
基于MAPFormer 的人体动作识别研究
2024-01-26 01:06陆静芳
内蒙古师范大学学报(自然科学汉文版) 2024年1期
陆静芳,智 敏
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
自Vision Transformer(ViT)[1]适应图像分类任务以来,以其为基础的后续改进,在各种计算机视觉任务中实现了更高的性能[2-4]。ViT(图1)的成功归因于基于注意力这一思想。但是多头注意力模块过高的参数量以及计算复杂度不容忽视。因此,后续开发了许多注意力模块变体[5-8]以改进ViT。然而,文献[9]将注意力模块完全替换为空间MLP,并发现导出的类似MLP 模型可以很容易地在图像分类任务上获得良好性能。文献[10-12]通过提高数据训练速度和特定MLP 模块设计进一步对MLP 类模型进行改进,逐渐缩小与ViT 的性能差距,为替代ViT 模型中的注意力模块提供数据支持。
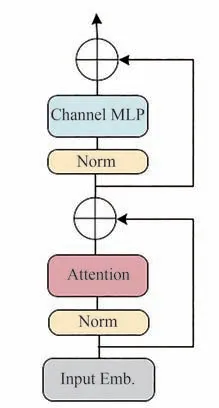
图1 ViT 结构图Fig.1 The structure diagram of ViT
为了降低ViT 的参数量以及计算复杂度,本文对ViT 进行两步改进,并将其应用到人体动作识别任务。首先,仅使用简单的并行池化层替代ViT 的注意力模块,模型仍然可以实现极具竞争力的性能;其次,将网络中patch embedding 模块的常规卷积替换为深度可分离卷积,继而构建MAPFormer,并将其引入人体动作识别研究领域,提高人体动作识别任务的准确性;最后,提出MAPFormer在Miniimagnet 和MS COCO 数据集进行实验,相比ViT 实验精度分别提高4.3% 和2.1%,参数量减少65.2 M 和58.3 M,以此验证了MAPFormer 与人体动作识别任务结合的可行性。
1 相关工作
受Transformer[13]在NLP 中的成功启发,许多研究人员将注意力机制和Transformer 应用于视觉任务[14-17]。文献[18]提出将Transformer 训练为自动回归预测图像上的像素以进行自监督学习。文献[1]提出将patch 嵌入作为ViT的输入,通过实验结果表明,在有监督的图像分类任务中,由3 亿张图像的大型专有数据集上预训练的ViT 可以获得优异的性能。DeiT[3]和T2T ViT[4]进一步证明,约130 万张图像的ImageNet-1K 数据集上,从头开始预训练的ViT 也可以实现很好的效果。
本文将注意力模块抽象为token 混合器,如图2 所示。输入I首先通过输入嵌入来处理,如式(1)
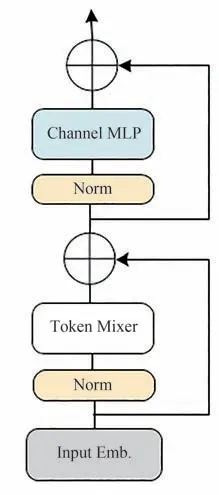
图2 ViT(token 混合器)结构图Fig.2 The structure diagram of ViT(token mixer)
