
运动想象脑电信号的跨被试动态多域对抗学习方法
2024-03-21 02:25罗天健
计算机应用 2024年2期
曹 铉,罗天健*
(1.福建师范大学 计算机与网络空间安全学院,福州 350117;2.数字福建环境监测物联网实验室(福建师范大学),福州 350117)
0 引言
脑机接口(Brain Computer Interface,BCI)采集人脑信号并解译成控制指令,绕过外周肌肉系统达到控制外部设备目的,实现人脑与外部设备的直接通信[1]。由BCI 技术构建的系统不但能够为脑卒中类病人提供辅助康复[2],还能服务于工业生产和多媒体娱乐[3]。按照采集人脑信号级别,BCI 技术通常划分为非侵入式和侵入式[4]。其中,非侵入式手段无须开颅手术,其代表性的脑电(ElectroEncephaloGraphy,EEG)信号[5],采集时间分辨率较强的脑皮层信号,广泛应用于常人可参与的场景。基于EEG 信号的常见BCI 任务包括:运动想象,事件相关电位,以及稳态视觉电位。其中,运动想象(Motor Imagery,MI)为主动BCI 技术,通过分析记录不同肢体MI 过程中的EEG 信号,解码出相应的意图并形成控制指令。运动想象脑电(MI-EEG)信号编码运动脑区,不同肢体MI 意图特征主要集中在μ 节律和β 节律,呈现大脑同侧能量增加以及对侧能量降低的模式,该模式被称为事件相关去同步(Event-Related Desynchronization,ERD)现象[6]。解码MI-EEG 信号即为识别出不同MI 意图ERD 模式,从而获取BCI 系统可用的控制指令。
实际上,MI-EEG 属于典型时变性强、多通道耦合且信噪比低的信号,它的解码过程是一项具有挑战性的困难任务。常用的MI-EEG 信号解码方法包含两个分支:以共同空间模式(Common Spatial Pattern,CSP)为代表的空域特征滤波器,和以卷积神经网络(Convolutional Neural Network,CNN)为代表的端到端模型。CSP 方法[7]构建类别间最优空域投影,保证不同MI 类别的空域特征差异最大化。基于CSP 特征,Ang等[8]通过滤波器组提取MI-EEG 不同频段FBCSP(Filter Bank CSP),并在各个频段上提取具有频率特性的CSP 特征。Kang 等[9]构建了被试间可迁移的组合CSP 特征(Composite CSP,CCSP),Samek 等[10]则在子空间中构建可迁移的CSP 特征SSCSP(Stationary Subspace CSP),这些可迁移的CSP 特征,在跨被试的MI-EEG 解码中取得了不错的效果。经典的CSP系列空域特征向量,一般使用支持向量机或线性判别分析实现分类。随着研究的深入,以支持矩阵机(Support Matrix Machine,SMM)为代表的直接矩阵分类方法,也被应用至MI-EEG 的分类[11]。Zheng 等[12]为了进一步提取稀疏特征,构造了稀疏支持矩阵机(Sparse SMM,SSMM),筛选稀疏的特征提升分类性能。CNN 模型则采用端到端的MI-EEG 解码过程,无须分类器,直接提取特征并获取分类结果。Schirrmeister 等[13]应用浅层CNN 模型(ConvNet)即获得了超越CSP 的解码性能。Sakhavi 等[14]使用CNN 模型学习了MIEEG 信号的时域信息C2CM(Channel-wise Convolution with Channel Mixing),同时联合时域和空域特征提升分类性能。Dose 等[15]采用一维卷积神经网络同时提取时域和空域特征MI-CNN(Motor Imagery-Convolutional Neural Network),并尝试应用于跨被试的迁移学习。
