
基于伪实体数据增强的高精准率医学领域实体关系抽取
2024-03-21 02:25郭安迪李天瑞
计算机应用 2024年2期
郭安迪,贾 真,李天瑞,2*
(1.西南交通大学 计算机与人工智能学院,成都 611756;2.综合交通大数据应用技术国家工程实验室(西南交通大学),成都 611756)
0 引言
实体关系抽取属于信息抽取的关键子任务之一,它从非结构化的文本中识别出实体并确立实体之间的关系。在医疗领域,实体关系抽取被广泛应用于结构化信息处理、构建知识图谱和其他下游任务。
与通用领域相比,医学领域的信息抽取任务对错误信息的容忍度更低,对模型的精准率要求更高。然而,医学领域的实体和关系密度更大,约为通用领域7 倍[1],很多与文本语义不相关的医学名词将被识别为假正例的实体,且不同关系之间可能会共用主语或宾语,主语和宾语中一旦出现假正例将影响多组关系分类,这将进一步放大由实体抽取错误带来的误差传递。另外,医疗的关系种类多且易混淆,如疾病类型的实体之间就可能存在“症状相关”“转化相关”“病发症”“病理分型”等多种不同关系,若关系分类训练的负样本不足则很难获得较好的精准率。在实体抽取方面,医学领域有很多长实体,存在实体嵌套、边界难以划分的问题。例如,“免疫功能低下患者”可能被错误识别为“免疫力”或“免疫力功能低下”。
根据实体和关系抽取任务的表示层是否共用,实体关系抽取模型可以分为实体关系联合抽取和实体关系流水线抽取两大类,其中流水线抽取模型可以分别针对实体和关系任务训练最优的编码器,从而取得较好的效果[2];然而,此类模型存在没有考虑实体抽取错误导致的误差叠加和错误层级传播的问题。
本文针对实体关系流水线抽取框架存在的误差传递问题,提出用于进行数据增强的关系负例生成模块,同时针对医学文本特点对实体抽取和关系抽取进行优化。本文的主要工作如下:
1)关系负例生成模块。为了缓解误差传递,本文通过数据增强方法模拟生成容易引起误差传递的关系负例。具体地,利用关系负例生成模块中的基于欠采样的伪实体生成模型(Under-Sampling-based Pseudo-entity Generation Model,USPGM)生成可以混淆关系抽取模型的“伪实体”,再结合关系数据增强策略对关系抽取任务进行数据增强。USPGM 采用基于片段的解码方式,可以处理不同粒度的实体,并利用悬浮标记[3]提高伪实体生成的F1 值。适当的欠采样率可以在保证一定精准率的情况下大幅增强召回能力,从而满足生成多样伪实体的目的。此外,本文还提出了三种数据增强生成策略,以解决主语宾语颠倒、主语宾语边界错误和关系分类错误等问题,提高关系抽取阶段鉴别错误关系的能力。
2)基于Transformer 特征读取的实体抽取模型(Transformer Feature Reader based entity extraction Model,TFRM)。本文针对医学实体密集、短语形长实体较多且边界难以划分的问题,选用Transformer[4]网络作为实体类别特征读取器,利用解码器模块的交叉注意力计算单元计算实体类别特征对于序列特征向量的注意力,强化原有的向量表示,增强对整体类别语义信息的捕捉能力。与基于片段的模型相比,TFRM 采用的序列解码方式能更好地平衡医学实体嵌套造成的粗粒度长实体和细粒度短实体边界难以区分的问题,提升实体抽取阶段的精准率。
3)基于悬浮标记关系抽取模型(Levitated-Marker-based relation extraction Model,LMM)。数据增强在缓解误差传递的同时也带来了训练时间成倍增加的问题,若仍采用传统的关系抽取模型,即使利用GPU 加速运算,也几乎无法完成正常的调参工作。为了解决这个问题,本文采用LMM,在保证精准率的前提下,大幅减少了模型训练所需的时间,提高了推理速度。
1 相关工作
1.1 实体关系抽取
