
基于龙芯3B处理器的Linpack优化实现
2014-05-12 07:57刘刚,张恒,张滇,毛睿
深圳大学学报(理工版) 2014年3期
刘 刚,张 恒,张 滇,毛 睿
深圳大学计算机与软件学院,广东省普及型高性能计算机实验室,深圳 518060
基于龙芯3B处理器的Linpack优化实现
刘 刚,张 恒,张 滇,毛 睿
深圳大学计算机与软件学院,广东省普及型高性能计算机实验室,深圳 518060
HPL是高性能计算广泛采用的Linpack测试软件包.针对龙芯3B处理器体系结构的特点,为Linpack中的核心部分——矩阵乘法设计矩阵分块策略,利用龙芯3B的cache锁机制将频繁调用的数据分块锁在cache中,从而显著降低cache缺失率.同时为龙芯3B处理器中的访存加速部件设计了高效的预取算法,以实现计算时间掩盖访存时间.另外,分别对Linpack所调用的dtrsm和行交换等热点函数进行优化,并通过参数训练来优化Linpack参数.实验结果表明,在龙芯3B处理器上,单节点4核以及双节点8核的Linpack实测性能均达到理论峰值的60%左右,优化后的Linpack性能较优化前提升了10倍左右.
计算机系统结构;龙芯3B处理器;线性系统软件包;矩阵乘法;数据预取
在信息社会,高性能计算 (high performance computing,HPC)是衡量国家科技能力的重要标志,被广泛用于数值计算、金融统计和模拟仿真等领域.龙芯系列处理器是中国科学院计算技术研究所自主研发的通用处理器,其中龙芯3B处理器[1]是面向高性能应用设计的多核处理器,现已成功研制出国产万亿次普及型高性能计算机KD-90[2-3].
线性系统软件包 (linear system package,Linpack)[4]通过使用高斯消元法求解稠密一元N次线性代数方程组来评估高性能计算机的实际浮点性能.Linpack根据问题规模与优化选择的不同分为Linpack100、Linpack1000及 HPL(high performance Linpack)[5].前两种测试包因运行规模较小且固定不变,已不适于现代计算机的发展;HPL由于规模可变,成为目前最流行的用于测试高性能计算机浮点性能的测试基准.当Linpack求解问题规模为N时,浮点计算次数为(2/3×N3-2N2),若计算时间为t,则HPL测试值=计算量×(2/3×N3-2N2)/t,测试结果是高性能机Top 500排名的重要依据.
本研究基于龙芯3B处理器,对HPL测试程序进行分析和优化.通过分析Linpack算法找到制约HPL峰值性能的因素;分析龙芯3B处理器的特性,并针对该体系结构优化Linpack的核心函数矩阵乘法及其他热点函数.实验表明,优化后的Linpack性能测试较优化前提升10倍左右.
1 Linpack算法分析
Linpack采用高斯消元法求解N元一次稠密线性代数方程组的测试来评估高性能计算机的浮点性能,它也是目前国际最流行的高性能计算机测试基准.高斯消元法首先将系数矩阵A,通过分块递归的LU分解法,将其分解,为一个下三角阵L与一个上三角阵U的乘积,然后将线性代数方程组Ax=b变成Ux=L-1b形式,最后,通过上三角方程回代求得线性方程组的解[6].
图1为Linpack中分块递归的第i次LU分解算法过程,其基本思想是,通过递归将大矩阵分解为小的分块子矩阵,小的分块矩阵再分解为更小的分块子矩阵,直到子矩阵的分块足够小.其中,N为矩阵规模;M为矩阵分块的大小;A、L和U为普通矩阵;H为下三角矩阵;P为记录行交换信息的数组.分块递归LU分解算法每完成M大小的矩阵LU分解后,将问题转换为一个规模更小的矩阵LU分解问题.每次分解过程包括3部分:首先,对图1中panel内 (图1中阴影区域为一个panel)M×M大小的矩阵通过选主元的操作进行LU分解,并记录各列主元所在的行,如图1(b)中步骤②;然后,广播LU分解后所得的panel内部分矩阵及行交换信息;最后,根据LU分解后的矩阵以及行交换信息对整个系数矩阵的其他部分进行行交换操作以及更新操作,如图1(b)中步骤④—步骤⑥.

