
基于用户兴趣改进模型的智慧图书馆个性化检索服务研究
2024-03-12 04:25李菲菲
图书馆研究与工作 2024年2期
李菲菲


摘 要:为了解决目前用户在图书馆检索系统中无法找到自己感兴趣的内容的困境,文章以抓取的各类教育网站上的课程信息作为实验数据,将用户兴趣与基于倒排索引的Lucene算法及LDA算法模型相结合,引入UCI-Lucene算法:使用Lucene算法得出基于倒排索引的搜索结果,使用LDA主题模型算法对Lucene算法得出的搜索结果计算得到课程的兴趣分布,与此同时使用LDA主题模型算法通过对用户日志进行计算得出用户的兴趣分布,接下来将课程的兴趣分布与用户的兴趣分布做相似度计算,得到课程—用户的兴趣相似度,最后通过加权Lucene算法得出的搜索结果得分和课程—用户的兴趣相似度得分得到每个课程的综合得分,得到最后的搜索排序结果。基于上述改进算法,文章设计了一款智慧图书馆个性化检索系统。实验表明,基于用户兴趣改进模型的智慧图书馆个性化检索系统不仅能够更好满足用户的搜索需求和用户兴趣,还能够显著提升搜索结果的准确性和召回率。
关键词:Lucene;LDA;个性化检索系统;UCI-Lucene;用户兴趣改进模型;智慧图书馆
中图分类号:G250.7;G252.62文献标识码:A
Research on Personalized Retrieval Services in Smart Libraries Based on User Interest-Enhanced Models
Abstract To address the challenge of users not being able to find content of interest in library retrieval systems, this article utilizes course information collected from various educational websites as experimental data. It combines user interests with the Lucene algorithm based on inverted indexing and introduces the UCI-Lucene algorithm. The UCI-Lucene algorithm derives search results based on the Lucene algorithm's inverted indexing. It then employs the LDA topic modeling algorithm to calculate the interest distribution of courses from the search results obtained by the Lucene algorithm. Simultaneously, it utilizes the LDA topic modeling algorithm to calculate the interest distribution of users based on their activity logs. Next, it computes the similarity between the interest distributions of courses and users, resulting in course-user interest similarity scores. Finally, it combines the scores from the weighted Lucene algorithm and the course-user