
视觉识别手势指令实现无人机飞行控制
2024-03-19 05:17刘润萱龙斌关源王二凯张勇王鹤
电子制作 2024年5期
刘润萱,龙斌,关源,王二凯,张勇,王鹤
(1.辽宁科技大学 机械工程与自动化学院,辽宁鞍山,114051;2.辽宁福鞍重工股份有限公司,辽宁鞍山,114016)
0 引言
传统无人机交互控制系统中,通常采用的语音识别技术,以及各种传感器信息融合技术基本是将传感器采集来的信号转化为较有限的指令,然后通过指令驱动机器人执行事先定义好的运动或操作[1~2]。这样的交互方式操作较为刻板,一定程度上限制了人机交互的灵活性与直观性。要使无人机能够更好地工作,深度学习技术必然是其重要的研究和应用方向[3]。
手势识别类似于人体动作识别,常用的基于深度学习的方法有,基于图像序列的LSTM 动作识别、基于3D 卷积的视频分类以及基于关键点的动作识别。在基于图像序列的LSTM 动作识别方面,杨万鹏等[4]提出了一种特征级融合的LSTM 和CNN 方法。该方法将独立的传感器数据依次接入到LSTM 层和卷积组件层用于特征提取,之后汇聚起多传感器的特征再进行动作分类。张儒鹏等[5]提出了O-Inception结构,并将其与LSTM 进行了融合,进而提出了OI-LSTM动作识别模型。实验结果表明,所提出的OI-LSTM 动作识别模型,在WISDM 和UCI 两个数据集上其准确率比当前最先进的方法分别提高了约4%和1%。在基于3D 卷积的视频分类方面,刘岩石等[6]提出一种改进的三维卷积神经网络模型。该模型将传统的3D CNN 网络结构拆分为空间流和时间流进行数据运算,并借鉴ResNet 网络的设计思想,减少参数设置,避免梯度消失。实验结果表明,文中模型在保证识别精度的条件下,训练速度得到了大幅提升。