考虑不对模型进行更新。当然,由于样本D的特殊性,其距离当前分类超平面很近,后续成为支持向量的可能性非常大,样本D应当被加入到保留集中,待下次模型更新时再做考虑。需要注意的是,若出现了类似样本A和B情况的样本,则当前模型必须进行更新。综上,μ的值应当介于0到1之间,其值越大则触发机制越为宽容,从而减小模型更新的频率。
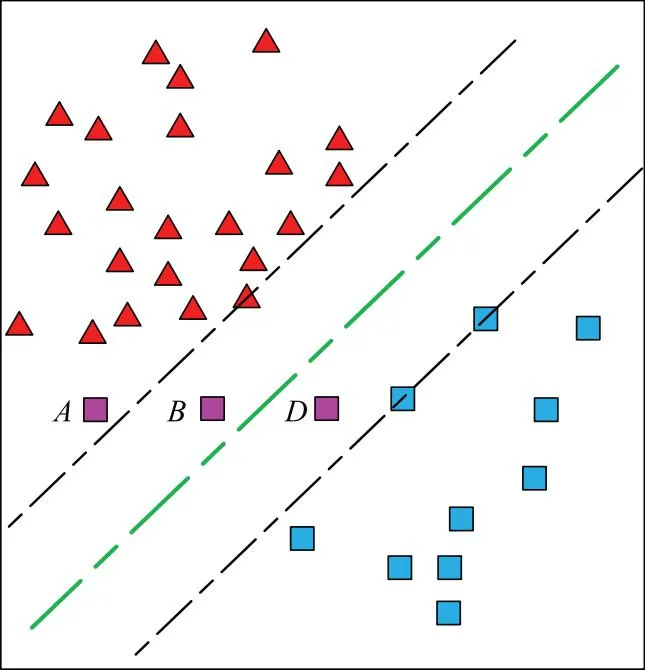
图7 新样本违背KKT条件的3种情况Fig.7 Three cases where the new sample violates the KKT condition
2.2.2 保留集的选取
对于样本i,其重要度反应了其后续可能成为支持向量的可能性。这里给出一个假设,即距离分类面越近,同时距离类中心越远的样本更有成为支持向量的潜力。基于这个假设,可以将样本i的重要度定义为
(13)

在得到排序的样本集后,保留集SR由重要度高的前γ%样本组成,而对于重要度低的样本,则可以通过设定以遗忘率p∈[0,0.5]对重要度较低的样本进行遗忘以减少后续保留集更新的计算量。
这里需要注意的是,该遗忘策略的执行是有前提条件的,即当前样本数量足够多并且已经能够基本体现出总体样本的分布情况。在这个前提下,后续新样本的加入对于分类面的影响将会比较小,分类超平面也不会出现太大的偏移和旋转,被遗忘的样本成为支持向量的可能性也就将维持在一个很低的水平。
图8 正负样本的重要度排序示意图Fig.8 Schematic diagram of importance ranking of positive and negative samples
2.2.3 增量过程中不平衡数据的处理
在SVM的增量过程中,可能成为新支持向量的样本集St本身已经在原有样本集上进行了筛选,如果采用欠采样的方式继续对该集合中的样本进行舍去,将很有可能损失一些有价值的训练样本,从而导致SVM模型的性能下降。基于上述分析,这里仍然使用过采样的方式补充相应样本。借鉴第2.1.3节中新样本的生成,这里对于St中的样本采用式(5)和式(11)产生新的样本并加入到St中,以在增量过程中适应系统监控数据样本不平衡的特点。
综上所述,本文提出的基于SVM增量学习的C4ISR(command, control, communication, and computer, intelligence, surveillance and reconnaissance)系统状态监测算法总体流程如算法3所示。

