
数据流聚类算法分析
2011-10-21 06:05王冬秀张海鹏
大众科技 2011年5期
王冬秀 张海鹏 李 辉
(1.广西工学院,广西 柳州 545006;2.柳州市公安局,广西 柳州 545000)
数据流聚类算法分析
王冬秀1张海鹏2李 辉1
(1.广西工学院,广西 柳州 545006;2.柳州市公安局,广西 柳州 545000)
数据流作为一种新的数据对象,近年来成为了数据挖掘领域的研究热点问题,具有很大的应用前景。文章首先比较了数据流聚类分析和传统的聚类分析的一些不同点,然后对目前几个典型的数据流研究成果进行了分析,最后对数据流的进一步研究方向进行了展望。
聚类分析;数据流;数据流聚类
(一)引言
近年来,数据流作为一种重要的数据对象,受到越来越多学者的关注,针对数据流的挖掘成为了研究领域的热点问题。数据流是一种数据规模大、变化速度快、时间有序、潜在无限的数据。它最大的特点是以一种动态、流的形式出现,而不像传统的数据被静态、固定地存储在介质中,可随机多次访问。那么对于这样一种特殊且日益主流的数据形式,我们该如何从中快速、高效地挖掘出有价值的信息,成为了众多应用领域的客观需求,也吸引了国内外众多专家学者的注意。聚类分析作为数据挖掘领域的一种重要的研究方法,受到了广泛地关注。本文首先介绍传统的聚类方法和数据流聚类方法的一些特点,然后对最近几年典型的数据流研究成果进行了分析和评价。
(二)传统的聚类分析
聚类是将数据对象分成类或簇的过程,使同一簇中的数据对象之间具有很高的相似度,不同簇中的对象高度相异。聚类分析形式定义为:在数据空间S中,数据集X由许多数据点或数据对象组成,数据点 Xi(Xi1, Xi2,…Xin)∈ S,
Xi的每个属性Xij可以是枚举型、数值型等任意类型。数据集X相当于一个 M × n 的矩阵。假设X中有M个对象Xi(i=1,2…M)。聚类的目的是把数据集X划分为k个分割Cx(x =1,2…K),在划分的过程中,会产生噪声Cy,Cy不属于任何一个分割。数据集X就是所有这些分割和噪声Cy的并集,并且分割之间不存在交集,即这些分割xC就是聚类。
聚类分析技术作为数据挖掘领域一个非常活跃的分支,在很多领域都得到了广泛地应用。在聚类分析中,目前已出现了许多适用于各种数据类型和不同应用的算法,这些算法概括起来可分为如下几类:基于划分的方法(如k-均值、k-中心点算法)、基于层次的方法(如 BIRCH、CURE算法)、基于密度的方法(如DBSCAN、OPTICS 算法)、基于网格的方法(如STING、Wave Cluster算法)、基于模型的方法(如EM 、COBWEB算法)等。这些算法的处理结果通常从以下几个标准进行评价:可伸缩性、处理不同属性数据的能力、数据记录的输入不敏感性、发现任意形状的聚类、处理高维数据的能力、可解释性和可应用性等。
(三)数据流聚类算法的特点
数据流数据规模大、变化速度快、到达速度不确定等特点决定了很多传统的优秀聚类算法不能直接应用于数据流,必须对其进行“量身”改造,相比于传统的聚类算法,数据流聚类算法应具备以下特点:
(1)单遍扫描:由于数据流具有数据量大、流速快,因此每个数据元素只能被检测一次,即只能进行单遍扫描;
(2)存储空间有限性:由于数据流的数据是潜在无限的,因此不可能存储如此海量的数据,待对其进行清洗后再进行处理,只能在尽量不影响聚类结果的前提下,存储数据流的摘要信息;
(3)实时性:由于数据流的速度非常快,因此对数据流的处理要适应“流”的快速变化,每条记录的处理时间应该越少越好。
数据流的以上特点决定了我们不可能存储海量的数据,待对其进行清洗和整理后再进行处理,因此其研究核心是设计高效的聚类算法,在一个远小于数据规模的内存空间里不断更新一个代表数据集的结构—概要数据结构,使得在用户有任何请求时,都能够根据这个结构迅速获得近似查询结果。一个通用的数据流处理模型如图1所示:
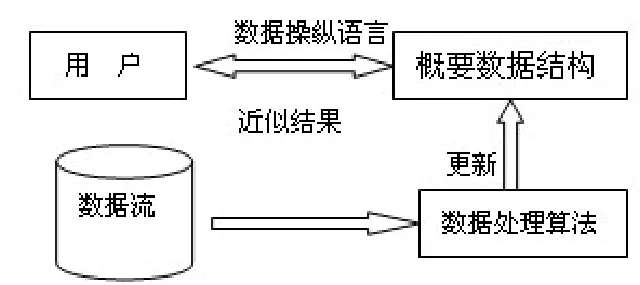
图1 数据流处理通用模型
数据流的这些特点,使得许多传统的优秀的聚类算法不再有效,因此,许多传统的聚类方法必须针对数据流进行“量身改造”才能获得有意义的结果,数据流聚类算法就在这样的背景下应运而生了。
(四)数据流聚类算法
目前,由于数据流的大量涌现,国内外众多专家学者纷纷投入了数据流的研究中,尤其是数据流在现实生活中的广泛应用,如网络监控、传感器网络、行星遥感、股票交易分析、Web点击流、气象与环境监控等方面的广泛应用,使得数据流的研究成为了一个前沿的热点问题,本文对现有的比较典型的数据流聚类算法进行介绍,并分析了这些算法的优缺点。
1.CLIQUE算法
R.Agarwal 等人在文献中提出的CLIQUE算法,该算法采用自下而上的方式搜索数据集的所有子空间,由于CLIQUE把每一维划分成网格状的结构,并且根据每个网格单元所包含点的数目来确定该网格单元是否稠密,因此该算法是基于密度和基于网格方法的一种集成。该算法吸收了 Apriori算法的思想,在算法的执行过程中,不断地搜索满足指定阈值的稠密网格单元,同一子空间内相连的稠密网格单元作为聚类输出。对于一个稠密的区域,该区域在所有低维子空间的投影都将是稠密的,因此输出的聚类簇可能会存在大量重叠。
2.CluStream算法