在基于关键点的动作识别方面,刘源[7]提出了一种基于目标分割网络的人体关键点检测方法,以提高人体关键点的检测精度。尹建芹等[8]提出了时序直方图的概念用以建模关键点序列。再通过比较轨迹间关键点序列的相似性,完成动作识别任务。
本文提出一种基于深度学习技术,即YOLOv5(You Only Look Once)的手势指令智能识别方法。利用该方法无人机根据人的手势指令执行相应的飞行动作,为无人机的交互式控制提供技术支持。
1 YOLOv5 算法
YOLOv5 与之前的模型相比,它的识别速度和准确率都有了明显提高,成为目标识别的最佳选择[9],其网络结构如图1 所示。主要的改进思路如下:
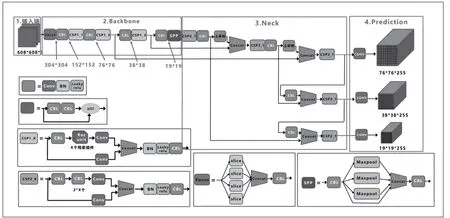
图1 YOLOv5网络结构图
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic 数据增强、自适应锚框计算、自适应图片缩放;
Backbone:融合其他检测算法中的一些新思路,主要包括:Focus 结构与CSP 结构;
Neck:目标检测网络在Backbone 与最后的Head 输出层之间往往会插入一些层,YOLOv5 中添加了FPN+PAN结构;
Prediction:输出层的锚框机制与YOLOv4 相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
2 手势指令模型构建
采用YOLOv5 算法实现手势指令检测主要有三个阶段:第一阶段为数据集采集,第二阶段为模型训练,最后为模型验证。
2.1 数据集
