
基于一致性和多样性的多尺度自表示学习的深度子空间聚类
2024-03-21 02:25陈花竹
计算机应用 2024年2期
张 卓,陈花竹
(中原工学院 理学院,郑州 450007)
0 引言
子空间聚类是高维数据聚类的有效方法之一,广泛应用于人脸聚类[1-2]、运动分割[3-4]、图像分割[5]等实际应用中。子空间聚类是基于高维数据近似分布在几个低维线性子空间的假设,将来自不同子空间的高维数据分割到本质上所属的低维子空间。传统的基于谱聚类的子空间聚类(Subspace Clustering Based on Spectral Clustering,SCBSC)方法主要包括两个步骤:首先,通过自表示学习从高维数据中学习一个相似度矩阵;其次,对相似度矩阵使用谱聚类算法来分割数据。第一步是最重要的,因为谱聚类算法的成功在很大程度上依赖于构建一个较好的相似度矩阵。本文关注的是第一步即如何得到一个较好的相似度矩阵。基于SCBSC 方法具有无须预先设定子空间的维度、对初始化和数据噪声不敏感的优势而得到了科研工作者越来越广泛的关注。传统的SCBSC虽然取得了很好的结果,但这些工作主要集中在聚类线性子空间上,在实际应用中,数据不一定符合线性子空间模型的要求。例如,在人脸图像聚类中,反射率通常是non-Lambertian 的,人脸图像通常包含了不同的姿势和表情,在这些条件下,人脸图像更可能位于非线性子空间(或子流形)中[6]。
由于深度学习中的神经网络能够有效地挖掘深层特征并且具有强大的表示能力,近年来,受深度神经网络(Deep Neural Network,DNN)的启发,许多深度子空间聚类方法[6-8]被提出。深度子空间聚类(Deep Subspace Clustering,DSC)网络[6]是基于深度自编码器(Deep Auto-Encoder,DAE)发展的网络,该方法通过一系列的自编码器学习深层的自表示系数矩阵。在DSC 的基础上,很多方法[7-12]被提出。虽然这些方法在一定程度上都增强了数据聚类的性能,但还是存在一些不足。在基于DAE 的子空间聚类中,较浅的层学习更多的像素级信息,较深的层提取更多的语义级或抽象级信息。然而文献[7-9,11-12]方法只考虑了最深层提取的特征,忽略了较浅层次中有用的特征。Kheirandishfard 等[13]提出了深度子空间聚类的多级表示学习(Multi-Level Representation learning for Deep Subspace Clustering,MLRDSC),该方法在各编码层和对应的解码层之间都插入了一个全连接层,通过学习各层的自表示系数矩阵提取不同尺度的特征信息,同时该方法引入伪标签矩阵提升聚类精度。MLRDSC 相较于已有的方法,提高了聚类精度,但是它只考虑了多尺度特征的一致性,没有深度分析多尺度特征的多样性。同时,它也没有考虑多级的输入数据和输出数据的重构损失。
本文仍然利用DAE 获得的不同尺度的自表示系数矩阵解决子空间聚类的问题,为了能够充分利用多尺度的特征表示,通过深入分析不同尺度特征之间的区别以及多尺度之间的自表示特征存在的多样性的特点,能够有效增强最终的聚类性能。基于一致性和多样性的多尺度自表示学习的深度子空间聚类(Multiscale Self-representation Learning with Consistency and Diversity for Deep Subspace Clustering,MSCDDSC)与MLRDSC 相比,主要区别在于本文方法将多级别的自表示特征进行互补,同时对于优化目标进行改进,使多级编码器能够充分提取有利于最终聚类任务的特征,进而增强最终的聚类效果。主要工作包含以下几个部分:
1)将输入数据的重建损失函数替换为多级重建损失函数,监督不同级别编码器参数的学习。
2)提出了一个新的正则项,该正则项有利于加强多尺度特征之间的联系。
3)增加了特有的自表示矩阵的多样性模块,该模块能够使每层嵌入特征对应的自表示矩阵更具有块对角性。
