
数据库复杂网络构造算法及特征分析
2012-07-25 03:38李春芳刘连忠刘振国
电子与信息学报 2012年11期
李春芳 刘连忠 刘振国
①(北京航空航天大学自动化科学与电气工程学院 北京 100191)
②(北京航空航天大学计算机学院 北京 100191)
③(河北体育学院网络中心 石家庄 050041)
1 引言
数据库是各类管理信息系统(Management Information System, MIS)的数据核心。随着软件规模扩大,数据库的规模和关联复杂性相应增加。软件网络是软件复杂系统的骨架,而数据库复杂网络是业务系统内部关联性的骨架。在顶层设计中,主要是将业务内部的关联性映射为数据表之间的关联性,尽管业务系统的功能不可能全部在数据库设计中实现,但是显而易见,优化的数据库关联设计,能尽可能多地覆盖业务逻辑,减少系统实现的复杂性和代码量。由于在数据表的基本字段确定后,非主键和非外键字段的添加和删除,不会影响其他的关联性,因此通过主键和外键建立数据表之间的复杂网络,作为对MIS系统宏观层面的描述是合理的。
从文献看,复杂网络的解释为,从实际复杂系统抽取的网络结构,具有明显的“无标度”和“小世界”特性,其网络特征介于随机网络和规则网络之间,即不是完全随机,也不完全规则。软件是一类人工复杂系统,复杂网络理论引入软件工程来描述和度量软件的复杂性,形成了软件网络[1]。软件网络主要探索了软件包级[2]、类级[3-6]、方法级[4-6]的网络构造和统计特征,以及软件的动态运行环境网络[7],从复杂网络角度探索了软件的宏观结构和软件度量[8,9]以及软件网络的应用[10-12],然而对软件网络的分支数据库复杂网络的研究较少。何克清等认为软件网络没有被准确定义,泛指从软件系统中抽取的网络结构,该结构具有复杂网络的特征[1]。以数据库中表作为节点,将外键到主键形成的参照依赖作为有向边,MIS系统的数据库可以建模成一个有向图,本文发现该结构也具有“小世界”和“无标度”特征,可以认为,数据库复杂网络是软件网络的一个分支,笼统指从数据库中抽取的网络结构,研究数据层关联形成的网络统计特性。
早在 1983年,文献[13]利用超图(hyper networks)超网络来描述数据库,其节点是一个数据模式的所有数据表的字段集合,一个数据表定义为一个超边(hyper edge),它能连接多于两个节点。由于超图的可视化信息不便于直观理解,远不如复杂网络描述数据库内部关联更直接。
尽管一个MIS系统的数据库网络可能仅有几十到上千的节点,但是其关联复杂性足以让软件开发人员难以应对,需要 CASE(Computer Aided Software Engineering)工具辅助描述其复杂性。CASE工具,如 Rational Rose, PowerDesigner,Microsoft Visio, Visual Paradigm等均采用了数据库关系图描述数据表间的关联,但是其抽象粒度不够,开发人员无法看到数据库网络更宏观的视图,难以驾驭大型系统的数据库设计。数据库关系图没有从复杂网络的角度统计其网络结构特性,本文从更抽象的复杂网络的角度研究MIS系统数据模式的关联,以更加“骨感”的形式来描述和度量数据层的复杂性,使软件开发人员能掌控数据关联的概貌。
