
基于神经网络控制的LMS算法及其仿真*
2011-11-27 01:46修海燕闫德勤
网络安全与数据管理 2011年5期
修海燕,闫德勤
(辽宁师范大学 计算机与信息技术学院,辽宁 大连 116081)
自适应信号处理已广泛应用于系统辨识、声纳技术及图像处理等相关领域[1]。基于自适应滤波理论滤波器参数可以最佳方式进行反复调整。Widrow和Hoff在1960年提出了一种简单而有效的LMS(Least-Mean-Square)算法。在LMS算法中,确定学习步骤μ是一个基本的问题。如果选择太小,收敛速度将会非常缓慢,而选择太大则极易造成不稳定[2-3]。尽管Widrow已经建议了学习步长的范围 μ (0<μ<1/λmax,λmax是输入信号的最大特征值),保证了算法的收敛,但最佳学习步长选择问题并未得到解决,更多的是采用调低以取得收敛速度和稳定性的折中。这类方法大多是仅仅提出一种与失调情况下的学习步调相关的抽样函数[4-5]。最近的研究提供了一种新的可变步长的LMS算法,学习步长由BP神经网络(BP-LMS)控制。使用BP神经网络来构建一个嵌入在输入向量、偏差以及学习步长之间的模块。由于对BPLMS算法最重要的工作是设置BP神经网络控制,假设,如果输入信号相同,则只需要构建一个BP神经网络即可控制几个自适应滤波器的学习步骤。此外,实验结果表明,BP-LMS算法能在滤波器稳定运行的状态下提高收敛速度。
1 LMS自适应滤波
自适应滤波器的实现如图1所示。图中 s(n)、v(n)、d(n)、e(n)分别是输入的信号、噪声、设定值以及偏差。LMS算法由以下方程描述:
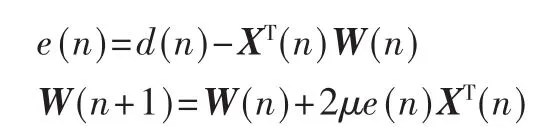

图1 自适应滤波器原理
式中,μ为学习的步长,X(n)为采样时间n时的输入向量,W(n)为自适应滤波器的系数向量;尺寸为自适应滤波器的步长,d(n)为期望输出值,e(n)为偏差。
收敛速度和稳态失调量是评估自适应滤波器性能的两个重要因素。当减少学习步长μ时,可以减少稳态失调量,但也减慢了收敛过程;增加μ时,收敛的速度增加了,滤波器的失调量输出也随之增加。
本文将寻找最佳的学习步长,在适当的收敛速度下获得最佳失调量。假设一种新的LMS算法,学习步长被输入向量及偏差所影响,而之前寻找最佳步长的经验也有助于自适应过程的后一阶段寻找最佳学习步长。由于诸如自学习等方法的非线性解决能力强,本文中采用了人工神经网络(ANN),用神经网络确定自适应滤波器的学习步长是克服收敛速度和稳态失调量矛盾的一种很好的办法。
2 BP神经网络
ANN使用的神经细胞群形成了一个网络,可以模拟任何复杂的非线性系统。ANN有许多重要的特征,如自学习、自组织、自适应及容错能力等[6]。近期来,ANN在许多应用中取得了很好的结果,特别是多层前馈神经网络(MFNN),是一种解决实际工程问题的有效工具。