4)对4 个常用的数据集进行实验,实验结果表明本文方法可以有效地处理来自非线性子空间的数据聚类,并且它在大多数子空间聚类问题上的表现优于很多方法。
1 相关工作
1.1 符号说明
表1 对本文主要使用到的符号进行了说明。

表1 符号说明Tab.1 Symbol description
1.2 相关工作介绍
DSC 网络以DAE 为基础将传统子空间聚类方法与深度神经网络相结合,整体由堆叠编码器、自表达层和堆叠解码器3 部分组成。堆叠编码器使用卷积自动编码器,能使堆叠编码器中的参数比全连接层的参数更少,更容易训练网络;在卷积中使用2×2 的卷积核;自表达层由无偏置值和线性全连接层构成,节点之间使用线性权值进行全连接,修正线性单元(Rectified Linear Unit,ReLU)激活函数作为编码层、解码层的非线性激活函数。整体网络将输入数据通过堆叠的卷积自动编码器进行编码,映射到潜在子空间,再经过自表达层学习权重,最后通过堆叠的反卷积自动解码器将潜在子空间的数据还原到原始数据空间。
在DSC 基础上很多模型被提出,如过完备深度子空间聚类网络(Overcomplete Deep Subspace Clustering network,ODSC)[10]将数据并行输入完备编码层以及普通编码层,融合它们输出的特征矩阵,再通过自表示层学习自表示矩阵,使特征表示更具有鲁棒性;具有双域正则化的子空间聚类网络(Robust Subspace Clustering Network with dual-domain regularization,RSCN)[11]将双流行约束纳入深度子空间聚类,使模型在有噪声的情况下显著提高了性能;基于局部拓扑嵌入的图像深度聚类(Image Deep Clustering based on localtopology embedding,IDC)[12]通过建立数据本身特征与局部拓扑信息表示之间的联系,增强了特征表示。
与上述方法不同,MLRDSC 在每一层的编码器与其对应的解码器之间都添加全连接层,并以此捕获多尺度的特征,它的优化目标如下所示:
其中:原始数据X∈RN×C×H×W,N、C、H、W分别表示输入数据数量、通道数、高度和宽度是X经过DAE 后的解码数据;θe是编码器、解码器及全连接层的参数;L是网络的深度;表示数据经过编码层后通过改变形状成为矩阵后的行数,Ml=Cl×Hl×Wl)是第l层网络的嵌入特征;C∈RN×N是所有网络层的嵌入特征共有的自表示系数矩阵;Dl∈RN×N(l=1,2,…,L)是第l层的嵌入特征特有的自表示系数矩阵;Q=(Qij) ∈RN×K是伪标签矩阵,Qij表示第i个数据属于第j类的可能性是为了使解码后数据与原始数据尽可能地接近是为了找出第l层的嵌入特征的自表示矩阵用于将从输入数据的初始为标签中获得的信息利用在网络中;正则化项使相似度矩阵与各层的数据都有关联性。
但是MLRDSC 没有深度分析Dl之间的多样性,同时,MLRDSC 虽然引入了多尺度嵌入特征,但只考虑了输入数据和输出数据的重构损失,而忽略了不同层嵌入特征的重构损失。这些对于最终的聚类效果都会有影响。
2 本文方法
2.1 本文方法原理
MLRDSC 学习了网络层的多尺度特征,本文将这些多尺度特征分为所有网络层嵌入特征共有的自表示系数矩阵(Common Self-Representation Matrix,CSRM)和特有的自表示矩阵(Special Self-Representation Matrix,SSRM)两部分。由于较浅的层学习更多的像素级信息,较深的层提取更多的语义级或抽象级信息,所以每个网络层的SSRM 之间应该具有多样性,但是MLRDSC 没有深度分析这些SSRM 之间的多样性;其次,LRR(Low-Rank Representation)[14]指出,自表示矩阵应具有块对角性,由于MLRDSC 中每一层的自表示矩阵是CSRM 和SSRM 的和,所以二者之和同样具有块对角性;最后,MLRDSC 只考虑了输入数据和输出数据的重构损失,不能保证各网络层的编码器能够恢复对应层输入的数据,所以应该建立不同层嵌入特征的重构损失,监督不同级别编码器参数的学习,从而促进每层嵌入特征的学习。