尽管以CSP 与CNN 为代表的解码方法已经在MI-EEG 分类中取得不错进展,但是由于EEG 信号的非线性、非平稳特性,使它在跨采集周期和跨被试上呈现分布变化,跨被试样本集不再符合独立同分布(i.i.d)假设,无法直接应用机器学习方法[16]。针对跨被试的MI-EEG 分类方法,以域适应(Domain Adaptation,DA)为代表的迁移学习方法取得了不错的解码性能。DA 类方法将每个被试者看作“域”,采用域适应方法提取域间可泛化的特征,从而实现跨被试MI-EEG信号解码,主要包含两大研究分支。一类是基于经典信号处理方法的EEG 协方差或特征对齐的方法。协方差矩阵均值能够衡量MI-EEG 样本集分布。Zanini 等[17]将协方差矩阵映射到黎曼空间,并将不同被试者信号的协方差均值对齐至单位矩阵(Riemannian Alignment,RA),随后提出了基于最小黎曼均值距离的分类器方法,获得了不错的跨被试解码性能。He 等[18]为了解决黎曼均值计算的低效率问题,直接在欧氏空间对齐协方差矩阵(Euclidean Alignment,EA),随后在对齐后的样本上提取CSP 特征,提升了跨被试解码性能。Zhang 等[19]则联合子带CSP 滤波与目标域对齐方法,获取了更有分辨性的跨域特征。在此基础上,Zhang 等[20]则构建了两步骤的对齐方法,首先通过EA 对齐协方差矩阵,提取切空间特征向量,随后在特征向量之上构建流形嵌入知识迁移方法,进一步提升了跨被试解码性能。Cai 等[21]则提出流形嵌入迁移学习方法,通过Grassmann 流形和结构风险最小化提升跨被试解码性能。
另一类方法则是基于深度神经网络的对抗学习方法。Ganin 等[22]首次将域对抗神经网络应用至图像跨域分类,通过域分类器保证特征提取器提取到域不变特征。近年来,域对抗学习方法也逐渐被应用至EEG 跨被试解码领域。Sakhavi 等[23]利用目标域被试样本集的伪标签样本,微调源域被试样本集预训练的CNN 模型,虽然达到跨域解码效果,但是当目标域样本量较少时容易造成过拟合问题。为了解决样本量稀少问题,Li 等[24]提出了一种双半球域对抗神经网络模型(Bi-hemisphere Domain Adversarial Neural Network model,BiDANN),解决跨被试样本分布偏移问题,并成功应用至EEG 情感识别。在基于对抗神经网络的跨被试MI-EEG解码中,Zhao 等[25]提出了深度表征的域适应(Deep Representation-based Domain Adaptation,DRDA)方法,通过同时优化MI-EEG 特征提取器、分类器和域鉴别器这3 个模块,由神经网络模型获取域不变的深度表征,提升解码性能。为了解决DRDA 方法忽略的不同MI 类别子域分布差异,Hong等[26]采用动态对抗适应网络(Dynamic Joint Domain Adaptation Network,DJDAN),在模型中加入多个子域鉴别器,以期提升对抗模型性能。
综上,在跨被试MI-EEG 解码领域,协方差对齐方法与神经网络域对抗模型并未有机结合起来,且最新的DJDAN 模型虽然考虑到多个子域的样本分布差异,但是构建了过于复杂的梯度反向传播模块,它的性能和效率还有进一步的提升空间。此外,文献[16]将协方差对齐方法与CSP 特征的联合分布对齐方法相结合,虽然有一定的性能提升效果,但是经典的联合分布对齐方法受限于所提取特征的有效性。通常情况下,CSP 特征仅能表达MI-EEG 的空域特征,其有效的时频域特征将被忽略。因此,它跨被试MI-EEG 解码的性能远低于基于神经网络的跨域对抗模型。针对现有跨被试MI-EEG 解码性能不足问题,本文提出了一种动态多域对抗网络(Dynamic Multi-Domain Adversarial Network,DMDAN)模型,该模型同时考虑到样本协方差对齐优势,以及面向不同MI 类别的多域对抗优势,并通过跨域对抗神经网络模型提取有别于经典CSP 特征联合分布对齐方法的有效特征,获取更佳的MI-EEG 解码性能。所提出的方法包含两个关键步骤:首先,针对不同被试样本域实施EA 样本对齐;其次,划分源域与目标域样本集,分别构建跨域所有样本的全局域鉴别器,以及跨域不同类别样本的类别子域鉴别器,通过多个鉴别器的动态多域对抗学习过程,提取全局域以及各MI 类别子域均不变的特征,服务于跨被试MI-EEG 解码。本文的主要工作如下:
1)融合样本协方差对齐方法和跨被试域对抗神经网络模型的优势,克服单一域适应类型方法的瓶颈,进一步提升了跨被试MI-EEG 解码性能。
2)分别针对跨被试样本集的边缘分布和条件分布,构建了全局域鉴别器和类别子域鉴别器,通过动态对抗学习过程适应两类分布,并在两个公开数据集上验证了可行性。
1 跨被试动态多域对抗学习方法
1.1 符号定义