早期实体关系抽取的工作主要依靠模板和词典完成,这类工作通常由领域专家结合专业知识设计模板,以匹配实体和关系[5-7]。然而,这种方法的精准率严重依赖词典和模板设计的质量,灵活性差,召回率较低。随着传统机器学习技术的快速发展,以特征工程为核心的机器学习模型被广泛应用于实体关系抽取领域[8-11]。这些模型将实体识别和关系抽取转化为依赖特征集与核函数的分类任务;但性能效果仍然依赖于人工设计的特征工程和核函数,在模型层面上仍需要大量人力。近年来,深度学习方法被大量应用于实体关系抽取工作。深度神经网络架构中的卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)是解决实体关系抽取的两大主流模型。CNN 模型可以获取局部特征,RNN 模型则具有捕捉序列前后依赖的能力。与传统方法相比,基于深度学习的方法无须进行繁琐的特征工程,可自动从领域文本中提取文本的语义表示。Li 等[12]通过结合依存句法分析和双向长短时记忆循环神经网络(Bi-directional Long Short-Term Memory RNN,Bi-LSTM-RNN)模型完成实体关系抽取;Bekoulis 等[13]构建了基于对抗训练的Bi-LSTM(Bi-directional Long Short-Term Memory)模型,提高了抽取的鲁棒性;张世豪等[14]在Bi-LSTM 和CNN 的基础上提出了融合多通道自注意力机制的中文医学实体关系抽取模型。
预训练模型可以通过自监督的方式从海量文本中获取知识,并能考虑上下文为文本提供动态的向量表示,该类模型显著提升了自然语言处理领域模型的性能。BERT(Bidirectional Encoder Representation from Transformer)[15]和ELMo(Embeddings from Language Models)[16]是该类模型的代表,被广泛应用于实体关系抽取。Luo 等[17]使用ELMo 作为表示层,提出了一种基于注意力机制的模型;Zhao 等[18]通过阅读理解的方式将实体关系抽取转化为序列预测问题;Eberts 等[19]提出了基于片段的端到端实体关系联合抽取模型SpERT(Span-based Entity and Relation Transformer),通过拼接预训练模型向量表示、实体大小嵌入表示、关系上下文特征对实体片段和关系进行分类;Shen 等[20]在SpERT 的基础上加入了触发器感知流捕获实体和关系之间的联系,并使用图神经网络引入了语法依赖等额外信息,进一步提高了模型的性能;Zhong 等[2]提出了一种实体关系流水线处理模型,分别训练实体和关系的预训练模型,实验证明联合抽取模型可能会混淆预训练模型的表示,流水线式的模型性能更佳;Ye 等[3]使用面向相邻实体的填充式悬浮标记,将相同起始位置的片段的悬浮标记填充在一条语句中,以获取片段之间的联系,进一步提高了实体关系抽取的性能。
1.2 数据增强
数据增强(Data Augmentation,DA)是一种从有限的数据挖掘更多数据以扩展训练数据集的技术。它用于克服训练数据不足、缓解数据偏见和解决样本不平衡,在深度学习的各个领域都得到了广泛的应用[21]。本文使用DA 技术解决容易混淆关系抽取模型的负样本数据不足的问题,缓解实体关系抽取过程中的误差传递。
数据增强主要分为两类:基于规则和基于模型。
基于规则的数据增强方法的代表是:Wei等[22]提出的简单数据增强(Easy Data Augmentation,EDA)方法,通过对文本进行随机替换、插入、交换和删除等操作增加样本数;Abdollahi等[23]提出了基于本体引导的数据增强方法,使用统一医学语言系统(Unified Medical Language System,UMLS)识别句子中的医学本体,并将本体替换成词典中的同义词,丰富训练数据;Kang等[24]同样使用UMLS结合EDA实现实体抽取。