图1 Linpack中分块递归的LU分解Fig.1 Block recursive LU decomposition in Linpack
可见,运行Linpack测试程序的时间主要花在对矩阵的更新操作上.表1是对未优化的Linpack程序进行的测试结果.其中,测试矩阵的规模为10 240×10 240,分块大小为128 byte,测试时间为1 127.41 s.由表1可见,该程序主要耗时在其调用的基础线性代数子程序库 (basic linear algebra subprograms,BLAS)中与矩阵和向量相关的计算中 (其中,dgemm实现普通双精度矩阵与矩阵之间的计算;单进程时dgemmNN完成图1中A的更新操作;dgemmNT完成图1中panel内部矩阵更新操作).

表1 未优化时Linpack测试的时间占比Table 1 Original Linpack test 单位:%_
2 龙芯3B处理器上的Linpack优化
龙芯3A 4核处理器和龙芯3B 8核处理器均是中国科学院计算技术研究所自主研发的国产高性能处理器.何颂颂等[7]利用龙芯3A的128 bit访存指令、循环展开及使用地址交错技术减少擦车冲突失效等策略,使Linpack效率从优化前的27%提高至57%.与龙芯3A处理器结构不同,龙芯3B处理器片内集成8个64 bit的GS464V处理器核,支持向量运算加速,如图2.其中,每4个处理器核构成1个节点,节点之间通过总线互连 (hyper-transport,HT).龙芯3B处理器有两个特殊的访存加速部件,即矩阵转置模块和向量存储器直接访问 (direct memory access,DMA)通道,前者通过软件配置可实现对存放在内存的矩阵从源矩阵到目标矩阵的行列转置或搬移功能;后者包含3个读通道和1个写通道,通过配置其寄存器可实现内存或cache与浮点/向量寄存器间的直接读写操作.此外,龙芯3B处理器共享的cache在设计时增加了锁机制,通过配置锁窗口寄存器,位于加锁区域中的cache块会被锁住,因此不会被替换出cache.
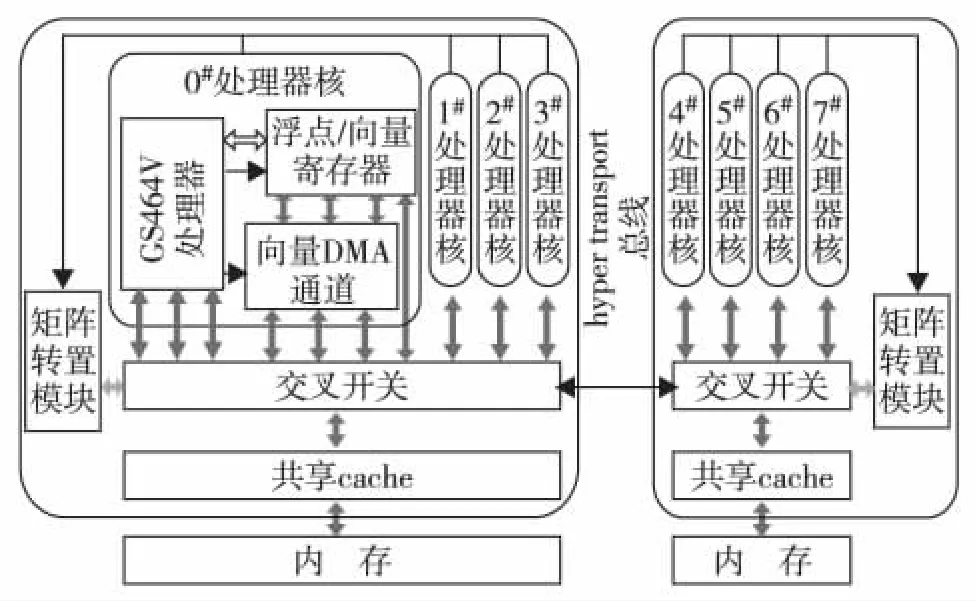
图2 龙芯3B处理器体系结构Fig.2 Loongson3B processor architecture
本研究针对龙芯3B处理器的体系结构,对Linpack测试程序进行优化,以期提高其测试值.
2.1 dgemm函数优化
该函数实现的是LU分解中A及panel内部矩阵的更新操作,其本质是普通双精度矩阵间的乘加运算.本研究利用龙芯处理器提供的向量指令及访存加速部件对其进行优化.