为了跟踪进化数据流聚类,2003年Aggarwal等提出了一种基于划分的 CluStream算法,该算法分为在线和离线双层结构处理数据流,在线部分执行 K - means算法产生微簇,离线部分执行 K - means算法以微簇累积快照产生宏簇。至今很多算法还沿用这种双层结构。
3.SHStream算法
2006年,在文献中,周晓云等人提出一种基于Hoeffding界的高维数据流子空间聚类发现及维护算法—SHStream,该算法将数据流分段(分段长度由Hoeffding界确定),在数据分段上进行子空间聚类,由于该算法采用 Apriori方法得到候选密集单元,在操作过程中,会产生大量的候选单元,占用大量的存储资源,这无疑降低了算法的效率。
4.CELL TREE算法
为了有效地跟踪高维数据流聚类,2007年Nam Hun Park等人又提出了 CELL TREE算法,该算法吸收了子空间聚类算法的思想,是一个基于网格和密度算法的结合,改进了hybrid-partition算法,在内存中维护一个聚类模型,它把一个密集网格单元划分为一定数量的相等互斥的网格单元。该算法能够有效地处理在线的高维数据流,具有以下优点:(1)不需要事先知道聚类的数量;(2)能够处理任意形状的聚类;(3)能够较好地处理高维数据流。但该算法也存在一定的问题:(1)需要大量的存储空间来保存网格单元的密度信息,使算法的空间伸缩性受到限制;(2)在处理过程中,内存网格单元的更新需要大量的计算时间,使算法的时间效率受到了限制;(3)该算法在划分的过程中,会产生大量空网格单元,随着数据维数的增加,内存的使用量迅速增长。
5.SWClustering算法
为了跟踪进化数据流聚类,2008年Aoying zhou等人提出了SWClustering算法,该算法结合指数直方图技术,提出了一种新的数据结构 EHCF(the Exponential Histogram of Cluster Features),EHCF为跟踪进化数据流提供了一个灵活的框架,能够有效地跟踪聚类而不受其它聚类的干扰。
尽管以上这些算法的设计都适应了数据流的特点,并取得了较好的效果,但面向数据流的聚类分析方法仍然存在很多问题,如:(1)算法在运行过程中会产生大量的侯选子空间,聚类效果相对较差;(2)在操作过程中,会产生大量空的网格单元,算法的时间和空间效率均受到一定的限制等。因此对数据流聚类算法的深入研究具有十分重要的意义。
(五)结论
本文回顾了最近几年来国内外数据流聚类的研究成果,并对该领域的几个典型的算法进行了分析和讨论。近年来,数据流聚类正在蓬勃发展,数据流聚类是一个非常活跃且具有挑战性的研究课题。随着经济的快速发展,实际生产和生活中,实时的数据流将大量产生,基于实时的数据流聚类技术具有重要的理论和实际意义。随着研究的不断深入,实时的数据流聚类技术必将在航天航空、行星遥感、工业控制、交通监控等领域扮演越来越重要的角色。
[1]B.Babcock,S.Babu,M.Datar,R.Motwani,J.Widom.Models and issues in data stream systems.In Proceedings of the Twenty-first ACM SIGACT SIGMOD-SIGART Symposium on Principles of Database Systems,June 3-5,Madison,Wisconsin,USA,pp.1-16.ACM,2002.
[2] J.W.Han,M.Kamber著.数据挖掘:概念与技术[Ml.范明,孟小峰,译.北京:机械工业出版社,2006.
[3] 纪希禹,韩秋明,李微,李华锋,等.数据挖掘技术应用实例[Ml.机械工业出版社,2009:53.
[4] M.Garofalakis, J.Gehrke, R.Rastogi. Querying and mining data streams: you only get one look.in: The Tutorial Notes of the 28th International Conference on Very Large Databases, Hong Kong,China,August2002.
[5] 金澈清,钱卫宁,周傲英,等.流数据分析与管理综述[Jl.软件学报,2004,15(8):1172-1181.
TP311
A
1008-1151(2011)05-0029-02
2011-02-21
王冬秀(1981-),女,广西桂林人,广西工学院财政经济系实验师,硕士研究生,研究方向为数据挖掘、数据流聚类;张海鹏(1974-),男,广东惠州人,柳州市公安局工程师,研究方向为数据挖掘;李辉(1981-),男,广西桂林人,广西工学院财政经济系讲师,硕士研究生,研究方向为数据挖掘,模式识别。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
铁道通信信号(2019年6期)2019-10-08
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
信息通信技术(2015年6期)2015-12-26
西北工业大学学报(2015年3期)2015-12-14
电子设计工程(2015年6期)2015-02-27
中国卫生(2014年7期)2014-11-10