基于模型的数据增强方法通过神经网络模型直接生成训练样本或参与样本生成的过程。直接生成训练样本的典型例子是Sennrich 等[25]提出的基于“回译”的数据增强的方法,即将序列翻译成另一种语言后再翻译回原始语言,从而直接生成样本。参与样本生成的数据增强模型更常见,例如Wang 等[26]提出的基于强化学习的数据增强方法,通过强化学习训练一个生成器生成数据增强动作序列,以解决传统数据增强中神经网络模型与数据增强模块之间缺乏联系的问题。Kobayashi 等[27]通过将单词替换为根据上下文语言模型分布得到的单词来生成增强示例。Yang 等[28]从预训练的语言模型生成的示例中选择信息量最大和最多样化的集合进行扩充。Quteineh 等[29]类似地使用GPT-2 标生成标记,证明了DA 方法的有效性。
2 本文模型
2.1 模型背景
2.1.1 任务介绍
医学实体关系抽取任务的输入是医学文本,在经过标记解析器分词后得到长度为n的标记序列X={x0,x1,…,xn},再由预训练模型得到特征表示H={h0,h1,…,hn}。实体关系流水线抽取可分解为实体抽取和关系分类两个子任务。
实体抽取 给定实体类别集合E,实体抽取任务是从标记序列X中提取实体片段及其类别的集合Y={(si,ei),si∈S,ei∈E},其中实体片段集合S用于标识实体位置。实体抽取任务可以分为基于序列标签预测的实体抽取和基于实体片段的实体抽取两种类型。
基于序列标签预测的实体抽取首先对序列中的每个标记预测它的类别,得到标签序列O={o0,o1,…,on},然后通过解码算法获得实体片段和实体类型,并输出实体集合Y=decoder(O)。基于实体片段的实体抽取任务是先定义一个最长的实体片段长度l,再枚举出标记序列X中所有可能的片段集合S,对于每个片段si∈S,预测它的实体类型ye。
关系分类 记R为预定义的关系抽取框架,关系抽取任务是对Ssub×Sobj中的每一组候选实体片段对(si,sj)预测关系类型yr∈R,该任务的输出为关系三元组集合T={(si,sj,yr):si∈Ssub,sj∈Sobj,yr∈R}。
2.1.2 悬浮标记
标记是指通过标记解析器拆分字符串后得到的符号,每个标记都被分配唯一的ID。例如,将“Miller-Fisher 综合征”经过标记解析器后,可以得到标记[“Miller”,“ -”,“ Fish”,“##er”,“综”,“合”,“征”]。除了由文本生成的标记,还有一类特殊标记,这些标记不与实际输入建立映射,而是额外加入模型序列,用于提醒预训练模型捕捉任务所关注的信息。例如,在BERT 中,规定使用“[CLS]”进行全局预测,“[SEP]”用于分隔序列。本文中定义了与任务相关的特殊标记,例如在后文的USPGM 实体抽取模型中,使用标记实体头,标记实体尾;在LMM 掩码示意图中,使用x,x标记主语标记宾语。标记可以被插入到原始输入中实体所在位置的前后,以便预训练模型关注该位置;但是由于标记的引入对原序列具有侵入性,因此每条输入语句只能对应一组标记,如果要枚举所有主语宾语组合,则需要额外生成大量的输入序列。
悬浮标记可以让模型尽早接触实体的位置信息,解决输入序列过多的问题。具体地,为了避免对原始输入造成侵入,悬浮标记被打包到一起,拼接在原始序列的末尾。悬浮标记通过和它所关注的原始输入的标记共享相同的位置ID,提醒模型关注原输入相关位置。
2.2 模型主体
本文提出的实体关系抽取框架共分为3 个部分:1)基于Transformer 特征读取的实体抽取模型;2)关系负例生成模块;3)基于悬浮标记关系抽取模型。
整体模型流程示意图如图1 所示。在实线指示的训练阶段,首先训练实体抽取模型TFRM 和USPGM。实体抽取模型训练结束后,再使用USPGM 模块生成用于数据增强的伪实体,并根据数据增强策略生成伪关系训练样本。最后LMM 使用数据增强后的训练样本完成关系分类模型的训练。在虚线指示的测试和抽取阶段,LMM 对TFRM 抽取得到的实体对预测关系。

图1 整体模型流程示意图Fig.1 Schematic diagram of overall model process