2.1.1 向量化计算
龙芯3B处理器提供了一组256 bit的向量浮点寄存器堆,以及一组针对寄存器堆的向量计算与访存指令.通过向量乘加指令、128 bit访存指令与256 bit寄存器堆的配合,实现矩阵的向量化运算.
向量乘加指令,即在支持向量乘加操作的龙芯3B处理器上,其将分开的乘法和加法指令合并成1条乘加指令.该指令可在1个时钟周期内完成4次双精度浮点乘加运算,故可大幅提升效率[8].
128 bit向量访存指令,即将普通的64 bit访存指令替换为128 bit向量访存指令,不仅可减少访存指令数,还可提高程序性能.配合向量浮点寄存器的数据置换指令可将4个双精度数据存入256 bit向量浮点寄存器中,满足向量乘加指令要求.
2.1.2 大规模矩阵乘法的分块与预取策略
数据分块技术就是通过重新组织数据的访问顺序,减小cache的失效率来提高程序性能的方法.文献[9]针对矩阵乘法中矩阵分块方法进行了论证,本研究在此基础上针对龙芯3B体系结构及其访存加速部件设计了数据移动代价最小、运算访存比最高的划分方案,如图3(a).
通过龙芯3B处理器的cache锁机制,把一些局部性佳的数据和一些被经常调用的子函数 (即指令集合)锁在cache中,可降低cache的缺失率,提高整体性能.在矩阵乘法计算中,将图3(a)中第4层mr×kc大小的矩阵A和kc×nc大小的矩阵B的小块数据拷贝到连续地址空间,并锁在cache中,如图3(b),将实现矩阵乘加运算的核心函数锁在cache中.这样,在核心循环计算中,取数据和取指令均不会发生cache缺失,提高了执行效率.
图3(c)为龙芯3B上基于访存加速部件的矩阵乘法计算的预取策略.其中,A0和 A1为图3(a)中mr×kc大小的小块矩阵A;B0为kc×nc大小的小块矩阵B(B在计算中会被划分成kc×nr的更小矩阵块与mr×kc大小的矩阵A和mr×nr大小的矩阵C);C0和C1为mr×nr大小的小块矩阵C.
算法具体实现过程为:在计算A0与B0时,通过转置模块将下一块A1预取到锁住的cache中;在计算C0时利用向量DMA的读通道将下一块矩阵块C1从内存预取到下一组向量寄存器中;而在计算C1时将通过向量DMA的写通道把矩阵块C0写入内存;写完后将下一块C2预取到C0存放的寄存器中.在计算mr×nr的小块矩阵C中,参与计算的A和B都是通过向量DMA的读通道从锁住的空间中预取到寄存器中的,每次预取A和B的大小分别为mr×kr和kr×nr.
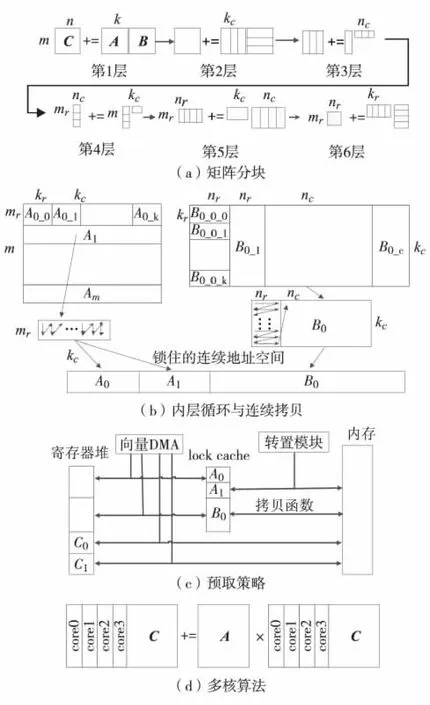
图3 龙芯3B上矩阵分块与预取策略Fig.3 Block matrix and prefetching strategy on Loongson 3B
在龙芯3B中,每4个处理器核为1个节点,它们共享一个矩阵转置模块、L2cache和内存控制器.本研究在龙芯3B的一个节点上采用1进程分4线程计算的模式,线程任务划分如图3(d),将B划为4个部分分别由4个线程计算.由4核共享1个矩阵转置模块,A的预取工作全部由主线程完成.
为达到最佳性能,算法要求使用访存加速部件所实现的读写能被完全掩藏在计算中,即满足式(1)至式(3)的限制.其中,Rcomp为CPU的计算速度;Rmem为从内存中读写的访存带宽;Rcache为向量DMA读写时cache命中的访存带宽.