其中,X∈RN×C表示具有序列长度为N和维度为C的嵌入token。然后,token序列被输入到重复的Transformer 块,每个块包括两个残差连接。其中,第一部分主要包含token 混合器以在token 之间传递信息,并且该子块可以表示为
其中,Norm(·) 表示归一化,归一化有多种形式,例如层归一化[19]或批量归一化[20],TokenMixer(·) 表示主要用于混合token 信息的模块,由最近ViT 模型[1,4,8]中的各种注意力机制或类似MLP 模型中的空间MLP[9,12]来实现。尽管一些token 混合器用注意力来混合通道信息,但是token 混合器的主要功能是传递token 信息。第二部分主要由具有非线性激活的双层MLP 组成,用来维度变换,如式(3)
其中,W1∈RC×rC和W2∈RrC×C具有MLP 扩展比为r的可学习参数,σ(·)是一个非线性激活函数,可以为GELU[21]或ReLU[22]。
为了降低ViT 中多头注意力模块的计算量,同时提高模型性能,目前很多方法都集中在通过移动窗口[2]、相对位置编码[23]、细化注意力图[8]或合并卷积[24-26]等对token 混合器进行改进。文献[2]提出移位窗口方案,通过自注意计算限制在非重叠的局部窗口,同时允许跨窗口交互,从而以更少的计算复杂度实现更高的精度。文献[22]提出分段函数将相对位置映射到编码,相对位置编码对输入token 之间的相对距离进行编码,并通过具有与自注意力模块中的query 和key 交互的可学习参数的查询表来学习token 之间的成对关系。该方案允许模块捕获token 之间长距离依赖关系,将计算成本从原始O(n2d)降低到O(nkd)。文献[8]提出Refiner 方案对自注意力的扩展进行了探索,将多头注意力图映射到一个更高的维度空间,以促进其多样性,同时应用卷积来增强注意力图的局部特征,相当于在局部用可学习的内核聚合分布式的局部注意力特征,再用自注意力进行全局聚合,使改进后的ViT 在ImageNet 数据集上仅用81 M的参数达到86% 的分类精度。为平衡ViT 和现有的卷积神经网络在性能和计算成本上的差距,文献[24]提出一种新的基于ViT 的混合网络,利用ViT 来捕获远程依赖关系,利用卷积神经网络对局部特征进行建模,并对该网络进行缩放获得CMT 模型,与以前的基于卷积和ViT 的模型相比,获得更好的准确性和效率。文献[25]与上述方法不同,而是在网络中每个阶段的开始位置引入一个卷积token 编码,通过重叠的卷积操作在图片上进行卷积,即将token 序列变回原来的图片,该操作可以捕捉局部信息并且减少序列的长度,增加token 的维度,同时用卷积投影层替换之间的线性投影层,减少计算复杂度。
