
基于标签的Folksonomy机制研究——以CiteUlike为例
2010-07-12 08:08刘向红
图书馆理论与实践 2010年5期
●刘向红,宋 文,姚 朋
(1.承德石油高等专科学校 信息中心,河北 承德 067000;2.中国科学院 文献情报中心,北京 100080)
1 引言
Folksonomy是近年来流行于网络的一种用户参与、主导的资源自组织方式,是web2.0时代的一个重要技术辅助手段。现在,很多应用Folksonomy的网站成为web2.0的明星网站,如国外的del.icio.us、Flickr、43-Things、CiteUlike、Connotea等,国内的豆瓣网、天天网摘等。这些网站允许用户根据自己的需要自由选择自然语言,即使用Tag(标签)存储和管理自己的信息资源,并提供分享和交流的平台。Tag之间是平等的关系,不必考虑等级结构,每个Tag相当于用户对资源的一个分类。信息专家ThomasVanderWal将这种信息分类方式命名为“Folksonomy”。国内对Folksonomy的译法很多,如大众分类法,自由分类法,大众标注,分众分类法等,本文采用“自由分类法”的名称。
Folksonomy这种组织形式的特点是自由、共享和动态更新,能够迎合用户的需求,体现用户价值,促进集体交流,是一种基于用户合作的分类方式。本文以国外著名的学术网摘CiteUlike为例,对社会化标签系统中的Folksonomy机制进行分析研究。
CiteULike与del.icio.us很类似,同样是一款免费的社会化书签网络工具,是专门为学术研究人员提供组织学术文章的网站。它可以帮助学术工作者分享、储存和组织他们正在浏览的文献形成个人资料库。支持Tags、RSS订阅、设定优先权、内容输出到BibTeX、EndNote文献管理系统和由BibTeX输入内容,并支持按Tags和作者查询以及提供用户组等服务。[1]
Citeulike使用简单,注册后无需安装插件,如果是PubMed、SD等学术数据库中的文章,收藏时点几下鼠标就可自动添加作者、期刊名、文章卷期、页码、出版商、摘要等信息,形成标准的引文格式。而且所有的这些工作均在浏览器中完成,不需要安装什么特别的插件。[2]
2 数据集
本文的研究目的是通过数据收集和图表分析,分析用户与所标注资源的关系、用户与所使用标签的关系、用户使用标签的时间变化规律以及标签的共现关系和聚类特性,旨在探讨社会化书签系统中用户的标注行为特征,验证标签的资源组织能力。
笔者通过GoogleReader,使用CiteUlike[3]提供的RSSFeed服务,抓取了CiteUlike网站2008年12月21日至2009年6月30日时间段以Folksonomy作为标签检索的数据233条,去重后获取183篇文献,得到一组资源概况数据集,其中每条数据都包括文献题名、作者、发表时间、文献出处、用户名以及标注人数。统计工作围绕这个数据集展开。
通过统计,可以看到,被标引最多的资源是Scott Golder和 Bernardo A.Huberman 2005年发表的 《The StructureofCollaborativeTaggingSystems》,有 246个个人用户、62个群用户都标引了该资源。被标注次数较多的资源和作者,说明其被关注程度较高,在某种程度上可视为有关Folksonomy研究的核心资源和核心作者。
另外,笔者所获取的83%的资源出版年限集中在2005年—2009年,2007年和2008年尤为集中,这与Folksonomy一词在2005年开始在网络上出现有关,同时也说明,人们对近期出现的资源较为关注,越远期的资源关注度越低。
笔者还发现这些文献作者数量为2—4人的最多,占64%;作者为1人的仅占23%;5个作者以上的文献占13%,这表明,科学研究越来越趋向于合作,而非单打独斗。[4]
3 统计结果分析