2.2 方法构成
由于MLRDSC 忽略了多尺度特征的多样性,本文方法为了深入分析不同网络层的SSRM 之间的多样性,在MLRDSC的基础上,进行了如下改进:1)对于特征提取模块,增加了不同层嵌入特征的重构损失;2)对于多尺度自表示模块,本文提出了一个新的正则项,该正则项有利于加强多尺度特征之间的联系;3)增加了SSRM 的多样性模块,该模块能够使每层嵌入特征对应的自表示矩阵更具有块对角性。
MSCD-DSC 网络主要由特征提取模块、多尺度自表示模块、多样性的多尺度特征模块以及谱聚类模块组成。其中:特征提取模块主要由自编码器组成,负责提取多尺度特征;多尺度自表示模块加强共有以及特有的自表示矩阵的联系,获得自表示矩阵;多样性的多尺度特征模块用来获取不同尺度的特征的多样性,学习更多有利的特征。本文的网络架构如图1 所示。
2.2.1 特征提取模块
本文方法采用DAE 架构,即利用多个卷积层构造对称的编码器和解码器。第l(l=1,2,…,L)层编码器的输入为和Wl分别表示数据的数量、第l层的通道数、高度和宽度),其中并且下一层的输入为上一层的输出;第(ll=1,2,…,L)层解码器的输出为整个网络的重构损失函数为:
2.2.2 多尺度自表示模块
2.2.3 多样性的多尺度特征模块
首先给出排他性的定义。(Vij) ∈Rn×n的排他性定义如下:
定义1排他性[15]。两个矩阵U=(Uij) ∈Rn×n和V=
其中:⊙是Hadamard 积,即两个矩阵对应元素的乘积。
由定义1 可知,排他性的目的是使两个矩阵尽可能地具有多样性,即如果Uij≠0,则对应Vij≠0。由于矩阵Dl是第l层嵌入的SSRM,所以本文希望不同层的SSRM 也具有这样的多样性,即:
但是‖ ⋅ ‖0具有非凸性和离散性,本文将‖ ⋅ ‖0松弛为‖ ⋅ ‖1,因此在这一模块中,定义如下优化目标:
这样网络可以学到具有多样性的特有的自表示矩阵。以三层网络为例,如图2 所示,其中Dl(l=1,2,3),D=D1+D2+D3。
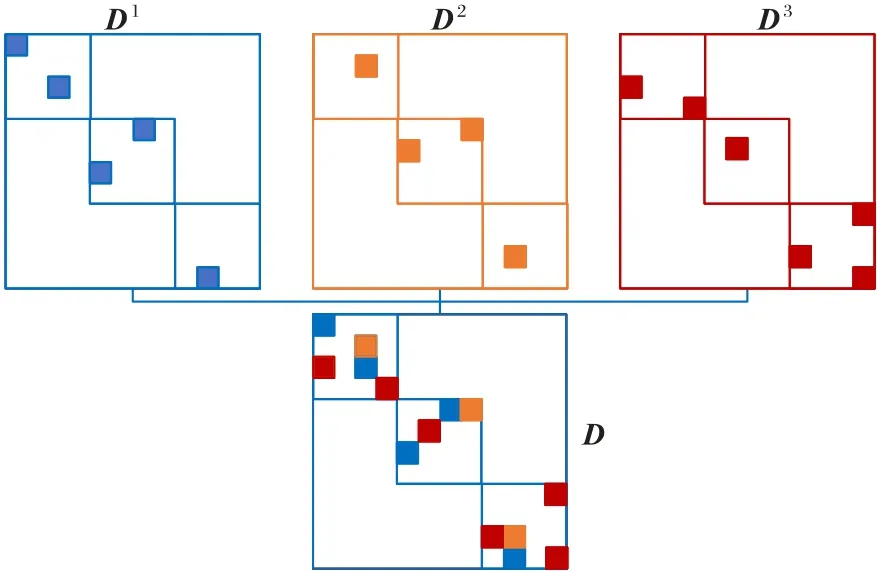
图2 第l层特有的自表示矩阵Fig.2 Unique self-representation matrix of lth layer
2.2.4 网络优化目标
综上所述,整个网络的优化目标为:
其中:λ1、λ2和λ3是调节参数。与MLRDSC 相比,本文方法增加了SSRM 矩阵多样性模块,考虑了每层嵌入特征的CSRM 和SSRM 和的块对角性,同时增加了每个网络层的重构损失函数。其中将重构损失设置为多层的重构损失累加求和,这样的目的是深度自编码器能够尽可能还原每一层的原始输入数据,监督编码层参数的学习,提高特征学习的能力。
最后将W用在谱聚类算法[16]中得到最终的聚类结果。
2.3 求解算法
本文提出的MSCD-DSC 的求解算法总结如下:
算法1 MSCD-DSC 的求解算法。
输入 原始数据X,更新周期T0,最大迭代次数T,随机初始化自编码器网络参数θ,t=0;
3 实验与结果分析
本文的MSCD-DSC 网络是在Python 中使用Pytorch 实现,同时优化方法采用自适应动量的梯度下降算法Adam(Adaptive momentum)进行优化,在实验中的学习率设置为1.0 × 10-3训练网络参数,对于DAE 中的卷积层,设置步幅为2 的滤波器,使用ReLU 为激活函数,对于自表示层使用线性无偏移值的全连接层。不同数据集的网络结构如表2 所示,在本文中,为了与MLRDSC 进行有效的比较,对于网络结构的设置与MLRDSC 的网络结构保持一致。为了评估本文方法的效果,通过3 个用于子空间聚类的基准的人脸数据集(Extended Yale B[17]、ORL[18]和Umist[19])以及物体数据集(COIL20[20])进行大量实验,这4个数据集的部分图像见图3。