interest similarity scores to obtain comprehensive scores for each course, yielding the final search ranking results. Based on the improved algorithm described above, the article designs a personalized retrieval system for smart libraries. Experimental results demonstrate that the user interest-enhanced model in the smart library personalized retrieval system not only better satisfies users' search needs and interests but also significantly improves the accuracy and recall of search results.
Key words Lucene; LDA; retrieval system; UCI-Lucene; User Interest-Enhanced Models; smart library
1 引言
隨着信息技术的快速发展,各类检索系统[1]应运而生并得到了迅速发展,人们的需求日益多样化,对于检索系统的期望也越来越高。图书馆作为人类精神文明的重要载体,核心任务就是致力于为用户提供更加人性化和智慧化的服务[2],以满足用户工作、学习和研究需求,不断探索和提高智慧化的可能性。但是,当前的图书馆检索系统存在一些不足,例如搜索结果与用户的期望不符,不能够满足用户的需求和兴趣等,这些问题导致了用户必须花费大量的时间来筛选和过滤没有价值的内容,因此需要设计一种挖掘用户潜在兴趣的检索算法[3]来提高读者的检索效率。
早期的检索系统旨在通过分析和优化已有信息,以提高搜索结果的准确性和可靠性。Metacrawler检索系统[4]可以有效地收集和处理用户的信息,用户可以轻松地在浏览器中查询所需的信息,提升了检索系统的效率。Google检索系统使用PageRank算法[5]评估网站的权重,从而确保用户可以获得更多有价值的信息,但是这种方式的缺陷是无法实现满足用户兴趣的个性化检索。随着时间的推移,网络上信息数量急剧增加,搜索结果的准确性和可靠性也在不断下降,越来越多的研究人员开始将研究重心转向用户兴趣。研究人员通过深入分析用户行为,挖掘用户兴趣,建立用户兴趣模型,以期望满足个性化搜索和提高搜索结果的准确性,在个性化搜索领域的用户兴趣模型研究取得了长足的进步和丰硕的成果。Personal WebWatcher为用户提供了一种个性化的服务[6],它能够根据用户的不同需求进行实时调整,通过用户的点击行为来获取用户的最新需求。雅虎(中国)公司推出的MyYahoo[7]利用用户的个性化偏好和兴趣,构建出一个完整的用户模型,从而帮助用户更加有效地搜索出所需信息,但是由于缺乏实时性和可靠性,使得其无法有效地满足用户的需求。南京大学开发的个性化检索系统DOLTRI-Agent[8]运用挖掘用户特征、行为、兴趣等个人信息进行计算分析构建出用户的兴趣模型,以便更好地满足用户的需求,并且能够及时发现其中存在的问题,从而提升用户的搜索体验。