3.1 用户与资源的关系
笔者按照用户标注数量排序后得到一组“用户标注资源数量”数据集,其中每条数据包括:用户名、标注次数。表1显示,有1224名用户参加了这183条资源的标注活动,共发生了3662次标注活动,平均每个用户标注2.99次,平均每条资源被标注的次数是20.01次;标注活动最频繁的两个用户分别标注了53条资源和48条资源,共有24个用户的Folksonomy标注行为超过20次。这说明近两年人们对有关Folksonomy的研究还是非常关注的。
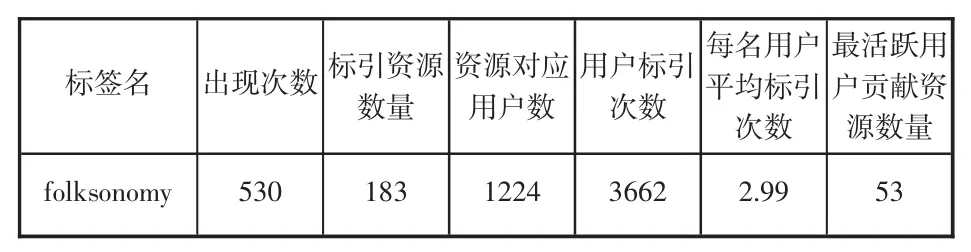
表1 基于folksonomy的资源及其对应的用户
通过分析用户数目与标注行为数目之间的关系,笔者发现大多数的标注行为是由相对较少的用户产生的,标注资源数大于20篇的用户数占用户总数的0.19%,他们占有了17.9%的标注行为数(即标注篇数);标注资源数为1篇的用户占了用户总数的56.9%,而标注行为数(即标注篇数) 仅为总数的1.9%。这表明:数量较少的用户标注行为频次高,而大多数用户的标注行为频次较低,呈现“长尾(Long-Tail)”现象,遵循幂律分布规律,也就是说,数量较少的用户贡献了大部分资源。
3.2 标签与用户的关系
ThomasVanderWal、AdamMathes等多位学者均指出,标签的使用情况也遵循幂律分布(Power Law):一方面,代表用户共同知识的一部分标签被多数用户使用,具有较高的使用频率;另一方面,存在大量“个性化”的标签,仅对少数用户甚至个人有意义,这些标签的使用频率很低,但在数量上却比成为“热门类目”的标签庞大很多。
笔者选取了本组数据中被标注次数最多的1篇文献 《The Structure ofCollaborative TaggingSystems》,统计了其2007年1月至2009年6月的标签使用情况,得到一组共现标签数据集,其中每条数据包括:用户、标签、标注时间。
统计数据显示:该文献在此时间段共被标注了148次,其中个人用户标注125次,群用户23次,共使用了349次标签,平均每个用户使用2.35个标签,出现的共现标签数为98个,还有10人未使用标签。
作者将数据集中标签的序号和标签使用人数两列的数据取值映射到坐标系中,标签的序号作为自变量x,标签的使用人数作为因变量y,用柱形图表现标签与标签使用次数的关系,图像呈现出明显的幂函数的特征。
如图1所示,排序在前几位的标签具有较高的使用次数,代表使用频率高的热门类目,但这样的标签是极少数,使用次数超过30的标签仅2个;随着标签序号的值增大,对应标签的使用次数减少,并且这一下降的趋势非常迅猛,使图像的前半部分具有很大的切线斜率绝对值;在接下来的一段取值区间中,图像经过一个短暂的过渡后,走势逐渐趋于平稳,图像的后半段分布的是使用频率低的标签,即使用人数为2或1的标签达到67个,占据本篇文献标签数量的68.37%,形成了一条基本与x轴平行的“长尾”,也就说大多数标签属于个性化标签,不代表用户的共识。
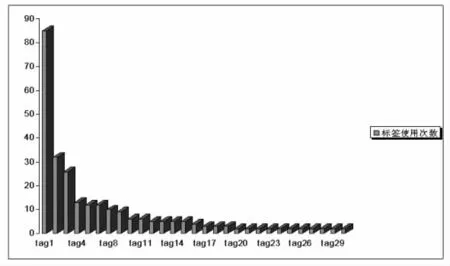
图 1 《The Structure of Collaborative Tagging Systems》标签使用情况
而使用人数超过2的标签,它们中的一部分反映了用户的共识,如tagging和folksonomy,去除拼写错误和单复数形式,这两个标签的使用人数是85和38,分别占总标注人数的57.4%和25.7%,可以说,tagging和folksonomy就是用户对这篇文献的网络自由分类名称。
以上的数据分析验证了用户对标签的选择遵循幂律分布规律。这一特征与文献计量学中的齐夫定律很相似。这类幂律分布的现象普遍存在于自然界和人类社会中,统计物理学家将这类现象称为“无标度现象”,即系统中个体的尺度相差悬殊,例如互联网、人际网,这些网络中不同节点所拥有的连接数都遵循幂律分布规律。