由于隐藏单元引入ANN,使ANN具有了更强的分类和记忆能力。学习复杂的多层网络模型最流行、有效又简单的方法是20世纪70年代发展起来的前馈、反向传播架构。它的优势表现在对不确定问题的非线性解决能力,已在多种场合得到应用。典型的反向传播(BP)网络有一个输入层、一个输出层,并至少有一个隐藏层,每一层都连接到下一层。BP网络的规则是:输入值Xi通过输入节点作用于输出节点。
隐藏层通过非线性变换生成输出值Yk。每个网络训练样本为:输入值 X、期望输出 t,输出值 Y和期望值 t的偏差。可以调整输入层节点i和隐藏层节点j之间的连接权重Wij、隐藏层节点j和输出层节点 t之间的连接权重Tjk,以及阈值使得偏差呈梯度下降。通过反复学习和训练,根据最小允许偏差获得BP模型参数(连接权重和阈值),训练过程就此完成。
训练后的BP模型参数指出了输入信号和输出信号的非线性关系,数据输入训练过的BP网络可以获得响应结果。
3 BP-LMS算法
在大部分可变步长LMS算法中,学习步长通过一些采样函数获得偏差决定,但是在BP-LMS中,建立了输入向量、偏差及学习步长之间的关联。即学习步长被最近的输入和偏差所影响。
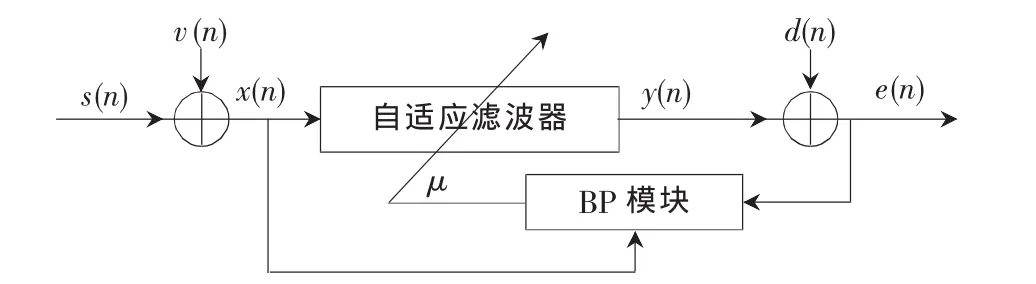
图2 BP-LMS在自适应滤波器内的应用
BP神经网络以它强大的非线性解决能力使得BPLMS成为现实[5]。图2所示为BP-LMS在自适应滤波器中的应用原则,s(n)表示采样时间n内的输入信号;v(n)为噪声,与 s(n)无关联;d(n)和 e(n)分别为设定值和偏差;e(n)和 x(n)为 BP模块的输入向量;学习步长 μ 为BP网络的输出。因此BP-LMS算法的本质是建立一个BP模型,根据输入向量和偏差寻找最佳步长,在训练过程中需要为它寻找合适的训练样本、输入向量、偏差及学习步长之间的关联,并集成到BP-LMS算法中去。
在BP模型训练完成之后,BP模型的参数代表了输入向量、偏差和最佳学习步长之间的非线性关联。因此BP-LMS算法根据以下方程更新滤波器的参数:
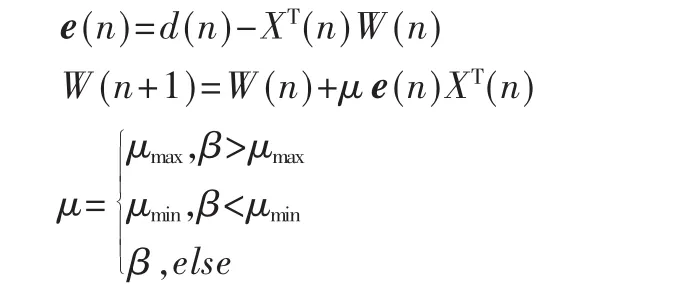
在以上方程列表中,β是在采样时间n中根据输入向量x(n)和偏差e(n)得到的 BP模型的输出。为保证BP-LMS 算 法的收敛,β 必 须<n/λmax(λmax是输入信 号 的最大特征值),且为正数。使用μmin(很小的小数),以确保μ仍然是受变化的误差和输入信号的影响,而β非常接近于零,从而提高了算法的收敛速度。在实际应用中,μmax和 μmin可由实验得出[5]。
神经网络成功地将先验知识导入到LMS算法,保证了滤波器更快地收敛,显示出BP-LMS具备智能控制的能力。
4 BP-LMS算法流程