2.2.1 基于Transformer特征读取的实体抽取模型
为了更好地捕获主语头尾和宾语头尾的特征,本文设计一种基于Transformer 特征读取的实体抽取模型。该模型借助Transformer 解码器单元对实体类别特征进行读取操作,从而分别获取相应类别的全局特征,并用这些特征增强原有的序列表示。
TFRM 模块的训练分为两个阶段。如图2 虚线所示的第一个阶段仅包括特征写入(更新),目的是优化主语头、主语尾、宾语头、宾语尾的类别特征表示;第二个阶段为特征读取阶段,在该阶段继续更新类别特征,并通过Transformer 解码器的交叉注意力计算单元读取不同实体的特征,以进一步强化相关的特征表示。
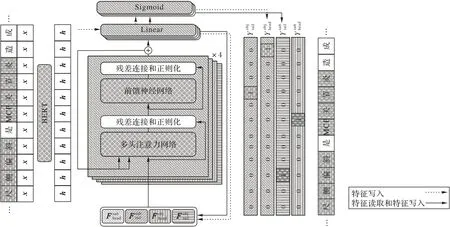
图2 TFRM示意图Fig.2 Schematic diagram of TFRM
特征写入(更新)阶段 在图2 实线所示的特征写入阶段将实体分类器的权重视为实体的特征,由交叉熵损失函数更新主语头尾、宾语头尾的特征:
其中:L代表实体序列预测的损失函数,lr代表学习率,p(yi=e) 表示第i个标记预测结果属于类别e的概率,e∈E=
特征读取阶段 本文采用N层TFRU 结构读取实体类别特征的信息。每层结构由交叉注意力网络和全连接前馈神经网络两个子层组成。各子层之间采用残差连接和正则函数进行连接。
SubLayer 在TFRU 单元中指多头交叉注意力网络或全连接前馈网络。其中交叉注意力网络的计算公式如下:
多头交叉注意力由u个头的注意力拼接后,再通过一个权重为W全连接网络计算得到,其中[Α:B]是向量的拼接操作。
将读取到的特征HTFRU和原序列标记特征HBERT取平均得到序列的向量表示HMEAN。再经由两个线性变换与ReLU激活函数构成前馈神经网络(Feedforward Neural Network,FNN)获得序列最终的特征表示:
解码 对于TRFU 模块得到的序列特征,本文使用参数为F的全连接层得到序列的标签得分。给定阈值α,当VScore>α时,认为该标记属于e类型。
解码算法主要基于贪心的思想。先根据实体头的预测序列找出实体片段的起始位置,再从该位置开始遍历相应类别的实体尾预测序列,以寻找该实体片段的结束位置。在遍历实体尾预测序列的过程中,若发现了另一个实体片段的起始标记,则舍弃当前查询的实体片段。具体步骤如下:
输入 实体头预测标记序列Ohead,实体尾预测标记序列Otail;
2.2.2 关系负例自动生成模块
实体抽取负例欠采样 欠采样是处理非平衡分类问题时的常用手段,通过对数量多的一类样本进行少量随机选择,使样本变得平衡,从而使模型更好地关注缺少样本的类别。本文通过对实体片段的负例进行欠采样,使得模型更倾向于预测正例,以获得更多的伪实体。这些伪实体将在后续的数据增强策略中使用,用于生成关系训练样本。
在图3 的例子中,通过枚举所有可能成为实体的片段得到共计个候选实体片段,其中实体片段正例样本集合为Spos,对应图3 中使用条纹填充的片段。负例样本集合为Sneg=S/Spos,对应图3 中未使用条纹填充的片段。通过对负例样本集合随机采样得到负例采样集合Ssample=RandomSampling(Sneg)。最终的实体训练样本集合为正例集合与采样集合的并集,Strain=Spos+Ssanple。
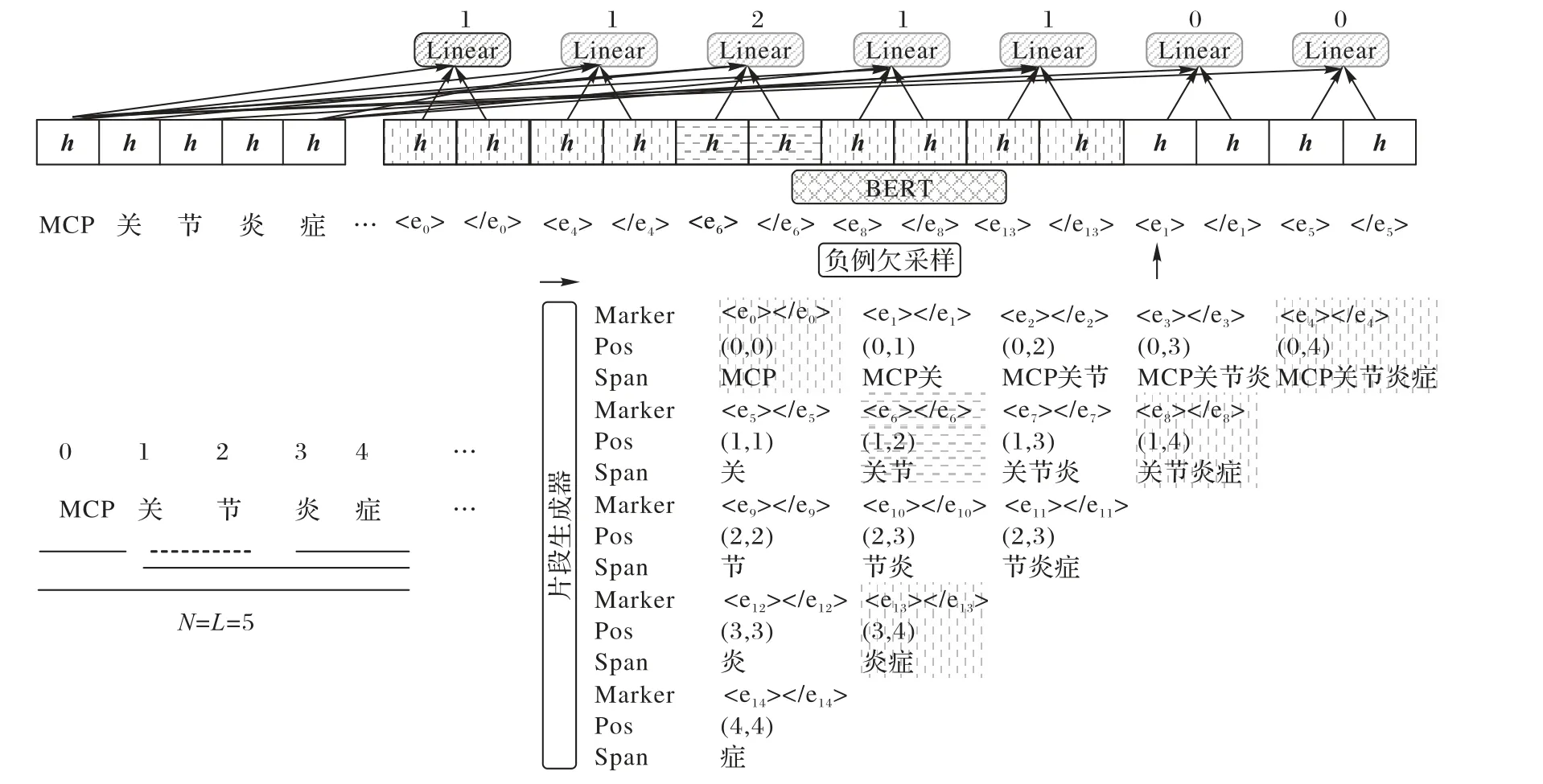
图3 USPGM示意图Fig.3 Schematic diagram of USPGM
基于欠采样的伪实体生成模型 与基于序列的TFRM不同,USPGM 属于基于片段的实体抽取模型,支持识别不同粒度的嵌套实体。为了让预训练模型能提前意识到实体片段的存在,可将对应实体片段的悬浮标记拼接到原始标记序列后。
将带有悬浮标签的序列送入与训练模型后得到对应的特征表示H。实体片段的特征hsipan由头尾位置处的标记和共享位置的悬浮标记的特征表示拼接到一起得到,并使用一个全连接层得到该实体片段的类别。
