
基于HMM和ANN的语音情感识别研究
2011-08-07 07:53胡洋蒲南江吴黎慧高磊
电子测试 2011年8期
胡洋,蒲南江,吴黎慧,高磊
(中北大学信息与通信工程学院 太原 030051)
0 引言
目前,大多数研究者都是基于Plutchik划分的6大基本情感(平静、高兴、惊奇、愤怒、悲伤、恐惧),本文也以上述分类标准进行语音情感识别研究。语音情感识别的研究已取得许多成果,但是传统的方法大多都是运用单一的分类器来进行情感识别,比如文献[3]构建HMM模型进行语音情感识别,得到了不错的识别率。而文献[4]通过自组织人工神经网络进行语音情感识别也有比较理想的识别结果。但是由于单一分类器的固有缺点,识别率还有待提高。本文考虑将HMM和ANN两种分类器进行融合,将进一步提高语音情感识别率。
1 语音情感库建立
由于语音情感识别研究的特殊性,没有统一的语音情感识别库,大多数研究者都是自建符合自己研究的语音情感识别库,主要有两种获得语音情感库的方法:一是诱导录音法,通过准备没有情感状态倾向的中性语句作为录音脚本,记录录音者在各种模拟情感状态下的语音材料作为语音库;二是视频剪辑法,通过截取影视作品中的带有需要情感状态的语句作为语音库的来源。
因为视频剪辑法工作量大,而且得到的语音材料大多包含背景音,给后期工作带来额外的麻烦。本文采取诱导录音法建立情感语音库,即邀请8位(4男4女)情感丰富的录音者对30个语音脚本分别用高兴、愤怒、惊奇、悲伤、恐惧以及平静的方式录音1遍。然后邀请录音者之外的10人对录音材料进行试听实验,去除情感特征不明显的语句,最终得到600句符合要求的情感语句,400句作为训练语句,200句作为识别语句。
语音听取实验的结果见表1。
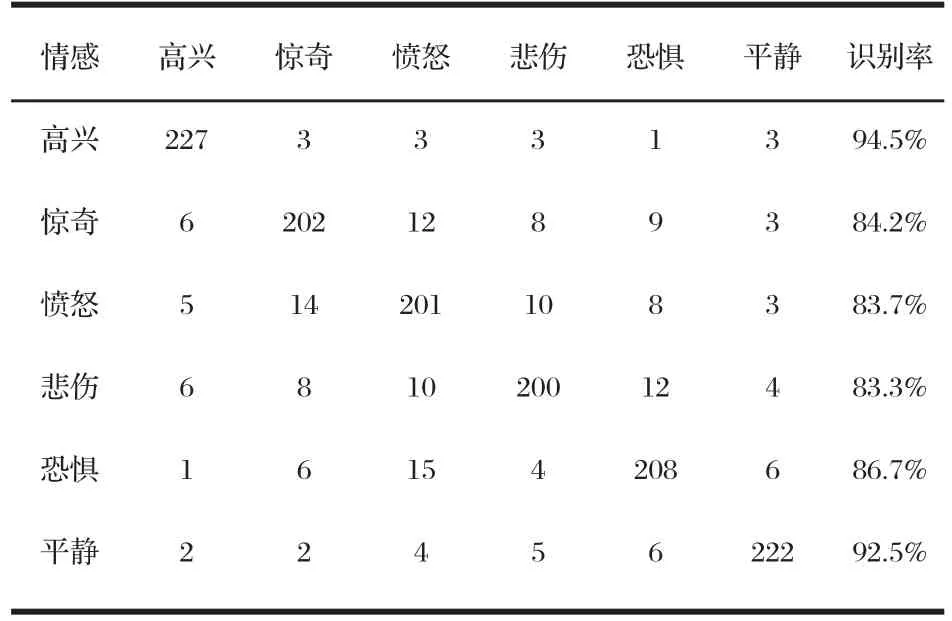
表1 情感语音听取实验结果
2 特征提取
语音之所以能够表达情感,是因为其中包含能体现情感特征的参数。情感的变化通过特征参数的差异而体现。因此研究从语音信号中提取什么样的特征来反映情感状态的差别,对于情感语音识别具有极其重要的意义。
选取语音情感特征要考虑两个方面的因素:一是选取的情感特征要适合所采取的语音情感识别模型的结构和特点;二是要携带情感信息。本文分别从语音的语音特征和韵律特征两个方面提取符合上述要求的语音情感特征。
2.1 基音频率参数
研究表明在不同的情感状态下,对于同一句话,基频的变化是不同的,基音频率反映的是整个语音信号的语调轨迹,较好地体现了人的情感的变化。比如惊奇情感信号的基频轨迹曲线在句尾的地方往往有上翘的特征。
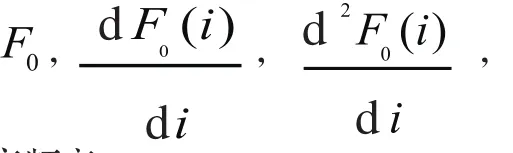
2.2 短时能量参数
短时能量参数反映了语音振幅或能量随时间变化的关系。语音信号短时能量定义为:
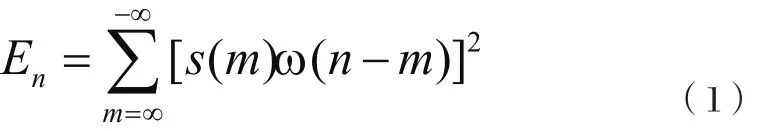
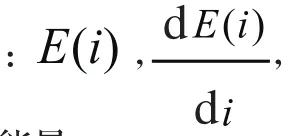