2 形式化表示
数据库完整性指数据的正确性和相容性,完整性包括域、实体、参照和用户定义完整性,其完整性设计就是约束设计。在大型MIS系统设计中,参照完整性是核心,它集中体现了业务逻辑,也是软件设计复杂性的根源之一,本文将数据表间的参照完整性建模为复杂网络,以更简洁的方式描述其复杂关联性。完整性约束可以通过数据库管理系统(DataBase Management System, DBMS)或应用程序实现,通过DBMS实现的参照完整性即主外键关联,而由应用软件实现的参照完整性本文定义为语义隐性关联,简称语义关联,它隐含表示了数据表主外键之间的参照关系。
大量的开发经验表明,外键关联和语义关联各有优势,表1列出了两种关联的比较,在本文分析的9个数据模式中,4个采用了外键,5个采用了隐性语义关联。外键关联采用数据库集中管理数据关系,在海量数据查询情况下跨表查询性能比语义关联差。由于DBMS能自动维护数据的完整性,因此在故障发生时,能够保证数据的一致性,而语义关联可能会引入不一致数据。在开发阶段,由于系统的不完备性,外键会羁绊代码实现,而语义关联需要增加代码来维护参照引用数据的一致性。CASE工具支持外键关联和部分语义关联的图结构分析。

表1 外键关联和语义关联比较
大部分的DBMS系统和逆向工程工具都采用了数据库关系图,其节点是数据表结构信息,边是外键到主键的关联依赖,因此在数据库复杂网络构造上用数据表作为节点,外键关系作为边是合理的。在已有的数据库关系图中,节点信息复杂,然而对复杂性起关键作用的是主键和外键,其他非主键和非外键字段的添加和删除对关联复杂性没有影响,因此进一步化简节点是可能的。
数据库复杂网络(DataBase Complex Networks,DBCN)G={V,E} 是从数据库模式中抽取的有向网络模型,V={v1,v2,…,vn}是节点集,代表数据库模式中的数据表,E={(vi,vj)|i,j=1,2,…,n} 是有向边集合,代表一个数据表外键(或隐含外键)到其它数据表主键的依赖。
基于复杂网络的统计参数[1],定义如下特征参数:
(1)节点数N:数据表个数;
(2)边数E;
(3)平均最小路径长度L;
(4)平均聚类系数C;
(5)平均出度/入度Di/Do;
(6)节点对可达率R:定义为有向网络上任意不同的两个节点之间存在的可达路径总数除以N×(N-1),R是对内部关联紧密程度的一种度量,网络内聚度越高,R越大,如果系统内部存在级联删除和级联更新,在数据库内部传递的可能性越大;
(7)网络连接率S:定义为最大连通图上的节点数除以总节点数。
在DBCN上,节点的入边是其它数据表的外键(或隐含外键)字段到该数据表主键的引用,节点的出边是该数据表的外键(或隐性外键)到其它数据表主键的引用。数据库主键和字段的关系是一对多的关系,主键可能是一个字段,或者多个字段,即联合主键,绝大多数是一个字段,在联合主键情况下每个独立字段都是外键,即到其他表主键的引用。因此入边都是对节点主键的引用,而出边是对其他节点主键的引用。
由于一个数据表中可能有多于一个字段引用其它表的同一个主键字段,因此DBCN是一个可能包含重边的有向图,在以下的构造算法中去掉了重边,只考虑简单有向图构造的网络。
3 构造算法
3.1 基于主外键的构造算法