算法3 基于SVM增量学习的C4ISR系统状态监测算法输入 初始样本集合S0,增量样本集合Si(i=1,2,…,T)离线阶段:步骤 1 设定参数:利用支持向量生成新样本的比率α,分带数q,保留比例γ,遗忘率p,模型更新触发的松弛系数μ;步骤 2 利用算法1生成由支持向量产生的新样本集合Ssv;步骤 3 利用算法2生成由支持向量产生的新样本集合Snsv;步骤 4 对Sz=S0∪Ssv∪Snsv进行SVM训练,得到并输出初始分类模型M0;步骤 5 利用式(13)计算Sz中的样本重要度,并根据保留比例γ生成保留集SR,令i=1;在线阶段:步骤 6 若i≤T,接受新样本集Si,否则转步骤12;步骤 7 利用判定式yif(xi)-1筛选出Si中需要参与训练的样本,形成集合S'i,并令Sz←SR∪S'i;步骤 8 利用判定式yif(xi)+μ-1判断新加入样本是否触发模型更新条件,若存在满足更新条件的样本则执行步骤9,否则,执行步骤11;步骤 9 将Sz作为输入,利用算法1和算法2生成新样本集合S'sv;步骤 10 对Sz=Sz∪S'sv进行SVM训练,得到并输出初始分类模型Mi;步骤 11 利用式(15)计算Sz中的样本重要度,并根据保留比例γ生成保留集SR,根据遗忘率p对Sz中的样本进行遗忘,转步骤6;步骤 12 算法结束输出 实时输出SVM分类模型
其中,步骤1~步骤5属于离线阶段,利用已有样本进行训练以得到一个初始的分类模型。步骤6~步骤11属于在线阶段,根据新样本集对分类模型不断更新以改善分类效果。由于SVM在小样本情况下也能够表现出良好的性能,因此算法3能在初始样本集中样本数量较少的情况下获得不错的分类效果。此外,该算法在离线和在线两个阶段都存在着样本的过采样操作,能够在线处理系统监控过程中样本集的不平衡问题。
3 仿真验证
本文利用真实系统中的数据对算法进行测试以验证本文所提算法的有效性和优越性。Bookstore系统是具有B/S架构的分布式系统,主要功能包括:用户注册和登录,商品搜索和显示,广告推荐以及线上支付等功能。Bookstore结构逻辑较为复杂,且运行环境动态,需要为数量庞大的用户群提供服务,因此其容易出现异常,方便收集到相应的异常状态信息,适合作为监控的对象。
在本实验中,主要对Bookstore系统的5项参数进行监控,即响应时间、错误率、中央处理器利用率、内存利用率以及存储负载,并通过这些参数对系统的状态进行判断。在此基础上,样本集合可以表示为
{(xi,yi)|xi∈Rn×1,yi∈{-1,+1},i=1,2,…,m},
xi={ResponseTime,ErrorRate,CPU,RAM,Load}
式中:ResponseTime为系统响应时间;ErrorRate为错误率;CPU为中央处理器的利用率;RAM为内存利用率;Load为系统负载。
