
区域性多机构海洋预报产品集成的初步研究
2013-10-20 06:43李璟,吴萍
海洋信息技术与应用 2013年1期
李 璟 , 吴 萍
(1.中国海洋大学 青岛 266100;2.国家海洋局东海预报中心 上海 200081)
随着海洋经济的高速发展,各级部门、各涉海行业以及社会公众对预报服务质量越发重视。区域范围内海洋预报质量评估是提升各机构的预警报能力和服务水平的有效途径,同时还有助于预报减灾部门有效管理预报服务质量,对防灾减灾具有积极的意义。
海洋预报质量评估最直接的方法是将海洋预报数据与海洋观测实况数据进行比较。海洋观测数据来源广泛,如岸基站、浮标、雷达等。随着通讯技术的发展和数据处理技术的广泛应用,实况观测数据通过传输和处理后实时录入到数据库中,为预报和实况数据的比对提供及时有效的数据。但如何集中、有效地获取区域内各预报机构的海洋预报产品是当前亟待解决的问题。
本文旨在通过分析区域内各机构海洋预报产品的数据源和提供方式,采用数据同步、Web service和数据抓取3种方式获取预报产品,经抽取和清洗等处理后将预报区域、预报要素、预报值、预报时效等信息录入数据库中,为预报质量评估提供数据。
1 研究对象分析
本研究的对象为东海区7家预报机构在网站上发布的海洋预报产品。从各预报产品涉及的要素以及是否有符合比对条件的实况资料两方面进行分析。例如:预报产品有预报要素(如水温),但可供对比的测点的实况数据里没有该要素或是数据的连续性较差,无法进行比对,因此,不选取该产品的此项要素作为提取对象。同时,综合考虑预报产品多要素提取的复杂性,此次研究仅选取浪高作为提取对象,由此确定从各机构提取的预报产品的预报区域和预报时效如表1所示。

表1 预报产品提取列表
综合表1分析结果,本次研究提取的对象符合下述条件:预报区域为各机构辖区内1个以上的预报区域,预报要素为浪高,预报时效为24 h。
2 研究方法
根据确定的研究对象,分析其所在网站发布预报产品的数据来源和提供方式,从而得出数据提取的方法。
通常情况下,网站发布数据的来源主要有两类:(1)后台有数据库服务,发布页面直接从数据库读取数据并显示在页面上;(2)后台通过对指定文件内容进行解析并在页面发布所得的预报数据,或是通过页面编辑器直接将数据写入页面相应位置实现预报发布。
对于通过数据库发布预报产品的,如果开放数据库或是提供Web service接口,则可根据访问说明文档,直接读取数据并写入本地数据库。对于通过文档上传或网页编辑器方式发布预报产品的,由于后台不具备数据库,无法通过直接访问的方式获取数据。因此,需要研究其他的数据提取方法,能够既不增加预报机构工作量同时又不影响预报发布。数据抓取在数据提取方面是一种常见的方法,技术也较为成熟,不需要发布端提供额外的数据服务,可以有效地解决如何从无数据库的页面获取数据的问题。
综上所述,结合数据来源和技术实现两方面因素,本研究采用数据同步、Web service、数据抓取3种方式,分别针对提供数据库开放、提供数据接口和上述两者均不提供的3种情况,实现提取预报产品中的预报要素值。各机构预报产品的数据来源和本次研究的数据获取方式如表2所示。

表2 预报产品的数据来源和获取方式列表
3 实现过程
本研究通过搭建一个预报产品集成系统(包含一组程序和服务以及一个集成数据库)实现预报数据的自动化提取和入库,如图1所示。其中,程序和服务用于实现数据的同步、访问、抓取以及录入动作的周期性和自动化;数据库则接收和存储经由程序处理过的各类数据。