BP-LMS算法最重要的是建立一个BP神经网络,然后寻找学习样本,并进行训练。由于在工程应用中自适应滤波器的大部分输入信号相似,因此为了避免巨大的训练样本搜集和训练工作量,定义如果自适应滤波器B和A的输入信号类似,A已经具有了一个可控的BP网络,那么这个BP网络可以直接应用于B而不必构建一个新的网络。
D定义成识别两个滤波器的输入信号是否相似的相似因子,欧氏距离公式用于计算相似因子d,即:

式中,x和θ分别表示两个自适应滤波器的特征值,k为输入信号特征值的数量。由于相似性是一个模糊的概念,如d<c,那么这两个输入信号是相似的,其中c定义成相似范围,可通过实验获得。
5 实验结果与分析
为了证实BP-LMS算法的有效性,与其他三种LMS算法同时进行仿真比较。(1)标准LMS算法,其学习步长是一个小的正常数。(2)归一化最小均方差(NLMS)算法,其学习步长由以下方程得出:
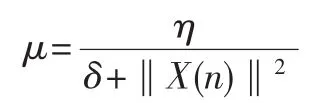
式中,η是自适应常数;δ是正数,它在输入向量比较小的时候保证了NLMS比较小,X(n)是在采样时间n内的输入信号值。(3)可变步长最小均方差(VSS)算法[3],它的学习步长μ(n+1)由以下方程决定:

式中,α 和 γ是 VSS-LMS算法的两个参数,e(n)和 μ(n)是采样时间n内的偏差和学习步长。μmax和μmin的意义与BP-LMS算法中提到的相同。
仿真1:在输入为标准正弦波信号的情况下对四种算法的比较,如图3所示。

图3 仿真1中四种算法的性能表现
该滤波器的阶数定为L=10。
(1)自适应滤波器的初始权重W(n)定义为0。
(2)输入信号s(n)是标准正弦波信号。
(3)加入的噪声 v(n)是一个零均值,方差为 0.04的独立高斯随机序列。
(4)标准 LMS算法的不变学习步长 μ设置为 0.005;NLMS自适应滤波器的参数 η和 δ分别为0.15和 2;VSS-LMS算法的参数 α和 γ设为 0.97和 0.000 8,而μmax和 μmin在该算法中为 0.008和 0.000 1;初始学习步长μ(0)设为 0.003。
(5)平均统计时间为 20,样本容量为 1 000。在 BPLMS自适应滤波器里,首先使用greedy算法为BP模型寻找训练样本,部分训练样本数据如表1所示。
建立一个BP模型,包含11分量的输入向量 (假设自适应滤波器的输入信号是10,偏差是1),25个隐藏单元,然后扫描BP模型的输出以产生最佳的学习步长μ。经过实验, 最佳的 μmax、μmin和相似范围 c被确定为 0.2、0.005和 0.17。

表1 仿真1 BP模型的部分训练样本数据
可以看出,相比其他三种算法,BP-LMS算法可以使得自适应滤波器取得更高的收敛速度。