本文要实现无人机的飞行动作主要有:启动、起飞、降落、悬停,以及向上/下/左/右/前/后飞5cm。无人机的飞行动作对应的手势指令分别为:OK 手势,大拇指向上,大拇指向下,拳头,以及手势一/二/三/四/五/六。具体对应关系如表1 所示。

表1 无人机飞行动作与手势的对应关系
为了提高模型训练的效率,在训练前调整每张图片大小为同一尺寸,每张图像像素大小设置为600×600。训练集、验证集和测试集按照7:1:2 的比例随机分配和规划。该自制手势行为数据集样本数量大约有200 张图片。在进行正式训练手势数据集前,首先通过Labelme 软件对每张图片进行手势类别标注,生成带有位置信息的XML 文件,标明每张图片所对应的标签,将全部的训练图片标注完成后放入训练集文档中,至此完成数据集的制作。
2.2 模型训练
使用YOLOv5 训练模型进行训练,在进行了200 次迭代后达到了收敛,训练结果如图2 所示。从图2 中可以看出,模型随着训练次数的增多很快就达到了收敛状态,Loss 值也逐渐趋于稳定,达到了期望的数值。Precision 和Recall曲线的波动较小表明模型训练的效果较好,可认为模型具有较好的精确度和稳定性。并且训练数据集和测试数据集的损失函数基本都减小到了0.01 以下。经过训练,最终模型的准确率达到了90%以上。
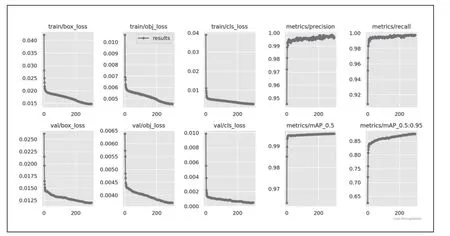
图2 模型训练收敛曲线
2.3 模型验证
为了验证模型的性能,这里采用F1 分数,Precision 值,Recall 值和mAP 值四个指标来评估所训练的模型。四个指标的作用和具体计算方式可参见文献[10]。验证的结果如图3~6 所示。从图3 可以看到F1 曲线很“宽敞”且顶部接近1,说明在测试集上表现得很好(既能很好地查全,也能很好地查准)的置信度阈值区间很大。