最近一些方法[27-30]探索ViT 体系结构中其他类型的token 混合器,并展示出很好的性能。其中,文献[27]用傅里叶变换代替注意力,实验结果仍然达到97% 的精度。文献[28]引入连续域注意力机制,推导了相关的有效梯度反向传播算法。为让模型具备更长的长期依赖关系,文献[29]以文献[28]的方法为基础,扩展了具有无界长期记忆的ViT,通过利用连续空间注意力机制来捕获长期依赖关系,提出∞-former 模型中的注意力复杂度与上下文长度无关,更精确选择模型的记忆长度。为掌握影响精度最重要的部分,∞-former保持了“黏性记忆”,能够对任意长的上下文进行建模,同时保持较少的计算开销。文献[30]指出在傅里叶变换中,计算变换后某一位置的信息时可能会计算变换前多个位置的信息,有综合考虑整个图像的趋势,这一点与ViT 侧重于关注图像的全局性类似,于是提出在傅里叶变换之后的图像上用可学习的全局滤波器进行处理,更好地处理图像信息。文献[31]提出Poolformer 模型,简单利用池化层作为基本token 混合器来降低ViT 的参数量。
除了以上对token 混合器的改进外,文献[9]和文献[12]发现仅采用MLP 作为token 混合器仍然可以获得相当好的效果。此外,还有一些方法通过改变ViT 的其他架构来探索各个分支的作用以及证明模型的可变性。文献[32]证明在没有残差连接或MLP 的情况下,输出以双指数收敛到一阶矩阵。文献[33]比较了ViT 和之间的特征差异,发现注意力允许早期收集全局信息,而残差连接将特征从较低层传播到较高层,并通过改变损失函数来提高模型的准确性和泛化能力。
2 本文方法
本文整体网络框架如图3 所示,其基本思想将ViT 模型的多头注意力模块用MAPFormer 模块替换,将patch embedding 模块中的常规卷积替换为深度可分离卷积。整个网络结构包含4 个阶段,每个阶段由改进的patch embedding 模块和MAPFormer 组成,在4 个阶段分别得到不同分辨率的特征图,以获得不同尺度的特征。整个网络总共有12 个MAPFormer 块,4 个阶段将分别包含2、2、6、2 个MAPFormer 块。在MAPFormer 块内部,引入最大池化层与平均池化层并行处理数据,同时在2、3、4 阶段使用改进的patch embedding 模块。
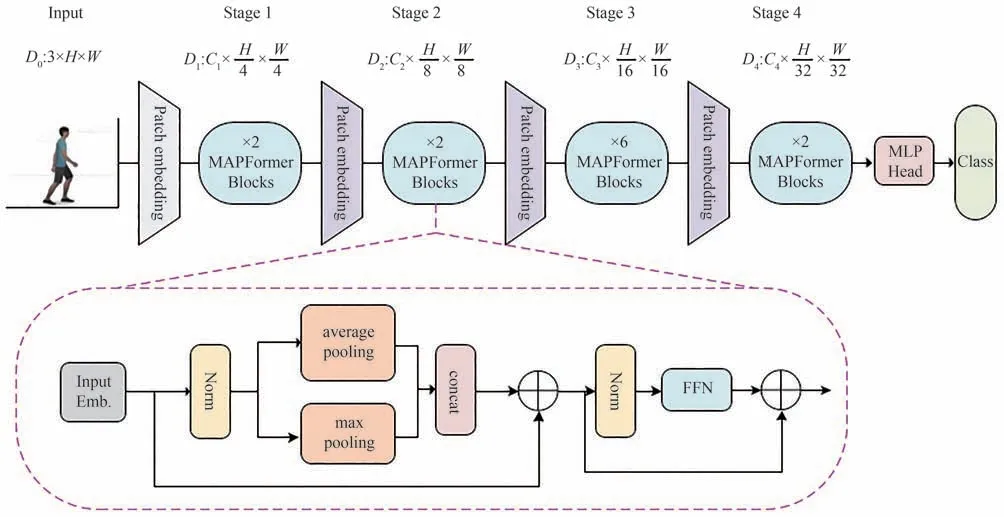
图3 整体框架图Fig.3 The diagram of overall framework
对于输入的图像,其中H和W表示输入图像的宽度和高度。首先输入图像进入patch embedding 进行卷积操作,之后转换成序列进入MAPFormer,经过并行池化层进行特征提取,平均池化用于提取全局上下文信息,最大池化用来提取局部信息,将得到的特征进行融合,以此对输入图像进行特征提取。最后与原始输入相加,进行特征增强,得到的特征输入到下一个残差块进行维度转换,输出到下一阶段,经过四个阶段处理后,通过MLP Head 获得最终的分类结果。