经过深入分析发现,目前个性化检索系统存在诸多挑战,其中最突出的几个问题如下:(1)当前的个性化检索系统未能充分考虑用户特征、行为信息、兴趣等,也无法深入挖掘用户潜在的兴趣,从而导致搜索结果无法真正满足用户的需要。(2)当前的个性化检索系统会出现“兴趣漂移”的问题,即用户的需求会随着时间的推移而发生变化,而现有的个性化检索系统无法及时发现和满足这些新的兴趣和需求。针对上述问题,本文以隐含狄利克雷分布主题模型算法(Latent Dirichlet Allocations, LDA)和Lucene算法为基础,引入用户兴趣并加以改进,设计了一種智慧图书馆个性化检索算法模型:UCI-Lucene。该模型不但更能挖掘用户潜在的兴趣和更加满足用户现有兴趣,而且能大大提升准确率和召回率。
2 研究方法
2.1 LDA主题模型
LDA主题模型[9]已经成为一种普遍采用的自动化技术,可以有效地深入探索文本的语义特征[10],帮助人们发现文档中隐藏的主题,从而可以根据主题分布来对文档进行分类或计算出主题之间的相关性。该主题模型基于EM算法,能够将复杂的语义概念转化为一种简单的数学形式,这样就能够让人们更容易地理解和接受这些信息。由于LDA主题模型没有充分考虑词语之间的顺序关系,大大降低了模型的复杂度,从而使得该主题模型成为更加高效的方法。2.2 Lucene基本原理
Lucene通过倒排索引技术,将文件、图表以及其他数据结合在一起构建出一个有效的索引系统[11]。Lucene算法原理:(1)创建文档对象,将每个文件的属性存储在创建的文档对象中,并在每个属性中添加一个域以便更好地管理文件,将文档对象中的每个属性编号,以便更加有效地管理文件。(2)分析文档,使用文档对象的两个域(文件名和内容)来进行更加细致的研究。首先需要根据文件中的字符串,在每个空白处划分出一个词语,然后将其中的每个单词都转换成小写,可以将那些无意义的单词称为停用词,并进行删除。通过这种方式,可以创建一个关键词清单,这个关键词清单由一系列独立的关键词组成,它们分别代表着一个独立的域,而这些域又可以由一系列的单词组成,从而形成一个完整的系统。(3)创建索引。为了提升查询的效率,可以构建一个索引库,将相关的关键词列表与文档对象结合起来,以实现查询的高效性,同时也能够准确地记录下这些关键词与文档对象之间的关联关系。
2.3 分词器
分词器的主要功能是筛选信息,鉴于Lucene自带的分词器Analyzer[12]在中文分词中表现不佳,本文选择了分词效果更好的IKAnalyzer[13]来实现更加准确的分词。IKAnalyzer分词器是一款功能强大的开源中文分词工具。该分词器支持Java平台,并且具备良好的扩展性。Lucene技术为IKAnalyzer提供了强大的支持。IKAnalyzer支持中文、英文、日文等多种语言,其中中文版本符合用户的需求,性能更加优异;除了拥有多种分词技术,如精细化分词和智能分词,IKAnalyzer还拥有惊人的分词速度,每秒钟可以处理超过60万个单词;IKAnalyzer还可以有效地减少内存消耗,显著改善自定义词典的效率和准确度;通过对Lucene的改进,其分词器的功能和性能显著增强,使得搜索的效果和效率有了显著的改善。
3 基于LDA主题模型的用户兴趣改进算法实现过程
随着互联网的快速发展,用户数量和网页数量都在迅速增长,导致了传统的基于关键词的图书馆检索系统难以满足当前用户的需求,检索结果容易出现“漂移”现象[14]。用户在使用关键词检索系统时,系统会使用分词技术把一个特定的词语拆解为更多的字符,并使用倒排索引来获取索引库中的结果。由于用户无法准确地描述自己的真正需求,因此系统会给出错误的结论和无效的解决方案。因此,在图书馆检索系统中,引入用户兴趣是十分重要且必要的。
针对目前图书馆检索系统检索结果无法满足用户兴趣和需求的问题,本文以抓取多个教育网站的课程信息作为实验数据进行研究,设计出一种基于LDA主题模型的用户兴趣改进算法:UCI-Lucene排序算法。经过实验表明,采用基于LDA主题模型的用户兴趣改进算法得到的检索结果不但可以挖掘用户深层次潜在兴趣,构建更加精确的用户兴趣模型;搜索结果更加满足用户的兴趣和需求,而且可以显著提升搜索结果的准确性和召回率。