伪关系生成策略 数据增强的目的是解决关系分类模型中误差传递导致的假正例问题,并提高模型的精准率。造成假正例误差传递的关系组合有以下几种:主语宾语位置颠倒、主语或宾语边界不正确、关系与句子语义无关,以及关系分类错误。
在没有数据增强的情况下,关系抽取的训练样本仅包括人工标注(ground truth,gt)主语和人工标注宾语的笛卡尔乘积,其中T指的是关系三元组。
本文提供的3 种数据增强策略如下。
1)为了提高模型识别主语宾语颠倒的能力,可以使用逆关系进行数据增强,即将人工标注中的主语作为宾语,将宾语作为主语构建新的负例训练样本。
2)进一步地,对于主语宾语颠倒的情况,还可以为逆关系添加标签Rreverse。例如,在三元组(痛风主语,鉴别诊断关系,RA宾语)的逆关系上添加伪标签“逆-鉴别诊断关系”,从而获得新的训练样本(R A主语,逆-鉴别诊断关系,痛风宾语),记作Tgt_reverse_label。
3)主语或宾语边界不正确、关系分类错误的情况通常是由于负例样本不足导致的,因此,利用USPGM 生成的伪主语和伪宾语的笛卡尔乘积生成伪关系样本:
2.2.3 基于悬浮标记关系抽取模型
如表1 所示,使用增广策略进行训练后的训练样本数是原模型的7 倍,给模型训练带来时间和资源上的浪费。然而,医疗文本常围绕同一实体介绍知识,通常多个宾语共用同一个主语。从表1 可以看出,宾语数大于主语数,且一段文本中通常只有一个主语。因此,只将主语的实际标记x,x插入原始输入中,而对于相同主语的宾语,则使用悬浮标记以提高计算速度。
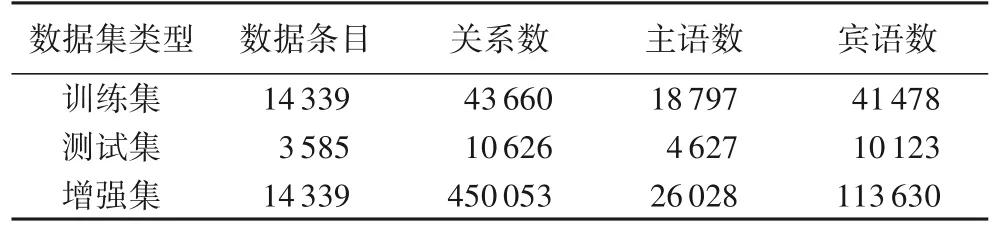
表1 实验中使用的CMeIE数据集信息Tab.1 Information of CMeIE dataset used in experiment
同时,为了避免悬浮标记对原输入带来噪声,或者不同宾语的悬浮标记之间产生噪声,在预训练模型处采用有向注意力掩码。每个悬浮标记只会对它相匹配的悬浮标记可见,而不会对正文的字符或其他悬浮标记可见。LMM 中的掩码矩阵如图4 所示。

图4 LMM中的注意力掩码矩阵Fig.4 Attention mask matrix in LMM
主语和宾语的特征表示分别用与它对应标记的头尾特征表示拼接得到,使用全连接层分别得到它们的关系分类得分,关系分类的最终得分为主语和宾语得分之和。
3 实验与结果分析
本文的实验评估在CBLUE(Chinese Biomedical Language Understanding Evaluation)的 CMeIE(Chinese Medical Information Extraction)数据集(数据集网址https://tianchi.aliyun.com/dataset/95414)上进行。CBLUE 是国内首个医疗信息处理领域公开的基准数据集,CMeIE 是CBLUE 数据集中的一个子任务,该数据集是由2 位来自三甲医院的专家和20名硕博研究生进行标注的医学领域数据集,其中设计了53 类关系。表1提供了CMeIE数据集的详细数据分布情况。
3.1 数据处理
由于CMeIE 只提供关系三元组信息,没有提供实体在句子中的具体位置,需要先通过预处理确定实体具体位置。默认从左到右找到第一个匹配实体位置作为标准答案。在经过标记解析器分词之后,截取最大标记序列长度到128。从训练集中剔除超过该长度实体和包含该实体的关系样本,但测试时仍会考虑这部分数据。
3.2 参数设置及实验环境
本文模型均使用BERT-base-Chinese[30]作为预训练模型,采用AdamW 作为优化器,并用预热策略进行训练。对于基于实体片段的模型需要设置最大片段长度。如图5 所示,大多数实体的长度集中在1~10。本文将最大实体片段长度设为20,可以覆盖99.96%的实体。对于TFRM,TFRU 层数设置为2,特征读取开始的Epoch 设置为5。其他具体实验参数如表2 所示。