2.1 并行池化层
自Transformer[13]问世以来,注意力成为研究者关注的重点,并专注于设计各种基于注意力的token 混合器机制。众所周知,注意力机制和空间MLP 通常只能处理数百个token,但是注意力机制和空间MLP的计算复杂性与要混合的token 数量成二次计算复杂度。此外,空间MLP 在处理较长序列时会带来更多的参数。相比之下,池化与序列长度成线性计算复杂度,而不需要任何可学习参数。本文使用并行的两个池化层作为token 混合器代替注意力模块,在此过程中没有可学习参数,仅是使每个token 平均以及最大程度地聚合其附近的token 特征,消除多头注意力带来的大量参数以及过高的计算复杂度。并行池化层由平均池化层和最大池化层组成,下面将对这两个池化层进行介绍。
2.1.1 平均池化 平均池化可以保留背景信息,进行平均池化时,池化窗口类似于卷积的窗口滑动方式在特征图上进行滑动,取窗口内的平均值作为结果,其过程为
其中,ykij表示第k个特征图有关矩形区域Rij的平均池化层的输出值,xkpq表示第k个特征图有关矩形区域Rij中位于位置(p,q)的元素值。平均池化对特征图进行采样的同时防止模型过拟合。平均池化的反向传播过程是把某个元素的梯度等分为n份分配给前一层,以保证池化前后的梯度之和保持不变,其过程为
其中,gkpq表示第k个特征图位于位置(p,q) 经过反向传播后的输出值,xkpq表示第k个特征图位于位置(p,q)的元素值,n为xkpq表示在区域的元素个数。即假设进行平均池化反向传播的元素值为2,经过反向传播后的结果为[0.5 0.5;0.5 0.5]。
当需要综合特征图上的所有信息做相应决策时,通常会用平均池化。执行人体动作识别任务时,首先要对图像数据进行特征提取,从单一像素的角度观察很难分辨图像中的人体动作,此时需要考虑全局信息的影响,全局信息不但可以提供周围的环境因素,还可以更好地协助描述局部语义信息。因此,本文选用平均池化提取全局信息,从而帮助分类器进行分类。
2.1.2 最大池化 最大池化用来提取局部纹理特征,减少无用信息的影响。最大池化通过前向传播将patch 中最大的像素值传递给后一层,而其他的像素值直接被舍弃掉,其过程为
其中,fkij表示第k个特征图有关矩形区域Rij的最大池化层的输出值,xkpq表示第k个特征图矩形区域中位于位置(p,q)的元素值。
最大池化的反向传播直接将梯度传给前一层某一个像素,而其他像素不接受梯度,其值保持为0。假设进行最大池化反向传播的元素值为3,经过反向传播后的结果为[0 3;0 0]。