通过运行和收集Bookstore系统运行过程中的相关参数,本文得到了500个带标签的样本,其中系统状态正常的样本320个,系统异常的样本180个。为了充分体现算法的持续学习能力,这里选取200个样本作为初始学习样本集合,100个作为测试样本,其他200个样本则平均分为10组,用于验证算法的学习过程。需要注意的是,为了反映算法应对不平衡数据的能力,初始学习样本中,正常状态样本数量设定为150,异常状态样本数量设定为50。为了更好地对分类算法的性能进行评估,采用G-means[25]和F-measure[26]两种指标对本文所提算法进行评价。当TP=0时,召回率和精确率都将归零从而造成F-measure无法计算。为了处理这种情况,当分类器将测试集中的所有正类样本都预测为负类时,认为本次分类失败,分类器的F-measure记为零,并对失败的次数进行统计为后续计算分类的成功率提供依据。
由于训练集、测试集以及学习集中的样本是随机选取的,本文通过蒙特卡罗模拟的方式进行1 000次随机实验以测试算法的性能。同时,为了体现本文所提算法在增量学习和处理不平衡数据上的优越性,实验将本文所提出的算法与SVM、SVM+INV(incremental variation)、SVM+UB(unbalanced)算法进行了比较。其中,SVM即为不带学习策略的经典SVM算法;SVM+INV为带有学习机制的SVM算法;SVM+UB为带有不平衡数据的处理过程的SVM算法。SVM和SVM+UB算法由于没有学习机制,在每次新增样本集到来时直接与已有样本集合并进行重新训练,实验结果如下所示。
图9显示了SVM、SVM+INV、SVM+UB和本文算法的G-means指标、F-measure指标和分类准确率。可以看到,SVM和SVM+INV算法由于不具备不平衡数据的处理机制,在G-means、F-measure和分类准确率3个指标上的表现较差;SVM+UB和本文算法则通过对不平衡数据的处理机制,在各个指标上均获得了更好的效果。此外,可以看到具备学习机制的算法(SVM+INV和本文算法)的G-means、F-measure和分类准确率3个指标相比于每次都使用全部样本进行训练的算法(SVM和SVM+UB)将略有下降,这是由学习机制中保留率和遗忘率的存在使得每次参与训练的样本个数减少所造成的,但这同时也降低了单次训练的复杂程度。在表1中可以发现,具有学习机制的算法在训练样本个数上要明显少于对应的非学习算法。表2显示了各算法的平均训练时间,具备不平衡数据处理机制的算法运行时间要高于不具备不平衡数据的处理机制的算法。需要注意的是,从理论上看,算法的运行时间应当与参与训练的样本个数成正比关系。由于具有学习机制的算法需要每次对保留集进行选取,这部分时间也将被计算在总训练时间内,因此在表1中SVM+INV的训练样本个数虽然小于SVM算法,而在表2中其训练时间却高于SVM算法。但随着样本这数量的上升样本总数量的上升,在SVM训练过程中节约下来的时间将会弥补这一额外的时间开销,以SVM+UB与本文算法的时间开销为例,在初始阶段本文算法的时间开销略高于SVM+UB,但随着学习过程的进行,到第10次学习阶段时本文算法的时间开销明显低于了SVM+UB算法。
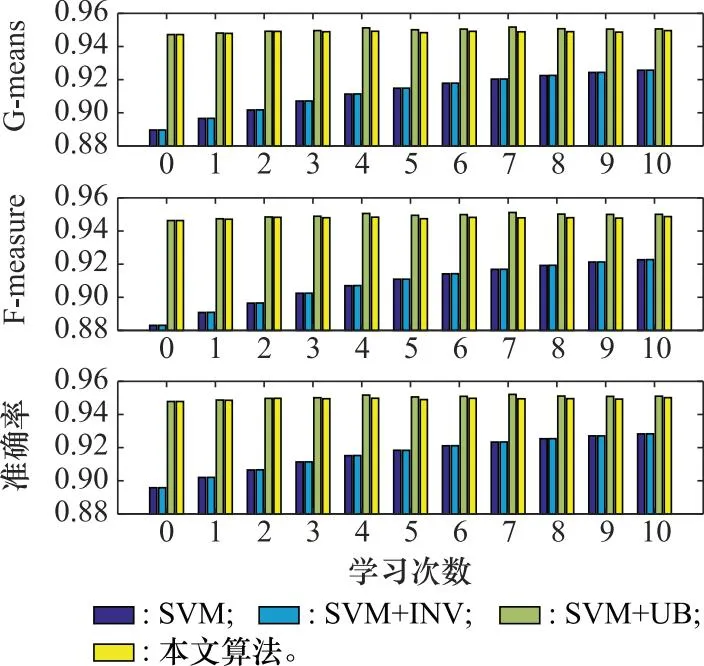
图9 各算法的3种指标比较Fig.9 Comparison of three indicators of each algorithm