表2 实验参数详情Tab.2 Details of experimental parameters
3.3 评价指标
本文采用精确率P(Precision)、召回率R(Recall)以及F1(F1 值)作为实体关系抽取的评价指标。这些指标在CMeIE的dev 数据集上通过微平均的方式计算,具体公式如下:
其中:TP指正确识别的实体或关系数;FP表示预测为某一类型但识别错误的实体或关系数,即假正例;FN表示未能预测出的实体或关系数。
3.4 实验结果
为了验证本文模型的有效性,将它与基于预训练的实体关系抽取基线模型进行对比。
3.4.1 基线模型
1)SpERT[19]是一种实体关系联合抽取模型。在实体抽取模块中将实体片段的最大池化特征、长度特征以及“[CLS]”标记的全局特征拼接起来,作为实体的特征表示。在关系抽取部分,首先通过实体筛选器筛选出得分大于阈值的主语和宾语,然后将主语和宾语的最大池化特征、长度特征和两个实体之间的上下文特征拼接起来,作为这组关系的特征表示。
2)PURE(Princeton University Relation Extraction)系 统[2]属于流水线式实体关系抽取模型。在实体抽取部分,将实体的头尾字符特征拼接起来,并通过一个两层的前馈网络进行分类,从而得到实体的表示;在关系抽取部分,在主语和宾语的位置同时插入标记,并将标记处的特征拼接起来,再通过全连接层进行分类。
3)PL-Marker(Packed Levitated Marker)[3]属于流水线式的实体关系抽取模型。在实体抽取部分,相同起始位置的实体片段的悬浮标签被打包在一起作为一个样例,实体片段头尾和对应悬浮标记拼接的特征被用于分类。在关系抽取部分,使用主语处的实标记和宾语的悬浮标记进行分类。
4)CBLUE[31]同样属于流水线式的实体关系抽取模型。其中实体抽取任务被视为序列预测任务,对每个标记的特征使用全连接分类器进行预测。而关系抽取任务和PURE 的处理方式类似。
3.4.2 性能提升
实体关系抽取的实验结果如表3 所示,本文模型相较于之前的工作性能显著提高。相较于基线模型PL-Marker,实体抽取部分的TFRM 的F1 值提升了2.26%;而实体关系抽取整体F1 值提升了5.45%,精准率提升了15.62%。这些结果表明,通过数据增强,模型能够更好地解决误差传递问题,并针对实体抽取中得到的错误实体做出更加精准的判断。

表3 各模型总体实验结果比较 单位:%Tab.3 Comparison of experimental results among different models unit:%
3.5 消融实验
为了更深入地分析本文模型各个组件的有效性,进行了消融实验。为了避免其他因素对模型的影响,本文在所有的消融实验中未提及的参数与表2 中的设置保持一致。
3.5.1 负例欠采样
在实体抽取阶段,不同的负采样率同样会影响模型的效果。根据图6 采样数-模型性能曲线,随着采样数的增加,模型的精准率和F1 值逐渐提高,但是召回率却不断降低。这表明可以通过欠采样的方式提高模型的召回能力,生成尽可能全面的伪实体。最终选择采样数为128 的模型生成伪实体。在该采样数下,模型的召回率较高,且精准率也超过了60%,不会引入过多低质量的伪实体。

图6 采样数-模型性能折线图Fig.6 Sampling number-model performance line chart
3.5.2 TFRM
为了验证实体抽取模型TFRM 的有效性,比较了使用相同关系抽取模型但不同实体抽取模型的效果。如表4 所示,相较于PURE、PL-Marker 和CBLUE 提出的模型,本文提出的TFRM 在F1 值上分别提高了3.15、2.03 和0.61 个百分点。对于TFRM 的核心模块TFRU,由表5 可见,添加该模块后模型的精准率有了显著提高,对于使用不同层数TFRU 的模型,使用2 层的模型召回率较高,且最终应用于关系分类模型的效果较好。值得注意的是,对比未使用TFRU 的模型,虽然模型的精准率得到了较大程度的提升,但最终对于关系分类精准率的提升的贡献并没有特别显著。可能的原因是本文提出的数据增强模块提高了关系分类模型鉴别实体抽取部分错误信息的能力。