3.1 用户兴趣建模
通过建立一个有效的用户兴趣模型[15],可以将用户的需求和偏好有机地组织起来,从而更好地反映出用户的真实需求。通过使用关键词来提取用户的兴趣信息时,由于存在一些相似的概念或者一个词有多种含义,因此仅仅基于这些关键词来构建用户兴趣模型是不够可靠的。经过研究发现,在用户的点击行为、浏览时长和浏览内容方面,有一套完整的用户兴趣构建流程,它由三个方面组成。
(1)兴趣行为表示
本文用三元组来描述用户最近一段时间内的兴趣行为,以便更好地了解用户的行为特征。其中content代表用户浏览的内容,本文主要用文章的摘要或者简介来表示;ltime代表用户最近一次浏览该文章的时间;hits指的是在一段时间内用户对该文章的点击次数。
(2)浏览记录权重计算
在一段时间内,用户可能会浏览多条记录,本文将这些记录以列表形式表示出来:,其中dk表示用户浏览的第k条记录,其兴趣行为可以用公式(1)中的三元组来表示。根据分析,不同的记录会影响用户的兴趣,点击次数越多,代表用户对此内容兴趣更大,也就意味着这些记录的权重越大。最后一次访问的时间也代表了此内容更符合目前的兴趣,因此权重也会更大。使用w(dk)来衡量用户行为对用户兴趣的影响,可以通过公式(1)来计算浏览记录的权重。
在本公式中,tn代表当前的时间, ltimek代表dk最近一次访问的时间,表示正态分布,hitsk表示记录dk的访问次数,为阻尼系数,其具体数值可以通过实验来确定。
(3)用户兴趣抽取
本文通过使用LDA主题模型算法从多条记录中抽取出用户的兴趣。该方法的步骤是:采用LDA主题模型算法计算出用户日志中每条记录的兴趣分布,然后将这些兴趣分布(分数)进行加权求和,根据公式(2)来确定用户的最终兴趣。
I(user)代表用户的初始偏好,而I(dk)则是通过使用LDA主题模型算法计算出的每条用户兴趣分布值。
3.2 UCI-Lucene排序算法
LuceneScore是使用基于倒排索引的Lucene算法得出的课程分数,UC-InterestScore是通过使用LDA主题模型算法分别对课程和用户日志进行计算,得出的课程兴趣分布和用户兴趣分布做余弦相似度计算得到的分数结果(课程—用户兴趣分布),这反映了课程与用户兴趣之间的相似程度,而UCI-LuceneScore则是通过加权Lucene排序算法和UC-InterestScore(课程—用户兴趣分布)得到的最终的综合分数,是一个阻尼系数,具体取值取决于实验过程。通常来说,我们无法精准地预测每个维度所代表的主题属性,但能够推断出相似的主题属性,即使在不同的文档中,只要有相同的维度,就会有相似的主题属性,从而使得最终的排序结果更加准确。UCI-Lucene搜索排序算法流程图如图1所示。
UCI-Lucene搜索排序算法过程如下:使用Lucene算法得到基于倒排索引的搜索结果,记为LuceneScore;然后使用LDA主题模型算法计算出课程的兴趣分布,同时使用LDA主题模型算法对用户日志进行分析计算得出用户的兴趣分布;接下来将课程兴趣分布和用户兴趣分布做余弦相似度计算,得到课程—用户的兴趣相似度分数,记为UC-InterestScore;最后通过加权LuceneScore和UC-InterestScore得到每个课程的综合分数UCI-LuceneScore,即最后的搜索排序结果,计算方法如公式(3)所示。
4 实验与分析
4.1 实验数据
通过采用分布式爬虫技术[16]和经过精心筛选,实验组最终确定了50 000条数据作为实验数据,这些数据具有完整、明确的主题和均匀的分布特征,可以满足本实验要求,表1列出了其中的部分数据结果。
经过精心地对文档集标题、简介以及其他相关信息的研究,我们最终选择了38 796条文章数据并对其主题打标签,其中包括8个一级主题和26个二级主题。