仿真2:进一步评估BP-LMS算法的性能。在仿真2中,t加入到标准正弦波信号中的噪声增加到0.09,其他的参数与仿真1中相同。
图4显示了仿真2中四种算法的性能表现。

图4 仿真2中四种算法的性能表现
计算相似因子d用以估计仿真1与仿真2的输入信号是否相似。输入信号有两个特征值:一个来自标准正弦波信号,另一个来自高斯白噪声序列。由于标准正弦波信号在这两个仿真里未改变,因此相似因子只被高斯白噪声序列的特征值影响。高斯白噪声序列的方差是作为它的特征值使用的。因此,两个输入信号的相似因子如下:
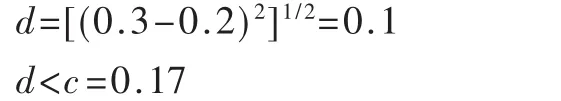
即不需要在仿真2中建立新的BP控制网络,只需要继续使用仿真1即可。可以看出被BP-LMS算法调节的滤波器可以收敛得更加快速,只需要约150个迭代周期。但是VSS-LMS、NLMS和标准LMS算法,至少需要250、300和400个迭代周期来取得类似的效果。
仿真3:四种算法之间的比较,输入信号为高斯白噪声序列:
(1)自适应滤波器的阶数L=5。
(2)自适应滤波器的权重定义为 W (n)=[0.25,0.75,1,0.75,0.25]T。
(3)输入信号 s(n)是零均值,方差 σ2=1的高斯白噪声随机序列。
(4)加入的噪声 v(n)是一个零均值,方差为 0.01的独立高斯随机序列。
(5)标准 LMS算法的不变学习步长 μ设置为 0.005,NLMS自适应滤波器的两个参数η和δ分别为0.15和2。VSS-LMS算法的参数 α和 γ设为 0.97和 0.000 8。μmax和 μmin在算法中分别为 0.05和 0.000 5,初始学习步长 μ(0)设为 0.005。
(6)平均统计时间为 200,样本容量为 1 000。
和仿真1相同,首先使用greedy算法为BP模型寻找训练样本,部分训练样本数据如表2所示。
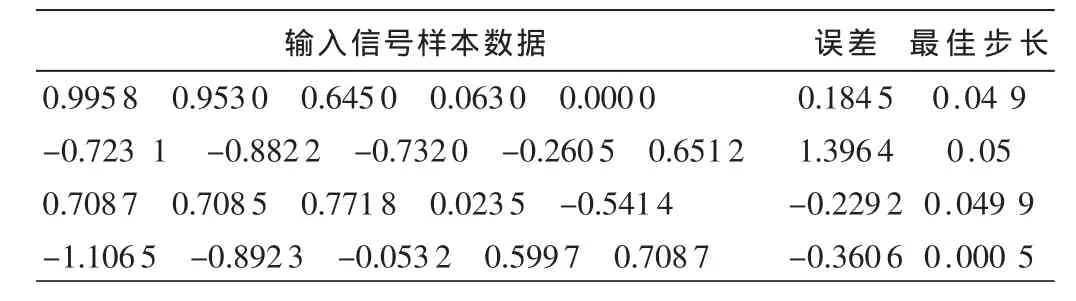
表2 仿真3BP模型的部分训练样本数据
建立一个BP模型,包含6分量的输入向量(假设自适应滤波器的输入信号是5,偏差是1),15个隐藏单元,然后扫描BP模型的输出以产生最佳的学习步长μ。经过实验, 最佳的 μmax、μmin和相似范围 c被确定为 0.05、0.000 5和0.22。
仿真 4:输入信号 s(n)是零均值,方差 σ2=1.21的高斯白噪声随机序列,加入的噪声v(n)是一个零均值,方差σ2=0.04的独立高斯随机序列。其他参数与仿真3相同。
因此相似因子d在仿真3和仿真4均为:

因此,在仿真3应用的控制BP神经网络同样可以用在仿真4。
图5和图6分别列出了在仿真3和仿真4中四种算法的性能,可以从两组图示中获知该噪声功率的BPLMS算法具有稳定的错误调整系统,且比其他三种算法收敛速度都快。