最大池化和平均池化的不同点在于反向传播时是否需要记录下原始像素值的位置,平均池化关注全局信息,最大池化重视局部信息。由于人体关键节点的变化对人体动作识别任务会产生很大的影响,还会影响最后的识别结果,而仅使用平均池化并不能对局部特征加以描述。因此,本文使用最大池化对人体行为进行局部特征提取,提高模型的识别精度。鉴于平均池化与最大池化的特性,利用平均池化来获取全局信息,利用最大池化来获取局部信息,将二者得到的信息进行融合,以此提取输入图像中所包含的人体行为较为全面的特征。
2.2 DsConvPE(深度可分离卷积patch embedding)
人体动作识别任务中的图像数据与ViT 的输入要求不匹配,因此需要通过patch embedding 模块对图像数据的三维矩阵进行数据变换。该模块通过卷积操作将图像划分为一系列的patch,再将patch 转换成一维向量送入ViT 进行处理。整个流程包含多个patch embedding 模块,卷积层参数不断累积,降低了识别效率。鉴于此,本文提出在2、3、4 阶段的该模块中使用深度可分离卷积替换常规卷积,降低参数量,提高识别效率。
深度可分离卷积网络包含两部分,分别为深度卷积和逐点卷积,主要用来降低卷积运算参数量。深度卷积在二维平面内进行,是指每个卷积核对应输入图像的每一个通道;逐点卷积将深度卷积得到的各自独立的特征图进行组合生成新的特征图。深度卷积将不同的卷积核独立应用在输入图像的每个通道,在卷积过程中,一个卷积核负责一个通道。深度卷积完成后得到的特征图数量与输入层的通道数相同,无法扩展特征图。而且该运算对输入层的每个通道独立进行卷积,每个层的特征都被分开,没有有效利用不同通道在相同空间位置上的特征信息。因此需要逐点卷积将这些各自独立的特征图进行组合生成新的特征图。逐点卷积运算与常规卷积运算相似,卷积核尺寸为1×1×M,M为上一层的通道数,同时将深度卷积得到的特征图在深度方向上进行加权组合生成新特征图,新特征图的数量与卷积核个数相同。
例如,对于一张5×5 像素、3 通道彩色输入图片(shape 为5×5×3)进行深度可分离卷积,首先经过深度卷积运算,卷积核的数量与通道数相同(通道和卷积核一一对应)。所以一个3 通道的图像经过运算后生成3 个特征图,如果每个卷积核的填充步长相同,则得到的特征图尺寸与输入层相同,均为5×5,如图4 所示。其中Filter包含一个大小为3×3 的卷积核,卷积部分的参数个数计算为:N_depthwise=3×3×3=27。
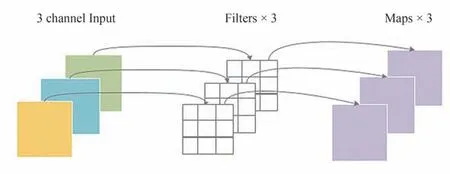
图4 深度卷积Fig.4 Deep convolution