其中,M为寄存器堆大小
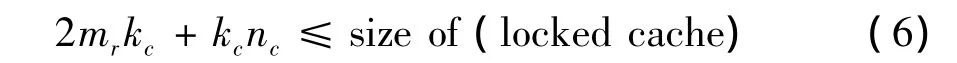
式(1)保证在完成当前mr×nr大小的矩阵C计算前,向量DMA能将上一轮计算完的C写入内存并读取完下一轮即将参与计算的C值;式(2)保证在完成mr×kc大小的矩阵A与kc×nc大小的矩阵B计算前,矩阵转置模块能完成下一块mr×kc大小的矩阵A从内存搬到锁住的cache中的预取工作;式(3)保证核心循环在完成当前mr×kr大小的矩阵A与kr×nr大小的矩阵B计算前,向量DMA能够完成下一轮即将参与计算的mr×kr大小的矩阵A和kr×nr大小的矩阵B的预取工作;式(4)为核心循环中计算与访存之间的比例关系.可见,当mr=nr时计算访存比最大,且比值随mr和nr的增大而增大,即mr和nr的值越大,访存压力越小.
由式(1)和式(2)可知,kc和nc的值越大,向量DMA读写C和转置模块预取A就越能被掩藏在计算中.由式(3)和式(4)可知,mr和nr的值越大,向量DMA的访存压力越小,且A和B的预取时间就越能被掩盖.但是这些值必须满足式(5)和式(6)所限制的条件:式(5)要求所用向量寄存器不能超过龙芯3B处理器能提供的最大个数;式(6)要求锁住的A和B不能超过龙芯3B处理器可提供的最大锁住空间(s表示A和B的寄存器每经过多少次计算后才会重复使用之前的寄存器,kr为每次计算选取几列参与计算.由实验可知,当s=4,kr=2时可获得比较理想的性能).为此,在条件允许的情况下,尽可能增大mr、nr、kc和nc的值.
2.1.3 小规模矩阵的乘法优化
在Linpack算法中为panel内部矩阵更新而调用矩阵乘法运算中,矩阵B的规模k和n都非常小,最大不超过Linpack测试分块M的一半,最小值为2.此时由于k和n非常小,每个局部计算时间都很短,造成向量DMA对数据的读写时间不能被忽略,加之启动向量DMA等需要时间,导致在k和n非常小时,上述算法的性能比使用128 bit向量访存指令直接在内存中进行读写并使用向量乘加指令进行向量化计算的效率低.
此外,龙芯3B处理器的ld指令和$0寄存器配合使用可实现非阻塞的预取功能,即在不阻塞流水线的情况下,将数据加载到1级数据cache.同时,循环展开和合理的指令调度[10-12]可有效解决因数据相关而产生的流水线中断.因此,在对矩阵乘法向量化计算的同时,结合预取指令、循环展开和合理调度指令可有效提高程序性能.
2.2 dtrsm函数优化
在Linpack测试中,dtrsm函数实现了图1中矩阵U的更新,即一个三角矩阵求逆后与一个矩阵相乘的操作,B=A-1B或B=BA-1.未优化时,该函数由于未能充分利用龙芯3B处理器资源而无法达到理想性能,本研究则利用前面针对矩阵乘法优化的方案对该函数进行优化.具体实现如图4,将三角矩阵求逆后存放在锁住的cache中,再分块调用矩阵乘法来实现.
上述算法虽有冗余计算,但相对Linpack调用的原始BLAS库,因该算法充分利用了龙芯3B处理器的cache锁机制、向量指令及访存加速部件,性能较理想.