本节研究了基于复杂网络的数据库关联分析技术,实现对Oracle, MySQL, SQLServer数据库中表的元数据的关联分析。针对基于数据库主外键的关联和无外键的语义隐性关联提出了两种网络构造算法。
算法1基于主外键的构造算法(FK-DBCN)(1)查询系统表读取一个数据模式下的所有数据表名称,作为网络节点信息;
(2)查询系统约束表,读取数据模式的所有外键约束,作为从一个数据表节点(外键)到参照表节点(主键)的有向边信息。
用算法 1构造了非开源软件学校管理系统Yundl的数据库网络,其DBMS为SQLServer,它采用了外键实现参照完整性约束,显示度排名前三位的节点是 tbStudentBasis, tbTeacherBasis和tbYearBasis,反映该系统中所有的关系中最重要的是学生、教师在学年中的各种关系,这种直接宏观的业务逻辑表示对于变更的开发团队、软件的二次开发以及更新维护非常重要,可以缩短增量开发时间。
3.2 基于语义关联的构造算法
由于DBCN内部关联的复杂性,很多的软件开发实践表明,业务的主、外键关联往往通过程序内部映射实现,而不采用DBMS本身的完整性约束,从而避开某些关联控制的难题。实际上,无论在软件的设计还是实现上,关联引起的复杂性无法回避。开源软件网络与主机监控系统 Zabbix的数据库关联采用了 MySQL数据库,内部无外键约束。从对Zabbix的分析中发现,尽管没有主外键,但是从规范的数据表字段命名规则可以推理语义隐性关联,进而推理出关联关系,而CASE工具PowerDesigner也采用这种语义推理。例如:在Zabbix数据库中有两个数据表History和Items,其中History有3个非主键的字段itemid, clock和value,在Items数据表中仅有一个主键itemid,那么可以推出表History到表Items有一个隐性外键关联。根据数据表的字段命名规则推理出外键约束,进而构造DBCN的有向边,这种推理一般近似正确,主要取决于隐性主外键的命名规则。根据语义隐性关联设计了算法2。
算法2基于语义隐性关联的DBCN构造算法(HFK-DBCN)
(1)查询一个数据模式的所有数据表名称,作为网络节点信息,节点数为n;
(2)查询每个数据表节点 Nodei(i=1,2,…,n)的非主键字段个数fc和名称FFields[1,2,…,fc];
(3)查询每个数据表节点 Nodej(j=1,2,…,n,且j≠i)所有主键字段个数pc和名称 PFields[1,2,…,pc];
(4)如果 FFields[1,2,…,fc]的某个字段等于PFields[1,2,…,pc]中某个字段,则添加一条从节点i到节点j的边。
针对语义关联下,通过算法 2仍不能构造DBCN的情况,提出了HFK-DBCN+算法。以开源课程管理系统 Moodle为例,其中所有表的主键均采用id命名,通过HFK-DBCN检索不到任何边信息,但是在大量的引用表中采用了“数据表名称”+“id”方式引用主键表中的字段,例如在mdl_user表中主键为 id,而在引用表 mdl_course_display等多个数据表中均使用userid隐性关联。
算法2+扩展的语义隐性关联的数据库复杂网络构造算法(HFK-DBCN+)