逐点卷积过程如图5 所示。由于逐点卷积采用的是1×1 的卷积方式,经过逐点卷积之后,输出4 张特征图,与常规卷积的输出维度相同。此过程中卷积涉及参数个数可以计算为:N_pointwise=1×1×3×4=12;因此,深度可分离卷积的参数由两部分相加得到N_separable=N_depthwise+N_pointwise=39,而常规卷积的参数个数为:N=4×3×3×3=108。经过计算可以观察到相同的输入,同样是得到4 张特征图,深度可分离卷积的参数个数约是常规卷积的1/3。因此,在参数量相同的前提下,采用深度可分离卷积的神经网络层数可以做的更深。在卷积层数相同的前提下,深度可分离卷积相比常规卷积具备更少的参数。鉴于此,在patch embedding模块中使用深度可分离卷积替换常规卷积,以降低整体模型的参数量。
3 实验
实验环境提出算法使用的硬件为NVIDIA Tesla 4 GPU,Pytorch 作为基础,保证实验运行。实验数据选用三个人体动作识别数据集:Miniimagenet 数据集和MS COCO 数据集。Miniimagenet 是从ImageNet 分出来的数据集,包括100 类不同的动作类别,每一类至少包含600 张图片,具有丰富的类别和多样化的图像内容。MS COCO 数据集是人体动作识别领域常用的数据集之一,包含约40 000 张图片数据。该数据集具有规模大、多样化、背景复杂、遮挡问题等特点,图像来源真实场景,覆盖了广泛的环境、场景和情境,并涵盖不同尺度和角度。其中,一些图像中的目标可能非常小,而其他图像中的目标可能占据整个图像。此外,该数据集还包含多种场景和动作,例如人在室内或室外运动等,选用该数据集可评估模型对不同场景和动作的泛化能力。
本文采用四个阶段的嵌入尺寸为64、128、320、512 的模型,MLP 膨胀比设置为4(表1)。第一阶段patch embedding 的大小步长为4,卷积核大小为7×7 的常规卷积,其余三个阶段步长为2,卷积核大小为3×3 的深度可分离卷积,以此对上一阶段得到的特征图进行特征提取,同时降低参数量。平均池化与最大池化均采用步长为1,池化窗口大小为3×3 的池化层,提取全局上下文信息以及局部特征。
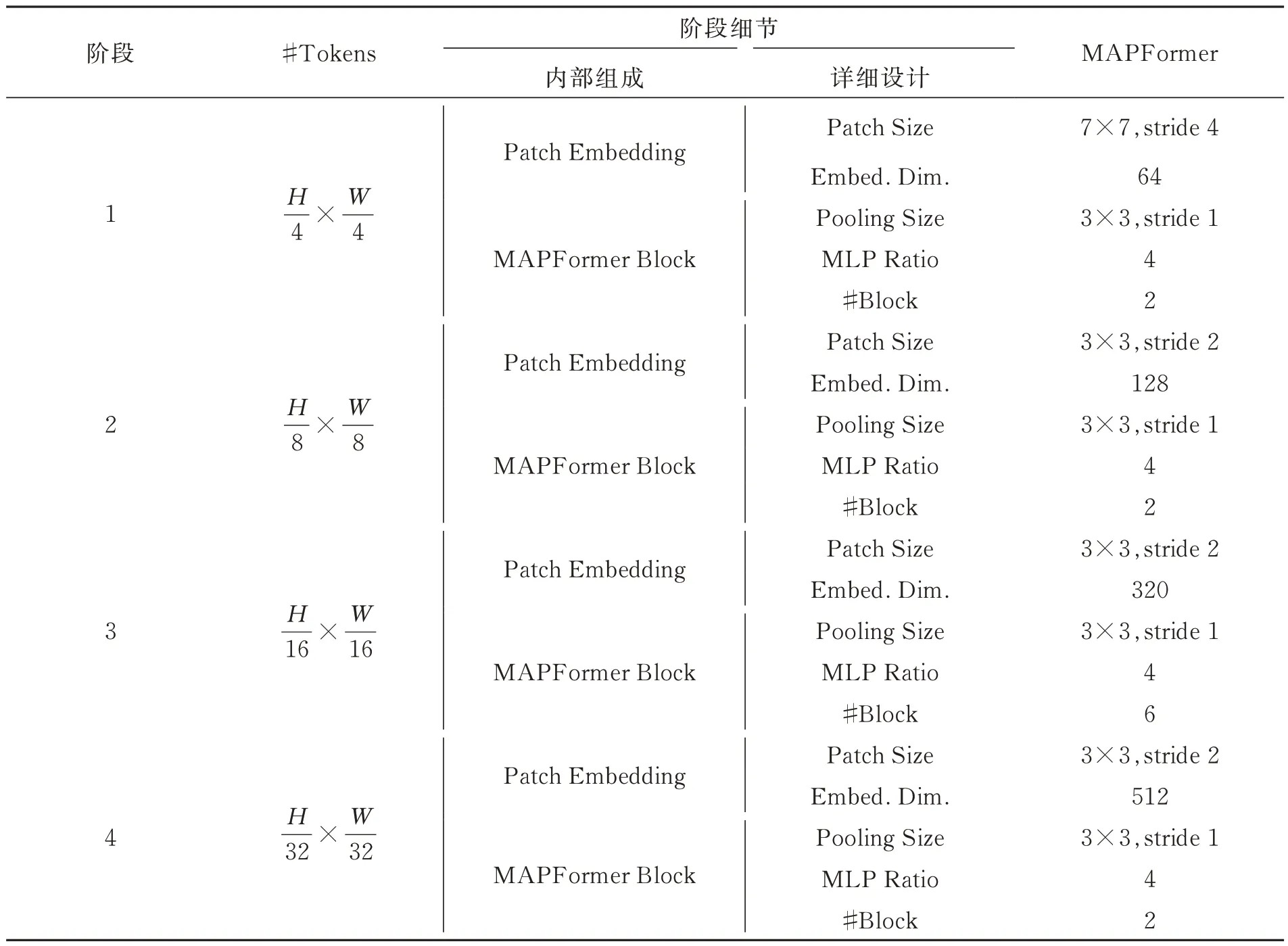
表1 MAPFormer 实验参数Tab.1 The experimental parameters of MAPFormer
3.1 实验结果
本文将MAPFormer 与ViT、典型模型Swin Transformer、人体动作识别任务中较为先进的模型TSNTransformer[34]以及池化模型PoolFormer 进行比较。由表2 所示,ViT 模型具有对全局上下文信息建模的优势,但是由于多头注意力过高的参数量,使其在实际应用中受到限制;Swin Transformer 对多头注意力进行改进,提高了识别精度,但由于注意力模块自身的复杂性,参数量和计算复杂度并没有下降到理想状态;PoolFormer 通过将注意力机制替换为无参数量的平均池化层,大大降低模型的参数量,提高模型的实验精度,由此也验证了在一定程度上注意力机制不是影响ViT 性能的主要因素。