4.2 实验评价指标
精确度和召回率作为评测指标被广泛用于检索系统,来衡量算法得到检索结果的质量和性能[17-18],精确度越高,表明检索结果质量和性能越好、越精确,召回率越高,说明查准率越高。通过计算兴趣精确度和兴趣召回率来研究用户兴趣的精确度和性能,兴趣精确度和兴趣召回率越高,表明兴趣越精确。
(1)精确度的计算如公式(4)所示。
TP表示正类判定为正类,FP表示负类判定为正类。以主题词“计算机”为例,本文抽取10 000条数据,将与“操作系统”有关的3 000条数据打标签为“计算机”。当在检索系统中输入“计算机”时,得到的搜索结果有3 200条,Lucene检索结果中标记为“计算机”的有2 487条,即TP=2 487,FP=3 200-TP=713,由此可以得出精确度P=0.777的结果;UCI-Lucene结果中标记为“计算机”的课程条数为2 550条,即TP=2 550,FP=3 200-TP=650,最终得出精确度P=0.797。
(2)召回率的计算如公式(5)所示。
TP表示正类判定为正类,FN表示正类判定为负类。根据公式(4)中的数据,TP=2 487,FN=3 000-TP=513,可以得出,基于倒排索引的Lucene的搜索结果召回率为P=0.829;基于UCI-Lucene算法得到的搜索結果:TP=2 550,FN=TP=450,计算得出召回率为P=0.85。
(3)用户兴趣精确度可以根据公式(6)计算得出。
SIN代表检索出的用户兴趣数,TN代表总数目。以“计算机”为例,本文取10 000条关于“计算机”的数据,将“计算机”分为10个类,如“数据结构、操作系统、人工智能原理、计算机组成原理、Java程序设计、算法分析与设计、数据库原理”等。在这些数据中,与“数据库原理”相关的数据有2 000条,将“数据库原理”作为一个兴趣,实验组模拟用户多次点击与“数据库原理”相关的数据。当在检索框中输入“计算机”时,得到的检索总数目为2 100条,基于倒排索引的Lucene算法结果显示,“数据库原理”的数据有282条,即SIN=282,TN=2 100,得到兴趣精确度P=0.134;改进的用户兴趣算法模型UCI-Lucene结果显示,“数据库原理”的数据量达到846条,即SIN=846,TN=2 100,计算可得兴趣精确度P=0.403。
(4)根据公式(7)可以计算出兴趣召回率。
SIN代表检索出的用户兴趣数,IN代表的是所有的兴趣。以上一段第(3)部分中的数据为例,与“数据库原理”相关的数据有2 000条,根据倒排索引的Lucene算法结果显示,“数据库原理”的数据共计282条,即SIN=282,IN=2 000,得到兴趣召回率P=0.141;根据UCI-Lucene的结果显示,“数据库原理”的数据量达到了846条,即SIN=846,IN=2 000,计算得到兴趣召回率P=0.423。
4.3 实验过程与实验结果
在用户登录系统并输入检索词之后,其浏览行为会被记录下来,包括点击次数、点击时长以及其他相关信息。在重新进行搜索时,可以通过LDA主题模型算法对存储的日志信息进行分析计算,从而统计出用户的兴趣,具体的算法搜索结果如表2所示。
通过实验,本文发现“计算机”、“经济学”、“医学”、“理学”、“管理学”和“工学”这6个主题词在图书馆个性化检索系统结果中的有效性是通过使用用户兴趣模型和LDA主题模型来验证的。通过下面四组实验,本文探究了用户兴趣如何影响搜索结果,并将LDA主题模型算法与Lucene算法和UCI-Lucene算法進行了比较,具体数据可参见表3。
根据表3的数据可以看出,采用UCI-Lucene算法比采用Lucene算法的精确度更高,召回率更高,用户的兴趣更加准确,兴趣召回率也更高,从而大大提升了智慧图书馆检索系统的精确度、查准率和性能;用户对同一搜索词的搜索请求可能会有所不同,但最终的结果往往会更加符合用户的需求,从而满足用户的搜索期望。