假设MI-EEG 样本集Datasetu|u=1,2,…,U含有U个被试者,每个被试者u含有相同数量的样本集,其中:xi∈RC×T表示每个MI-EEG 样本,C为通道数,T为采集时间点数;yi表示相应的MI 类别标签。在跨被试的MI-EEG 解码中,每个被试者样本集被看作一个域D,该域由特征空间S'和边缘分布P(X)组成,包含有个样本,每个样本均来自特征空间S。通常,跨被试包含多源域至单目标域(Multi To Single,MTS)和单源域至单目标域(Single To Single,STS)的两种设定,而MTS 更符合MI-BCI 的应用特点。因此,本文研究MTS 问题,针对U个被试者,选定1 个被试作为目标域Dt,剩下U-1 个被试作为源域Ds,源域与目标域之间的EEG 样本来自不同分布。跨被试解码的目标是在ns个源域样本上学习解码模型M,使得nt个目标域上样本在M上取得最高的解码性能。
1.2 样本域协方差均值对齐
在划分源域Ds和目标域Dt之前,每个被试者域Du(u=1,2,…,U)的EEG 样本集存在边缘分布差异。由于协方差矩阵可有效刻画边缘分布,因此在进行对抗学习之前,本文应用EA 方法[18],对齐每个被试者域的协方差均值至单位矩阵,实现边缘分布域适应的预处理。针对被试者域Du,对该域中的个样本,首先计算协方差矩阵均值:
EA 方法应用协方差均值的-1/2 次幂对齐样本,即针对该域中的某个样本xi,通过如下方式对齐样本:
显然,由对齐后样本重新计算协方差矩阵均值即为单位矩阵I。因此,针对U个被试者域的EEG 样本,均实施式(2)的对齐策略,使得所有被试者样本集的协方差矩阵均为单位矩阵。经过EA 预处理后,选择任意被试者作为目标域,余下被试者作为源域,即可保证相同的协方差矩阵,减少了边缘分布差异。
1.3 DMDAN模型架构
实际上,仅依靠协方差矩阵的对齐,还不足以有效提升跨域MI-EEG 解码的性能。因此,本文在对齐后的样本集基础上划分源域Ds与目标域Dt,并基于CNN 模型构建动态多域对抗网络。图1 给出了本文构建的DMDAN 模型架构。
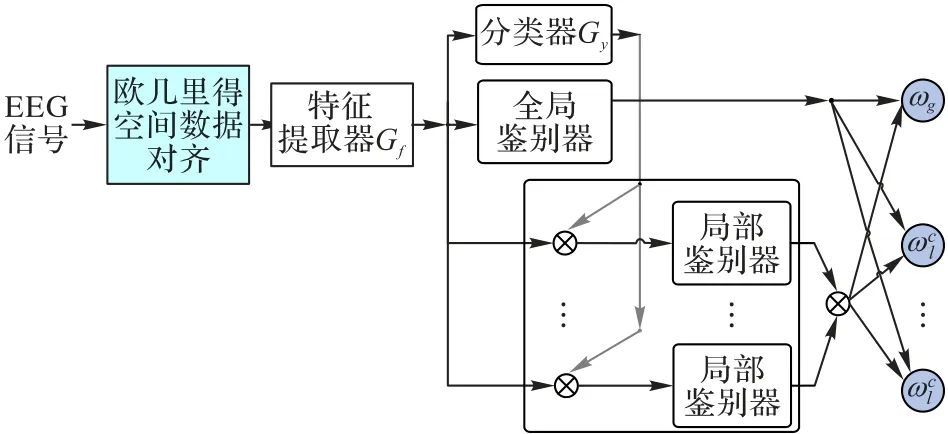
图1 DMDAN模型架构Fig.1 Architecture of DMDAN model
由图1 可知,DMDAN 模型涵盖4 个部分:特征提取器、分类器、全局域鉴别器和类别子域鉴别器。
DMDAN 模型的工作原理与流程如下:MI-EEG 信号xi∈RC×T首先经过EA 方法进行协方差对齐,对齐后的样本由特征提取器Gf提取特征fi,同时作为分类器、全局鉴别器和多个局部鉴别器的输入。如果xi来自源域Ds,还需根据源域的真实标签值和提取到的特征fi计算中心损失。分类器根据特征fi确定样本xi的类别向量P。全局鉴别器根据特征fi输出二分类概率,判断样本xi来自源域或目标域。局部鉴别器将特征fi和分类器的输出概率作为输入,由特征与类别的乘积Pi×fi判断对应子类的样本xi来自源域或目标域。模型的训练过程如下:将全局鉴别器和多个子鉴别器的输出概率值和输入样本xi的真实域标签值之间的交叉熵,分类器的输出概率和样本xi的真实分类标签之间的交叉熵,以及样本xi的中心损失,共同构建损失函数并采用梯度下降方法,逐步优化DMDAN 的模型参数。在模型的训练过程中,全局鉴别器和多个局部鉴别器的损失在梯度下降前还需要分别乘以对应的动态对抗系数ωg、,动态对抗系数在图1中用ω表示。
1.3.1 特征提取器与分类器
由于MI-EEG 信号中含有复杂时变和空间耦合特征,因此采用经典的ConvNet[13]模型,分别对时域和空域进行卷积操作,实现DMDAN 模型的特征提取器。鉴于MI-EEG 样本时间维度较高,采用1×30 的卷积核提取时域特征,而采用C×1 的卷积核提取所有采集通道的空域特征。在特征提取卷积操作后,连接均值池化层防止过拟合。为进行MI 任务分类,首先采用两个全连接层将卷积特征图转化为特征向量,最后采用softmax 实现分类,选择概率最高的类别输出。图2给出了特征提取器和分类器的结构。

图2 DMDAN模型中的特征提取器和分类器结构Fig.2 Architectures of feature extractor and classifier in DMDAN model
表1 给出了特征提取器与分类器CNN 模型参数。

表1 特征提取器与分类器CNN模型参数Tab.1 CNN model parameters of feature extractor and classifier
1.3.2 全局鉴别器