图3 不同数据集采样图像Fig.3 Sampled images from different datasets

表2 不同数据集的网络结构Tab.2 Network structures of different datasets
本文对数据集进行了多个子空间聚类实验,并且将以下几个网络作为基线与MSCD-DSC 网络的聚类性能进行比较,包 括DSC[6]、EDSC(Efficient Dense Subspace Clustering)[7]、DASC(Deep Adversarial Subspace Clustering)[8]、MLRDSC[13]、LRR[14]、LRSC(Low Rank Subspace Clustering)[21]、SSC(Sparse Subspace Clustering)[22]、AE+SSC(SSC with the pretrained convolutional Auto-Encoder features)、KSSC(Kernel Sparse Subspace Clustering)[23]、SSC-OMP(SSC by Orthogonal Matching Pursuit)[24]、AE+EDSC(EDSC with the pre-trained convolutional Auto-Encoder features)。需要注意的是,所有对比方法的实验结果所使用的网络参数都依照原文设置,或者直接参考原文中的实验结果。
3.1 在数据库Extended Yale B上的实验
Extended Yale B 数据集作为流行的子空间聚类基准,采集自38 个不同的受试者。每个受试者在不同光照条件下获得64 个正面的面部图像,为了与DSC 等算法对比,采取与文献[11,14,25]中相同的实验方案,对原始人脸图像从192×168 下采样到48 × 42,并且逐渐增加类别个数n进行测试,即n∈{10,15,20,25,30,35,38}。与文献[8,14,24]中一样给出每个(39 -n)实验的均值聚类误差,即当类别个数为n时,报告了(39 -n)个实验的平均聚类误差。
由于本文方法要与目前表现较好的MLRDSC 算法进行比较,在网络结构上使用与之相同的自编码器模型,即由3个堆叠的卷积编码器组成,过滤器和卷积核分别是10、20、30 以及5×5、3×3、3×3。
在参数的选择上,λ1=1 × 10(n/10-1),λ2=40,多样性的多尺度模块对应的参数项λ3=10,T=100,将最大的迭代次数设置为1 500。
不同比较算法的聚类错误率如表3 所示。从表3 中的数据观察到,在所有列出的比较方法中,本文的MSCD-DSC 算法能显著降低聚类错误率,并在n∈{25,30,35,38}时达到最低的聚类误差,在n=38 时,相较于MLRDSC 降低了15.44%。特别当n=30 时,MSCD-DSC 获得了1.09%的聚类误差,比次优的MLRDSC 降低了38.76%。此外,MSCD-DSC在n∈{10,15,20}时也比绝大多数算法的效果好,这意味着MSCD-DSC 网络从DAE 中学到了比较多有用的信息。对于n∈{10,15,20}的聚类结果,猜测是由于该算法对于较小的数据集使DAE 提取的多尺度特征不稳定而导致的。

表3 不同算法在Extended Yale B数据集上的聚类错误率 单位:%Tab.3 Clustering error rates of different algorithms on Extended Yale B dataset unit:%

表4 Extended Yale B上的消融实验结果Tab.4 Ablation experiment results on Extended Yale B
