
基于改进极限学习机的数据智能化分析算法设计
2024-03-11 01:51范晓东
电子设计工程 2024年5期
范晓东
(河北北方学院附属第一医院,河北张家口 075000)
综合型医院通常体系繁杂拥有众多科室,随着其规模的不断扩大,经济数据处理过程中遇到的问题也越来越多[1-4]。为了提高对财务状况的分析判断能力并减少人工成本,基于改进极限学习机技术,该文提出一种数据分析算法,该算法利用改进的极限学习机从海量数据中挖掘关键信息,分析各种因素与最终结果之间的强弱关系,从而实现对医疗财务数据的精确分析以及风险预测。
1 极限学习机
极限学习机(Extreme Learning Machine,ELM)是一种新的单隐藏层前馈神经网络,网络结构如图1所示。极限学习机只需要提前确定隐藏层节点的数量,便可以随机初始化链接权重和偏差。极限学习机通过一步计算即可获得最佳的输出权重,从而获得高训练速度[5-8],其已被证明在回归和分类问题中具有良好的表现。
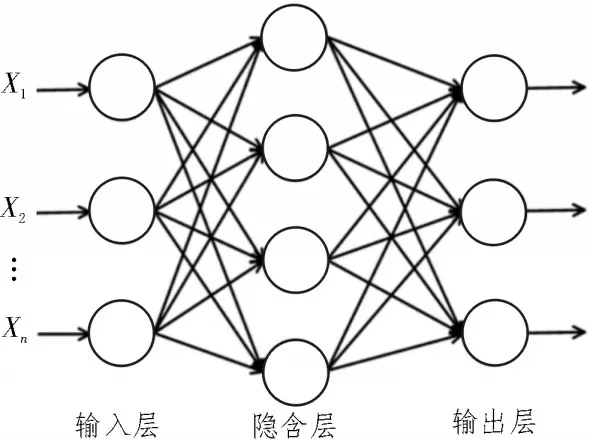
图1 极限学习机的网络架构图
给定大小为N的数据集(Xi,Ti),其中Xi=[xi1,xi2,…,xin],Ti=[ti1,ti2,…,tim],具有K个隐含层节点和激活函数G的极限学习机回归模型可表示为:
其中,ai=[ai1,ai2,…,ain],表示第i个隐含层节点和输入节点的权重向量;βi=[βi1,βi2,…,βim],表示第i个隐含层节点和输出节点之间的另一个权重向量,bi表示第i个隐含层节点的偏差,ai·xj表示a和x的内积,Oj表示输入为xj时的输出。当模型完全拟合N个样本时,可以得到:
其中,H为隐含层输出矩阵,输出权值可通过求解以下线性系统得到:
其中,H+为隐含层输出矩阵H的广义逆。而式(5)是式(6)的唯一最小范数的最小二乘解,可表示为:
当隐含层节点数与样本数相同时,网络可以较好地近似样本。但在实际应用中,隐层节点数通常小于训练样本数,因此数据样本可能存在多重共线性问题。在求解广义逆H+=H+(HHT)-1时,多重共线性的存在可能使HHT为奇异矩阵。每当使用极限学习机对模型进行建模时,所得到的矩阵H不同,则隐含层的隐含输出权值β也不相同。这些原因最终导致极限学习机的输出容易出现随机波动,模型的稳定性和泛化能力不理想。
2 算法设计
2.1 灰狼优化算法的设置
灰狼优化(Grey Wolf Optimizer,GWO)算法源自对灰狼种群捕食行为的模拟,通过狼群的跟踪、包围、追击和攻击实现优化。GWO 算法的优点包括原理简单,需要调整的参数少,易于实现且全局搜索能力强等[9-13]。