3.1 集成数据库
本研究采用主流的关系型数据库管理系统Microsoft SQL Server搭建数据库,用于存储各机构的预报数据。数据库主要包含两张数据表:基础信息表和预报信息表。前者用于存储各机构预报产品的基本信息,关键字段包括:基础信息编号、预报机构名称、预报名称、预报区域、预报要素、预报时效。后者用于存储通过程序提取的所有预报数据,关键字段包括:记录编号、预报产品编号、发布时间、预报值。两者通过基础信息表的基础信息编号进行关联,如图2所示。
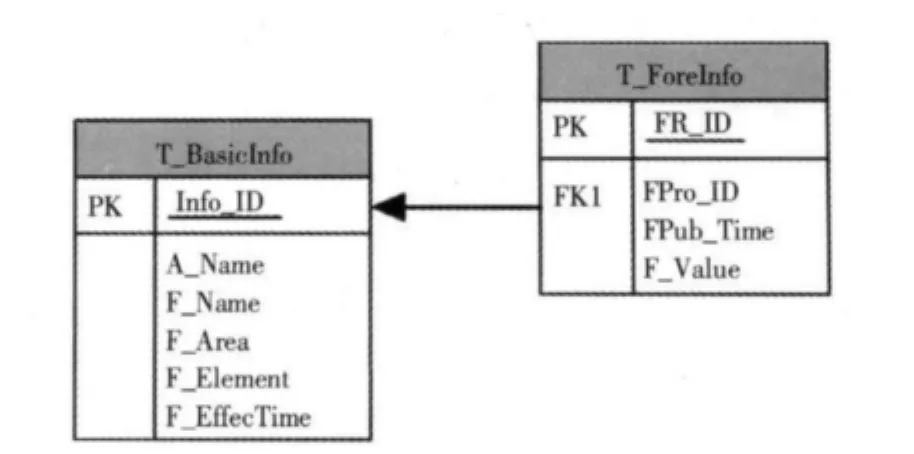
图2 预报产品集成数据库示意图
3.2 数据提取程序
根据各机构提供预报数据的方式,本研究采用数据同步、Web service、数据抓取3种方式,分别开发数据提取和入库程序,并通过建立对应的Windows服务进行周期性运行,实现自动化和长期化的效果。
3.2.1 数据同步方式
根据对厦门预报机构网站发布的预报产品的数据来源进行分析可知,其后台具备数据库,并且开放数据库访问,因而采取数据同步的方式就可提取所需预报数据,过程如下:
1) 根据源数据库和目标数据库的地址、用户名、密码、数据库名分别建立与两者的连接。
2) 使用SQL语句从源数据库表中查询得出预报日期、发布时间、预报时效、预报区域、要素值的数据集。
3) 根据数据集中的预报时效、预报区域连同预报机构在目标数据库中的基础信息表得出预报产品编号,连同数据集中的发布时间和要素值写入预报信息表。
程序采用的是ADO.NET实现数据库读、写操作编程。
3.2.2 Web service方式
根据对福建和温州两家预报机构网站发布的预报产品的数据来源进行分析可知,两者均具备数据库基础,且均提供Web service接口。因此,可以通过采用Web service方式,分别访问两个机构的数据接口提取到的所需预报数据。
Web service技术目前已广泛地应用于各类信息系统开发的数据集成环节。Web service是一个可编程的Web应用程序,直观地表现为向外部提供出一个可以被调用的API[1]。Web service的协议、接口和注册服务可以使用松散耦合的方式协调工作[2]。服务描述自身接口的特性、参数、数据类型等但对于服务用户而言,隐藏了实现服务的细节[2],便于程序语言、中间层组件或平台的整合[3]。因此,Web service的实现和其所需的软硬件平台以及编写服务所用的编程语言是相对独立的。
由于本研究涉及的网站的开发语言、数据库环境不尽相同,因此,在确定数据获取方式时需要考虑如何规避由于网站异构造成的复杂性。Web service的应用程序具有松散耦合的特性[4],支持跨平台和跨语言。同时,该技术具有很好的封装性、集成性,传输透明,框架稳定,且发展也比较成熟。因此,采用Web service方式既可以稳定地从福建和温州发布的数据服务中获取到预报产品,又能够规避由于网站异构造成的复杂性。
通过Web service方式提取产品的实现过程包括:根据两家机构提供的接口说明文档对访问方法的描述,编写程序实现预报数据集提取和对原始数据进行抽取、清理、转换后写入本地数据库,流程如3所示。

图3 Web Service方式提取数据流程图
上述过程主要包括4个步骤:
1)获取原始数据集:创建访问Web service接口的实例,通过循环得到某预报单的包含所有预报区域的数据集。
2)筛选数据集:在原始数据集范围内通过匹配预报区域关键字,提取目标区域的数据子集。
3)解析数据集:依次将预报区域、预报时间、预报时效、预报要素值、预报单信息等值绑定到实体并追加入目标数据集。其中预报要素值提取时需要使用正规表达式将要素数值从数据子集中解析出来。
4)写入数据库:将目标数据集写入本地数据库的预报信息表内。
3.2.3 数据抓取方式
根据对浙江、江苏、闽东、宁波4家预报机构网站发布的预报产品的数据来源进行分析可知,其发布后台均不具备数据库。对于上述4家机构采用的数据获取方式需综合考虑对预报工作量和数据安全两方面的影响。本研究采用的数据抓取技术可以解决此类问题。
数据抓取是搜索引擎常用的一种技术,可以智能地从网络资源上提取可用的数据[6],为从海量的互联网数据中获取有用信息提供了一种便捷的途径。数据抓取程序的基本原理是分析网页的内容和属性,并建立一个内容索引用于提供搜索查询服务。程序运行过程中,逐一对网页分析文档内容进行信息抽取的同时,将发现的新链接归入待分析队列中,迭代遍历预设范围内的所有页面[7]。抓取过程一般包括:确定抓取目标网址、分析页面内容和结构并确定抓取规则以及借助爬网程序根据规则抓取数据3个步骤[5]。
由于数据抓取技术可以直接解析发布页面进而获得预报信息,不需发布方提供额外的接口或产品,因此,不会影响工作量和后台数据安全。
通过分析4家机构预报页面的结构和内容,确定需要抓取的发布页面的地址形式(即固定的还是动态的)以及需要抓取的预报信息所在位置的标记特点,然后通过编程实现抓取动作,流程如图4所示。