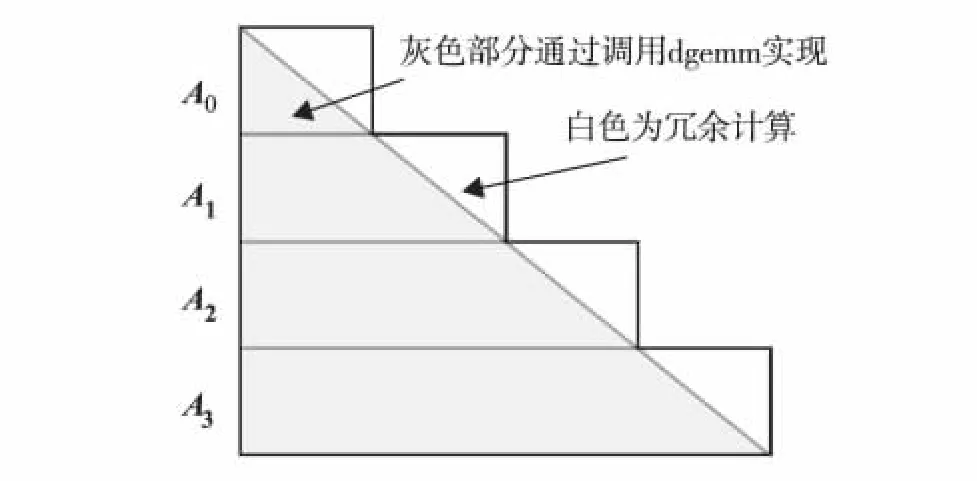
图4 龙芯3B上dtrsm实现Fig.4 Dtrsm implementation on Loongson 3B
2.3 dgemv函数优化
在Linpack测试中,dgemv函数实现了对列向量x的求解及列向量b的更新操作,其本质是一个列向量与矩阵的乘加操作.由于参与计算的一个矩阵为列向量,导致直接调用上述优化后的dgemm函数会因向量DMA的访存时间不能被完全掩盖而达不到理想性能.因此,本研究使用小规模矩阵乘法优化的方案对该函数进行优化.
2.4 行交换的并行化优化
在每次LU分解过程中,需进行M次行交换.由于Linpack测试中,矩阵是列主序存放的,在进行行交换时因地址不连续而导致大量缓存不命中及页缺失,因而耗时大.由于访问地址的不连续及行交换的数据具有相关性 (交换次序不能更改),使该函数无法使用向量指令和访存加速部件对其进行优化.在Linpack测试中,行交换是通过单线程来实现的,所以可通过对其列方向进行多线程并行化操作来优化.如图5,各线程根据数组P[i]的值即主元行与目标行依次进行互换工作.
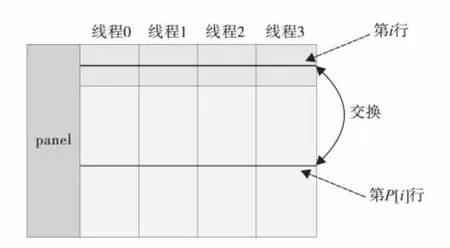
图5 行交换的多线程优化Fig.5 Optimize row interchanges by multi-thread
3 实验与性能分析
本研究实验平台为800 MHz的龙芯3B处理器(单节点理论峰值为51.2 Gflops),内存控制器频率为350 MHz,每个节点内存容量为8 Gbit.实验时,Linpack测试调用的底层BLAS库为GotoBLAS库.矩阵乘法优化时所选择的各分块参为:mr=12,nc=480,kc=384,nr=12,kr=2,s=4.
在矩阵乘法实验中,矩阵规模m和n取等值并从小变大,而k的取值为分块kc的值(即k=384);而在Linpack测试中,分块参数M也取kc的值 (这样可保证在Linpack调用矩阵乘法运算时k=384,避免边角影响性能).
表2为矩阵乘法单核和4核在优化前后的测试结果对比.从表2可见,优化后的矩阵乘法单核算法性能 (效率)约为理论峰值的90%,4核算法性能约为理论峰值的83%,性能较未优化的Goto-BLAS库中矩阵乘法提升了10倍左右.

表2 矩阵乘法优化结果Table 2 Optimization of Matrix multiplication单位:%
表3和表4分别为龙芯3B处理器的单节点和双节点在Linpack优化前后的对比实验结果.表3中选项1为优化dgemm函数;选项2为优化dgemm函数和 dtrsm函数;选项3为优化 dgemm函数、dtrsm函数和dgemv函数;选项4为优化dgemm函数、dtrsm函数、dgemv函数和行交换.单节点Linpack测试时使用1个进程进行测试,其调用上述优化函数均采用4线程进行计算.双节点Linpack采用2个进程进行测试,即每个节点上运行一个进程(双节点测试时,Linpack的配置文档中表示进程2维网格的P和Q取值分别为1和2).从表3和表4可见,经一系列函数优化后,随着矩阵规模的增大,无论单节点还是双节点,其Linpack测试值均达到龙芯3B处理器理论峰值的60%左右,性能较未优化时提升了10倍左右.
