
一种基于熵的连续属性离散方法
2014-02-28 09:32张鹏飞李本威秦明于复磊
燃气涡轮试验与研究 2014年6期
张鹏飞,李本威,秦明,于复磊
(1.海军航空工程学院研究生管理大队,山东烟台264001;2.海军航空工程学院飞行器工程系,山东烟台264001;3.南京军区司令部军训部,江苏南京210016;4.91883部队,山西长治046001)
一种基于熵的连续属性离散方法
张鹏飞1,李本威2,秦明3,于复磊4
(1.海军航空工程学院研究生管理大队,山东烟台264001;2.海军航空工程学院飞行器工程系,山东烟台264001;3.南京军区司令部军训部,江苏南京210016;4.91883部队,山西长治046001)
针对粗糙集理论应用于航空发动机磨损故障诊断的关键问题——连续属性离散化映射,提出了一种考虑属性重要性的基于熵的连续属性离散算法。该算法中,给出了一种衡量连续属性重要度的方法,克服了基于最小熵标准选取断点时最小熵对应多个断点难以取舍的问题,并选用IRIS数据对算法进行了分析和验证。最后,将该算法应用到发动机故障诊断中,自动提取得到了发动机的磨损故障知识,并对待测样本进行了验证,表明了算法的有效性。
航空发动机;离散;信息熵;属性重要性;磨损故障;知识获取
1 引言
航空发动机磨损故障诊断,应用最为广泛的方法是使用专家系统,并已取得了较为显著的成效。但专家系统普遍存在知识获取能力弱、知识获取过于依赖专家等问题,从而限制了其发展。粗糙集理论作为一种研究不精确、不完整信息分类问题的数学工具,可实现专家系统知识的自动获取[1-2]。但粗糙集理论仅能对离散数据进行处理,而实际监测到的光谱数据为连续型参数。因此,连续属性值的离散化映射,是粗糙集理论应用于航空发动机磨损故障诊断中的关键。
目前,人们对于粗糙集连续属性离散进行了广泛研究,提出了很多新的离散方法。依据离散时是否改变原决策表的相容性,这些方法可分为两类:第一类是不把相容性是否改变作为指标,仅考虑数据本身的规律,进而可能得到较少的断点,如MDLP算法[3]、CAIM算法[4]和贺跃等基于熵的离散算法[5]等,但这些算法离散后都破坏了决策表的相容性,使得学习精度较差;第二类则是在保证决策表相容性不变的条件下选取最少的断点,如Nguyen等提出的布尔逻辑与粗糙集理论相结合的离散算法[6],及在此基础上改进的贪心算法[7],都能得到较好的结果,但算法复杂程度呈指数级。谢宏等[8]基于信息熵,从所有条件属性中依据最小信息熵标准选取结果断点,并依据某标准停止算法。该算法可较好地选出最优断点,大大减少了结果断点的数目,但在最小熵对应多个断点时的取舍具有一定的局限性。
本文针对基于最小熵选取断点时最小熵对应多个断点难以取舍的问题,提出了一种考虑属性重要性的基于信息熵的连续属性离散方法,并给出了一种评估连续属性重要度的方法,完善并优化了文献[8]中算法;选用国际上著名的IRIS(鸾尾花)数据,对完善后的算法进行了分析验证。最后,将该算法应用于航空发动机磨损故障诊断知识规则获取。
2 离散化问题描述
粗糙集的相关概念及理论详见文献[9]~[12],此处仅对离散化问题的描述加以说明。
设决策表S=〈U,R,V,f〉,其中U={x1,x2,…,xn},R=A⋃{d},决策种类的个数为r(d)。条件属性值域上的一个断点可记为(a,c),其中a∈A,c∈R。值域Va=[la,ra]上的任意一个断点集合,定义了Va上的一个分类Pa,,其将属性a的取值分为k+1个等价类。因此,任意的定义了一个新的决策表〈U,R,Vp,fp〉,
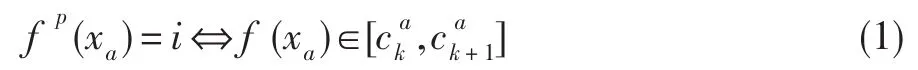
即离散后,原信息系统被一新信息系统所替代。
评价一个离散化算法的优劣性,应从以下方面考查:①连续属性离散化后的空间维数尽量小,即选取的断点应尽量少;②离散前后,决策表的相容性不应改变或在允许范围内变化;③离散的断点经后续处理后,应具有较好的分类预测精度,即提取出的规则有较好的泛化能力[13]。
3 考虑属性重要性的基于信息熵的连续性离散化方法
3.1 基于信息熵的连续属性离散化方法
文献[8]提出了一种基于信息熵理论的粗糙集离散化算法,其在Shannon信息熵的基础上,定义了粗糙集决策表中的每个分类集合的信息熵H(X),和断点针对集合的信息熵H(c,X)。具体原理如下:
首先对各条件属性的属性值进行排序,取相邻两个属性值的中点为候选断点;接着计算每个候选断点针对给定集合X的信息熵H(c,X),并选取具有最小信息熵的断点加入到结果断点集中,当两个断点的信息熵相同时,比较两个断点所在属性已选取的断点数,优先选取断点数少的属性的断点;然后根据选取的断点对原集合进行划分,重复计算剩余候选断点对划分后集合的信息熵,直到整个决策表相容为止。各参数定义及具体步骤详见文献[8]。
该算法在不改变决策表相容性的前提下,可获得较为理想的离散效果,能大大减少断点数目。但当两个断点的信息熵相同时,该算法优先选取已选断点数少的属性的断点,这具有一定的随意性;并且当两属性已选取的断点数也相同时,该算法将不适用。因此,本文引入属性重要性评估,完善并优化文献[8]中算法。
3.2 连续属性重要性评估
针对连续属性,当决策表中各条件属性互异的属性值个数较多时,文献[9]中给出的经典属性重要性判断方法,将不能很好地分辨各属性的重要性。在此,给出一种衡量连续属性重要度的方法。