2.3 线性预测倒谱系数(LPCC)
语音情感识别常用的一种特征参数是线性预测倒谱系数(LPCC),线性预测倒谱系数是从线性预测编码系数LPC推导出来的。LPCC的主要优点是提取出了语音产生过程的激励信息,该信息主要反映声道特性,而且只要十几个倒谱特征参数就能很好的反映出语音的共振峰特性。
为了适应HMM模型的结构,对提取出来的各种语音情感特征要进行归一化处理,归一化后的特征参数连接形成了18维的语音特征向量:
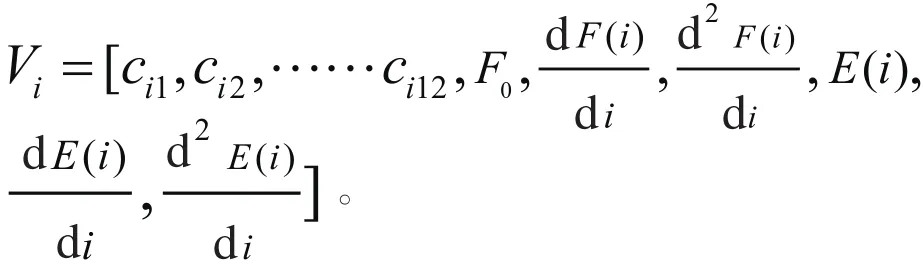
3 语音情感识别
ANN和HMM是在语音情感识别中应用较多的分类器,两者各有优势和缺点。HMM是对语音信号进行统计建模的强有力工具,但模式识别性能较差,识别和训练算法依赖于较强的假设。ANN则具有较强的模式识别性能和并行处理能力,它具有学习特定知识而不需要预先假设的能力,缺点是不能处理语音动态变化的特征序列。本文将结合两者的特点,建立一个融合HMM和ANN的语音情感识别器。
隐马尔科夫链(HMM)是双重随机过程,一个随机过程描述状态的转移,另一个描述状态与观察值之间的统计对应关系。在HMM中,不能直接看到随机过程的状态,只能看到观察值,通过另一个随机过程去感知状态的存在及其特性。
HMM模型可以很好地模拟人类的语言过程,自从20世纪80年代,L. R. Rabiner把HMM|统计模型引入语音情感识别上以来,研究者已经取得了不少研究成果。HMM在语音情感识别中的主要问题有:Baum-Welch训练算法、Viterbi算法等问题。传统的Baum-Welch算法是一种基于最大似然训练准则的算法,其本质上是似然概率 P ( X )最大化的问题的一个局部最优解的问题。 是模型的参数集,X表示用于训练的数据。它是用已知类别的模型数据来训练模型,使其似然概率趋于局部最大,但是不能保证这个似然概率比其他模型对应的数据的似然概率更大。本文考虑使用基于最大互信息量(MMI)的参数重估方法。
对于HMM模型,要为每一种情感建立一个HMM模型,本文对高兴、惊奇、愤怒、悲伤、恐惧、平静这6种情感分别建立一个HMM模型,标记为 Hi, i = 1 , 2 , 3 , 4 , 5 , 6 。在进行语音情感识别过程中,对于每一个要识别的情感语音样本M,都要进行分帧、预处理、特征参数的提取和特征参数的归一化的准备工作,得到所需要的语音特征向量Vi,对于每一种HMM模型,利用Viterbi算法求出相应的最大概率,语音样本就被识别与其匹配概率最大的HMM所代表的语音情感。
然后考虑HMM和ANN的融合问题,这里选用的人工神经网络是多层感知器(Multilayer perception)。MLP有以下特点:(1)它能将复杂的声学信号映射为不同级别的语音学和音韵学的表示(2)对不同的类,可以在超平面中形成分离得部分,适合于分类(3)不需要事先做出假设,对模型使用全局约束,识别效果好。