本研究的矩阵乘法优化算法在单线程时随矩阵规模的变大其性能亦变大,并最终稳定在理论峰值的90%左右,但最高也仅90%(误差为±1.0%).这是由于CPU启动矩阵转置模块、向量DMA读写通道及判断其各自的信号位、清信号位等操作都需时间.4算法性能较单核低约7%,原因在于4算法中线程之间的同步会对性能产生影响;另由于4线程算法是从锁住的cache中读取共享矩阵A,使cache的供数压力变大,导致向量DMA读A的延迟变大,最终致4核算法的效率低于单核算法.
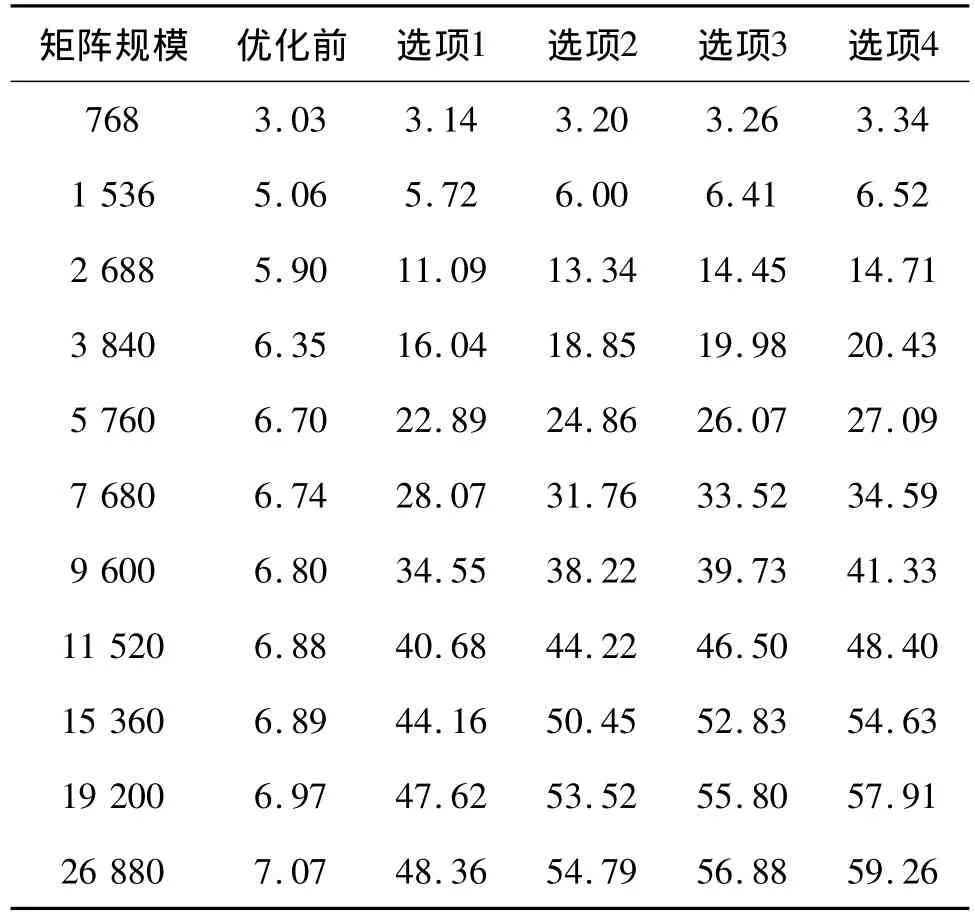
表3 Linpack单节点效率测试结果Table 3 Linpack single-node testing 单位:%
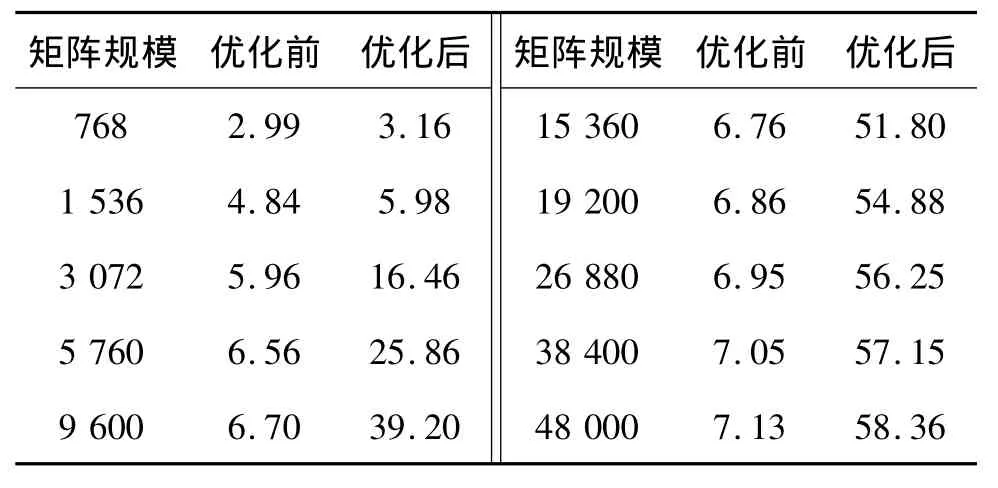
表4 Linpack双节点测试结果Table 4 Linpack two-node testing 单位:%
如表4,在Linpack测试中,经过函数优化后其性能仅理论峰值的60%,这是由于本研究只优化了上述的几个函数,而Linpack调用的其他函数尚未被优化,而这些未优化的函数都是使用单线程计算的,故导致性能不理想.而双节点测试时,相同规模的测试比单节点又低约2%,这是由于双节点测试时,两个进程之间的通信要消耗一部分时间,故导致相同测试规模双节点效率较低.
结 语
本研究针对中国自主研发的龙芯3B处理器对Linpack测试程序进行分析并优化.对Linpack的核心函数矩阵乘法,根据龙芯3B处理器的体系结构特点,设计合理的矩阵分块,利用龙芯3B的访存加速部件将矩阵的访存时间掩藏在计算中;对于其他的几个特点函数,利用多线程、向量化等一系列优化技术进行优化.经过优化的Linpack核心函数矩阵乘法运算在单核和多核都超过理论峰值的80%,Linpack测试也接近理论峰值的60%.
本研究的优化技术仅针对Linpack测试算法中对性能影响较大的几个函数,其他未优化部分均使用单线程进行计算,现阶段研究尚未充分利用龙芯3B处理器的多核优势;此外Linpack自身的配置文档中各配置参数对Linpack测试值的影响在此并未进行分析论证,这些都将在下一步工作中进行.
/References:
[1]Chinese Academy of Sciences Institute of Computing Technology.Loongson 3B processor user manual:volume 1[M].V1.0.Beijing:Chinese Academy of Sciences Institute of Computing Technology,2011.(in Chinese)
中国科学院计算技术研究所.龙芯3B处理器用户手册:上册[M].V1.0版.北京:中国科学院计算技术研究所,2011.
