
一种Glibc互斥锁的统计方法
2011-05-08 01:21王磊曹龙汉
中国新技术新产品 2011年2期
王磊曹龙汉,2
(1.重庆邮电大学通信工程学院,重庆 400065 2.重庆通信学院控制工程重点实验室,重庆 400035)
引言:近年来,随着 GNU(GNU's Not Unix)旗下的linux操作系统的蓬勃发展,GNU发布的C库--Glibc的使用几乎无处不在。与此同时,由于CPU性能的提高特别是多核技术的出现,无论在服务器级应用还是嵌入式程序中都普遍使用了多线程技术,而互斥锁正是解决多线程技术中同步与资源互斥问题的常用手段。Glibc库提供的互斥锁为pthread_mutex_t,一方面,互斥锁提供了资源互斥和任务同步的功能[1][2];另一方面,滥用互斥锁也会导致应用程式出现死锁与程序性能低下等问题。一个有效地互斥锁统计工具应具有以下功能:(1)记录互斥锁的最近操作,以便程序发生死锁时进行分析;(2)统计程序运行后互斥锁的各种操作次数,特别是阻塞发生次数,以便应用程序性能优化时使用。
目前,针对C库进行互斥锁统计的软件并不多,主要原因是:(1)在用户态对C库互斥锁统计准确度不高;(2)互斥锁一般使用在多线程环境,此时资源竞争状况往往十分频繁,添加不适宜的统计操作会严重影响应用程序的效率,甚至改变线程间的执行顺序;(3)由于统计是在多线程环境执行,必然会遇到资源竞争,如果再使用互斥手段避免冲突,就会陷入循环统计。
由于使用互斥锁不当导致的死锁和效率低下问题几乎在每一个软件中都出现过,所以开发一种互斥锁统计工具,对于排查应用程序故障特别是在项目的开发测试阶段进行排查是非常有意义的。本文提出一种统计互斥锁使用情况的方法,程序员可以根据统计结果优化或排查应用程序的互斥锁使用情况,从而减小使用互斥锁带来的负面效应。
2 互斥锁统计算法的原理。本文使用哈希算法查询技术查找mutex统计对象,使用循环队列技术记录mutex近期的操作,使用原子操作解决资源冲突的情况。
2.1 哈希算法简介。用来产生一些数据片段(例如消息或会话项)的哈希值的算法叫哈希算法[3][4][5],它是信息存储和查询所用的一项基本技术,基于Hash函数的文件构造方法,可实现对记录的快速随机存取。哈希算法把给定的任意长关键字映射为一个固定长度的哈希值,一般用于鉴权、认证、加密、索引等。使用好的哈希算法,在输入数据中所做的更改就可以更改结果哈希值中的所有位。
哈希算法也称为"哈希函数"。主要优点是运算简单,预处理时间较短,内存消耗低,匹配查找速度比较快,便于维护和刷新,支持匹配规则数多等。好的Hash算法具有以下三个性质:
(1)单向性。给定一个输入数,容易计算出它的哈希值,但是已知一个哈希值根据同样的算法不能得到原输入数。
(2)弱抗碰撞性。给定一个输入数,要找到另一个得到给定数的哈希值,在使用同一种方法时,在计算上不可行。
(3)强抗碰撞性。对于任意两个不同的输入数,根据同样的算法计算出相同的哈希值,在计算上不可行。
然而,要实现哈希算法,完全满足上述三个性质几乎是不可能的。实际上,哈希算法用于分类时,需要考虑不同关键字之间哈希值可能发生的地址冲突。当发生冲突时,一般采用开放定址法来解决冲突,即建立冲突解除区,并使用链表在冲突解除区中存放冲突的关键字。如图1所示,当不同的输入产生相同的Hash值时,后输入的数将被以链表的形式存放在冲突解除区(哈希桶)中。冲突的数越多,该Hash值后面的链表越长。在进行信息检索时,如果所需的信息存放在冲突解除区,就需要遍历冲突解除区中的链表。
2.2 互斥锁统计对象的哈希表查找方法。本统计中的哈希表是根据哈希算法由C语言实现的,为了达到统计算法的要求,我们使用了以下几个关键技术:

图1 哈希表结构
1 )使用面向对象技术,针对每个哈希表对象封装了一套自定义的哈希算法、哈希表遍历操作;
2 )使用除余法来构建哈希函数。由于使用mutex对象的指针对作为键值,考虑到程序实际运行时mutex指针前两个字节变化较少后两个字节变化频繁的特点,让其前后两个字节的异或做除余法。即,异或值除以哈希表的桶数(哈希表的容量)作为哈希值;
3 )使用开放定址法来处理冲突。如图1,当出现哈希值冲突的情况,在桶中建立一个链表,解决冲突。
2.3 互斥锁近期操作的循环队列记录方法。循环队列[6]是指循环利用的队列,具有队列的先进先出特性,同时在队列被写满后循环到队列首部保存下一次数据。由于记录互斥锁操作只关心最近N次的操作内容,所以循环队列完全可以满足要求,并且还可以节约软件的空间消耗。