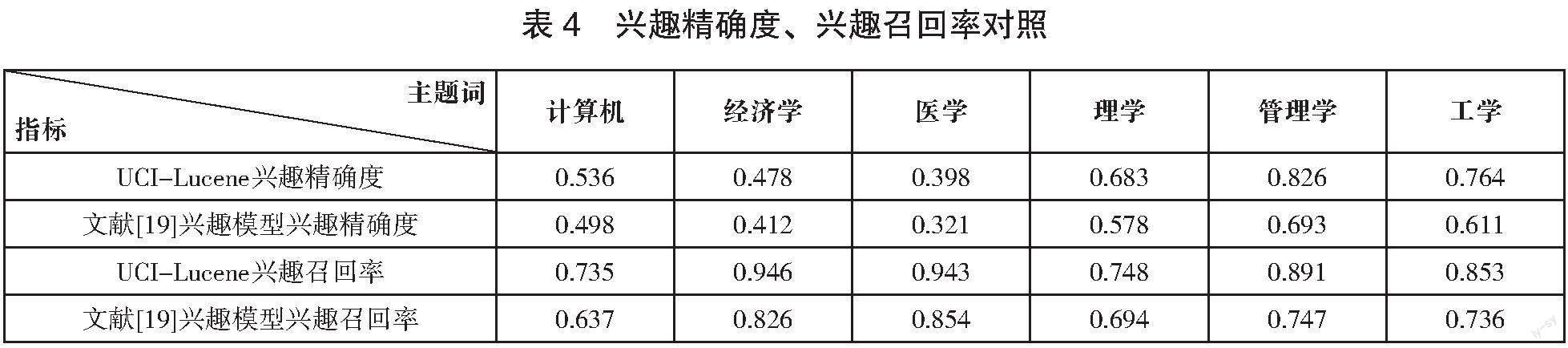
本文通过两篇文献研究了不同用户兴趣模型对搜索结果的影响,并对其进行了详细的分析。文献[19]研究设计的一种用户兴趣模型是通过对用户的浏览偏好进行全面分析,建立的一个能够满足用户长期和短期需求的兴趣模型,并将其应用于个性化检索系统中。根据本文中提出的算法以及参考文献[19]中的研究成果,对兴趣精确度和兴趣召回率进行了分析和计算,具体结果可见表4。
通过对比,UCI-Lucene的搜索结果比参考文献[19]中的兴趣精确度和兴趣召回率更高,这说明了本文所构建的用户兴趣模型在发掘用户偏好方面拥有极大的优势,具有更好的用户兴趣精确率和查准率。经过深入研究发现,文献[19]中的用户兴趣模型未能充分考虑网页点击次数、网页权重以及其他相关因素[19]。相比之下,本文提出的算法不仅能够精确衡量网页点击时间,更好地捕捉网页的兴趣特征,还能够更精确地反映出网页的点击频率和内容。
参考文献[20]提出的兴趣模型是通过一组具有权重的关键词构成的向量集捕捉用户的兴趣偏好并分析用户浏览行为和内容[20],该模型能够根据用户不同时期的时间段来划分其兴趣,并且可以通过公式(8)来确定其实际需求。
Ptd代表了这一天的兴趣,用一个m维的向量来表示,其中每一项Ptdtk代表了用户的实时兴趣,如公式(9)所示,S0代表了一天内访问的总页面数。
用户的稳定兴趣可以用一段较长的时间内用户的访问历史来得出,如公式(10)所示。
Psd表示了用户的稳定兴趣,用一个m维的向量来表示,其中每一项Psdti如公式(11)所示。
n代表了稳定兴趣的时间窗口,Si代表了前i天访问的总页面数,e-log2/h1*(d-din)为衰减因子,反映了一个人对某个关键词的关注度,也可以用来衡量一个人对该关键词的记忆程度,hl代表了人们兴趣持续一段时间后开始减弱,d-din代表了人们对某个兴趣持续的天数,Sn代表了n天内访问的总页面数。通过分析用户的实时兴趣和长期兴趣,可以建立一个用户兴趣模型,如公式(12)所示。
在这个公式中,a+b=1,而c是一个常量,具体值根据实验所得。经过对文献[20]进行详细的分析研究,本文将抓取的教育类数据集划分为多个文本类别,并计算出每个文本类别的权重,用户兴趣类别及权重如表5所示。根据本文中的UCI-Lucene算法和参考文献[20]中的研究方法,对兴趣精确度和兴趣召回率进行了计算,并将计算结果汇总在表6中。
根据表6的数据,可以发现本文提出的UCI-Lucene算法得到的搜索结果表现出更高的兴趣精确度和兴趣召回率,这说明本文提出的UCI-Lucene算法具有更加优秀的发现能力、精确率和查准率,能够帮助用户更加精确地发现和挖掘用户的潜在兴趣。本文提出的算法采用LDA主题模型算法,可以自动计算出内容的主题个数,而且可以有效地计算出内容的兴趣分布,这种方法比文献[20]中提出的兴趣模型更加智能化。
5 结语
本文提出了一种新的算法模型来改善用户体验,即基于LDA主题模型的用户兴趣改进算法模型:UCI-Lucene算法模型。UCI-Lucene算法模型在发现用户潜在兴趣方面表现更出色,它能够准确地捕捉用户的兴趣,并且能够大大提升个性化检索系统的精确度、召回率、兴趣精确度和兴趣召回率,同时也提高了检索系统的检索效率、准确度和查准率。智慧图书馆检索系统融入用户兴趣使得搜索结果更符合用户兴趣和期望,也更好地满足了用户获取信息、学习科研的需要。
参考文献:
[1] 汤玮,刘旭,尹志帆,等.基于solr下的检索系统核心技术研究与应用[J].电子制作,2020(14):40-41,50.DOI:10.16589/j.cnki.cn11-3571/tn.2020.14.017.