虽然通过EA 对齐方法降低了边缘分布差异,但是由特征提取器提取到的源域与目标域特征依然存在边缘分布差异。在DMDAN 模型中,本文构建的全局域鉴别器进一步降低边缘分布差异。采用DRDA 模型[25]的对抗学习思路,全局域鉴别器构建源域与目标域特征的二分类问题,通过对抗训练保证鉴别器无法鉴别特征来源,达到提取全局域不变特征目的。全局域鉴别器在二进制标签集Z={0,1}上进行对抗学习,并将源域和目标域特征向量的类别标签分别设置为0和1。表2 给出了全局域鉴别器的CNN 参数,具体由4 个全连接层组成,分别为128、64、32 和1。其中,前3 层采用修正线性单元(Rectified Linear Unit,ReLU)作为激活函数,最后1层采用二分类sigmoid 激活函数。图3 给出了全局鉴别器和特征提取器的结构。

表2 全局域鉴别器和各类别子域鉴别器CNN模型参数Tab.2 CNN model parameters of global discriminator and all local discriminators
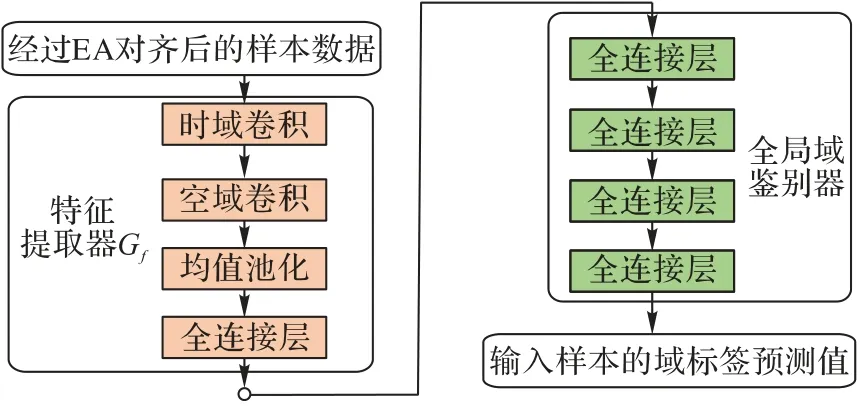
图3 DMDAN模型中特征提取器和全局鉴别器结构Fig.3 Architecture of feature extractor and global discriminator in DMDAN model
1.3.3 类别子域鉴别器
研究表明,域适应中边缘分布和条件分布同等重要[27]。在基于神经网络的域对抗学习中,Yu 等[28]采用子域鉴别器进行条件分布适应,而DJDAN 将它应用至跨域EEG 解码中。同样地,DMDAN 模型通过添加类别子域鉴别器,解决源域和目标域具体MI 类别的条件分布适应问题。具体地,添加与MI 类别数相同的子领域鉴别器,负责源域与目标域中同一个类别的样本集条件分布适用,对抗学习过程与全局域鉴别器类似。由于在条件分布适应时需要目标域样本的伪标签,因此类别子域鉴别器依赖每轮迭代时分类器的输出。采用文献[28]中的实现方式,本文将分类器输出的类别概率作为权重,在对抗学习时预先与输入特定类别子鉴别器的特征向量相乘,实现特定类别的条件分布动态对抗学习。图4 给出了局部鉴别器的网络结构。
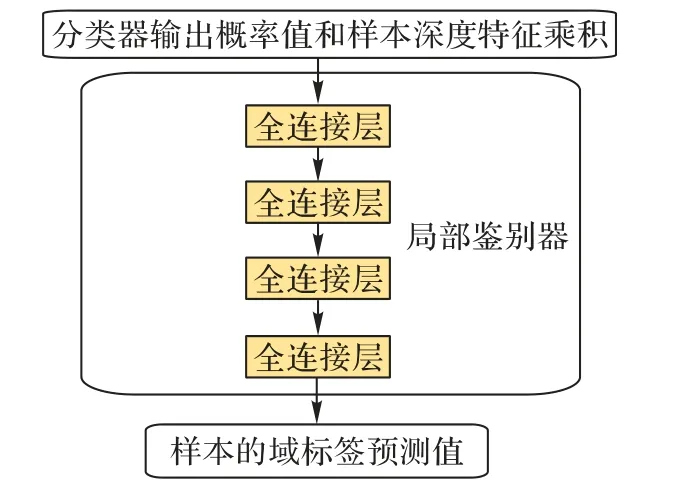
图4 DMDAN模型中子域鉴别器结构Fig.4 Architecture of sub-domain discriminators in DMDAN model
表2 给出了每个类别子域鉴别器的CNN 参数,具体由4个全连接层组成,分别为128、32、16 和1。其中,前3 层采用ReLU 激活函数,最后一层采用二分类sigmoid 激活函数。
1.4 动态多域对抗学习的损失函数
在DMDAN 模型训练中,源域Ds和目标域Dt使用共享权重的特征提取器和鉴别器。通过全局域鉴别器和类别子域鉴别器的结合,能够解决边缘分布相似的情况下,各个类别子域条件分布不一致的情形。同时,源域和目标域之间边缘分布与条件分布的重要性,则通过动态计算的对抗系数获得,实现自适应的动态多域对抗学习。具体地,DMDAN 模型对特征提取器和分类器,以及全局域鉴别器与类别子域鉴别器进行交叉训练。即首先固定特征提取器和分类器的参数,通过反向传播更新全局域鉴别器与类别子域鉴别器的参数;随后,再固定全局域鉴别器与类别子域鉴别器的参数,通过反向传播更新特征提取器和分类器的参数,如此交错训练,直到鉴别器无法鉴别提取到的特征来自源域Ds或目标域Dt,此时由分类器给出最佳的跨被试MI-EEG 解码结果。因此,DMDAN 模型包含如下4 个损失函数。
1.4.1 分类损失函数
分类器采用交叉熵作为损失函数,即:
其中:C表示MI 类别数表示属于类别c的概率,数值是分类器输出的概率;Gy表示分类器CNN 模型,Gf表示特征提取器CNN 模型。
1.4.2 全局域鉴别器损失函数
全局域鉴别器同样使用交叉熵作为损失函数,源域和目标域的域标签分别设置为0 和1,损失函数Lglobal为:
其中:Ld表示交叉熵,Ed表示全局鉴别器模型,Gf表示特征提取器CNN 模型,di表示对齐后的输入样本的域标签。
1.4.3 类别子域鉴别器损失函数
类别子域鉴别器数量与类别数C相同,每个子域鉴别器模型分别负责适应类别c的条件分布,同时依赖分类器迭代输出的类别概率,其损失函数为:
1.4.4 中心损失函数
为保证特征提取和域鉴别交叉训练过程中的稳定性,DMDAN 模型同样添加了DRDA 模型[25]给出的中心损失函数:
1.5 损失函数的权重计算
在动态多域学习过程,多个域鉴别器对于跨被试MI-EEG 解码贡献不同。为了动态适应不同域对抗学习,本文采用A-distance[28]衡量贡献度。每轮训练迭代完成后,通过各域损失函数估计边缘分布与条件分布的相对重要性。其中,全局域鉴别器与类别子域鉴别器的A-distance 分别为:
其中Lglobal代表全局鉴别器的损失。为C个类别构建的C个子域鉴别器,它们之间的A-distance 为:
DMDAN 模型训练起始阶段,动态对抗系数设置为:ωg=1.0;=0.0,c=1,2,…,C。
每轮迭代完成后,全局鉴别器的损失计算方法如下:
分类器将为目标域所有样本输出伪标签,通过输出的伪标签,可以计算类别c的子域鉴别器损失:
综上,在DMDAN 模型的训练中,应考虑上所有损失函数的加权结果,其学习目标为:
其中:θf为特征提取器的CNN 模型参数,θc为分类器的CNN模型参数,θg为全局域鉴别器的CNN 模型参数,为类别c子域鉴别器CNN 模型参数。动态对抗参数在每轮迭代完成后由式(9)和式(10)进行更新,分类损失、对抗损失和中心损失权重αcls、αadv、αct采用经验值。
2 实验与结果分析
2.1 数据集
为验证所提出DMDAN 模型的可行性与有效性,选择两个常用的公开数据集进行跨被试MI-EEG 解码实验。数据集具体信息[29]如下:
2.1.1 数据集2A
数据集2A 采集了9 个健康被试者的MI-EEG 信号,包含4 个类别的MI 任务,分别是左手、右手、双脚和舌头。实验刺激范式如图5(a)所示,实验由响铃刺激开始,[0,2] s 屏幕中心出现十字架集中被试者注意力,[2,3] s 出现4 个类别的MI 任务提示,被试者根据提示进行4 s 的MI 过程。本次MI结束后给予1.5 s 休息时间,随后进入下一次MI 任务。实验采集设备包含22 个EEG 电极,采样率设置为250 Hz,样本采集分为训练周期和测试周期,每个周期采集288 个MI-EEG样本,共计576 个样本,每个MI 类别包含144 个样本。MIEEG 解码实验选择[2,6] s 时间段内的EEG 时间点作为样本。

图5 数据集2A和数据集2B运动想象范式示意图Fig.5 Schematic diagrams of motor imagery on dataset 2A and 2B
2.1.2 数据集2B
数据集2B 同样采集了9 个健康被试者的MI-EEG 信号,包含2 个类别的MI 任务,分别是左手和右手。实验刺激范式如图5(b)所示,实验开始后,[0,3] s 屏幕中心出现十字架集中被试者注意力,响铃刺激出现在第2 s,[3,4] s 出现2 个类别的MI 任务提示,被试者根据提示进行4 s 的MI 过程。本次MI 结束后给予1.5 s 休息时间,随后进入下一次MI 任务。实验采集设备包含3 个EEG 电极,采样率设置为250 Hz,样本采集分为5 个周期,前两个周期每个包含120 个样本,后三个周期每个包含160 或120 个样本。MI-EEG 解码实验选择[3,7] s 时间段内的EEG 时间点作为样本。
2.2 实验设置
在采用所提出的DMDAN 模型进行跨被试MI-EEG 解码时,都采用留一被试交叉验证法(leave one subject crossvalidation)。针对数据集2A,一共有A01~A09 这9 个被试者,每次交叉验证选择1 个被试者样本集作为目标域,其中训练周期样本作为训练集,测试周期样本作为测试集,余下8 个被试者样本集作为源域。针对数据集2B,一共有B01~B09这9 个被试者,每次交叉验证选择1 个被试者样本集作为目标域,其中前三个周期样本作为训练集,后两个周期样本作为测试集,余下8 个被试者样本集作为源域。表3 给出了数据集2A 和2B 的样本设置情况。

表3 数据集2A和2B的样本设置情况Tab.3 Sample ettings of dataset 2A and 2B
在训练DMDAN 模型时,权重经验参数设置为:αcls=1.0,αadv=0.01,αct=0.05。CNN 模型采用Adam 优化器,初始学习率设置为l=0.000 2,每经过10 轮迭代,学习率衰减0.01%,每次训练的批处理大小(batch size)为64,训练迭代轮数为epoch=200。训练过程中采用early stopping策略,每训练20轮若损失未出现明显下降,则停止训练避免过拟合。