(1)查询一个数据模式的所有数据表名称,作为网络节点信息,节点数为n;
(2)查询每个数据表节点 Nodei(i=1,2,…,n)的非主键字段个数fc和名称FFields[1,2,…,fc];
(3)查询每个数据表节点 Nodej(j=1,2,…,n,且j≠i)所有主键字段个数pc和名称PFields[1,2,…,pc],增加其扩展的可能主键字段名 PFields[pc+1,…,pc+e];
(4)如果 FFields[1,2,…,fc]的某个字段等于PFields[1,…,pc+e]中某个字段,则添加从节点i到节点j的一条边。
在Moodle中,所有数据表名以前缀“mdl_”开始,去掉前缀后,人工分析后增加了4项可能匹配的主键字段名,4条规则如下:取出表示数据表的名字,例如表 mdl_course中原仅有一个主键“id”,增加了“course”;取出表示数据表的名字,直接加“id”,例如表mdl_user中原仅有一个主键“id”,增加了“userid”;取出表示数据表的名字,去掉“s”后加“id”,例如表mdl_external_services中原仅有一个主键“id”,增加了“externalserviceid”;取出表示数据表的名字,去掉“ies”直接加“yid”,例如表 mdl_glossary_entries中原仅有一个主键“id”,增加了“glossaryentryid”。
需要指出的是,由于字段名命名的随意性,通过算法2和算法2+构造的DBCN是近似正确的,而在 CASE工具中不支持 HFK-DBCN+类型的数据模式图结构分析。
3.3 语义隐性关联下确定性DBCN构造的数据表字段命名规范
为准确构造语义隐性关联的DBCN,在数据库设计中,需要满足以下条件:
(1)主键使用表名 TableName,或者表名的子串,并拼接“id”,描述为 subString(TableName).concat(“id”)。
(2)所有对主键引用的外键字段,采用与所引用的主键同名字段标识。
基于以上规范,不仅基于算法2能构造准确的DBCN,也支持使用CASE工具的语义推理。
4 实验与分析
4.1 实验数据
本节实现了一个数据库复杂网络分析工具(DBCN Tool),其系统结构如图1所示,通过JDBC连接各种数据库管理系统,提供用户名、密码和连接数据源信息,构造一个以 Pajek(Pajek是一个成熟的社会网络分析工具)格式存储的DBCN,网络结构可以通过Pajek软件分析,或在DBCN Tool中进行可视化分析,其可视化部分采用了网络分析的Java API 开发包JUNG。

图1 数据库复杂网络分析工具的系统结构
在数据库复杂网络中,由于数据表作为节点,网络分析的粒度较大,一般节点数在几十到几百、甚至上千个数量级,可视化的意义远大于参数分析。与 PowerDesigner提供的图结构关系表示不同,DBCN弱化了节点信息,将数据表视为一个节点,不考虑其内部的字段数和名称,凸显了节点间的参照引用关系。
实验抽取了9个中大型MIS系统的DBCN,其数据基本信息如表2,其中2个非开源系统,7个开源系统;1个Oracle, 2个SQLServer, 6个MySQL数据模式。
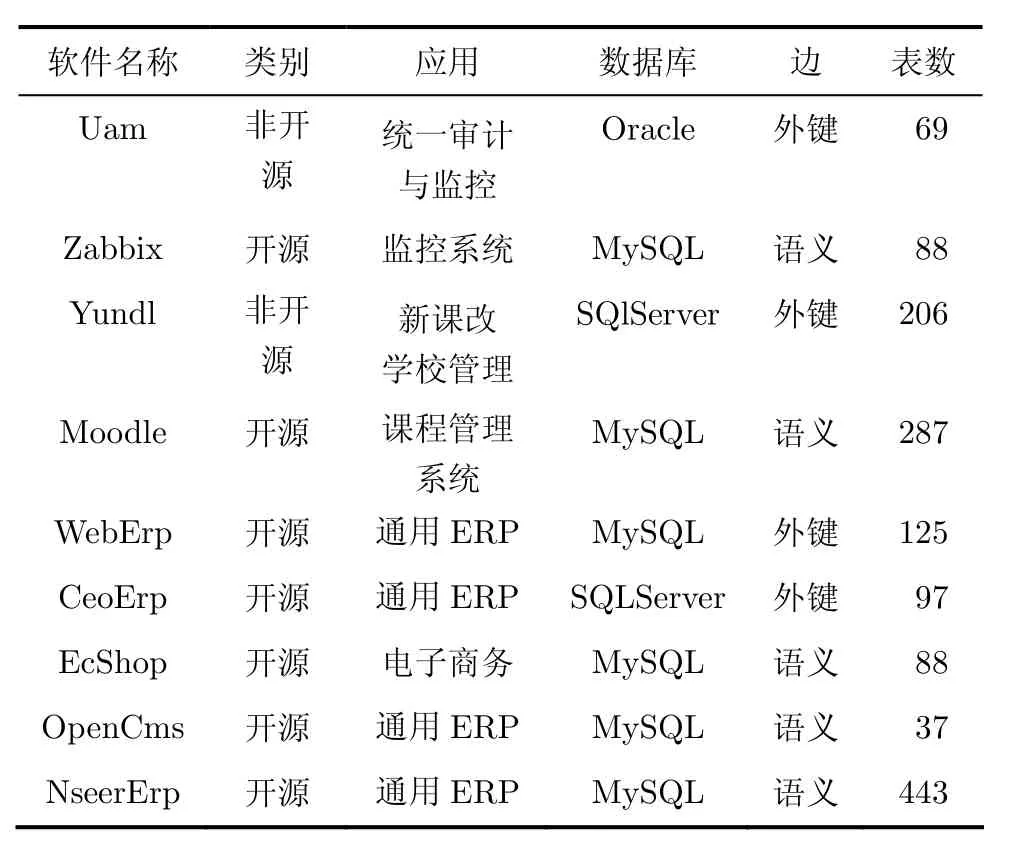
表2 实验数据基本信息