图4 数据抓取方式提取数据流程图
要实现数据抓取需要对各个页面进行不同的数据匹配,主要包括3个步骤:
1)确定发布地址:如果地址是固定的(如:江苏预报发布页面),直接利用该地址进行请求解析;如果地址不是固定的(如:浙江预报发布页面),就通过解析该页面的上一层地址。根据时间或其他关键字确定当天是否有最新预报单发布,如果存在则将该地址确定为最新发布地址。
2) 获取发布内容:为了方便数据的解析,以及保证其准确性,使用AJAX的请求方式,直接对发布地址进行请求,再将反馈内容动态写入指定的容器内,让浏览器自动进行解析,从而得到标准的文件内容,即像操作本地源代码一样对其解析的内容进行操作。
3)写入数据库:将解析后的数据集写入本地数据库的预报信息表内。
4 研究应用
随机选取2012年5月10日至6月28日为统计日期区间,对东海区7家机构的预报产品分别连续获取49次。统计通过数据同步、Web service接口、数据抓取3种方式获取产品的平均成功率如表3所示。

表3 预报产品获取情况统计表
结果分析:
1)可能造成Web service接口获取数据失败的原因主要是被访的服务发布不稳定或是网络拥堵。
2)可能造成页面数据抓取失败的原因包括:a)被访网站服务繁忙,引起页面访问超时,程序无法获取地址或无法解析页面,导致抓取失败。b) 页面文本的格式不规范或结构有变动,程序无法按原定的规则解析页面,导致抓取失败。
3) 3种方式各有特点:a) 数据库直接读取方式虽能稳定地获取数据,但开放数据库存在数据安全隐患。b)页面数据抓取虽然不影响数据安全性,但欠缺灵活性,不仅要求页面发布的格式必须规范,而且如果页面结构改变,需要对程序进行相应调整,否则无法得到正确的数据。c) Web service接口方式既可以较稳定地获取数据,同时也能保证数据传输的安全。
5 结论与展望
通过使用数据同步、Web service接口、数据抓取技术可以初步实现对东海区范围内多家机构的海洋预报产品的集成,为今后预报质量评估所需的预报和实况集成数据库提供预报数据来源。
数据同步和数据抓取2种方式存在一定的局限性。在今后的预报制作和发布平台建设过程中,如果采用统一的预报发布规范和数据接口规范,既有利于域内各预报机构海洋预报产品的集成与共享,又能为海洋预报质量评估提供稳定可靠的数据来源。
[1]尹建锋,胡宏涛.基于Web Services的数据整合在企业中的应用[J].电脑开发与应用,2010,23(1):23-24,27.
[2]龚玲,张云涛.Web服务:原理和技术[M].北京:机械工业出版社,2010.
[3]周长胜.J2EE与.NET在建置XML Web Services方面的比较[J].黑龙江信息,2008,23(3):69.
[4]文求实,陈光忠.基于Web Services的数据库中间件在电网信息管理系统数据库中的应用 [J].自动化技术与应用,2007,(2):71-73.
[5]兰秋军.互联网金融数据抓取方法研究 [J].计算机工程与设计,2011,(5):1 829-1 832.
[6]刘志辉,许捍卫.基于Google Maps API和网络数据抓取技术的 Web GIS 开发[J].测绘通报,2009,(3):68-70.
[7]刘继红,吴军华,任明鑫.基于改进的网络蜘蛛算法抽取Web站点结构的方法[J].江南大学学报(自然科学版),2009,(5):555-559.
猜你喜欢
保健医苑(2022年1期)2022-08-30
中学生数理化·高一版(2021年4期)2021-07-19
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
财经(2017年2期)2017-03-10
福建中学数学(2016年7期)2016-12-03
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
网络安全技术与应用(2011年3期)2011-03-14