本文的实验由python 编程语言实现,采用的深度学习框架为Tensorflow1.14。实验使用的硬件为Intel Core 5-9300HCPU 和NVIDIA GeForce GTX1650 GPU。本文提出的DMDAN 模型在两个数据集上的运行时间如表4 所示。
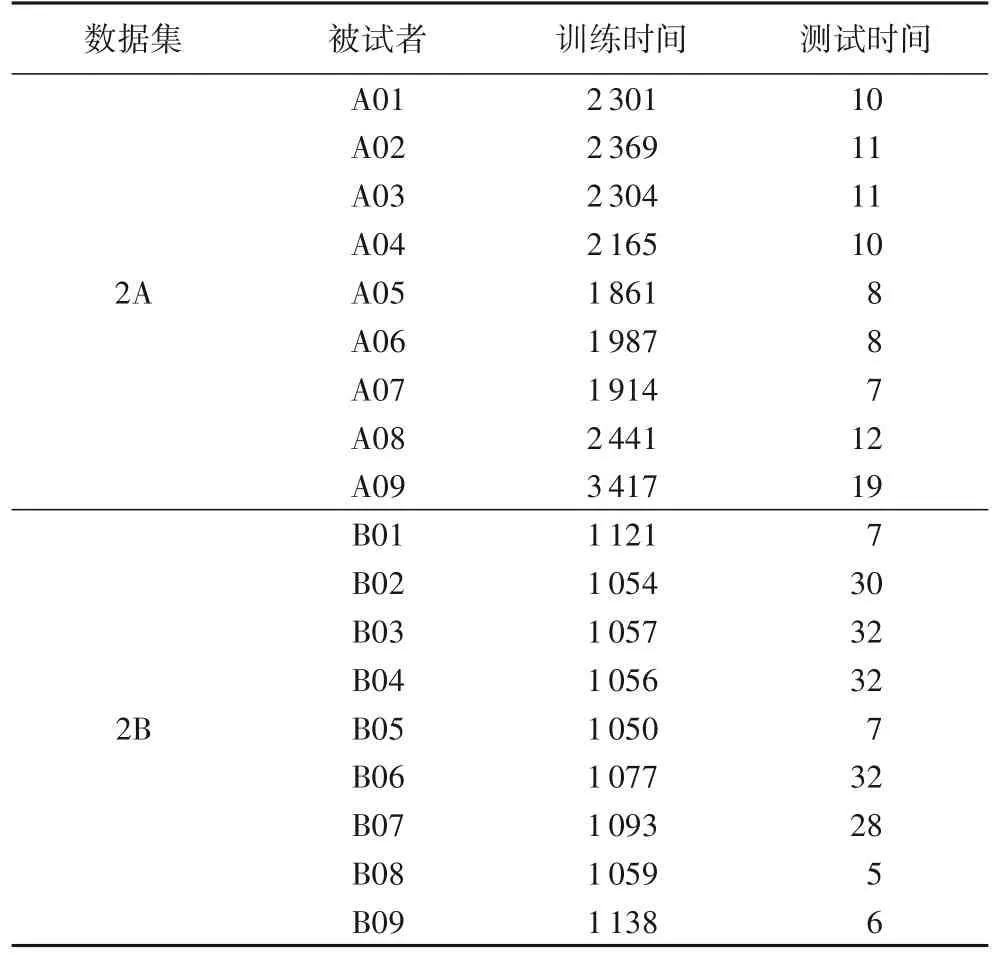
表4 DMDAN模型在数据集2A、2B上的运行时间 单位:sTab.4 Running time of DMDAN model on dataset 2A and 2B unit:s
2.3 基线方法
为了验证DMDAN 模型在跨被试MI-EEG 解码上的性能,在两个公开数据集上,分别选择两类基线方法进行对比:1)非深度学习方法:包括经典的FBCSP[8]、CCSP[7]和SSCSP[10]等跨被试迁移空域特征提取算法,以及直接采用EEG 矩阵计算的SMM[11]和SSMM[12]算法。2)深度学习方法:包括经典的ConvNet[13]、C2CM[14]和MI-CNN[15]等卷积神经网络模型,以及采用深度神经网络对抗学习的DRDA[25]和DJDAN[26]模型。最终,模型和方法对于跨被试MI-EEG 解码性能,采用留一被试交叉验证法的平均分类准确率衡量。
2.4 跨被试MI-EEG解码结果
表5 给出了DMDAN 模型与基线方法在数据集2A 上的对比结果,数据来自相应的参考文献。从表5 中结果可知,DMDAN 模型获得了更高的跨域MI-EEG 平均分类准确率,同时在不同被试者之间获得了更小的标准差。数据集2A 中的A02、A05 和A06 三个被试者的样本被认为是样本分布差异很大的代表,对于这3 个跨域分类难样本集,本文提出的DMDAN 模型能获得60.53%的平均跨域分类准确率。不同于基线方法仅对齐边缘分布或仅对齐条件分布,DMDAN 模型一方面通过EA 预处理和全局域对抗实现边缘分布适应,另一方面添加多个类别子域鉴别器实现条件分布适应,同时利用A-distance 动态计算多域对抗学习权重,尤其是子域内原本就难以区分类别的情况(A02/A05/A06),学习到了更具分辨性的特征,提升了识别准确率。相较于DRDA,DMDAN的平均分类准确率提高了1.80 个百分点。然而,DMDAN 模型在2A 数据集上的平均准确率低于DJDAN,原因在于DJDAN 使用梯度反转层(Gradient Reversal Layer,GRL)策略。该策略使域分类损失梯度传播在更新特征提取器前自动取反,加强了特征提取器、分类器和域鉴别器之间的对抗关系,使它在通道数更多、样本分布更复杂的2A 数据集上取得了更佳效果。相较于文献[16]在2A 数据集上左手、右手两个类别上取得最高的76.70%跨被试MI-EEG 解码性能,本文所提出的DMDAN 模型在2A 数据集上左手、右手、双脚和舌头四个类别上取得最高的76.50%跨被试MI-EEG 解码性能。DMDAN 模型在样本量更大、实验设置更复杂且类别数更多的实验中取得了与文献[16]几乎相同的准确率。实际上,DMDAN 模型的性能高于文献[16]的最佳性能。
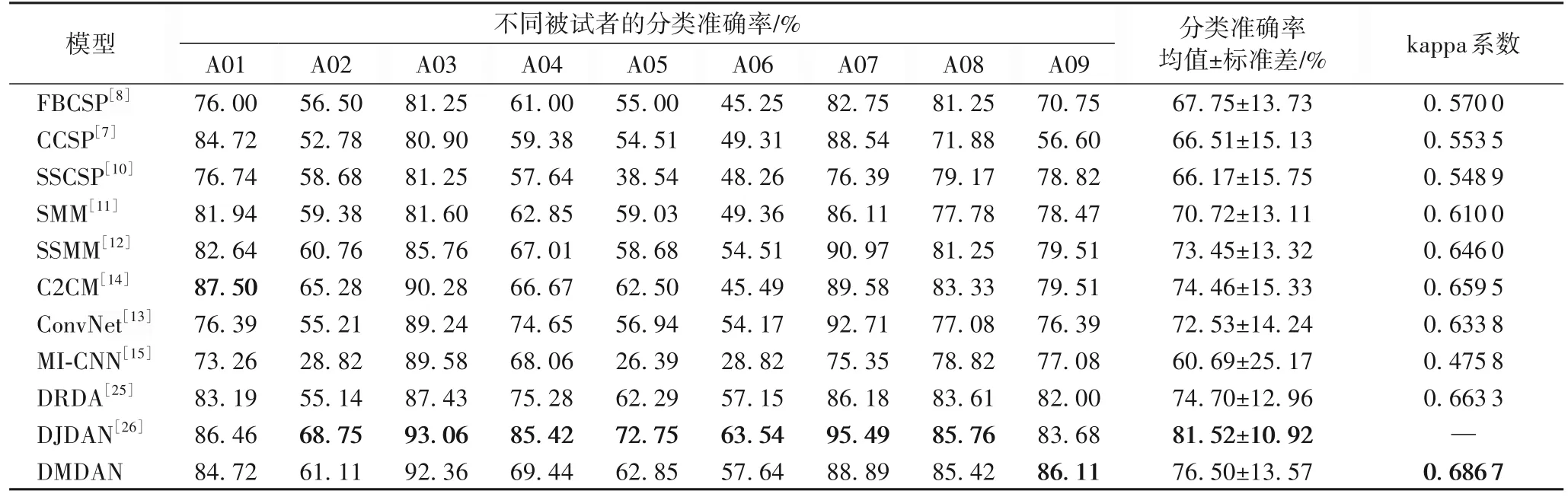
表5 DMDAN模型与基线模型在数据集2A上的平均分类准确率和kappa系数对比结果Tab.5 Comparison results of average classification accuracy and kappa coefficient between DMDAN model and baseline models on dataset 2A
为了展示DMDAN 模型在不同类别上的分类结果,图6给出了数据集2A 上9 个被试者的平均混淆矩阵。从图6 中的结果可以看出,DMDAN 模型在左手、右手、双脚和舌头四个类别上均取得了70%以上的识别准确率,不同运动想象类别之间提取到的特征差异较大。其中,双脚和舌头之间具有一定的概率出现混淆,左手和右手之间的混淆概率较低。
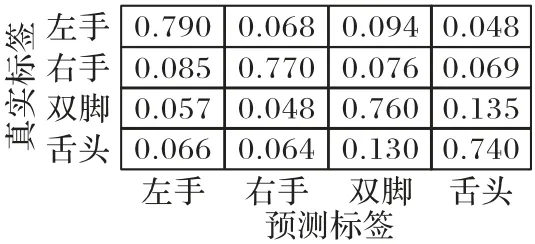
图6 数据集2A的平均混淆矩阵Fig.6 Average confusion matrix of DMDAN on dataset 2A