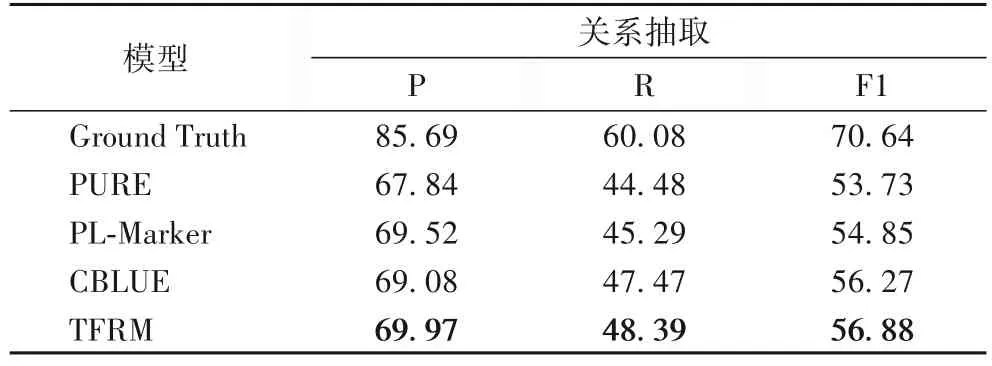
表4 实体抽取模型实验结果比较 单位:%Tab.4 Comparison of experimental results of entity extraction models unit:%

表5 TFRU模块参数对比实验结果 单位:%Tab.5 Comparison experiment results of TFRU module parameters unit:%
TFRU 注意力模块可以为不同实体类型提供针对性的全局信息。以图7 所示的2 层TFRU 模块的权重分布情况为例,layer0 用于获取低层次的全局上下文信息,而第1 层的权重分布差异较大,能够针对实体类型的不同关注句子中不同的位置。通过注意力可视化可以发现模型能够根据上下文信息有效地去除不相关实体(图7(a)所示)。如果不使用TFRU,对于宾语,会额外得到“肝功能障碍”“低血糖”两个假正例的宾语。从整个句子的分析可以推断出,该语句主要关注的是和“检查”相关的实体。在TFRU 的第1 层实体头特征读取时,对于假正例实体的关注较弱,但它会根据上下文强化对正确答案“电解质测试”的关注。另外,TFRU 可以正确识别医学文本中大量短语类的长实体和嵌套实体(如图7(b)所示)。若不加入TFRU 机制,模型抽取的宾语是“免疫力低下”,而根据文本分析,正确的宾语应该是“免疫力低下患者”。可以看出在对实体头读取过程中,第1 层对于“者”的关注更强,从而修正了错误。

图7 TFRU注意力可视化Fig.7 TFRU attention visualization
3.5.3 关系负例自动生成模块
为了证明关系负例自动生成模块的有效性,进行了消融实验,比较了负例生成模型和伪关系生成策略对于模型性能的影响。如表6 所示,当移除所有数据增强数据时,模型的F1 值下降了3.24 个百分点,而精准率下降了11.26 个百分点。
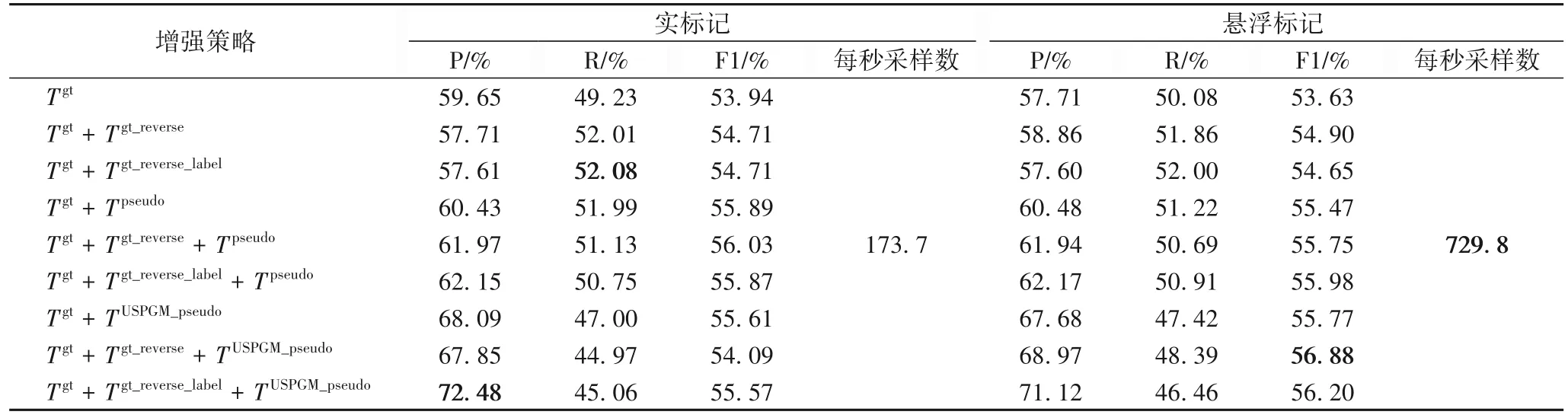
表6 关系负例自动生成模块消融实验结果Tab.6 Ablation experimental results of automatic generation module of relation negative examples
关系负例自动生成模块由模型和增强策略两部分组成,本文分别分析了这两个部分对于模型性能的影响。
不同的增强策略 如表6 所示,采用增强策略1:Tgt+Tgt_reverse后,模型的F1 值提升了1.27 百分点;采用增强策略2:Tgt+Tgt_reverse_label则提升了1.02 百分点;而仅使用增强策略3:Tgt+TUSPGM_pseudo则提升了2.15 个百分点。其中,增强策略3由于使用了额外的伪实体,对F1 值提升的效果最佳。相比增强策略1,增强策略2 虽然增加了逆关系标签这一额外信息,但表现更差,原因在于在最后的分类阶段,分类器需要考虑的关系类型翻倍,因而在优化过程中对于逆关系的关注影响了正常关系的判断。对比不同增强策略的组合效果,其中策略2 和策略3 的组合效果最佳。
伪实体生成的模型 基于USPGM 生成的伪实体的数据增强数据TUSPGM_pseudo相较于未采用欠采样机制的伪实体生成模型生成的Tpseudo,单独使用和组合使用时,F1 值分别提高了0.3 和1.13 个百分点,其中精准率分别提高了7.2 和7.03 个百分点。
案例分析 关系负例自动生成模块对于关系抽取的提升体现在两个方面。