式中:k=1,2,…,L。
mi表示第i类样本单位化后的均值,有:

Si表示第i类样本单位化后的类内散度,有:

以上两式中:i=1,2,3,…,n。
针对连续属性a,其越易分辨各类别,则重要性越大。为更好地分辨各类别,则应类间距离大、类内分布散度小。为此,连续属性a的重要度定义为:
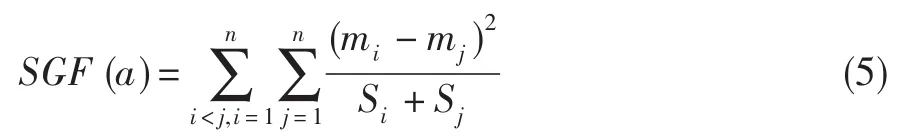
3.3 考虑属性重要性的离散算法
设决策表S=〈U,A∪{d},V,f〉,条件属性集合A={a1,a2,…,an},P为已选取断点的集合,Q为实例被断点集合P所划分成的等价类集合,B为候选断点的集合,H为决策表信息熵,α表示离散后决策表的相容度,具体计算见文献[10]。则离散化算法如下:
步骤1:初始化,P=φ,H=H(U),Q={U}。
步骤2:将各条件属性的属性值排序,取相邻两个属性值的中点加入到候选断点集B中。
步骤3:对每一个断点c∈B,计算H(c,Q)。
步骤4:若H≤min{H(c,Q)}或min{H(c,Q)}=0,则结束,否则转步骤5。
步骤5:H(cmin,Q)=min{H(c,Q)},若cmin不是唯一断点则转步骤6,若其是唯一断点则转步骤7。
步骤6:计算信息熵相同断点的条件属性的重要度SGF(ai),选取重要度大的条件属性的断点作为结果断点。
步骤7:P=P⋃{cmin},H=H(c,Q),B=B-{c},cmin把等价类X划分为X1和X2;将X从Q中去除,把等价类X1和X2加入到Q中。
步骤8:计算离散后的决策表的相容度α,若α=1,则结束,输出断点集P;若α<1,则转步骤3。
4 方法验证
选用IRIS数据实验来验证算法的有效性。该数据集包含三种IRIS,每种50个样本,共计150个样本;4个条件属性,分别记为A1、A2、A3、A4。
首先对150个数据,分别用文献[8]算法和本文算法进行计算。按文献[8]算法计算,在计算第一个结果断点值时,断点(A4,0.80)和断点(A3,2.45)计算所得熵值最小,均为0.333 3;且之前各条件属性的断点数均为0,文献[8]算法无法取舍,计算中止。为使运算继续,在此处随机选取一结果断点,计算结果如表1所示,得到4个剩余属性,7个断点。按照本文算法计算,由表2可知A4的属性重要度大于A3,则优先选取断点(A4,0.80),断点最终计算结果如表3所示,得到6个结果断点。这说明本文算法能很好地解决文献[8]算法的局限性,并可得到较少断点。
为进一步验证本文算法的有效性,进行了规则获取实验。作为对比,首先采用文献[3]中的MDLP离散算法、文献[8]中基于信息熵的离散算法和本文算法进行离散,然后运用一般约简算法进行属性约简、启发式约简算法进行属性值约简,最后采用获取的知识规则对测试数据进行测试。同时,运用10折交叉验证准则来比较和评价算法,即在实验初将原始数据随机分为10份,在每次实验中利用其中9份进行离散、提取规则,用剩余的1份作为测试集,轮转一遍进行10次实验取其平均值,各统计结果见表4。