循环队列使用两个变量--队列头和队列尾记录队列的开始和结束,其关键算法为队列头或尾的上移(标志减一)和下移(标志加一)。设pos为当前位置,n_pos为移位后的位置,volume为循环队列的容量,则上移(标志减一)算法为:
n_pos=(volume+pos-1)%volume
下移(标志加一)算法为:
n_pos=(pos+1)%volume
2.4 互斥锁资源冲突的原子操作方法。所谓原子操作是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会被切换到另一个线程。
原子操作是不可分割[7]的,在执行完毕不会被任何其它任务或事件中断。在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是“ 原子操作”,因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源互斥的原因。但是,在对称多处理器(Symmetric Multi-Processor)结构中就不同了,由于系统中有多个处理器在独立地运行,即使能在单条指令中完成的操作也有可能受到干扰。我们以decl(递减指令)为例,这是一个典型的"读-改-写"过程,涉及两次内存访问。设想在不同CPU运行的两个进程都在递减某个计数值,可能发生的情况是:(1)CPU A(CPU A上所运行的进程,以下同)从内存单元把当前计数值1装载进它的寄存器中;(2)CPU B从内存单元把当前计数值2装载进它的寄存器中;(3)CPU A在它的寄存器中将计数值递减为1;(4)CPU B在它的寄存器中将计数值递减为1;(5)CPU A把修改后的计数值1写回内存单元;(6)CPU B把修改后的计数值1写回内存单元。我们看到,内存里的计数值应该是0,然而它却是1。如果该计数值是一个共享资源的引用计数,每个进程都在递减后把该值与0进行比较,从而确定是否需要释放该共享资源。这时,两个进程都去掉了对该共享资源的引用,但没有一个进程能够释放它,所以两个进程都推断出:计数值是1,共享资源仍然在被使用。
原子操作大部分使用汇编语言实现,因为C语言并不能实现这样的操作。以下是在x86体系下的一个原子加操作代码:


3 互斥锁统计算法的实现。首先,规避和解决在互斥锁统计的限制因素:
1 )由于,本统计工具是用宏观统计信息解决应用程序的效率问题,所以对互斥锁的统计精度要求不高,在5%以内的偏差是可以接受的。导致统计数据不准确主要发生在多线程之间对互斥锁竞争操作的时候,这种极端环境对绝大多数应用软件不会在整个运行周期普遍存在。所以采用修改C库互斥锁操作相关代码,使用钩子函数嵌入统计操作的方法可以满足统计性能要求;
2 )为了不影响应用软件的效率,嵌入的统计操作应该非常快速。对于查找统计对象--互斥锁,采用哈希算法,可以极大的减小查找开销;
3 )对于统计中不可避免的资源冲突,不能使用加互斥锁或其它锁的方式。本文采用原子操作解决该问题;
4 )需要说明:在记录互斥锁最近N次操作时,采用循环队列技术,可以有效减小统计工具对内存的需求,减小记录结果插入队列的时间开销。
应用软件运行后,互斥锁统计的步骤与操作的Glibc接口不同而稍有差异,但主要流程基本一致。下面以对pthread_mutex_lock接口操作为例,介绍工具运行时的主要步骤:
setp1:应用软件运行,统计工具构造函数初始化作为统计结果储存器的HASH表;
setp2:应用软件调用Glibc中的pthread_mutex_lock接口,获取锁被阻塞,触发阻塞统计钩子函数;
setp3:钩子函数查询HASH表找到相应mutex统计对象,将其阻塞次数加一,记录该次操作。如果HASH中不存在对应mutex对象,则执行setp4;
setp4:初始化一个新的mutex统计对象,并添加到HASH表中;
setp5:应用软件调用Glibc中的pthread_mutex_lock接口,试图获取锁出现锁状态异常退出,触发锁状态异常退出统计钩子函数;
setp6:钩子函数查询HASH表找到相应mutex统计对象,将其异常次数加一,记录该次操作;如果HASH中不存在对应mutex对象,则执行setp4;
setp7:应用软件调用 Glibc中的pthread_mutex_lock接口,获取锁成功,触发锁成功统计钩子函数;