[2]Cai Ye,Liu Gang,Mao Rui,et al.Design and performance optimization of a popular high performance computing system KD-90 [J].JournalofShenzhen University Science and Engineering,2013,30(2):138-143.(in Chinese)
蔡 晔,刘 刚,毛 睿,等.KD-90普及型个人高性能计算机系统设计与性能优化 [J].深圳大学学报理工版,2013,30(2):138-143.
[3]Chen Guoliang,Cai Ye,Luo Qiuming.The China made personal high performance computing system [J].Journal of Shenzhen University Science and Engineering,2011,28(6):471-477.(in Chinese)
陈国良,蔡 晔,罗秋明.国产个人高性能计算机系统研制[J].深圳大学学报理工版,2011,28(6):471-477.
[4]Dongarra Jack J,Luszczek P,Petitet A.The Linpack benchmark:past,present,and future [J].Concurrency and Computation:Practice and Experience,2003,15(9):803-820.
[5]Petitet A,Whaley R C,Dongarra J,et al.HPL:A portable implementation of the high-performance Linpack benchmark for distributed-memory computers[EB/OL].[2012-10-26].Claxton(USA):University of Tennessee.http://www.netlib.org/benchmark/hpl/.
[6]Zhang Wenli,Chen Mingyu,Fan Jianping,et al.Emulation and forecast of HPL test performance[J].Journal of Computer Research and Development,2006,43(3):557-562.(in Chinese)
张文力,陈明宇,樊建平,等.HPL测试性能仿真与预测并行Linpack分析与优化探讨 [J].计算机研究与发展,2006,43(3):557-562.