表1 文献[8]中算法离散化断点结果Table 1 Discretized breakpoint results by the algorithm in reference[8]

表2 属性重要性Table 2 Attribute importance

表3 本文算法离散化断点结果Table 3 Discretized breakpoint results by the new algorithm
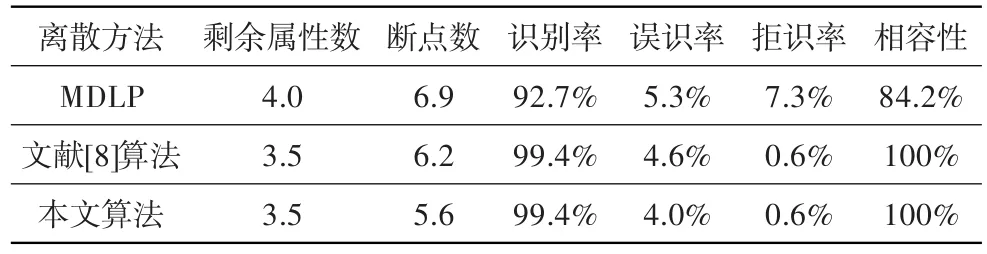
表4 不同方法的10折交叉验证结果Table 4 10-fold crossover validation results
分析表4:MDLP是一种基于信息熵的局部离散算法,对每个属性离散时,没考虑其他属性及相互间的影响,往往会破坏原始数据的相容性,故测试结果的识别效果最差。文献[8]算法在全局搜索具有最小信息熵的断点,并以决策表相容性为停止准则,因此其与MDLP相比,计算结果的各评价指标都有较大提升。本文算法在文献[8]算法基础上,引入属性重要性评估,重要属性理应优先获取断点,进而可最快达到停止准则;其计算结果与文献[8]算法相比,离散后的断点数减少了9.7%,误识率下降了13%,使得得到的规则更为简单,正确辨识率提高,进而验证了本文算法的有效性。
5 应用实例
应用本文离散算法对某型航空发动机油样光谱分析数据进行离散,然后运用一般约简算法进行属性约简、启发式约简算法进行属性值约简,对磨损故障进行知识获取,并进行验证。该数据包含了10台航空发动机在正常状态和磨损状态下的234个样本,条件属性分别为Fe、Al、Cu、Cr、Ag、Ti、Mg七种元素的含量。磨损状态F分别为1(正常)、2(轴间轴承磨损)、3(轴间轴承磨损且保持架断裂)三种形式。磨损状态F为决策属性D,具体数据见文献[14]。随机选取其中154个样本数据作为训练样本进行规则提取,用其余的80个样本作为测试样本对规则进行验证。计算结果见表5~表8。从表8可以看出,提取的规则对测试样本识别很好,误识率仅为1.25%,识别精度较高,表明该算法可有效离散光谱数据,进而实现航空发动机磨损故障知识的自动获取,验证了本文方法在实例应用中的有效性。

表5 属性重要性Table 5 Attribute importance

表6 光谱元素离散断点结果Table 6 Spectral element discretized breakpoint results

表7 规则提取结果Table 7 Results of extracting rules
检查误识样本,其Fe含量为19.2 ppm,Cu含量为1.5 ppm,实际类别为轴间轴承磨损且保持架断裂,将其误分为了类别2轴间轴承磨损。其原因可能是:由于上述规则依据本文算法直接从样本数据中提取得到,其正确性和适用性很大程度上依赖于样本集的完整性和代表性。为提高磨损故障诊断精度,在不断完善样本集的同时,还应考虑相关的先验知识,如摩擦副材料、专家经验等。如何将其结合进行融合诊断,是下一步研究的重点。