1)可以提高关系模型对于实体抽取阶段错误主语和宾语的纠正能力。如表7 所示,未使用数据增强的模型在案例一中错误地将“吉兰-巴雷综合征的特殊亚型”作为主语抽取,并在案例二中错误地将“地高辛”作为宾语识别。然而,通过语境可以发现这两个实体之间的关系在文本中并没有被明确提及,本文模型可以正确地进行预测。

表7 案例分析Tab.7 Case analysis
2)可以纠正模型对于正确实体的假正例或分类出错的情况,提高模型的精准率。在表7 的案例二中,未使用数据增强的模型错误地将关系类型识别为(室上速主语,同义词关系,室性心动过速宾语),属于分类出错的情况。另外,在案例二中,(室上速主语,同义词关系,室速宾语)则是一个假正例。
3.5.4 基于悬浮标记关系抽取模型
如表6 所示,基于悬浮标记的关系抽取模型的训练速度相较于传统实标记的模型提升了3.2 倍。但在模型性能方面,由于基于悬浮标记的模型主语处使用实标记而宾语处使用悬浮标记,导致主语和宾语特征表示的能力不平衡。虽然悬浮标记没有对输入造成侵入性的修改,但同时降低了对预训练模型的提示能力,使得当宾语信息较少时,仅使用Tgt的情况下,基于悬浮标记的模型的F1 值略低于基于实标记的模型。然而,当使用由USPGM 生成的样本进行数据增强后,宾语的多样性和数量的增加弥补了使用悬浮标记带来的性能影响。特别是在使用TUSPGM_pseudo增强策略时,基于悬浮标记的模型的F1 值均超过了基于实标记的模型。
4 结语
本文提出并验证了一种基于伪实体数据增强的高精度医疗实体关系抽取框架,并对实体抽取和关系分类两个阶段进一步优化。模型在公开医学关系抽取数据集CMeIE 表现出较好的性能,F1 提升了5.45%,精准率提升了15.62%。
本文提出的框架主要包括3 个部分:1)针对实体关系流水线框架存在误差传递的缺陷,在经典的流水线模型的基础上插入关系负例自动生成模块。使用欠采样的伪实体生成模型获取用于数据增强的伪实体,并提供了三种数据增强的策略。消融实验结果表明,基于欠采样模型生成的伪实体对于关系分类模型的性能的提升更大,尤其在精准率指标上模型提升幅度较大,证明欠采样模型可以生成更加多元和全面的伪实体。由三种不同的数据增强策略生成的增强数据,都对于关系分类任务性能有着不同程度的提升,其中Tgt+Tgt_reverse+TUSPGM_pseudo的组合方式取得了最好的效果。说明这种数据增强的组合下,数据可以更全面地为关系分类模型提供主语宾语颠倒、主语或宾语边界不对、关系分类错等情况的负样本。2)提出了基于Transformer 特征读取的实体抽取模型。TFRU 单元通过读取不同实体类别的特征信息强化相应类别的序列特征表示,实验和可视化结果表明该模块可以有效捕获全局类别信息,解决医学实体长、密度大、干扰多的问题,提高实体抽取的精准率。3)为缓解数据增强带来的时间成本剧增的问题,选用悬浮标记批量打包同主语的关系,通过一种非侵入式的方式将相同主语的宾语信息拼接到一条训练样本中,通过实验证明该模型的训练速度提高了3.2倍,且在训练数据充足的情况下,模型的性能甚至略优于基于实标记的模型。
在未来的工作中,将进一步提高模型的精准率。目前本文所使用的数据增强算法并没有引入额外的知识,然而在研究中发现,存在大量实体和关系在缺乏先验知识的情况下仅依靠上下文或其他训练样本无法得到准确信息,如对缺乏医学专业知识的人,很可能认为“颅内出血”是一个“症状”而非“疾病”。因此如何将额外的医学知识引入到模型中,将是未来亟待解决的问题。
猜你喜欢
语数外学习·高中版中旬(2023年7期)2023-08-25
疯狂英语·新阅版(2023年7期)2023-08-17
疯狂英语·初中天地(2021年4期)2021-06-09
疯狂英语·初中天地(2019年12期)2020-01-04
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中学生英语(2016年11期)2016-12-01
渭南师范学院学报(2014年12期)2014-03-20