3.2 在ORL、COIL20和Umist数据集上的实验
ORL 数据集包含40 个受试者的面部图像,其中每个受试者在不同的光照条件下有10 张面部图像,具有不同的面部表情(睁眼/闭眼、微笑/不微笑)以及面部细节(戴眼镜/不戴眼镜),如图3(b)所示。由于人脸图像是在不同的面部表情和细节下拍摄的,与Extended Yale B 相比,ORL 数据集存在子空间更加非线性并且数据集规模更小的特点,因此对于子空间聚类就更具有挑战性。为了易于比较,本文采取与DSC 一致的处理方式:将ORL 数据集的人脸图像从112×92降采样到32×32。
COIL20 数据集由20 个物体的图像构成,每个物体对应72 张图像,每张图像都是由黑色背景下的不同角度拍摄照片构成,大视点变化可能对这两个数据集的子空间聚类问题构成严重挑战,如图3(c)所示。
Umist 数据集包含20 个受试者的面部图像,共计480 张,每张图像都采用非常不同的姿势,如图3(d)所示。在使用数据集时本文将每个图像都下采样到32×32。
为了分析出不同的损失项对于实验结果的影响,以ORL数据集为例,进行如下的参数分析:
1)令超参数λ1、λ2、λ3初始值为1。
2)通过固定λ1、λ2的值来调整λ3的值,使λ3在{10-2,10-1,1,10,100}范围内取值,找到λ3的最佳取值。
3)用同样的方式调整λ1、λ2的取值,获取相对较好的取值为λ1=10,λ2=100,λ3=1。
4)进一步调整参数λ2的取值范围为{5,10,15,20},调整方法与2)相同,获取相对更好的取值,从而获得最佳的参数取值。
为了分析得出不同损失项对于实验的影响,本文以ORL数据集为例对参数进行消融实验,结果如表5 所示。

表5 ORL上的参数消融实验结果Tab.5 Parameter ablation experiment results on ORL
最终在数据集ORL、COIL20 和Umist 中λ1的值分别为10、170 和1,λ2的值分别为75、100 和1,λ3的值分别为1、65和1,T的值分别为10、5、10,最大迭代次数分别为1 110、85和130。ORL、COIL20 和Umist 数据集上不同方法的实验结果如表6 所示。

表6 在数据集 ORL、COIL20和Umist上的聚类的错误率 单位:%Tab.6 Clustering error rates for datasets ORL,COIL20 and Umist unit:%
由表6 可知,本文提出的MSCD-DSC 网络仍然比绝大多数的聚类方法的聚类错误率低,相较于次优的MLRDSC 降低了2.22%、3.37%与13.17%,这也说明本文方法有利于最终的聚类结果。
4 结语
本文在MLRDSC 网络的基础上通过分析不同尺度特征的多样性,利用每层嵌入特征的CSRM 和SSRM 和的块对角性、不同层的SSRM 之间的多样性和每个网络层的重构损失函数,提出基于一致性和多样性的深度子空间聚类算法,使不同尺度的多样性自表示特征不能充分利用的问题得到了有效的改善。所提算法在Extended Yale B、ORL、COIL20 和Umist 数据集上的实验结果表明,该算法能有效处理非线性子空间中的聚类问题,对比同类的算法中取得了较好的结果,验证了算法的有效性。在之后的研究工作中,会在本算法的基础上继续研究多尺度的多样性自表示特征信息对于深度子空间聚类效果的影响。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2017年20期)2017-02-10
太空探索(2016年5期)2016-07-12
电子器件(2015年5期)2015-12-29
电子设计工程(2015年6期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
电测与仪表(2014年13期)2014-04-04