[2] 汤尚.图书馆元宇宙赋能智慧服务研究[J].图书馆工作与研究,2023(5):22-27,74.DOI:10.16384/j.cnki.lwas.2023.05.005.
[3] 夏翔,刘姜,倪枫,等.基于混合相似度和用户兴趣迁移的改进协同过滤推荐算法[J].计算机时代,2023(3):36-39.DOI:10.16644/j.cnki.cn33-1094/tp.2023.03.009.
[4] 晏一平,岳泉.中外元检索系统的比较研究[J].图书馆学研究,2005(11):19-24.DOI:10.15941/j.cnki.issn1001-0424.2005.11.006.
[5] SU Q Y,CHEN C,LONG Z,et al.Identification of critical nodes for cascade faults of grids based on electrical PageRank[J].Global Energy Interconnection,2021,4(6):587-595.
[6] MLADENIC D.Text-learning and related intelligent agents:a survey[J].IEEE Intelligent Systems & Their Applications,2002, 14(4):44-54.
[7] 柯青.基于RSS技术的个性化信息服务新方式:由雅虎看RSS在搜索引擎中的应用[J].情报理论与实践,2005(5):537-541.
[8] PAN J G,HU X L,LI J,et al.Design and implementation of a personalized information retrieval agent[J].Journal of Software, 2001,12(7):1074-1079.
[9] LYU Y,YIN M,XI F,et al.Progress and Knowledge Transfer from Science to Technology in the Research Frontier of CRISPR Based on the LDA Model[J].Journal of Data and Information Science,2022,7(1):1-19.
[10] TAN J.Discusses of User Interest Model in Personalized Search[J].International Journal of Advancements in Computing Technology,2013,5(1):619-626.
[11] LUO G,XU H. Intelligent Retrieval Knowledge Repository Model Design Based on Lucene Research[C]//Science and Engineering Research Center.Proceedings of 2015 International Conference on Industrial Informatics,Machinery and Materials(IIMM 2015).Lancaster:DEStech Publications,2015:102-105.
[12] SIRINART C,AREENUCH T,SUMITTRA J, et al. Evaluation of the ESR fast detector and Improve? ESR analyzer as modified Westergren methods for erythrocyte sedimentation rate.[J].Scandinavian journal of clinical and laboratory investigation,2022,82:7-8.
[13] 孟帮杰,王占刚.两种中文分词算法在云计算平台上的实现及比较[J].网络安全技术与应用,2014(12):67,71.
[14] DING H,LIU Q,HU G W.TDTMF:A recommendation model based on user temporal interest drift and latent review topic evolution with regularization factor[J].Information Processing and Management,2022,59(5):528-543.
[15] TAN J.Discusses of User Interest Model in Personalized Search[J].International Journal of Advancements in Computing Technology,2013,5(1):619-626.
[16] PU Q.The Design and Implementation of a High-Efficiency Distributed Web Crawler[C]//Dependable,Autonomic and Secure Computing,Intl Conf on Pervasive Intelligence and Computing,Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress.New York:IEEE,2016:100-104.
[17] TAN C C,SHENG B,WANG H,et al.Microsearch:A search engine for embedded devices used in pervasive computing[J].Acm Transactions on Embedded Computing Systems,2010,9(4):1-29.
[18] 陈弄祺.国内互联网检索系统评价研究[J].统计与决策,2017(3):63-66.
[19] 张宏亮,王海燕.基于改进用户浏览行为个性化检索系统系统研究[J].软件导刊,2013,12(10):89-91.
[20] 蔣翀,费洪晓,张啸.基于用户兴趣模型的Nutch个性化检索系统研究[J].计算机时代,2015(9):26-28.
猜你喜欢
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
意林图解作文(小学版)(2019年6期)2019-07-16
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
专利代理(2016年1期)2016-05-17
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