4.2 网络参数
9个MIS系统的DBCN统计参数如表3所示,其节点和边的数量级接近,与随机网络相比可达节点之间的平均长度L较小,1<L<3;聚类系数C较大;平均入度和出度Di/Do较小,0<Di<3;可达节点对比例R较小,它反映级联更新和级联删除的传播能力;网络连通性参数S较大,反映数据表孤立节点数较少,大部分数据表与其他数据表有参照引用关联。
作为一个反例,笔者一直犹豫将对开源系统NseerErp的分析写进来,该系统拥有443个数据表,它采用隐性语义关联,由于数据表和字段命名的随意性,通过算法 2和算法 2+都无法获得其真实的DBCN。鉴于NseerErp在所讨论的9个系统中规模最大,DBCN在大型系统的作用非常明显,讨论该系统的数据表和字段命名格式非常必要。由于NseerErp所有数据表的第1个字段名为主键且名称均为“id”,其可能真正的主键没有被定义为主键,如crm_order表中主键为系统自增量“id”,其后跟一个非主键“order_id”,在 crm_order_details,crm_discussion等多个表中也存在“order_id”,因此有理由认为这些“order_id”,参照引用表crm_order中的“order_id”字段。由于crm_order的order_id在数据库中没有被定义为主键,尝试根据表名提取关键字,构造可能的主键,即 crm_id,order_id,而由 crm_order_details构造可能的主键也包含crm_id, order_id和details_id,无法确定哪个表中的order_id是主键,进一步以最短数据表名确定其中一个为主键,按照以上规则进一步筛选,其DBCN参数见表3,可以断定该网络具有不确定性,近似真实地反映系统的数据表关系,由于字段命名的不规范,可能存在遗漏和虚假的边。如果系统采用 3.3节的命名规范,满足外键字段和相关联的主键字段同名,则容易构造确定性的DBCN,为软件的理解和增量设计提供直观的关系视图。
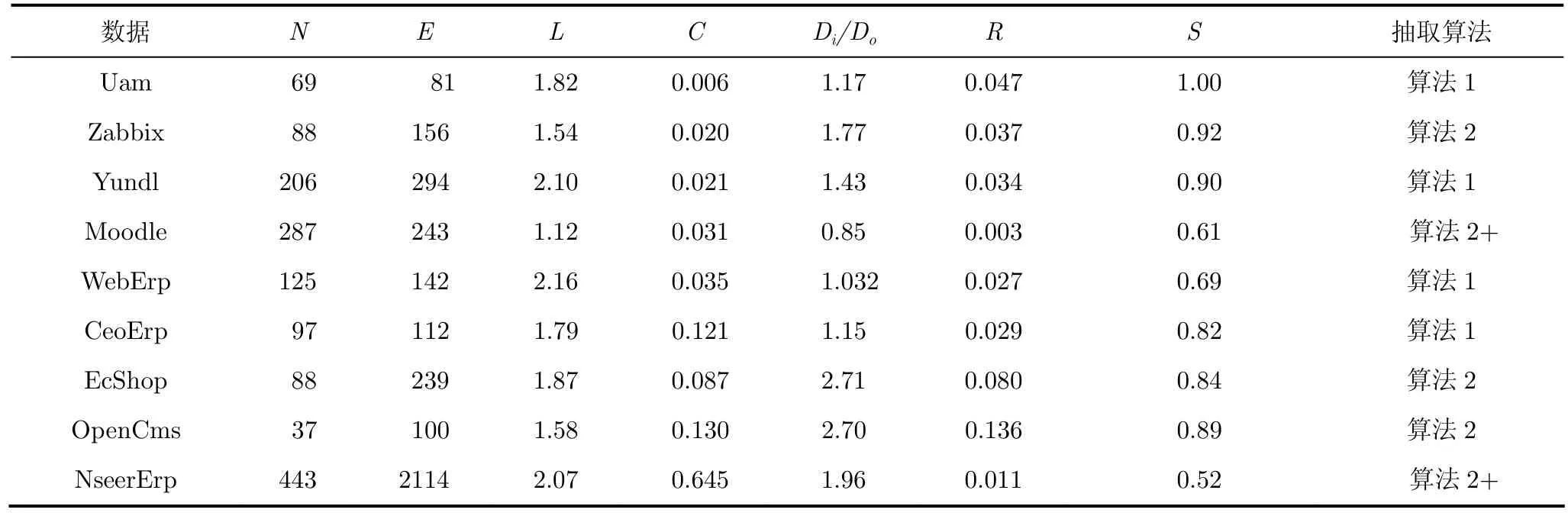
表3 DBCN统计参数
4.3 距离分布和度分布
图2所示为6种DBCN的节点距离的概率分布,从确定性的主外键DBCN实例 CeoErp, Yundl和WebErp可以看出,密度最大的距离都为2,即存在传递一次的关联关系最多,最长的传递距离分别是4, 5和5,它表示操作一个数据表在级联更新和级联删除时影响其他数据表的深度。
图3分析了Yundl, EcShop, WebErp和CeoErp中每个节点的出入度,对入度按照降序排序,发现入度分布离散,出度分布比较均匀,例如在 Yundl中节点tbStudentBase入度达到33, EcShop的节点ecs_group_goods入度为 24, WebErp的节点stockmaster入度为18, CeoErp中节点tCustomer的入度为13。
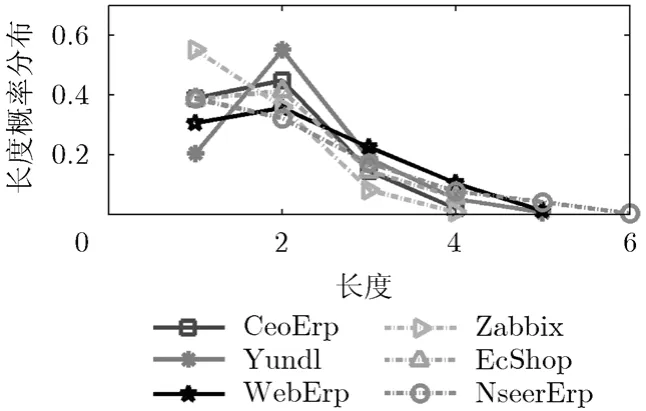
图2 6种DBCN的节点距离分布
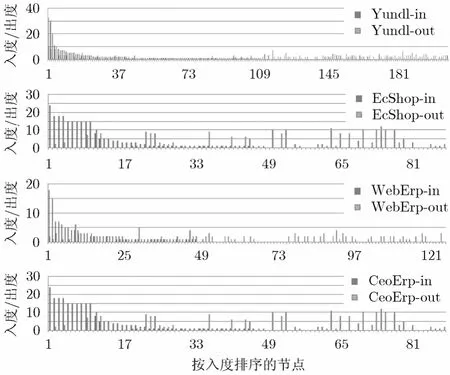
图3 4种DBCN的各节点出入度