[7]He Songsong,Gu Naijie,Zhu Haitao,et al.Optimization of BLAS for Loongson-3A architecture[J].Journal of Chinese Computer Systems,2012,33(3):571-575.(in Chinese)
何颂颂,顾乃杰,朱海涛,等.面向龙芯3A体系结构的BLAS库优化[J].小型微型计算机系统,2012,33(3):571-575.
[8]Goto K,Van De Geijn R.High performance implementation of the level3 BLAS [J].ACM Transactions on Mathematical Software,2008,35(1):12-26.
[9]Zhu Haitao,Chen Yunji,Qian Cheng,et al.Optimization of matrix multiplication based on mutli-core architecture extended with vector unit[J].Journal of University of Science and Technology of China,2011,41(2):174-182.(in Chinese)
朱海涛,陈云霁,钱 诚,等.基于向量扩展多核处理器的矩阵乘法算法优化研究[J].中国科学技术大学学报,2011,41(2):174-182.
[10]Li Wenlong,Liu Li,Tang Zhizhong.Loop unrolling optimization for software pipelining[J].Journal of Beijing University of Aeronautics and Astronautics,2004,30(11):1111-1115.
[11]Goto K.Anatomy of high-performance matrix multiplication [J].ACM Transactions on Mathematical Software,2007,34(3):1-24.
[12]Sasou T,Matsuoka S.Performance tuning high-performance linpack(HPL) [J].IPSJ SIG Notes,2002,91(22):125-130.(in Japanese)
笹生健,松岡聡.HPLのパラメータチューニングの解析 [J].IPSJ SIG Notes,2002,91(22):125-130.
2013-04-25;Revised:2014-02-25;
2014-04-28
Optimization of Linpack for Loongson 3B processor
Liu Gang,Zhang Heng,Zhang Dian,and Mao Rui†
College of Computer Science and Software Engineering,Guangdong Province Key Laboratory of Popular High Performance Computers,Shenzhen University,Shenzhen 518060,P.R.China
High performance Linpack(HPL)is a linpack benchmark package widely adopted in high performance computing.An efficient partition strategy is introduced by Loongson 3B processor's architectural features in the matrix multiplication,and the cache lock mechanism which locks the frequently used data blocks into the locked cache is introduced to reduce the missing cache.To make the computation cost hides the memory access cost,a new prefetching algorithm is included in the memory access acceleration device.Other functions,such as dtrsm and line swapping,are optimized,and the optimal value is achieved for each parameter by training.Experimental results indicate that both single-node(4 cores)and double-node(8 cores)have achieved about 60%of theoretical peak performance,which are nearly 10 times performance improvement compared with non-optimized Linpack.
computer architecture;Loongson 3B processor;linear system package;matrix multiplication;data prefetching
TP 301;TP 319
A
10.3724/SP.J.1249.2014.03286
Foundation:National High-Tech Research and Development Program of China(2012AA01A30904);Academician Workstation Construction Projects in Guangdong Province(2012B090500020)
†
Associate Professor Mao Rui.E-mail:mao@szu.edu.cn
:Liu Gang,Zhang Heng,Zhang Dian,et al.Optimization of Linpack for Loongson 3B processor [J].Journal of Shenzhen University Science and Engineering,2014,31(3):286-292.(in Chinese)
国家高技术研究发展计划资助项目(2012AA01A30904);广东省院士工作站建设项目 (2012B090500020)
刘 刚 (1978—),男 (汉族),安徽省合肥市人,深圳大学讲师、博士.E-mail:gliu@szu.edu.cn
引 文:刘 刚,张 恒,张 滇,等.基于龙芯3B处理器的Linpack优化实现[J].深圳大学学报理工版,2014,31(3):286-292.
【中文责编:英 子;英文责编:雨 辰】
猜你喜欢
小学生学习指导(低年级)(2022年10期)2022-11-05
中国交通信息化(2022年9期)2022-10-28
数学小灵通(1-2年级)(2021年10期)2021-11-05
语数外学习·初中版(2020年11期)2020-09-10
山东农业工程学院学报(2020年12期)2020-03-19
小学生学习指导(低年级)(2019年9期)2019-09-25
湖州师范学院学报(2016年2期)2016-08-21
华人时刊(2016年13期)2016-04-05
山西大同大学学报(自然科学版)(2016年6期)2016-01-30
信息安全与通信保密(2015年9期)2015-11-02