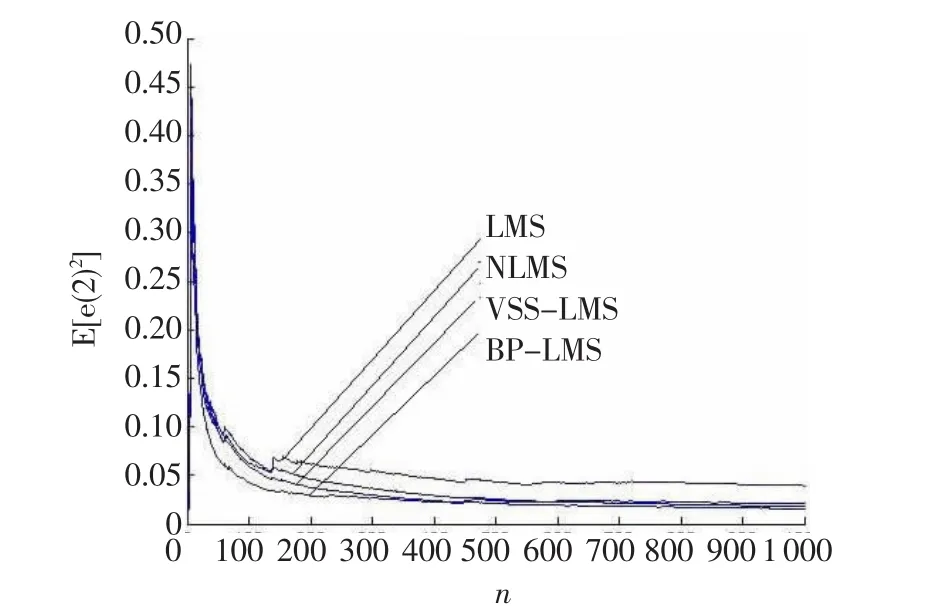
图5 仿真3中四种算法的性能表现
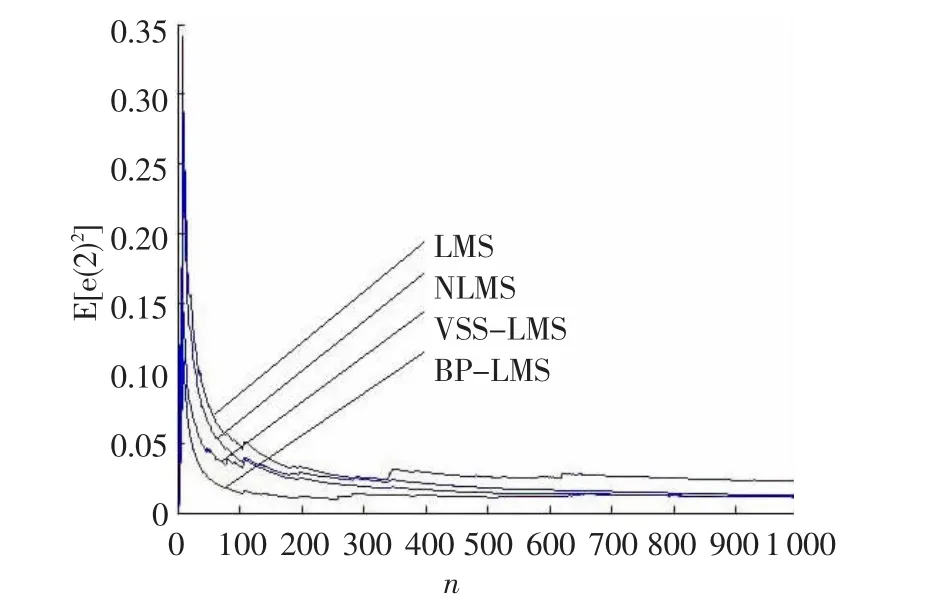
图6 仿真 4中四种算法的性能表现
四个模拟实验结果都说明了BP-LMS算法的功效,及其合理性。
自适应滤波算法是信号处理的重要基础,在各个领域已取得了广泛的应用。本文提出了BP-LMS算法采用一种新的自适应步长控制技术,新算法中其学习的步骤通过BP神经网络控制,可用于具有自适应滤波应用的理想功能,并得以明显体现。同时模拟实验结果证明了BP-LMS算法的优势特征,可改进保持小错不同环境条件下的调整收敛速度,从而使算法的性能得到了改善。
[1]SIMON H K.Adaptive filter theory[M].Fourth Edition,Prentice Hall,2001.
[2]KWONG R,JOHNSTON E W.A Variable step size LMS algorithm[J].IEEE Trans.On Signal Process., 1992,40(7):1633-1642.
[3]ABOULNASR T,MAYYAS K.A robust variable step size LMS-type algorithm: analysis and simulations[J], IEEE Signal Process., 1997,45(3):631-639.
[4]GAO Y,XIE SH.L.A variable step size LMS adaptive filtering algorithm and its analysis[J], Acta.Electronica Sinica, 2001,(29):1094-1097.
[5]QIN J F, ZH J, YANG O.A new variable step size adaptive filtering algorithm [J], Data Collecting and Processing, 1997,12(3):171-194.
[6]ROJAS R.Neural Networks-A Systematic Introduction[M].1996.
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
中国惯性技术学报(2020年2期)2020-07-24
科技创新与应用(2020年6期)2020-02-29
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
系统工程与电子技术(2016年7期)2016-08-21
北京航空航天大学学报(2016年12期)2016-02-27