图4(a)所示为4种DBCN的入度和出度的概率分布散点图,图4(b)为在双对数坐标下近似拟合的直线,发现DBCN网络具有比较明显的无标度特征。以Yundl为例,数据表中47%的节点入度为0,有43%的节点出度为0,网络结构不均匀,少数节点有较大的度,大量节点具有较小的度。
4.4 核网络特性
一个图的k-核指反复去掉度小于或等于k的节点后,所剩余的子图。一个节点存在于k-核网络,而在(k+1)-核中被移除,那么节点的核数为k,核数表明节点在核中的深度,也表明在网络传递关系上,节点的复杂程度。Yundl-DBCN是基于主外键的DBCN,其网络结构准确,它是一个 3-核网络。其中 0-核即网络全集,节点数较多,不易区分重要节点,难以观察到网络核心层。在3-核网络上,迭代删除了度为0,度为1和度为2的节点,节点数由初始的206个减少到35个,从网络上能直观获得其骨干和深层的关联信息。软件工程过程使用DBCN的核网络可视化数据层的关联,能降低分析设计的难度。
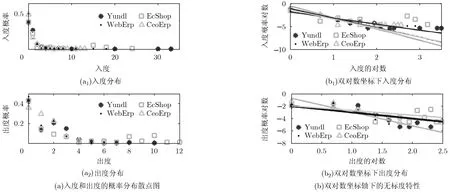
图4 4种DBCN的节点度分布概率
在逐次构造的核网络上,其参数,即以节点数表示的网络规模,网络聚类系数,平均长度和网络密度的变化随k-核网络变化分别如图 5(a)-5(d)所示,随着k-核的增大,网络节点数下降,在最大核网络上,从确定性的主外键DBCN的实例CeoErp,Yundl和WebErp看,网络规模下降到0.2倍以下,DBCN的核在3或4之间,而带有不确定性的隐性语义关联的 DBCN实例 Zabbix, EcShop和NseerErp,从图上可以推测,构造算法可能引入了实际不存在的关联,网络的统计特性异常。聚类系数随k-核的增大变化不确定。网络平均长度随着k-核的增大在减少。网络密度表示网络节点间实际存在的边数和可以存在的边数比,其随k-核的增大而增大,表明高核网络上节点之间边多,关联紧密, 反映出用高核网络分析网络的骨干和深层关联是合理的。
5 结束语
本文提出了数据库复杂网络的概念,其工程意义在于为管理信息系统提供了一种规模度量,为软件的数据库设计提供一种新的辅助工具,研究了常用数据库管理系统的主外键关联和语义隐性关联形成的复杂网络构造算法,并分析了网络的统计特性。在大型的 MIS系统中,或者企业内部的多个 MIS系统关联形成的数据中心,DBCN的工程意义更加明显,可以化简数据层的复杂性。数据库复杂网络表示了数据库关联图的统计特性,其节点(数据表)在网络上的重要性是不同的,少量的节点之间蕴含了大多数的业务逻辑关系。此外,数据库复杂网络视图也为软件开发文档的数据库描述提供了一种新的形式,是一种自说明的文档,使得在软件版本变更、增量设计以及开发人员变动情况下,尤其在开源软件的二次开发中,能快速理解数据库内部的关联,从而理解业务逻辑关系,缩短开发时间。鉴于构造基于隐性语义关联的数据库复杂网络具有不确定性,提出了按照外键字段名与参照引用主键同名的原则来规范命名数据字段,能支持构造准确的网络结构,辅助于软件开发人员对系统逻辑的理解。
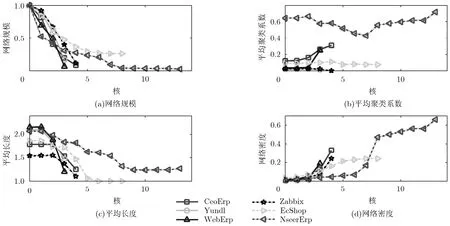
图5 不同核深度下6种DBCN网络参数比较
[1]何克清, 马于涛, 刘婧, 等. 软件网络[M]. 北京: 科学出版社,2008: 5-37.