HMM和ANN融合的整体识别流程图如图1所示。

图1 ANN/HMM识别流程图
首先对该分类器进行训练,HMM采用简单的从左到右的单向HMM模型,训练算法采用基于最大互信息量准则。对每一个样本计算它和所有HMM模型的似然概率,同时为了得到等维的特征矢量,这里采用平均矢量法对得到的语音特征矢量进行规整,从而完成对神经网络的训练过程。在识别阶段,先用每个HMM的均值矢量序列与待识别的语音信号进行线性匹配,选择距离最小的HMM对待识别的语音规整,作为神经网络的输入节点,通过MLP识别。实验结果表明识别结果有了一定的提高。具体数据如表2所示。
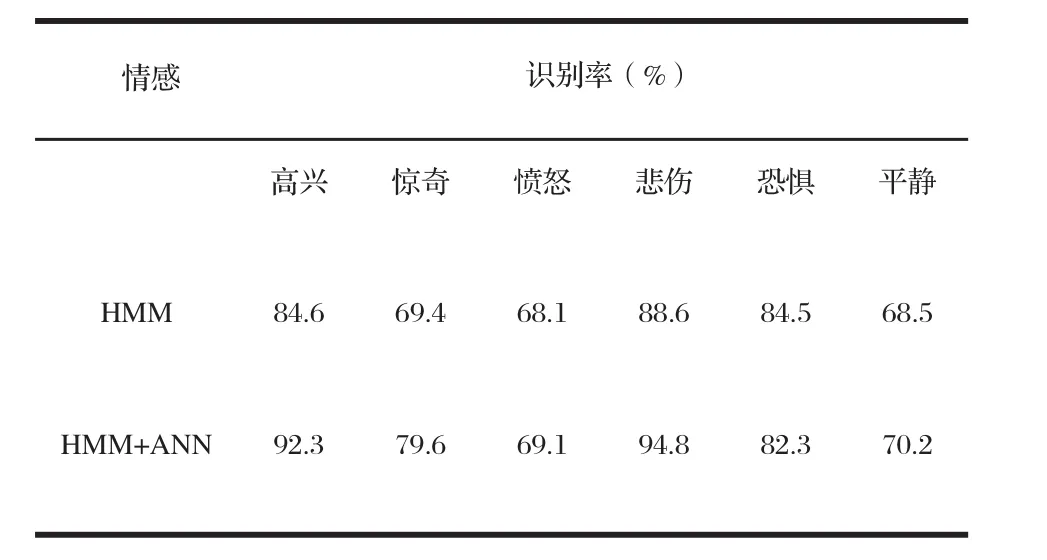
表2 HMM和HMM/ANN识别结果对比
4 结束语
基于多种分类器的融合的方法是一种值得探究的方法,在单一分类器的识别率提高有一定困难的情况下,多分类器融合为提高语音情感识别率开创了新的方向,由于语音样本不足等种种原因,语音情感识别率还有待提高,有些技术还有待突破,例如MMI准则还有待改进等问题。
[1]蒋丹宁,蔡莲红.基于语音声学特征的情感信息识别[J].清华大学学报:自然科学版,2006, 46(1):86-89.
[2]赵力,蒋春晖,邹采荣,等. 语音信号中的情感特征分析和识别的研究[J]. 电子学报,2004,32(4):606-609.
[3]国辛纯,郭继昌,窦修全.基于HMM的语音情感识别研究[J].电子测量技术,2006,29(5):69-71.
[4]石瑛,胡学钢.基于神经网络的语音情感识别[J]. 计算机工程与应用, 2008, 44(24):191-194.
[5]林奕琳,韦岗. 基于短时和长时特征的语音情感识别研究[J]. 通信技术,2006,6(4):450-454.
[6]赵力,钱向民,邹采荣,等,语音信号中的情感识别研究[J]. 软件学报,2001(12):1050-1055.
[7]茅晓泉,胡光锐.基于最大互信息量的离散隐马尔科夫模型训练方法[J].上海交通大学学报,2001,35(11):1713-1716.
[8]李玉萍,朴春俊,韩永成.一种带噪语音信号端点检测方法研究[J].电子测试,2008(2):14-17.
猜你喜欢
阅读(快乐英语中年级)(2021年10期)2021-03-08
空间科学学报(2020年1期)2021-01-14
阅读(快乐英语中年级)(2020年10期)2020-12-09
阅读(快乐英语中年级)(2020年5期)2020-07-27
计算机工程(2020年3期)2020-03-19
阅读(快乐英语中年级)(2019年9期)2019-09-10
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
制造技术与机床(2017年11期)2017-12-18
中国交通信息化(2017年8期)2017-06-06