表1 各算法训练样本数量比较Table 1 Comparison of training sample number of each algorithm

表2 各算法训练时间比较Table 2 Comparison result of training time of each algorithm ms
为了进一步体现本文算法与现有增量学习算法在不同数据集上的分类效果,这里在UCI-machine learning repository机器学习数据库[27-30]中选取了3类6种不同的数据集进行实验,各数据集的相关参数如表3所示。本组实验对比了经典增量SVM(simple incremental SVM, Simple-ISVM)、基于KKT条件的SVM(KKT-ISVM)、基于组合保留集的SVM(combined reserved set incremental SVM,CRS-ISVM)和本文算法在上述6个数据集中的分类效果。为了避免训练集和测试集划分不同所产生的差异,这里同样采用了1 000次蒙特卡罗模拟并对各指标进行了平均计算。考虑到部分数据集不平衡比较高可能导致分类器无法区分正类的情况,该次实验对TP=0的情况进行了统计,并计算了每种算法的分类成功率。实验结果如图10所示。

表3 不同数据集参数Table 3 Parameters of different data set


图10 不同数据集下各算法的对比实验结果Fig.10 Comparative experimental results of each algorithm under different data sets
从图10可以发现,本文算法相较于Simple-ISVM、KKT-ISVM和CRS-ISVM算法在6个数据集上均体现出了优势。但数据集的不平衡比较低时,如yeast1和ecoli1,算法间的差距较小,且成功率均接近于1;而当数据集的不平衡比较高时,本文算法的优越性逐渐凸显,在G-means和F-measure指标上明显由于其他算法。同时,其成功率也能始终保持在较高的水平,从而减少“漏警”的情况出现。
表4和表5分别为各算法在不同数据集上的训练样本数量和时间开销的平均值。由于对不平衡数据的处理机制采用的过采样方式增加了每次训练的样本数量,本文算法的时间开销要高于其他算法。当数据集的不平衡比较高时(poker-8-9vs6和poker-8-9vs5样本集),上述情况要尤为明显。但本文算法的时间开销还处于毫秒级,考虑到实验平台的计算性能限制,本文算法的时间开销是在可接受的时间范围内的。

表4 各算法训练样本平均数量比较Table 4 Comparison result of average training sample size of each algorithm

表5 各算法训练平均时间比较Table 5 Comparison result of average training time of each algorithm ms
图11和图12分别为各算法在学习过程中训练样本数量和时间开销的增长率。可以看出,本文算法由于采用了保留策略和遗忘策略,在训练样本增长率上相比于KKT-SVM和CRS-SVM算法具有一定优势。而在训练时间增长率上,本文算法的表现将会受数据集不平衡比的影响。当不平衡比较小时(yeast1,yeast3和ecoli1),本文算法的训练时间增长率与Sample-SVM算法基本持平,明显优于KKT-SVM和CRS-SVM算法;而当不平衡比较大时(ecoli4,poker-8-9vs6和poker-8-9vs5),本文算法的训练时间增长率与CRS-SVM算法基本持平。总体来看,本文所提出的学习策略能够有效减少增量学习过程中的样本训练数量,降低增量学习过程的时间开销。

图11 不同数据集下各算法增量学习过程中训练样本数量增长率Fig.11 Growth rate of training samples number in incremental learning process of each algorithm under different data sets

图12 不同数据集下各算法增量学习过程中训练时间增长率Fig.12 Growth rate of training time in incremental learning process of each algorithm under different data sets
4 结束语
针对指挥信息系统的状态监控问题的特点,本文设计了一种面向不平衡数据的SVM增量学习方法。该方法通过对历史监控样本的过采样处理,消除正/异常状态样本数量不平衡造成的影响;通过修正模型更新的触发条件并引入样本的保留和遗忘机制,减少增量学习过程中样本的训练数量以降低时间开销。实验结果证明了本文算法的有效性,显示了其在真实系统状态样本集中的分类效果,并在不同不平衡数据集中对比现有算法,充分表现出了在增量学习过程中应对不平衡数据的能力。值得注意的是,随着系统运行时间的增加,系统状态样本数量也将不断上升。对于样本数量较多的分类问题,深度学习方法将表现出更加优异的性能。因此,在后续工作中可以对深度学习在指挥信息系统状态监控问题中的应用展开进一步的研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
数学物理学报(2019年1期)2019-03-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
高中生学习·高三版(2016年9期)2016-05-14