表6 给出了DMDAN 模型与基线方法在数据集2B 上的对比结果,数据来自相应的参考文献。从表6 中结果可知,DMDAN 模型获得了更高的跨域MI-EEG 平均分类准确率,相较于DRDA,提高了2.52 个百分点;同时在不同被试者之间获得了更小的标准差。对于分布差异较大的B02 和B03 被试者样本集,DMDAN 也取得了超过70%的识别准确率。相较于多域对抗学习的DJDAN[26]模型,DMDAN 模型设计了更为复杂的多域鉴别器,并通过动态对抗学习的方式适应不同域的深度特征图。同时,采用EA 预处理策略能够保证特征提取器获取的特征具有域不变性,从而加强了类别子域鉴别器区分特征来源能力。此外,与新近提出的DRDA[25]和DJDAN[26]模型相比,在B01、B04、B06 和B09 上的准确率有所下降,其原因可能是因为过多地引入类别子域鉴别器,对全局域鉴别器有一定的抑制作用。与此同时,采用EA 对齐样本预处理,也有一定风险降低样本的多样性。
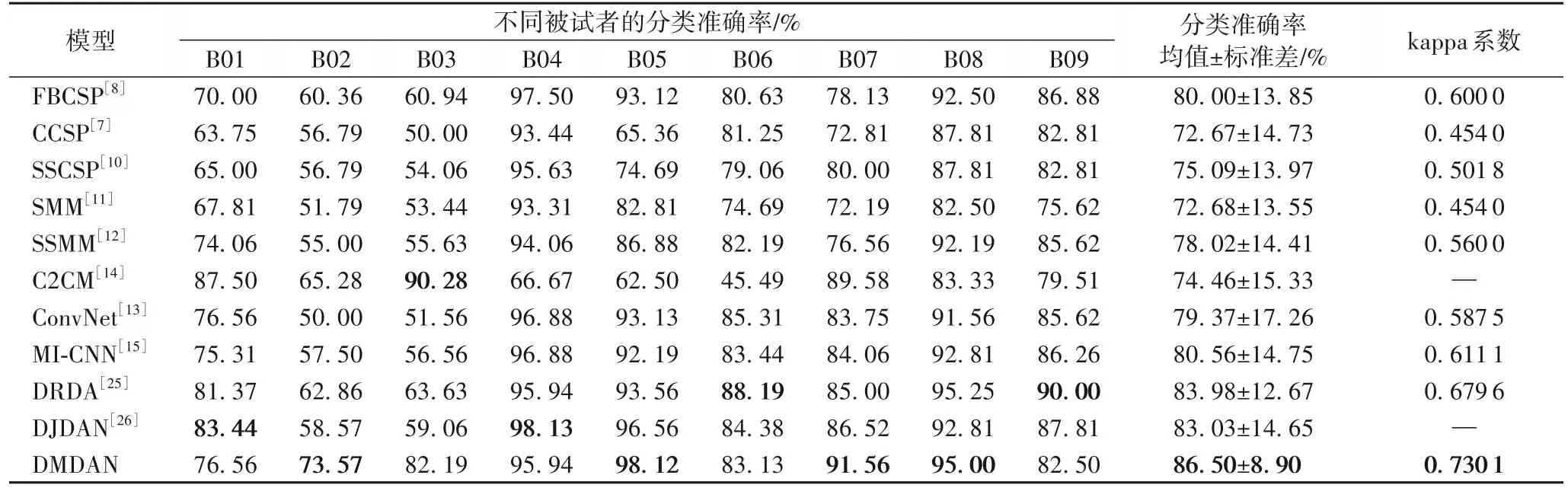
表6 DMDAN模型与基线模型在数据集2B上的平均分类准确率和kappa系数对比Tab.6 Comparison results of average classification accuracy and kappa coefficient between DMDAN model and baseline models on dataset 2B
2.5 消融实验
为了进一步验证所提出的DMDAN 模型的性能,本文从各模块影响因素、特征展示和收敛分析三个方面进行消融实验。
2.5.1 各模块影响因素
DMDAN 模型包含两个关键模块:EA 样本对齐预处理和动态多域对抗学习。为了进一步验证两个模块的有效性,设置了如下的4 个消融实验:单域对抗学习模型(实验1)、EA预处理后单域对抗学习模型(实验2)、动态多域对抗学习模型(实验3)、EA 预处理后动态多域对抗学习模型(即DMDAN 模型)。图7 给出了上述4 个任务分别在数据集2A和2B 各个被试者上的跨域MI-EEG 分类准确率,不同消融实验设置在两个数据集上的平均分类结果则统计了4 个消融实验设置在两个数据集上的平均准确率。
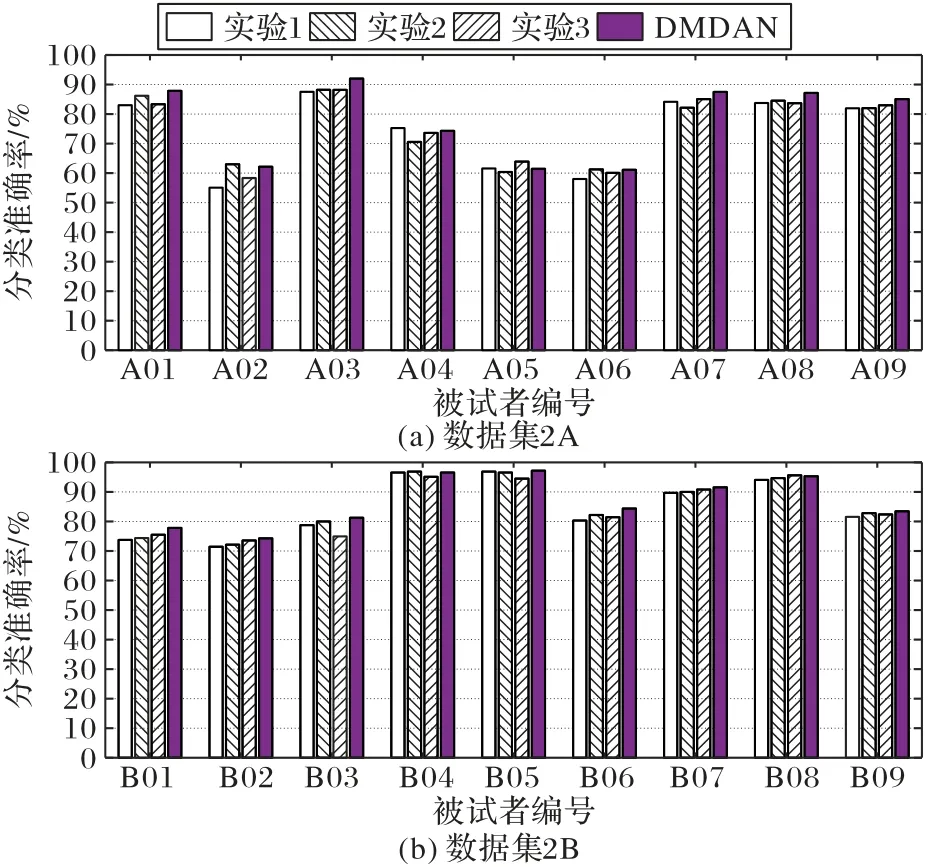
图7 不同消融实验设置在数据集2A、2B上各被试分类准确率Fig.7 Different subject classificaiton accuracies under different ablation experiment settings on dataset 2A and 2B
从图7(a)的结果可知,DMDAN 模型在A01、A03、A07、A08、A09 几个被试者上获得了最高的分类准确率,实验1 在A04,实验2 在A02、A06,以及实验3 在A05 上获得了最高的分类识别准确率。从图7(b)的结果可知,DMDAN 模型在B01、B02、B03、B05、B06、B07、B09 几个被试者上获得了最高的分类准确率,而实验2 在B04,实验3 在B08 上取得了最高的识别准确率。上述结果说明,将不同被试者样本集作为目标域,由于样本集的边缘分布和条件分布各不相同,因此不同消融实验设置在相应的目标域上取得了不同结果。形式上,EA 样本对齐预处理对边缘分布适应效果更好,而动态多域对抗学习模型则对条件分布适应效果更好。由于EEG 非线性、非平稳特性,实际需要适应的样本分布是未知的。因此,所提出的DMDAN 模型同时考虑适应边缘分布和,因此能够在数据集2A 和2B 所有被试者上,获得最佳的平均的跨域MI-EEG 分类准确率。
根据表7 中的结果显示,对比消融实验1、2、3,DMDAN模型在两个数据集上均取得了更高的平均分类准确率。对比实验1 与实验2,EA 样本对齐预处理方法的分类准确率在数据集2A 和2B 上分别提升了0.88 和0.75 个百分点;对比实验1 与实验3,动态多域对抗模型在数据集2A 和2B 上的准确率分别提升了1 和0.1 个百分点;对比实验3 与DMDAN模型,在动态多域对抗模型基础上,EA 样本对齐预处理在数据集2A 和2B 上的准确率分别提升了2.1 和2 个百分点。上述结果表明,本文所使用的EA 样本对齐预处理方法、动态多域对抗模型,均能够提升分类准确率,尤其将二者相结合,带来了更大幅度的跨域MI-EEG 分类准确率。