从图4 可以看出当判定概率超过置信度阈值时,各个手势识别的准确率。当置信度越大时,手势检测越准确,但是这样就有可能漏掉一些判定概率较低的真实样本。从图5 可以看出当置信度越小的时候,手势检测的越全面,即手势检测不容易被漏掉,但容易误判。从图6 可以看出mAP 曲线的面积接近1,也就是说所训练出的模型在准确率很高的前提下,基本能检测到全部的手势类别。因此通过四个指标的曲线图可知,所训练出的模型具有良好手势识别的性能。
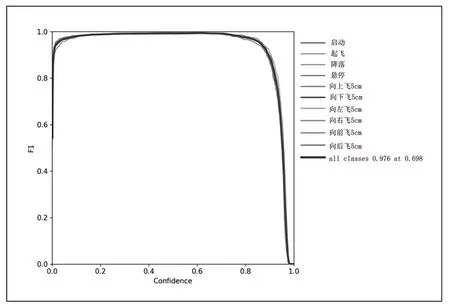
图3 F1 曲线
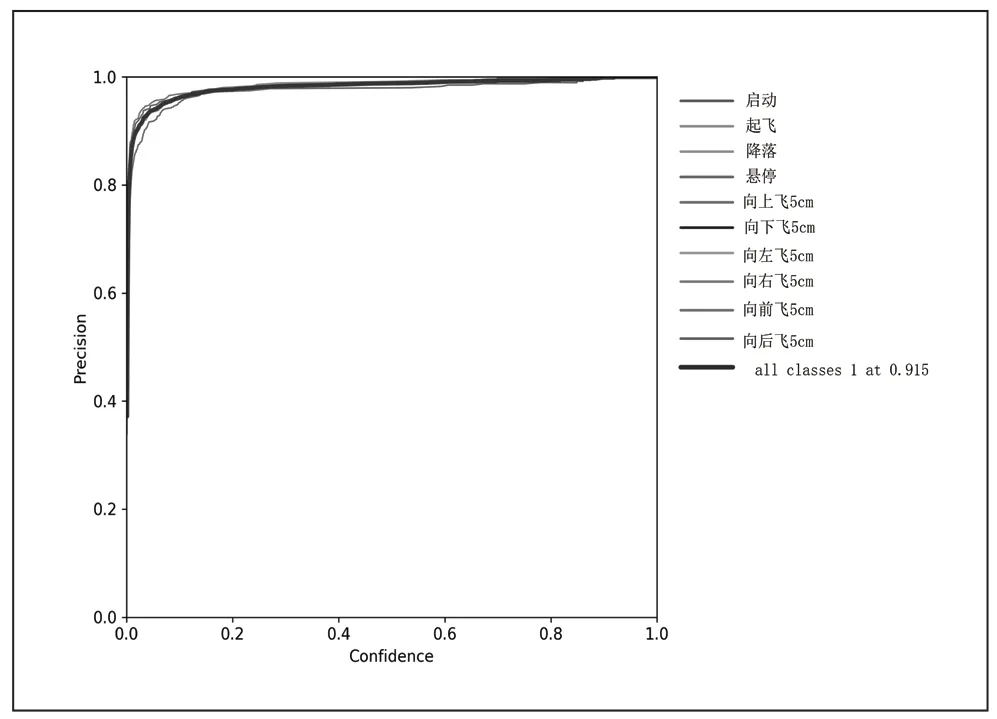
图4 Precision 曲线
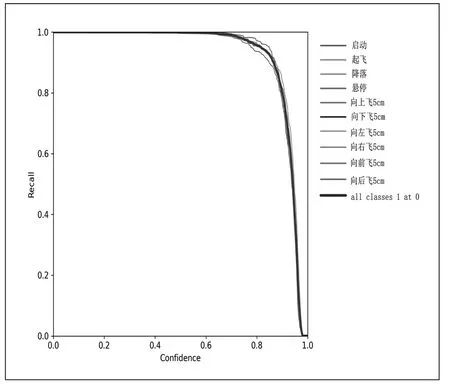
图5 Recall 曲线
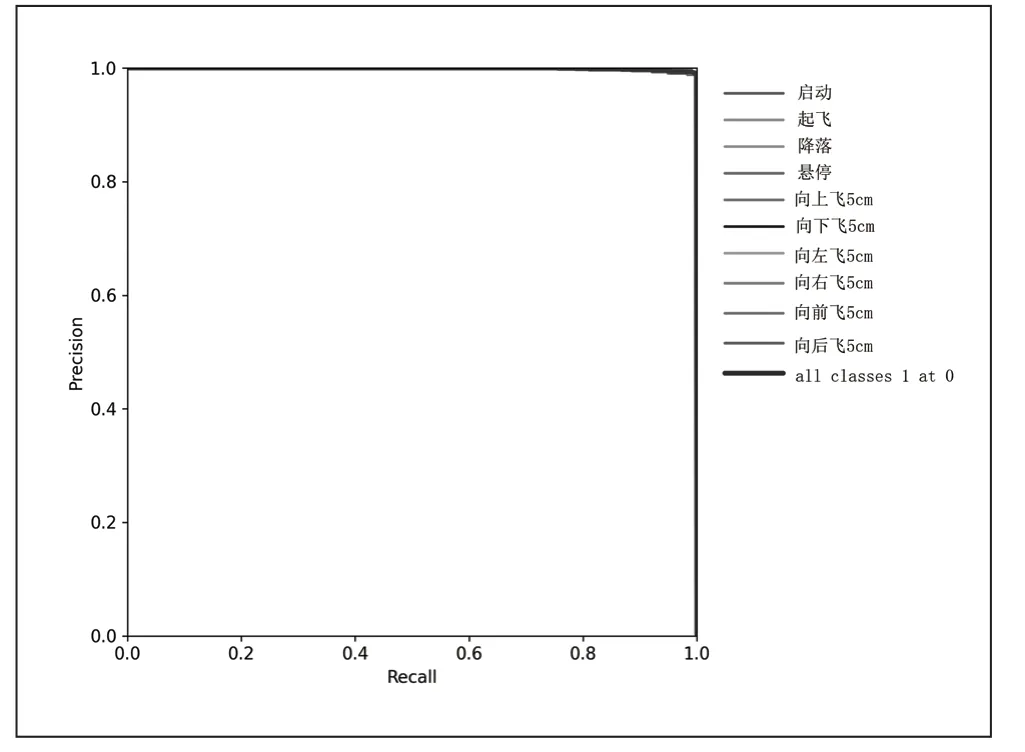
图6 mAP 曲线
为了进一步验证模型的性能,将与原先数据集中人物、场景均不同的全新的100 个样本的测试集放进训练好的模型中进行测试。结果表明,模型在测试集上表现良好。通过图7 混淆矩阵分析可知,模型对这10 种手势都达到了良好的检测效果。一部分样本由于图片背景过于复杂而导致识别错误,例如具有较强的反射光背景或者是图片像素过低所造成的。
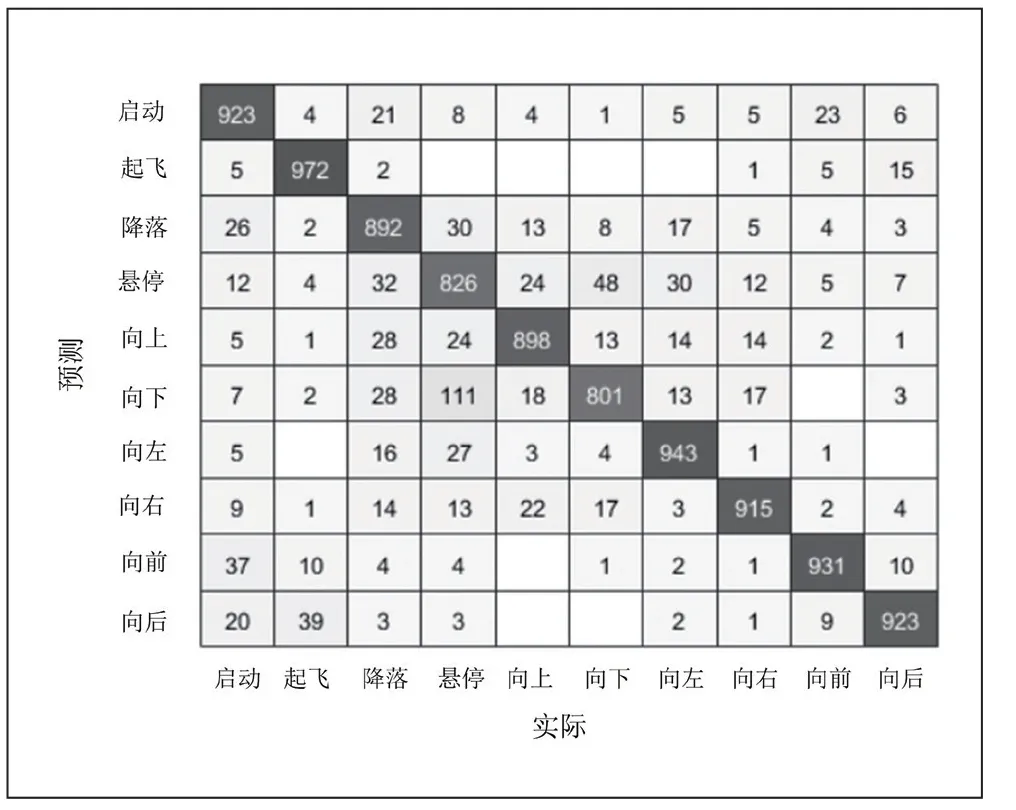
图7 混淆矩阵
2.4 模型对比