表8 规则验证结果Table 8 Verification results for rules
6 结束语
本文提出了一种考虑属性重要性的基于信息熵的粗糙集连续属性离散算法,完善了文献[8]中算法的局限性,得到了更好的计算结果,并利用IRIS数据进行了分析和验证。最后,将该算法应用于航空发动机磨损故障知识提取中,自动提取得到了航空发动机的磨损故障知识,并用测试样本数据验证了规则的正确性,表明了本文算法的有效性。
[1]陈果,宋兰琪,陈立波,等.基于粗糙集理论的航空发动机滑油光谱诊断专家系统知识获取方法研究[J].机械科学与技术,2007,26(7):897—901.
[2]刘燕,李世其,董颖辉,等.油液监测诊断系统的知识发现方法研究[J].机械科学与技术,2010,29(4):524—527.
[3]Fayyad U M,Irani K B.Multi-Interval Discretization of Continuous-Valued Attributes for Classification Learning [C]//.Proceedings of Thirteenth International Joint Confer⁃enceonArtificialIntelligence.SanMateo:Morgan Kaufmann Publishers,1993:1022—1027.
[4]Kurgan L A,Cios K J.CAIM Discretization Algorithm[J]. IEEE Transactions on Knowledge and Data Engeering,2004,16(2):145—153.
[5]贺跃,郑建军,朱蕾.一种基于熵的连续属性离散化算法[J].计算机应用,2005,25(3):637—638.
[6]Nguyen H S,Skowron A.Quantization of Real Values At⁃tributes,Rough Set and Boolean Reasoning Approaches [C]//.Proceedings of the Second Joint Annual Conference on Information Science.Wrightswile Beach,1995:34—37.
[7]Nguyen H S,Nguyen H S.Some Efficient Algorithms for Rough Set Methods[C]//.Proceedings of the Conference of Information Processing and Management of Uncertainty in Knowledge-Based Systems.Spain,1996:1451—1456.
[8]谢宏,程浩忠.基于信息熵的粗糙集连续属性离散化算法[J].计算机学报,2005,28(9):1570—1574.
[9]王国胤.Rough集理论与知识获取[M].西安:西安交通大学出版社,2001.
[10]曾黄麟.智能计算[M].重庆:重庆大学出版社,2004.
[11]张文宇,贾嵘.数据挖掘与粗糙集方法[M].西安:西安电子科技大学出版社,2007.
[12]Richard J,Michael R,Geatz W.数据挖掘教程[M].翁敬农,译.北京:清华大学出版社,2003.
[13]石红.一种基于粗糙集的离散化算法[J].模式识别与人工智能,2006,19(3):412—416.
[14]葛科宇.发动机磨损故障知识获取方法研究及应用平台开发[D].南京:南京航空航天大学,2011.
A Method of Continuous Attributes Discretization Based on Entropy
ZHANG Peng-fei1,LI Ben-wei2,QIN Ming3,YU Fu-lei4
(1.Graduate Students’Brigade,Naval Aeronautical and Astronautical University,Yantai 264001,China;2.Department of Aerocraft Engineering,Naval Aeronautical and Astronautical University,Yantai 264001,China;3.Command Department of Nanjing Military Region,Nanjing 210016; 4.The 91883thUnit of PLA,Changzhi 046001,China)
In view of the key problems of aero-engine wear fault diagnosis for application of rough set theo⁃ry,a new method of continuous attribute discretization based on entropy was proposed.In the method,a new measure of assessing the importance of continuous attribute was given to solve the problem of breakpoint choice.The IRIS data was used to analyze and verify the method.Finally,this method was applied to the aero-engine fault diagnosis.The wear fault knowledge was extracted automatically and verified by the sam⁃ples,proving the validity of the algorithm.
aero-engine;discretization;information entropy;attribute importance;wear fault;knowledge acquisition
V263.6;TP18
:A
:1672-2620(2014)06-0049-04
2014-04-14;
:2014-09-25
张鹏飞(1989-),男,河南宝丰人,硕士研究生,主要从事航空发动机状态监控、故障诊断等领域研究。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
辽河(2022年4期)2022-06-09
科教导刊·电子版(2021年6期)2021-05-06
洛阳师范学院学报(2021年2期)2021-03-31
电脑报(2019年20期)2019-09-10
小型微型计算机系统(2019年9期)2019-09-09
计算机与数字工程(2019年8期)2019-09-03
电子技术与软件工程(2019年12期)2019-08-22
初中生世界·九年级(2019年6期)2019-08-15
计算机与生活(2019年3期)2019-04-18