3.3 标签随时间的变化情况
在CiteUlike中,每个用户的标引记录是按照时间先后顺序排列的,这有助于了解用户标签随时间推移的分布情况。笔者选取了标注这183条资源的用户中标注活动最活跃的两名用户ianturton和brusilovsky,分别提取了他们所有标签中使用率最高的前4个标签随时间变化的的情况,二者都是2006年开始有标注行为的,其标注行为如表2,然后借助Excel统计出这些标签的使用率随时间的增长情况,具体结果如图2—图3,其中横坐标代表时间,纵坐标代表该标签的使用率,而不同的标签则用不同颜色表示。
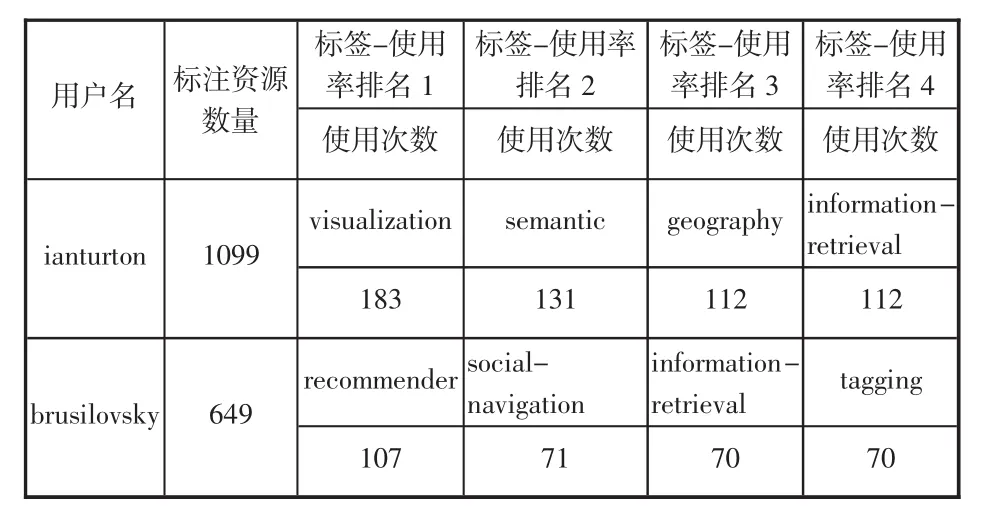
表2 用户使用标签情况
在标签增长曲线中,线段的斜率代表标签使用率的增长速度。线段在某段时间内向上的斜率越大,表示该标签的使用率增长就越快;向下的斜率越大,表示该标签的使用率减少越快,高位平行线段表示该标签在这段时间内使用率较高,呈匀速增长,而低位平行线段则表示该标签在这段时间内的使用率较低,用户很少使用,甚至可能没有使用。
通过图2和图3,笔者发现:
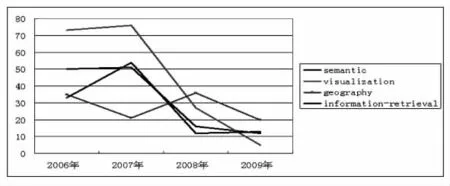
图2 用户ianturton的标签变化情况

图3 用户brusilovsky的标签变化情况
(1)在每个用户的每个标签增长曲线中都存在一个顶点,说明在这个时间点,用户对标签的使用达到一个高峰。如用户brusilovsky在2007年对information-retrieval这个标签的使用达到顶峰,说明2007年的某个时间点,brusilovsky非常关注这方面的资源,或许对之在进行集中研究。
(2)有些标签在高位平行线段形成顶点后开始迅速向下,或形成低位平行线段,或继续下降,说明用户对标签的关注率在下降。如visualization这个标签,82%都是在2006年和2007年使用的,说明用户ianturton在这个时期对可视化这个专题的资源非常感兴趣,而2008年以后对之关注度明显下降。
(3) 有些标签长期保持持续增长态势,如用户brusilovsky的标签recommender和tagging,说明用户对标签的关注率在持续提升。
这些现象表明,标签的生命周期具有阶段性,即用户研究问题的视角可能是不断转移的。若从特定标签的角度来看,则说明用户对它的使用率可能是集中在某一个或几个时间段内,在其余大部分时间内,用户对该标签所代表的问题关注度非常低,而对某些标签来说,用户对它们的关注则属于一次性的短期行为。若选取相同时间段来观察不同标签的斜率,可以发现,增长趋势越接近的标签,其相关性也越高,如图3中的标签semantic和information-retrieval。该现象可以从一定程度上反映出这些标签的共现频率较高的事实,有助于人们判断用户研究热点的变化情况。
3.4 标签之间的关系分析
在社会化标签系统中,标签之间存在一定的隐性关系,挖掘标签之间的联系,有助于更好地理解标签的语义和用户行为。一般而言,共同标注某一资源的所有标签都互为共现标签,标签被用户使用标注同一资源的次数越多,其共现频率越高,相关度也就越高。标签的共现关系可以在一定程度上反映出标签之间的语义关系,如同义关系、层次关系等。
3.4.1 标签共现强度表达了标签的相关度
笔者还是选取《TheStructureofCollaborativeTagging Systems》2007年1月至2009年6月的标签使用情况,查重后共得到98个标签,然后将所有标签按照使用次数排序,因为标签被共同标注的次数越多,其共现频率越高,它们之间的关系越密切。为了统计准确,在统计过程中合并了标签词汇的单复数形式以及明显的拼写错误,如Folksonomy和folksonomies以及olksonomy(明显拼写错误),Tag和Tags、Tagx,collaborative-Tagging和ollabrative-Tagging(拼写错误) 等等,用Excel表绘制图4。图4是上述资源指定标签的频度统计排名分布图,横坐标为标签序号rank(按标签使用频率排序),纵坐标为标签出现的频次与序号的乘积—f*r。可以明显看出,标签的频度统计排名分布基本符合齐夫定律:C=f*r(rank)