表7 不同消融实验设置在两个数据集上平均分类准确率 单位:%Tab.7 Average classification accuracy of different ablation experiment settings on two datasets unit:%
2.5.2 特征可视化
为了可视化DMDAN 模型提取到的特征,分别从数据集2A 和2B 选择A03 和B05 被试样本,展示模型学习到的不同类别特征。实验中,分别将A03 和B05 作为目标域,其他被试者作为源域,训练DMDAN 模型200 轮迭代后,获取特征提取器输出特征向量,并使用t-SNE[30]工具将特征降至二维展示。图8 分别给出了在A03 和B05 测试集上,提取到的最佳特征可视化结果。
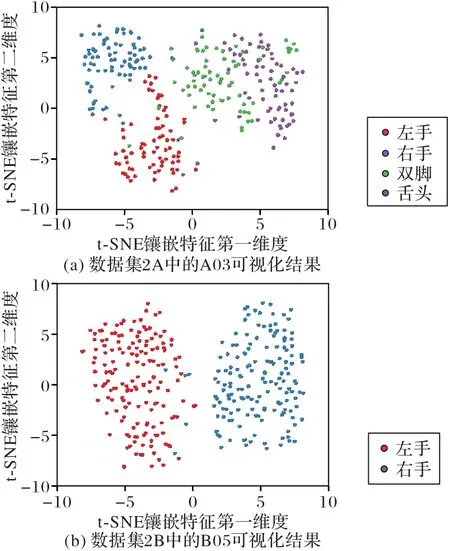
图8 不同数据集的被试者特征可视化Fig.8 Visualization of subject features on different datasets
从图8 中可以看出,无论是A03 还是B05 的EEG 样本集,经过200 轮迭代训练后,DMDAN 模型中训练好的特征提取器,均可获取到具有较强分辨性的特征,不同类别的样本之间存在明显的分界线,因此具有更高的跨被试识别准确率。其中,图8(a)的双脚(绿色)与舌头(紫色)类别之间仍然有一些样本不可分。实际上,数据集2A 的双脚与舌头两个类别是MI-EEG 模式识别中的困难问题,有待进一步研究更强的特征提取器,以期在难分辨的MI 类别上,获得更高的跨被试识别准确率。
2.5.3 收敛分析
应用所提出的DMDAN 模型,在数据集2A 和2B 各9 个被试者样本集上,经过有限轮次迭代均能够收敛到最佳的跨被试MI-EEG 识别结果。以数据集2A 和2B 中A03 和B05 样本集为对象,图9 分别给出了DMDAN 模型的分类器损失以及各个鉴别器损失收敛情况。由图9 总体结果可以看出,DMDAN 模型经过100 轮迭代后,分类器损失和各个鉴别器损失均下降至较低水平,在随后的迭代轮次中基本保持平稳。对于图9(a)的收敛过程,在100 次迭代后鉴别器总损失出现过拟合现象,由图中可以看出过拟合是由各个类别子域鉴别器形成的。实际上,DMDAN 模型采用了early stopping策略,在损失上升超过一定比例后即停止训练,获得最佳的结果。反观图9(b)的收敛过程,则没有出现过拟合现象,无论是分类器损失还是各个鉴别器损失,在200 轮迭代后均下降至最低水平。
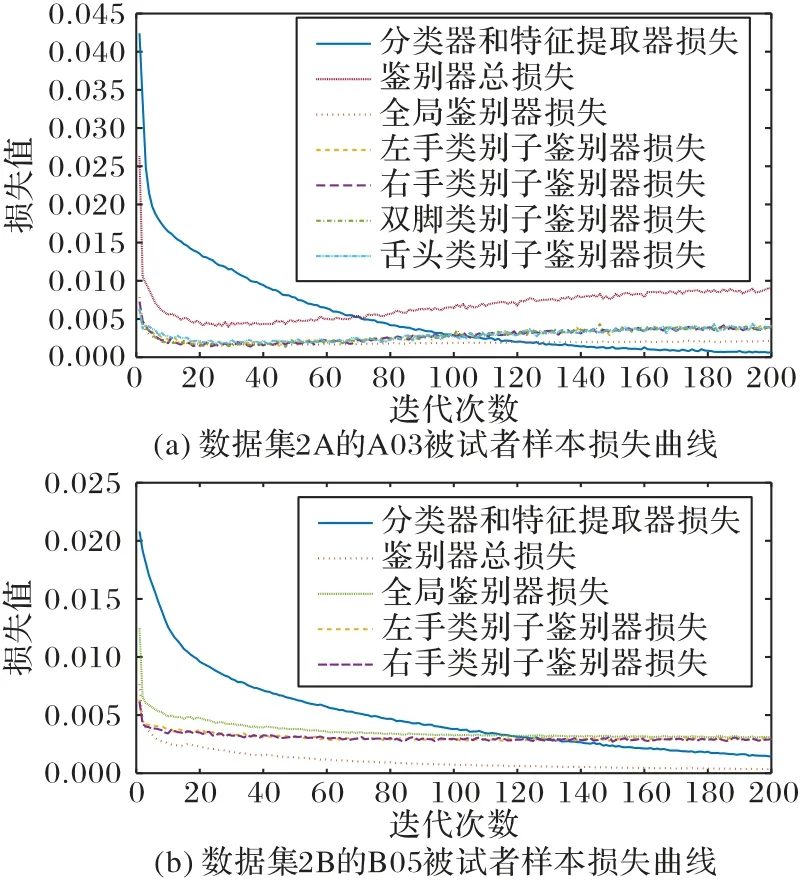
图9 DMDAN模型训练多个鉴别器误差收敛情况Fig.9 Error convergence situations of multiple discriminators trained by DMDAN model
3 结语
在跨被试MI-EEG 信号解码领域,EEG 信号时变强、多耦合的特性极易被忽视,仅依靠边缘分布适应或条件分布适应,容易导致分类性能瓶颈。本文提出了一种动态对抗学习方法,分别使用样本对齐预处理和全局域鉴别器适应样本边缘分布,以及类别子域鉴别器适应样本条件分布,并自适应学习多鉴别器对抗系数,自适应调整不同鉴别器的贡献,克服了经典对抗学习方法在样本分布适应上的缺点。在两个代表性的公开MI 数据集上进行跨被试EEG 解码实验验证,结果表明所提出的DMDAN 模型是可行的,与经典对抗学习方法相比,在两个数据集上分别获得76.50%和86.50%的平均分类准确率。后续将展开两个方面的研究工作:一是探究多个类别子域鉴别器在迭代中容易产生的过拟合问题,以及评价EEG 样本分布适合何种类型的分布适应方法,在实际在线MI-BCI 应用中保障跨域解码性能;二是将新方法推广到其他EEG 类型跨被试识别应用中。当前,EEG 信号分析的瓶颈在于时变性和低信噪比,如何提取被试域间可泛化的特征,是未来工作重点。
猜你喜欢
通信学报(2022年10期)2023-01-09
电子学报(2022年2期)2022-04-18
煤炭工程(2021年7期)2021-07-27
共产党员(辽宁)(2019年7期)2019-11-18
国防科技大学学报(2019年4期)2019-07-29
共产党员·上(2019年4期)2019-04-26
物理学报(2018年10期)2018-06-14
环球时报(2017-08-18)2017-08-18
系统工程与电子技术(2016年5期)2016-11-02
奥秘(2016年3期)2016-03-23