He Ke-qing, Ma Yu-tao, Liu Jing,et al.. Software Networks[M]. Beijing: Science Press, 2008: 5-37.
[2]LaBelle N and Wallingford E. Inter-package dependency networks in open-source software[OL]. http://arxiv. org/abs/cs/0411096, 2011, 2.
[3]Myers C R. Software systems as complex networks: structure,function, and evolvability of software collaboration graphs[J].Physical Review E, 2003, 68(4): 046116.
[4]Pan Wei-feng, Li Bing, and Ma Yu-tao. Multi-granularity evolution analysis of software using complex network theory[J].Journal of Systems Science and Complexity, 2011,24(6): 1068-1082.
[5]韩言妮, 李德毅, 陈桂生. 软件多粒度拓扑特性分析及其应用[J]. 计算机学报, 2009, 32(9): 1711-1721.
Han Yan-ni, Li De-yi, and Chen Gui-sheng. Analysis on the topological properties of software network at different levels of granularity and its application[J].Chinese Journal of Computers, 2009, 32(9): 1711-1721.
[6]王红春. 网络化软件多粒度动态特性分析[D]. [博士论文], 武汉大学, 2010.
Wang Hong-chun. Multi-granularity dynamic characteristic analysis of networked software[D]. [Ph.D. dissertation],Wuhan University, 2010.
[7]Cai K Y and Yin B B. Software execution processes as an evolving complex network[J].Information Sciences, 2009,179(12): 1903-1928.
[8]Li Huan and Li Bing. A pair of coupling metrics for software networks[J].Journal of Systems Science and Complexity,2011, 24(1): 51-60.
[9]Ma Y T, He K Q, Li B,et al..A hybrid set of complexity metrics for large-scale object-oriented software systems[J].Journal of Computer Science and Technology, 2010, 25(6):1184-1201.
[10]Ma Yu-tao, Liu Yu-chao, Zhang Hai-su,et al.. A hybrid method for prioritizing software requirements in terms of use cases[J].Journal of Convergence Information Technology,2012, 7(5): 17-27.
[11]Li C F, Liu L Z, and Li X Y. Software networks of java class and application in fault localization[C]. Proceedings of ISDEA, Sanya, China, January 7-8, 2012: 1117-1120.
[12]马于涛, 何克清, 李兵, 等. 网络化软件的复杂网络特性实证[J]. 软件学报, 2011, 22(3): 381-407.
Ma Yu-tao, He Ke-qing, Li Bing,et al.. Empirical study on the characteristics of complex networks in networked software[J].Journal of Software, 2011, 22(3): 381-407.
[13]Fagin R. Degree of acyclicity for hypergraphs and relational database schemes[J].Journal of the Association for Computing Maceinery, 1983, 33(3): 514-550.
猜你喜欢
无线互联科技(2022年15期)2022-11-03
新世纪智能(数学备考)(2021年9期)2021-11-24
党员生活·下(2020年3期)2020-04-20
党员生活(2020年2期)2020-04-17
教育界·中旬(2019年7期)2019-11-24
当代陕西(2019年15期)2019-09-02
铁道通信信号(2018年10期)2018-12-06
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
中国石油企业(2014年4期)2014-11-30