为了进一步验证Yolov5 在数据集上的性能优越性,构建了ResNet,VGG16 和RCNN 三个深度学习算法手势指令检测模型,使用上述的测试集进行训练和评估,与Yolov5进行对比测试,实验结果如图8 所示。由图8 可以直接看出,在本文构建的手势数据集上,RCNN,VGG16 和ResNet 分别获得了90.6%,92.1%和93.2%的准确率,而Yolov5算法的准确率在对比实验中最高,为96.4%,能够更好地满足手势指令的检测要求,为控制无人机提供更加准确的手势指令。
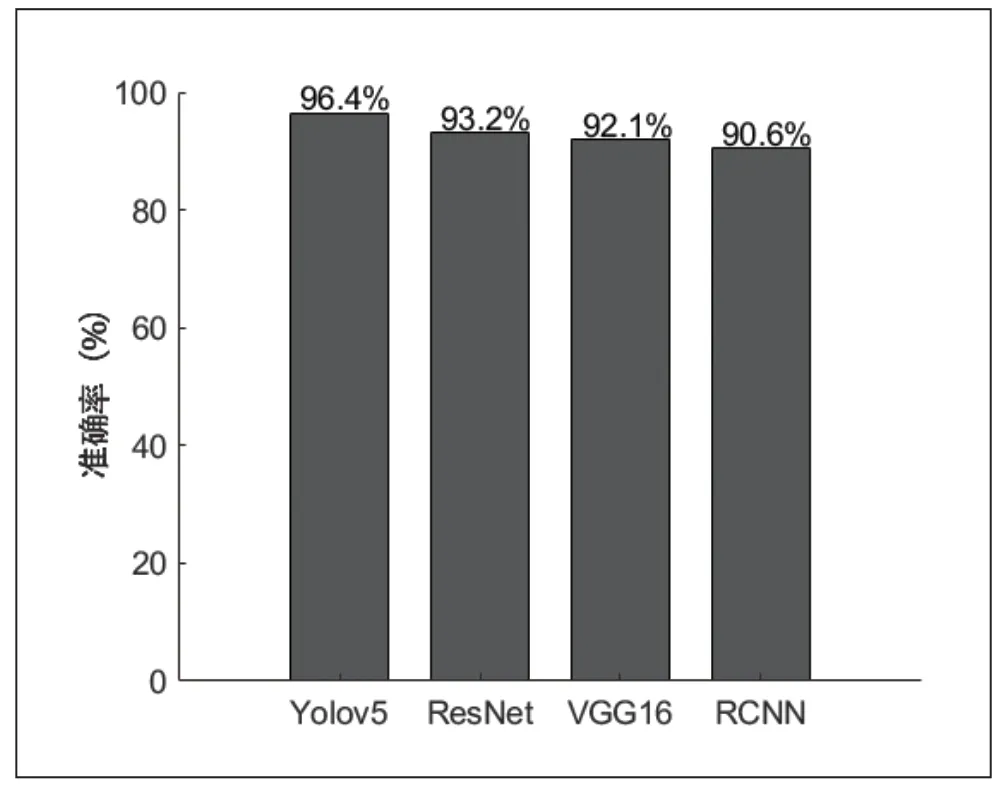
图8 不同深度学习算法的对比
3 实验验证
实验平台采用的是大疆Tello 无人机,此无人机支持Python 编程,并提供Python API 接口。同时提供了Tello SDK,其能够通过Wi-Fi UDP 协议与无人机连接,让用户可以通过文本指令控制无人机。图9 为使用YOLOv5 作为检测模型对手势指令的检测效果。从检测结果可以明显看出,该模型对10 种手势指令都具有良好的识别效果,并且无人机能够根据识别出的手势指令执行相应的飞行动作。

图9 实际识别手势指令的效果
4 结论
本文为了实现视觉识别手势指令以控制无人机飞行运动,建立了基于YOLOv5 算法的识别模型。具体结论如下:第一,采用测试集对模型进行验证。验证结果显示所建立的模型对10 种手势指令具有较高的识别准确率;第二,在无人机应用验证显示所建立的模型对手势指令识别准确率在90%以上。
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
测控技术(2018年5期)2018-12-09
电子测试(2018年18期)2018-11-14
中国交通信息化(2018年5期)2018-08-21
小学阅读指南·低年级版(2017年6期)2017-06-12