该文所采用算法中狼被分为四个层次:α代表群体中占主导地位的狼,其处于第一级,β代表第二级从属狼,帮助α做决定,δ代表该狼遵循α和β的指示,ω则代表最低级别的狼。算法中的追逐行为由α、β和δ执行,ω跟随前三个跟踪和分配猎物,最后完成捕食任务。假设灰狼的数量为M,搜索空间的维数为d,第i个灰狼在第d维空间中的位置可表示为xi=(xi1,xi2,…,xid)。根据特定优化问题的适应度函数,将最优个体记录为α,将排名第二和第三的相应个体记录为β、δ,其余个体记录为ω。此外,猎物的位置意味着优化问题的全局最优解。
定义1:灰狼和猎物之间的距离:
定义2:包围猎物,在自然界中灰狼总是通过包围的方式来捕食猎物,其数学模型如下:
定义3:狩猎和捕获猎物。
因为猎物在实际优化问题中的位置是未知的,所以为了模拟猎物狩猎的行为,根据其与猎物的距离来定义α、β和δ三种类型的狼,并且它们对猎物的位置有最为清晰的了解。距离越近,则狼越了解猎物的位置。因此可以利用上述三种狼的位置找到猎物,并带领其余的ω狼更新自身的位置。狩猎猎物的数学表达为:
在捕猎过程中,首先由式(12)~(13)计算群体内个体与α、β、δ之间的距离,再由式(14)综合确定个体向猎物移动的方向。最后,狼在捕获猎物时完成狩猎,算法终止。
GWO 的主要思想可以用以下定义来描述:在问题空间中随机生成一群灰狼;根据定义1 评估每匹狼与猎物的距离,提名α、β和δ狼,然后根据定义3 更新每匹狼的位置;重复评估操作并更新狼的位置,直到捕获猎物。
2.2 基于GWO的极限学习机设计
该文使用GWO 来优化ELM 的权重和参数,即GWO-ELM,算法流程如图2 所示,其具体步骤如下:(此处为具体算法改进优化)
步骤1:根据均方根误差(RMSE)定义适应度函数为:
其中,N表示训练样本的数量,yi表示输入xi的实际值,pi是所提出的模型中需要优化的参数和权重的向量,ϕ(xi,pi)是带有xi和pi的模型预测值。
步骤2:设置运行GWO 的参数,包括最大迭代次数、总体大小、四种不同类型的核函数的参数以及正则化参数的上限和下限。随机初始化每匹狼在上边界和下边界之间的位置,并将α、β和δ狼的适应度值设置为无穷大。设迭代次数初始值t=1,初始化、。
步骤3:对于每匹狼,若已有的狼适合度低于α狼,用其替换α狼;如果适合度在β狼和α狼之间,则用其替换β狼;若适合度介于δ狼与β狼之间,即用其替换δ狼。
步骤5:判断t是否大于最大迭代次数;如果不是,转到步骤3;若是,则中断迭代,输出α狼的pα值作为ELM 的优化参数和权重。
3 实验结果与分析
3.1 实验环境与数据
该文利用Python 对所设计算法进行实验仿真,验证所提医疗财务数据风险预测算法的有效性和可行性。具体使用的计算机配置如表1 所示。

表1 计算机配置
为了验证所提出算法的有效性,文中采用了真实数据集作为实验仿真的数据。数据主要来源于某医院智能金融发展研究中随机抽取的后台金融数据。初始数据样本有3 790个数据集,数据分类如表1所示。数据中可将风险类别分为五种,分别是A、B、C、D、E,代表着风险等级极低、风险等级低、风险等级一般、存在一定风险和有较大风险。在实验中,该文将该数据集分为训练集、验证集和测试集。实验数据分布如表2 所示。