TSN-Transformer 通过有效地捕捉视频中的时空关系,使用自注意力机制在时间和空间维度上对特征进行建模,而自注意力机制更适合捕捉长期时序依赖和全局上下文,因此其对局部特征的表达能力较弱。MAPFormer 通过引入并行的最大池化与平均池化以及将常规卷积替换为深度可分离卷积,使模型参数在两个数据集上相比ViT 均降低60 M左右,实验精度分别提高4.3% 和2.1%,因此验证了ViT 模型基础上改进部分的有效性。
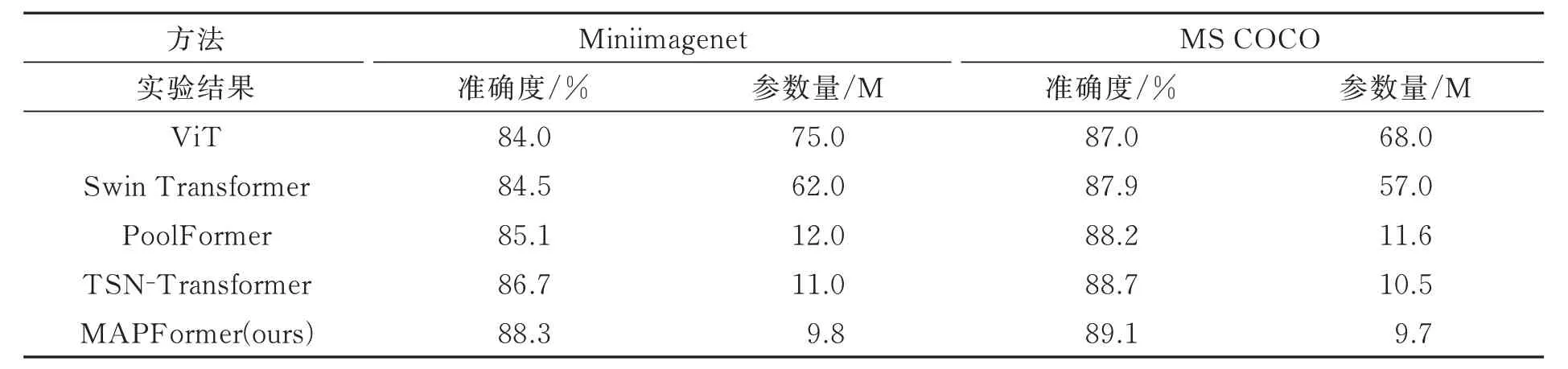
表2 方法对比Tab.2 The comparison of different method
3.2 消融实验
在Miniimagenet 数据集上加入不同模块融合的实验结果见表3。其中ViT-a代表去除ViT 中的多头注意力模块剩余的基本架构。首先,ViT 的实验结果,但是参数量较大;其次,将单一的平均池化、最大池化、串行的平均池化与最大池化、并行的平均池化与最大池化填入其基本架构中,实验结果表明并行的效果最好;最后,将改进后的ViT 与深度可分离卷积进行消融实验,准确度的提升和参数量的下降有效证明了对patch embedding 改进的有效性。因此,将池化层与深度可分离卷积引入ViT 架构中,与人体动作识别任务相结合可以显著提高动作识别的准确度,充分证明MAPFormer 的优越性。

表3 消融实验Tab.3 The ablation experiment
4 结论
本文通过MAPFormer 模型对图像数据进行人体动作识别,利用并行的平均池化和最大池化提取全局上下文信息和局部信息,引入深度可分离卷积提取局部特征并降低参数量。该算法在两个常用的数据集上取得较好的实验结果,证明改进ViT 与人体动作识别任务相结合的可行性,提高了人体动作识别精度。同时,经过消融实验对比发现,识别精度随着模块的增加而提升。但是,本文仅在ViT 内部的token 混合器进行改进,忽略了对输入端改进的可能性。由于ViT 对全局信息建模能力较强,对局部关系建模能力不足。因此,可以在输入端添加对重点区域进行局部标记的模块,然后通过卷积层对已标记的重点区域进行特征提取,再送入ViT 中以减少冗余信息的影响,从而提高实验精度。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
舰船科学技术(2022年21期)2022-12-12
软件导刊(2022年3期)2022-03-25
科技创新与应用(2021年23期)2021-08-30
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
计算机技术与发展(2019年1期)2019-01-21
雷达科学与技术(2018年3期)2018-07-18
中国塑料(2016年7期)2016-04-16