图4 folksonomy同现标签的频度排名分布图
图4 显示,在标签出现频次排名较高的部分,曲线相对平坦,即这几个标签的C常数(C=f*r(rank)基本相等,这主要是因为:语义相近或重叠的常用词语(同义词或近义词)会在使用上存在竞争关系,或者说并列关系,如“tagging”“folksonomy”和“Tag”之间就存在这种关系。图中标注了频度最高的4个共现标签,我们定义这4个标签(认为这4个标签能集中地反映该资源的特征) 为强共现标签,[5]即这4个标签共同出现的机会较高,词义相关度极高。对于某个特定的标签,其强共现标签频率分布显示出了与该标签联系密切的“词汇”。
3.4.2 共现标签之间的层次关系
在标注此文献的共现标签中,可以发现以folksonomy为中心,共现标签的关系呈几种层级分布:
●从属关系,上位类:knowledge,socialsoftware,classification,web2.0
●相关关系(同义词关系):tagging,tag,collaborative-tagging,socialbookmarking,social-tagging
●并列关系,同位类:collaborative-filtering,collective_knowledge,semantic,ontology
通过分析特定的标签,从词汇关联角度可以发现有意义的知识模式和语义关联。
3.5 标签的网络聚类特性分析
聚类分析是一种无监督分类,目标是将资源划分为有意义的簇(Cluster)或类,每个聚类簇中的资源之间具有较大的相似性,而聚类簇之间的资源具有较小的相似性。[6]通过聚类簇可以聚合同类资源和同类用户,从而形成网络上的社团结构。
自由分类得以实现,主要是采用社群成员共同建立的标准来进行分类体系的建构。成员提交的标签可能千奇百怪,但系统很容易通过统计方法在这些关键词中发现最适合的元数据。自由分类的分类标准是——“对于同一内容,采用使用频率最高的一个或几个关键字标签来作为其分类元数据”。[7]
由图4容易看出,tagging采用的关键字使用的频率最多(85次),其他几个共现标签——Tag,folksonomy,collaborative也有较高的使用频率,那么这几个标签可以作为这一资源的元数据标签,tagging则可以作为这一资源的Folksonomy分类名称。这是通过自发过程选出的满足大多数人需要的分类标签,这种分类方式与主流网络信息分类体系相比,可以更好地聚合满足用户需求、符合用户分类习惯的资源,并且能帮助用户更好地理解信息分类,从而更快更准确地找到需要的信息。这种有别于学科聚类、主题聚类的方式可以称为社群聚类,它是Folksonomy机制的核心部分。[8]这就进一步体现出Folksonomy是一种基于用户提交关键字的分类,它反应的是整个社群的群体意识倾向和知识背景,具有不同成员结构的社群对同一网络内容就可能形成不同的元数据标签。本文所使用的数据集就是以Folksonomy为标签聚合的资源,同时还将对自由分类法具有共同兴趣的用户也聚合在一起。这种聚类方式,可以凸显出社群成员关心的热点信息,形成一个特别适合本社群成员特点的信息分类体系。
4 结论
由上述分析我们发现:标签是用户在描述资源时自由选用的词汇,在CiteUlike这样的社会化书签系统中,标签的分布和用户的标注行为是遵循幂律分布规律的,即少数用户贡献了大部分资源,少数标签具有较高的使用频率;当标注同类资源时,具有较高使用频率的少数标签成为强共现标签,强共现标签具有社群聚类功能,聚合了同类资源以及同类用户。而Folksonomy正是通过同一标签对不同资源和同一资源对不同标签的聚合作用来不断扩充主题(标签)和资源间的动态联系的,其作用主要表现在:
(1)从标签角度聚合资源,可以揭示资源之间存在的内容相关性,反映通过标签发现新资源的能力;还可以聚合使用该标签的用户,通过追踪他们的标注行为,以类似滚雪球的方式找出许多相关文献。
(2)CiteUlike这样的社会化书签系统可以从资源角度聚合用户行为,即通过选定某资源,揭示标注过该资源的所有用户及其采用的标签,既可以反映不同用户对同一资源的不同理解,帮助人们从不同角度加深对该资源的认识,又可以发现与之具有相同或相似兴趣的人。
(3)同类标签所标注的资源中被标注次数较高的资源和资源作者,相对这个领域可能较为重要,而且有可能以此发现某一学科新的研究热点。
(4)CiteUlike可以按用户来聚合资源,浏览某一用户所有的标引活动,从该用户对标签的使用规律能够分析其研究热点的变化。
(5)CiteUlike这样的社会化书签系统可以通过计算,推荐资源的强共现标签作为用户标注资源时的参考,以便于按标签聚合资源,同时,用户可以从中学习其它收录者是用何种标签描述文献的,为用户的标注行为和浏览行为提供方便和效率。
(6)可以通过研究某一标签的共现标签,深化对用户对资源的理解。
由此可得出结论:Folksonomy这种分类形式在网络资源组织和用户行为研究上都具有独特的优势。
[1]学术网络书签工具——CiteULike介绍[EB/OL].[2009-06-20].http://www.xxc.idv.tw/blog/xxc/webtryit/academic_social_1.html.
[2]个性化站点:CiteULike.org[EB/OL].[2007-06-20].http://www.guwendong.cn/post/2007/site_citeulike_org.html.
[3]CiteULike[EB/OL].[2009-06-30].http://www.citeulike.org/.
[4]Margaret E I Kipp.TaggingPractices on Research Oriented Social BookmarkingSites[EB/OL].[2009-03-20]http://www.cais-acsi.ca/proceedings/2007/kipp_2007.pdf.
[5]王萍.基于自由分类法的elearning标签研究[J].中国远程教育,2008(10):65-70.
[6]王萍.基于自由分类法的e-Learning共现标签网络分析[J].中国电化教育,2008(1):99-104.
[7]ACapocci,GCaldarelli.Folksonomies and clustering inthecollaborativesystemCiteULike[EB/OL].[2009-03-31].http://arxiv.org/PS_cache/arxiv/pdf/0710/0710.2835v2.pdf.
[8]周荣庭,郑彬.分众分类:网络时代的新型信息分类法[J].现代图书情报技术,2006(3):72-75.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
车迷(2018年11期)2018-08-30
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
海峡姐妹(2018年3期)2018-05-09
初中生世界·七年级(2017年9期)2017-10-13
雷达学报(2017年6期)2017-03-26
公民与法治(2016年10期)2016-05-17
互联网天地(2016年1期)2016-05-04