表2 实验数据分布
3.2 评价指标
对于回归预测模型,需要将预测值和真实值保持一致或者接近[14-16]。因此,该文选择了决定系数R2作为评价指标。R2常用于评价回归模型的实际结果,评价回归模型对因变量y变化的解释程度。R2值的范围为0~1,通常使用百分比来表示。如果回归模型的R2=0.7,则该回归模型对预测结果的解释率为70%。学术界一致认为R2>0.75,模型拟合较好,可解释性高。如果R2<0.5,可认为模型拟合存在问题,不适合回归分析。R2的计算公式如下:
其中,yi表示第i个样本的真实值,表示第i个样本的预测值,yˉ表示真实值的平均值。
3.3 医疗财务数据风险预测仿真
通过不断进行实验仿真验证,最终确定ELM 隐含层的层数为150 时,该算法可以得到最佳的预测结果。根据最佳参数,该文提出的基于改进极限学习机的数据分析算法在实验数据集上得到的R2值为0.96。
同时,为了验证文中提出的基于灰狼优化算法的极限学习机在医疗财务数据风险预测方面的有效性和优越性。该文还与原始ELM 算法以及多种机器学习算法进行了对比,具体结果如表3 所示。其中,未加入灰狼优化算法的ELM 在数据集上得到的R2=0.81,由此表明,通过灰狼优化算法验证了ELM优化后的有效性。而在机器学习算法中线性回归表现最差,R2值仅为0.64。决策树和随机森林表现较好,R2分别为0.86 和0.89,SVM 是机器学习算法中效果最优的,R2为0.90。通过上述实验表明,该文提出的基于灰狼优化算法的极限学习机在金融风险预测方面的表现要优于原始ELM,以及决策树和SVM 等机器学习算法,证明了该文算法的优越性。
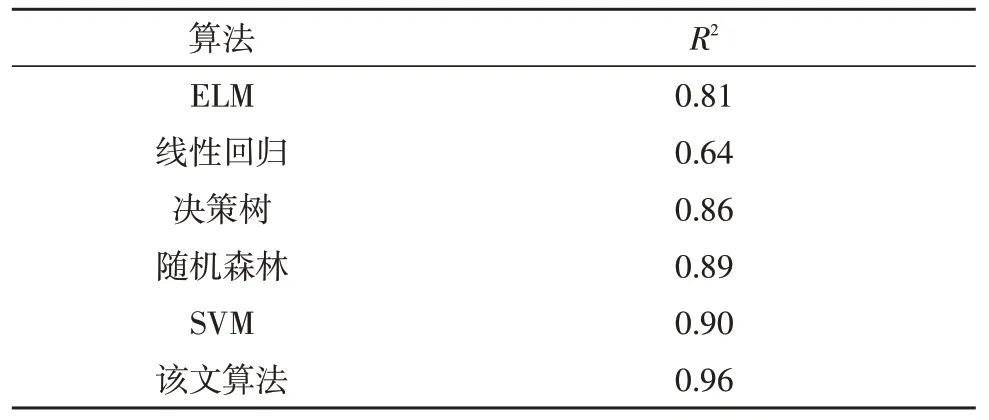
表3 实验结果对比
4 结束语
为了对医院财务数据的金融风险进行预测,文中提出了一种基于灰狼优化算法的极限学习机设计方案,并将其用于医疗财务数据的风险预测。该算法利用极限学习机从海量数据中挖掘关键信息,并通过灰狼优化算法对极限学习机的参数进行优化。通过在实际数据集上进行实验仿真,验证了该文算法的有效性和优越性。实验结果表明,经过灰狼优化算法改进的极限学习机可以精确地预测出医疗财务数据的风险等级,其效果优于多数机器学习算法。
猜你喜欢
小太阳画报(2019年1期)2019-06-11
测控技术(2018年10期)2018-11-25
数学大王·低年级(2018年5期)2018-11-01
证券市场红周刊(2018年33期)2018-05-14
证券市场红周刊(2018年10期)2018-05-14
证券市场红周刊(2018年5期)2018-05-14
证券市场红周刊(2018年27期)2018-05-14
自动化学报(2018年2期)2018-04-12
制造技术与机床(2017年4期)2017-06-22
快乐语文(2016年15期)2016-11-07