setp8:钩子函数查询HASH表找到相应mutex统计对象,将其成功锁次数加一,记录该次操作。如果HASH中不存在对应mutex对象,则执行setp4;
setp9:应用程序退出,统计工具打印当前互斥锁的完整统计信息。
4 算法测试及性能分析
编写测试程序,设置10个线程分别对20个互斥锁进行初始化、锁和解锁操作(其中每个线程对20个锁依次申请,然后统一释放,如此循环100次),得到的总体测试结果如表1所示。
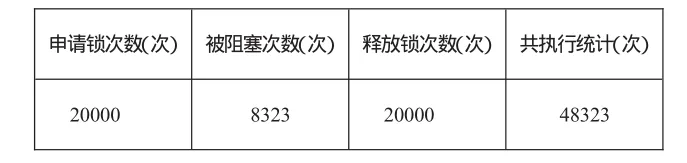
表1 测试程序总体统计结果
为了分析加入互斥锁统计后对软件性能的影响,本文采用打点计数法。对于X86CPU体系的计算机,其CPU提供了一个64位高精度计时器,上电后清零,在每个CPU时钟周期累加。计时器的值可以通过读RDTSC寄存器获得,由于使用X86指令实现打点计数只需要几条汇编指令就可完成,用来分析统计的时间消耗影响较小。本文进行了三次打点计数测试,测试结果如表2所示。
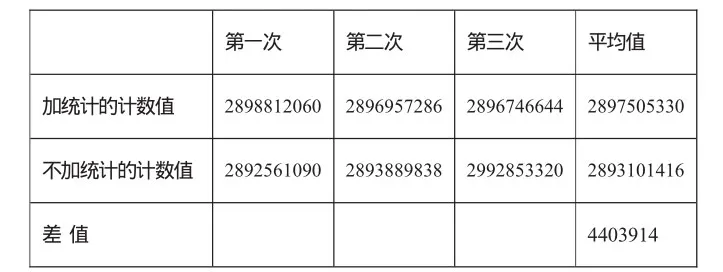
表2 加统计和不加统计的计时器对比
由于CPU的时钟频率为3.0GHz,统计执行次数为48323,所以三次统计平均每次总消耗时间1.7977×10-4秒,平均每次统计耗时3.72×10-9秒。可以看出加入互斥锁统计后对软件的效率影响是比较小的,在大多数软件的可接受范围以内。
结束语
本文提出一种针对Glibc互斥锁的统计方法,给出了统计流程和算法的实现过程,分析了该统计方法对被统计应用软件效率的影响情况。本方法具有开销小和记录互斥锁近期操作的功能,特别是在应用软件项目的开发测试阶段使用,可以快速有效地定位死锁流程,减小了无谓的互斥锁阻塞,提高了应用软件的执行效率。
[1]杨中良,蒋朝根.Linux内核的可抢占性分析和研究 [J].成都信息工程学院学报,2008 vol.23.5:505-507.
[2]Usui T,Behrends R,Evans J,Smaragdakis Y.AdaptiveLocks:Combining Transactionsand Locks for Efficient Concurrency[C]//International Conference on Parallel Architectures and Compilation Techniques.IEEE Computer Society,2010.Page(s):3-14
[3]Thomas H.Cormen,Charles E.Leiserso,Ronald L.Rivest著.潘金贵,顾铁龙,李成法,译.算法导论[M].北京:机械工业出版社,2006,9.
[4William Stallings著. 陈向,群陈渝,译.操作系统:精髓与设计原理[M].北京:机械工业出版社,2010,9.
[5]Tsukamoto,Daisuke,Nakashima,Takuo.Implementation and Evaluation of Distributed Hash Table Using MPI[C]//International Conference on Broadband,Wireless Computing,Communication and Applications.IEEE Computer Society,2010.Page(s):684-688
[6]Mark Allen Weiss著.冯舜玺,译.数据结构与算法分析:C语言描述[M].北京:机械工业出版社,2004.1.
[7]William Stallings著.张昆藏,译.计算机组织与体系结构:性能设计[M].北京:清华大学出版社,2006.3.
猜你喜欢
小学生学习指导(低年级)(2020年4期)2020-06-02
军营文化天地(2018年2期)2018-12-15
快乐语文(2018年15期)2018-11-29
产品可靠性报告(2017年7期)2017-09-05
小朋友·快乐手工(2017年3期)2017-04-26
中华戏曲(2017年2期)2017-02-16
计算机工程(2015年8期)2015-07-03
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
